Началось все с одной истории, которая три года назад случилась в моей профессиональной карьере, когда я работал в Киргизии, в компании, которая представляла собой сеть розничных магазинов. Тогда у меня произошел разговор с моим директором по IT, который сказал: «Денис, у нас одна из важных, критичных операций – это проведение документа «Чек» на кассах. Как мы можем максимально ускорить этот процесс, распараллелить его, при этом получая оперативные остатки?»
Сразу скажу, что у нас на тот момент использовалась платформа 8.1 и автоматические блокировки. И я тогда ему ответил, что да, мы можем перейти на управляемые блокировки и распараллелить этот процесс на уровне номенклатуры. На что он мне задал естественный вопрос: «а что произойдет, если у нас на нескольких кассах одновременно будет проводиться одна и та же номенклатура?» Тогда я на этот вопрос какого-то внятного ответа дать не смог, но надеюсь, сейчас у меня это получится.
Тренды развития аппаратного обеспечения

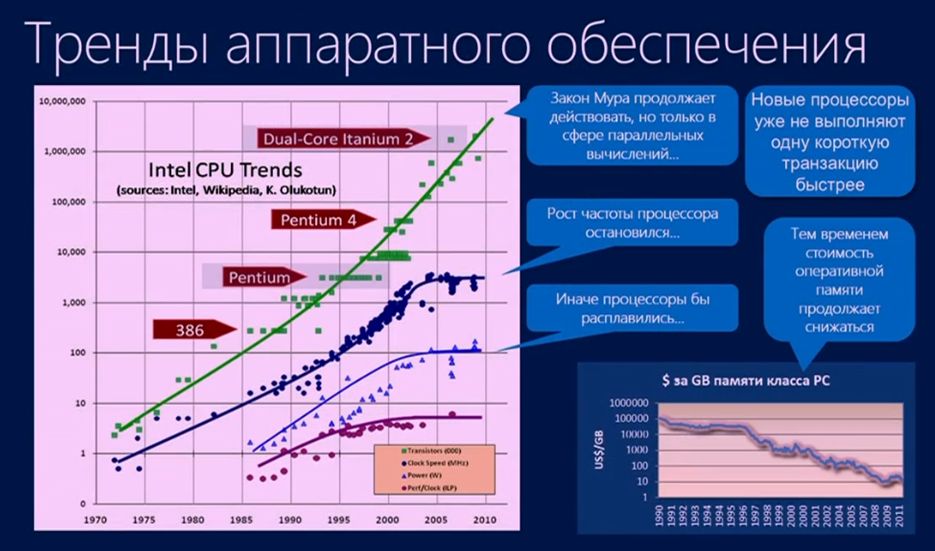
Если мы посмотрим на развитие индустрии IT за последние несколько лет, мы увидим определенные тренды в аппаратном обеспечении:
- Первый тренд касается памяти. Ни для кого не новость, что память со временем дешевеет, и на данный момент мы уже можем получить достаточно большой объем памяти за сравнительно небольшие деньги.
- Второй тренд – по процессорам. Всем известно соответствие роста производительности, потребляемой мощности и выделяемой температуры процессоров по закону Мура. В определенный момент это соответствие на уровне одного ядра закончилось (сейчас у нас одно ядро уже долгое время не может выполнять одну простую операцию быстрее, чем раньше), но оно продолжилось на уровне многих ядер (многоядерных процессоров). Поэтому все наши надежды и помыслы идут в область параллельных вычислений, и мы, как разработчики и архитекторы СУБД, для повышения производительности наших приложений должны планировать в них параллельность работы.
Тренды развития бизнес-приложений

А что в это время происходит на уровне бизнеса? Мы наблюдаем: все большее количество пользователей, которые используют все большее количество устройств, на которых выполняется все большее количество программ, и все это в свою очередь генерирует все большее количество данных.
При этом большинство из этих процессов поддерживаются облаками.
Помимо облаков есть еще такая сущность, как мобильность, которая представляет собой сочетание всех мобильных устройств, а также программ и данных, ими генерируемых.

Облака и мобильность всегда были связаны между собой, и именно от взаимодействия этих двух сущностей мы в будущем сможем получать какие-то прорывы. Такое взаимодействие привело к появлению известной на Западе стратегии: Mobile-First – Cloud-First (изначально мобильное и изначально облачное).


Индустрия IT всегда менялась, и сейчас меняется, испытывает трансформацию. И в этом мире, изначально мобильном и изначально облачном, непрерывно возрастает темп формирования этих данных, и рост этот – экспоненциальный. Исходя из этого возникает проблема сохранения, накопления и актуализации информации, которая со все возрастающей скоростью попадает в наши системы.
Соответственно, возникает потребность в специальных технологиях. И, если касаться конкретно In-memory OLTP, то это – всего лишь одна из многих технологий, призванных на данный момент обеспечить дальнейшее развитие IT-индустрии.
Технология In-memory OLTP
 Почему появилась технология In-memory OLTP? И почему она важна?
Почему появилась технология In-memory OLTP? И почему она важна?
- Дело в том, что бизнес предъявляет все большие требования:
- к всевозрастающей пропускной способности:
- к ожидаемому OLTP процессу с прогнозируемой скоростью и минимальными задержками и за небольшие деньги.
- В свою очередь аппаратное обеспечение предъявляет требования к реляционным базам данных, чтобы они соответствовали последним изменениям в архитектуре аппаратного обеспечения.
Соответственно, In-memory OLTP – это: высокопроизводительный механизм, который отвечает современному аппаратному обеспечению и максимально оптимизирован для работы с памятью.
И, что самое важное, In-memory OLTP – это не какой-то отдельный продукт (не какая-то отдельная лицензия, за которую нужно платить). Начиная с SQL Server 2014 In-memory OLTP – это часть ядра этого продукта, которая доступна в рамках редакции Enterprise.

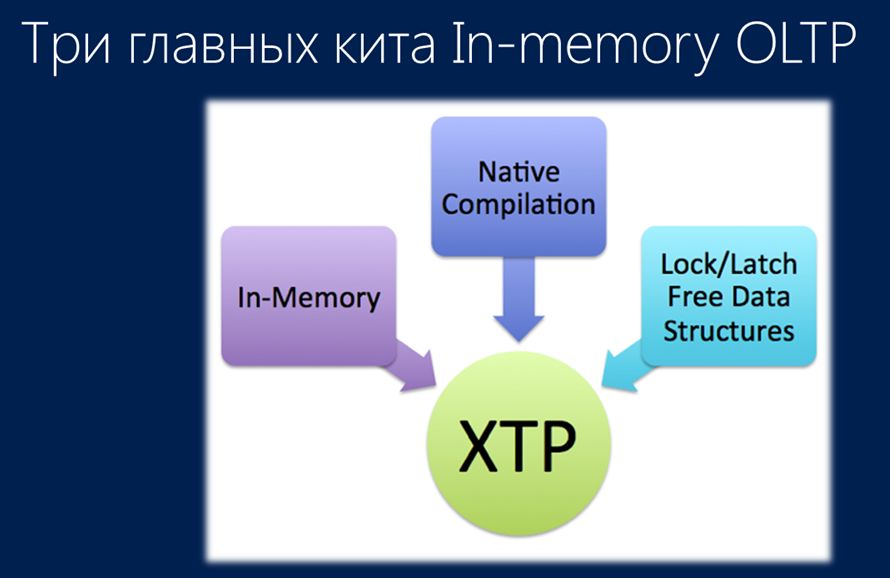
Здесь вы видите три основных компонента, которые представляют собой технологию In-memory OLTP. Именно они позволяют ей осуществить такой прорывной эффект:
- Первое – это четкая установка на то, что все данные находятся в памяти.
- Второе, что немаловажно: эти данные располагаются в специально разработанных, свободных от блокировок структурах данных.
- И третье – это нативная, родная компиляция. Она представляет собой хранимые процедуры, содержащие бизнес-логику, которые скомпилированы в машинный код в памяти SQL-сервера.
Сравнение инфраструктуры взаимодействия (традиционной схемы и In-Memory OLTP)

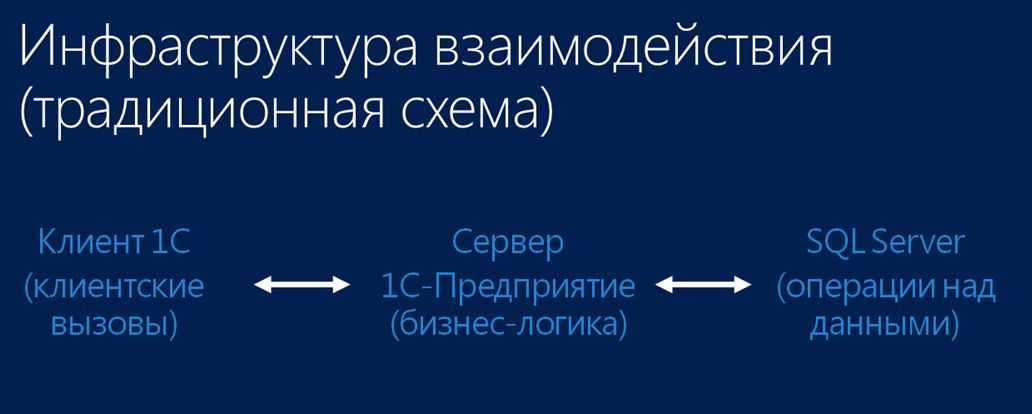
Если мы посмотрим традиционную схему взаимодействия клиента и СУБД, то тут все очевидно:
- У нас есть клиент со своими клиентскими вызовами,
- Есть сервер 1С:Предприятие, который вмещает всю бизнес-логику.
- И есть сервер СУБД. Он в традиционной схеме используется в основном для манипуляции с данными (а конкретно - для четырех операций: выборка, накопление, изменение и удаление).

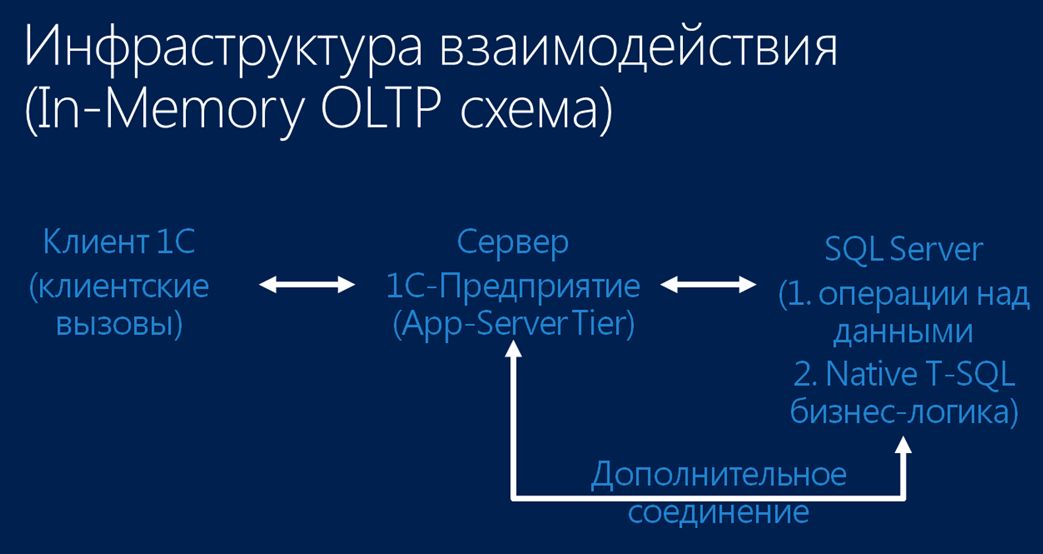
В случае применения схемы In-Memory OLTP в рамках платформы 1С, схема чуть-чуть меняется:
- Остаются те же клиенты со своими клиентскими вызовами.
- Но в данном случае сервер 1С:Предприятие немного трансформируется. В целом полностью остаются все его функции и назначение, но теперь нельзя сказать, что он полностью контролирует всю существующую бизнес-логику. Здесь я его назвал слоем программного сервера. Почему?
- Потому что появляется дополнительное внешнее прямое соединение к СУБД, с помощью которого осуществляется вызов хранимых процедур, о которых я говорил ранее.
- Сущность этих хранимых процедур теперь состоит в том, чтобы производить операции с данными в соответствии с той бизнес-логикой, которую вы заложили на уровне СУБД.
Яркий пример того, как физический слой «протек» на слой логический.
Основное преимущество In-Memory OLTP


Здесь на слайде перечислены некоторые основные характеристики технологии In-Memory OLTP. Более подробно об этом можно прочитать в интернете (в основном, на сайте Microsoft, а также в большом количестве блогов западных разработчиков). Здесь же я хочу уточнить один нюанс, о котором я еще не говорил: в In-memory OLTP появился совершенно новый мультиверсионный оптимистичный контроль параллельного выполнения. В его рамках полностью отсутствует какое-либо понятие блокировок при работе с данными. При его работе конфликты между различными потоками редки, но если они и случаются, то быстро решаются, и не нужно очень долго ждать, как в случае использования стандартного блокировочного механизма.
Тестовый сценарий для проверки работы технологии In-Memory OLTP в рамках платформы 1С

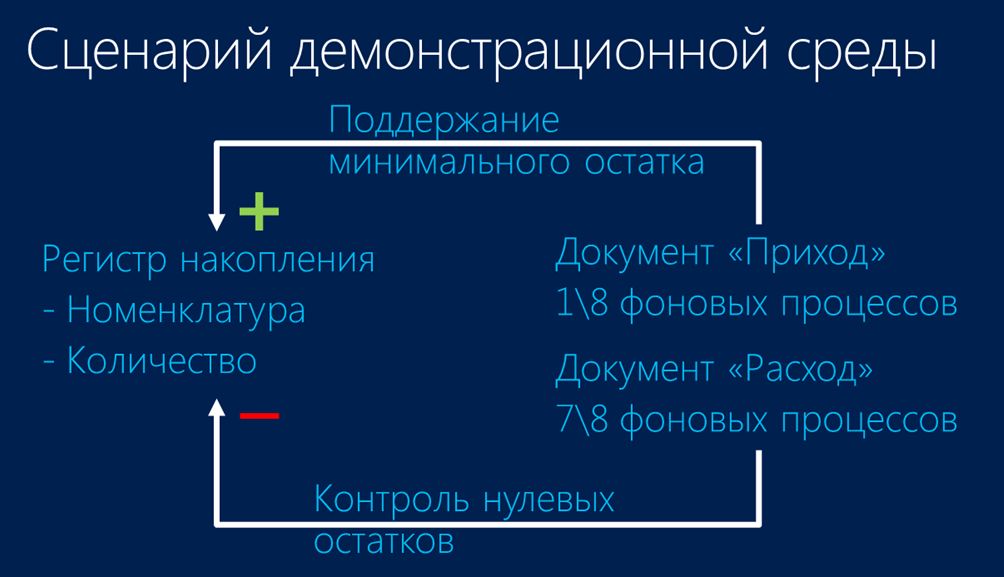
Анализируя те возможности, которые дает технология In-memory OLTP, я решил реализовать достаточно простой тестовый сценарий для проверки работы этой технологии в рамках платформы 1С. Демонстрационная среда, которая у меня получилась в результате, выглядела следующим образом:
- Я взял очень простую конфигурацию с одним регистром накопления, в котором учитывались остатки по номенклатуре в разрезе количества.
- Также в этой конфигурации было два документа – Приход и Расход, в которых была реализована следующая бизнес-логика:
- Документ Приход обеспечивал поддержку минимального остатка.
- А при проведении документа Расход контролировалось отсутствие нулевых остатков.
- Для того чтобы сымитировать конкурентную многопоточную нагрузку при проведении этих документов, я использовал стандартный подход с фоновыми процессами, которых для проведения документа Расход было подавляющее большинство.
- Также следует отметить, что я в своей демонстрационной сети использовал две виртуальные машины:
- Одну – для сервера 1С:Предприятие,
- А другую – для SQL-сервера.
Но обе виртуальные машины находились в рамках одного хоста виртуализации.
Первый замер – базовый показатель

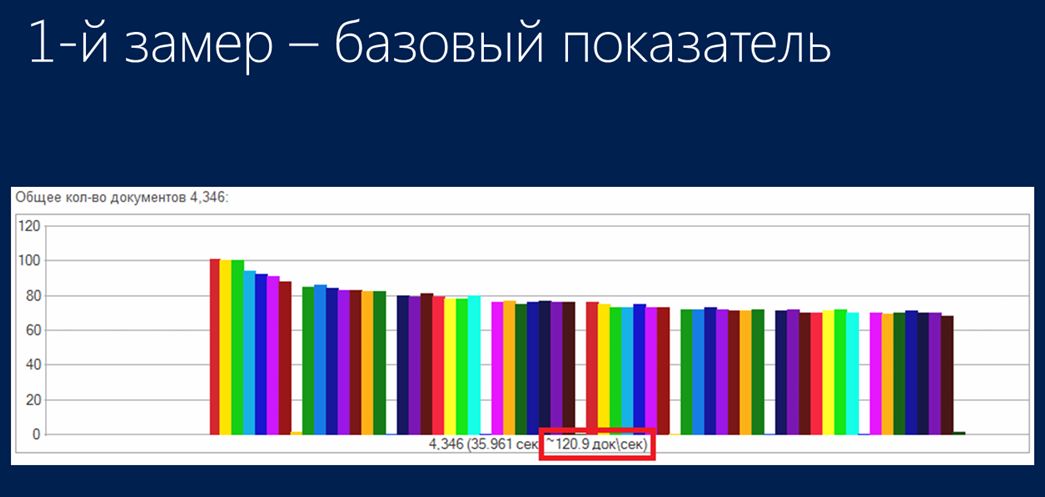
После того, как эта схема была реализована, я провел контрольный замер базовых показателей для стандартного, традиционного проведения документов средствами 1С с использованием управляемых блокировок. Что я получил в результате первого замера?
На слайде подчеркнуто значение того показателя, который я получил: 120 документов в секунду при 64 фоновых процессах – это тот базовый показатель, который у меня был.

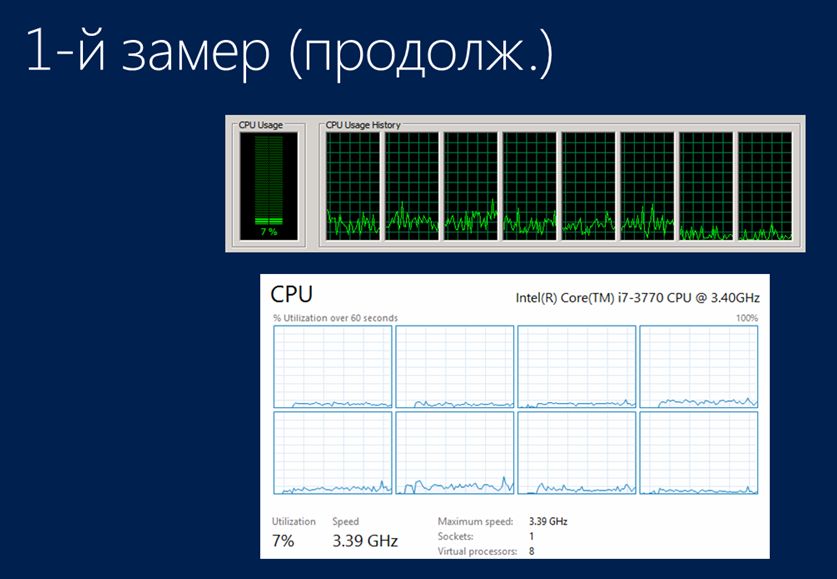
При этом была измерена нагрузка на процессоры:
- Сверху – нагрузка на сервер 1С:Предприятие
- И нижняя часть – это нагрузка на процессоры SQL-сервера.
Как вы видите, и там, и там нагрузка небольшая – процессоры отдыхают, работают только управляемые блокировки.
Второй замер – миграция в In-Memory только таблиц

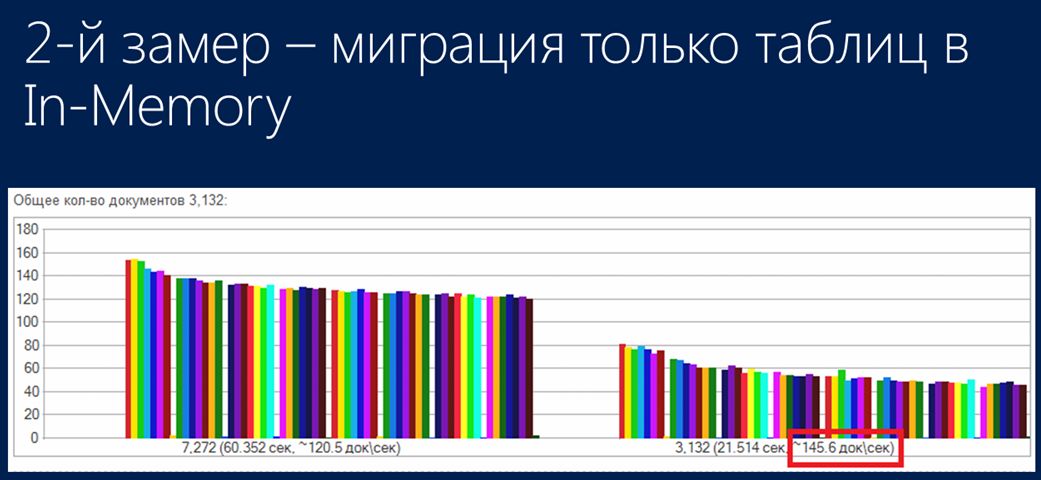
Следующим шагом я решил сделать миграцию структур, в которых хранились стандартные данные, в In-memory-таблицы. И после того, как я их мигрировал, я запустил свой стандартный тест. В нем происходило все то же самое: средствами платформы 1С проводились документы, но только теперь они уже хранились в In-Memory-таблицах (сама платформа об этом не знала).
Результат получился в районе 150 документов в секунду, следовательно, небольшой рост все-таки произошел, но незначительный, и в некоторых системах вы можете даже и не увидеть этого увеличения. В целом, в данном случае нагрузка на процессоры никак не поменялась, поэтому я их здесь даже не привожу.
Хочу добавить к этому, что если кто пытался реализовать эту же задачу, то обычно она вызывает проблемы – чуть позже я расскажу, как эти проблемы решаются.
Третий замер – миграция в In-Memory и таблиц, и бизнес-логики

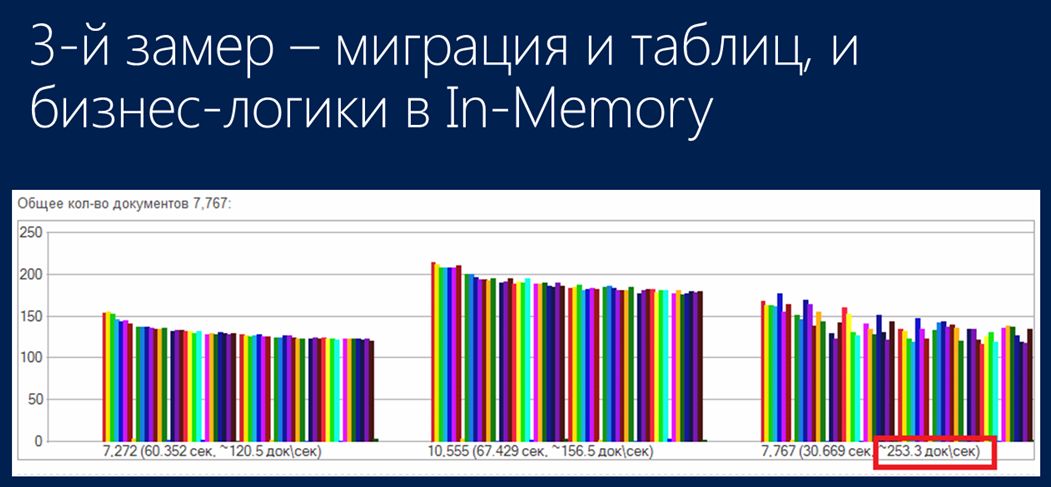
На третьем шаге помимо того, что была полностью реализована миграция структур данных в In-memory-таблицы, также была полностью смигрирована и та бизнес-логика, которая была нужна для проведения документов – все действия, необходимые для:
- Формирования документов и их табличных частей;
- Их записи;
- Формирования движений документов;
- И изменения текущих остатков.
В итоге был получен результат 250 документов в секунду. По сути, по отношению к базовому показателю 120 и 250 – это выигрыш чуть больше, чем в два раза.

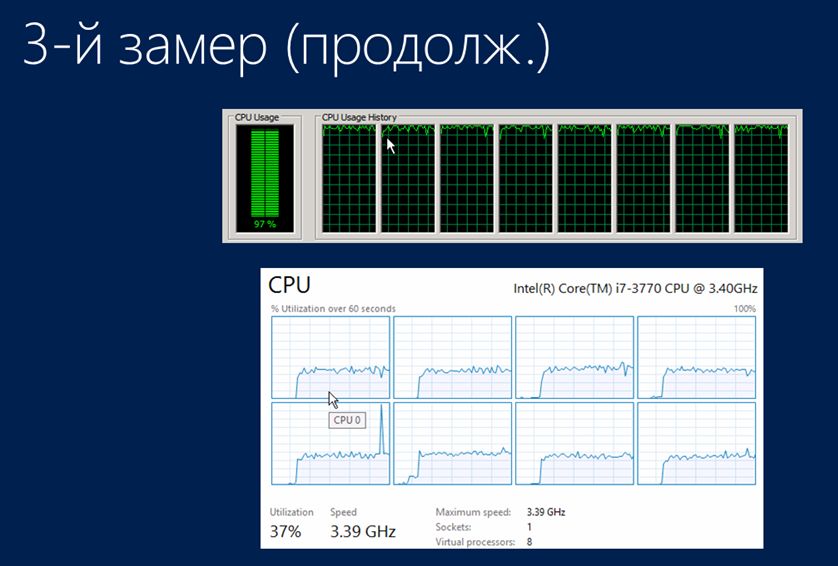
Тут можно немного посмеяться и сказать, что мы же можем взять железо в два раза мощнее и получить примерно тот же результат. Но все объясняется, если посмотреть на загрузку процессоров в этом случае:
- Сервер 1С:Предприятия полностью загружен;
- В то время как сервер SQL занят только на треть.
Мне удалось выяснить, что данная нагрузка на сервер 1С:Предприятие показывала, что он просто не успевал сгенерировать это количество документов на лету, а также не успевал их отдавать на проведение SQL-серверу, чтобы полностью его загрузить.
Позже удалось выяснить, что для того, чтобы полностью загрузить SQL-сервер в данном примере, потребовалось бы около восьми подобных виртуальных машин. Но в этом все равно не было бы никакого смысла, потому что у меня использовался только один хост виртуализации, и никакого дополнительного железного выделенного оборудования у меня не было. Но в дальнейшем это и не понадобилось.
Четвертый замер – передача 15 документов для проведения за один вызов

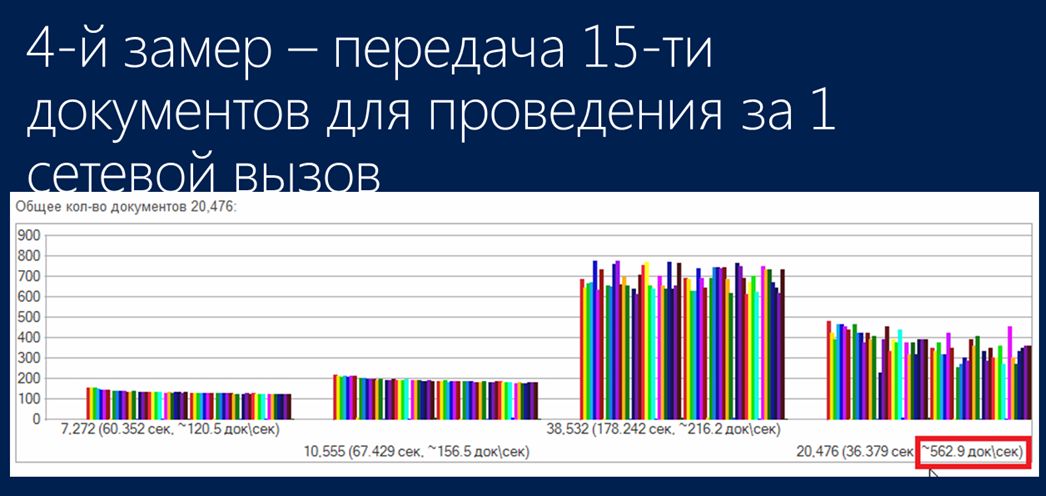
Четвертый замер я сделал в надежде на то, что удастся все-таки за один сетевой вызов отдавать на SQL-сервер побольше работы. Для этого бизнес-логика была переписана таким образом, чтобы за один вызов отдавать на проведение сразу 15 документов. В результате скорость выросла до 550 документов в секунду.

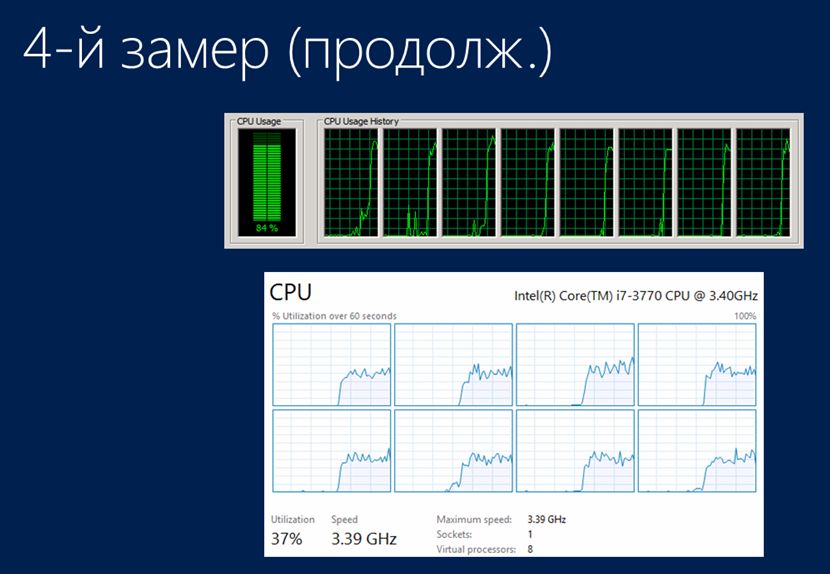
При этом, как видно на графиках, сервер 1С:Предприятие был все так же полностью загружен, а SQL-сервер продолжал «отдыхать».
По сути, этот сценарий скорее фейковый, потому что он вообще не имеет никакой практической пользы, и был реализован только в качестве проверки. Но в любом случае мы явно видим проблему переноса достаточной нагрузки на SQL-сервер, чтобы полностью его загрузить.
Пятый замер – запуск подготовленной нагрузки на стороне SQL Server

Следующим шагом я решил сгенерировать всю нагрузку предварительно. Эта нагрузка выглядела в виде 64 сформированных файлов SQL-скриптов на 700 мегабайт. Я перенес их на SQL-сервер, и с помощью известной утилиты OStress, которой можно «скормить» эти файлы, чтобы запустить параллельную нагрузку, получил следующий результат.


- По загрузке процессора – получившееся время отработки поместилось в стандартное окошко диспетчера задач: есть начало нагрузки, потом полностью все процессоры почти на 100% отработали, и нагрузка закончилась.
- В результате нагрузки было создано 112 тысяч документов, при этом полностью сохранялись все те процессы, которые были при проведении документов «Расход»: контролировались все остатки, выполнялись все действия.
- Нагрузка заняла 53 с лишним секунды.
- Если сделать определенные вычисления, получится, что среднее время проведения одного документа составило менее половины миллисекунды,
- а средняя скорость проведения документов составила больше 2000 документов в секунду.
Когда я первый раз получил этот результат – не мог поверить. Просто представьте себе, какие объемы вам теперь доступны, вы теперь можете мыслить в совсем других категориях. И теперь я могу ответить своему бывшему директору по IT, как мы можем ускорить проведение документов «Чек» на кассах. И даже если при этом у нас будут какие-то конфликты, блокировки, сам процесс теперь пройдет очень быстро.
Методология миграции

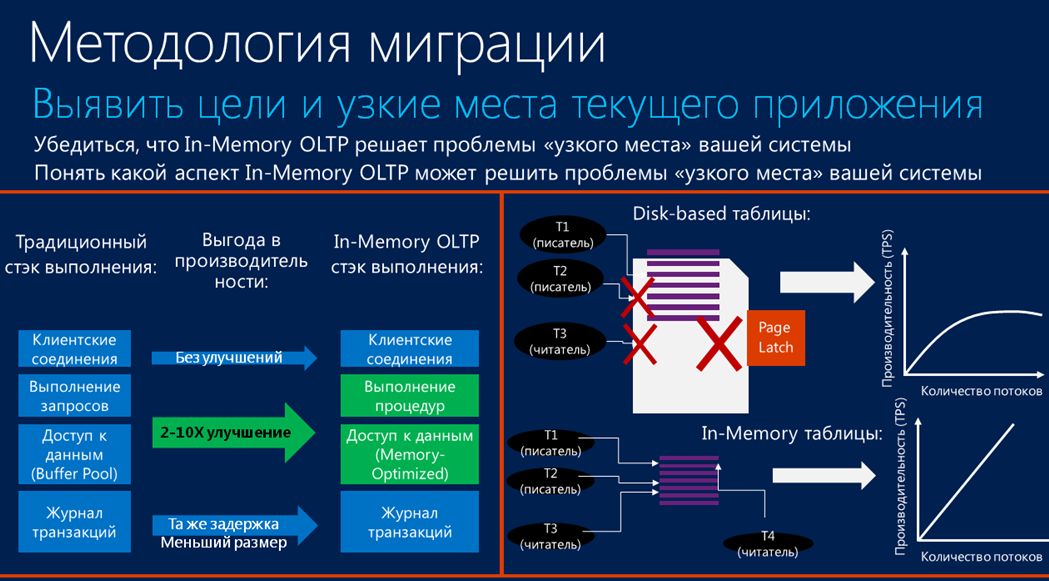
Если же вернуться к методологии миграции в In-Memory OLTP, то надо отметить, что она подходит не для всех случаев. Ее надо использовать только для некоторых узких мест вашей системы, где важен гарантированно быстрый доступ к данным. Поэтому прежде, чем внедрять эту технологию, нужно провести тщательный анализ:
- Например, если сравнить стеки выполнения (традиционный и In-Memory OLTP), то на уровне сетевого взаимодействия ничего не поменялось. Поэтому, если ваша программа (ваше приложение) очень «разговорчивое», обменивается с сервером СУБД очень большим количеством сообщений, то вам технология In-Memory совсем не поможет – здесь нет никаких улучшений.
- Также, если мы посмотрим на уровень журнала регистрации базы данных, то тут тоже особо ничего не поменялось. Хотя размер журнала регистрации при операциях In-memory OLTP сокращается, минимальная задержка транзакций при записи в этот журнал остается той же.
- Основную выгоду вы сможете получить только на уровне выполнения запросов и доступа к данным.
Преимущество технологии In-memory OLTP не в том, что данные располагаются в памяти. Хотя технология и называется In-memory, выигрыш происходит не от этого – ускорение происходит за счет того, что меняется инфраструктура самой базы данных:
- используются новые, специально разработанные структуры данных, которые лишены блокировок,
- а также используются скомпилированные в машинные коды хранимые процедуры, которые хранят вашу критичную бизнес-логику.
И, если мы посмотрим на стандартную систему, то в случае добавления в нее большого количества потоков, они со временем начинают друг другу мешать, тем самым пропускная способность вашей системы уменьшается. В то же время при использовании технологии In-memory OLTP система при увеличении количества пользователей продолжает масштабироваться, поскольку нет блокировок (используются новые структуры данных, которые их лишены), а также применяются быстрые, предварительно скомпилированные хранимые процедуры.


Что можно сказать по поводу самого процесса миграции в In-memory? Он в целом состоит из двух шагов, которые поочередно повторяются:
- Первый шаг – это миграция структур данных.
- И второй шаг – это миграция вашей критичной бизнес-логики на сторону СУБД.
Решение проблемы записи в In-Memory из 1С

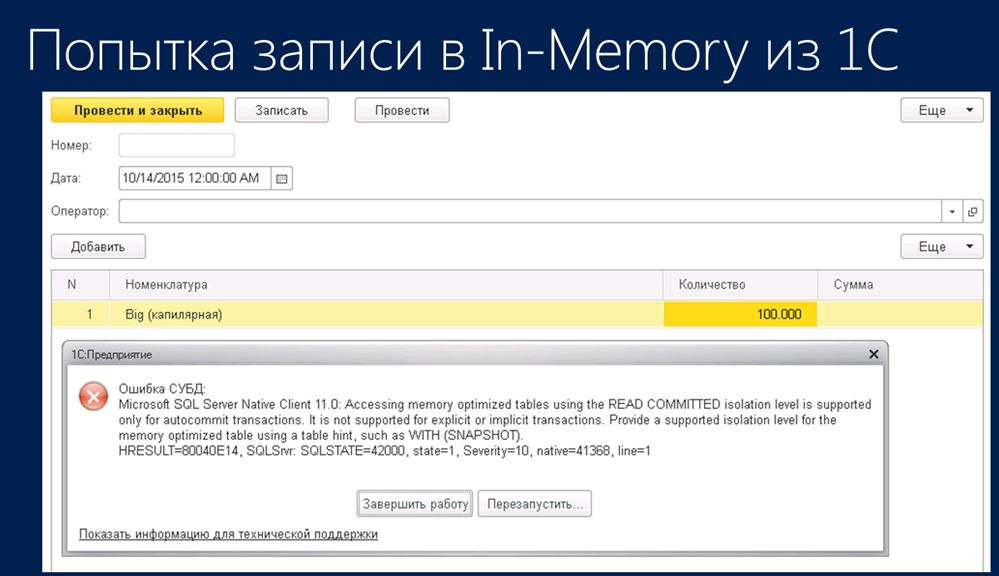
При работе из 1С с мигрированными на сторону СУБД структурами данных возможны некоторые трудности. Например, если при смигрированных таблицах в рамках платформы 1С кто-либо попытается осуществить какую-то запись в таблицы либо в документы (Приход или Расход), вы увидите стандартное сообщение об ошибке, которое в целом говорит о каких-то проблемах в уровнях изоляции.


С чем связана такая ошибка? Стандартная схема выполнения поддерживает пять уровней изоляции, а механизм In-memory OLTP – только три уровня. При этом платформа 1С по умолчанию использует уровень изоляции ReadCommited, которому как раз нет соответствия в механизме In-Memory OLTP. Соответственно, возникает проблема согласованности между этими уровнями изоляции.
Пытаясь решить эту задачу, я потратил очень много времени. И поиск решения даже завел меня в реверс-инжиниринг («обратный инжиниринг»), мне казалось, что придется динамически перехватывать запросы, которые идут от платформы к СУБД, и изменять их текст на лету для того, чтобы они стали соответствовать синтаксису In-Memory. Но оказалось, что решение находится на поверхности – оно тривиальное и простое.


В самом SQL Server 2014, в котором как раз и появилась технология In-Memory, есть такое свойство базы данных, как is_memory_optimized_elevate_to_snapshot_on. По умолчанию, оно неактивно, выключено – это можно проверить запросом, который показан на слайде.

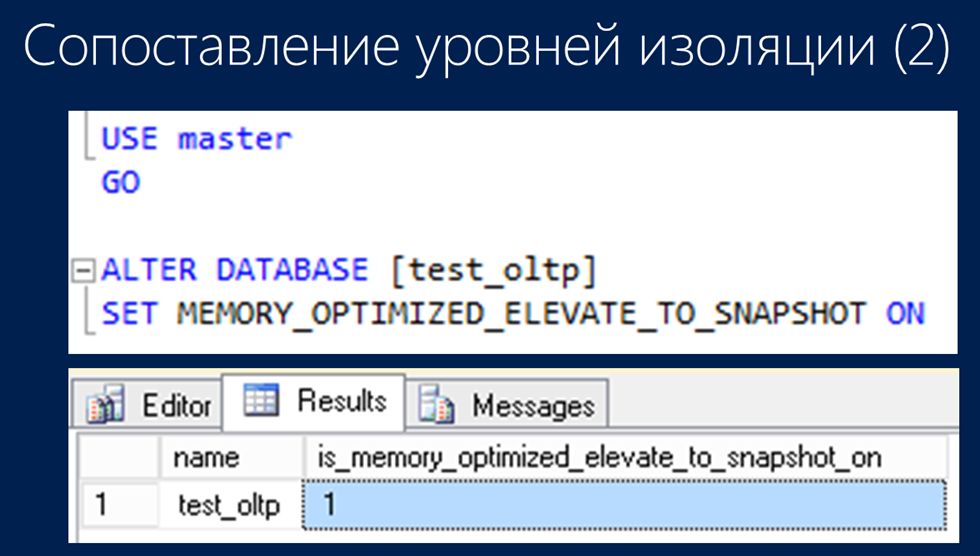
Соответственно, если вы выполните команду, которая активирует это свойство, то проблем с согласованностью уровней изоляции у вас не будет.


При этом вы поднимете уровень изоляции, который СУБД использует по умолчанию, и он как раз будет соответствовать уровню изоляции Snapshot, по умолчанию использующийся для таблиц In-Memory. Таким образом, проведя небольшие манипуляции на стороне СУБД, у вас в In-Memory-таблицы будут записываться любые документы и любые данные.
Общая схема миграции бизнес-логики на сторону СУБД

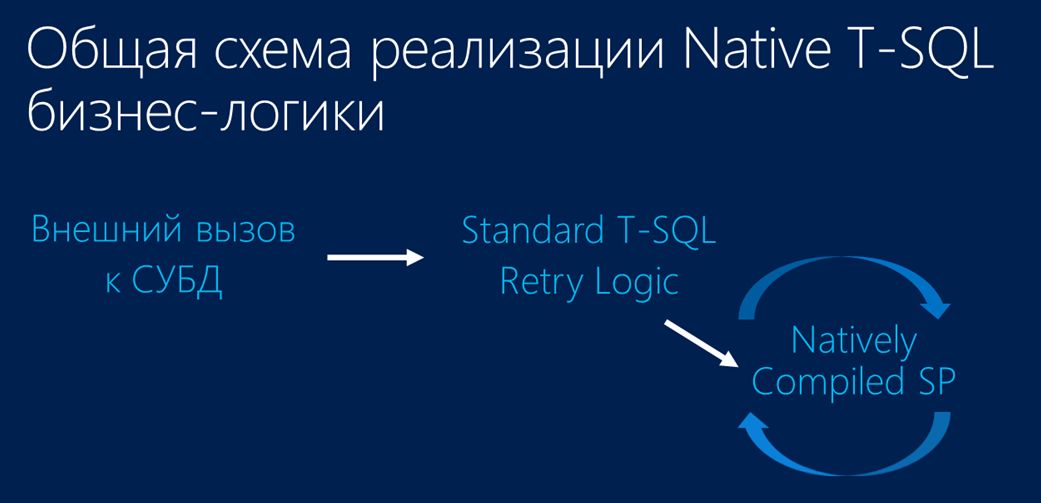
Что же можно сказать по поводу общей схемы миграции самой бизнес-логики на сторону СУБД?
Она включает в себя два объекта:
- Во-первых, это та скомпилированная процедура, которая будет выполнять непосредственную работу.
- И над ней обертка, которая реализует так называемую RetryLogic (логику перезапуска). Почему? Потому что нет никакой гарантии того, что ваша хранимая процедура выполнится. В процессе ее выполнения может произойти какой-то конфликт, поэтому необходимо сделать так, чтобы в результате конкретного сетевого вызова эта процедура, реализующая вашу бизнес-логику, обязательно выполнилась до конца.


Вот примерная схема реализация «обертки». Здесь AddOutcome – это внешний StandardT-SQL-(обертка). Внутри цикла располагается процедура, уже непосредственно скомпилированная в машинные коды. Видно блок TRY (Retry). Соответственно, если возникает конфликт, то происходит исключение, в котором вы, как разработчик, закладываете какой-то период ожидания, чтобы конфликтующая транзакция успела выполниться, а затем, соответственно, выполнится ваша.
Заключение


Ну и в заключение можно сказать, что миграция в таблицы In-Memory OLTPприменительно к 1С потребует задействовать:
- Большое количество интеллектуальных и финансовых ресурсов,
- Подключение большого количества специалистов.
- Ну и самый основной вопрос – это то, что поддержка технологии In-Memory OLTP на данный момент в платформе отсутствует, и в этом плане можно только смотреть в сторону фирмы 1С. По крайней мере, я надеюсь, что они хорошо отреагируют на появление возможности использования этой технологии в рамках платформы.
*****************
Приглашаем вас на новую конференцию INFOSTART EVENT 2019 INCEPTION.
Вступайте в нашу телеграмм-группу Инфостарт