
{kind=link}
300 млн. строк? Что это? Разве такое возможно? Да, и если кто-то не может представить себе такую ситуацию - поверьте, вполне! В моей практике в ИБ 1С, в регистре сведений, хранились все изменения всех-всех ключевых документов/справочников/регистров сведений сильно измененной, большой и сильно допиленной УПП - создания, изменения и т.д. За год там накопилось около 320 млн строк. И, как всегда это бывает, понадобилось добавить колонку, то есть новый реквизит в эту таблицу. Вот алгоритм действий, с помощью которого можно довольно быстро решить задачу:
Все описанное актуально для ИБ, развернутых в клиент-серверном варианте. Я тестировал на MS SQL, но думаю, на остальных СУБД - все тоже самое. Тесты проводились на типовой УПП 1.3.78.1. Платформа 8.3.5.1460, MS SQL EXPRESS.
1. Делаем резервную копию базы-источника средствами СУБД. Подчеркиваю, средствами СУБД, так как нам нужен полный зеркальный снимок нашей базы данных. Не используем выгрузку в dt, да собственно, раз Вы столкнулись с такими объемами - то навряд ли подумаете об этом.
2. Из резервной копии поднимаем точно такую же базу, регистрируем ее на сервере приложений 1С. Далее, в моем примере UPP1 - база-источник, UPP2 - ее точная свежая копия.
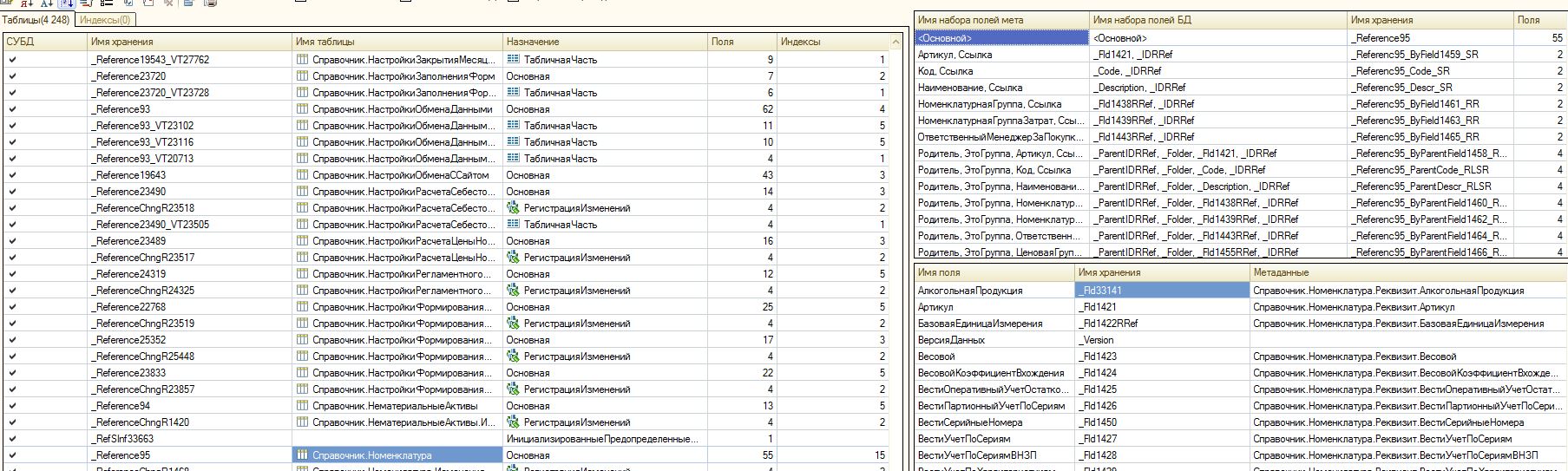
3. Для начала добавим в базе UPP2 в справочник Номенклатура строковый реквизит, к примеру назовем его СтрокаПокупатель, тип строка (50), неиндексируемое. После того, как мы подняли из резервной копии новую базу, подключаемся к ней средствам СУБД, например с помощью Management Studio. Теперь нам надо выяснить, какая же таблица БД соответствует имени метаданных "Справочник.Номенклатура". Я для этой цели использовал удобную обработку из состава мобильных Инструментов Разработчика, но у кого ее нет под рукой - легко вытащить всю нужную информацию с помощью функции ПолучитьСтруктуруХраненияБазыДанных. Итак, я выяснил, что в моей конфигурации это таблица _Reference95. Будем считать, что именно в этой таблице у меня миллионы строк. Произведем ее очистку скриптом:
TRUNCATE TABLE UPP2.dbo._Reference95
Данная инструкция - самый быстрый способ очистить таблицу от данных. Но, для миллионных объемов - придется подождать, конечно во много раз меньше, по сравнению с типовой реструктуризацией.
4. Запускаем конфигуратор для UPP2. Снимаем нужный объект с поддержки, добавляем реквизит - все как обычно. Обновляем конфигурацию базы данных, так как строки из таблицы мы удалили - реструктуризация и обновление пройдет быстро.
5. Теперь нам снова нужно выяснить, какая колонка в БД SQL была добавлена в нашу таблицу справочника "Номенклатура". У меня это колонка имеет название _Fld33662, тип nvarchar(50), NULL. Идем в базу UPP1 с помощью MenStudio. Находим таблицу_Reference95 и добавляем столбец. Как добавить столбец, выполнить произвольный запрос - будем считать, что это все умеют, а кто не умеет - разберется самостоятельно. Обращаю внимание, что добавлять столбцы в уже существующую и заполненную таблицу можно только установив флаг "разрешить Null", иначе инструкция ALTER TABLE, которая изменяет таблицу - не сработает.
6. Выгоняем пользователей из UPP1. Далее выполняем следующий скрипт:
BEGIN TRAN Tr1
DELETE FROM UPP1.dbo.Config
DELETE FROM UPP1.dbo.DBSchema
DELETE FROM UPP1.dbo.Files
DELETE FROM UPP1.dbo.Params
INSERT INTO UPP1.dbo.Config
SELECT *
FROM UPP2.dbo.Config
INSERT INTO UPP1.dbo.DBSchema
SELECT *
FROM UPP2.dbo.DBSchema
INSERT INTO UPP1.dbo.Files
SELECT *
FROM UPP2.dbo.Files
INSERT INTO UPP1.dbo.Params
SELECT *
FROM UPP2.dbo.Params
COMMIT TRAN Tr1
7. Открываем конфигуратор UPP1, видим, что наш реквизит добавился в справочник "Номенклатура". Запускаем предприятие и выясняем, что новому реквизиту действительно соответствует колонка _Fld33662. Пробуем открыть любой элемент справочника или выполнить запросов, прочитав новый реквизит. Если прочиталось - все получилось. Для очистки совести можно выполнить проверку ссылочной целостности конфигурации в меню тестирования и исправления. У меня проблем не возникло.
8. Обращаю внимание, что мы добавили в таблицу новое поле, значение которого во всех строках этой таблицы, существовавших ранее - Null. Для справочников и регистров сведений - я считаю, это допустимо. Особенно, если вновь добавленный реквизит примитивного типа.
Для более сложной ситуации, когда например нужно добавить измерение ссылочного типа в таблицу регистра накоплений - здесь уже нужно анализировать и принимать решение о целесообразности таких действий.
Алгоритм тот же самый, но теперь колонки в искомую базу из ее зеркальной копии мы будем добавлять не в одну таблицу, а в две - таблицу самих движений и таблицу итогов. И, если измерение индексируемое - выясняем, какой индекс добавился (добавится 1-н некластерный индекс) и как изменится кластерный индекс и вручную выполняем эти изменения в базе-источнике для обеих таблиц. Смотрим состав полей индекса в зеркале, переносим в источник. Так как в таблицах регистров накопления значения ссылочных полей не допускают типа Null, то в этой ситуации придется выполнить скрипт:
UPDATE UPP1.dbo._AccumRg17789
SET UPP1.dbo._AccumRg17789._Fld33665RRef = Convert(binary(16), 0)
FROM UPP1.dbo._AccumRg17789
UPDATE UPP1.dbo._AccumRgT17798
SET UPP1.dbo._AccumRgT17798._Fld33665RRef = Convert(binary(16), 0)
FROM UPP1.dbo._AccumRgT17798
Так как у нас там миллионы строк - неизвестно, насколько быстро это отработает. К сожалению, для тестов у меня не было таких объемов данных, поэтому однозначного ответа дать не могу. Но, если очень нужно - можно немного усложнить эти запросы, обновлять эти поля в таблицах порциями, например по 100 тыс. записей и повесить выполнение на "тайм-джоб" в самой СУБД.
Надеюсь, мой опыт кому-нибудь будет полезен.
Вступайте в нашу телеграмм-группу Инфостарт