Классификация проблем производительности
Давайте немножко помечтаем:
Вы работаете в крупной корпорации и вам поставлена задача оптимизации информационной системы. Вы, конечно же, располагаете определенными знаниями, владеете несколькими языками программирования, но оптимизацией ранее вам заниматься не приходилось.
Для более простого понимания проблем производительности, мы их разделили на несколько групп.
-
Первая группа – легковоспроизводимые проблемы. Я уверен, что вы с ними сталкивались повсеместно. Это может быть оптимизация запросов, неоптимальность алгоритма, различные индексации полей, если они требуются. Про эти проблемы написаны десятки книжек, сотни статей. Компания 1С и прочие крупные франчайзинговые компании разрабатывают курсы «Эксперт по технологическим вопросам» и прочее. Подобные проблемы, как правило легко воспроизвести на тестовой базе данных в однопользовательском режиме и, обычно они исправляются самими специалистами компании.
Вторая группа - это проблемы непостоянные и непредсказуемые. Наверняка, вы тоже отчасти с этим сталкивались, но, возможно, представляли совсем другую их природу. Это могут быть проблемы, которые неожиданно появляются. Например, это падение на каком-нибудь узле – пользователя, сервера приложений или торможение системы в определенный момент. В общем-то, причинами этого всего может быть что угодно, в том числе выполнение регламентного задания, которое приводит к сбою или вызывает общее торможение ИС в момент своей работы. А может быть – банальная халатность персонала. Для таких проблем обычно должна использоваться другая методика решения и обнаружить их можно только при многопользовательском режиме работы.
Третья группа – это проблемы предсказуемые, но сложно решаемые, я специально выделил их в особую группу. О них частично упоминал Алексей Лустин в своем докладе. Вы понимаете, что никакими средствами 1С не решить определенные задачи (для примера возьмем проведение больших регламентных документов, восстановление последовательностей, которое не укладывается у вас в определенное время). Соответственно, вы понимаете, что эти проблемы есть, вы понимаете, что их надо решать, но не понимаете, как это сделать. Для решения подобных задач используется ряд технологий, такие как параллельные вычисления, распределенные дисковые хранилища и пр.
На картинке не зря присутствует изображение с рукой, которая измеряет дыхание или меряет пульс. Между медициной и оптимизацией легко увидеть аналогию, в общем-то, все те же самые «профилактические процедуры» вы можете встретить и в медицине. Для "лечения" системы мы используем практически все те же самые средства, которые врачи используют для лечения человека. ИТ система — это тоже многофакторный сложный организм. К ее исследованию нельзя подходить «в лоб», и без учета хотя бы основных факторов, делать какие-то заключения.
"Жили мы, жили без проблем… и вдруг…они появились" - собственно, так не бывает. Проблемы существуют, но не всегда их диагностируют вовремя (заранее) и во многих случаях они скрываются за мощным оборудованием. Стоит упомянуть о способах их решения. В момент, когда в отрасли компьютерной техники происходил бурный рост – увеличивалась частота процессора – проблемы, которые у нас тогда все равно были – мы решали простой покупкой нового оборудования – частота растет, диски улучшаются, объем памяти увеличивается – все решается автоматом. А где-то уже в начале 2000-х годов, когда частоту процессора увеличить было нельзя, процессоры стали многоядерными. Наступила другая эпоха - когда свойство информационной системы к масштабированию на все ядра процессора стало гораздо важнее, чем общая производительность аппаратных ресурсов.
Поиск причин проблем производительности
Если взять ситуацию, при которой ваша система хоть какое-то время в начальном периоде работала приемлемо, то основные причины деградации производительности это:
- Плохое качество контроля - информационную систему запустили и не следили за ее параметрами
- Бурный рост компании привел к тому, что увеличились информационные потоки, а IT-инфраструктура не поспевает за этим процессом. Конфигурация, предназначенная для автоматизации бизнеса вашей компании, сначала разрабатывалась одним программистом, потом двумя-тремя-четырьмя, потом происходили рокировки в числе разработчиков, образовывались тупиковые ветки функционала, алгоритмы, в которых никто не может разобраться… Система вышла из-под контроля.
- При внедрении нового функционала не всегда проверяется его влияние на производительность. В частности, не проводятся нагрузочные тестирования, либо тестирование не затрагивает новый функционал. Эта причина, в основном связана с уровнем развития IT-инфраструктуры в целом в организации. Чаще всего на это закрывают глаза, думая, что, купив дорогостоящие программные или аппаратные ресурсы, можно это решить.
Особенности проектов по оптимизации производительности информационных систем
Интересно обсудить отличие проектов оптимизации, от автоматизации.Есть несколько специфичных особенностей проектов производительности, которые надо учитывать:
Первая особенность проектов по оптимизации производительности
Первую особенность проектов по оптимизации производительности можно сформулировать так:

Другими словами, объясним "на пальцах" посредством аналогии из медицины: если человек испытывает сильную боль, то более слабая боль отходит на второй план – человек ее даже не чувствует. Это обстоятельство всегда надо учитывать, и не заблуждаться на счет того, что проблемы все находятся на поверхности. Не факт, что очевидные для вас причины текущих проблем производительности являются единственными.
Вторая особенность проектов по оптимизации производительности
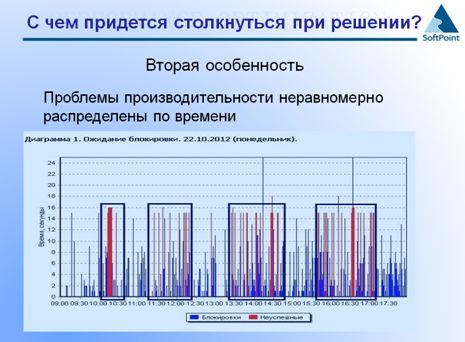
Вторая особенность проектов производительности заключается в том, что проблемы производительности неравномерно распределены во времени.
Если вы решаете проблемы из второй и третьей групп (проблемы непостоянные и непредсказуемые или предсказуемые, но сложно решаемые), то обычно бывает, что система в принципе хорошо работает почти весь день. 7 часов стабильной работы – 15 минут система стоит. Дальше снова работаем весь день, и 15 минут система опять стоит. Может быть много факторов, от которых это может зависеть: регламентные операции, административные мероприятия – отгрузки, акции, сезонность, т.е. множество факторов… Но вы должны помнить, что эти «зависания» системы сосредоточены в определенных временных участках.
Третья особенность проектов по оптимизации производительности

Не надо думать, что проблем – 1000. Несмотря на то, что у вас большое количество строк кода, проблем у вас как раз-таки, ограниченное количество. Экономисты эффективно пользуются законом Парето, который говорит о том, что 20% усилий можно добиться 80% результата.
Конечно, это абсолютно не подтвержденный математически закон, но он актуален и для производительности.
Как показывает практика, проблемных мест ограниченное количество (3-5 ). Основная цель – их найти.
Четвертая особенность проектов по оптимизации производительности
Четвертая особенность заключается в том, что объективных данных бывает недостаточно – некоторые данные могут быть получены только от пользователей. А субъективное мнение пользователей не всегда соответствует реальному положению дел.

У вас есть объективные результаты – количество ошибок, длительности проведения и прочее. А еще есть пользователи, которые, под влиянием множества факторов могут давать неправильную оценку, искажать ситуацию своим субъективным мнением.
Опять же вернемся к медицине. Человек приходит на прием. Перед тем, как отправить пациента на комплексное обследование, врач просит его заполнить анкету, в которой много-много пунктов, по каждому из которых нужно дать ответ в виде оценки по 10-бальной шкале (болевые ощущения, крепкий сон, проблемы с пищеварением и пр.). Оценив ответы пациента, врач направляет его на сдачу анализов. И теперь – уже видна комплексная картина – анализы человека в качестве объективной оценки болезни и собственная субъективная оценка ситуации самим пациентом. Комплексно оценив картину, врач назначает лечение.
Требования, которые необходимо соблюдать для ведения проектов по оптимизации производительности системы
Мы рассмотрели особенности, которые надо учитывать, теперь надо рассмотреть требования, которые необходимо соблюдать при проектах для поиска проблем второй и третьей группы.
Первое требование к ведению проекта по оптимизации производительности системы
Первое требование – это непрерывный качественный мониторинг. За этими простыми словами скрывается очень большой смысл.
Если этот критерий не соблюдать – включать анализ только на 15-20 минут, то это будет своего рода «рыбалка». Вы стараетесь «поймать причину проблему», но на самом деле, может быть там, когда проблема произошла, были причины, которые сейчас отсутствуют. Если у вас нет качественного, не нагружающего систему мониторинга, то в следующей ситуации, когда вы что-то "поймали" – вы подумали – это «то что надо», а на самом деле – это уже совсем другая проблема с другими причинами.
Конечно, "лечить" надо и то, и другое, но все-таки важна определенность при анализе. Нужно использовать это требование и собрать максимальное количество знаний, чтобы потом можно было вернуться к истории и посмотреть – что же конкретно происходило в системе в этот момент.
Второе требование к ведению проекта по оптимизации производительности системы
Второе требование – это Step by Step
Проекты оптимизации, в отличие от других проектов, нельзя параллелить. Вы делаете первую итерацию и, если ваш ресурс 10 человек, вы не можете распределить между ними все проблемы, которые на первом этапе вы увидели.
Почему? Потому что система – это сложный организм, и, при решении первой, все остальные проблемы (вторые и последующие) перераспределяются, а возможно и исчезнут.
Вам нет смысла оптимизировать все строчки, потому что может так случиться, что после первой итерации они сами уйдут из проблемных. Эту сложность параллельной работы надо учитывать.
Третье требование к ведению проекта по оптимизации производительности системы
Третье требование – необходимо принять тот факт, что нахождение первопричины может занять больше времени, чем ее исправление.
Нужно выстроить цепочку событий, которые привели к проблеме производительности. При этом важно найти первое событие в цепочке, оно и будет первопричиной. Если мы эту первопричину не найдем, значит мы не эффективно потратили свое время.
Четвертое требование к ведению проекта по оптимизации производительности системы
Четвертое требование – касается аргументации.
Мы должны взять себе за правило, что по всем своим решениям – будь то «Переключатель установить в это состояние», а «Этот флажок установить в это состояние» - касательно настроек MS SQL, Windows, 1C… - вы должны четко знать, что к этому по вашей системе были предпосылки в виде данных.
Если вы основываетесь в своих решениях на форумах, на базах знаний – вы должны понимать, что вероятность ошибок достуточно большая. Можно черпать методики, как люди делали, но не брать готовое решение – универсальных настроек не бывает, иначе бы их поставили в правильное положение сразу.
Пятое требование к ведению проекта по оптимизации производительности системы
Пятое – это даже не требование. Это необходимость.
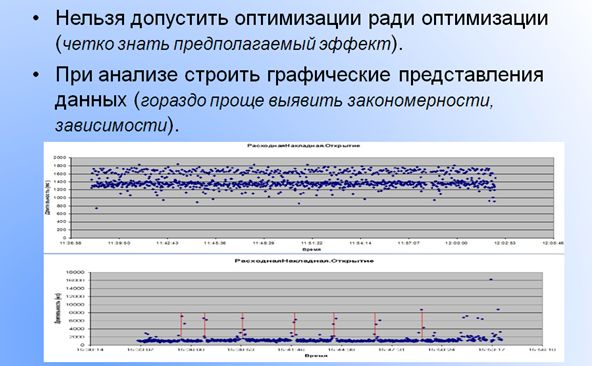
Чем это требование отличается ото всех остальных? Тем, что на начале проекта оптимизации вы должны определить свои главные цели (ваш планируемый результат) – нельзя вступать в проект и делать «Оптимизацию ради оптимизации». В общем-то, если вы не видите четких критериев, что улучшиться – вы ввязываетесь в очень тяжелое дело.
То есть, по сути, вам необходимо для всех измеряемых показателей строить графические представления. Если бы мы работали по максимальным средним величинам – мы бы не увидели бы эти закономерности двух графиков на рисунке.
Видите, там есть дельта и определенные периодические всплески на втором графике. Эта длительность – длительность ваших операций. Соответственно, особенно по второму графику очевидно, что длительность определенных операций может увеличиваться в разы (в пять, в шесть). Видно, что периодичность таких увеличений совпадает. У вас есть объективные данные, для того, чтобы посмотреть внимательно, что происходит по расписанию в это время. Возможно, это какие-то фоновые административные задачи, а возможно, что-то еще.
Предпосылки к оптимизации производительности информационных систем
Есть несколько направлений оптимизации производительности:
- Оптимизация блокировочного механизма
- Оптимизация конфигурации
Предпосылки к оптимизации блокировочного механизма
Рассмотрим предпосылки к оптимизации блокировочного механизма.
Основной ход рассуждений должен быть такой – если у вас в системе есть ОШИБКИ НА БЛОКИРОВКАХ, увеличение по сравнению с однопользовательским режимом длительности выполнения транзакций и НЕДОЗАГРУЖЕННОСТЬ РЕСУРСОВ – то, соответственно, в этом случае у вас есть полные предпосылки к оптимизации блокировочного механизма.
У вас может возникнуть резонный вопрос – а что значит «недозагруженность»? Дело в том, что в условиях полной загрузки оборудования становится очевидно, что скорее всего именно перегрузка оборудования является причиной того, что у вас повышен уровень блокировок. А вот уже недозагруженность говорит о том, что ресурсы свободны и ничего не мешает транзакциям выполняться максимально быстро. Значит – есть некое неоптимальное «блокировочное множество», которое мешает параллельной работе.
Вопрос аудитории – а если нет ошибок на блокировках? К чему это может быть предпосылкой? Тут надо проверять глубже. Если есть ошибки, значит, сработали «таймауты». Возможно, ваши длительности просто не доскочили до «таймаута». Вам надо посмотреть, собрать более подробную информацию из SQL, из технологического журнала 1С (если это управляемые блокировки) и посмотреть, есть ли вообще событие ожидания.
Предпосылки к оптимизации конфигурации 1С
Случается, что надо просто оптимизировать конфигурацию 1С (изменить селективность измерений, проиндексировать ключевые измерения). Какие могут быть к этому предпосылки?
В общем-то, ничего, кроме большой длительности выполнения операций в 1С не является предпосылкой к тому, чтобы оптимизировать конфигурацию 1С.
В основном эти ошибки относятся к первой группе - их, чаще всего, можно решить без привлечения сторонних специалистов.
Предпосылки к оптимизации конфигурации 1С посредством параллельных вычислений
Какие еще могут быть предпосылки к оптимизации? Например, предпосылки посредством параллельных вычислений.
Это длительность операций в 1С. Недозагруженность аппаратных ресурсов. И в операции есть набор «псевдонезависимых» действий друг от друга (ничего независимого в нашей жизни, к сожалению, нет) – просто эти действия мы можем как-то логически разделить, для того, чтобы выполнять эти действия в разных потоках.
Инструмент, применяющийся в проектах по оптимизации производительности
Теперь – самое интересное. Что же нам позволяет соблюдать все требования при ведении проектов по оптимизации?
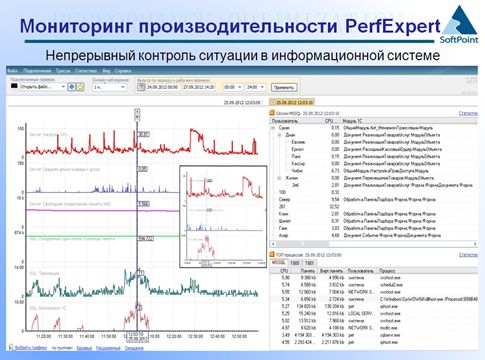
Нам это позволяет система мониторинга PERFEXPERT, которая первоначально была разработана специально для внутренних нужд (сейчас это уже коммерческий продукт).
Эта система – не часть системы 1С, она внешний наблюдатель, ваш бортовой самописец.
Она позволяет, не нагружая сервер, постоянно мониторить все данные, причем, не только с базы данных, но и из сеансов пользователей 1С, из сеансов сервера приложений, из сеанса сервера СУБД.
С помощью математики, она сопоставляет запросы 1С и SQL, и вы получаете информацию сразу же в нужных вам разрезах.
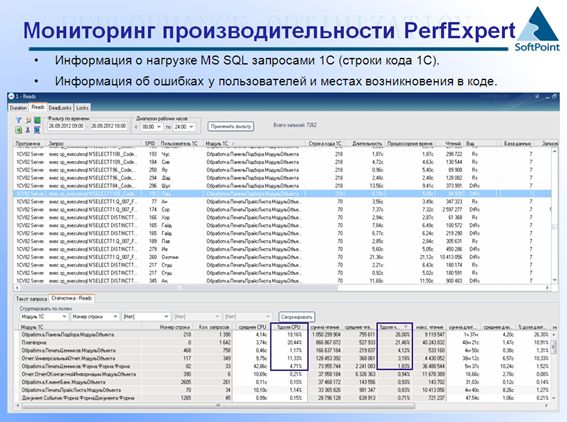
На этом слайде видно, какие строки кода 1С вызвали проблемы, и можем привлечь все свои ресурсы 1С на эти пять строчек, которые занимают более 70% ресурсов по CPU и более 70% по диску. Вы сразу видите, как каждая строчка вашего кода влияет на работоспособность MS SQL и это измерение конкретных ресурсов CPU и конкретных величин логического чтения с диска. Вы понимаете, что от этого зависит и эффективность использования кэша, и дисковая нагрузка.
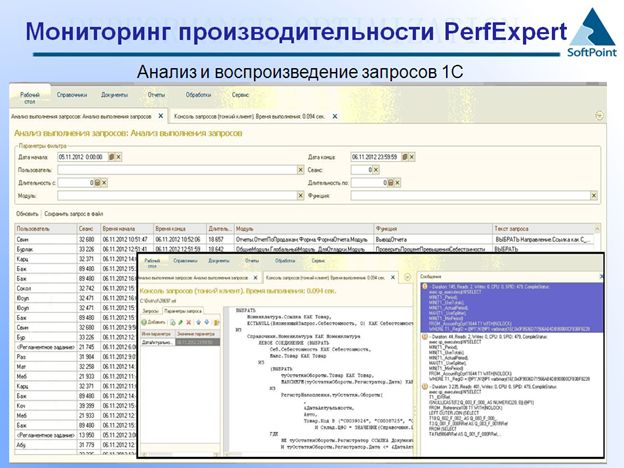
Инструмент для анализа и воспроизведения запросов 1С
Наш сервис мониторинга развивается, в нем появился ряд инструментов для работы с запросами, есть возможность минимальными усилиями по внедрению замерить запрос 1С, записать его параметры и воспроизвести его на тестовой базе с нужными выборками. Это важно для построения планов запросов и оптимизации различных выборок.
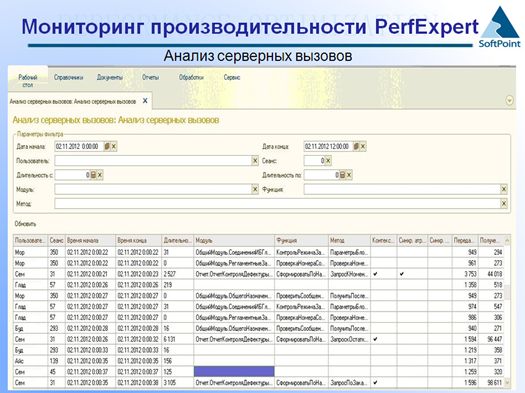
Инструмент для анализа серверных вызовов (замера трафика между тонким клиентом и сервером приложений)
Дальше, в нашем сервисе есть инструмент для тонких клиентов, который создан для того, чтобы можно было оценить влияние клиент-серверного взаимодействия между тонким клиентом и сервером приложений. У разработчиков уже есть рекомендации относительно того, как надо правильно писать код при работе с тонким клиентом. Но, тем не менее, есть ряд рабочих систем, где код написан без учета этих рекомендаций. То есть, там используется слишком много клиент-серверных вызовов и это делает невозможным параллельную быструю работу тонких клиентов (к тому же, это сложно отлаживается). Этот комплекс помогает замерять трафик между тонким клиентом и сервером приложений. Замеряет длительности, устанавливает, была ли это синхронизация данных и т.д.
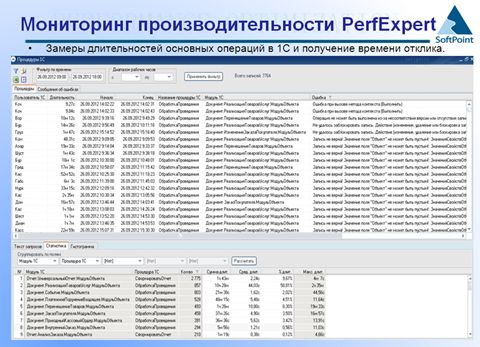
Механизм работы сервиса
Один важный момент – наш сервис мониторинга получает информацию с помощью ВК от пользователей о длительности всех операций в системе. То есть, вам не надо для каждой операции внедрять код 1С. Вам надо просто внедрить внешнюю компоненту, и она тотально соберет вам все данные по всем обработкам проведения, всем выполнениям отчетов, обработок и прочего.
Какие это дает возможности?
Во-первых, эта ВК это делает очень быстро. Практически не нагружая систему (нагрузка составляет порядка 2-3%). Самое главное – эта информация приходит именно от клиента, и это реальный отклик системы. Это очень важно.
Более того, система перехватывает все ошибки, которые были у пользователя, в том числе и синтаксические и ретранслирует их в мониторинг для того, чтобы вы ПРОактивно действовали в вопросе некорректной работы и кода, и ошибок у пользователей.
Когда вам звонит пользователь – это уже Реакция на событие.
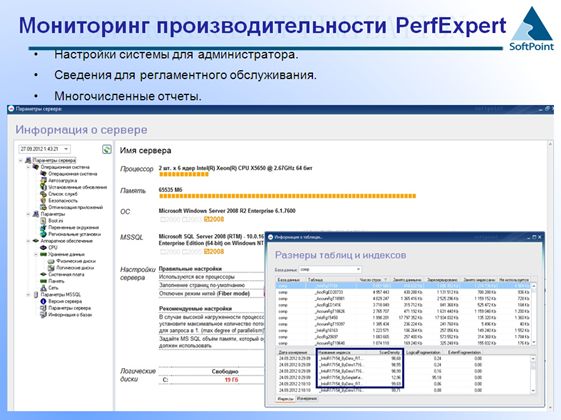
Административные возможности
У сервиса мониторинга производительности есть много административных возможностей. Например, вы можете проследить за тем, правильно ли вы обслуживаете базу данных. Мониторинг собирает вам данные о дефрагментации индексов, о ваших настройках, о расположении файлов, различные дифференцируемые нагрузки на CPU и пр.
Применение сервиса мониторинга производительности на практике
Хотелось бы показать на практике, как можно использовать сервис мониторинга производительности. Перед нами стоит простой пример, он очень методический и показательный. Отнеситесь к нему, пожалуйста, очень внимательно. Цель – показать один из способов анализа типовой проблемы производительности.
У вас тормозит диск, и пользователи жалуются на «торможение».

У вас тормозит диск – сотни форумов пестрят вариантами расчета "цилиндров". Начинается расчет головки, как увеличить пропускную способность диска, прорабатываются варианты того, как его можно ускорить – сделать дисковый массив или что-то еще купить…

Здесь важно помнить следующую вещь: кому вы хотите сделать лучше – диску или пользователям? Наверняка пользователям, и этот подход, который вы выбираете, пытаясь улучшить характеристики диска, принципиально неверен.
Вы ведь не проанализировали, а почему диск у вас тормозит. Вы «априори» заявили, что у вас все правильно и диск – это самое узкое место. На самом деле это не так. Для того чтобы узнать причину, почему диск тормозит, вы как раз и можете использовать данные мониторинга производительности. Здесь наглядно видны преимущества графического представления данных о нагрузке на систему.
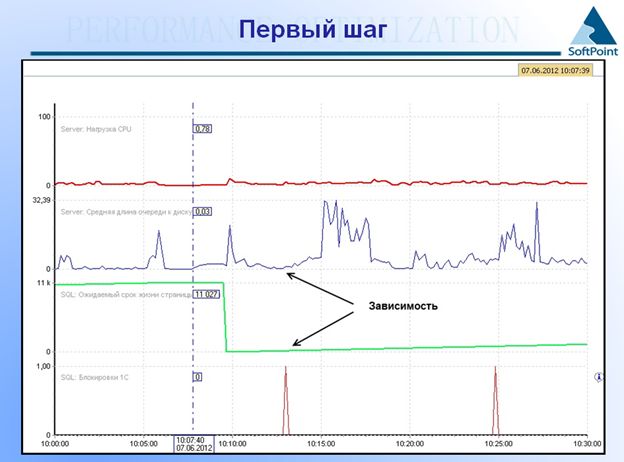
Вы видите графики, которые расположены друг под другом. Эти графики могут быть построены с абсолютно разных машин. С помощью линейки, которую вы можете двигать по экрану, вы можете смотреть корреляцию, масштабировать картинку. И вы получаете результат – оказывается, что есть график «Ожидаемый срок жизни страницы памяти», который описывает прогнозируемое время, которое страница задерживается в кэше MS SQL. Соответственно, мы видим, что очередь к диску возрастает именно в момент, когда упало значение этого графика – уменьшилось время жизни страницы в кэше. Вы нашли причину того, почему у вас тормозит диск.
Потому что какой-то процесс, какие-то запросы, какой-то пользователь или что-то еще выдавили какие-то необходимые данные из кэша. И получается, что все пользователи, не находя там, в оперативной памяти эти данные, берут их из диска. Поэтому диск и тормозит
Соответственно, что надо делать в этой ситуации:

Находится второй "умелец", который говорит – а давайте мы увеличим память. А что такого? Раз кэш проседает, значит, памяти не хватает.
Опять возвращаясь к аналогиям из медицины – это то же самое, что зубную боль лечить обезболивающими. Вроде как боль не чувствуется, а зуб-то все равно разрушен – проблема не решается. В один прекрасный момент это средство уже не сможет решить проблему.
Соответственно, мы видим, что при добавлении оперативной памяти мы вроде как эффективно решили нашу проблему, однако, когда, допустим, через 2 года, эта проблема у вас проявится снова, вы с ней уже ничего не сможете сделать, потому что она будет у вас настолько запущена, что объем исправительных работ увеличится в разы.
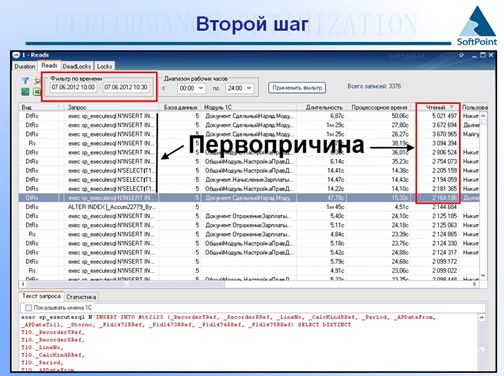
Соответственно, лучше посмотреть по поводу кэша: а кто повлиял – какие процессы, какие запросы повлияли на то, что кэш в памяти упал – для этого нам опять пригодится сервис мониторинга производительности. Обратившись к его данным, мы можем увидеть, что в этот диапазон времени, когда у нас слетел график «Ожидаемый срок жизни страницы памяти», у нас сильно изменилось значение некоторого показателя. Это не мифический какой-то показатель – это количество чтений, которое необходимо для того, чтобы получить выборку из запроса. Мы можем посмотреть запросы, которые явились причиной тому, что кэш MS SQL уменьшился до критической величины.
После того, как мы этой логической цепочкой прошли, самый эффективный способ – это проанализировать эти запросы и, возможно, надо банально поставить галочку в конфигураторе «проиндексировать».

Выводы
"Не важно кто ударит по гвоздю, важнее кто покажет куда бить". Аналогично с оптимизацией: намного сложнее найти первопричину, чем ее устранить.
Повышение масштабируемости в проектах по оптимизации производительности информационных систем
Теперь – самое интересное. Я хочу рассказать вам о нашей новинке.
В этом году нам удалось очень сильно продвинуться в плане горизонтального масштабирования серверов баз данных SQL Server.
Фирма 1С разработала кластер сервера приложений. Этот кластер позволяет масштабировать нагрузку на второе звено трехзвенной архитектуры. Вы знаете, что терминалы давно масштабировались, с этим не было проблем. Были проблемы с масштабированием сервера MS SQL.
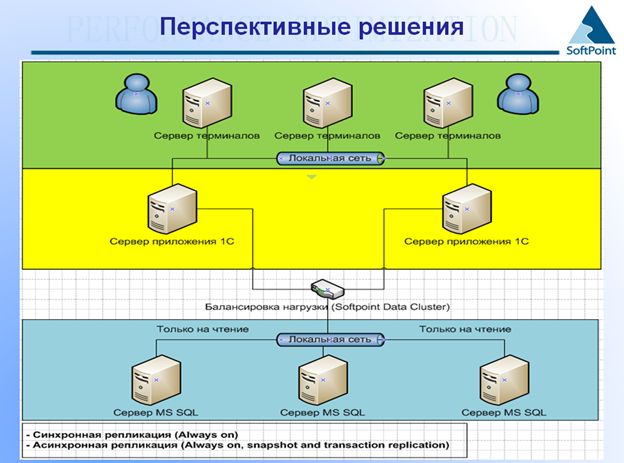
Это не сервер в режиме file-over, который был до последнего времени. Режим file-over использовали только для резервного копирования – его нельзя было использовать для масштабирования нагрузки. Это была основная проблема к тому, что оборудование не простаивало. Также был такой момент – это было одно дисковое хранилище: две железки обращались к одному дисковому хранилищу и там переключались. В нашем новом решении мы используем полноценные сервера (в приведенном примере их три). На первый сервер можно направить нагрузку по оперативной работе транзакционной. А на второй и третий можно направить, например, запросы на получение отчетов.
Более того, это может делаться в несколько режимов. Первый режим, который полностью работоспособен, работает по технологии Always on – технологии, которая появилась в MS SQL 2012 (технологии синхронной репликации). При работе в этом режиме, эти три узла синхронно обновляются в рамках транзакций. Единственное ограничение – у нас не может быть больше четырех узлов.
****************
Приглашаем вас на новую конференцию INFOSTART EVENT 2019 INCEPTION.