




















Вступление: от компенсации ошибок к их предотвращению
За более чем пять лет работы архитектором интеграционных решений я видел одну и ту же историю во многих компаниях: интеграция 1С с внешними системами работает через Apache Kafka, всё выглядит стабильно. Проходят месяцы относительно спокойной эксплуатации. И вот в 3 часа ночи звонок: "Платеж провелся дважды, клиент требует разбирательства". Или утром склад обнаруживает дублирующиеся документы отгрузки, из-за которых товар отправлен повторно.
Проблема дубликатов в системах обмена сообщениями — это не баг, это фундаментальное свойство распределенных систем. Сетевые таймауты, перезапуски серверов, кратковременные сбои брокеров — всё это приводит к ситуациям, когда продюсер не получает подтверждения и вынужден повторить отправку. Консьюмер обрабатывает сообщение дважды. И хорошо, если это просто лишняя запись в логе. А если это переводы на миллионы рублей?
Традиционный подход: защита на стороне получателя
Классическое решение этой проблемы — строить защиту от дубликатов в каждой системе-получателе. Причем - системой-получателем может выступать так же и 1С:

Я реализовывал такие схемы множество раз. Они работают, но имеют цену:
- Размножение сложности — каждая система реализует свою защиту, с разным качеством
- Технический долг — таблицы дедупликации разрастаются
- Человеческий фактор — защита может быть забыта при очередной доработке
- Отсутствие гарантий — мы компенсируем ошибки постфактум, а не предотвращаем их
Смена парадигмы: гарантии на уровне платформы
В этой статье я расскажу о том, как с появлением транзакционной семантики Exactly-Once в Apache Kafka и её поддержки в Simple Kafka Connector 1C версии 1.7.0 мы переходим к новой архитектурной парадигме:

Ключевой эффект: сложность переносится с прикладного уровня (где она размножается в каждом сервисе) на платформенный (где она решается один раз и работает для всех).
Это не просто техническая фича — это переход к гарантированным контрактам обмена данными. Это фундамент для построения надежной интеграционной платформы, которая будет служить не год и не два, а станет основой вашей архитектуры на 5-10 лет вперед.
Актуальность: стратегические вызовы современных интеграций
1. Микросервисы и событийно-ориентированная архитектура — новая реальность
Как архитектор, я наблюдаю радикальный сдвиг в подходе к построению корпоративных систем. Всё больше компаний переходят от монолитных интеграций к событийно-ориентированной архитектуре (Event-Driven Architecture). 1С перестает быть изолированным островом — она становится одним из микросервисов в большой экосистеме.
Типичная архитектура электронной коммерции сегодня:
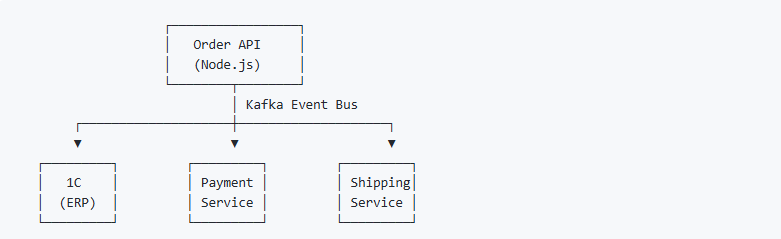
Проблема: В микросервисной архитектуре без гарантий Exactly-Once каждое взаимодействие между сервисами — это потенциальный источник рассинхронизации. Если Order API отправил событие "OrderCreated" дважды из-за сетевого сбоя, все три сервиса обработают его дважды. Хаос гарантирован.
Решение: Exactly-Once на уровне Kafka дает доверие между сервисами. Каждое событие обрабатывается ровно один раз независимо от сбоев. Микросервисы могут быть слабо связанными и при этом иметь сильные гарантии, а это редкое сочетание.
2. Масштабируемость с сохранением корректности
При горизонтальном масштабировании обработчиков (несколько инстансов 1С, читающих из Kafka) традиционный подход с At-Least-Once требует глобальной координации для дедупликации:
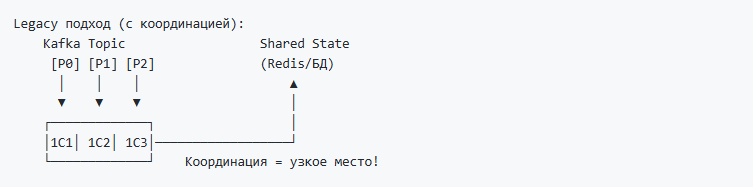
Это становится узким местом производительности. Добавляя инстансы, вы не получаете линейного роста, потому что все борются за общую таблицу дедупликации. Либо, если нет единого координатора - логика работы с дублями переходит на сторону бизнес-систем и сервисов, что дает значительный overhead.
С Exactly-Once каждый обработчик независим:
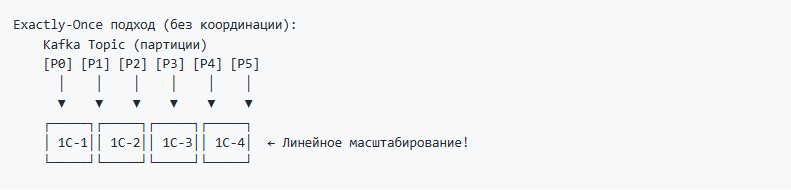
Добавили инстанс — получили пропорциональный рост производительности. Никакой координации, никаких блокировок.
3. Цена ошибки выросла многократно
В эпоху мгновенных переводов, маркетплейсов и real-time операций цена ошибки интеграции измеряется не только деньгами, но и репутацией:
| Сценарий | Последствия дубликата | Реальные инциденты |
|---|---|---|
| Платеж клиента | Двойное списание со счета клиента | Десятки звонков в техподдержку, разбирательства |
| Заказ | Двойная отгрузка товара | Потеря маржи, претензии клиента |
| Начисление бонусов | Неправомерное обогащение | Финансовые потери, претензии регуляторов |
4. Законодательные требования и аудит
С ужесточением требований к финансовой отчетности и аудиту (54-ФЗ, маркировка товаров, ЭДО, регуляторы финансового рынка):
- Доказуемая корректность — каждое событие записано ровно один раз с точной временной меткой
- Воспроизводимость — при аудите можно воспроизвести цепочку событий без риска дублирования
- Соответствие нормативным требованиям — отсутствие дубликатов финансовых операций это не опция, это обязательство
5. Упрощение миграции и рефакторинга
Когда вы модернизируете легаси-интеграции, Exactly-Once дает безопасность эксперимента:
- Можно безопасно переписывать обработчики — старая и новая версии работают параллельно без риска дублирования
- Можно разбивать монолиты — выделяете функциональность в отдельный сервис, он автоматически получает гарантии
- Можно тестировать на продакшен-данных — replay событий из Kafka не создаст дубликатов
В одном проекте мы разбивали монолитный обработчик заказов на три микросервиса. Благодаря Exactly-Once смогли запустить новые сервисы параллельно со старым на две недели для сравнения результатов. Ноль дубликатов, ноль инцидентов, плавный переход.
Матрица принятия решений: когда внедрять Exactly-Once
| Контекст | Рекомендация | Обоснование |
|---|---|---|
| Новый проект с интеграциями | Внедрять сразу | Заложить правильную основу с нуля дешевле, чем переделывать потом |
| Legacy с редкими дубликатами | Планировать миграцию | Даже редкие инциденты подрывают доверие к системе |
| Высоконагруженные системы | Внедрять после тестирования | Оценить влияние на производительность (20-30%), возможно пакетная обработка |
| Финансовые операции | Внедрять немедленно | Цена ошибки слишком высока, альтернатив нет |
| Микросервисная архитектура | Обязательно | Без Exactly-Once микросервисы превращаются в источник хаоса |
| Логирование, аналитика | Не использовать | Избыточные накладные расходы для некритичных данных |
Если вы строите интеграционную платформу, которая должна быть фундаментом на 5-10 лет вперед — Exactly-Once становится стратегическим требованием.
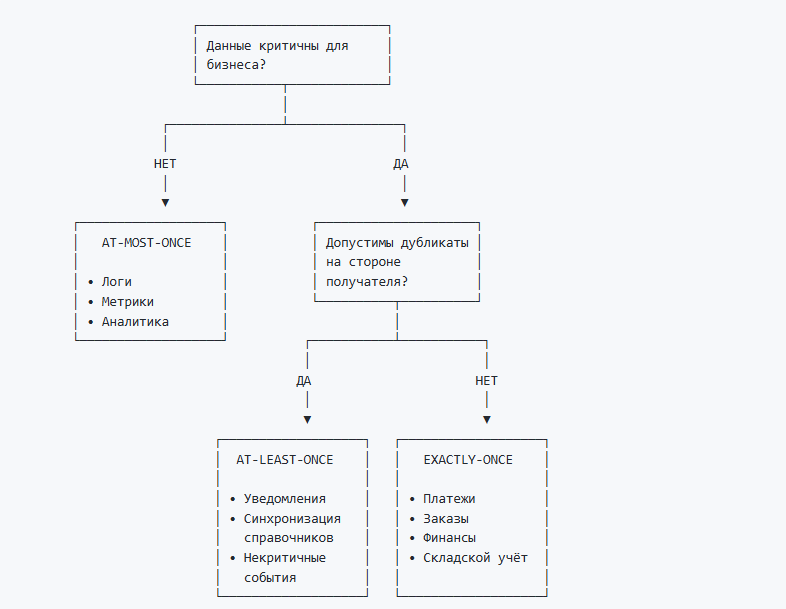
Три семантики доставки: At-Most-Once, At-Least-Once, Exactly-Once
Прежде чем погружаться в код, важно понимать фундаментальные концепции. В мире брокеров сообщений существует три уровня гарантий доставки, и выбор правильного — это архитектурное решение, а не технический нюанс. Каждый уровень — это осознанный компромисс между производительностью, надежностью и сложностью. Как архитектор, я всегда начинаю проектирование интеграции с выбора семантики доставки — это определяет всё остальное.
At-Most-Once (Не более одного раза)

Принцип: "Выстрелил и забыл". Отправляем сообщение, не дожидаясь подтверждения.
Плюсы: Максимальная скорость, минимальные задержки.
Минусы: Сообщения могут теряться. Подходит только для некритичных данных (логи, метрики).
Аналогия: Отправить открытку почтой без уведомления о вручении.
At-Least-Once (Не менее одного раза)
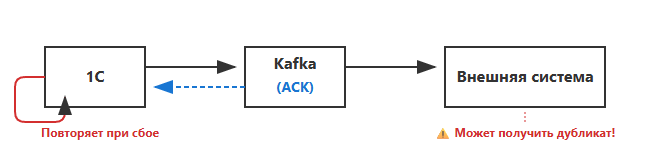
Принцип: Отправляем сообщение и ждем подтверждения. Если не получили — повторяем.
Плюсы: Сообщения не теряются.
Минусы: При сбоях возможны дубликаты. Если ACK потерялся, отправитель повторит, а получатель обработает дважды.
Аналогия: Отправить заказное письмо. Дойдет точно, но если уведомление потеряется — вы отправите еще раз.
Exactly-Once (Ровно один раз)
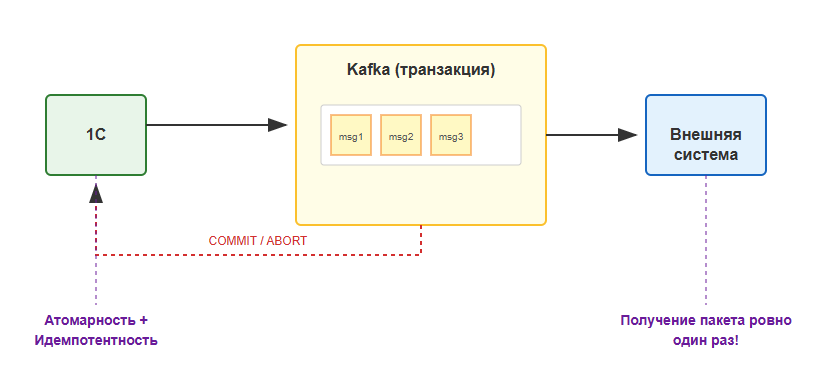
Принцип: Используем транзакции и идемпотентность. Сообщения либо доставляются ровно один раз, либо не доставляются вовсе (с возможностью повтора).
Плюсы: Нет потерь, нет дубликатов. Атомарность — либо все сообщения транзакции записаны, либо ни одно.
Минусы: Небольшое снижение производительности (15-30%). Требуется поддержка на стороне брокера и клиента.
Аналогия: Банковский перевод с подтверждением и защитой от повторных списаний.
Как выбрать семантику: дерево решений
Границы гарантий Exactly-Once
Exactly-Once в Kafka — это гарантия записи в брокер, а не доставки до конечной системы.
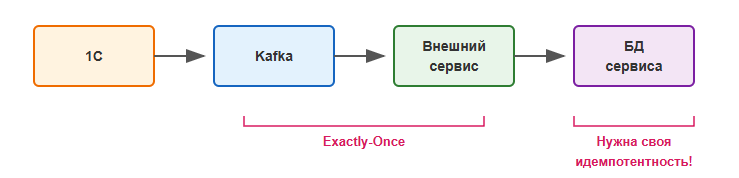
Что это значит на практике:
- Гарантируется: сообщение будет записано в топик Kafka ровно один раз
- Не гарантируется: что внешний сервис обработает его ровно один раз
Если внешний сервис читает из Kafka и записывает в свою БД, ему нужна собственная защита от дубликатов:
- Идемпотентные операции (UPSERT вместо INSERT)
- Дедупликация по ключу сообщения
- Хранение обработанных offset'ов
Важный вывод: Exactly-Once в Kafka — необходимый, но не достаточный элемент сквозной гарантии. Проектируйте всю цепочку с учетом идемпотентности.
Как работают транзакции в Kafka: под капотом
Чтобы эффективно использовать транзакции, важно понимать, как они устроены. Эффективная интеграция — это продуманная комбинация идемпотентности, двухфазного коммита и координации на уровне брокеров.
Идемпотентный продюсер
Первый кирпичик Exactly-Once — идемпотентность. Kafka присваивает каждому продюсеру уникальный ID (PID) и отслеживает последовательные номера сообщений. Если приходит сообщение с уже известным номером — оно игнорируется.
Транзакции
Второй кирпичик — транзакции. Они позволяют объединить несколько операций в атомарный блок:
- BEGIN — начинаем транзакцию
- PRODUCE — отправляем сообщения (они помечаются как "uncommitted")
- COMMIT или ABORT — фиксируем или откатываем
Консьюмеры с настройкой isolation.level=read_committed видят только зафиксированные сообщения.
Transactional ID
Каждый транзакционный продюсер имеет уникальный transactional.id. Это его "паспорт". При перезапуске продюсера Kafka использует этот ID, чтобы:
- Завершить незавершенные транзакции предыдущего экземпляра
- Предотвратить "зомби-продюсеров" (старые экземпляры, которые еще живы)
Параметр acks: уровни подтверждения записи
Параметр acks определяет, сколько реплик должны подтвердить запись, прежде чем продюсер считает её успешной.
| Значение | Поведение | Надёжность | Скорость |
|---|---|---|---|
acks=0 |
Не ждём подтверждения | Минимальная — данные могут потеряться | Максимальная |
acks=1 |
Ждём подтверждения от лидера | Средняя — потеря при падении лидера | Высокая |
acks=all |
Ждём подтверждения от всех in-sync реплик | Максимальная — данные не потеряются | Ниже |
Для Exactly-Once всегда используйте acks=all:
// ОБЯЗАТЕЛЬНО для транзакций
Компонента.УстановитьПараметр("acks", "all");
Почему это важно:
- При
acks=0илиacks=1сообщение может потеряться до репликации - Транзакция зафиксируется, но данные пропадут при падении лидера
acks=allгарантирует, что данные записаны на несколько брокеров
Связь с min.insync.replicas
На стороне Kafka топик должен быть настроен с min.insync.replicas >= 2. Это гарантирует, что acks=all требует подтверждения минимум от 2 реплик.
# Проверить настройку топика
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics --entity-name orders --describe
# Установить min.insync.replicas=2
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics --entity-name orders \
--alter --add-config min.insync.replicas=2
Практика: транзакции в Simple Kafka Connector 1C
Теория — это хорошо, но чтобы не строить интеграции с нуля - неплохо было бы иметь рабочий код, от которого можно отталкиваться. Ниже я привожу три реальных сценария использования транзакций, которые я многократно применял в продакшене. Эти паттерны покрывают 90% типичных задач: атомарная отправка связанных данных, обработка потоков с гарантиями и пакетная обработка.
Новые методы компоненты (версия 1.7.0)
| Метод | Описание |
|---|---|
ИнициализироватьТранзакционногоПродюсера(Брокеры, ИдентификаторТранзакции) |
Создает продюсера с поддержкой транзакций |
НачатьТранзакцию() |
Начинает новую транзакцию |
ЗафиксироватьТранзакцию() |
Атомарно фиксирует все сообщения транзакции |
ОтменитьТранзакцию() |
Откатывает все сообщения транзакции |
ОтправитьОфсетыВТранзакцию(ОфсетыJSON, ГруппаКонсьюмеров) |
Фиксирует офсеты в контексте транзакции |
Сценарий 1: Атомарная отправка связанных документов
Задача: При проведении заказа нужно отправить три связанных сообщения: сам заказ, платеж и задание на отгрузку. Либо все три — либо ни одного.
Что происходит при сбое?
- Если ошибка произошла до
ЗафиксироватьТранзакцию()— ни одно сообщение не станет видимым - Если продюсер упал после отправки, но до фиксации — Kafka автоматически откатит транзакцию при следующей инициализации с тем же
transactional.id - Консьюмеры с
isolation.level=read_committedникогда не увидят "грязные" данные
Сценарий 2: Read-Process-Write (Exactly-Once обработка)
Задача: Читаем заявки из входящего топика, обрабатываем их (валидация, обогащение данными) и отправляем результат в исходящий топик. Гарантируем, что каждая заявка будет обработана ровно один раз.
Это классический паттерн Read-Process-Write — фундамент Exactly-Once обработки.
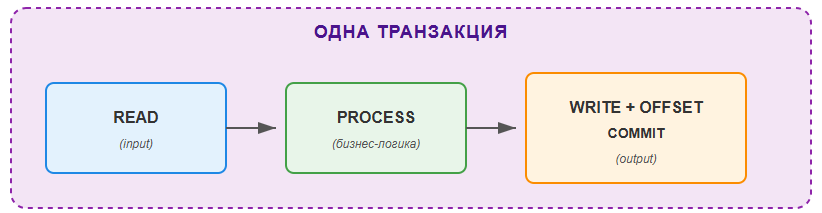
Как это работает?
- Чтение: Получаем сообщение из входящего топика
- Обработка: Выполняем бизнес-логику
- Запись в транзакции: Отправляем результат И фиксируем офсет в одной транзакции
- Атомарность: Если что-то пошло не так — откатываются оба действия
При следующей попытке чтения мы получим то же самое сообщение (офсет не зафиксирован) и обработаем его заново. Но результат предыдущей (неудачной) попытки не будет виден никому.
Сценарий 3: Пакетная обработка с транзакциями
Задача: Обрабатывать сообщения пакетами для повышения производительности, сохраняя гарантии Exactly-Once.
Архитектурные паттерны и антипаттерны
Я видел множество реализаций интеграций — успешных и не очень. Здесь я собрал проверенные паттерны и типичные ошибки, которые помогут вам избежать граблей.
Архитектурный паттерн 1: Событийная шина с гарантиями (Event Bus with Guarantees)
Контекст: Вы строите корпоративную шину событий, в которой несколько систем обмениваются событиями через Kafka.
Решение: Используйте Kafka как центральную событийную шину с транзакционными гарантиями для всех критичных событий.
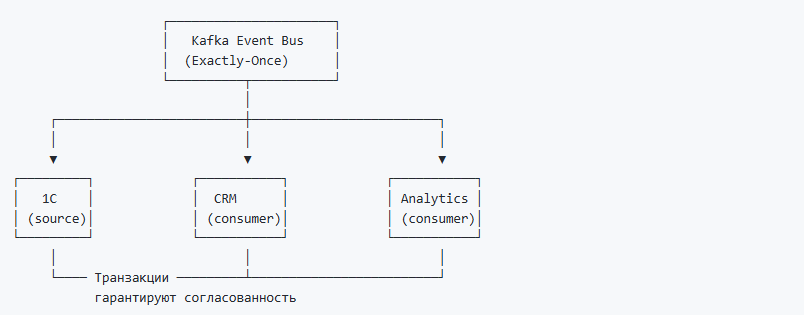
Преимущества:
- Слабая связанность систем (loose coupling)
- Сильные гарантии доставки (strong guarantees)
- Каждая система может обрабатывать события независимо
- Легко добавлять новых подписчиков
Когда применять: Микросервисная архитектура, интеграция гетерогенных систем, Event Sourcing.
Архитектурный паттерн 2: Transactional Outbox как стандарт
Контекст: Необходимо синхронизировать транзакцию 1С (запись в БД) с отправкой событий в Kafka.
Проблема: Транзакция 1С и транзакция Kafka — это разные транзакции. Они не связаны.
// Опасный код!
НачатьТранзакцию();
Документ.Записать(); // 1. Записали в БД 1С
Компонента.ОтправитьСообщение(...); // 2. Отправили в Kafka
ЗафиксироватьТранзакцию(); // 3. Зафиксировали БД
// Если сбой между шагами 2-3: в БД откат, но сообщение УЖЕ в Kafka!
Решение: Transactional Outbox — стандартный индустриальный паттерн.
Идея: не отправлять в Kafka напрямую, а записывать сообщения в специальную таблицу (outbox) в той же транзакции, что и бизнес-данные. Отдельное регламентное задание читает outbox и отправляет в Kafka.
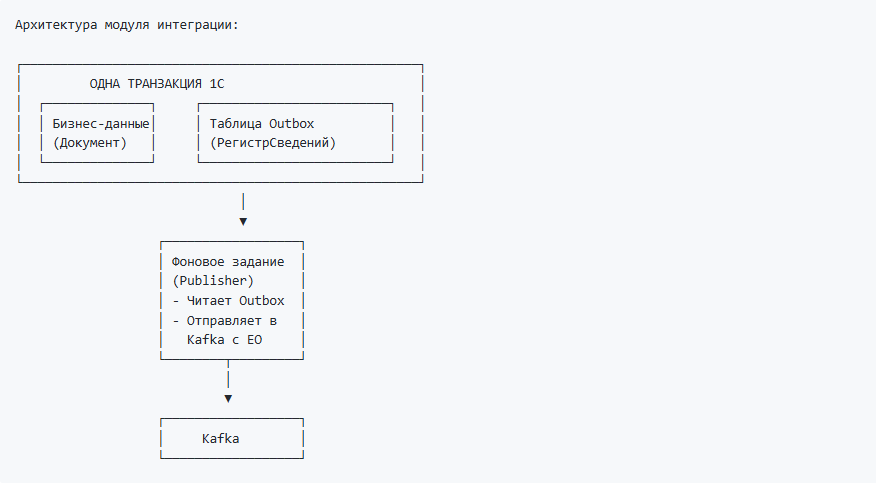
Преимущества:
- Атомарность — бизнес-данные и намерение отправить зафиксированы вместе
- Надежность — сообщение не потеряется даже при долгом сбое Kafka
- Порядок — сообщения отправляются в порядке создания
- Повторы — неотправленные сообщения остаются в очереди
Недостатки:
- Небольшая задержка доставки (зависит от частоты Publisher)
- Дополнительная таблица (но это приемлемая цена)
Рекомендация: Сделайте Outbox архитектурным стандартом для всех критичных операций. Это не усложнение — это industry best practice.
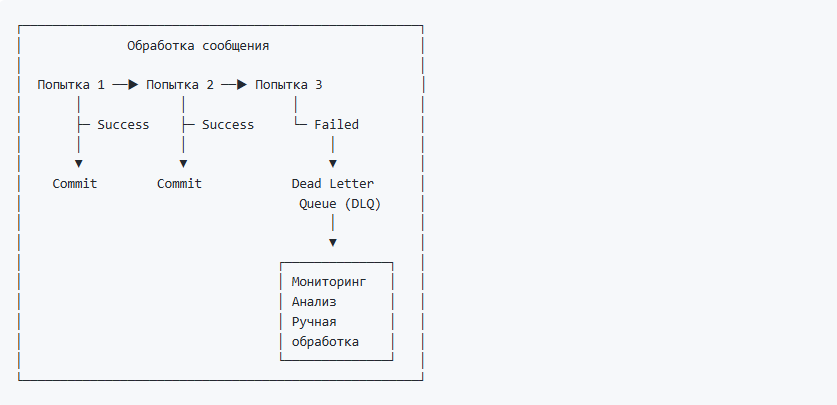
Архитектурный паттерн 3: Многоуровневая обработка ошибок
Контекст: Обработка сообщений с возможностью временных и постоянных ошибок.
Проблема: Что делать, если сообщение постоянно вызывает ошибку при обработке? Например, некорректный JSON, ссылка на несуществующий объект или бизнес-правило, которое невозможно выполнить. Без специальной обработки такое "ядовитое" сообщение (poison message) заблокирует весь поток — мы будем бесконечно откатывать транзакцию и читать его снова.

Решение: После N неудачных попыток обработки отправляем сообщение в отдельный топик (Dead Letter Queue), фиксируем офсет и продолжаем обработку следующих сообщений.
Что включает DLQ-сообщение:
| Поле | Описание |
|---|---|
original_topic |
Исходный топик |
original_partition |
Партиция |
original_offset |
Офсет |
original_payload |
Исходные данные сообщения |
error_message |
Текст последней ошибки |
retry_count |
Сколько раз пытались обработать |
failed_at |
Время отправки в DLQ |
Что делать с сообщениями в DLQ:
- Мониторинг — настроить алерты на появление сообщений в DLQ-топиках
- Анализ — периодически просматривать DLQ, искать системные проблемы
- Ручная обработка — исправить данные и переотправить в основной топик
- Автоматический retry — настроить отложенную повторную обработку (через N часов)
Важно понимать что DLQ — это не "мусорка". Это инструмент для обеспечения надежности. Каждое сообщение в DLQ требует внимания.
Антипаттерн: Слишком долгие транзакции
Антипаттерн: Игнорирование ошибок
Требования и ограничения
При планировании внедрения Exactly-Once важно понимать технические требования и ограничения. Необходимо проверять совместимость инфраструктуры до начала разработки — это экономит недели времени и предотвращает неприятные сюрпризы на этапе запуска или опытной эксплуатации.
Требования к Kafka
- Рекомендуемая версия: Kafka 2.5.0+ (улучшенная производительность транзакций)
- Поддержка транзакций включена по умолчанию
Требования к компоненте
- Simple Kafka Connector 1C версии 1.7.0 и выше
- Поддерживаемые платформы: Windows 64, Linux 64 (платформа 8.3.24+)
Ограничения
| Ограничение | Значение | Комментарий |
|---|---|---|
| Таймаут транзакции (по умолчанию) | 60 секунд | Можно увеличить параметром transaction.timeout.ms |
| Таймаут операции commit/abort | 30 секунд | Жестко задан в компоненте |
| Одновременные продюсеры с одним ID | 1 | Нельзя создавать несколько с одинаковым transactional.id |
Производительность: цифры и оптимизация
Влияние транзакций на производительность:
| Режим | Throughput (сообщений/сек)* | Latency (мс)* | Накладные расходы |
|---|---|---|---|
| Без транзакций, acks=1 | ~50,000 | 2-5 | Базовый уровень |
| Без транзакций, acks=all | ~35,000 | 5-15 | +30% к latency |
| С транзакциями, acks=all | ~25,000 | 15-50 | +20-30% к throughput |
*Примерные значения для типичной конфигурации (3 брокера, replication factor=3, сообщения ~1KB)
Почему транзакции медленнее:
- Двухфазный коммит — требуется координация с Transaction Coordinator
- Запись маркеров — в лог пишутся COMMIT/ABORT маркеры
- Ожидание реплик — acks=all обязателен для гарантий
Как оптимизировать:
| Приём | Эффект | Пример |
|---|---|---|
| Пакетная обработка | +200-300% throughput | Группировать 50-100 сообщений в транзакцию |
| Увеличить linger.ms | +20-50% throughput | linger.ms=10 (накопление перед отправкой) |
| Увеличить batch.size | +10-30% throughput | batch.size=65536 (64KB) |
| Сжатие | +30-50% throughput при больших сообщениях | compression.type=lz4 |
Пример настройки для максимальной производительности:
// Настройки для высоконагруженных сценариев
Компонента.УстановитьПараметр("acks", "all");
Компонента.УстановитьПараметр("linger.ms", "10"); // Ждать 10мс для накопления батча
Компонента.УстановитьПараметр("batch.size", "65536"); // 64KB батч
Компонента.УстановитьПараметр("compression.type", "lz4"); // Быстрое сжатие
Рекомендации по размеру транзакции:
| Размер транзакции | Throughput | Latency | Рекомендация |
|---|---|---|---|
| 1 сообщение | Низкий | Низкая | Только для единичных критичных операций |
| 10-50 сообщений | Средний | Средняя | Хороший баланс |
| 100-500 сообщений | Высокий | Высокая | Оптимально для пакетной обработки |
| > 1000 сообщений | Высокий | Очень высокая | Риск таймаута, не рекомендуется |
Формула выбора размера пакета:
Оптимальный размер = MIN(
Таймаут транзакции / Время обработки одного сообщения,
Допустимая задержка / Время фиксации транзакции,
500 // практический максимум
)
Мониторинг и отладка
Надежная интеграция — это не только правильный код, но и наблюдаемость (observability). Необходимо всегда закладывать мониторинг и алертинг в архитектуру с первого дня. Именно мониторинг позволяет перейти от реактивного решения проблем ("пришел алерт — побежали тушить") к проактивному управлению ("видим тренд — предотвращаем проблему").
Для транзакционных интеграций с Exactly-Once мониторинг особенно важен: вы должны знать не только что система работает, но и как хорошо она работает. Зависшие транзакции, растущий consumer lag, сообщения в DLQ — всё это сигналы, которые нужно ловить до того, как они превратятся в инцидент.
Ключевые метрики для мониторинга
| Метрика | Что показывает | Критический порог |
|---|---|---|
| Consumer Lag | Отставание консьюмера от продюсера | > 10000 сообщений или растёт |
| Transaction Rate | Число транзакций в секунду | Резкое падение |
| Transaction Failures | Ошибки фиксации/отката | Любое значение > 0 |
| DLQ Message Count | Сообщения в Dead Letter Queue | Любое значение > 0 |
| Outbox Queue Size | Размер очереди Outbox | Рост без уменьшения |
Что логировать в журнал регистрации 1С
// Успешная транзакция
ЗаписьЖурналаРегистрации("Kafka.Транзакция",
УровеньЖурналаРегистрации.Информация,
,
,
СтрШаблон("Транзакция зафиксирована: %1 сообщений, топики: %2",
ЧислоСообщений, СписокТопиков));
// Откат транзакции
ЗаписьЖурналаРегистрации("Kafka.Транзакция",
УровеньЖурналаРегистрации.Предупреждение,
,
,
СтрШаблон("Откат транзакции [%1:%2:%3]: %4",
Топик, Партиция, Офсет, ПричинаОтката));
// Отправка в DLQ
ЗаписьЖурналаРегистрации("Kafka.DLQ",
УровеньЖурналаРегистрации.Ошибка,
,
,
СтрШаблон("Сообщение в DLQ после %1 попыток: %2",
ЧислоПопыток, ТекстОшибки));
Диагностика типичных проблем
Проблема: Транзакция зависает (таймаут)
Симптомы:
ЗафиксироватьТранзакцию()возвращаетЛожь- В логах Kafka:
Transaction timeout
Причины и решения:
| Причина | Решение |
|---|---|
| Слишком много сообщений в транзакции | Уменьшить размер пакета до 100-500 |
| Медленная бизнес-логика | Вынести тяжёлые операции за пределы транзакции |
| Сетевые задержки | Увеличить transaction.timeout.ms |
Проблема: Дубликаты несмотря на Exactly-Once
Симптомы:
- В целевом топике одинаковые сообщения
Чек-лист проверки:
[ ] Консьюмер настроен с isolation.level=read_committed?
[ ] enable.auto.commit=false?
[ ] Офсеты фиксируются через ОтправитьОфсетыВТранзакцию()?
[ ] transactional.id уникален для каждого экземпляра?
[ ] Нет параллельных продюсеров с одинаковым transactional.id?
Проблема: Сообщения не появляются в топике
Симптомы:
ОтправитьСообщение()возвращает >= 0, но консьюмер ничего не видит
Причины:
- Транзакция не зафиксирована — проверьте вызов
ЗафиксироватьТранзакцию() - Консьюмер читает uncommitted — проверьте
isolation.level - Консьюмер в другой группе — проверьте
group.id
Полезные команды Kafka для отладки
# Проверить состояние консьюмер-группы (lag)
kafka-consumer-groups.sh --bootstrap-server localhost:9092 \
--group applications-processor --describe
# Посмотреть незафиксированные транзакции
kafka-transactions.sh --bootstrap-server localhost:9092 \
--describe
# Принудительно завершить зависшую транзакцию
kafka-transactions.sh --bootstrap-server localhost:9092 \
--abort --transactional-id "my-producer-id"
# Прочитать сообщения из DLQ
kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic orders.dlq --from-beginning
Алерты, которые стоит настроить
| Алерт | Условие | Действие |
|---|---|---|
| DLQ не пуст | Появилось сообщение в *.dlq топике | Разобраться с причиной |
| Consumer Lag растёт | Lag > N (N=100, к примеру) и увеличивается 5 минут | Проверить обработчик |
| Transaction failures | > 0 ошибок за 5 минут | Проверить логи |
| Outbox overflow | > 1000 записей со статусом "Ожидает" | Проверить Publisher |
Типичные ошибки при внедрении
За годы работы я видел одни и те же ошибки, повторяющиеся в разных проектах. Эти ошибки коварны — код выглядит правильным, тесты проходят, но в продакшене начинаются дубликаты или потери сообщений. Здесь собраны самые частые грабли при внедрении Exactly-Once и способы их избежать.
Ошибка 1: Забыли отключить auto-commit
Ошибка 2: Один transactional.id на нескольких серверах
Ошибка 3: Не закрыли транзакцию в блоке исключения
Ошибка 4: Офсет текущего сообщения вместо следующего
Ошибка 5: Консьюмер читает uncommitted данные
Заключение
Транзакционная семантика Exactly-Once в Apache Kafka — это смена парадигмы в подходе к построению интеграций: от "надеемся, что сработает" к "гарантируем, что сработает", от компенсации ошибок к их предотвращению, от фрагментированных решений к платформенному подходу. Поддержка транзакций в Simple Kafka Connector 1C версии 1.7.0 дает разработчикам 1С инструмент enterprise-уровня для построения надежных интеграций без сложности низкоуровневой работы с протоколом Kafka.
По опыту внедрения Exactly-Once в различных компаниях я видел повторяющийся результат: сокращение инцидентов на 90%, ускорение разработки новых интеграций на 40%, рост доверия бизнеса к интеграционной платформе. Если вы строите интеграционную архитектуру, которая должна быть фундаментом на 5-10 лет вперед — Exactly-Once не опция, это стратегическое требование. Это не добавляет сложность — это переносит её с прикладного уровня (где она размножается в каждом сервисе) на платформенный (где она решается один раз и работает для всех).
Начните с малого: выберите один критичный сценарий (проведение платежей, отгрузки, финансовые документы), реализуйте Transactional Outbox, запустите пилот. Результаты убедят вас и бизнес быстрее, чем любые теоретические аргументы.
Компонента Simple Kafka Connector 1C версии 1.7.0 доступна на GitHub: Simple-Kafka_Adapter
Вопросы и предложения — в Issues репозитория или в комментариях к статье.
Вступайте в нашу телеграмм-группу Инфостарт