Переиндексация в несколько потоков.
Не раз слышал мнения 1сников, что переиндексации вообще не нужна. Так как мы живем сейчас в век ssd и nvme. И неважно, какая у вас фрагментация индекса, нужно просто делать обновление статистики и все. И как подтверждение кидают абзац от Microsoft

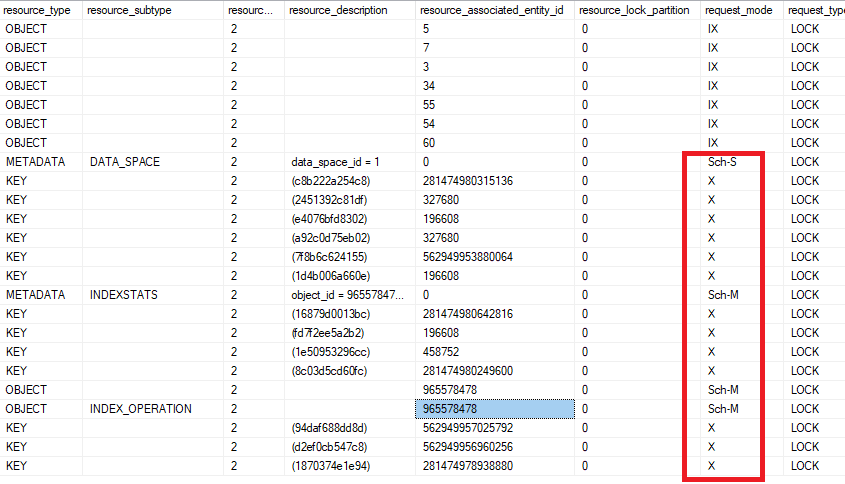
Но почему – то не читают начало этой статьи, в которой сказано, как влияет фрагментация и плотность страниц на общую производительность. И расход ресурсов

И то, что даже на ssd и NMVE последовательная скорость чтения запись всегда выше, чем случайная
И про плотность, (если у вас, конечно, на сервере на 2ТБ памяти на базу 2ТБ)


Подытожим. Обновление статистики и правда даст вам сиюминутный эффект. Но со временем фрагментация сделает свое, и вам не хватает уже мощностей железа, чтобы перекрыть тормоза.
Так что мое мнение - переиндексация нужна! Но не нужно каждый день перестраивать все индексы) Благо всевозможных скриптов хватает в сети.
Идея появилась из-за проблемы, что база в 20 ТБ не могла за выделенное техокно пройти «полную» переиндексацию. И через неделю-две начинались дикие тормоза, и обновление статистики не давало явного ускорения. Пробовал чужие скрипты с паузой и прочие. Но во всех скриптах перестройка индексов идет в один поток (я говорю не про maxdop). Что пока один индекс не перестроится, другие не начнут. Так что вот представляю мой костыль)
Скрипт представляю в немного урезанном виде и на 2 потока.
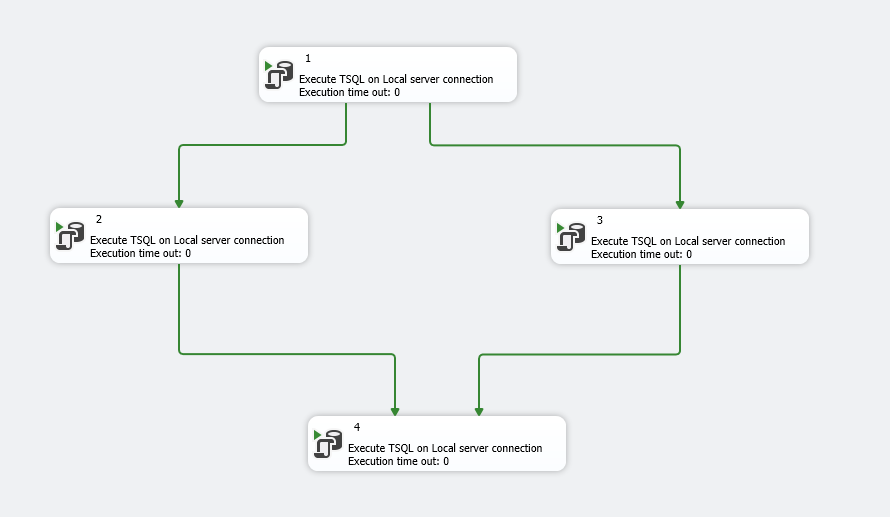
Шаги в скрипте.
- Собрать статистику по всем индексам в базе их фрагментации и размеру. Занести данные в служебную базу.
- Выполнить задание перестройки по первой половине данных
- Выполнить задание перестройки по второй половине данных
- Обновить статистику, по всей базе.
Зачем, вы спросите, обновлять статистику по всей базе, если переиндексация обновляет статистику? А я отвечу. Мы перестраиваем не все таблицы, часть с малой фрагментацией мы пропускаем. А таблицы с только что перестроенными индексами (при условии, что не было еще ни одной вставки) будут пропущены, с сообщение, что нечего там обновлять. Это проще чем делать еще один шаг с условием. Что если переиндексация по таблице не проходила, то обнови статистику.
Можно все сделать разными jobs с привязкой старта разным логом и прочим. Но так как это lite версия скрипта, пример будет создан на maintenance Plan.
Так как я встречал моветон имена БД через – а не _ , что заставляет городить конструкции с выделением имени БД в несколько кавычек (так как – в скриптах это может быть как действием, так и символом).
Поэтому в скрипте есть 2 разные «переменные» DATA-BASE(Имя базы) и DATA_BASE(Служебная переменная). Во всех файлах необходимо заменить DATA-BASE имя вашей БД (к примеру SP-UPP), DATA_BASE заменить (SPUPP или SP_UPP)
Скрипт на первом шаге, создает служебную базу profiler (если ее нет). Собираем статистику по индексам и заполняем базу profiler. Сбор статистики - достаточно долгий процесс, который не сильно влияет на скорость. То есть 1 шаг лучше запускать заранее. К примеру, техокно у вас с 21:00 часа, первый шаг у вас выполняется за 40 мин. и не мешает пользователям, то статистику можно начать собирать в 20:20.
-
SET QUOTED_IDENTIFIER ON; if DB_ID('profiler') IS NULL BEGIN PRINT 'Creating Profiler database' CREATE DATABASE Profiler END declare @astor_name VARCHAR(255) declare @astor_id INT SELECT TOP 1 @astor_name = QUOTENAME(name), @astor_id=database_id FROM sys.databases where name like 'DATA-BASE' DECLARE @rebuildOptions nvarchar(MAX) = N' WITH (maxdop = 10, ONLINE = ON, SORT_IN_TEMPDB = ON)' DECLARE @partitionnum bigint; DECLARE @partitions bigint; DECLARE @objectid int; DECLARE @indexid int; DECLARE @partitioncount bigint; PRINT 'Woring with ' + @astor_name DECLARE @indexTable VARCHAR(255) SET @indexTable= @astor_name + '.sys.indexes' if OBJECT_ID('temporary_indexes_DATA_BASE') IS NOT NULL DROP VIEW temporary_indexes_DATA_BASE; EXEC('CREATE VIEW temporary_indexes_DATA_BASE AS SELECT idx.object_id as object_id, idx.index_id as index_id, sch.name as schema_name, obj.name as table_name, idx.name as index_name, idx.type_desc as type_desc FROM ' + @astor_name + '.sys.indexes as idx JOIN ' + @astor_name + '.sys.objects as obj ON obj.object_id = idx.object_id JOIN ' + @astor_name + '.sys.schemas as sch ON sch.schema_id = obj.schema_id') DECLARE @FramentationReportTable VARCHAR(255) SET @FramentationReportTable = 'Fragmentation_DATA_BASE_'+REPLACE(convert(varchar, getdate(), 102), '.', '_') IF OBJECT_ID('tempdb..##fragmentation_DATA_BASE') IS NOT NULL DROP TABLE ##fragmentation_DATA_BASE DECLARE @reportNum INT SET @reportNum = 1 WHILE OBJECT_ID('[Profiler].dbo.' + @FramentationReportTable+'_' + CAST(@reportNum AS nvarchar(255))) IS NOT NULL SELECT @reportNum = @reportNum + 1; SELECT @FramentationReportTable = @FramentationReportTable + '_' + CAST(@reportNum AS nvarchar(255)) DROP SEQUENCE IF EXISTS Sequence; CREATE SEQUENCE Sequence START WITH 1 INCREMENT BY 1 MINVALUE 1 MAXVALUE 2 CYCLE RAISERROR( N'Analyzing indexes',0,1) WITH NOWAIT SELECT DB_NAME(stats.database_id) as db_name, idx.schema_name as schema_name, idx.table_name AS table_name, idx.index_name AS index_name, idx.type_desc as index_type, stats.partition_number AS partition_num, stats.avg_fragmentation_in_percent AS fragmentation, stats.avg_page_space_used_in_percent as page_fullness, stats.avg_record_size_in_bytes as record_size, stats.record_count as rows_count, stats.page_count as page_count --- ,next value for Sequence over (order by [record_count] desc) as num INTO ##fragmentation_DATA_BASE FROM sys.dm_db_index_physical_stats (@astor_id, NULL, NULL , NULL, 'SAMPLED') as stats JOIN temporary_indexes_DATA_BASE idx ON idx.object_id = stats.object_id and idx.index_id = stats.index_id DROP VIEW temporary_indexes_DATA_BASE EXEC ('SELECT [db_name] ,[schema_name] ,[table_name] ,[index_name] ,[index_type] ,[partition_num] ,[fragmentation] ,[page_fullness] ,[record_size] ,[rows_count] ,[page_count] ,next value for Sequence over (order by ROUND ([fragmentation],0 ) desc, [rows_count] desc) as num INTO profiler.dbo.'+ @FramentationReportTable +' FROM ##fragmentation_DATA_BASE')
2 и 3 шаги почти идентичные кроме условия условий выбора и названия курсора.
-
DECLARE @FramentationReportTable_1 VARCHAR(255) SET @FramentationReportTable_1 = (SELECT top 1 table_name FROM Profiler.INFORMATION_SCHEMA.TABLES WHERE table_Name LIKE 'Fragmentation_DATA_BASE_'+REPLACE(convert(varchar, getdate(), 102), '.', '_') + '%') print @FramentationReportTable_1 exec (' DECLARE bad_indexes_1 CURSOR FOR select frag.db_name, frag.schema_name, frag.table_name, frag.index_name, frag.partition_num, case when frag.record_size*16 <= 403 then 95 when frag.record_size*16 <= 806 then 90 when frag.record_size*16 <= 1209 then 85 else 80 end as suggested_fillfactor from Profiler.dbo.'+ @FramentationReportTable_1 +' frag where frag.page_count > 24 and frag.fragmentation >= 5 and frag.num = 1 and frag.index_type <>''HEAP'' order by ROUND ([fragmentation],0 ) desc, [rows_count] desc') -- Open the cursor. OPEN bad_indexes_1 DECLARE @db_name nvarchar(130); DECLARE @schema_name nvarchar(130); DECLARE @table_name nvarchar(130); DECLARE @index_name nvarchar(130); DECLARE @fragmentation bigint; DECLARE @suggested_fillfactor int; DECLARE @partition_num bigint; DECLARE @partitionOption nvarchar(130); DECLARE @fillfactorOption nvarchar(130); DECLARE @object_name nvarchar(1000); DECLARE @command nvarchar(1000); DECLARE @time nvarchar(130) WHILE (1=1) BEGIN FETCH NEXT FROM bad_indexes_1 INTO @db_name, @schema_name, @table_name, @index_name, @partition_num, @suggested_fillfactor; IF @@FETCH_STATUS < 0 BREAK IF @partition_num > 1 begin SET @partitionOption = N' PARTITION=' + CAST(@partition_num AS nvarchar(10)); set @fillfactorOption = N'' end else begin SET @partitionOption = N'' set @fillfactorOption = N' FILLFACTOR=' + CAST(@suggested_fillfactor as nvarchar(10)) + N', ' end SET @object_name = QUOTENAME(@db_name) + N'.' + QUOTENAME(@schema_name) + N'.' + QUOTENAME(@table_name) BEGIN TRY SET @command = N'ALTER INDEX ' + QUOTENAME(@index_name) + N' ON ' + @object_name + ' REBUILD ' + @partitionOption +' WITH(' + @fillfactorOption + N'maxdop = 0, ONLINE = ON, SORT_IN_TEMPDB = ON, MAX_DURATION = 10 minutes, ABORT_AFTER_WAIT = BLOCKERS)' set @time = CURRENT_TIMESTAMP; print @time RAISERROR(@command, 0, 1) EXEC(@command) set @time = CURRENT_TIMESTAMP; RAISERROR(N'DONE', 0, 1) END TRY BEGIN CATCH SET @command = N'ALTER INDEX ' + QUOTENAME(@index_name) + N' ON ' + @object_name + ' REBUILD ' + @partitionOption +' WITH(' + @fillfactorOption + N'maxdop = 0, SORT_IN_TEMPDB = ON)' set @time = CURRENT_TIMESTAMP; print @time RAISERROR(@command, 0, 1) EXEC(@command) set @time = CURRENT_TIMESTAMP; RAISERROR(N'DONE', 0, 1) print @time END CATCH END close bad_indexes_1 deallocate bad_indexes_1 -
DECLARE @FramentationReportTable_2 VARCHAR(255) SET @FramentationReportTable_2 = (SELECT top 1 table_name FROM Profiler.INFORMATION_SCHEMA.TABLES WHERE table_Name LIKE 'Fragmentation_DATA_BASE_'+REPLACE(convert(varchar, getdate(), 102), '.', '_') + '%') print @FramentationReportTable_2 exec (' DECLARE bad_indexes_2 CURSOR FOR select frag.db_name, frag.schema_name, frag.table_name, frag.index_name, frag.partition_num, case when frag.record_size*16 <= 403 then 95 when frag.record_size*16 <= 806 then 90 when frag.record_size*16 <= 1209 then 85 else 80 end as suggested_fillfactor from Profiler.dbo.'+ @FramentationReportTable_2 +' frag where frag.page_count > 24 and frag.fragmentation >= 5 and frag.num = 2 and frag.index_type <>''HEAP'' order by ROUND ([fragmentation],0 ) desc, [rows_count] desc') -- Open the cursor. OPEN bad_indexes_2 DECLARE @db_name nvarchar(130); DECLARE @schema_name nvarchar(130); DECLARE @table_name nvarchar(130); DECLARE @index_name nvarchar(130); DECLARE @fragmentation bigint; DECLARE @suggested_fillfactor int; DECLARE @partition_num bigint; DECLARE @partitionOption nvarchar(130); DECLARE @fillfactorOption nvarchar(130); DECLARE @object_name nvarchar(1000); DECLARE @command nvarchar(1000); DECLARE @time nvarchar(130) WHILE (1=1) BEGIN FETCH NEXT FROM bad_indexes_2 INTO @db_name, @schema_name, @table_name, @index_name, @partition_num, @suggested_fillfactor; IF @@FETCH_STATUS < 0 BREAK IF @partition_num > 1 begin SET @partitionOption = N' PARTITION=' + CAST(@partition_num AS nvarchar(10)); set @fillfactorOption = N'' end else begin SET @partitionOption = N'' set @fillfactorOption = N' FILLFACTOR=' + CAST(@suggested_fillfactor as nvarchar(10)) + N', ' end SET @object_name = QUOTENAME(@db_name) + N'.' + QUOTENAME(@schema_name) + N'.' + QUOTENAME(@table_name) BEGIN TRY SET @command = N'ALTER INDEX ' + QUOTENAME(@index_name) + N' ON ' + @object_name + ' REBUILD ' + @partitionOption +' WITH(' + @fillfactorOption + N'maxdop = 0, ONLINE = ON, SORT_IN_TEMPDB = ON, MAX_DURATION = 10 minutes, ABORT_AFTER_WAIT = BLOCKERS)' set @time = CURRENT_TIMESTAMP; print @time RAISERROR(@command, 0, 1) EXEC(@command) set @time = CURRENT_TIMESTAMP; RAISERROR(N'DONE', 0, 1) END TRY BEGIN CATCH SET @command = N'ALTER INDEX ' + QUOTENAME(@index_name) + N' ON ' + @object_name + ' REBUILD ' + @partitionOption +' WITH(' + @fillfactorOption + N'maxdop = 0, SORT_IN_TEMPDB = ON)' set @time = CURRENT_TIMESTAMP; print @time RAISERROR(@command, 0, 1) EXEC(@command) set @time = CURRENT_TIMESTAMP; RAISERROR(N'DONE', 0, 1) print @time END CATCH END close bad_indexes_2 deallocate bad_indexes_2
В скриптах 2 и 3 есть пара моментов, которые я хочу прояснить.
- есть проверка на партиции, и в зависимости от этого будет меняться запрос.
- есть изменение fillfactor в зависимости от record_size
- идет 2 условия. Пробует перестроить индекс online и с ожиданием, если не удается, то перестраивает индекс просто.
- RAISERROR со временем было сделано для того, чтобы узнать время начала переиндексации по таблице и конца (Здесь осталось как отладочная команда). Эту инфу можно передать в другую базу для истории или диагностики.
4. Обновление статистики.
USE [DATA-BASE]
GO
EXEC sp_updatestats;
Если вдруг вы хотите добавить потоков, то необходимо будет в скрипте 1. Изменить параметр в SEQUENCE
Установить MAXVALUE на значение желаемых потоков и создать шаг наподобие 2 или 3.
Но тут нужно хорошо думать. Так как переиндексация достаточно сильно нагружаемый процесс. И можно поставить сервер колом, если делать несколько alter index сразу.
После пары запусков с разными настройками удалось добиться 30-40% выигрыша по времени. И задание успевает выполниться за техокно.
Вступайте в нашу телеграмм-группу Инфостарт