Меня зовут Ринат Юлчурин. Работаю в компании «DNS технологии» – это ИТ-компания сети магазинов электроники и бытовой техники DNS.
Я расскажу о том, как мы перешли на использование оптимизированного механизма реструктуризации, с какими мы столкнулись проблемами и как их решали.
Думаю, многим интересно, почему база такая большая. База управленческая, основной объем занимают регистры бухгалтерии.
Мы используем регистры бухгалтерии, потому что на них удобно строить управленческие отчеты, понятные финансистам.
Причем регистров бухгалтерии несколько, потому что с одним регистром бухгалтерии у нас в основном работают, и есть новый регистр бухгалтерии, на который возлагают большие надежды.
Краткое описание принципа ускорения реструктуризации для больших таблиц
Для начала я кратко расскажу про обычный механизм реструктуризации и его отличия от оптимизированного механизма.

Допустим, у нас есть документ с табличной частью, в обеих таблицах документа миллионы строк, и мы добавляем в шапку документа реквизит типа «Строка»:
-
Сначала создается пустая копия таблицы шапки NG с уже добавленным полем.
-
Затем создается пустая копия таблицы табличной части VTNG.
-
Далее в созданные копии выполняется перенос данных – именно этот момент при обычной реструктуризации больших таблиц с миллионами строк занимает основное время.
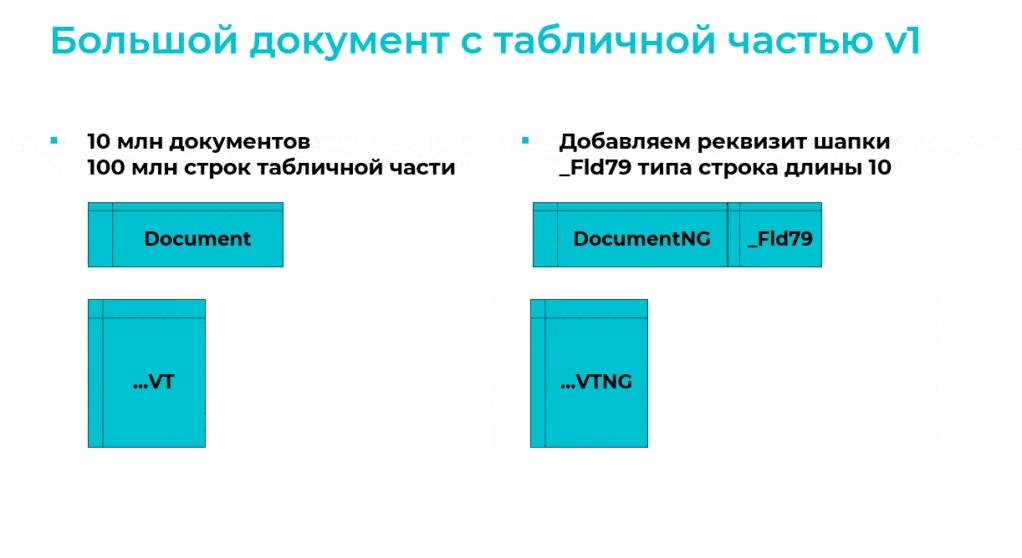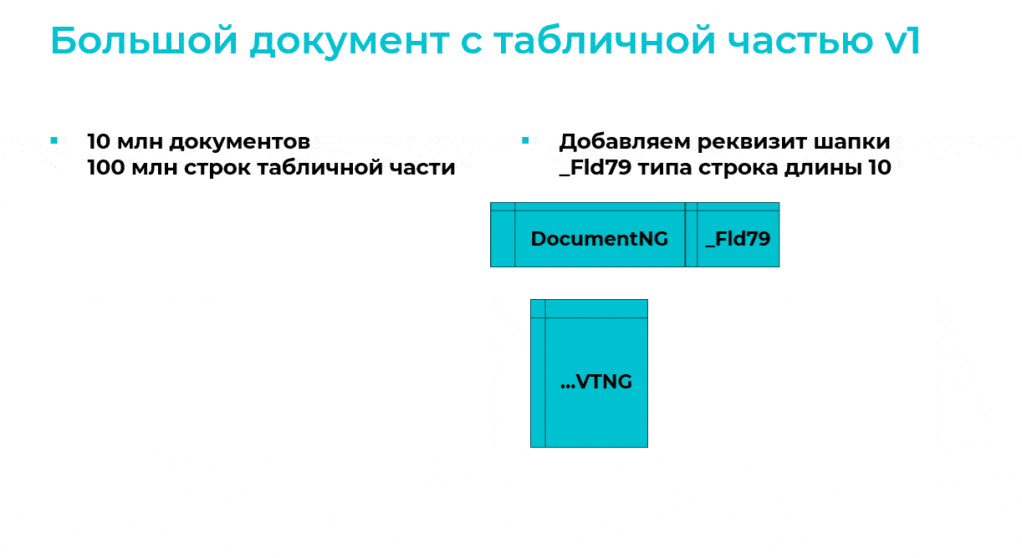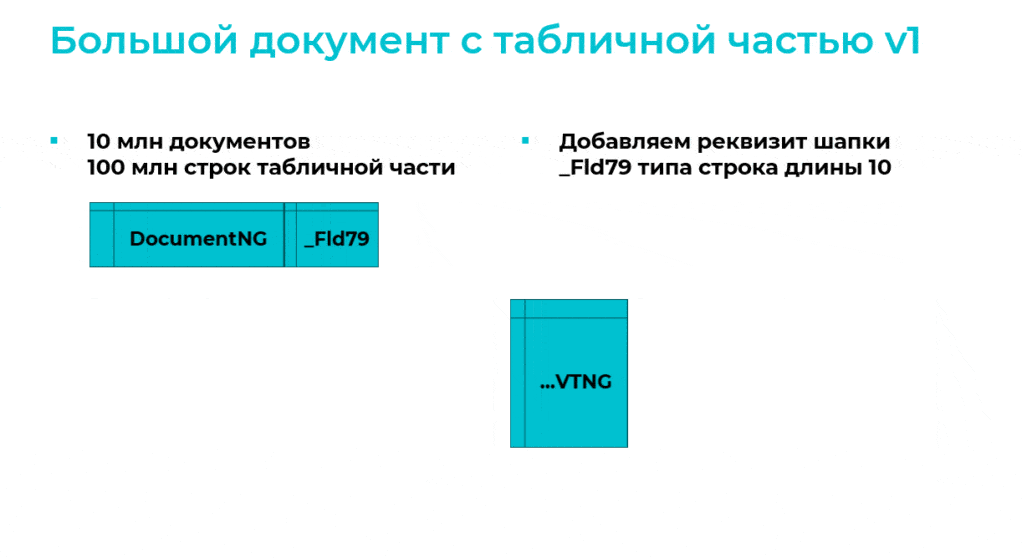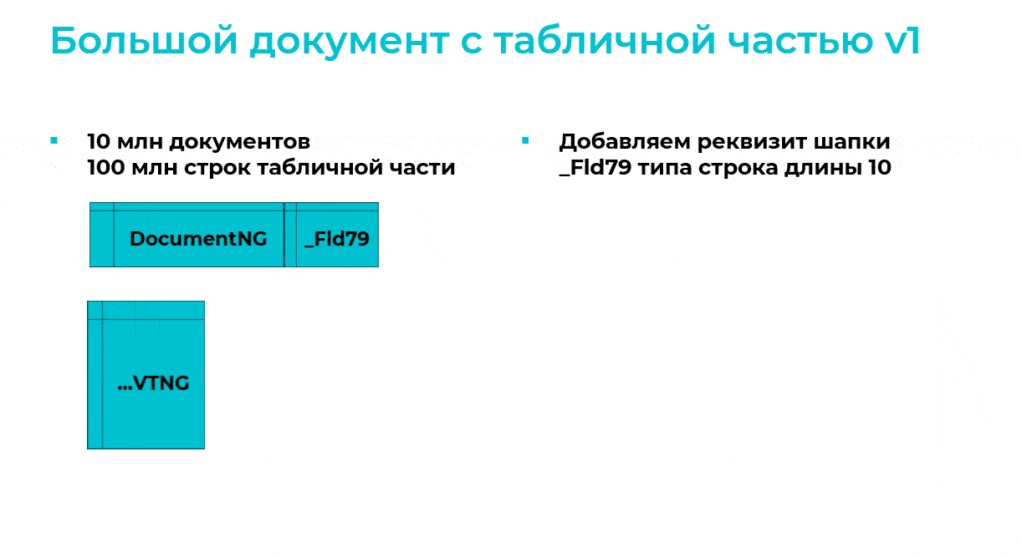
После переноса данных с новые таблицы старые удаляются, новые переименовываются – теперь в шапке документа есть новое поле, и с таблицами можно работать. Так работает обычная реструктуризация.
Теперь рассмотрим оптимизированный механизм реструктуризации.
Тот же пример документа с табличной частью и миллионами строк в таблицах. Так же добавляем реквизит в шапку документа.
-
Первое проявление оптимальности заключается в том, что изменяется только таблица шапки документа, а сколько бы у него ни было таблиц табличных частей, они не будут затронуты.
-
Второе проявление оптимальности – это то, что добавление поля выполняется через команду ALTER TABLE … ADD … которая очень быстро добавляет колонку на уровне метаданных, не трогая миллионы строк.
-
Казалось бы, для миллионов строк новое добавленное поле надо заполнить пустым значением, но здесь используется хитрый ключ DEFAULT, который определяет значение по умолчанию – в данном случае «пустая строка».
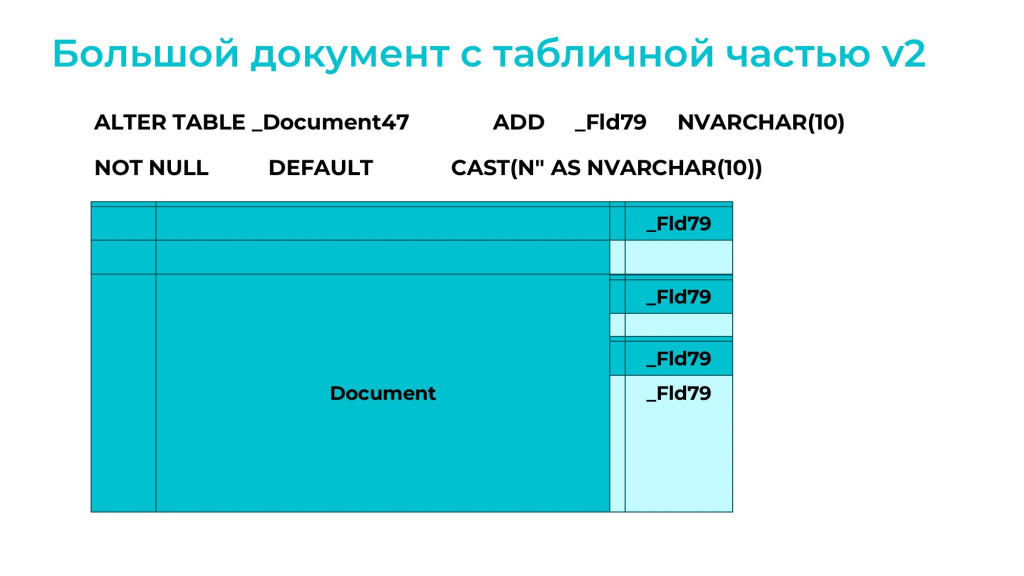
Причем в этом виде с таблицей уже можно работать.
-
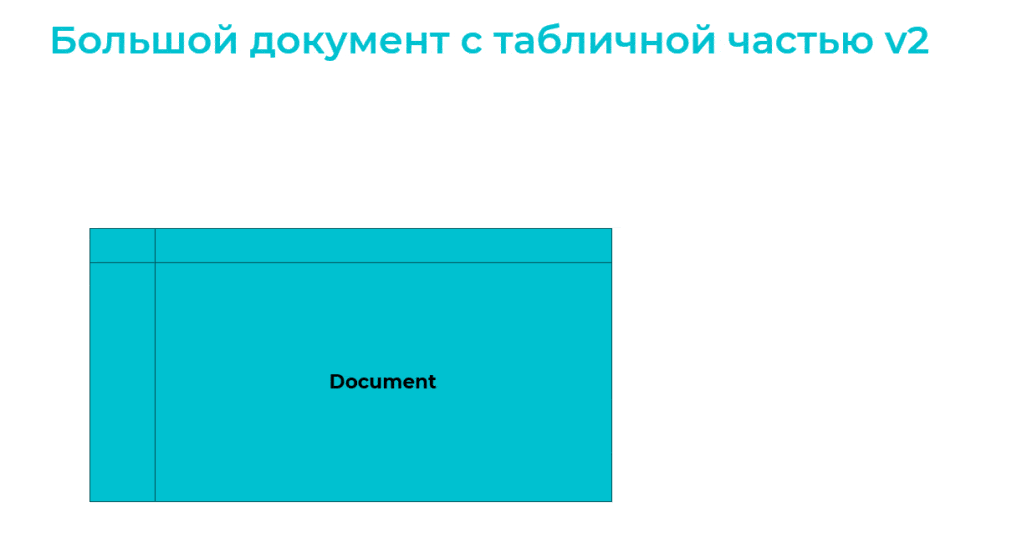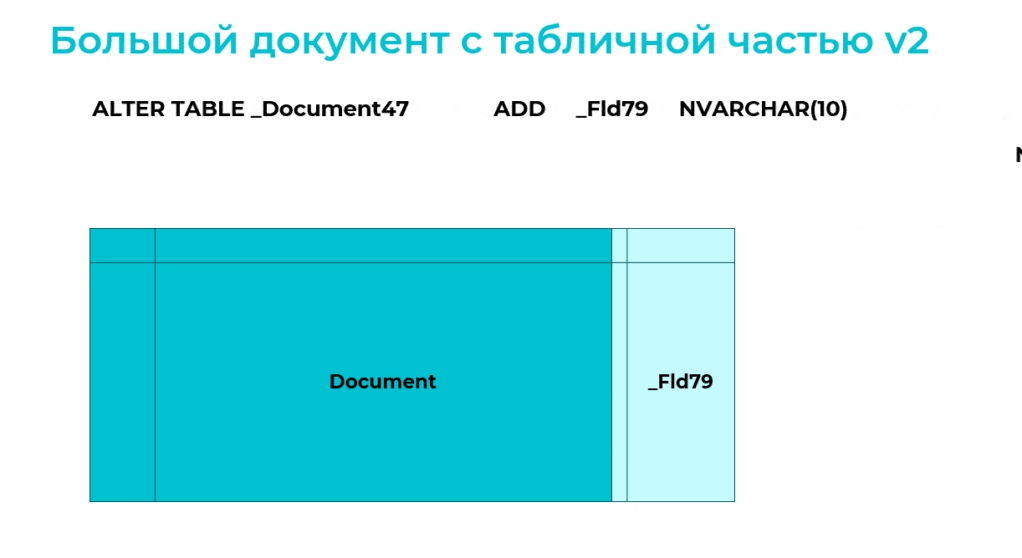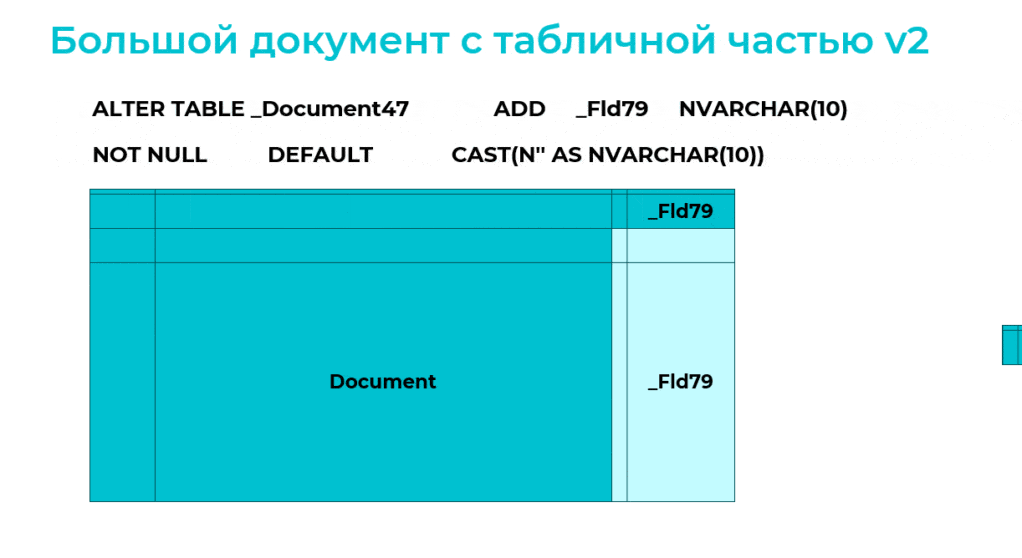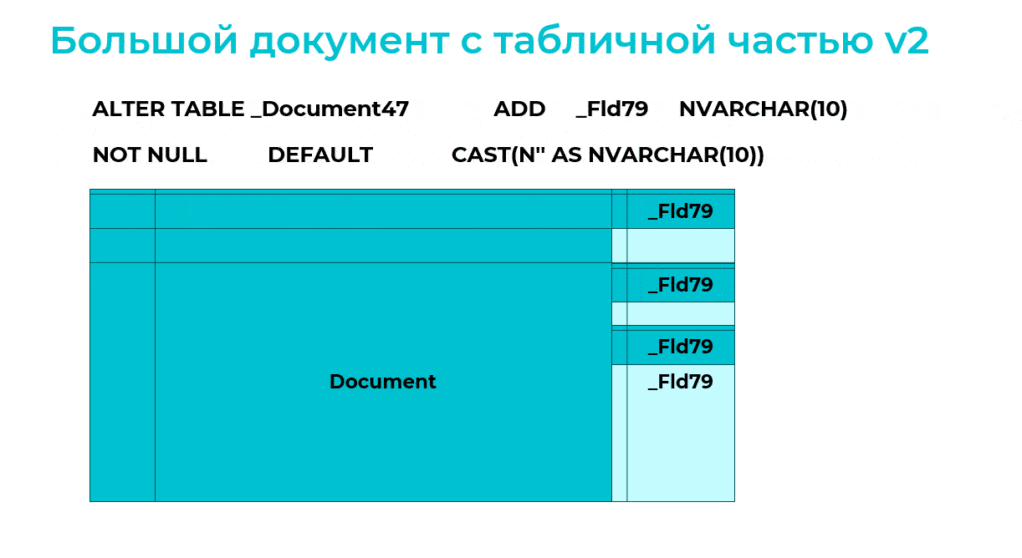
Если добавляются новые строки, то в новое поле будет записано реальное значение.
-
Если будет запрос к старым строкам, вернется значение по умолчанию, и платформа тоже будет нормально работать.
-
Если изменяются старые строки, то они также будут записываться с реальным значением нового поля.
Обновление структуры таблиц в таком режиме происходит на уровне метаданных, не затрагивая миллионы строк – в этом и преимущество.

Сразу предупрежу, что оптимизированный механизм не всегда работает быстро – иногда он также работает через копирование данных.
-
Если при оптимизированном механизме вы встретите команду CREATE TABLE, то, скорее всего, дальше будет перенос данных из одной таблицы в другую, например, INSERT INTO… SELECT… FROM…, это для больших таблиц занимает много времени.
-
Если при оптимизированном механизме для больших таблиц будет выполняться команда ALTER TABLE, реструктуризация выполнится быстро – можно не беспокоиться.
Проверка больших таблиц на возможность применения реструктуризации v2 (MS-SQL)
Казалось бы, оптимизированный механизм – это такая крутая штука, что можно сразу запускать его на рабочей базе. Но выяснилось, что сразу это может и не заработать.

Впервые мы попробовали перейти на оптимизированный механизм в сентябре 2021 года:
-
Сначала мы попробовали на небольшой тестовой базе добавить реквизит в шапку документа, в котором много строк – произошла реструктуризация через ALTER TABLE. Вроде все хорошо – никаких сюрпризов, подозрительных команд нет, CREATE TABLE нет.
-
Потом развернули бэкап рабочей базы в тестовом контуре и попробовали повторить добавление реквизита в шапку документа – база зависла.
-
Когда посмотрели, что происходит в этот момент в СУБД, оказалось, что там выполнялось длительное создание индексов.
Почему на большой базе не помог v2

Мы проанализировали действия СУБД при добавлении реквизита в документ:
-
Сначала начал создаваться индекс по дате документа – хотя вроде бы индекс был, но начал создаваться новый.
-
Потом начал создаваться индекс по реквизиту с дополнительным упорядочиванием.
-
А поскольку реквизитов с дополнительным упорядочиванием у нас было два, потом еще и по второму реквизиту с дополнительным упорядочиванием создавался индекс.
Поскольку в таблице были сотни миллионов срок, эти операции происходили очень долго.

Далее стали удаляться старые версии индексов – по дате документа и по индексам с дополнительным упорядочиванием. Удаление старых индексов произошло быстро.

Почему на большой базе начали создаваться новые индексы?
Дело в том, что у нас в базе большие таблицы уже несколько лет через 1С не обновлялись. Конечно, состав полей по данным 1С и СУБД был одинаковым, а вот состав индексов оказался различным.
Мы для этого документа добавляли индексы с дополнительным упорядочиванием вручную (выделены зеленым). Но забыли, что платформа 1С всегда добавляет значения полей реквизитов с дополнительным упорядочением еще и в индекс по дате, и в каждый из индексов по реквизитам с дополнительным упорядочением.
В результате для оптимизированного механизма разница в составе индексов выглядит так, что необходимых индексов нет, а есть какие-то лишние индексы. Лишний индекс удаляется быстро, а добавление новых индексов на миллионах строк занимает много времени.
Как смогли перейти на v2
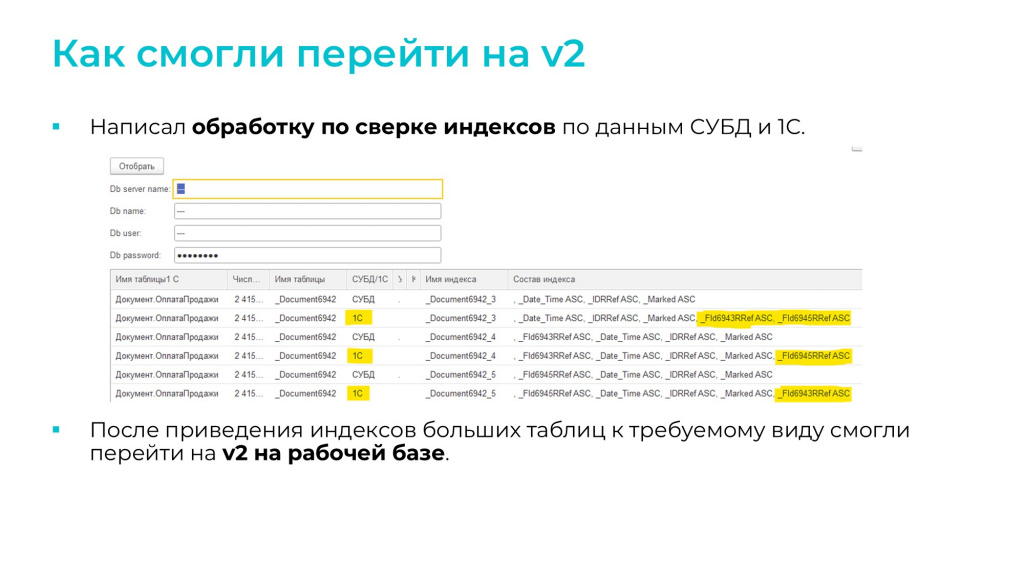
Я написал обработку по сверке индексов по данным СУБД и 1С.
На слайде как раз пример нашей таблицы, в которой мы не учли особенностей индексов с дополнительным упорядочиванием, и таблицы, созданной 1С. Потом мы привели индексы к требуемому виду и перешли на оптимизированный механизм.
Еще хочу упомянуть, что мы даже нашли различия в кластерных индексах. Это отдельная проблема для MS SQL. Далее расскажу.

Подытожим:
-
Состав индексов, требуемых по данным 1С, может различаться от существующих индексов СУБД.
-
Платформа в различных релизах также может менять состав индексов, это тоже надо учесть.
-
Как итог, перед переходом на оптимизированный механизм надо добавить недостающие индексы по данным 1С. Если у вас есть лишние индексы, оптимизированный механизм их быстро удалит, но создавать индексы для больших таблиц он будет долго.
Обработку сверки индексов я выложил на GitHub.
Пример, когда реструктуризация v2 не поможет (MS-SQL)
Сейчас будет пример с изменением кластерного индекса. Если у вас вдруг на рабочей базе кластерный индекс почему-то оказался отличным от того, который требуется для 1С, будет не очень хорошо.
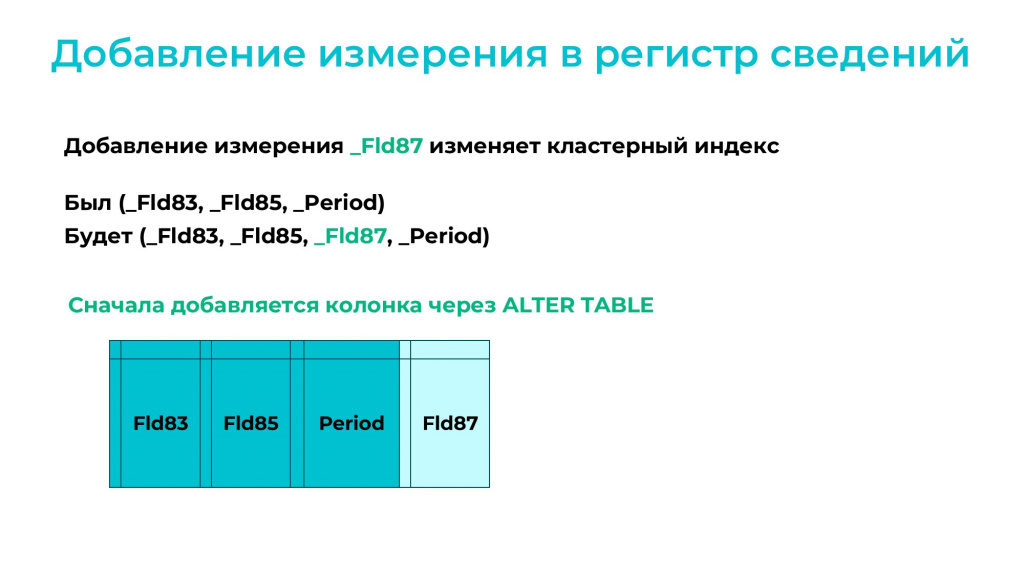
Пример. У нас есть периодический регистр сведений с двумя измерениями, куда мы хотим добавить третье измерение (_Fld87 на слайде).
Новое измерение через ALTER TABLE добавляется быстро, но дальше в регистре должны построиться новые индексы.
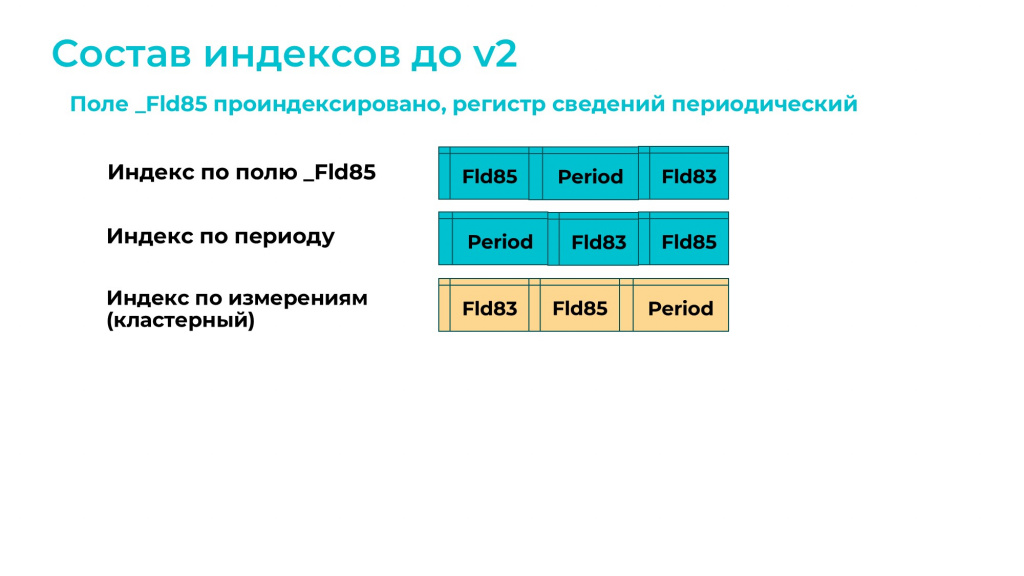
До реструктуризации в регистре есть три индекса:
-
индекс по второму измерению;
-
индекс по периоду;
-
и кластерный индекс – со всеми измерениями по порядку.
Оптимизированный механизм выполняет обновление так – сначала он добавляет новые индексы, а потом будет удалять старые.
-
Сначала он добавляет новый индекс по второму измерению с третьим измерением в конце.
-
Потом добавляет новый индекс по периоду с третьим измерением в конце.
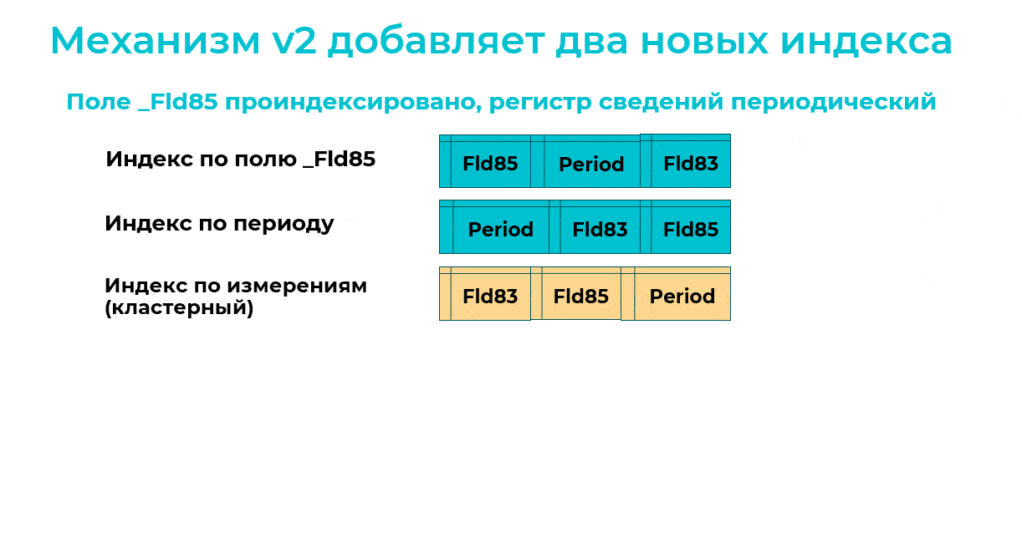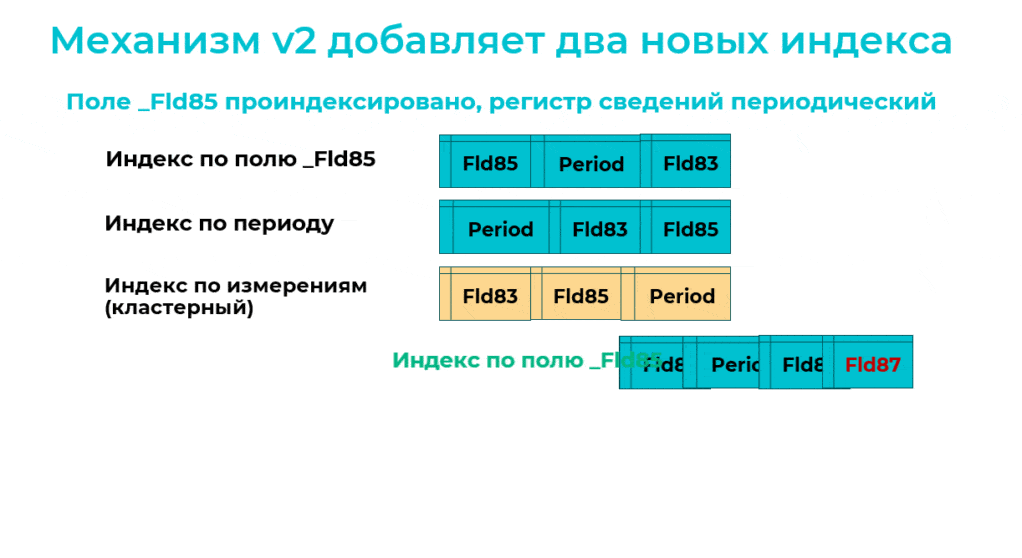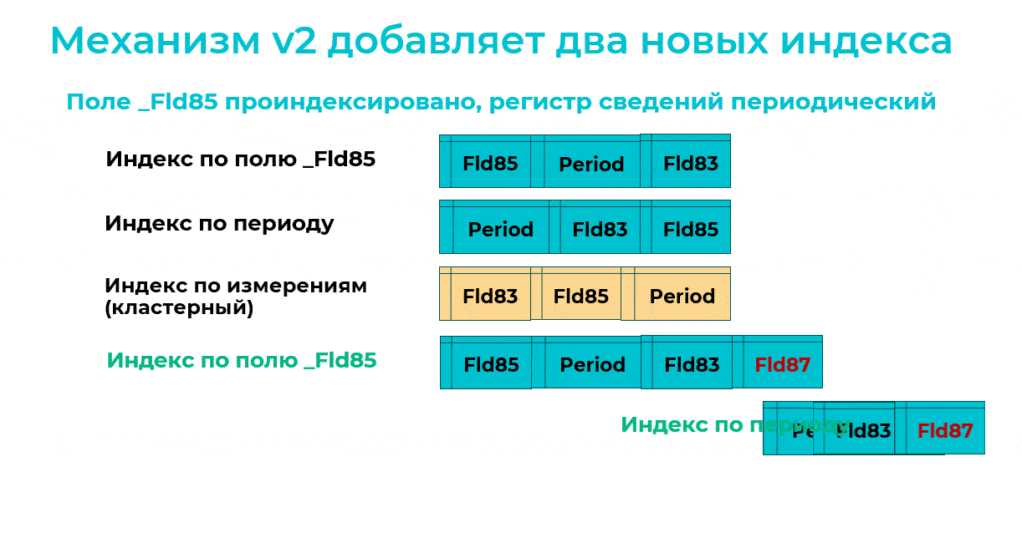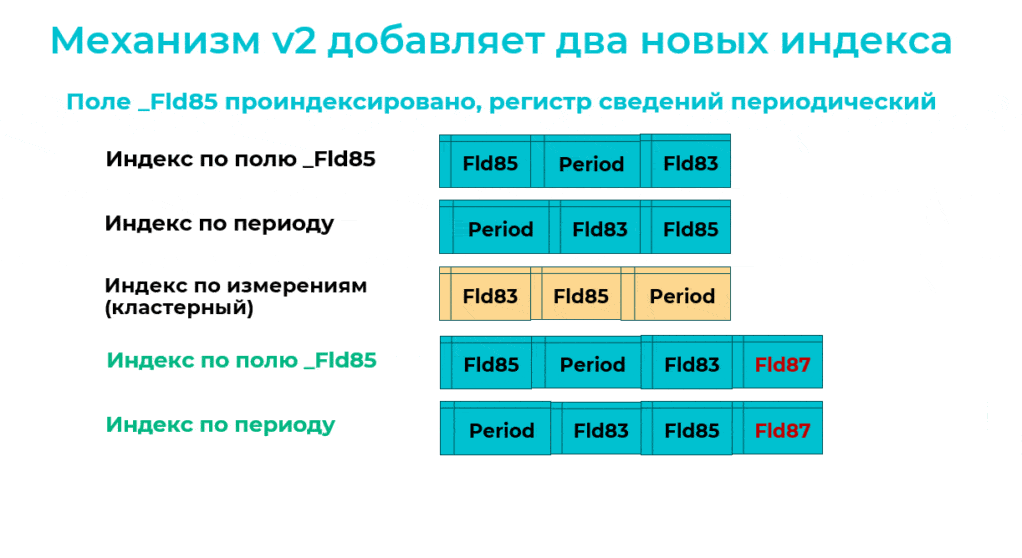
А теперь посмотрим, что внутри некластерных индексов.
На самом деле, когда есть кластерный индекс, каждая строка некластерного индекса содержит ключ кластерного индекса для поиска строки таблицы – здесь ключ кластерного индекса выделен желтым цветом.
И когда оптимизированный механизм добавляет новые версии некластерных индексов, в каждом из них тоже есть ключ кластерного индекса.

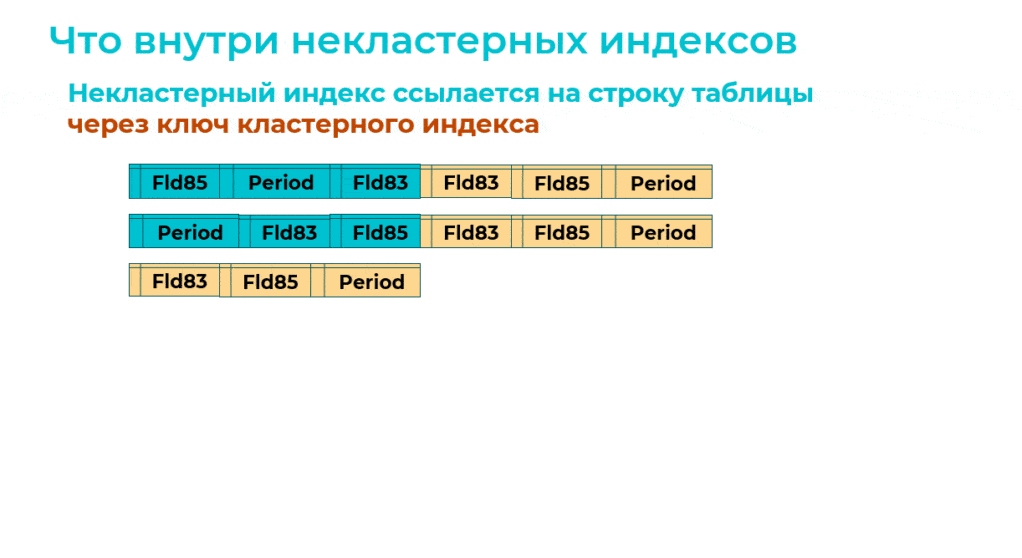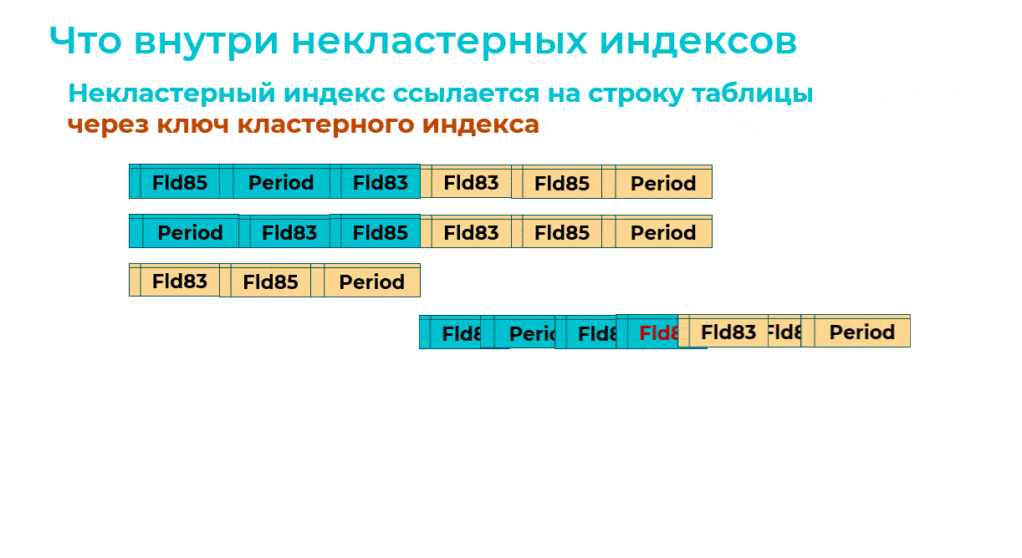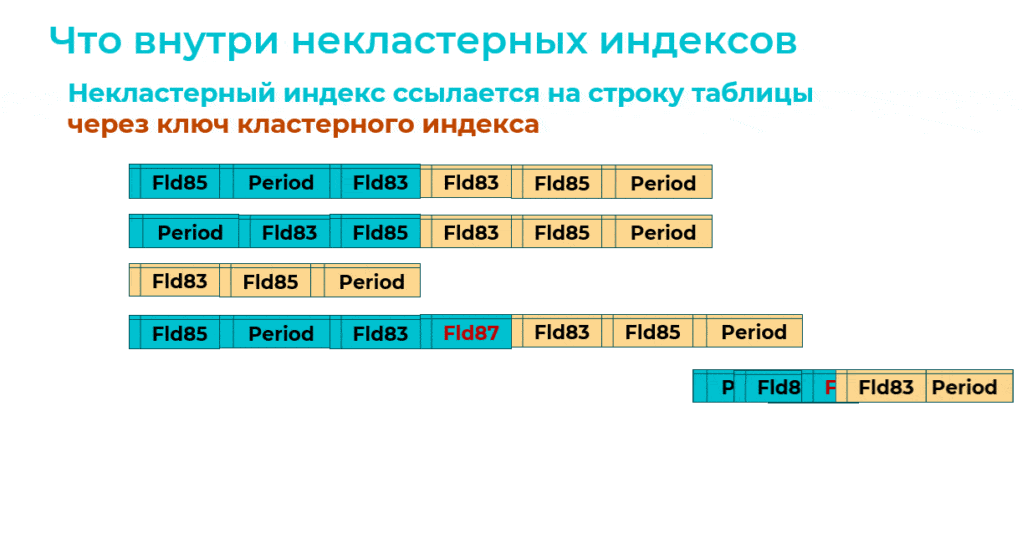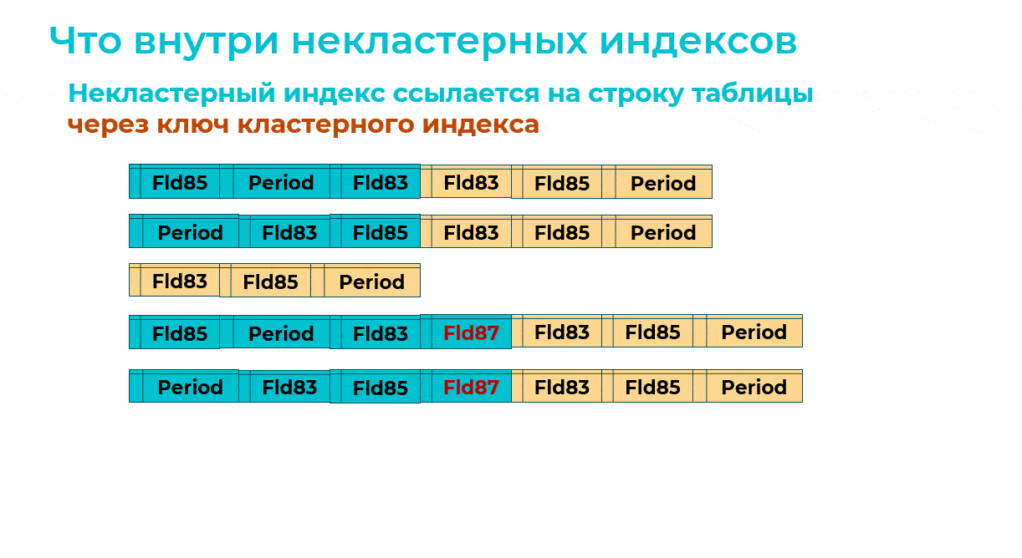
А далее оптимизированный механизм перестраивает кластерный индекс. При этом на MS SQL выполняется не очень оптимальная команда:
CREATE … CLUSTERED INDEX … WITH (DROP_EXISTING = ON)
Она меняет ключ кластерного индекса и добавляет в него третье измерение. И одновременно в каждом некластерном индексе обновляется ссылка на кластерный индекс.
Получается, что в данном случае одновременно перестраивается 5 индексов – это пример неудачной ситуации, неудачного сценария.
Причем это все происходит в одной команде, а значит, в одной транзакции. И если у вас в базе включена полная модель восстановления (а на большинстве баз она обычно включена), даже может переполниться журнал транзакции.

Подытожим, когда может возникнуть перестроение кластерного индекса?
-
Изменение состава измерений регистра сведений.
-
Если кластерный индекс был создан в старых версиях платформы, а вы вдруг решили эту таблицу изменить и думаете, что реструктуризация пройдет быстро, кластерный индекс может подкинуть проблем.
-
Если кластерный индекс был изменен вручную для каких-то своих задач, то при добавлении реквизита перестроение кластерного индекса на MS SQL тоже может затянуться.

В результате у нас появляется еще одна опасная команда, которую на MS SQL желательно избежать. И если вы при оптимизированной реструктуризации на тестовой базе видите, что происходит команда:
CREATE … CLUSTERED INDEX … WITH (DROP_EXISTING = ON)
надо задуматься и посмотреть, может у вас кластерный индекс не соответствует тому, каким должен быть по данным 1С.
И если все-таки понадобилось изменять кластерный индекс, например, изменить набор измерений регистра сведений, то на MS SQL для большой таблицы изменение кластерного индекса можно сделать на обычном механизме реструктуризации, и это будет быстрее, чем на оптимизированном.
Забегая вперед, скажу, что для PostgreSQL изменение кластерного индекса выполняется, как и при обычной реструктуризации через копирование таблиц, и такой проблемы нет.

Что делать, если кластерный индекс большой таблицы отличается по данным MS SQL и 1С?
-
Честный вариант – это согласовать большое технологическое окно и каждую такую таблицу перекрутить обычным механизмом реструктуризации, чтобы кластерный индекс был таким, как нужен по данным 1С.
-
Другой вариант – это конвертировать таблицы на СУБД. Но фирма «1С» это не одобряет.
Ограничения механизма реструктуризации v2 для PostgreSQL
Про ограничения механизма реструктуризации для PostgreSQL расскажу на примере его сравнения с MS SQL.
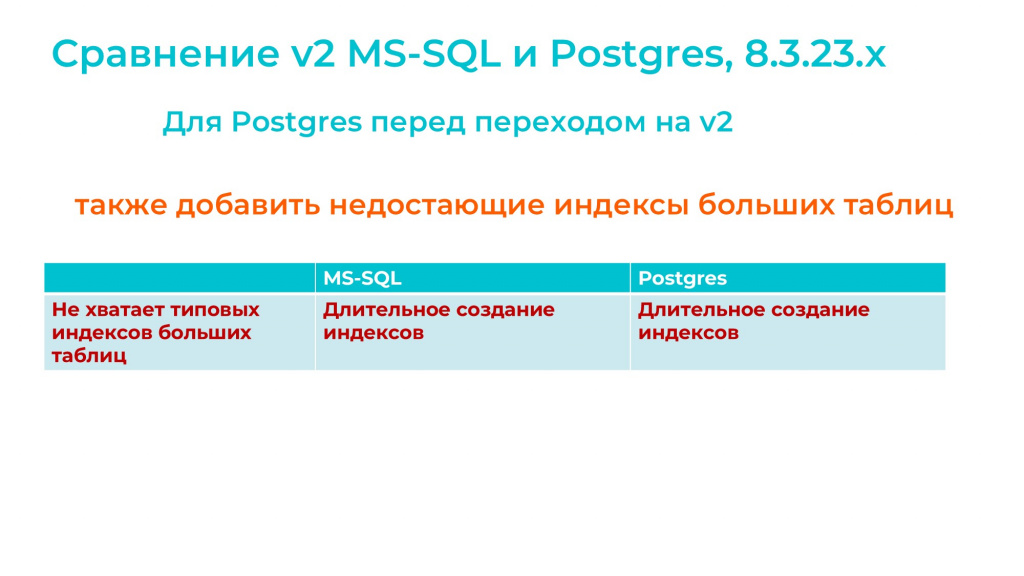
Что надо сделать перед переходом на оптимизированный механизм реструктуризации?
Для больших таблиц PostgreSQL, так же как и для MS SQL, надо создать недостающие по данным 1С индексы. Для маленьких таблиц это делать необязательно, но для больших лучше создать, иначе их отсутствие может замедлить реструктуризацию.

Также на PostgreSQL выявилась небольшая особенность – оптимизированный механизм реструктуризации для ссылочных полей задает режим хранения PLAIN.
Например, для полей табличной части *_idrref и *_keyfield (ID ссылки и ключ строки) он ставит: SET STORAGE PLAIN
Однако, если у вас база изначально была реструктуризирована обычным механизмом или загружена из dt-шника, для этих же полей может оставаться режим хранения по умолчанию EXTENDED.

А если оптимизированный механизм реструктуризации будет реструктуризировать такую таблицу, он увидит, что режим хранения EXTENDED отличается от режима хранения PLAIN, и это вызовет копирование таблиц. А если эта таблица большая, это будет долго.

Поэтому перед переходом на v2 для базы PostgreSQL желательно:
-
добавить недостающие по данным 1С индексы для больших таблиц;
-
добавить недостающие признаки хранения через SET STORAGE PLAIN – они устанавливаются на уровне метаданных, почти мгновенно.
На GitHub я также выложил обработку, добавляющую недостающие признаки хранения через SET STORAGE PLAIN.
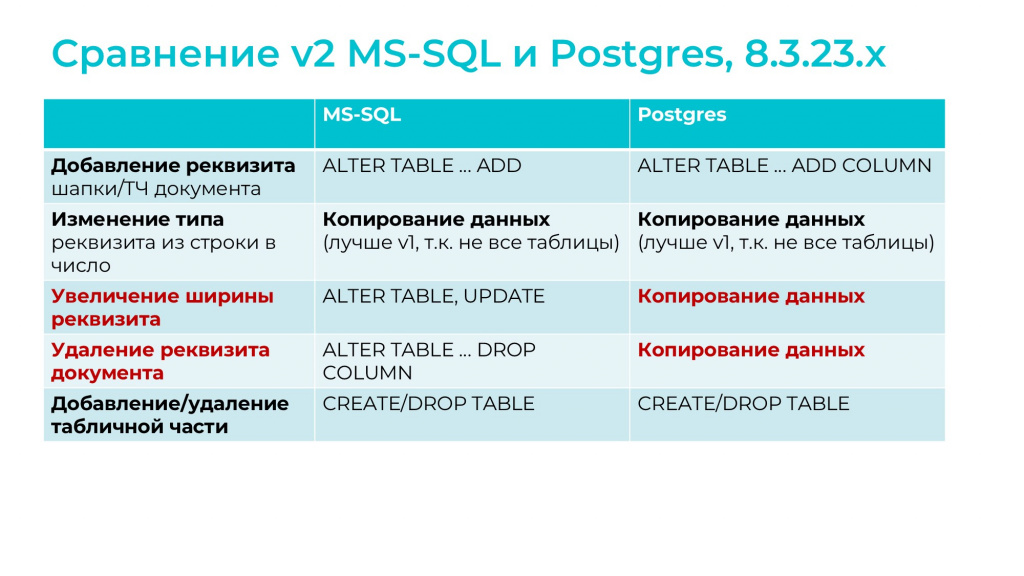
Продолжаем сравнивать особенности реструктуризации v2 для MS SQL и PostgreSQL:
-
Добавление реквизита шапки или табличной части документа, что для MS SQL, что для PostgreSQL, выполняется на уровне метаданных, через ALTER TABLE…ADD – и это быстро.
-
Изменение типа реквизита, например, из «Строки» в «Число» вызывает копирование данных – что на MS SQL, что на PostgreSQL. Здесь может сложиться впечатление, что обычный и оптимизированный механизм реструктуризации при копировании данных – это примерно одно и то же. Но принципиальное отличие в том, что:
-
При оптимизированном механизме обрабатывается только та таблица, которая затронута – в этом случае при добавлении реквизита, например, в одну из табличных частей, ни шапка, ни другие табличные части не затрагиваются.
-
А при обычном механизме реструктуризации копируются все таблицы объекта метаданных.
-
-
Если у вас происходит увеличение ширины реквизита или удаление реквизита документа:
-
На MS SQL это происходит довольно быстро – через ALTER TABLE, UPDATE или DROP COLUMN.
-
А на PostgreSQL это будет копирование таблицы – правда, в отличие от v1 будет копироваться только одна, а не все таблицы объекта, но это все равно надо иметь в виду. Мне кажется, что удаление реквизита на PostgreSQL тоже можно было бы выполнить через ALTER TABLE… DROP COLUMN – возможно, что платформу в будущем оптимизируют, тогда по этому сценарию удастся ускорить реструктуризацию .
-
-
Добавление или удаление табличной части на обоих типах СУБД выполняется довольно быстро – через CREATE TABLE или DROP TABLE.
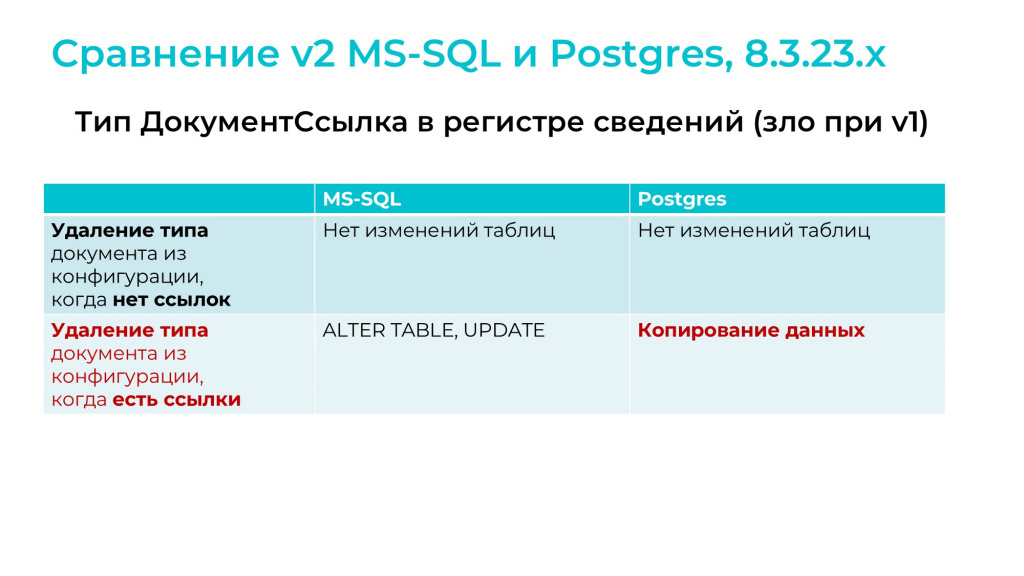
При обычном механизме реструктуризации самый опасный тип данных – это ДокументСсылка. Например, если тип ДокументСсылка используется в регистре сведений, то при удалении любого документа из конфигурации для такого регистра при обычной реструктуризации будет выполняться копирование таблицы, и если регистр большой, это займет много времени.
Оптимизированный механизм в этом плане сильно продвинулся.
-
Если в конфигурации нет ссылок на удаляемый документ, не будет никакого изменения таблиц – реструктуризация пройдет практически мгновенно.
-
Если в регистре сведений были ссылки на этот документ, то:
-
в MS SQL реструктуризация будет происходить через ALTER TABLE и UPDATE – удаляемый документ будет заменяться на пустую ссылку.
-
А PostgreSQL будет копировать таблицы – это менее оптимально.
-
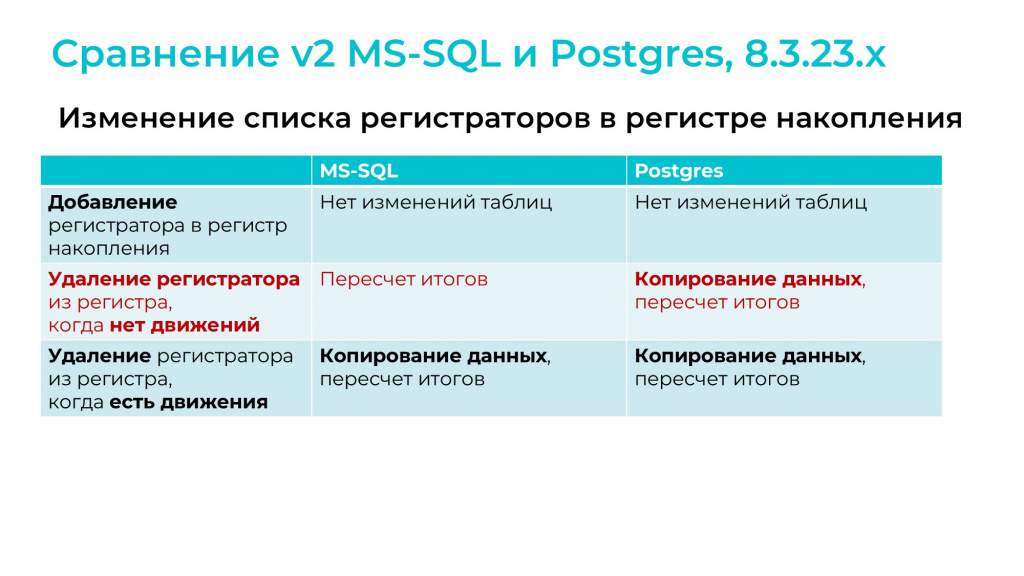
Посмотрим, что будет, если изменить список регистраторов в регистре накопления.
-
Добавление регистратора в регистр накопления не вызывает изменений таблиц на обоих типа СУБД – происходит довольно быстро.
-
А вот удаление регистратора из регистра, когда нет движений:
-
на MS SQL почему-то вызывает пересчет итогов;
-
а на Postgres кроме этого, происходит еще и копирование данных. На мой взгляд, можно было бы вообще не трогать таблицы – может быть, я что-то не учитываю, но мне кажется, это можно оптимизировать в платформе, чтобы в будущем реструктуризация происходила быстрее.
-
-
Если у вас были движения по регистратору, который вы удаляете из регистра, это вызовет копирование данных и пересчет итогов на любом типе СУБД. А поскольку копирования не избежать, то при большом количестве движений реструктуризация будет долгой.

Следующие две проблемы связаны с изменением кластерного индекса:
-
Изменение списка измерений в регистре сведений:
-
На MS SQL добавление измерения в регистр сведений вызывает перестройку кластерного индекса, и это получается даже менее оптимально, чем на PostgreSQL.
-
А. для PostgreSQL и при обычном механизме реструктуризации изменение списка измерений в регистре сведений вызывает обычное копирование данных.
-
-
Удаление измерения из регистра сведений работает чуть быстрее:
-
Но в MS SQL тоже вызывает перестройку кластерного индекса, и если индексов много, это может быть дольше, чем обычный механизм.
-
У PostgreSQL этот момент получше – там тоже происходит копирование данных.
-
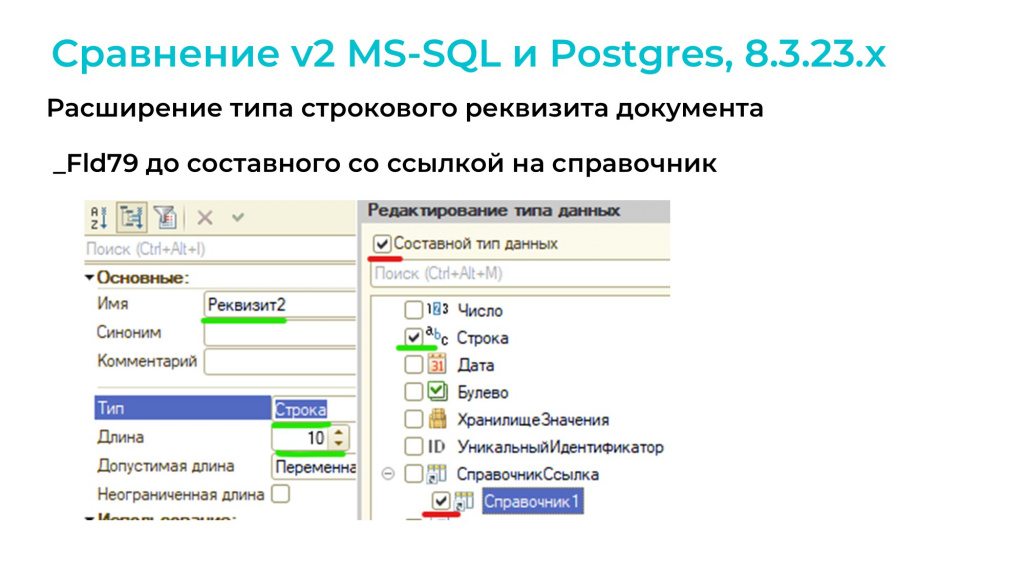
Мой самый любимый сценарий – расширение типа строкового реквизита документа. У нас есть реквизит типа «Строка», мы ставим галочку «Составной тип данных» и добавляем в тип ссылку на какой-то справочник.

В MS SQL расширение типа происходит довольно красиво – через ALTER TABLE добавляются поля Fld79_TYPE и Fld79_RRef:
-
для старых записей с типом «Строка» значение по умолчанию для поля Fld79_TYPE устанавливается как 0x05;
-
а значение по умолчанию Fld79_RRef – пустая ссылка.

При этом старое поле переименовывается (из Fld79 становится Fld79_S), и в таком виде с таблицей уже можно работать. Платформа видит в старых записях TYPE=0x05, которое значит, что там находится строка, и вытаскивает значение из старого переименованного поля.

При этом на PostgreSQL расширение типа до составного вызывает копирование данных.
Мы решили поэкспериментировать и вручную изменили структуру таблицы на PostgreSQL поля аналогично MS SQL:
-
добавили поле Fld79_TYPE со значением по умолчанию 0x05;
-
добавили поле RRef – пустая ссылка;
-
переименовали поле, где была строка – в конце добавили _S.
И решили, что вроде должно работать.
Но оказывается, что PostgreSQL в некоторых ситуациях использует для вставки строк команду COPY… FROM STDIN, которая шлет данные в «правильном» порядке полей: сначала поле TYPE, потом S и потом RRef.
А у нас после ALTER TABLE новые поля дописаны в конец строки, т.е. порядок полей другой. Поэтому при выполнении этой команды возникает ошибка несоответствия данных и размеров полей.

Подытожим – какие советы можно дать для PostgreSQL, чтобы постараться уложить время реструктуризации в технологическое окно:
-
На PostgreSQL перед переходом на оптимизированный механизм добавьте для ссылочных типов больших таблиц недостающий признак хранения SET STORAGE PLAIN. В обработке я накидал примерный алгоритм, который установит этот признак полям *_idrref и *_keyfield – но поскольку порядок работы оптимизированного механизма в платформе может измениться, корректность этого алгоритма не гарантируется.
-
И если у вас на PostgreSQL для большой таблицы нужно удалить реквизит или регистратор, обрабатывайте такие метаданные по одному.
Ошибки при реструктуризации v2 (номера ошибок и релизы с исправлением)
Конечно, в процесс эксплуатации оптимизированного механизма реструктуризации не обошлось без ошибок платформы. Здесь надо отдать должное фирме «1С» – все критичные ошибки, которые мы нашли, они исправили. Даже более того, они внесли исправления не только в последние версии платформы, но и предыдущие.

Например, ошибку «Конвертер … определил объект … как некорректный» фирма «1С» исправила для 8.3.24, 8.3.23, 8.3.22, 8.3.21, 8.3.20 и даже для 8.3.19.
Эта ошибка проявлялась следующим образом – у нас в справочнике был реквизит типа «ПеречислениеСсылка.Перечисление1», а мы решили поменять его тип на «ПеречислениеСсылка.Перечисление2». Реструктуризация оптимизированного механизма прошла хорошо, но в служебных таблицах не отразилась информация об изменении типа. И при следующей реструктуризации оптимизированного механизма возникала ошибка: «Конвертер… определил объект Reference35.Fld38 как некорректный» Т.е. платформа определяла измененное на предыдущей реструктуризации поле справочника как некорректное. Реструктуризация при этом даже не начиналась – сразу отваливалась на этой проверке.
Я подготовил тестовый пример и отправил его в фирму «1С» – ошибку зарегистрировали и исправили во всех последних релизах платформ от 8.3.19 до 8.3.24.
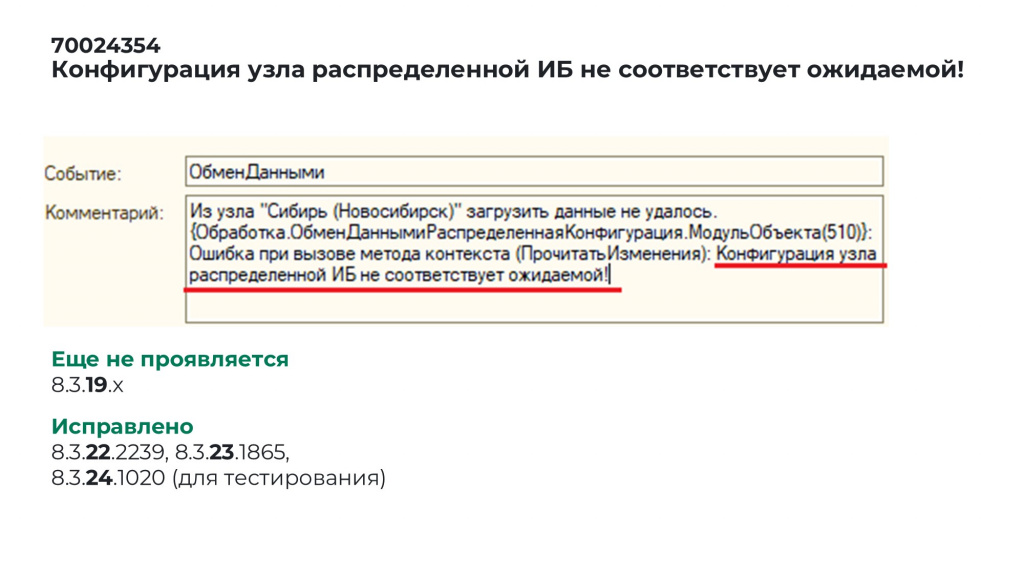
Другая ошибка – конфигурация узла распределенной ИБ не соответствует ожидаемой.
С определенного релиза платформы оптимизированный механизм реструктуризации перестал регистрировать изменения конфигурации для распределенной базы – изменения конфигурации не доходили до оригинальных узлов, и возникала ошибка.
Мы обнаружили это при переходе на 8.3.19 на 8.3.23. На платформе 8.3.19 ошибка еще не проявляется. А начиная с 8.3.22 и далее фирма «1С» ошибку уже исправила.
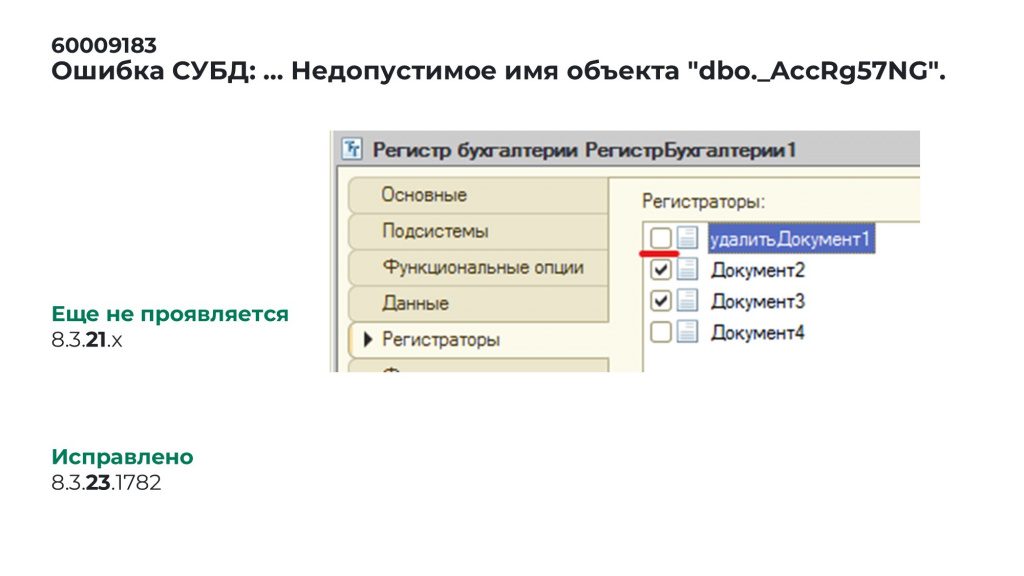
Еще одна ошибка – недопустимое имя объекта. Здесь упоминается внутреннее имя таблицы движений регистра бухгалтерии и в конце NG.
Ошибка проявилась, когда мы удаляли один из неудачных регистров бухгалтерии. Сначала удалили все его движения, потом решили удалять регистраторы – снимать галочки с документов, чтобы потом уже удалять и сами документы из метаданных.
В процессе удаления документа из списка регистраторов на одном из ранних релизов платформы 8.3.23 вылезла ошибка: «Ошибка СУБД: … Недопустимое имя объекта», имя таблицы и NG.
Я подготовил тестовый пример, отправил в «1С», оказалось, что ошибка уже исправлена в одном из релизов. Нам ошибку не зарегистрировали, а просто сказали номер релиза, в котором этой ошибки уже нет.
В релизе 8.3.21 ошибка еще не проявлялась.

Полный список ошибок, с которыми мы столкнулись, и релизов, где это исправлено, есть на GitHub.
Там же дополнительные материалы по настройке технологического журнала, чтобы логировать запросы оптимизированного механизма.
Небольшое замечание про v2 и секционированные таблицы на MS SQL
Большие базы не обходятся без секционирования – чтобы удобнее обслуживать большие таблицы и быстрее перестраивать для них индексы, их обычно секционируют или по периоду, или по ссылке. Расскажу про особенности использования оптимизированного механизма реструктуризации для секционированных таблиц.

До версии 8.3.22 в простых случаях секционированных таблиц еще можно использовать оптимизированный механизм реструктуризации.
А если вы попробуете использовать оптимизированный механизм реструктуризации для секционированной таблицы на 8.3.23, у вас возникнет ошибка «База данных не соответствует DbSpace»: таблица, которую вы реструктуризируете, не найдена.
У нас такая ошибка возникла при реструктуризации табличной части документа, которая была секционирована по ссылке.
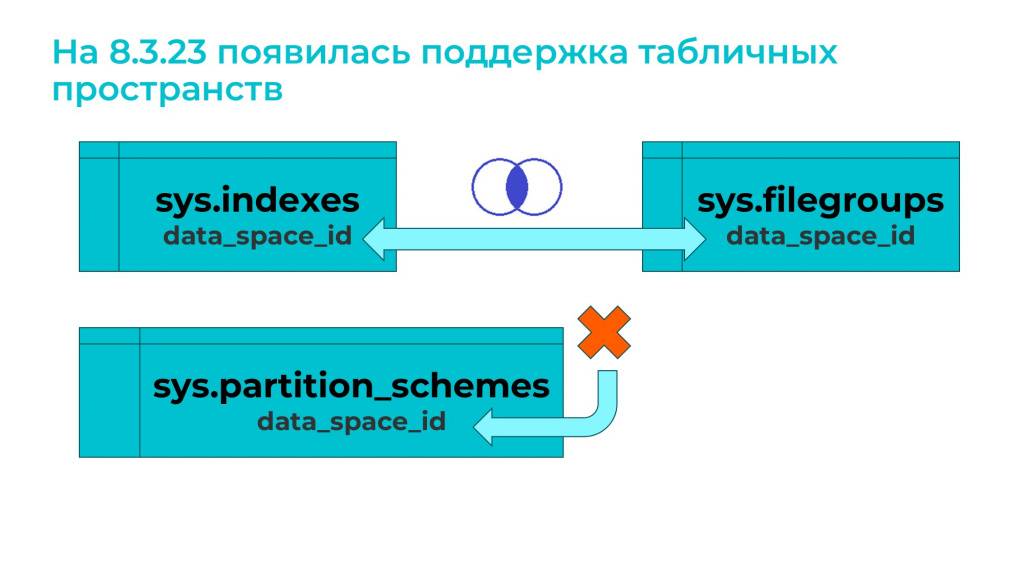
Ошибка возникает из-за того, что в платформе 8.3.23 появилась поддержка табличных пространств. И когда оптимизированный механизм получает данные о таблицах, он соединяет внутренним соединением таблицу индекса с таблицей файловых групп.
А когда таблица секционирована по какому-то полю, например, по ссылке или по периоду, данные об этом хранятся в таблице схем секционирования, с которой соединения не происходит. В результате получается, что таблица не найдена.

Подытожим:
-
До 8.3.22 еще можно добавлять поля и использовать оптимизированный механизм для секционированных таблиц.
-
На платформе 8.3.23 для секционированных таблиц использовать оптимизированный механизм уже нельзя. Но это нельзя считать ошибкой, так как официально секционирование таблиц не поддерживается.
Итоги доклада

Подытожу весь доклад, на какие моменты обратить внимание:
-
Перед переходом на оптимизированный механизм добавьте для больших таблиц недостающие индексы по данным 1С.
-
Старайтесь при оптимизированном механизме не менять кластерные индексы больших таблиц. Если все-таки это необходимо сделать, то для MS SQL лучше переключиться на обычный механизм.
-
На PostgreSQL перед переходом на оптимизированный механизм добавьте для ссылочных типов больших таблиц недостающий признак хранения SET STORAGE PLAIN.
-
На PostgreSQL, если у вас большие таблицы, то при удалении реквизитов или удалении регистратора старайтесь обрабатывать такие метаданные по одному.
Дополнение от одного из слушателей доклада
В оптимизированном механизме реструктуризации добавление субконто на счет приводит к пересозданию таблицы регистра бухгалтерии, поскольку по общему правилу для существующих движений по этому счету нужно добавить новое субконто со значением «Неопределено».
При этом в оптимизированном механизме итоги не пересчитываются – когда у счета было одно субконто, итоги хранились в таблице итогов по счетам с Субконто1, а в таблицу итогов по счетам с Субконто2 они сами при реструктуризации не мигрируют. И если после такой реструктуризации запрос будет идти к остаткам, механизм платформы подумает, что у счета два субконто и пойдет в таблицу итогов Субконто2, а там ничего нет, и запрос не будет ничего выдавать.
Это ошибка платформы, она тоже зарегистрирована на багборде, и у вендора воспроизвелась для оптимизированного механизма реструктуризации.
Вопросы и ответы
Получается, что если индекс уже существует, но его нужно достроить по данным 1С, достаточно сделать ALTER TABLE и добавить колонку – тогда реструктуризация будет гораздо быстрее, чем копирование таблиц? А если нужно поменять поля местами? Запушить поле не в конце, а вставить между существующими?
ALTER TABLE этого не сделает, потребуется перестройка и изменение кластерного индекса. Это особенность MS SQL, там кластерный индекс по-другому обрабатывается.
Почему вы вручную создаете индексы, которых не хватает? Платформа ведь может сама их создать в режиме исправления?
Она их, конечно, создаст. Но если таблица большая, это займет много времени.
Мы это делаем вручную, чтобы избежать риска увеличения технологического окна. Мы опасались, что не управимся и пытались сократить время.
Сразу оговорюсь – официально делать это вручную нельзя, это нарушение лицензионного соглашения. Поэтому мы делаем это по-тихому, а лучше не делаем. Лучше действительно изменить процесс разработки – создать еще один регистр, потихоньку туда переехать и так далее.
Можно ли вместо изменения типа реквизита просто удалить его и создать новый? Это ведь будет происходить более быстро на оптимизированном механизме реструктуризации?
Конечно, это приветствуется. Единственное, для PostgreSQL удаление реквизитов вызывает копирование таблицы. Это не оптимально, но вроде ошибкой считать нельзя, хотя мы надеемся, что это когда-нибудь исправится. А на MS SQL конечно, удаление и добавление – это хороший вариант.
Насколько я понимаю в зависимости от ситуации мы пользуемся либо версией 2, либо старой версией реструктуризацией со всеми вытекающими отсюда последствиями. Но когда мы прописали в конфигфайле «версия 2», а потом удалили, решив, что сейчас все будет по-старому, реструктризация продолжила выполняться по второму варианту. Чтение мантр и интернета не помогало. Единственное, что помогло – это переустановка сервера 1С:Предприятие. Вы сталкивались с такой ситуацией?
Вы меняли версию реструктуризации на сервере или на клиенте? С какой-то версии настройка идет на клиенте.
Мы меняли на клиенте – там, где запускается конфигуратор. Так написано в ИТС.
Могу предположить, что на компе оказалось два файла конфига, и она брала какой-то приоритетный. Надо потестить.
Наверное, тогда особому вниманию должны уделяться не только составные типы, но и планы видов характеристик, потому что они тоже могут неявно изменять состав других таблиц.
Надо тестировать. Здесь много комбинаций, которые мы не проходили.
У нас все-таки нет регистров расчета, и с регистром бухгалтерии мы работаем не так активно, как некоторые.
Можно ли заранее узнать, что будет происходить без тестовой реструктуризации на какой-нибудь тестовой базе?
Но вам надо такую тестовую базу подготовить, в которой индексы, типы полей и порядок полей точно такие же, как на рабочей. Но база не должна быть пустой – без строк поведение другое может быть.
Вы можете включить в технологическом журнале логирование запросов оптимизированного механизма и увидеть, какие там были команды CREATE TABLE или ALTER TABLE – у меня на GitHub есть настройка.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT.

Вступайте в нашу телеграмм-группу Инфостарт