1. Невнимательность: Следствие или причина?
Классическая, но критичная причина ошибок на всех этапах (написание ТЗ, разработка, тестирование): пропущенные запятые в запросах, вызовы функций не в том месте, упущенные детали. Часто невнимательность – лишь следствие других проблем: срочные запросы от продакт-менеджера по предыдущим задачам сбивают фокус, плохо структурированные ТЗ. Ключевые требования "теряются" среди скриншотов или не имеют четкой нумерации (отсутствие трассируемости). Например:
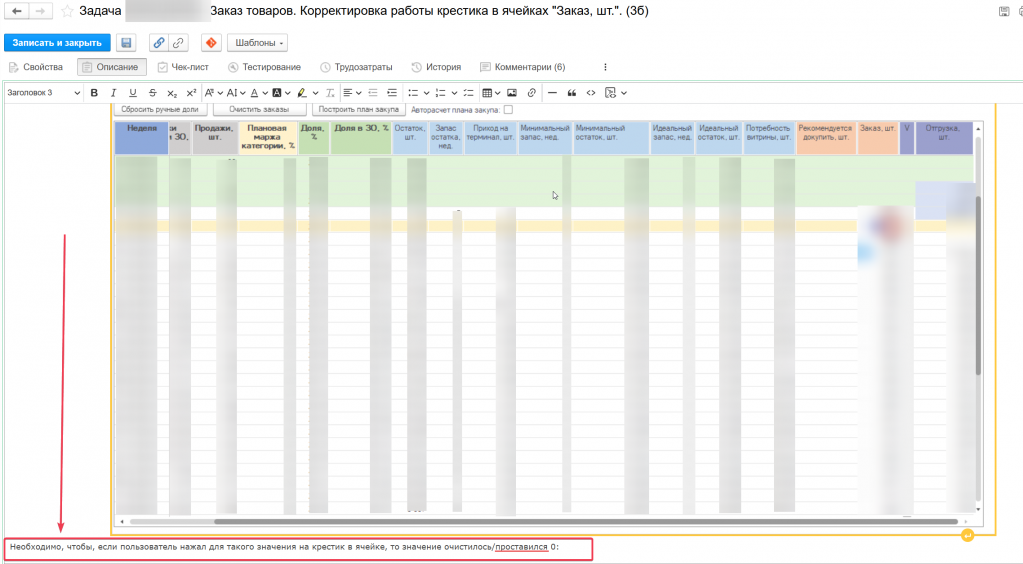
В ТЗ, для примера, показан скриншот с тем, как должно работать, и сразу же снизу после него требование, которое никак не пронумеровано и просто теряется, так как сразу после него идёт такой же большой скриншот, многие люди обратят внимание исключительно на скриншоты и упустят эту маленькую строчку текста.
Варианты решения:
- Ревью требований (Requirement Review): перед стартом разработки программист изучает ТЗ и дает обратную связь: понятна ли задача, есть ли неясности. Это проясняет нюансы до написания кода.
- Четкая структура ТЗ: обязательная нумерация требований, визуальное выделение, отдельные разделы для функциональных и нефункциональных требований. Трассируемость – ключ!
- Четкие критерии приемки (Acceptance Criteria): конкретный список условий, при которых задача считается выполненной. Фокусирует и разработчика, и тестировщика на ожидаемом результате.
2. Слепое копирование кода (Copy/Paste): Опасное удобство
Эту причину также можно отнести к невнимательности, но хотелось бы выделить отдельно. Механическое копирование кода – частый источник ошибок. Программист копирует фрагмент, адаптирует его под текущую задачу, но:
- Не адаптирует контекст: скопированный код может зависеть от переменных или условий, отсутствующих в новом месте.
- Не обновляет зависимости: не вносятся необходимые изменения в связанные объекты или параметры.
- Размножает ошибки: если в исходном фрагменте была ошибка, она тиражируется.
- Усложняет поддержку: появляются многочисленные почти идентичные, но слегка отличающиеся фрагменты кода, что затрудняет поиск ошибок и внесение глобальных изменений.
Варианты решения:
- Принцип DRY (Don't Repeat Yourself): вынесения повторяющейся логики в общие модули, процедуры/функции или обработчики команд. Переиспользование через вызов, а не копирование.
- Внимательный рефакторинг: при необходимости копирования – тщательный анализ всего контекста: какие переменные используются, от каких условий зависит, какие объекты задействованы. Полная адаптация к новому месту.
- Code Review: и в очередной раз ревью – ключевой инструмент для выявления необоснованного копирования, "клонов" и потенциальных проблем контекста.
- Статические анализаторы кода: использование инструментов способных выявлять дублирование кода.
3. Незнание функционала и бизнес-процессов
Ошибки возникают не только у новичков. Даже опытные программисты, отлично понимая техническую реализацию ("под капотом"), могут плохо представлять, как функционал используется в реальных бизнес-процессах. Это приводит к:
* Побочным эффектам - изменения непреднамеренно затрагивают смежные или зависимые процессы, запуская цикл "разработка-тестирование-доработка".
* Локальным изменениям - доработка функции в одном месте ломает ее в других, о которых разработчик не знал или не учел. Например, у нас есть форма, которая вызывается в 3х разных документах:

Казалось бы, логично, что, изменив саму форму, мы изменим её во всех местах, но на практике это оказывается не так, и при тестировании мы узнаём, что одна форма открывается как надо, а другие при открытии выдают ошибку.
Варианты решения:
- Обязательные бизнес-аттестации: разработчики изучают пользовательскую/техническую документацию и проходят аттестацию на знание ключевых бизнес-процессов компании и работы инструментов с точки зрения пользователя. Вопросы готовят бизнес-аналитики или опытные пользователи.
Результат:
- Программисты начинают лучше понимать контекст использования. Это позволяет им предвидеть потенциальные точки сбоя при изменениях.
- Осознанно вносить доработки во все необходимые места, даже если это не явно указано в ТЗ.
- Эффективнее коммуницировать с тестировщиками и аналитиками.
Знание процессов значительно сокращает появление ошибок, а также уменьшает так называемый «Бас фактор», ведь если даже программист не работал с функционалом, при знании процесса он может примерно представлять как работают те или иные функции.
4. Некорректные тестовые данные
Качество тестирования напрямую зависит от качества данных. В тестовых средах разработчиков данные часто:
- Устарели (не синхронизированы с основной БД).
- "Битые" (содержат ошибки, нерелевантны).
- Неполные/нерепрезентативные (не покрывают все сценарии, особенно граничные).
- Созданы вручную под конкретную задачу, не отражая реальной сложности.
- Причина может быть частично связана с пунктом 3 – без знания процессов сложно подобрать корректные данные. Тестирование на устаревших или "искусственных" данных не гарантирует корректной работы в рабочей среде с актуальными объемами.
Варианты решения:
- Регулярные срезы ЦБ (Центральной Базы): настройка процесса автоматического или полуавтоматического создания актуальных срезов рабочей БД для тестовых сред. Это дает более релевантную картину. Более подробно об этом рассказывает мой коллега в своей статье.
- Проблема актуальности: для задач, требующих самых свежих данных (например, за вчера), срезы не всегда помогают, поэтому приходится использовать такие механизмы как:
- Аккуратная ручная загрузка: выборочное обновление критичных данных в тестовых средах.
- Тестовые полигоны в рабочей базе (крайняя мера!): создание изолированных областей в основной базе для тестирования только при невозможности других вариантов, с высочайшей осторожностью и контролем.
5. Ошибки при помещении в хранилище
Наш процесс разработки включает локальные базы разработчиков, тестовые среды (часто с более репрезентативными данными) и основную рабочую базу. Ошибки возникают на финальном этапе – при помещении изменений в хранилище основной базы. Причины разнообразны: некорректный порядок строк кода (работавший в тесте, но не в проде), забытые объекты/роли, ошибки конфигурирования при помещении. Результат – "сюрпризы" для пользователей после обновления.
Варианты решения:
- Поэтапное внедрение Git. Вместо недостижимого пока CI/CD можно начать с внедрения Git. Это не панацея, но сильно снизит риски именно на этапе интеграции изменений в основную конфигурацию, также это шаг к внедрению CI/CD.
- Обязательный Code Review перед помещением в хранилище. Проводится после тестирования, когда логика зафиксирована. Цель – выявить очевидные ошибки конфигурации, пропущенные объекты, проблемы с правами. Ревью значительно снижает количество "заливных" ошибок.
Заключение:
Постоянная борьба с ошибками в 1С требует системного подхода. Ключевые направления улучшений:
- Контроль версий как фундамент: поэтапное внедрение Git для управления изменениями конфигурации, обеспечения истории, прозрачности и безопасного слияния правок. Это база для будущей автоматизации.
- Контроль качества на всех этапах: ревью требований, Code Review, четкие критерии приемки.
- Глубокое знание предметной области: бизнес-аттестации для разработчиков.
- Повышение культуры разработки: следование принципам DRY, осознанное использование копирования, постоянное обучение.
Внедрение даже части этих мер в вашем процессе разработки 1С позволит значительно повысить качество кода, снизить количество ошибок, проходящих в рабочую базу, и сэкономить время разработчиков, тестировщиков и пользователей.
А также про ручное тестирование в 1C и какой путь оно прошло в нашей команде, вы можете послушать в моём докладе, который я готовлю к INFOSTART TECH EVENT 2025. Проголосовать и тем самым поддержать автора, можно тут: https://event.infostart.ru/2025/agenda/2443352/
Вступайте в нашу телеграмм-группу Инфостарт