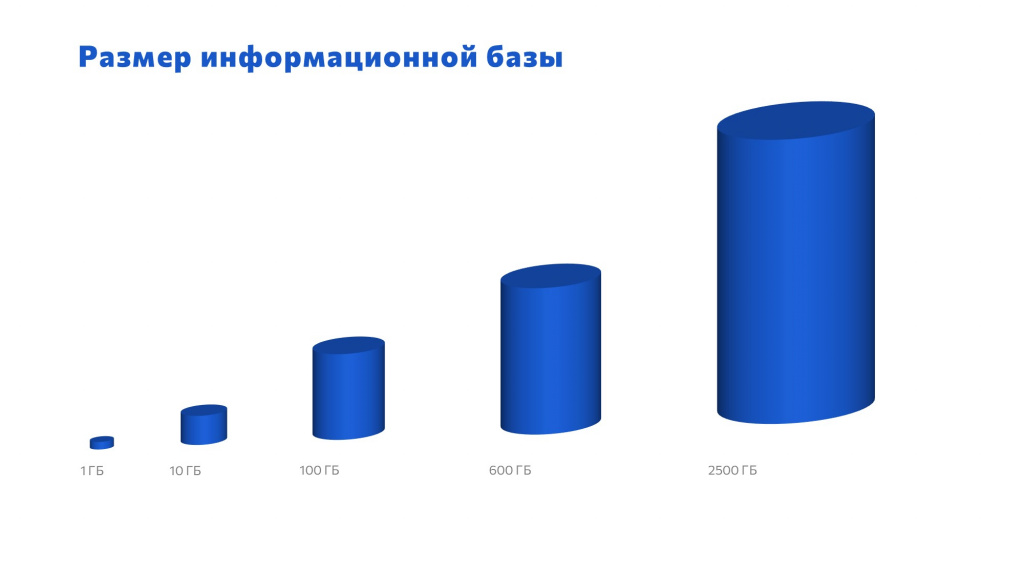
По мере моего роста как специалиста рос и размер информационной базы 1С, которую я сопровождал:
-
Когда я познакомился с 1С на своей первой работе в университете я работал с базой 1 гигабайт.
-
Через некоторое время я сменил место работы и уже работал с базой размером 10 гигабайт.
-
На следующем месте работы база 1С уже была 100 гигабайт.
-
Потом как-то так получилось, что я стал работать с базой 600 гигабайт. Мне казалось, что это очень много. Я приезжал на различные конференции, общался с коллегами, у которых базы по 50-100 гигабайт, они рассказывали о проблемах. Я им отвечал: «Какие у вас могут быть проблемы? Вот у меня база 600 гигабайт, это да». Они удивлялись: «Парень, ты там полегче с такими заявлениями» и спрашивали, как вообще с этим можно жить и работать.
-
Теперь я работаю с базой 2,5 терабайта – и это проблема для разработки и тестирования.
Способ №1 – Полная копия рабочей базы
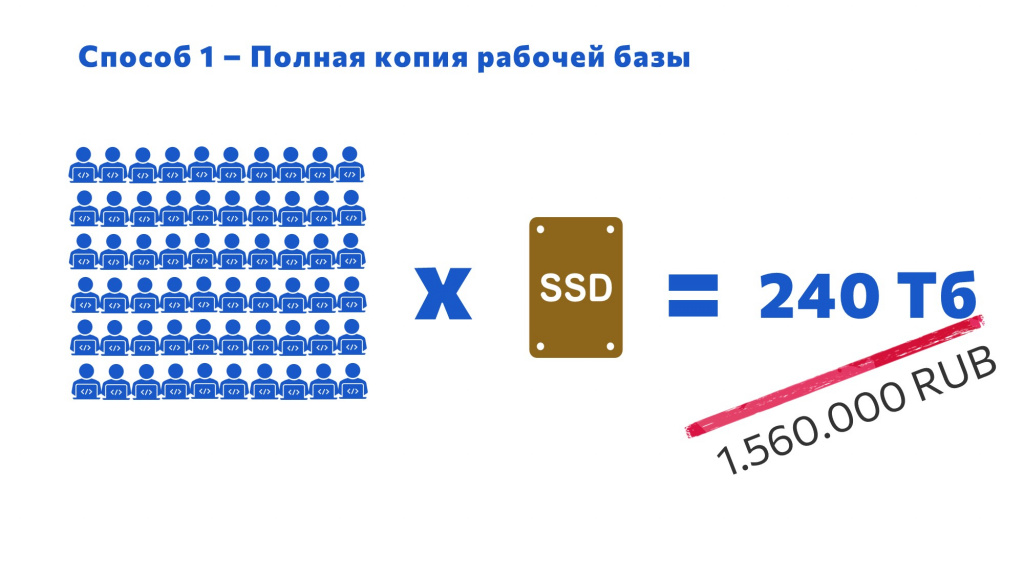
Понятно, когда у вас в штате три разработчика, развернуть каждому базу 2,5 терабайта никаких трудностей не составляет – можно пойти к руководству, выбить бюджет на новые диски, развернуть на каждому по копии и радоваться, что у вас все вмещается.
Но сейчас я работаю в организации, в которой 60 программистов. И каждый из разработчиков хочет себе полную базу данных. Это проблема.
Чтобы обеспечить их хотелки, нам понадобится каждому разработчику выделить по SSD-диску по 4 терабайта – это минимальный подходящий размер из возможных. Если мы перемножим 60 на 4 терабайта, окажется, что нам надо 240 терабайт места. Получается, что мы должны пойти к руководству и сказать: «Выделите нам бюджет более полутора миллиона рублей». Не каждый руководитель на это пойдет.
Хорошо, если руководство идет к нам на встречу и покупает каждому из 60 программистов по диску – мы все будем счастливы. Но все равно в какой-то момент место на этих 4 терабайтах закончится – базы же меняются.
Способ №2 – Удаление данных

Понятно, что решать вопрос с дисковым пространством можно не только через закупку железа, но и через удаление ненужных данных.
Поэтому мы как здравомыслящие программисты стали думать о том, какие ненужные данные можно убрать:
-
В первую очередь можно удалить данные независимых регистров сведений, которые вообще не нужны. Удаляем, вмещаемся в нужный объем, довольны, счастливы.
-
Проходит время, места снова не хватает – что-то отключаем, мутим. Хорошо, снова вмещаемся.
-
И последний вариант, который приходит в голову – это светка базы. Сворачиваем базу, живем какое-то время, а потом снова возникает вопрос.
При этом, если вы решите воспользоваться таким способом уменьшения размера тестовой базы, у вас будут минусы:
-
Первый минус – это время написания обработки. Это очень долго, потому что нужно проанализировать всю базу, узнать, что удалять. Колоссальное время.
-
Второй минус – это время на выполнение обработки. На базе 2,5 терабайта при достаточно хорошем железе обработка может крутиться сутки. Но мы можем подождать, все отлично.
-
Следующий этап – мы отдаем эту подготовленную базу программисту. Но если мы удалили данные до одного терабайта, 1 терабайт данных загрузить на обычный SSD-диск – это около четырех часов. Впору давать программистам day off, чтобы они отдохнули, пока грузится база. Мы своих программистов любим, мы им раньше давали это время.
-
По мере изменения конфигурации нам снова требуется актуализировать обработку. У нас времени хватает, мы дорабатываем.
-
Все компьютеры, как и люди, разные. На каждом компьютере могут быть разные жесткие диски. У кого-то 500 гигабайт, у кого-то 1 терабайт. И сложно вложиться в нужный размер. Но мы делаем невозможное. Мы влезаем в этот размер. Ходим счастливые, довольные.
-
И тут из-за угла вылезает мой коллега Антон и говорит: «Юра, ты удалил мне нужные данные!» Я говорю: «Антон, всем не угодишь!»
Способ №3 – Заполнение произвольными данными

Дальше мы начали думать, что еще можно сделать, и решили заполнять базу произвольными данными. Мы взяли пустую базу, заполнили все константы, справочники, провели нужные документы. Все красиво.
Посмотрим, как здесь обстоит ситуация с минусами:
-
Время на написание обработки. Написать такую обработку – самое сложное в данной задаче, потому что ее может написать только разработчик, который знает, как работает 1С:Предприятие в режиме пользователя. Знает, где какую кнопочку нажимать, и какие движения должен делать документ.
-
Время на выполнение обработки уже не так критично – обработка выполняется достаточно быстро, потому что мы можем регулировать наполнение данных под наши запросы.
-
Время на загрузку подготовленной базы – когда мы отрегулировали для базы нужный размер данных, загрузка занимает у программиста не больше часа, отлично.
-
Когда конфигурация изменяется, мы снова актуализируем обработку – проблема осталась, но она не так критична.
-
Но база – это живой организм, и когда пользователи начинают жаловаться: «Не работает отчет, формируются неправильные проводки», мы ничем помочь не можем – у нас в тестовой базе произвольные данные записаны. И программисты в растерянности, как быть с этим. Когда у нас нет реальных данных, мы не можем помочь пользователю.
Способ №4 – Махинации с базой данных

Мы начали изучать опыт коллег, что еще можно сделать с базой данных, чтобы уменьшить ее размер. А там все активные ребята предлагают делать с базой данных всякие махинации – работать с ней напрямую, в обход платформы 1С, через прямые запросы, использовать триггеры и представления. Это интересная тема, и она реализуема.
Однако, в этом способе есть минусы:
-
Самый главный минус, который нам подложила фирма «1С» – это нарушение лицензионного соглашения. Лезть в СУБД без платформы нельзя. Ужас. Может, когда-нибудь поменяют.
-
Сложно реализовать. Чтобы это реализовать, в штате нужен эксперт, который знает внутреннюю кухню базы данных – саму базу данных, какие-то специфические таблицы, как это все готовить, как это варить. И у нас классная компания – у нас есть такие специалисты.
-
Но мы снова нарушаем лицензионное соглашение. Замкнутый круг, дело – труба.
Способ №5 – ?

Мы сидели, думали – а есть ли еще способ? И оказывается, способ есть!
Правда пришли мы к такому способу совсем с другой стороны, решая совсем другую задачу.

Наш рабочий день начинался с очереди. В очереди куда? В конфигуратор.
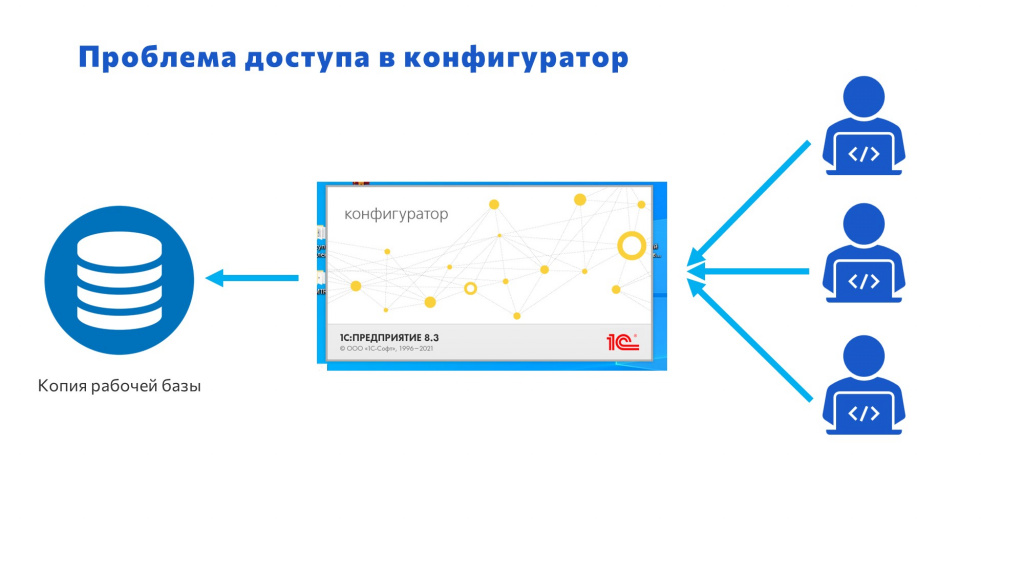
У нас была ежедневная копия рабочей базы, и все разработчики хотели попасть в конфигуратор. Но если база одна, это почти невыполнимая задача. Создатели платформы 1С интересно придумали – в конфигураторе 1С единовременно может находиться только один разработчик конфигурации. Получается очередь.
Открываешь утром чат, и начинается головная боль: «Я первый в конфигуратор», «Я второй в конфигуратор». Нужно создавать электронную очередь. Это был ужас дикий, голова кругом шла.
Но надо же решать проблему – помогать людям. У нас была одна база – придумали решение: создадим вторую базу! Место есть.
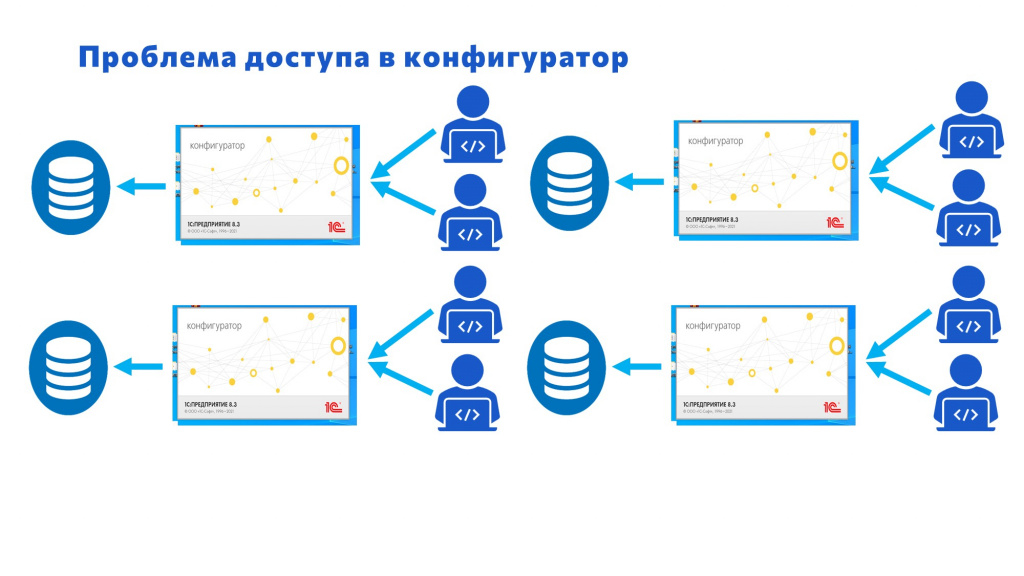
Создали вторую базу. Баттлы в чате не утихают: «Кто внес изменения? Кто выкинул у нас из конфигуратора?» Создали третью базу, четвертую. Красавцы, места хватает.
Но жить с этим очень сложно – вплоть до того что чуть ли не драки в чате начинаются.
Кто что внес и в какую конфигурацию – вообще непонятно. Никто не может работать с этим. Тихий ужас. И мы с этим жили.
Выход

Но в один прекрасный день я читаю технологический блог в интернете и нахожу такую программу SQL Clone. Читаю описание – думаю, что она решит нашу проблему.
Решил посмотреть, что еще есть – смотрю, есть Windocks и приблизительно с аналогичным принципом Database Lab.
Я такой счастливый, думаю: «Сейчас я пойду к руководству, расскажу им, что нашел, и мы решим вопрос с доступом в конфигуратор».
А потом решил посмотреть цены – сколько это стоит. Открываю вкладку «Цены» и вижу 1 терабайт с подпиской на год стоит 10 тысяч долларов. А у нас 3 терабайта – нам нужно 30 тысяч. Как это? Руководство будет не очень довольно.
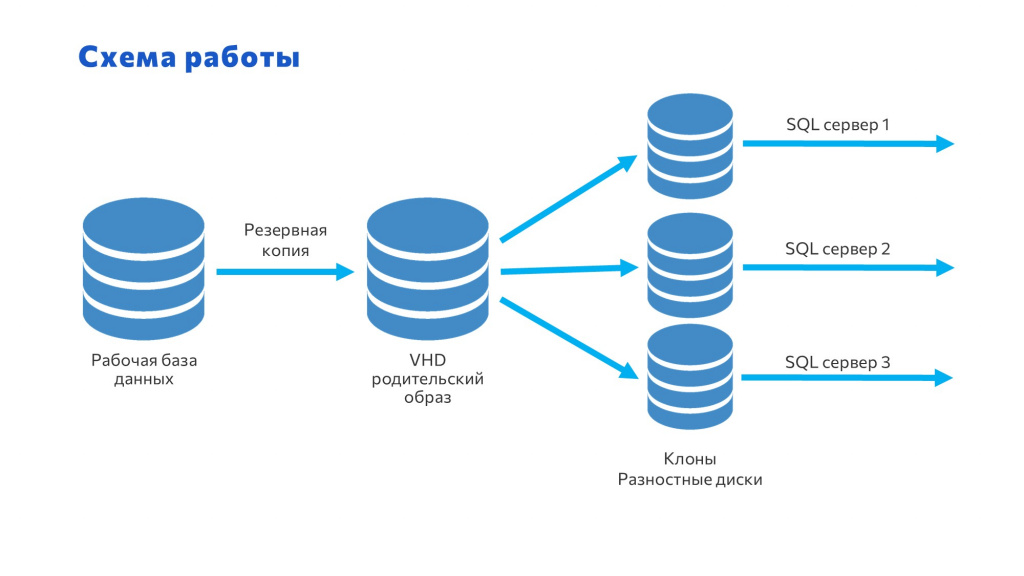
Тогда я решил изучить принцип работы, и оказалось, все не так сложно.
-
С рабочей базы снимаем резервную копию.
-
Создаем виртуальный жесткий диск и в этот жесткий диск загружаем эту копию.
-
И потом от этого диска создаем разностные копии, которые будут хранить только изменения. А файлы, которые хранятся на разностных дисках, мы подключаем к SQL и с ними работаем.

Прихожу к своему руководству и говорю: «Ребята, все, мы победили! Всем по конфигуратору, по базе!»
Собрали совещание, стали обсуждать, но у коллег возникли сомнения – как будет строиться очередь к этому файлу, какие для этого нужны диски?
Я предложил рассчитать, как будет строиться очередь в зависимости от различных параметров дисков. Например, мы можем взять старые HDD или новые SSD:
-
HDD – это такой семейный седан. В него сел, катишься довольный. Он вроде надежный, но медленный.
-
А SSD – это болид «Формулы-1», в котором скорость не лимитирована, он может ехать очень быстро, если позволяет дорога.
Они говорят: «Конечно, у нас будут SSD-диски, мы же современные».
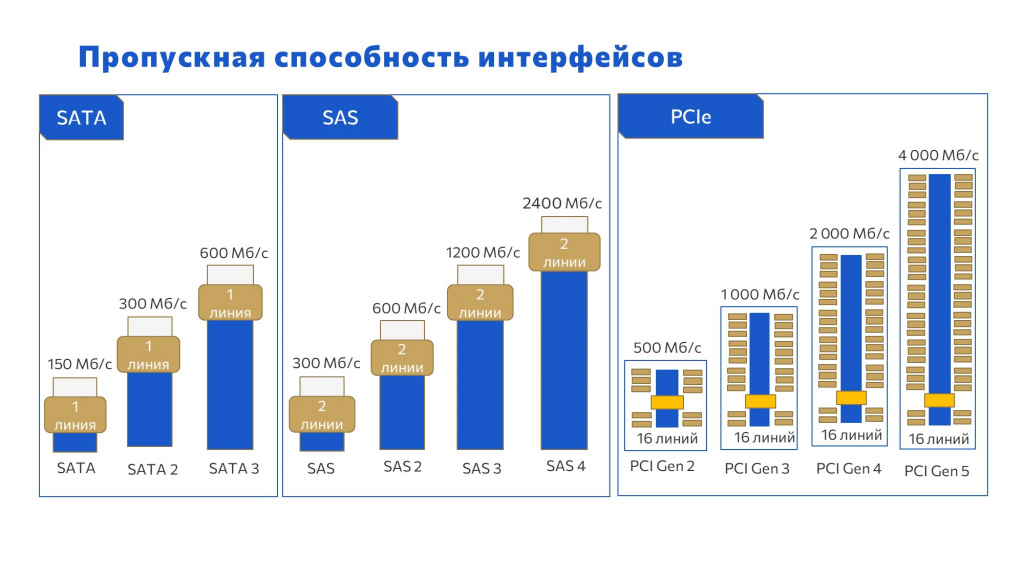
Возник следующий вопрос: «А что будет со скоростью?» Я предложил сравнить интерфейсы.
Если взять обычный пользовательский ПК, где стоит SATA:
-
SATA первый – 150 мегабайт в секунду;
-
SATA 2 – 300 мегабайт в секунду;
-
и SATA 3 – 600 мегабайт в секунду.
Но у нас в основном компьютеры Enterprise-сегмента, где главенствует SAS:
-
SAS первый – это 300 мегабайт в секунду,
-
SAS 2 – 600 мегабайт в секунду,
-
а современные модели SAS 3 и SAS 4 – 1200 и 2400 мегабайт в секунду.
Следующее поколение интерфейсов – PCI Express. Это M.2, U.2, U.3 и все остальные:
-
PCI Gen 2 – 500 мегабайт в секунду;
-
PCI Gen 3 – 1000 мегабайт в секунду;
-
PCI Gen 4 – 2000 мегабайт в секунду;
-
и последний PCI Express – 4000 мегабайт в секунду.
Если мы перемножим 16 линий на 4 гигабайта в секунду, то скорость чтения или записи на диск получится 64 ГБ в секунду. Это очень много.
А у нас оборудование где-то в районе SAS 3, PCI 3-4 – в общем-то, и неплохо.
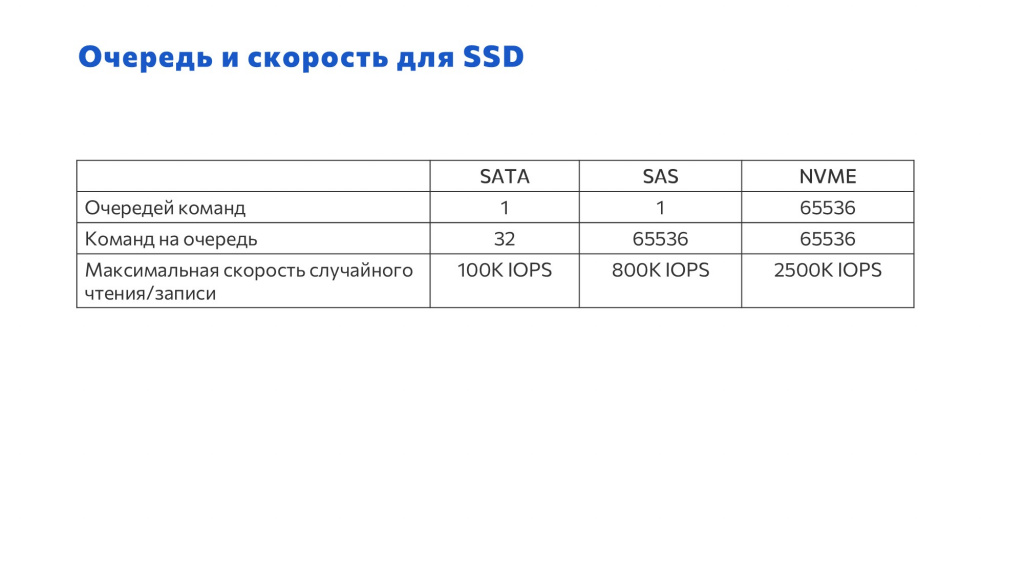
Теперь посмотрим, что будет с очередью – как ее обслуживает тот или иной интерфейс:
-
Например, если ты приходишь в магазин, а там сидит один кассир – SATA, он за сутки обслуживает 32 покупателя и доволен. Не очень надежный и небыстрый магазин.
-
SAS. Тоже одна очередь, но за сутки можно обслужить гораздо больше покупателей.
-
NVME. Это когда в магазине 65 тысяч касс, и каждая может обслужить 65 тысяч покупателей в сутки. Только у нас это все происходит за одну секунду.
Коллеги говорят: «Окей, сдаемся – давайте пробовать».

Для реализации очереди мне понадобились:
-
интерес;
-
желание;
-
время – времени мне выделили неделю;
-
PowerShell – я реализовал на нем скрипт;
-
для администрирования сервера 1С скрипт использовал утилиту Rac/Ras;
-
для СУБД – командлет Invoke-Sqlcmd.
-
для дисков – вначале был DiskPart, но потом я перешел на командлет от Hyper-V, потому что он более универсальный.

Этот слайд – вообще некрасивый. Я не хотел его показывать. Но это все команды, которые нужны для алгоритма по созданию родительского диска. Быстро пробежимся по ним.
-
Первая команда – New-VHD. С ее помощью мы создаем родительский диск.
-
Mount-VHD – подключаем его к системе;
-
Initialize-Disk– инициализируем,
-
New-Partition – создаем разметку,
-
Format-Volume – форматируем,
-
Get-VHD – получаем его номер,
-
Add-PartitionAccessPath – добавляем на диск операционную систему,
-
Restore Database – загружаем туда базу данных с помощью SQL-сервера;
-
Set Recovery Simple – переводим базу данных в режим Simple;
-
Set Auto_Shrink Off; DBCC Shrink File; Alter DataBase – шринканули;
-
EXEC sp_detach_db – отключились от SQL-сервера;
-
Remove_PartitionAccessPath; Remove-Item; Dismount-VHD – и отключаемся от операционной системы.
Отлично – быстро создали родительский диск.

А как создать разностный диск? Всего-то нам нужно:
-
New-VHD – создать разностный диск,
-
Mount-VHD – подключить его,
-
Add-PartitionAccessPath – добавить операционную систему,
-
EXEC sp_attach_db – подключить базу данных.
Вообще простота.
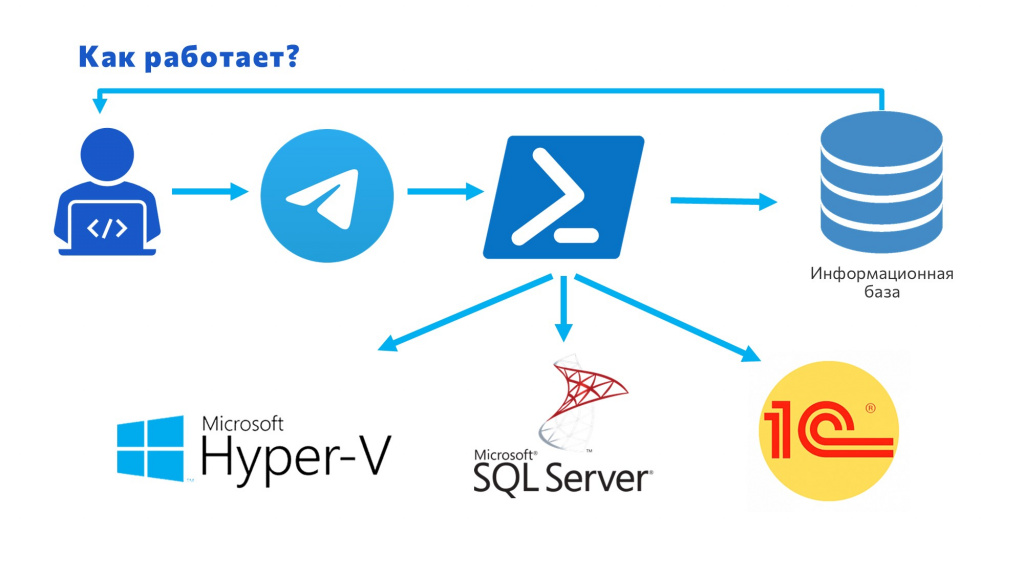
Сначала все это работало в ручном режиме – мне писали программисты, я запускал эти команды, и создавалась база. Все отлично работало – замечаний не было.
Потом мне надоело, что я вручную все делаю, и я автоматизировал процесс через Telegram. Теперь:
-
Программист отправляет в чат-бот Telegram команду определенного формата,
-
Telegram-бот запускает PowerShell с алгоритмом для SQL-сервера, который мы рассмотрели.
-
Дополнительно с помощью Rac/Ras подключает созданную базу в 1С и возвращает пользователю базу с подключением.
И это все работает, это классно.

Но самый смак в том, что создание базы теперь занимает 30 секунд. Это очень быстро.
Вы представляете, чтобы развернуть базу для проверки закрытия месяца, нужно 30 секунд. Выполнили и откатились.
В стандартном случае, чтобы загрузилась база 2,5 терабайта при хороших дисках нужно 30 минут. Помните, мы обсуждали, что у программистов на обычном SSD-диске, чтобы загрузить базу в 1 терабайт уходило 4 часа? Здесь – 30 секунд. Это вообще космос! Это сколько мы экономим времени разработчиков на тестирование!
И это все занимает 45 мегабайт. Представьте, у нас есть диск на 1 терабайт, сколько мы туда можем таких баз поместить? Да тысячи мы можем этих баз записать! И обеспечить тысячу человек полной копией. Это очень классно.
Понятно, что со временем количество изменений увеличивается, и разностные файлы растут. Но не так критично они растут.
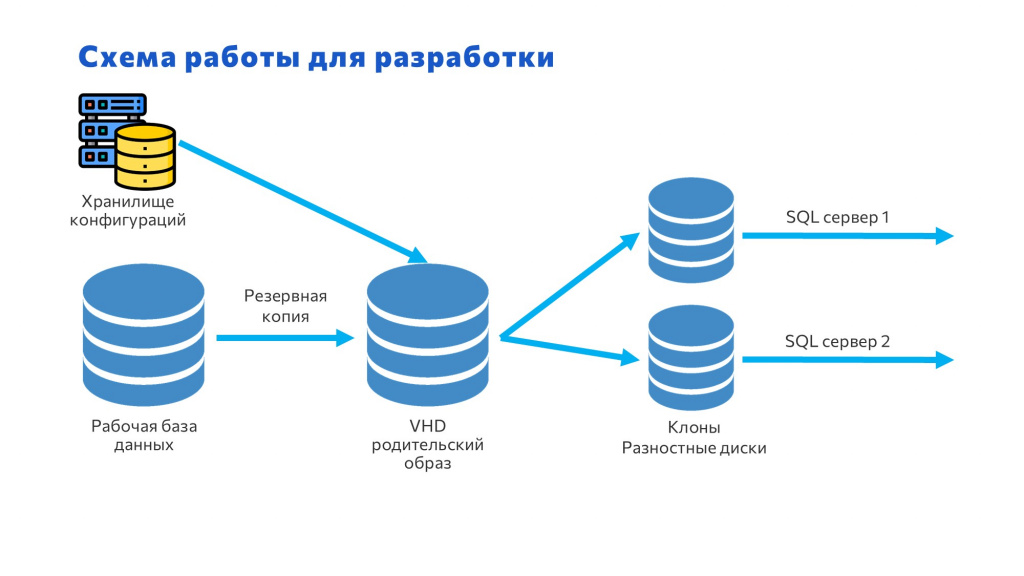
Это у нас работало полгода. Мы обкатывали механизм, и пришла в голову идея: «Слушайте, мы же вначале использовали урезанную базу. А давайте попробуем применить этот подход для баз разработки?» Я говорю: «Давайте попробуем»:
-
Мы снова сделали копию с рабочей базы.
-
Загрузили в родительский диск.
-
И еще дополнительно туда забрали изменения из хранилища, чтобы в этом родительском диске хранились изменения – это нужно, чтобы в разностных дисках не хранилась дублирующая информация.
-
И уже эти файлы из разностных дисков подключили к SQL, и программисты с этим работают.

На выходе мы получили следующую картину:
-
У нас теперь есть три полные базы:
-
Одна база – клон, который был родоначальником нашего подхода.
-
Вторая база – это база для разработки.
-
И третья база – для код-ревью и тестирования. Программисты тестируют и проверяют там свой код, и потом это уходит на релиз.
-
-
У нас остались все те же 60 разработчиков.
-
При этом все это занимает 5 дисков:
-
один из них на 12 терабайт;
-
и 4 обычных «седана» по 8 терабайт для хранения дифференциальных баз.
-
Все это нам все обошлось менее 400 тысяч рублей. Неплохо. Мне кажется, отлично. И руководство довольно.
Альтернативы на Linux

Когда я рассказываю ребятам про этот подход, они говорят: «Юра, ну ты же работаешь с MS SQL, у тебя Windows. А что нам делать? Мы на Linux, у нас PostgreSQL».
Я отвечаю: «Ребят, никакой разницы нет – подход работает и там, и там. Отличие только в том, что команды другие. Там не будет PowerShell, но там будет что-нибудь другое – хотя PowerShell есть и на Linux».

Тем более, Linux разрабатывает сообщество, и у него есть свои внутренние механизмы, которые могут делать то же самое.
Например, в Linux, в отличие от Windows, есть файловая система ZFS, которая приблизительно может делать такую же функциональность – там есть возможность клонировать образы, и она тоже хранит изменения. Правда, у ZFS есть проблемы с лицензией, но у нее есть аналог – BTRFS система, и там проблем с лицензией нет. Правда, в тонкостях, как это все работает из-под капота, я не разбирался, но оно должно работать.
Но если бы у меня был Linux, и нужно было бы выбирать – использовать файловую систему из ZFS/BTRFS или подход с виртуальными дисками – я бы выбрал виртуальные диски, потому что:
-
Подход универсальный – он применим и на Linux, и на Windows;
-
Я не уверен в надежности этих файловых систем – не знаю, как они работают с диском, как быстро на них диски выходят из строя. А мне нужна надежность в том, с чем я работаю.
Так вроде неочевидный подход позволил нам решить две задачи:
-
задачу с доступом в конфигуратор;
-
и задачу с доступом для баз разработчиков.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2022 Saint Petersburg.


Вступайте в нашу телеграмм-группу Инфостарт