Меня зовут Берлизов Сергей. В 1С я уже достаточно давно, с 2005 года — еще не динозавр, но уже матерый разработчик. Последние полтора года я занимаюсь переводом баз 1С с Microsoft SQL на Postgres.
Введение
Импортозамещение шагает по стране, и шаги все шире и шире... В мире 1С это в первую очередь касается замены СУБД с Microsoft SQL на Postgres.
Уже известно, что основной проблемой при переходе является довольно слабый оптимизатор запросов Postgres. Те запросы, которые на Microsoft SQL отрабатывали нормально, на Postgres вдруг начинают тормозить.
Традиционно для выявления таких запросов можно пойти простым путем: смигрировать базу на копию Postgres, запустить туда пользователей или аналитиков, чтобы они провели тестирование и выявили проблемные запросы. Но у такого подхода есть минусы. Прежде всего, это увеличение нагрузки на пользователей, а они не любят работать больше за те же деньги. Также часто не получается воспроизвести работу пользователей в полном объеме.
Чтобы исключить эти негативные моменты, мы разработали специальное решение. Причина его создания — большое количество систем на 1С в нашей организации. Если бы их было меньше, мы, наверное, ничего бы и не делали.
В статье я расскажу об основных этапах работ, опишу проблемы, с которыми столкнулись, покажу результаты использования программы в реальных базах.
Общая последовательность действий
Итак, в чем же суть предлагаемого метода? Если кратко, то выглядит это так:
- За требуемый период на рабочей базе снимаются расширенные события на сервере MSSQL.
- Затем снятые логи событий загружаются в специальную базу 1С – базу автотестов.
- Далее в базе автотестов выполняется преобразование текстов запросов MSSQL в запросы для Postgres.
- Делается копия базы на Postgres, с которой снимали логи расширенных событий.
- Из базы автотестов последовательно выполняются подготовленные запросы на этой копии.
- И последним пунктом находятся запросы, которые выполнялись на Postgres значительно дольше и которые могут быть оптимизированы.
Этап снятия расширенных событий
Теперь подробнее расскажу о каждом из этапов. Начнем со снятия расширенных событий. Предвидя вопрос «Зачем снимать запросы через расширенные события MSSQL, а не через Техжурнал 1С?», отвечу – причина в том, что в техжурнал попадают не все запросы, которые реально выполняются на сервере СУБД, а нам было интересно посмотреть все. В любом случае без техжурнала не обойтись, ведь только там есть данные по контексту, откуда был сформирован запрос.
Снятие расширенных событий выполняется без особых хитростей. Определяется период, за который выполняется большинство действий пользователя. Настраивается сеанс расширенных событий. Выбираются все события вида sql_batch_completed и rpc_completed. Можно также настроить отборы по тексту запроса, чтобы не грузить не нужные нам запросы – например, выборки из системных таблиц, установки параметров, управления транзакциями и т.д.
Нами было оценено влияние сбора расширенных событий как незначительное. Без отборов оно составило не более 10%, а при установке дополнительных отборов на тексты запросов нагрузка уменьшается.
Непосредственно сразу после старта сеанса расширенных событий выполняется скрипт на сервере Microsoft SQL для сбора данных по существующим временным таблицам на сервере. Это нужно потому, что 1С очень бережно относится к временным таблицам. Один раз создав временную таблицу, использовав ее в запросах, 1С ее не удаляет, а просто очищает и «складывает в чулан» до тех пор, пока не возникнет потребность во временной таблице с таким же набором колонок и типами данных.
Как только эта ситуация возникает, достается временная таблица из «загашника», «отряхивается от пыли», наполняется, опять используется, очищается и вновь забывается до тех пор, пока не возникнет потребность опять в такой временной таблице. И получается, что возможна ситуация, когда запросы по созданию временных таблиц не попали в наши логи, потому что были выполнены ранее старта сеансов расширенных событий. И мы сами должны написать этот запрос по созданию временной таблицы и выполнить его перед первым запросом, где эта временная таблица используется.
Также в этот момент времени можно уже начинать делать копию с рабочего сервера на Postgres. Для этого мы используем 1С-овскую утилиту IBCMD. Далее все действия выполняются уже в базе автотестов.
Описание интерфейса
Очень кратко расскажу об интерфейсе. Для возможности хранить в одной базе данные по различным тестам создан справочник «Настройка тестов». В нем хранятся только реквизиты, которые относятся именно к настройкам: пути подключения к серверам, настройки порционности загрузки данных и так далее. Сами же данные хранятся в регистрах сведений, в которых первым измерением как раз идет настройка тестов.
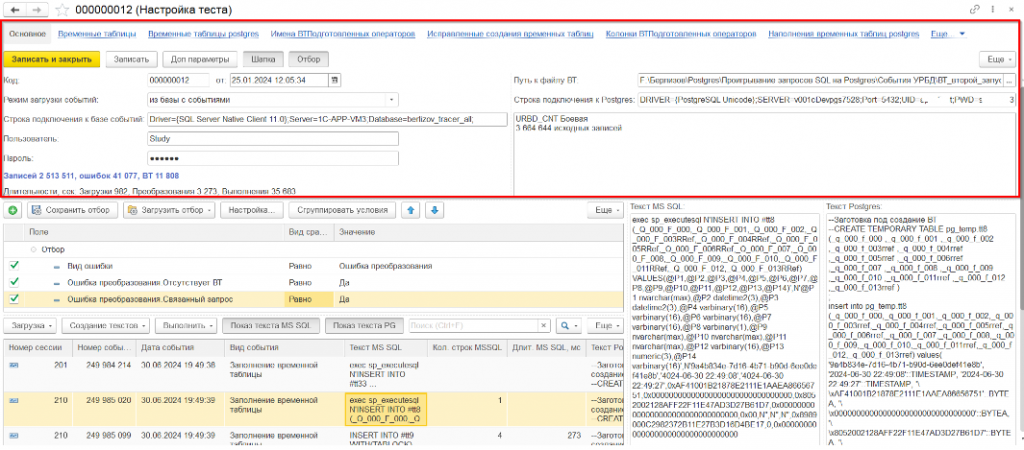
В верхней части формы расположены реквизиты справочника, в нижней части формы — динамический список с загруженными данными. Для удобства отдельно вынесены запросы Microsoft SQL и Postgres.
Загружаются, хранятся и обрабатываются данные в регистре сведений «Результат выполнения запросов». Структура его достаточно сложная. На этапе загрузки данных определяются дата события, номер сессии, номер события, длительность выполнения запроса и количество строк к запросам Microsoft SQL. Определяется вид события.
На этапах трансформации данных заносятся данные по тексту запроса Postgres, и фиксируется ошибка преобразования, если она была. При выполнении запроса уже на копии Postgres заносятся данные по длительности выполнения запроса, количеству строк, и если была ошибка, то она фиксируется при выполнении. Также для длительных запросов определяются и заносятся данные по предварительному плану запроса на Postgres.
Количество загружаемых и обрабатываемых данных очень велико и составляет десятки миллионов записей. Поэтому для удобства выполнения каждого этапа мы разбиваем обработку на порции, чтобы фиксировать промежуточные результаты и при сбое не начинать все сначала. Кроме того, для ускорения обработки используется многопоточность.
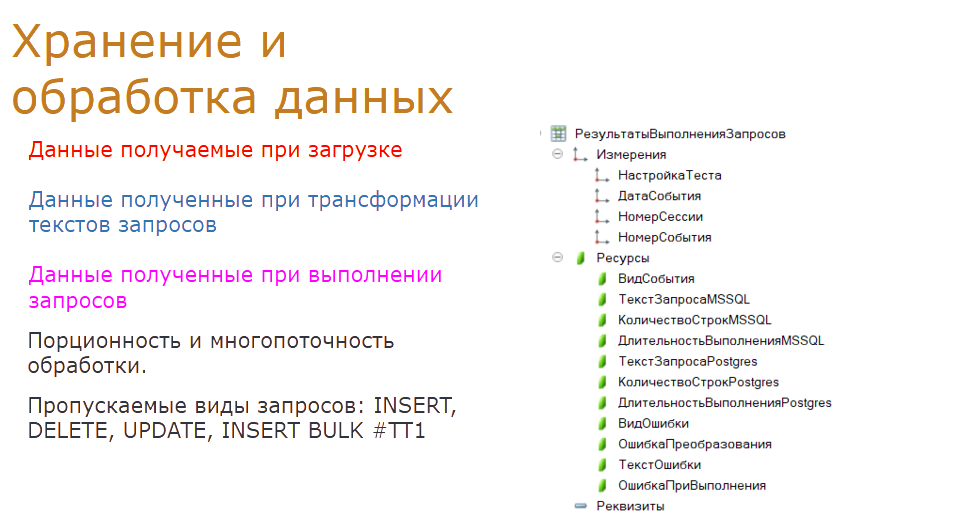
Также хочу добавить, что не все запросы будут обрабатываться. Исключаются запросы по изменению данных — INSERT, UPDATE и DELETE в таблицах базы. Также мы вынуждены были исключить запросы потоковой вставки данных во временную таблицу INSERT BULK. Такое событие возникает, когда с сервера 1С на сервер Microsoft SQL передается большой массив данных — например, большая таблица значений как параметр запроса. У нас просто нет данных, чтобы обработать подобный запрос. Хорошо, что таких событий немного.
Этап загрузки данных
Переходим к этапу загрузки данных. По настроенной строке подключения через внешний источник данных выполняется загрузка из базы расширенных событий в базу автотестов. При загрузке по ключевым параметрам определяется вид запроса. Пропускаются, если не были отсечены на этапе снятия логов, ненужные запросы.
Обрабатываться будут только запросы по созданию, очистке и заполнению временной таблицы, созданию индекса временной таблицы, выборке данных, операции с подготовленными операторами.

Немногие знают, что такое подготовленный оператор, поэтому коротко о нем расскажу. Эта конструкция есть и на Microsoft SQL, и на Postgres. Они отличаются синтаксисом.
Подготовленный оператор — это специальная конструкция с назначенным номером, для которой один раз назначается текст запроса и задаются параметры с их типами. Потом этот оператор многократно можно вызвать, просто указав его номер и значения параметров — дешево и сердито.
Также загружаются в отдельный регистр данные по реестру временных таблиц. Причины этого я указывал выше — это связано с особенностями работы 1С с временными таблицами.
Этап создания временных таблиц
На этапе создания временных таблиц выполняется обработка по запросам с временными таблицами. Этот этап вынесен отдельно, чтобы была возможность вручную исправить ошибки автоматического преобразования. Дело в том, что ошибка во временной таблице вызовет некорректный результат в запросе, который эту временную таблицу использует.
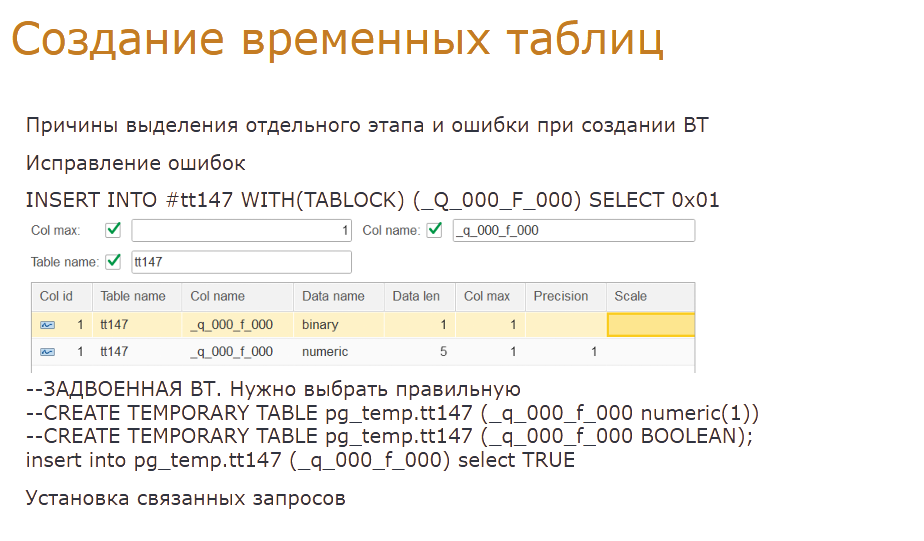
Основная сложность тут только в конвертации запросов по заполнению временной таблицы. По остальным видам операций преобразование запросов никакой сложности не вызывает и заключается в основном в замене одних конструкций запроса на другие.
Если в логи не попали события по созданию временной таблицы, то, как я говорил раньше, мы должны сами написать такой запрос. Для понимания покажу на примере: дошли до строки заполнения временной таблицы с номером 147, у которой всего одна колонка. В реестре Временных таблиц нашли две строки, подходящих по номеру таблицы, у которых одна колонка и имя колонки равно требуемому. В строках различия будут только в типах данных – бинари и ньюмерик. По данным этих строк сверху добавляем два запроса по созданию временных таблиц и фиксируем ошибку Задвоенные ВТ.
После завершения этапа автоматического преобразования можно выставить отбор по ошибкам преобразования и исправить их вручную. Такое исправление не требует много времени. Нужный запрос мы определяем по имени колонки либо по типу значения. В приведенном примере понятно, что подходит вторая строка создания временной таблицы с типом колонки BOOLEAN. Кроме того, можно вручную исправить запросы с другими ошибками при трансформации текстов запросов. Более подробно о таких ошибках я расскажу ниже.
Далее выполняем установку связанных запросов с временными таблицами, по которым есть ошибка. Сейчас это актуально только для запросов в начале логов, когда в них используются ВТ, которые были созданы и наполнены до начала снятия логов расширенных событий. По-хорошему эту ошибку нужно распространить на запросы, в которых вообще используются временная таблица, где была любая ошибка, связанная с ее наполнением.
Этап создания текстов запросов
Далее переходим к этапу создания текстов запросов. На этом этапе выполняется преобразование текстов запросов выборки SELECT.
Вначале выполняем замену имени временной таблицы с #tt на pg_temp.tt.

Далее откидываем конструкции, которые используются только в Microsoft SQL — dbo., WITH BLOCK и другие.

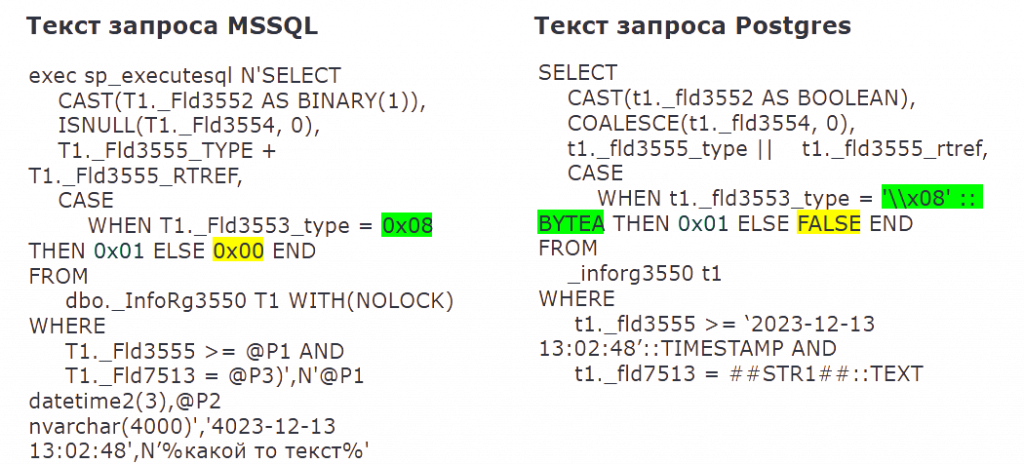
Потом выполняем преобразование бинарной строки «0x00» на FALSE, а все остальные бинарные строки, отличные от «0x01», на двоичные данные BYTEA. Обработку бинарных строк «0x01» покажу чуть дальше.
Для запросов rpc_completed выполняется замена параметров запроса на их значения. В запросах rpc_completed параметры, расположенные в нижней части запроса, разделены запятыми. Но просто так вычленить отдельные параметры не получается — мешают строковые параметры. В Microsoft SQL строковые значения оборачиваются одиночными кавычками с начальным символом N, и эти строковые значения могут содержать любые символы, включая запятые и скобки.
Поэтому мы вначале выполняем замену строковых значений на теги ##str##. Такой подход позволяет упростить дальнейшую обработку. Обратную замену тегов на строковые значения выполняем в конце конвертации.
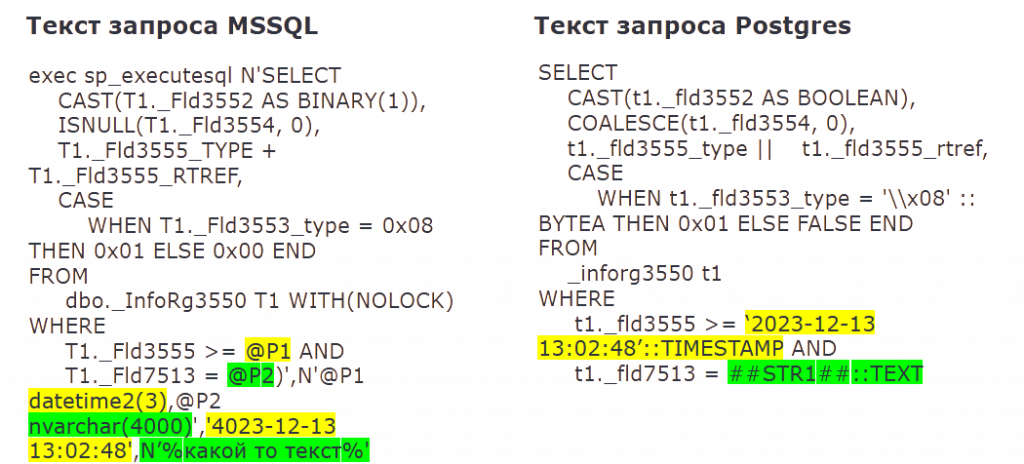
Далее выполняется замена типов Microsoft SQL на типы Postgres. Например, DATETIME2 заменяется на TIMESTAMP. Основная сложность здесь — конвертация BINARY(1), который может быть преобразован как в BYTEA, так и в BOOLEAN. Тут я могу ориентироваться только на постфикс имени поля. Если имя поля оканчивается на _type, то это BYTEA, иначе BOOLEAN.
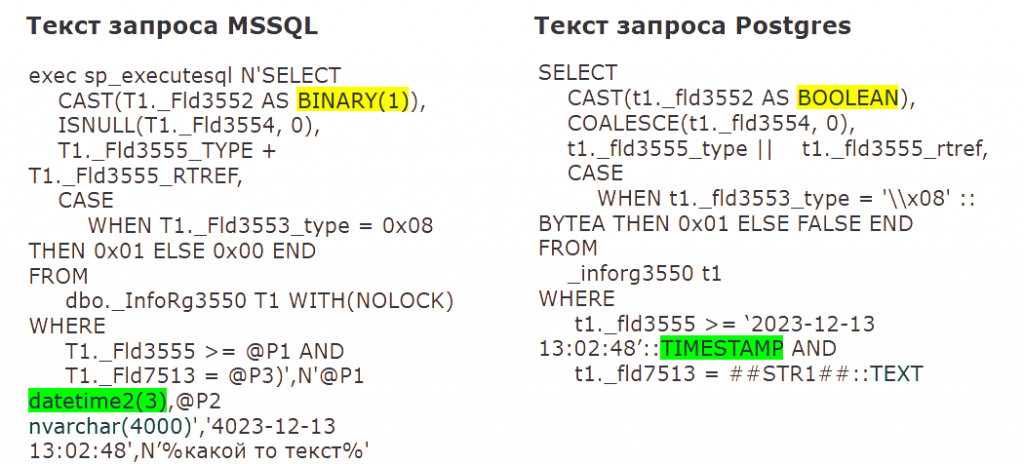
Потом выполняется замена функций — например, ISNULL на COALESCE, DATEDIFF на EXTRACT и так далее.
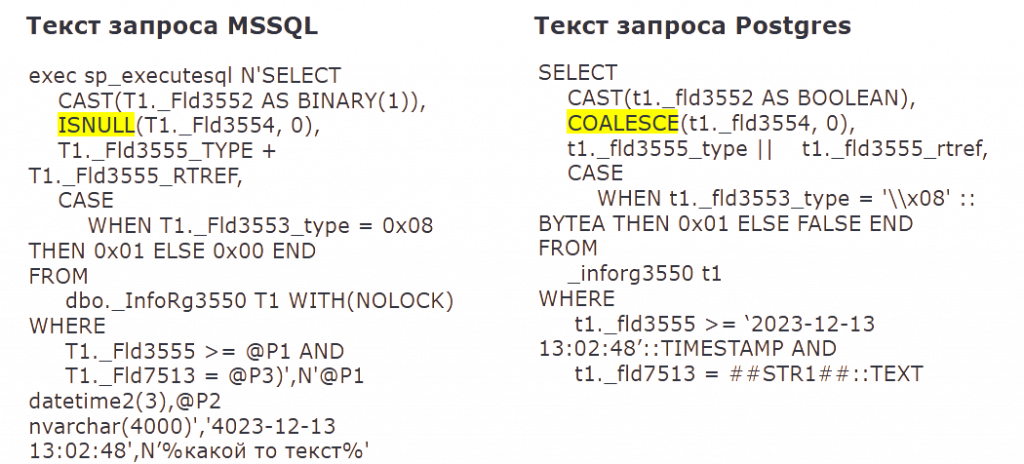
Затем попытка замены + на || для конкатенации строк.

Затем исправляем ошибку смещения дат на Microsoft SQL. То есть если у нас в дате четвертое тысячелетие, заменяем ее на второе. То же самое касается и пустой даты.

А потом мы переходим к самому сложному этапу преобразования — обработке 0x01. Как говорилось выше, BINARY(1) может быть преобразован в BYTEA или в BOOLEAN. Что касается бинарной строки «0x01», то она может быть преобразована как в двоичную строку '\\x01' – выделено желтым, так и в TRUE – выделено зеленым.
Строго говоря, исправление 0x01 выполняется в несколько этапов, и на первом этапе у нас шли относительно простые преобразования.

Например, в подсвеченной подстроке, ориентируясь на контекст, можно смело преобразовать 0x01 в TRUE. Кстати, о том, что это за подсвеченный подзапрос: так выглядит дополнение отбора, накладываемое RLS.
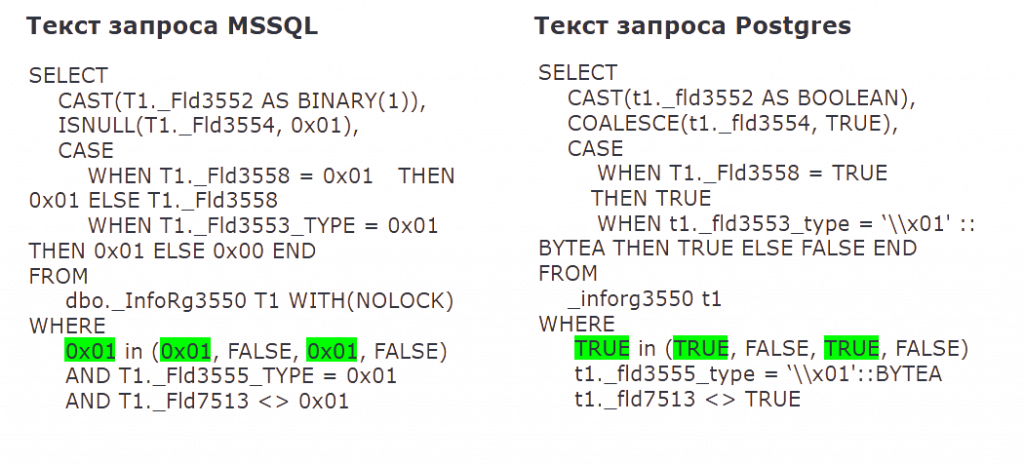
Можно ориентироваться на окончание поля — если поле заканчивается на _Type, то 0x01 конвертируется в BYTEA, иначе в TRUE. Нами было просмотрено более 40 таких простых ситуаций.
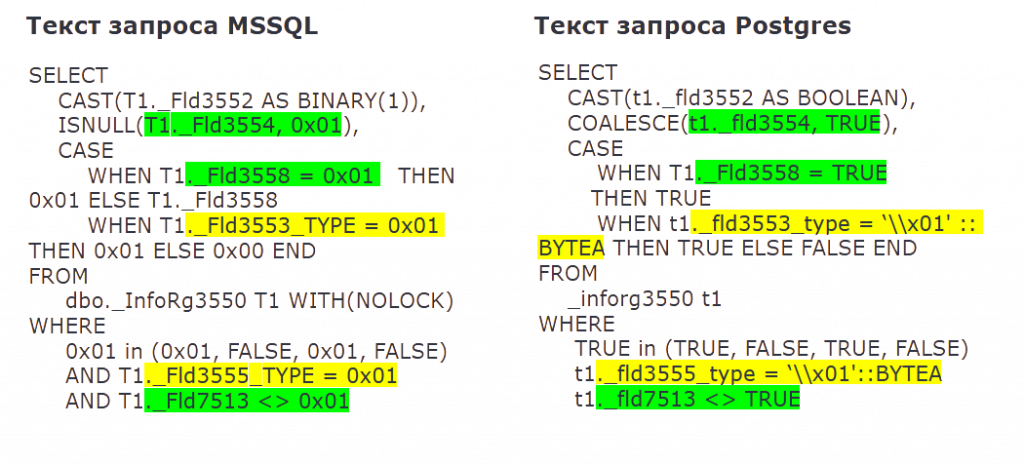
После выполнения всех этих простых преобразований, возможно, в запросе еще остались 0x01. Например, 0x01 идет после UNION, когда мы не можем ориентироваться на имя поля в нижнем подзапросе.
Кроме того, еще не было выполнено преобразование TOP в LIMIT. Если в Microsoft SQL TOP расположен в начале запроса, то в Postgres LIMIT идет в конце. Для простых запросов это не проблема, но если ограничение выборки накладывается на вложенный подзапрос — место для LIMIT найти сложно.
Для этих целей нами создан план запроса по аналогии со схемой запроса 1С — это фактически массив структур, составляющих запрос.

Если после всех преобразований в запросе остались 0x01, мы фиксируем ошибку преобразования. Также есть и другие ошибки автоматического преобразования — например, сложный TOP, когда ограничение выборки накладывается на подзапрос в условиях запроса. Эту ситуацию мы пока, к сожалению, не обрабатываем и подправим при доработке программы.
После автоматического преобразования можно исправить ошибки вручную. Для этого есть специальная команда.
Этап выполнения запросов на PostgreSQL
Мы преобразовали тексты запросов из Microsoft SQL в Postgres, исправили ошибки и перешли к выполнению запросов.
Для этого мы смигрировали базу в копию на Postgres, прописали настройки драйвера ODBC. Для каждого номера сеанса MS SQL делаем свое соединение с базой. При установке нового соединения выполняем запросы, которые 1С отправляет при установке соединения с СУБД.
На самом деле отдельных соединений можно и не делать. Потому что разбивку по сеансам – пулам соединений –Postgres выполняет самостоятельно, и нарушается уникальность имен временных таблиц, взятая из MSSQL в рамках сеансов Postgres. Для исключения этой ошибки в имя таблицы через нижнее подчеркивание добавляем номер сеанса. Например, таблица #tt10 из сеанса 87 преобразуется в tt10_87.
Перед отправкой каждого запроса на выполнение устанавливаем параметр statement_timeout, равный произведению длительности запроса на MS SQL и коэффициента длительности, назначенным ранее в настройках. Это позволяет исключить зависание при выполнении неоптимальных запросов.

Для контроля правильности выполнения фиксируется количество строк и сравнивается с количеством строк из логов MS SQL. Также приходится контролировать время жизни временных таблиц — при потере соединения временные таблицы могут создаваться заново с теми же номерами. Это нужно это учитывать – держать кэш созданных временных таблиц, и если текущий запрос – это создание ВТ, а временная таблица с таким номером на таком сеансе уже создана, то ее нужно «дропнуть» перед новым созданием.
Основные ошибки при выполнении вызваны некорректной трансформацией запросов и постепенно исправляются. Если же выполнение запроса прервано по таймауту, который мы задали сами, то выполняется повторный запрос для снятия предварительного плана запроса на Postgres. Для этого добавляем конструкцию EXPLANE в начало запроса.
Результаты тестирования на реальных базах
С помощью автотестов нами уже обработано пять баз. Пилотной базой была ERP — тут мы снимали расширенные события вообще без фильтров. Было снято больше 25 млн записей, после очистки осталось чуть больше 10 млн. На эту базу приходится самый большой процент ошибок преобразования — почти 19%.
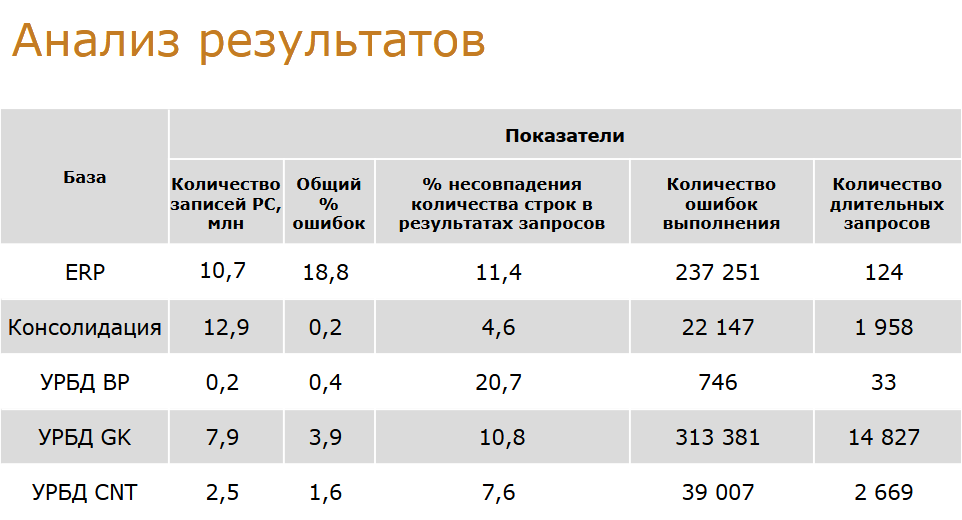
Ошибок при выполнении больше 200 000, ошибок преобразования 0x01 больше 34 000, сложных TOP — больше 7 000. Большинство ошибок было исправлено при исследовании других баз. Но даже здесь мы нашли 124 длительных запроса.
Следующая исследованная база — консолидация. Здесь сбор логов выполнялся трое суток. Ошибок уже очень мало, но обнаружилось около 2 000 длительных запросов.
Проблема в том, что конфигурация консолидации сильно изменена — исходного кода по функционалу осталось примерно 20%. Основная проблема в сложных запросах — гигантские конструкции с большим количеством JOIN, в том числе с виртуальными таблицами.
Также мы столкнулись с проблемами запуска параллелизма на Postgres и выбором неоптимального плана выполнения. Было оптимизировано более 500 запросов. Консолидация успешно переведена на Postgres три недели назад.
Следующими базами были три базы URBD. Они следующие на очереди на перевод. Здесь мы пока только сняли логи — времени на анализ не было, все силы ушли на консолидацию.
Но предварительный анализ уже можно дать. В глаза бросается большой процент несовпадения количества строк в результатах запросов. По URBD ГК очень много длительных запросов, что объясняется спецификой работы — огромное количество повторяющихся запросов.
Мы сделали механизм группировки текстов запросов по хэшу основных таблиц, и в результате 15 000 запросов вылились в несколько десятков уникальных.
Выводы
У нас на сегодня используется 64 информационных системы на базе 1С. Процесс перехода на Postgres уже начат, и все они в конечном счете будут переведены.
Разработанный нами инструмент, несмотря на несовершенство, уже используется и позволяет сделать переход менее болезненным. Без дополнительных трудозатрат мы можем определить запросы, которые следует оптимизировать.
Мы выложили программу в открытый доступ и надеемся, что общими усилиями ее доработаем. Что предполагается доработать:
-
Расширение плана запросов. Имеется ввиду добавить в плане запроса выделение запросов в условиях и соединениях, которые могут быть там, а в них могут быть и юнионы, и отдельно стоящие 0x01, и ограничения выборки TOP. Это позволит значительно сократить оставшиеся ошибки 0x01 и TOP.
-
Контроль безошибочности наполнения временных таблиц. Поясню: начало цикла использования ВТ – это ее опустошение либо создание. Далее идет запрос наполнения – и мы его не смогли трансформировать и не исправили вручную после завершения Этапа Создания ВТ, или была ошибка при выполнении запроса. В этом случае любой запрос, в котором используется эта ВТ, до ее следующего опустошения будет давать некорректный результат при его выполнении. Получается, чтобы быть уверенным в правильности выполнения запроса, следует рекурсивно определить все используемые в этом запросе ВТ и проверить, чтобы в их наполнении не было ошибок. Кроме того, данный подход поможет корректно отправлять на выполнение отдельные запросы из формы справочника.
-
Исправление ошибки для сложных конструкция case…end, когда одни кейсы входят в другие. Нужно рассматривать только данные конструкций then|else, которые относятся именно к текущему уровню then 0x01|else 0x01.
-
Исправление преобразования cast(null as binary(1). Они могут встречаться в отдельных подзапросах через UNION, причем это может быть либо вставка в ВТ, либо обычный селект. Если вставка в ВТ, то тип можно определить по имени поля либо использовать план запроса.
-
Исправление ошибки разбора строковых параметров в запросах rpc_completed.
-
Добавление реквизита настройки «Процент превышения» и ошибки выполнения.
Скачать программу можно по ссылке.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт