Я руковожу направлением развития финансово-хозяйственной деятельности Практики 1С в компании BIA Technologies. За этим сложным названием стоит простая идея: все проекты, прежде всего, перспективные проекты 1С, за исключением специфических решений в области MES и OPS систем по управлению производством, проходят через меня.
Одним из ключевых направлений нашей работы является нагрузочное тестирование и работа с производительностью. В среднем за год мы проводим около 50 собеседований с Заказчиками по вопросам аудитов производительности. В итоге выполняем не менее 10–15 аудитов ежегодно. За годы практики накопился значительный опыт, которым я хочу поделиться в этой статье.
На сегодняшний день у нас за плечами – более сотни аудитов. Мы не вели строгую статистику по каждому кейсу, но накопленный опыт позволяет делать выводы и сформулировать наблюдения, которые, возможно, покажутся и вам интересными. Итак, в начале остановлюсь на трех ключевых моментах.
-
Запрос со стороны Заказчиков в так называемом «предкорпоративном» сегменте, условно до водораздела ПРОФ/КОРП. Это широкий круг компаний, которые еще не перешли к использованию расширенных возможностей Технологической платформы.
-
Сам водораздел. Мы хорошо его знаем: 500 пользователей, работающих одновременно в одной информационной системе и 12 процессорных ядер. Это, скорее, маркетинговая граница, отражение лицензионной политики вендора. На практике с техническими ограничениями мы сталкиваемся гораздо раньше. Именно разница между маркетинговым и техническим водоразделом – важный момент, на котором я хотел бы остановиться отдельно.
-
Универсальность подхода. Мы выработали трансформационный подход, который позволяет не только эффективно решать вопросы производительности, но и оказывать влияние на представление Заказчиков о том, как целесообразно подходить к работе с нагрузкой и решению вопросов производительности.
Давайте начнем с определения. Что такое высоконагруженные системы? Это системы, в которых из-за неправильной настройки при выполнении машинных операций происходит большая нагрузка на определенные компоненты серверов.
Это определение кажется мне полезным, потому что подчеркивает две вещи. Во-первых, ключевыми словами здесь являются «неправильная настройка». Сама по себе Информационная система, особенно если к ней предъявляются повышенные требования по кастомизации, доступности или интерактивности, «автоматически» нормально работать не будет.
Во-вторых, условная граница, тот самый «водораздел» ПРОФ/КОРП, когда система становится высоконагруженной, на практике размыта.
На рисунке ниже я попытался совместить несколько сущностей, чтобы обозначить фокус и показать, что именно имею в виду, говоря о Трансформационном подходе к высоконагруженным системам.

Про разделение на ПРОФ/КОРП мы уже сказали: это данность от вендора. Фактически это маркетинговая веха, а не какой-то реальный барьер, который нужно преодолеть, чтобы перейти в категорию КОРП. Самого технического «барьера» в таком виде не существует – об этом мы еще поговорим подробнее.
Хочу обратить внимание на полоску внизу. Из нее вытекает идея выделения трех групп Заказчиков, у которых складывается принципиально разный подход к решению вопросов производительности:
-
Начальный уровень автоматизации,
-
Средний уровень автоматизации,
-
КОРП-уровень.
Начальный уровень автоматизации и требования к информационным системам
Важно уточнить: речь идет не о фактическом использовании информационных систем. Современный бизнес, даже с небольшим оборотом, изначально предъявляет высокие требования к автоматизации. Такие компании стремятся использовать и активно применяют информационные сервисы, предоставляемые в формате «система как услуга» (SaaS). Ответственность за их работу несет внешняя команда IT.
В этой модели закладываются две особенности:
-
Вопросы производительности снимаются с бизнеса, он сознательно уходит от их решения и перекладывает эту ответственность.
-
Они также не ложатся на внутреннюю IT-команду, которая могла бы представлять интересы бизнеса.
Именно с этой точки зрения можно говорить о начальном уровне автоматизации – здесь, как правило, не возникает каких-то уникальных требований и подход к решению вопросов производительности направлен на то, чтобы избежать или уклониться от необходимости их решения.
Средний уровень: кастомизация и рост нагрузки
Следующий уровень охватывает широкий спектр компаний, вплоть до формального «водораздела». Тренд всегда одинаков: бизнес начинает с коробочных прикладных решений, а затем постепенно движется по пути кастомизации, адаптации и доступности. При этом растет потребность в интерактивности: чем больше пользователей работает в системе, тем ближе она становится к категории высоконагруженных. Этот сценарий всегда повторяется.
Широкая часть спектра в этом сегменте до «водораздела» – это Заказчики, которые уже объективно сталкиваются с задачами производительности, но также все еще стараются их отложить. На это влияют два ключевых фактора:
-
Существенные бюджетные ограничения.
-
Стремление избежать прямого решения – компании предпочитают переложить вопросы нагрузки на подрядчиков или вовсе уйти от их проработки.
Корпоративный уровень: культура управления производительностью
И третья часть спектра – это КОРП-уровень в вопросах производительности. То есть те Заказчики, которые не просто решают вопросы производительности на регулярной основе, но у каждого из которых складывается свой регламент по решению этих вопросов и своя корпоративная культура.
Для каждой из трех групп Заказчиков я выделяю три блока вопросов:
-
Принципы подхода к решению проблем,
-
Подход к решению вопросов – это прежде всего текущие инциденты и SLA,
-
Принципы подхода в IT.
Если первые две вещи – это скорее реакция бизнеса и его представление о том, что допустимо, а что нет, то принципы подхода в IT формируют реакцию и представление IT-команды Заказчика.
Начальный уровень: установка и допуски
В начальной части спектра, как правило, нет выделенного бюджета на вопросы производительности. Заказчик стремится приобрести готовое прикладное решение «из коробки». И оно также по определению должно нормально работать! Бизнес действует исходя из простой установки – «будем решать проблемы по мере их поступления».
Подход декомпозиционный, планирования практически нет. Допуски в работе огромные:
-
стандартное время реакции IT-команды на инцидент может составлять 15–30 минут;
-
при этом вполне нормальным считается диапазон от 1,5–3 часов до суток или даже полутора дней простоя.
Около семи лет назад я работал IT-директором и отвечал за организацию службы поддержки сети розничных точек в Москве. SLA у меня предусматривал время реакции до полутора дней даже в самых критических случаях. Например, если выходил из строя фискальный регистратор на одной из точек, в течение трех часов нужно было заменить его на офисную кассу. Но если что-то шло не так, процесс устранения проблемы мог растянуться почти на два дня и это считалось допустимым.
Что касается принципов подхода в IT в данной части спектра, приведу еще один пример из своего опыта. В свое время я проходил курсы по ITIL и был поражен одной интерпретацией коуча. Он проводил очень четкую грань между Заказчиком и Пользователем. Эта грань действительно существует и заложена в самом подходе, но в его подаче она выглядела так:
-
Заказчика всегда слушаем внимательно, его требования учитываем и выполняем при проектировании и внедрении системы.
-
Пользователь же – это совершенно другое. Например, если бухгалтер месяцами вручную вводит в систему какие-то данные и при этом «плачет», это совершенно нормально, если бизнес считает, что так и должно быть.
Эргономичность и удобство с точки зрения работы пользователей далеко не всегда становятся приоритетом. В этой части спектра четко действует принцип Заказчик vs. Пользователь.
Средний уровень: появление планирования и адаптации
Если перейти ко второй и третьей части спектра, то рабочий подход постепенно меняется. Появляется и все больше прослеживается планирование. Теперь внимание сосредоточено на том, чтобы заранее предусмотреть известные риски и не допустить базовых провисаний в работе системы.
В части SLA допуски остаются значительными. Время первичной реакции может составлять 10–15 минут. Однако провисание системы в пределах 3–4 часов все еще считается допустимым.
Фактически SLA фиксирует несколько часов на устранение инцидента и это воспринимается, как нормальная практика.
На этом уровне IT-службы начинают:
-
выделять ключевых пользователей в каждой функциональной области,
-
ориентироваться на процессы и продуктовых владельцев,
-
учитывать их запросы и соответствующим образом адаптировать прикладные решения.
Запрос на повышение производительности формируется, но при этом чаще всего он редуцируется до решения уже известных проблем и «болей».
Корпоративный уровень: стоимость простоя и автоматизация
На корпоративном уровне рабочий подход принципиально иной. Здесь совершенно другие требования ко времени реакции и главный фактор, который его определяет – стоимость простоя.
В 2014 году консалтинговая компания Gartner оценивала минуту простоя крупной корпоративной сети в среднем в 5600 долл. США. Это означает, что час простоя обходился компании более чем в 300 тыс. долл. В том же году компания Avaya приводила диапазон от 2300 долл. до 9000 долл. за минуту простоя всей корпоративной сети.
Это, конечно, «средняя температура по больнице». У кого-то показатели выше, у кого-то наоборот. Однако именно они формируют представление о масштабе возможных потерь.
На этом уровне решение многих инцидентов уже автоматизировано:
-
известные типы проблем заранее классифицированы и имеют регламент обработки,
-
SLA устанавливается на уровне нескольких минут.
В каждой крупной компании со временем формируется собственная корпоративная культура решения вопросов производительности. В ее центре находится Регламент – система представлений о том, что допустимо, а что нет и как именно следует решать тот или иной вопрос.
Решение большинства типовых инцидентов автоматизировано. Для них существуют прописанные процессы и мы просто погружаемся в заранее предусмотренный сценарий решения. При этом время реакции и SLA могут различаться в зависимости от ситуации.
Иначе обстоит дело с новыми, масштабными проблемами. Здесь ключевая задача – не допустить их появления. Такие вопросы выносятся в бэклог и своевременно прорабатываются. Именно это становится определяющим моментом корпоративного уровня:
-
акцент делается не просто на планировании, но, прежде всего, на предотвращении, исключении вероятности возникновения крупных инцидентов,
-
используется комплексный профилактический подход, направленный на то, чтобы не выйти за рамки SLA там, где это особенно чувствительно для бизнеса.
Работа с Заказчиками до и после водораздела
Корпоративная часть спектра (за гранью ПРОФ/КОРП) интересует меня меньше, потому что с такими Заказчиками работать проще. Их вопросы очень фокусные и структурированные. Чаще всего им нужно просто проконсультироваться, услышать третью точку зрения или мнение коллег по кейсам, с которыми те уже неоднократно сталкивались.
Сложнее обстоит дело с частью спектра до корпоративного уровня. Здесь также возникают вопросы с производительностью, но экспертиза, да и просто готовность их решать есть не всегда. Например, я знаю два интернет-магазина, чьи обороты за три-четыре года выросли с нескольких сотен миллионов до более миллиарда руб. в год. При таких темпах роста попытки игнорировать вопросы производительности или продолжать использовать старые методы становятся источником серьезных проблем и дорогостоящих сбоев.
Универсальный трансформационный подход
Подход, который сложился у нас в плане решения вопросов производительности, мы называем Универсальным трансформационным подходом. Он строится на нашем опыте и тех услугах, которые мы предлагаем.
Аудит системы 1С
Работа начинается с аудита, который всегда ориентирован на какой-то конкретный запрос Заказчика. Мы начинаем с локализованных и понятных задач, что позволяет получить быстрый результат: пришли, оценили ситуацию, исправили критичные в работе моменты и двигаемся дальше.
Оптимизация производительности
То, что не удается решить во время аудита, переносится на этап оптимизации производительности. Вопросы могут попадать либо в бэклог разработки Заказчика, либо в наш собственный бэклог, в зависимости от того, как построено наше сотрудничество.
Моделирование нагрузки и нагрузочное тестирование
Это отдельная услуга, которая оказывается в двух направлениях:
-
Существующие проекты. Изменение текущих бизнес-процессов или внедрение новой функциональности (например, маркировка) часто создают потребность в моделировании нагрузки.
-
Новые системы. Если в системе будет работать большое количество пользователей, мы разрабатываем нагрузочные тесты, чтобы оценить, как она поведет себя при передаче в эксплуатацию.
Мониторинг, поддержка и эксплуатация
Подход, который начинается с принципа «пожар мы всегда успеем потушить», предполагает допуски, не совместимые с высоконагруженными системами.
Мы используем в работе систему мониторинга собственной разработки, но здесь рынок достаточно широк, существуют и open source продукты. Основное – это удобный интерфейс, настройка триггеров и оповещений, когда мы начинаем реагировать на ситуацию по метрикам, а не по данным, которые поступают нам от пользователей по факту.
Основная задача – чтобы каждый шаг был прозрачен и понятен: аудит, донастройка, моделирование нагрузки, мониторинг, техническая поддержка. Все эти блоки ясны сами по себе, но вместе они создают новое системное качество.
Каждый блок представляет самостоятельную бизнес-ценность. Например, установка системы мониторинга может быть отдельным запросом. Часто мы начинаем работу либо с мониторинга, либо с аудита, если, как уже отмечалось, требуется решить конкретные «боли».
При последовательной, пошаговой реализации данного подхода, появляется еще один уровень ценности:
-
мы решаем текущие проблемы и проводим санацию системы;
-
создаем удобный интерфейс для мониторинга высоконагруженных систем;
-
и, что особенно важно, и в чем и состоит Универсальный трансформационный подход:
-
влияем на подход Заказчика к решению вопросов производительности,
-
совместно создаем внутренние регламенты,
-
снимаем страхи и предубеждения, начиная с того, что это дорого или что нет и не будет экспертизы в этой области, поэтому не стоит и начинать, помогая избежать потенциальных проблем в будущем.
-
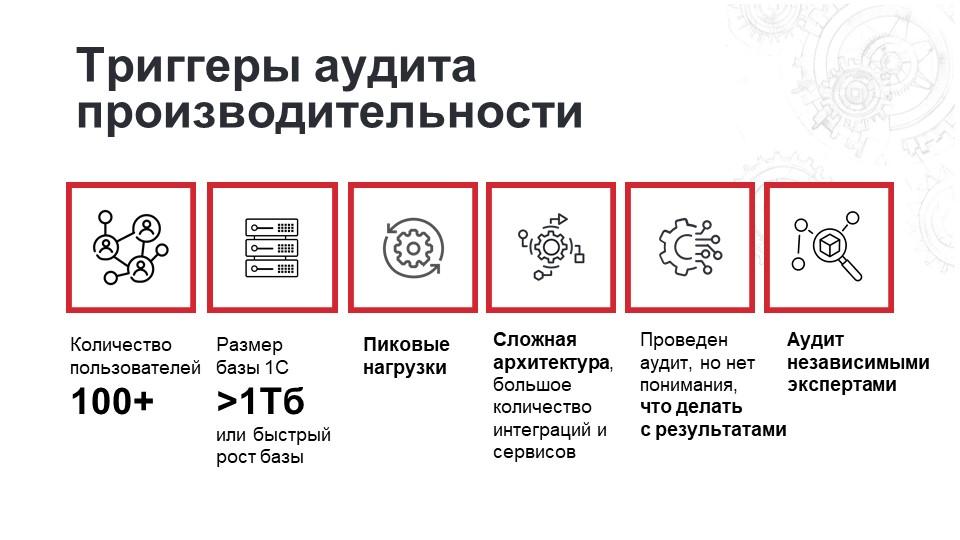
О запросе в «предкорпоративном» сегменте и о маркетинговой грани водораздела ПРОФ/КОРП мы уже достаточно детально поговорили. Сейчас предлагаю остановиться на триггерах аудита производительности, показанных на рисунке выше. Это ключевые причины, которые в комплексе заставляют компании заниматься решением вопросов производительности и нагрузки.
Количество пользователей
Если разбирать каждый фактор в отдельности, то все они довольно простые и понятные. Но чаще всего действует комплекс из нескольких факторов, который бывает непросто разлепить. Они действуют системно и технические границы чаще всего оказываются ниже порога, обозначенного вендором.
Когда стоит задумываться об аудите производительности, если речь идет о количестве одновременно работающих пользователей в информационной системе? Принимая решение о проведении аудита, обычно мы ориентируемся на цифру 100+ пользователей, что, возможно, в какой-то степени отражает технический водораздел.
При этом на практике самый дорогой аудит, который мы проводили, был связан с системой, где одновременно работало всего 20 пользователей. Основную нагрузку при этом генерировали роботы, в определенной последовательности запускавшиеся регламентные задания.
Размер базы 1С
Еще один условный параметр. Всем понятно, что он влияет на работу системы, но как именно, однозначно сказать трудно. Обычно мы обращаем внимание, если размер базы приближается к 1 терабайту или происходит быстрое увеличение размера базы 1С. Его воздействие, как и влияние предыдущего фактора, чаще всего проявляется в совокупности с другими факторами. Среди которых, пожалуй, ключевое место занимают пиковые нагрузки.
Пиковые нагрузки
Именно они превращают влияние отдельных факторов в системное.
Примеры типовых ситуаций:
-
закрытие кассовой смены в ритейле,
-
проведение маркетинговых акций, когда объем данных за несколько дней превышает месячные показатели,
-
синхронизация обмена данными в торговых сетях,
-
закрытие месяца в группах компаний или холдингах.
В такие моменты все начинает работать против Заказчика: количество пользователей, размер базы, качество кода. Именно поэтому на данном этапе оптимальная настройка системы становится критически важной.
Сложная архитектура
Следующий фактор – сложная архитектура, большое количество интеграций и сервисов. Основная сложность здесь состоит в том, что бывает не понятно, как спроектировать нагрузочное тестирование, направленное на тот или иной выделенный сегмент и как он влияет на производительность в целом.
У Заказчика нет понимания, что делать с результатами аудита
Нередко бывает, что аудит уже был проведен, но понимания, что делать с результатами, нет. Не возникает ощущения, что если выполнить все полученные рекомендации, то гарантированно будет результат, увеличится производительность ИС и проблемы уйдут.
Аудит независимыми экспертами
В таких случаях полезен независимый аудит. Третья точка зрения, позволяющая взглянуть на проблему со стороны. Аудит независимыми экспертами важен еще и потому, что решения в IT, особенно если речь идет о крупных развертываниях, всегда дорогостоящи и, так или иначе, связаны с серьезными затратами. Стоимость ошибки здесь гораздо выше, чем стоимость аудита. Что входит в первый этап Аудита производительности:
-
Обследование ИС,
-
Сбор и анализ логов технологического журнала,
-
Анализ настроек СУБД,
-
Сбор и анализ ресурсоемких запросов, ошибок СУБД,
-
Анализ запросов, их оптимизация,
-
Рекомендации по изменению архитектуры решения.
Основные разделы отчета по аудиту производительности:
-
Рекомендации по настройке серверов приложений,
-
Рекомендации по настройке серверов СУБД,
-
Список процессов с долгим выполнением кода,
-
Блокировки,
-
Сетевое взаимодействие серверов кластера между собой,
-
Топовые ошибки в работе баз данных.

В этом примере 24 782 ошибки связаны с определенным участком кода. Все достаточно наглядно. Наша задача локализовать проблему и представить результат так, чтобы Заказчик мог либо передать ее решение своей команде, либо решить ее с нашей помощью.
Как правило, в ходе аудита мы делаем несколько срезов. Сначала проводим анализ и устраняем какие-то наиболее очевидные ошибки. После чего предоставляем результаты повторно. Остаются уже более сложные и долгоиграющие вещи, которые выносятся на следующий этап.
Оптимизация производительности
Оптимизация производительности занимает разное количество времени. Основное, что здесь делается – также оптимизируются запросы, выполняются рекомендации по изменению архитектуры прикладных решений, производится установка оптимальных настроек и устраняются конфликты блокировок.
Далее следует этап моделирования нагрузки. Он включает:
-
Разработку сценария тестирования,
-
Доработку конфигурации запуска теста и сбора статистической информации,
-
Мониторинг работы теста и выявление точек роста,
-
Оптимизацию выявленных «узких» мест.
Если речь идет о решении конкретных «болей», моделирование нагрузки требуется не всегда. Но, если нужно ответить на какой-то содержательный вопрос, например: «При текущих темпах роста базы, сможем ли мы в конце года закрыть месяц без проблем?», такой вопрос уже может быть положен в основу полноценного сценария для разработки нагрузочного тестирования.
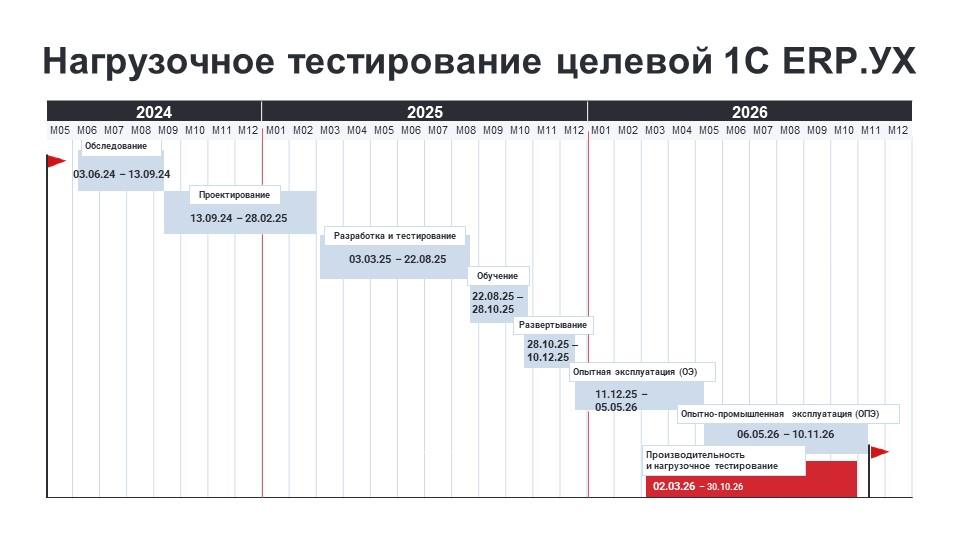
На слайде выше показан другой пример нагрузочного тестирования. Это обезличенный кейс внедрения целевой системы 1С:ERP.УХ. При проектировании предполагалось, что в системе должны одновременно работать более 4000 пользователей, и задача заключалась в том, чтобы проверить, как она будет себя вести в промышленной эксплуатации с учетом всех доработок и особенностей. Поэтому при подготовке к опытно-промышленной эксплуатации предполагалось разработать и провести специальные нагрузочные тесты.
Mониторинг
Этот этап включает в себя решение следующих задач:
-
Установка и настройка блоков мониторинга,
-
Настройка триггеров оповещений,
-
Регулярный контроль параметров производительности,
-
Разбор технологических проблем и их устранение,
-
Поддержка 24/7.
Как я уже сказал, принцип «пожар мы всегда успеем потушить» с высоконагруженными системами не работает. Здесь нужен удобный интерфейс, триггеры срабатывания, метрики. Нужно оперативно получать данные в удобном формате и реагировать на изменения, причем реакция должна быть моментальная.
Резюмирую. Универсальный трансформационный подход направлен на выработку эффективного подхода к решению вопросов производительности у Заказчика. И состоит из четырех понятных блоков:
-
Аудит 1С-систем. В среднем занимает около полутора месяцев. Самый быстрый аудит, который мы проводили, занял всего две недели.
-
Оптимизация производительности. Может выполняться параллельно с другими этапами и длится по-разному, в зависимости от выявленных проблем.
-
Моделирование нагрузки и нагрузочное тестирование. Отдельный блок, который может выполняться как параллельно с другими работами, так и самостоятельно.
-
Мониторинг, поддержка и эксплуатация. Развертывание системы мониторинга в среднем занимает около месяца (иногда дольше при глубокой настройке).
Таким образом, уже за 1–1,5 месяца можно полностью изменить и перестроить работу с высоконагруженными системами. Поэтому мы называем такой подход Универсальным трансформационным.
Мне показалось, что наш опыт может быть полезен для других еще и потому, что здесь есть каверза в запросах, которые возникают в той части спектра, где Заказчик не готов выделять средства на решение вопросов производительности. Часто там нет и кадровой основы, ведь подобные задачи требуют экспертов по технологическим вопросам. Но самое главное – отсутствует нацеленность бизнеса на то, что это действительно решаемо и несложно. Но это так. И мы знаем, как к этому подойти.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт