Меня зовут Александр Свойкин, я руковожу группой программистов в компании «ДНС Технологии».
О чем эта статья:
-
Об упрощении обмена данными с помощью Kafka, инструментарии и простоте таких решений.
-
Об использовании Kafka в ETL-процессах. ETL-процессы – это процессы Extract, Transform, Load (извлечение, трансформация, загрузка). Сейчас ими обычно занимаются специальные люди, которых называют дата-инженерами, но по факту мы, как 1С-ники, давно работаем с этими процессами. У нас много лет существует такая замечательная конфигурация, как «Конвертация 2», где всегда были эти процессы, поэтому мы еще и дата-инженеры.
-
О производительности Kafka. Kafka обеспечивает такую производительность, которую не обеспечивает ни один из существующих инструментов – ни RabbitMQ, ни одна из шин данных.
Статья практическая, поэтому будем углубляться в детали и подниматься в специфику. Сначала поговорим о Kafka.
На сайте Kafka написано, что это не просто брокер сообщений, а нервная система предприятия. Многие используют ее как брокер, но это только 10% функционала от Kafka. Потому что в Kafka, помимо самого механизма брокера сообщений, есть возможности KSQL – это язык наподобие SQL, который позволяет работать с потоками данных и получать данные в реальном времени. Также существует Kafka Connect – это механизм интеграции с различными источниками данных. И Kafka streams – инструмент для процесса трансформации в ETL.
Также есть Kafka Shema registry. Но об этом мы говорить не будем, потому что это выходит за рамки статьи.
Немного поговорим про Compact-топики, потому что они являются одной из интересных особенностей Kafka, которую можно использовать в 1С. И затронем вопросы надежности и высокой нагрузки (High Load).
Пример использования: WMS и Greenplum, введение в CDC
Сразу перейдем к примерам. У нас есть WMS-система, в ней 26 РИБ баз данных. И как вы понимаете, WMS-система – это система, в которой данные должны летать без проблем, по факту OLTP-система.
Минимальная задержка необходима, потому что сотрудники собирают складские заявки с помощью TSD, и они не должны испытывать никаких проблем, когда менеджеры запускают отчеты. Естественно, базы данных большие – терабайтные, двухтерабайтные и так далее.
Таким образом, у нас есть OLTP-система и задача с отчетами. Несколько лет назад было принято решение перенести всю аналитику в Greenplum. А так как мы всегда сталкиваемся с проблемой нехватки разработчиков для таких задач, в качестве альтернативы был предложен механизм CDC.
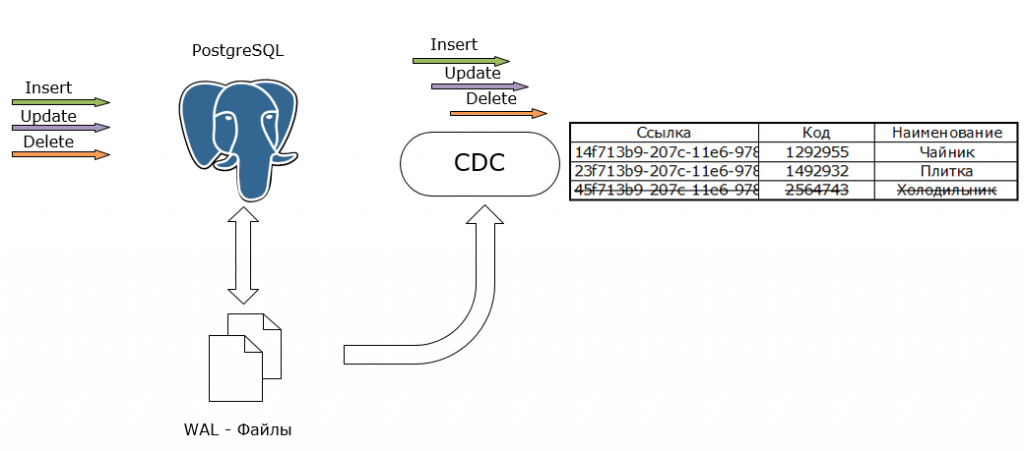
CDC расшифровывается как Change Data Capture, по сути это сбор данных об изменениях.
В случае с Postgres изменения не записываются сразу в Postgres, а проходят через WAL-файл, где и фиксируются. Изменения бывают трех видов: Insert, Update, Delete. Несмотря на то, что мы работаем с объектными сущностями в 1С, это никак не отменяет того факта, что в PostgreSQL все сводится к этим трем инструкциям.
Итак, данные сначала помещаются в WAL-файлы. WAL-файл, как вы прекрасно знаете, переводится как Write-Ahead Log – журнал упреждающей записи.
Как работает WAL (Write-Ahead Log) и механизм CDC
Механизм CDC подразумевает, что мы будем брать данные из WAL-файлов. У вас может возникнуть вопрос: «А что с лицензионной политикой?» В базу данных мы не лезем. Мы собираем данные из WAL-файла и забираем эти операции, которые могут выглядеть в 1С примерно так, как указано на рисунке.
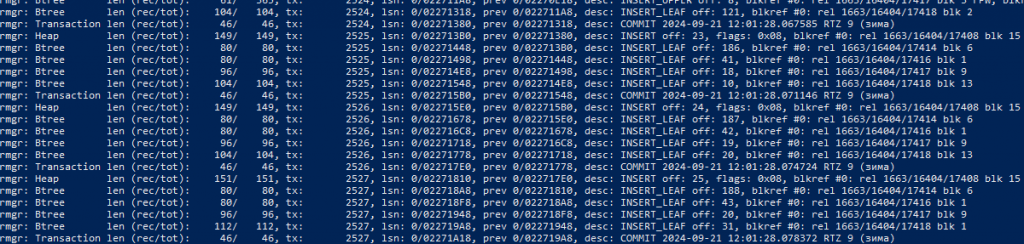
WAL-файл представляет собой просто журнал, в котором содержатся записи об изменениях. Можно сказать, что у нас есть журналы, и мы можем просматривать их с помощью специальных утилит, входящих в дистрибутив PostgreSQL.
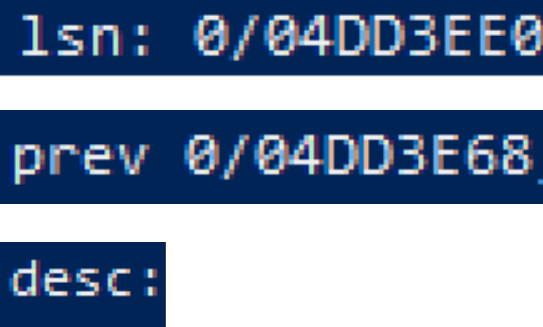
Нас интересуют три поля записи: LSN, PREV и DESC.
LSN – это Log Sequence Number. Это указатель на запись в журнале. Любая операция записывается в журнал WAL, и в этой же строке содержится указание на предыдущую запись. Также есть сама запись с данными об операции. Таким образом, позиционировавшись на строке в WAL-файле, мы можем увидеть, что было изменено в текущей записи и что было изменено в предыдущей.
Архитектура решения и пример транзакций
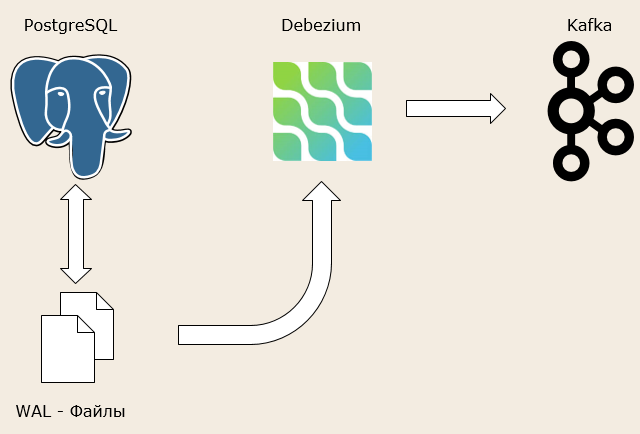
У нас есть PostgreSQL и WAL-файлы. Специальное ПО Debezium забирает данные из WAL-файлов и кладет их в Kafka.
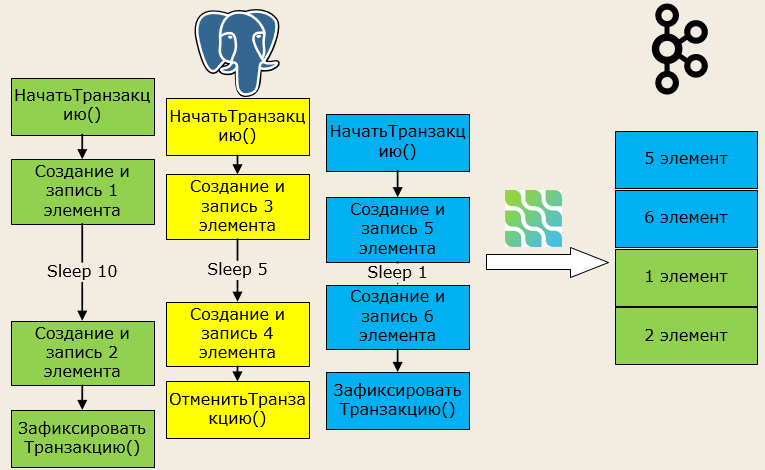
Теперь переложим это на язык 1С. У нас есть три параллельно запущенных транзакции. Первая транзакция обозначена зеленым цветом, вторая – желтым и третья – синим. Они начинаются по порядку и почти одновременно – вначале зеленая, желтая и синяя. Особенность желтой транзакции в том, что идет запись, а затем транзакция отменяется. У первой транзакции между созданием элементов будет Sleep 10, у второй Sleep 5, у третьей Sleep 1. Это значит, что вначале зафиксируется третья транзакция, потом отменится вторая, и только затем зафиксируется первая.
Желтые данные не попадут в Kafka с помощью Debezium , потому что мы отменили транзакцию. И обратите внимание на последовательность записи. В Kafka первой окажется транзакция, завершенная первой.
Чтобы все это запустить, нам достаточно REST-интерфейса в Debezium. Мы устанавливаем Debezium и начинаем его настраивать. По факту мы отправляем, например, с помощью Postman запрос в Debezium с определенными параметрами.
Настройка Debezium и формат сообщений
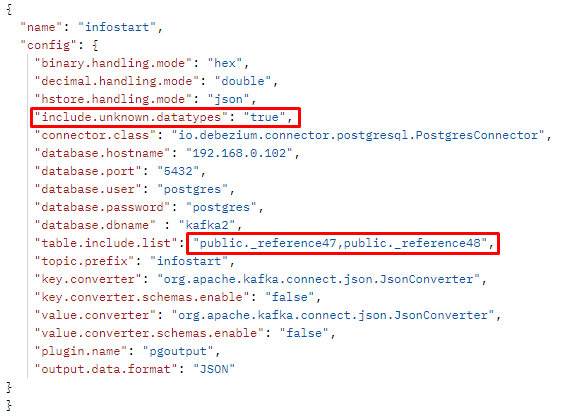
Нам нужно указать, какие данные нужно читать. Здесь указаны конкретные таблицы, потому что существует множество системных таблиц, которые нам могут быть не нужны. И есть еще одна опция сверху – include.unknown.datatypes. Пожалуйста, держите ее в уме.
После того, как мы отправим эту команду через REST-интерфейс, мы сможем получать сообщения в Kafka. И сообщение выглядит следующим образом.
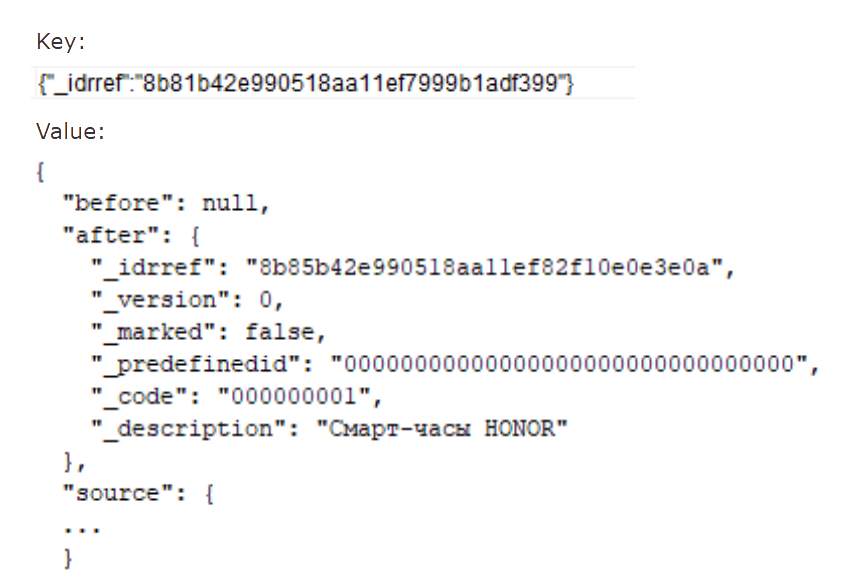
Ключом у него будет GUID, потому что Debezium прекрасно это понимает. А само значение представлено в формате JSON, потому что мы указали, что данные должны передаваться в этом формате. Получается, здесь нам нужен JSON, чтобы в принципе понять, что происходит, ведь его легко прочитать.
Мы видим, что в ключе находится GUID, а в значении – то, что было изменено. В данном случае была операция вставки, потому что в секции before, если вы заметили, ничего нет – null и auto – вот это описание. В данном случае товар – смарт-часы Honor.
Что нужно помнить, чтобы все это запустить? У нас есть PostgreSQL, мы устанавливаем какое-то ПО, и у нас все начинает работать. Так вот, ПО в нашем случае – это Docker-контейнер, который уже включает в себя и Kafka, и Kafka Connect, и сам Debezium.
Технические детали и требования к PostgreSQL
Debezium – это не самостоятельный продукт, который просто откуда-то появился. Он использует механизм Kafka Connect, о котором мы уже говорили. Debezium, используя Kafka Connect, вычитывает данные и кладет их в Kafka. Это механизм, предоставляемый непосредственно Kafka.
При работе нам нужно помнить о том, что:
WAL должен быть logical. Напомню, что write-ahead log (WAL) в настройках postgresql.conf может иметь четыре варианта: от minimal до logical. Уровень logical – это максимальный уровень настройки WAL-файла. Именно на уровне WAL настраиваются репликация и другие функции. То есть это обязательное требование для работы CDC.
Также необходимо знать и понимать, что вы загружаете в Kafka, и управлять размером сообщений. Возможно, у кого-то из вас возник вопрос: как же так? Ведь у Kafka ограничение на размер сообщения – 1 мегабайт. Мы пользуемся этим решением уже более четырех лет, и хочу сказать, что у нас есть таблицы, в которых размер сообщения может достигать 200 мегабайт. Для этого необходимо выполнить настройку как со стороны брокера, так и со стороны топика. О производительности при работе с большими и маленькими сообщениями в Kafka мы поговорим позже. Kafka на самом деле не ограничена 1 мегабайтом – мы можем изменить этот параметр.
Однако, если вы начинаете загружать сообщения размером по 2 гигабайта, вы должны понимать, что можете упереться в ограничения JVM и столкнуться с проблемами.
Старайтесь избегать больших транзакций. Мы видели на примере желтой и зеленой транзакции, что они могут быть длительными. В данном случае я демонстрировал пример с длительностью в 10 секунд.
Debezium хранит данные в буфере. То есть он считывает данные, но не записывает их в Kafka до тех пор, пока транзакция не завершена. А в этом кроется проблема. Потому что есть интересный нюанс в работе со стороны PostgreSQL. Со стороны PostgreSQL существует такое понятие, как слот репликации. Когда мы отправляем сигнал в Debezium, указывая ему таблицы, подключение и другие параметры, автоматически создается слот репликации. Это такой механизм в Postgres, который указывает: «Postgres, пожалуйста, не удаляй WAL-файл как раз до этой позиции (LSN)».
Получается следующая ситуация: у нас может быть большая транзакция. Debezium сообщает: «Я еще не прочитал», и WAL-файл начинает разрастаться. Поэтому большая транзакция – это плохо с той точки зрения, что Debezium начинает накапливать огромный буфер, WAL-файл не удаляется и не очищается, и в этом кроется проблема. Слот репликации – это, по сути, подсказка для Postgres, до какого момента можно удалять данные.
Помните, я выделял красным строку? Это был параметр include.unknown.datatypes. У нас в PostgreSQL есть два специфических типа данных: mvarchar и mchar. Это типы данных для совместимости с MS SQL. Наши операции сравнения со строками должны работать так же, как и в MS SQL. Но Debezium, как зарубежное решение, ничего не знает о так называемых кастомизированных типах данных, используемых в нашей системе. Поэтому нам эти типы данных нужно либо отдельно обрабатывать, написав плагины для Debezium, либо просто активировать опцию include.unknown.datatypes.
Использование Kafka Streams для трансформации данных
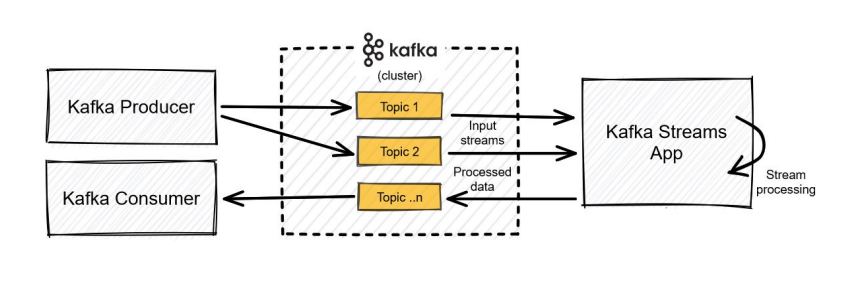
Теперь поговорим про механизм Kafka, который в ETL обозначается буквой T – transform.
Он не очень популярный, но его можно очень легко использовать в 1С. Мы записываем данные в топик. Когда данные находятся в топике, их можно обрабатывать на стороне 1С, выполняя какие-то действия, а можно непосредственно внутри самой Kafka. Это будет работать в разы быстрее.
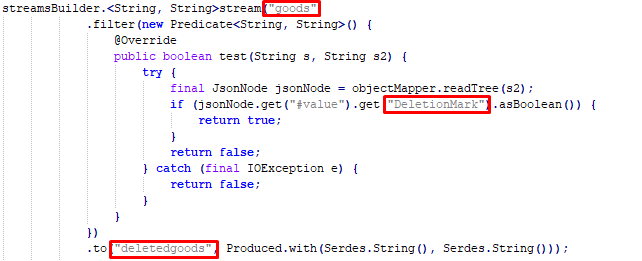
Здесь немного кода на Java, его общий смысл следующий: мы берем данные из одного топика, как-то их фильтруем и кладем в другой топик. Здесь мы отслеживаем пометку удаления. Если у нас есть проблема с какими-то критичными данными, которые не должны удаляться, но почему-то удаляются, мы должны где-то фиксировать информацию об этом. Kafka Streams идеально подходит для этой задачи, потому что с помощью Debezium сообщения очень быстро попадают в Kafka, затем мгновенно фильтруются и перенаправляются в другие топики.
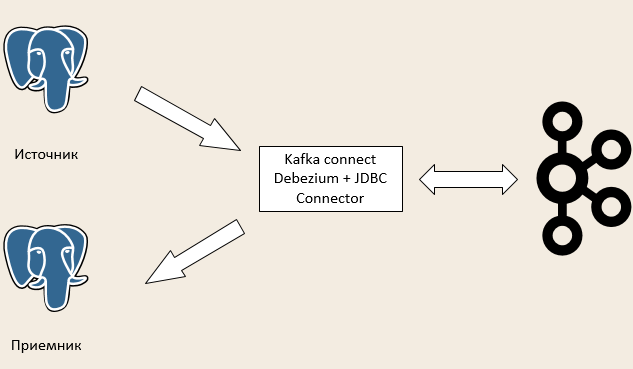
Если мы можем отправлять данные в Kafka, мы можем и получать их обратно. Для этого подойдет другой инструмент – Kafka Connect.
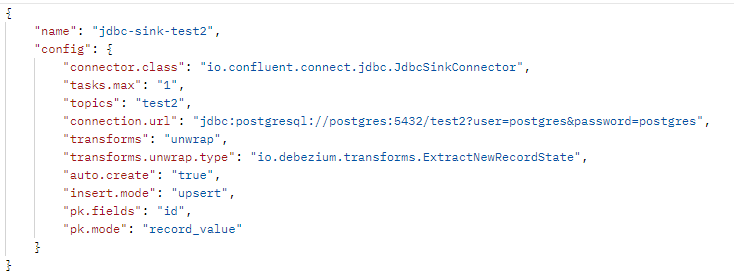
Для этого нам нужно сообщить Kafka, используя JDBC Sink Connector, из каких топиков забирать данные и куда их сохранять. Здесь интересным моментом является указание префикса топиков, с которыми этот инструмент будет работать.
Но это не подойдет для баз 1С, потому что в 1С мы не должны изменять данные не средствами 1С. Поэтому в данном случае пример скорее гипотетический – он подходит, если у вас есть данные, которые нужно куда-то сохранять вне 1С.
Компакт топики и их применение в обменах 1С
Теперь перейдем к другому механизму – механизму compact-топиков. Например, у нас есть план обмена, где фиксируется номер отправленного. Если мы один раз перезапишем ту же номенклатуру, номер отправленного всегда будет null. Потому что нет смысла каждый раз хранить все изменения.
В Kafka есть механизм, который позволяет объединить записи с одинаковыми ключами, оставляя только последнее значение. Этот механизм называется compact-топики. Compact-топики по определенному алгоритму просматривают дубли ключей в топике и объединяют их.
Нюанс в том, что это работает гораздо быстрее, чем те же планы обмена. У Kafka сложность поиска O(1). А даже в индексированной таблице сложность O(log n) по основанию 2. В любом случае по скорости Kafka не сравнится с традиционными решениями. Таким образом у нас есть возможность, настраивая топик с типом compact, добиться того, чтобы вся информация о необходимых ключах для обменов хранилась в Kafka.
Как вы понимаете, для нас важно самое последнее сообщение с максимальным смещением (оффсетом), сохранение которого Kafka и обеспечивает.
Производительность Kafka
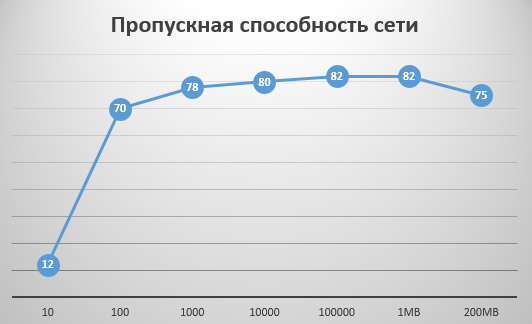
Поговорим о производительности. У Kafka есть особенность: она неэффективно работает с маленькими сообщениями. При работе с маленькими сообщениями вы начинаете упираться не в пропускную способность сети, а в процессор, диск или другие ресурсы, только не в сеть. Когда размер сообщения начинает расти, максимальная эффективность достигается при размере около 1 мегабайта. То есть сообщение размером 1 мегабайт начинает загружать сеть примерно на 82%. Мы проводили замеры.
Здесь речь идет о Kafka без кластера – она работает в единственном экземпляре с 10-гигабитной сетью. Из этого можно сделать вывод, что пропускная способность составляет примерно 1 терабайт за 17 минут. Это довольно неплохая скорость.
Мониторинг решения
Раз мы внедряем этот механизм, нам необходимо его мониторить, поскольку могут возникнуть различные проблемы. Нам важны следующие метрики:
-
Лаг репликации,
-
Свободное место на диске,
-
Длительные транзакции,
-
Размер базы данных.
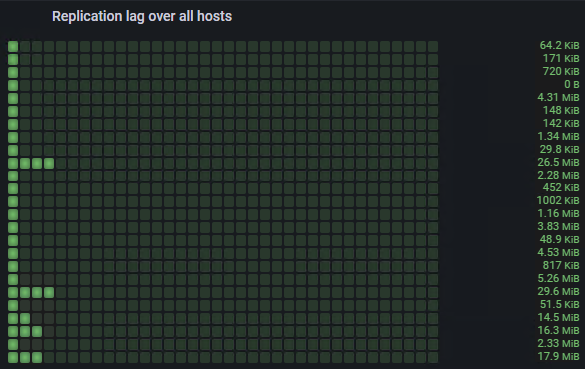
Что касается лага репликации, как вы понимаете, это задержка между моментом, когда изменение произошло в базе данных, и моментом, когда оно было захвачено и обработано Debezium.
Это важно, потому что если что-то идет не так, Debezium может перестать работать. Мы должны настроить алерты именно на эти показатели. Это самый главный параметр с точки зрения анализа.
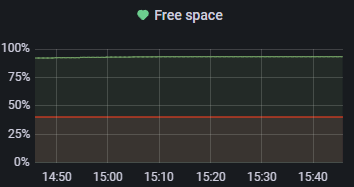
Конечно же, мы обязаны следить за свободным местом на диске. Если WAL-файл начинает разрастаться из-за слотов репликации, мы должны знать, что что-то идет не так.
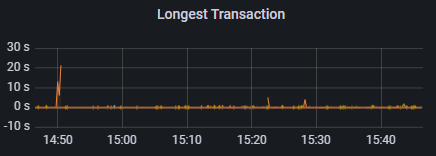
Длительные транзакции – чтобы можно было зайти в Grafana и посмотреть, что приводит к разрастанию WAL-файла и увеличению лага репликации. Основной причиной этого являются как раз длительные транзакции. В принципе, мы с этим и сталкивались.
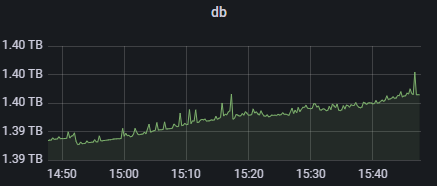
Размер базы данных. Если он начинает расти непропорционально, можно уточнить у коллег, что происходит. Возможно, идет какое-то новое заполнение данных. И, возможно, стоит временно отключить Debezium.
Проблемы и их решения
Конечно же, мы сталкиваемся с проблемой конвертации данных. Так как база самописная, у нас периодически происходят конвертации данных, которые могут нарушить работу механизмов CDC. В данном случае Debezium может отработать некорректно.
Что мы делаем в этом случае? Существует несколько сценариев. Один из них – просто отключить Debezium, очистить слот репликации и затем заново загрузить данные из таблицы. Это самый грубый способ, но тем не менее рабочий. Либо можно использовать механизм снэпшотов, который также доступен.
Также возникают проблемы при изменении структуры таблиц. Есть автоматическое изменение структуры таблиц, когда мы передаем схему, и Debezium может обработать структуру и добавить дополнительные колонки, а может и не обработать. В случае, когда система не справляется автоматически, то есть структура изменена вручную, нужно добавить изменения вручную и затем перезагрузить данные.
И, конечно же, долгие транзакции могут привести к катастрофическому росту WAL-файла до нереальных размеров. Debezium также может не справиться с обработкой таких данных.
Выводы и дальнейшие планы

Мы видим, что Kafka – это не молоток, а целый мультитул, в котором есть множество возможностей: Connect, Kafka Streams, Compact-топики, о которых мы говорили. Этим можно отлично пользоваться. Нельзя относиться к ней как к простому брокеру.
-
Определение, что это «нервная система предприятия» – самое удачное определение, которое только может быть.
-
В CDC мы видим простой и удобный механизм. По сути, это всего лишь вычитка из WAL-файла и запись данных в Kafka. Причем это делается буквально по щелчку пальцев с помощью одного контейнера.
-
Используя Kafka с 1С, мы видим такие особенности, как специфические типы данных 1С и неприятие длительных транзакций или частых изменений структуры данных.
Дальнейший план у нас следующий: мы планируем развивать использование Kafka в сообществе 1С, а также развивать конкретно Kafka Streams, потому что этот механизм интересный, но довольно слабо изученный и используемый в сообществе. И, конечно, будем делиться с вами результатами.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт