


{kind=link}
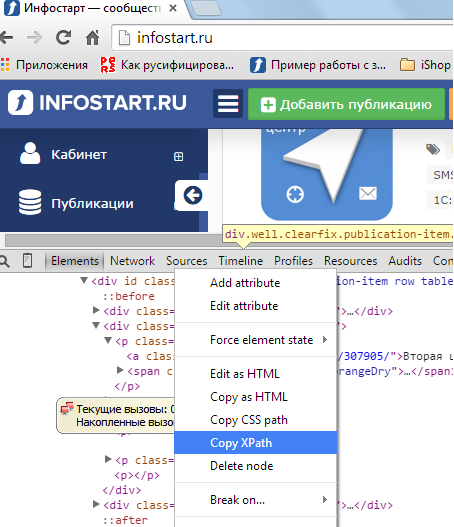
В процессе анализа сайтов с помощью браузера Chrome часто обращал внимание на пункт меню "Copy XPath"

После нескольких попыток разобраться как же это реализовано в 1С, почти забил.
Но нашел пример использования для Экселя http://www.ozgrid.com/forum/showthread.php?t=183596
Приписал для 1С . Результат представляю на Ваш суд
&НаКлиентеНаСервереБезКонтекста
Функция getXPathElement(sXPath, objElement )
// Split the xpath statement
лМассивХР = СтрЗаменить(sXPath, "/",Символы.ПС);
лИндексНоды = СтрПолучитьСтроку(лМассивХР,1); //лИндексНоды
Если Найти(лИндексНоды, "@id") > 0 Тогда
лИмя = СтрЗаменить(лИндексНоды,"[","");
лИмя = СтрЗаменить(лИмя,"]","");
лИмя = СтрЗаменить(лИмя,"=",Символы.ПС);
лИмя = СтрПолучитьСтроку(лИмя,2);
лИмя = СтрЗаменить(лИмя,"""","");
ЛobjElement = objElement.ПолучитьЭлементПоИдентификатору(лИмя);
лМассивХР = СокрЛП(СтрЗаменить(лМассивХР,СтрПолучитьСтроку(лМассивХР,1),""));
лИндексНоды = СтрПолучитьСтроку(лМассивХР,1);
Иначе
ЛobjElement = objElement;
КонецЕсли;
If Not Найти(лИндексНоды, "[") > 0 Then
sNodeName = лИндексНоды;
lNodeIndex = 1;
Else
лИндексНоды = СтрЗаменить(лИндексНоды, "[",Символы.ПС);
лИндексНоды = СтрЗаменить(лИндексНоды, "]",Символы.ПС);
sNodeName = СтрПолучитьСтроку(лИндексНоды,1);
lNodeIndex = Число(СтрПолучитьСтроку(лИндексНоды,2));
EndIf;
sRestOfXPath ="";
Для Сч =2 По СтрЧислоСтрок(лМассивХР) Цикл
sRestOfXPath = sRestOfXPath + ?(Сч=2,"","/")+СтрПолучитьСтроку(лМассивХР,Сч);
КонецЦикла;
getXPathElement = Неопределено;
лСчЭлементов = 0;
For lCount = 0 To ЛobjElement.ДочерниеУзлы.Количество() - 1 Цикл
If ВРег(ЛobjElement.ДочерниеУзлы.Item(lCount).ИмяУзла) = ВРег(sNodeName) Then
лСчЭлементов = лСчЭлементов + 1;
If lNodeIndex = лСчЭлементов Then
If sRestOfXPath = "" Then
getXPathElement = objElement.ДочерниеУзлы.Элемент(lCount);
Прервать;
Else
getXPathElement = getXPathElement(sRestOfXPath, ЛobjElement.ДочерниеУзлы.Элемент(lCount));
Прервать;
EndIf;
EndIf;
EndIf;
КонецЦикла;
Возврат getXPathElement;
КонецФункции
Публикую после тестирования в своей обработке (т.е. прошла боевую проверку).
Пользоваться оказалось очень удобно :
ЧтениеHTML = Новый ЧтениеHTML;
ЧтениеHTML.УстановитьСтроку(ОтветСервера);
ПостроительDOM = Новый ПостроительDOM;
ДокументHTML = ПостроительDOM.Прочитать(ЧтениеHTML);
// Соберем данные из оглавления каталога
СтрокаХР = "[@id="+""""+"ContentWrapper"+""""+"]/div[1]/div[1]/ul";
лКаталог = getXPathElement(СтрокаХР, ДокументHTML);
ОтветСервера - Это чистый HTML, в моем случае полученный как ответ WinHttp.ResponseText
Вступайте в нашу телеграмм-группу Инфостарт