Я занимаюсь разработкой и довольно часто провожу ревью кода – практически каждый день. Одна из моих любимых тем в разработке – это запросы. Интерес к ним у меня появился еще во времена «семерки». Если кто-то помнит, там были прямые запросы в SQL, и возможностей было заметно больше.

С помощью запросов можно реализовать многие вещи, которые стандартными средствами 1С недоступны.
Представьте, что мы идем в магазин. Чтобы ничего не забыть, мы составляем список покупок. В магазине мы сверяемся с ним: смотрим, что уже в корзине, и что еще нужно взять. Когда все куплено – отлично, задача выполнена.
В разработке все устроено аналогично. У нас есть чек-лист – список, в котором мы фиксируем, что именно нужно сделать и что проверить. Сравниваем план с результатом, убеждаемся, что все выполнено – и можем двигаться дальше.
Единообразие кода и команда разработчиков
Есть хорошая фраза: «все должно быть безобразно-единообразно». Кажется, ее говорил наш техлид в тот момент, когда речь шла о важности унификации кода в компании.
У нас достаточно большой пул разработчиков 1С – целый центр компетенции. Но даже в небольшой команде, где работает всего четыре с половиной разработчика, часто проявляется принцип «каждый сам себе художник». Каждый пишет код так, как он видит. Чтобы внести порядок и согласованность, мы придерживаемся упомянутого принципа единообразия.
Конечно, не все можно автоматизировать. В запросах часть проверок можно возложить на инструменты автоматического анализа. Но, например, таких моментов, которые Sonar регулярно находит – соединение с виртуальной таблицей без параметров отбора или забытые условия в запросе, – в моей статье не будет.
Психология и очевидные вещи
Небольшое лирическое отступление. В нашей компании много внимания уделяется заботе о сотрудниках: регулярно проводятся вебинары с психологами. И примерно месяц назад на одном из таких мероприятий мне запомнилась интересная мысль. Психолога часто спрашивали о каких-то «сакральных» практиках: что нужно сделать особенного, чтобы все получилось. А он в ответ уточнял: «А вы делаете самые очевидные вещи?»
«Ну, это же понятно», – отвечали ему. На что он замечал: «Если вы не делаете очевидное, то никакие особенные методы не помогут».
Чек-лист как раз и является такой «очевидной вещью». Он помогает не забывать про простые, но важные шаги и двигаться вперед.Хотя бы для того, чтобы понимать, как правильно, очень полезно обращаться к чек-листу.
Конечно, никто не идеален. Иногда приходится делать что-то неправильно, потому что сроки поджимают. Но даже в таком случае важно помнить: да, я сейчас делаю неправильно, но я делаю это сознательно, понимая последствия.
История создания чек-листа

В 2021 году, когда я проработал в компании всего несколько месяцев, у нас была небольшая команда: три разработчика и куратор. Куратор регулярно проводил ревью нашего кода и в какой-то момент заметил, что ошибки начинают повторяться.
Я был, наверное, главным генератором этих повторяющихся ошибок. Мы поговорили лично, и я пообещал больше так не делать, а заодно выписать для себя список наиболее частых промахов. Но руки у меня так и не дошли, а куратор сделал для нас общий чек-лист. В основном он был посвящен объектной модели.
Выглядел он примерно так: страничка убористого текста в Confluence, которая висела на виду для всех.
С тех пор все команды компании, которые работают с 1С, стараются этого чек-листа придерживаться. Часть пунктов там вполне очевидна: например, не дублировать код, не писать запросы в цикле, делать нулевое тестирование перед тем, как передать задачу на проверку.
Когда я стал проводить ревью на базе большого чек-листа по объектной модели, я заметил, что в запросах тоже начинают повторяться одни и те же ошибки. Так появилась идея создать свой отдельный подраздел.
У нашей команды есть собственная страничка на портале Confluence: там размещен тот самый большой чек-лист по объектной модели, а под ним мы добавили наш чек-лист по языку запросов.

Первые пункты в нем появились примерно в мае: их было всего 4–5. А через пару месяцев список вырос уже до десяти. Ко второму пункту сразу сделали картинку, потому что у ребят возникали вопросы. Так удобнее: сразу видно, о чем идет речь, и не нужно гадать.
Категории ошибок
Общая идея моей статьи – показать, как мы организовали работу у себя и как, возможно, это сможете сделать и вы.
Выше были показаны ошибки в том виде, как они появлялись и как мы их фиксировали. Долгое время они просто выписывались в список и оставались там без особой структуры. Но для статьи я решил систематизировать материал.
В итоге список я разделил на несколько категорий:
-
«Оформление» или «чистота кода».
-
Ошибки в логике. Дальше будут примеры, и станет понятнее, почему я их так назвал (возможно, кто-то сделает для себя другую классификацию).
-
Раздел про элементы оптимизации.
-
Раздел, который я обозначил как «неоднозначность интерпретации». Раньше это называлось «упрощение интерпретации», но мне подсказали, что это не совсем верно: упрощение – это скорее результат исправления ошибок. А вот сами ошибки, которые ведут к неоднозначному пониманию кода, я и выделил в категорию «неоднозначность».
Пример 1: Неиспользуемые поля

Первый пример – неиспользуемые поля.
Когда мы делаем выборку из таблиц, часто бывает так: разработчик двойным кликом берет всю таблицу в конструкторе, и весь состав полей автоматически попадает в выборку. Потом часть этих полей убирается, часть остается, но до конца список никто не проверяет. В результате остаются поля, которые фактически не используются.
Чаще всего такие поля «висят» после того, как запрос уже устоялся, и в него начинают вносить изменения. В процессе доработок про ненужные поля просто забывают.
Да, это не критичная ошибка. Она в первую очередь засоряет код и усложняет его восприятие. Но если говорить об оптимизации, то ситуация меняется: одно лишнее поле или несколько «забытых» полей в выборке по очень большой таблице могут заметно повлиять на производительность.
Пример 2: Неиспользование представления

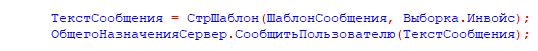
Следующий пример ошибки – неиспользование представления.
В языке запросов есть Представление и ПредставлениеСсылки. Очень часто возникает задача: из финальной выборки нужно взять поля и, например, вывести сообщение пользователю.
Для этого совсем не обязательно тащить саму ссылку. Мы можем прямо в запросе обернуть ее в представление и использовать именно его в объектной модели.
Пример 3: Таблицы без выборки полей

Еще один пример – таблицы без выборки полей.
Здесь важно быть внимательнее с условиями. Когда у нас идет соединение таблиц и из них не выбираются поля, ситуация может быть разной. Если это внутреннее соединение – оно накладывает условия и влияет на результирующую выборку. А вот если соединение левое и при этом поля из присоединенной таблицы не выбираются, интерпретатор просто игнорирует такое соединение.
Формально это не ошибка, скорее вопрос оформления: так код становится менее чистым и менее понятным. Но такие случаи бывают, поэтому я и отметил для себя – нужно быть аккуратнее.
Иногда встречается и более тонкий момент: внизу запроса могут дописать условие – например, сравнение поля основной таблицы с полем левой таблицы. Тут важно быть особенно внимательным, чтобы не получить неожиданный результат.
Пример 4: ЕСТЬNULL для поля основной таблицы

Вот один из примеров, который, как мне кажется, когда-то ловил Sonar.
Некоторые правила мы в команде отключили по договоренности. Сейчас найти все отключенные правила практически невозможно – их, наверное, больше 500. Так что точных данных нет.
В примере поле берется из основной таблицы, и NULL-значений быть не должно. Сбивает с толку при чтении запроса.
Пример 5: Разыменование и соединения

Возможно, что для подобных случаев существовало одно из правил Sonar (точно не помню).
Здесь разыменование, и общее правило: когда больше одной точки, нужно обернуть в ЕСТЬNULL, указать значение подмены, и все будет хорошо. И не забывать, что разыменование – это, по сути, неявное соединение.
Пример 6: Декартово произведение
Интересный случай, на который стоит обратить внимание.
Добавляется поле в одну таблицу и в другую таблицу, оно заполняется одинаковым значением, чтобы потом сделать соединение. В данном случае это приводит к так называемому декартову произведению. Немногие хорошо знакомы с этим понятием.
Здесь важно то, что в нашем чек-листе есть соответствующая строка. Когда приходит новый разработчик и видит незнакомое понятие, он начинает гуглить, получает информацию – и этот опыт у него откладывается, что помогает избежать ошибок в будущем.

Другой пример – в отличии от декартова, это «сложение» таблиц (а не произведение), важно не путать, т.к. в одном случае при отсутствии записей в одной из таблиц в итоге будет пустая выборка, а в другом нет.
Ошибки логики
Пример 7: Использование ЕСТЬNULL для выражения, а не для поля

Теперь переходим к разделу «ошибки логики».
Основной пример здесь связан с использованием ЕСТЬNULL. Проблема возникает, когда в ЕСТЬNULL прячется выражение, составные части которого сами по себе могут принимать значение NULL.
Внизу показан правильный вариант: мы каждое такое выражение оборачиваем в оператор подмены NULL-значений, а затем собираем в общее выражение. Это может быть произведение, сумма, оператор выбора – вариантов много. Главное – контролировать каждое отдельное значение, чтобы избежать неожиданных результатов из-за NULL.
Пример 8: Протягивание поля через запрос
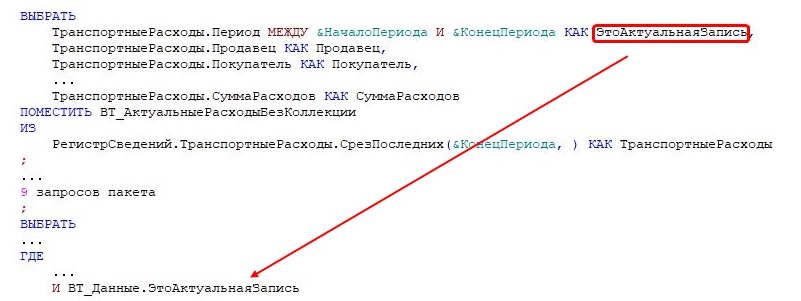
Ии… постепенно переходим к теме оптимизации.
Пример из реальной практики – «протягивание» поля через половину запроса. По сути, условие следовало бы сразу поместить в параметры виртуальной таблицы, но вместо этого оно «протаскивается» через весь запрос. В нашем случае это был пакет из девяти запросов между первым и последним. Только в самом конце выполняется отбор, хотя его можно было бы сделать сразу в начале.
У меня в конце будут две ссылки на статьи, которые меня вдохновили. Одна из них – статья Артема Кузнецова. Он как раз обсуждает похожую идею: не нужно «тащить» ссылку через весь запрос. Вместо этого лучше получить значения по ссылке в результирующей выборке. То есть через запрос мы пробрасываем ссылку, а конкретные значения получаем только там, где они реально нужны.
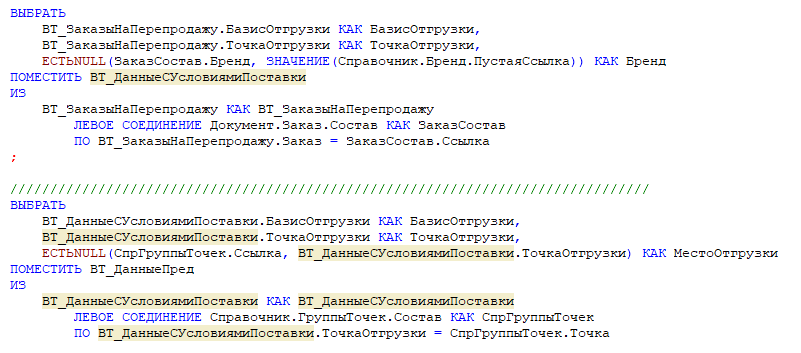
Пример 9: Лишние временные таблицы
Лишние временные таблицы – это именно тот пример, который отражен на изображении в чек-листе по запросам.
Вопросы по нему возникли не случайно: что за «лишние» временные таблицы? Я называю это «размазыванием тонким слоем по тарелочке». Переносимся в то время, когда разработчикам платили за количество строк кода.
Вместо того чтобы сделать сразу два левых соединения, почему-то создаются две временные таблицы. *Вендор утверждает, что 6–7 левых соединений – это нормально, но, если их больше, запрос лучше разбивать.
Пример 10: Дублирование кода в запросах

Один из примеров – дублирование кода. Это словосочетание привычнее слышать в контексте объектной модели, когда в разных методах встречаются одинаковые куски логики, дополненные чем-то еще. Там все очевидно: такие совпадающие фрагменты нужно выносить в отдельный метод.
В запросах ситуация немного другая. Здесь дублирование не всегда бросается в глаза, но бывает настолько явным, что совпадения видны буквально «до степени смешения».
Я сейчас сознательно не говорю о мелочах в данном примере: например, о скобках, которые появляются только потому, что в условиях перепутаны местами поля. Или о том, что корректнее сначала получить ключи аналитики, отобрать данные по ним, а уже потом соединять таблицы, вместо того чтобы сразу вставлять разыменование прямо в условие соединения.
Общий смысл в том, что мы можем из большого регистра сведений сделать выборку и уже потом отдельно поработать с результатом. Отдельно взять текущую коллекцию, отдельно взять предыдущую коллекцию, как на иллюстрации ниже.

К сожалению, невозможно показать весь запрос целиком – с тем, что сверху и снизу, например, как формировалась таблица ВТ_КоллекцииКлючиАналитики и так далее.
Но суть видна и на фрагменте. Наверху мы собрали во временную таблицу ВТ_КоллекцииКлючиАналитики коллекции отдельно и ключи аналитики отдельно, затем соединились с временной таблицей регистра СрезПоследних. При этом сделали отбор в параметрах виртуальной таблицы – как и рекомендует вендор.
Дальше мы работаем с общей таблицей ВТ_ЦеныИзПрайсЛиста. Например, можно взять коллекции из ВТ_СоставСпецификации и, отдельно, коллекции из таблицы ВТ_ПрошлаяКоллекция. Скорее всего, это будут не две разные выборки (как в исходном примере), а одна, в которой будет два ЕСТЬNULL и два соединения.
Пример 11: Неочевидное дублирование в объединении
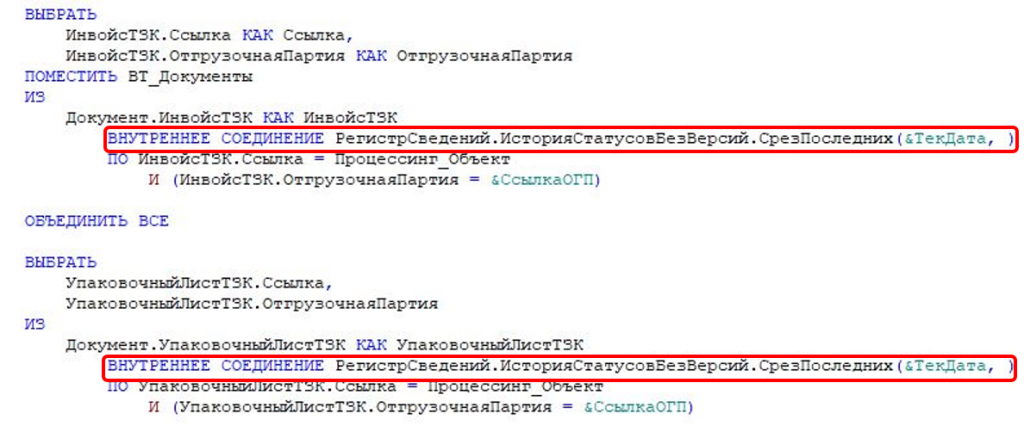
Общее правило, которое у нас сложилось: если мы видим в запросе строки, которые плюс-минус совпадают, – это всегда повод внимательнее посмотреть, что там происходит.
В данном примере вместо того, чтобы сначала сделать объединение и уже потом соединить его с виртуальной таблицей регистра (причем с параметрами отбора), все реализовано иначе: без параметров отбора дважды используется громоздкий срез последних в объединении.
Пример 12: Неоднозначность интерпретации и соединение с шапкой
В качестве примера явное соединение с шапкой объекта при наличии прямого соединения с его табличной частью (по полю Ссылка) вместо неявного при использовании разыменования.

Неоднозначность интерпретации – скользкий случай.
Сначала я обрадовался, когда нашел такой прием, но потом понял, что он применим не всегда. Не во всех ситуациях можно связать табличную часть с «шапкой». Например, если табличная часть соединяется только по своим внутренним полям, то этот вариант не сработает.

В примере же табличная часть соединена по ссылке, и то самое неявное соединение (из-за разыменования в условии) мы можем явно оформить: сделать соединение с «шапкой» объекта и уже без разыменования наложить условие на нужное свойство.
Здесь используется левое соединение – оно быстрее, чем внутреннее. И мы понимаем, что в 1С табличная часть не может существовать отдельно от «шапки». Поэтому просто пользуемся этой особенностью. Sonar, конечно, будет ругаться – но в данном случае это ожидаемо.
Пример 13: Поля из других таблиц и вложенные соединения

Представим ситуацию: у нас два соединения. У первого соединения все хорошо. Второе соединение идет со справочником. Первое условие в нем тоже нормальное, но вот второе условие подтянуло поле из таблицы ВТ_РеквизитыДокумента. В итоге получается, что третья таблица соединяется через поле из второй.
Мы внутри команды договорились так не делать. В свое время вокруг этого вопроса было сломано много копий – и в ERP-команде, и в нашей, и между командами в компании. К единому выводу все равно не пришли, поэтому это остается на уровне договоренности.
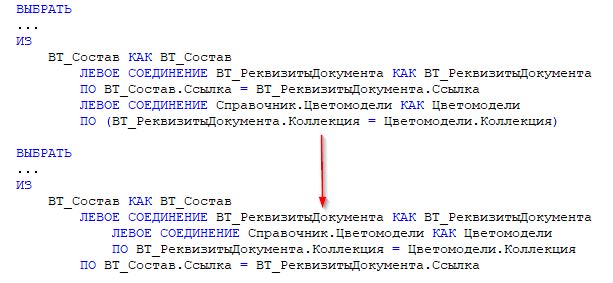
Для понимания: конструктор в 1С неспроста ставит скобки, когда мы соединяем с третьей таблицей. Он подсказывает, что что-то здесь не так. В нашем случае первая таблица справа – это реквизиты документа, вторая – «цветомодели». Когда мы соединяемся с ней через поле второй таблицы, на деле это означает вложенное соединение.
Вендор настоятельно рекомендует такие вложенные соединения не использовать: якобы они превращаются в подзапросы. Смоделировать это на практике у меня не получилось. Примера, когда соединение действительно бы превратилось в подзапрос, привести не могу. Но договоренность внутри компании все же есть: вложенные соединения мы не делаем. Это правило фактически сквозное для всех команд.
Пример 14: Рабочий пример

Что мы видим:
-
В запросе есть два левых соединения.
-
Третья таблица соединяется через вторую, причем условие идет по полю из второй таблицы.
-
При этом фактически мы соединяемся с одной и той же таблицей – «Товары из заказа клиента».
В таком варианте, на мой взгляд, это допустимо. Возможно, даже обоснованно. По крайней мере, мою картину мира такой пример не ломает и в наш чек-лист как «ошибка» не попадает.
Но повторюсь: все это остается на уровне командных договоренностей. Где-то подобное решение могут забраковать, а где-то – принять как норму.
Рекомендации и полезные ссылки
Доклады, которые меня вдохновили:
-
Дмитрий Дудин. SQL для 1С: пишем правильно, красиво, сложно – IE 2019. www.youtube.com/watch?v=e-NyKYgP0xo
-
Артем Кузнецов. Быстрый фронт в базе размером 6.8 терабайт – наши стандарты при разработке и рефакторинге запросов – IE 2021 Moscow Premiere. www.youtube.com/watch?v=oGEu44LolFA
Наиболее часто используемый в работе стандарт:
Ограничения на соединения с вложенными запросами и виртуальными таблицами https://its.1c.ru/db/v8std#content:655:hdoc + все, что «выше» – в этом разделе стандартов 1С https://its.1c.ru/db/v8std#browse:13:-1:26:28
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт