
{kind=link}
Механизмов определения кодировки текста известно множество, от MS Word до веб-сервисов и сайтов. Либо они не очень удобны, либо требуют сидеть и вручную тыркать, перебирая вариант за вариантом, либо, как некоторые опробованные мной онлайн-сервисы, просто выдают полную ересь. Поэтому я сварганил простенькую обработку для определения тупым перебором всех кодировок, поддерживаемых 1С. Скажу сразу - если логика внутреннего сравнения строк Unicode изменится, обработка станет неактуальна, но это маловероятно.
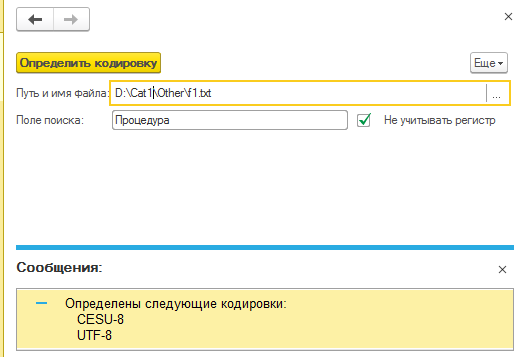
В обработке надо указать имя рассматриваемого файла (допустимо любое расширение, а скинуть в текст можно хоть блокнотом, хоть чем, хоть той же 1С), и надо указать поисковую строку. Если текст прочитан адекватно, то поисковая строка будет найдена, и это значит, что кодировка подошла. NB: к одному файлу может подходить (быть читабельными) несколько разных кодировок.
Кому надо в обычных формах - напишите, сделаю.
Тестировалось на 8.3.6 и 8.3.10, но по идее будет и на 8.2 работать.