Меня зовут Иван Кучин, я технический архитектор компании Axenix, мой соавтор – ведущий разработчик Ренат Низамиев. В этой статье мы расскажем:
-
О системе передачи сообщений Kafka,
-
О стандарте проектирования HTTP-сервисов OpenAPI,
-
Про отказоустойчивый веб-сервер на базе HAProxy и Apache,
-
Немного интересных фактов про 1С РИБ – в том числе в интеграциях с Zabbix.
Система передачи сообщений Kafka
Интересный факт: система передачи сообщений Kafka названа в честь Франца Кафки, который был одним из любимых писателей разработчика Джея Крепса.
Многие считают, что это просто еще один брокер сообщений, но это не совсем так. Сам вендор определяет эту систему как «open source distributed event streaming platform», что переводится как «распределенная платформа с открытым исходным кодом для потоковой передачи событий».
Изначально Kafka была разработана в недрах компании LinkedIn для собственных нужд, но уже в 2012 году передана фонду Apache Foundation, после чего получила широкое распространение.
Это решение изначально проектировалось под корпоративный сектор и высокие нагрузки, поэтому ему присущи высокая отказоустойчивость, масштабируемость и производительность. Спектр применения Kafka огромен – от обработки банковских транзакций до использования в стриминговых платформах – например, в Netflix.
Архитектура и внутреннее устройство Kafka
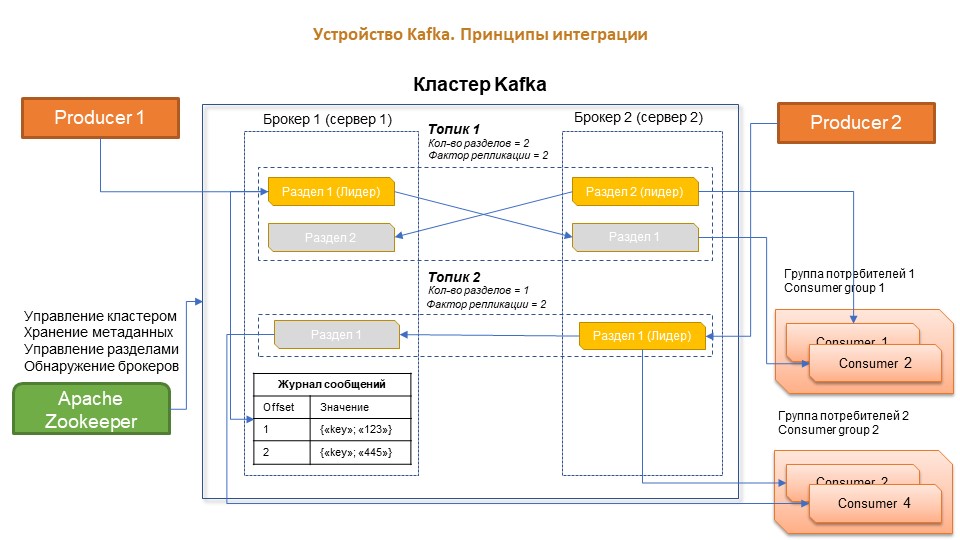
Кластер Kafka состоит из рабочих серверов, называемых брокерами. Естественно, он может быть один, но для повышения отказоустойчивости и производительности рекомендуется использовать как минимум три.
Приложения, работающие с Kafka, делятся на:
-
Продюсеров – это те приложения, которые пишут данные в Kafka,
-
Консьюмеров, или потребителей, которые читают сообщения из Kafka. Консьюмеры объединяются в консьюмер-группы.
Такая организация нужна для ускорения чтения сообщений.
Топик – это функциональная категория, которая нужна для группировки сообщений. Физически топики состоят из каталогов на жестком диске брокеров, которые называются разделами. Один раздел – это одна папка, и в этой папке лежат файлы, в которых хранятся сообщения.
Журнал сообщений показан схематически. Очень важное поле у каждого сообщения называется Offset. Это своего рода индекс – порядковый номер, по которому упорядочены все сообщения в журнале.
Стоит сказать, что, в отличие от RabbitMQ, на один и тот же топик может быть подписано несколько потребителей, и сообщения при прочтении не удаляются – они остаются в журнале.
Offset нужен для того, чтобы читать сообщения, не перечитывая их многократно.
Управляется вся эта система с помощью Apache ZooKeeper – центрального сервера, который хранит настройки, метаданные и состояние кластера.
Примеры использования Kafka в интеграциях
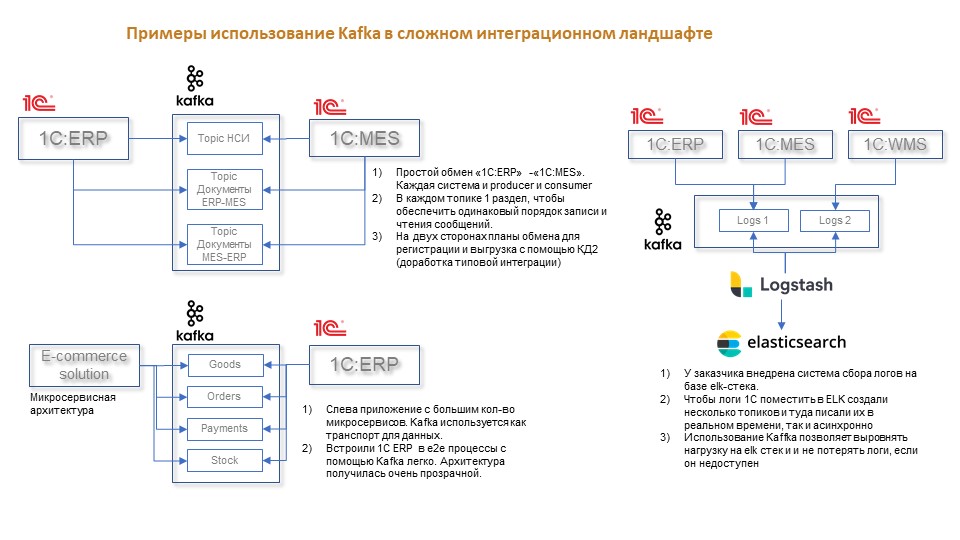
Самый простой пример использования Kafka в интеграционном ландшафте – это две информационные системы на платформе «1С:Предприятие 8»: ERP и MES, с двусторонней интеграцией НСИ и по документам. В данном случае используется три топика: одна система пишет, вторая читает, и наоборот.
Другой интересный кейс – это интеграция с большим, серьезным микросервисным приложением, в котором реализовано порядка 50 микросервисов. Kafka уже использовалась в нем как собственный инструмент для обмена данными между микросервисами. Наша задача заключалась в том, чтобы подключиться к Kafka и, согласовав определенные форматы и правила передачи сообщений, читать и записывать данные в топик. То есть в этом случае 1С выступала одновременно и консьюмером, и продюсером.
Третья интересная история – это решение задачи централизованного логирования. У заказчика был ELK-стек. Один из его компонентов – Logstash – умеет интегрироваться с топиками Kafka: читать оттуда логи, преобразовывать их и складывать в Elasticsearch. А вы можете записывать логи из ваших сообщений напрямую в Kafka и таким образом не изобретать никакого «велосипеда», а переиспользовать существующую инфраструктуру.
На данный момент есть два способа интеграции с Kafka.
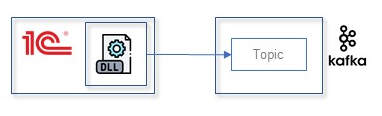
Первый – различные решения на базе open-source компонента librdkafka, написанного на языке Rust. Ссылка на GitHub https://github.com/confluentinc/librdkafka.
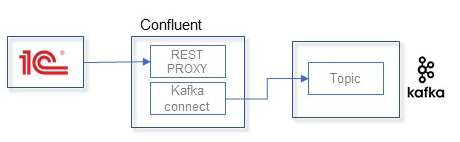
Второй способ – отдельное приложение, которое называется Confluent REST Proxy. Это, по сути, веб-сервер для обработки входящих HTTP-запросов и реализации протокола Kafka Connect. Ссылка: https://docs.confluent.io/platform/current/kafka-rest/.
Стандарт OpenAPI/Swagger для описания API
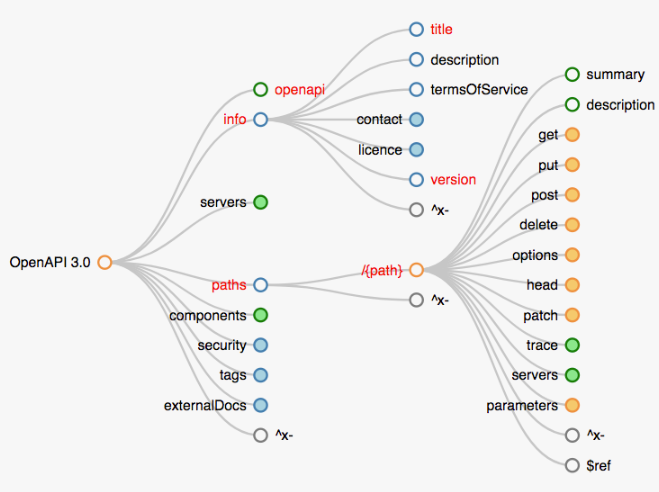
OpenAPI/Swagger – это стандарт формализованного и структурированного описания ваших интеграционных интерфейсов. Допустим, вы разрабатываете и проектируете решение, где у вас большое количество HTTP-сервисов. Чтобы упорядочить работу с этим, можно использовать OpenAPI. По сути, это несколько файлов в форматах JSON или YAML.
Структура древовидная, как на картинке. Если перейти по ссылке https://openapi-map.apihandyman.io, там будет интерактивная майнд-карта, где можно посмотреть, из чего состоит данный формат.
Посмотрим на его ключевые части:
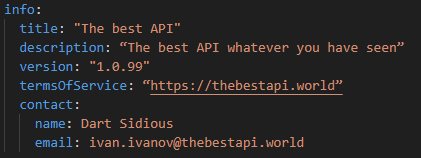
Основная информация о вашем API: его описание, условия использования, ссылки на контакты разработчика.
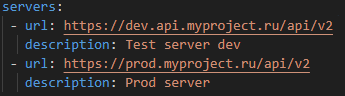
Информация о серверах – их корневые URL.
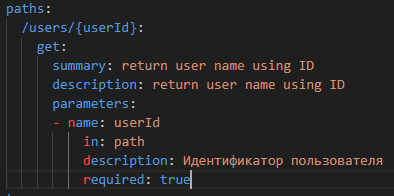
Самое главное – это описание методов с их параметрами.
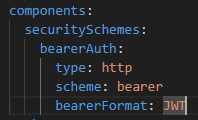
В разделе components хранятся различные переиспользуемые объекты. Вы, например, можете описать схему сообщения, которое будете принимать.
Как нам это может помочь? Считается, что проектирование API – это инструмент архитектора. Вы можете сначала создать спецификацию с помощью OpenAPI, а потом на ее основе приступать к реализации.
Можно сделать и наоборот: добавить в вашу сборочную линию некий инструмент, который при изменении конфигурации метаданных будет собирать это описание и, например, публиковать его в Git или где-то еще.
Также он может помочь значительно упростить тестирование вашего API до его разработки. То есть можно организовать мокирование сервиса, например, с помощью Postman, который позволяет валидировать запрос, если у вас описана схема сообщения.
Автоматизировать работу с этим форматом позволяет фреймворк Swagger. В его состав входят удобный редактор и Swagger UI – инструмент для локального запуска, чтобы можно было представлять спецификацию в удобном виде.
Отказоустойчивый веб-сервер на базе HAProxy и Apache
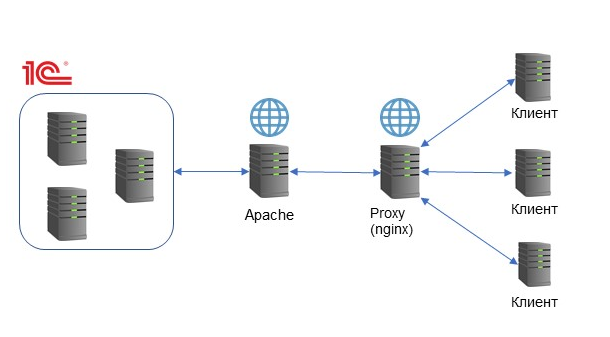
На приведенной выше схеме есть узкие места в плане отказоустойчивости – это веб-сервер Apache и прокси-сервер Nginx. Несмотря на то, что это достаточно устойчивые приложения, любое оборудование может отказывать.
Поэтому, если у вас высокие требования к отказоустойчивости системы в целом, то этот момент является узким местом, и такая архитектура – это не самый хороший вариант.
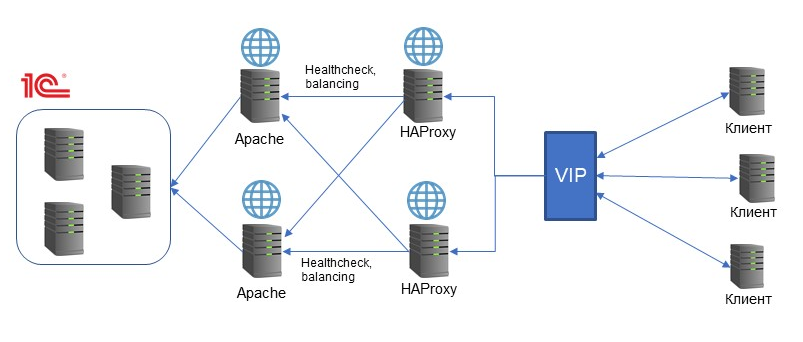
Для повышения отказоустойчивости используются два основных подхода. Первый – это резервирование основных компонентов системы и использование специальных инструментов для балансировки.
Синий квадратик VIP на схеме – это не «very important person», это virtual IP-адрес. Это технология, которая позволяет назначить один и тот же IP-адрес на несколько хостов. Причем один из них будет основным, а остальные – резервными. Если основной вдруг отказал и перестал отвечать на запросы, трафик автоматически переключается на резервный хост и идет дальше.
HAProxy в этой схеме – это тоже open-source инструмент, балансировщик нагрузки и прокси-сервер. Он обладает разными функциями health-check’ов. То есть он может понимать, какой из обрабатывающих серверов в данный момент работает, какой работает лучше, и направлять на него трафик. Apache, в свою очередь, будет взаимодействовать с 1С.
Мы рекомендуем использовать данные инструменты, но надо понимать, что отказоустойчивость имеет свою цену. Внедрение Kafka или Apache с HAProxy требуют вычислительных ресурсов – то есть нужны серверы, которые обеспечат их работу. Также потребуются компетентные специалисты, поскольку данная задача – непростая с инженерной и архитектурной точек зрения. Используйте OpenAPI для систематизации и упрощения работы, если в вашем проекте много HTTP-сервисов.
Оптимизация и автономность РИБ в 1С:Предприятие 8
Начнем разговор об оптимизации РИБ (распределенной информационной базы) с кейса, реализованного для крупного дистрибьютора с филиалами в 35 городах. Интенсивность его работы составляла около 5000 документов в день, при этом центральная база достигала 500 ГБ. Филиалы на тот момент продолжали работать на версии «1С:Предприятие 7.7», а обмен данными выполнялся один раз в сутки — вечером.
Прежде чем приступать к изменениям, важно было определить, какие слабые места типовой РИБ мешают ей быть автономной и требуют постоянного ручного контроля.
-
Нехватка оптимизации: одни и те же данные могут выгружаться повторно, а встроенных проверок, повышающих отказоустойчивость обмена, недостаточно.
-
Трудности с автоматическим обновлением. В нашем случае его вообще не было. В типовой БСП есть автоматическое обновление, но при этом оно надолго блокирует базу.
-
Нехватка удобных инструментов для логирования и отслеживания обменов.
Что было предпринято для оптимизации? В первую очередь мы немного изменили логику общения между узлами: инициатором всегда является главный узел, а подчиненные узлы только отвечают ему.
Второе важное изменение касалось обработки входящих файлов. В типовой РИБ входящий файл сообщения удаляется сразу после успешной загрузки. Мы изменили этот подход: входящий файл удаляется только после того, как успешно выгружен ответный файл обмена.
Благодаря этим двум изменениям обмен стал происходить поэтапно – узлы перестали «перебивать» друг друга.
Также была введена проверка отправителя и получателя. Для этого в узлы был добавлен реквизит для хранения адреса базы узла. В сообщения о выгрузке включили теги с адресом базы отправителя и получателя. При загрузке данного сообщения мы проверяли, соответствует ли адрес базы отправителя адресу, указанному в узле отправителя, и адрес базы получателя – текущей базе.
Таким образом, было исключено попадание в продуктивный контур тестовых данных, копий базы и так далее.
Отдельной идеей была оптимизация состава данных в обмене. На практике встречается ситуация, когда пользователь записывает объект, но фактически не меняет реквизиты. Мы попытались исключать такие записи из обмена, чтобы снизить нагрузку. Аналогично обработали кейс, когда документ проводится и перепроводится, но его реквизиты остаются прежними.
Однако после внедрения этих условий обнаружились случаи, когда в другие базы не попадали действительно нужные данные. Поэтому от механизма пришлось, к сожалению, отказаться.
Итоговая рекомендация: подходить к формированию таких условий объектно. За одним объектом может тянуться цепочка зависимых объектов, которые меняются вместе с ним, но не имеют самостоятельной регистрации в обмене. Если не зарегистрировать основной объект, есть риск, что «обрушится» и вся зависимая цепочка.
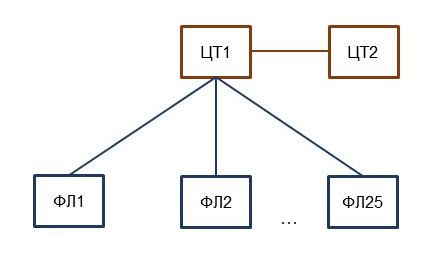
В нашей схеме мы использовали топологию «звезда». При этой топологии самой нагруженной частью является центральная база – в данном случае она обозначена как ЦТ1. Чтобы пользователи и обмен не мешали друг другу, мы создали отдельную базу для пользователей – ЦТ2.
Для скриптов автоматического обновления был выбран PowerShell, так как он является нативным и достаточно мощным решением для Windows. С автоматическим обновлением проблем не возникло, а ручной запуск, так как он инициируется пользователем, требовал UAC-подтверждения. Для обхода этой ситуации было написано два скрипта: первый получает UAC-подтверждение от пользователя и в нужное время запускает второй скрипт, который и выполняет все действия по обновлению.
Алгоритм обновления:
-
Предупреждение, блокировка и завершение работы,
-
Остановка агента 1С:
-
Завершение процессов rmngr/rphost,
-
Удаление сеансовых данных,
-
-
Запуск агента 1С,
-
Обновление конфигурации – 3 попытки (лицензия),
-
Разблокировка и повторный обмен.
Из интересного: в нашем кейсе часто зависали соединения 1С , что мешало получить монопольный доступ к базе для обновления. Помогал только перезапуск службы 1С, но остальные базы кластера при этом ожидаемо отваливались. Чтобы этого избежать, пригодился функционал платформы 1С, позволяющий регистрировать на одном сервере несколько служб с разными портами. В итоге скрипты определяют порты, а также находят по ним процессы rmngr/rphost и службу 1С, связанные с обновляемой базой.
Логирование, мониторинг и архивирование в РИБ
В первую очередь мы добавили запись лог-файлов:, для каждого узла в отдельном логе фиксируются ошибки и процесс обновления.
Чтобы следить за объемами обмена, которые помогают замечать массовые изменения данных (такие как групповое перепроведение документов), мы также начали фиксировать размеры исходящих и входящих сообщений.
Для стороннего мониторинга обменов был выбран Zabbix. Каждые пять минут центральная база отправляет в систему показатель успешности обменов с узлами. Если Zabbix получает менее 100% или центр перестает отправлять сообщения, то система сразу отправляет письма ответственным с указанием проблемы.
Дополнительно разработали отчет, в котором можно увидеть размеры выгрузок и продолжительность обменов в течение дня по каждому узлу. Такой отчет помогает понять, когда происходил пик обмена или когда филиал перестал работать и выгружать данные.
Кроме того, была добавлена панель для мониторинга за состоянием обмена – она запускается при старте у ответственных за обмен пользователей и отображает основные, самые важные показатели. Проблемные узлы подсвечиваются, также из панели можно открыть все каталоги и логи обмена.

Если для создания нового узла обмена не хватает технологического окна, процесс можно организовать через «копию» центрального узла. Сначала на центральном узле создается новый узел, затем разворачивается копия центральной базы, и формирование начального образа продолжается уже в этой копии. После этого узел настраивается стандартным образом и подключается к обмену с центральной базой.
Особенность свертки баз РИБ заключается в том, что их количество может быть достаточно большим. Чтобы при свертке избежать расхождения данных между базами, сворачивается только центральная база, а регистры для скорости очищаются с помощью SQL-скриптов. Сами объекты изменяются и удаляются непосредственно в 1С, либо регистрируются для обмена отдельно.
При каждой свертке появляются архивные базы для длительного хранения, и важно, чтобы архивные документы можно было выборочно загрузить в рабочую базу.
В новых архивных базах поднимается веб-сервис, через который пользователь из рабочей базы получает список архивных документов, указывает период, происходит подключение к архивной базе за запрашиваемый год. Так как конфигурации полностью идентичны, работают все отборы по реквизитам, доступен предварительный просмотр документов и их загрузка.
Таким образом работа с архивными документами происходит полностью бесшовно.
Когда нужен РИБ: применение, плюсы и минусы
РИБ особенно полезен при территориальной удаленности филиалов, когда важно, чтобы все они продолжали работать, даже если связь нестабильна или центральная база недоступна из-за аварии электросети.
Еще один практический сценарий – это ограничение прав доступа: в базе каждого подразделения остаются только свои документы и связанные с ними данные. Такой вариант работает быстрее, чем ограничение данных через RLS, к тому же сама база меньше, а работает отзывчивее.
Плюсы РИБ:
-
Масштабируемость и распределение нагрузки,
-
Широкие возможности кастомизации,
-
Типовая технология, меньше стоимость специалистов.
Минусы РИБ:
-
Актуализация состава обмена,
-
Требуются доработки типового механизма.
РИБ, как и любая технология, требует взвешенного применения. Он не потерял актуальности, но на фоне развития шин данных и других технологий обмена его использование стало менее повсеместным. Там, где нужна строгая автономность филиалов и устойчивость к сбоям связи, РИБ остается сильным решением.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт