Всем привет!
Я уже второй раз выступаю на конференции Infostart. В первый раз, это было в 2014 году, я выступал от компании «Деловые линии». Но в том же году весь ИТ-департамент «Деловых линий» был выделен в отдельное юридическое лицо BIA Technologies, и «Деловые линии» стали нашим основным заказчиком.

Итак, Hi-Load.
HI-Load бывает разный. В википедии вообще написано, что HI-Load – это просто высокая нагрузка и всё.
Договоримся на берегу, что буду говорить только о Hi-Load, отвечающих двум аспектам:
Первый. Высокая интенсивность работы пользователей в информационной системе. Т.е. когда много запросов, большой документооборот, много одновременно работающих пользователей.
Второй. Это система уровня Энтерпрайз. Т.е. когда работоспособность базы напрямую влияет на работу бизнеса. Грубо говоря, остановилась база - остановился бизнес.

Тут важный момент. Это должен быть не просто факт такого влияния, но и осознание этого самим бизнесом. Проще говоря, если владелец базы данных НЕ ставит отдельную цель обеспечить мощность, доступность и непрерывность работы своей базы, то значит он её НЕ ценит. А если НЕ ценит, значит это НЕ Энтерпрайз.
Что еще важно. Энтерпрайз не обязательно большая база данных с высокой нагрузкой, она вполне может быть маленькой, но бизнес её бережет и сдувает с неё пылинки.
Оба этих аспекта сочетаются в информационной системе нашего основного Заказчика.
Поэтому давайте про саму систему. Кратко.
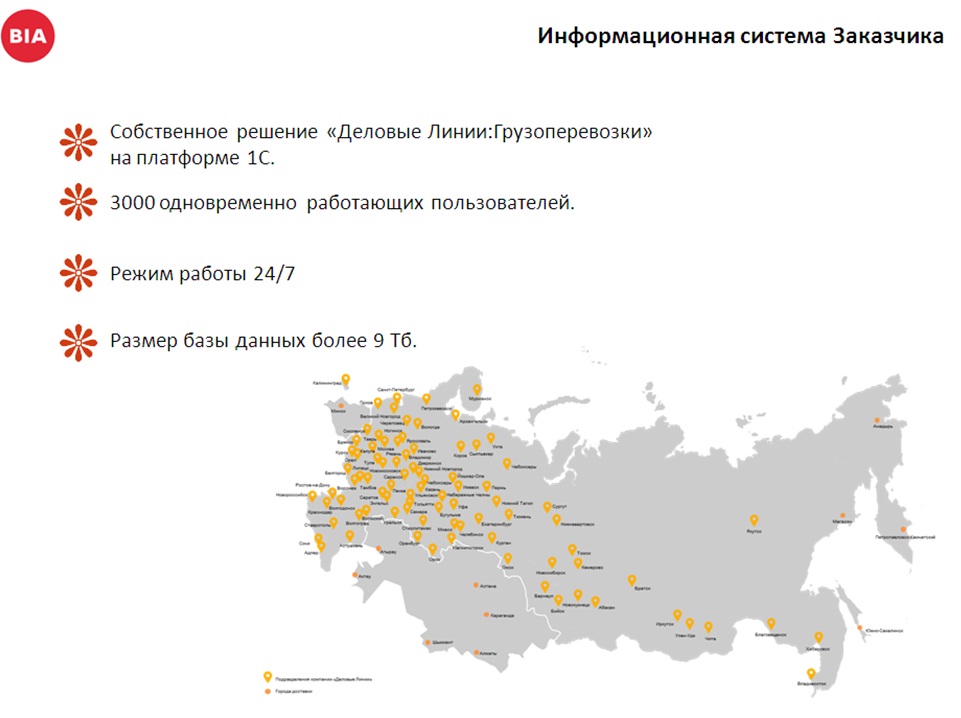
- Это – самописная конфигурация на платформе 1С.
- В базе одновременно работает более 3000 пользователей в 129 городах России.
- Режим работы круглосуточный.
На стороне сервера СУБД показатели следующие:
- MS SQL 2014
- Среднее число запросов 35'000 в секунду, пиками до 50'000.
- Больше 10'000 транзакций в секунду, пиками до 30'000.
- Нагрузка на процессор меньше 15%, пиковая до 40%.
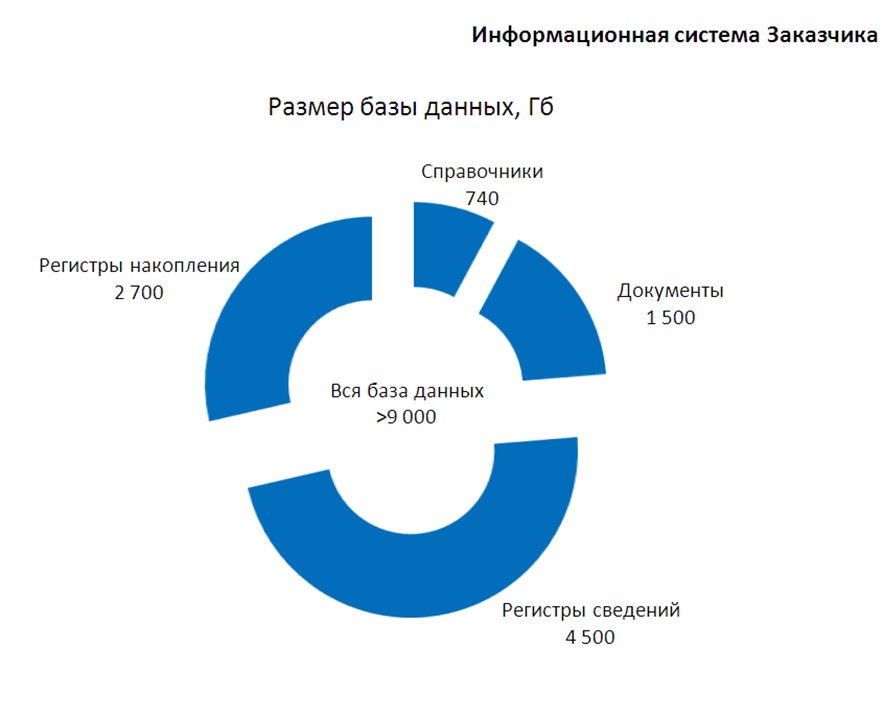
Суммарный размер базы более 9 ТБ. Из них:
- Чуть меньше половины занимают регистры сведений.
- На втором месте – регистры накопления.

Интенсивность работы:
- В сутки записывается и перепроводится (включая создание новых) более миллиона документов;
- Справочников – порядка 380 тысяч;
- И ежедневно пользователи формируют около 300 тыс. отчетов.
Повторюсь, это показатели за сутки. Режим работы 24 на 7, но почти 80% этой нагрузки приходится на 12-ти часовой промежуток времени. Примерно с 9 утра до 9 вечера.
Про платформу.
Используемая платформа: 1С 8.3.10

Переходу на 8.3 предшествовал достаточно длительный проект по нагрузочному тестированию, который мы провели совместно с центром корпоративной технической поддержки (ЦКТП) от 1С. Это тестирование мы проводили практически год.

Целью нагрузочного тестирования было:
- Добиться стабильной работы платформы и базы;
- Понять, выдержит ли вообще железо такие нагрузки – может быть, нам потребуется менять сервера, конфигурацию;
- Оценить перспективы роста (и для бизнеса в том числе).
- Понять, что будет с базой в ближайшие 3-5 лет.
В чем состояло само тестирование?
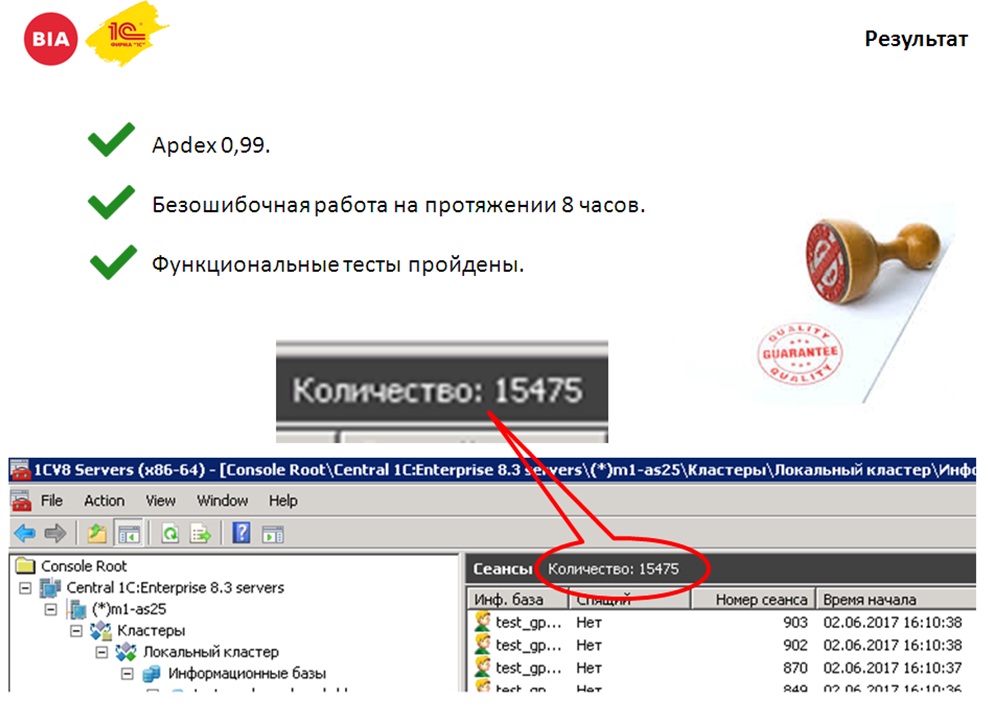
- На протяжении 8 часов 10 тысяч виртуальных пользователей должны были работать в системе;
- При этом итоговый APDEX должен быть на уровне «отлично».
- И никто из этих пользователей не должен аварийно завершить работу.
- Также отделом тестирования проводились еще и пользовательские (функциональные) тесты,
На скриншоте вы можете видеть 15 тысяч пользователей – это реальный скриншот с проведения теста. 15 тысяч – потому, что помимо 10 тысяч виртуальных пользователей были COM-соединения и работал фоновые задания. У нас такая специфика работы, что мы для построения отчетов подключаемся к копии базы по COM-коннекту. Поэтому нам важно было удостовериться, что кластер выдержит работу еще и с большим количеством COM-коннектов.
Подробно об этом проекте я рассказывать не буду, поскольку он похож на предыдущий проект, который освещался на Event 2014. Доклад назывался «Нагрузочное тестирование на 5 тыс. пользователей». Как видите, оказалось, что пользователей может быть еще больше.
Из интересно отмечу сам процесс перехода с 8.2 на 8.3.
Нам сказали: «Ребята, надо снять режим совместимости с 8.2, но пользователи могут не работать только один час, а дальше – пожалуйста, будьте любезны предоставить доступ».
Что было для этого сделано?
- Мы использовали свою собственную систему репликации, построенную на планах обмена.
- Развернули копию рабочей базы, включили обмены.
- На копии базы выполнили реструктуризацию типовыми средствами. Получили копию рабочей базы на новой платформе.

- Настроили обмен из рабочей базы 8.2 в эту копию 8.3. Обмен шел порядка двух суток. В планах обмена было около миллиарда изменений.
- Когда база 8.3 актуализировалась, мы просто переназначили ярлыки. Для пользователей это было буквально за 5 минут и все – они стали работать дальше.
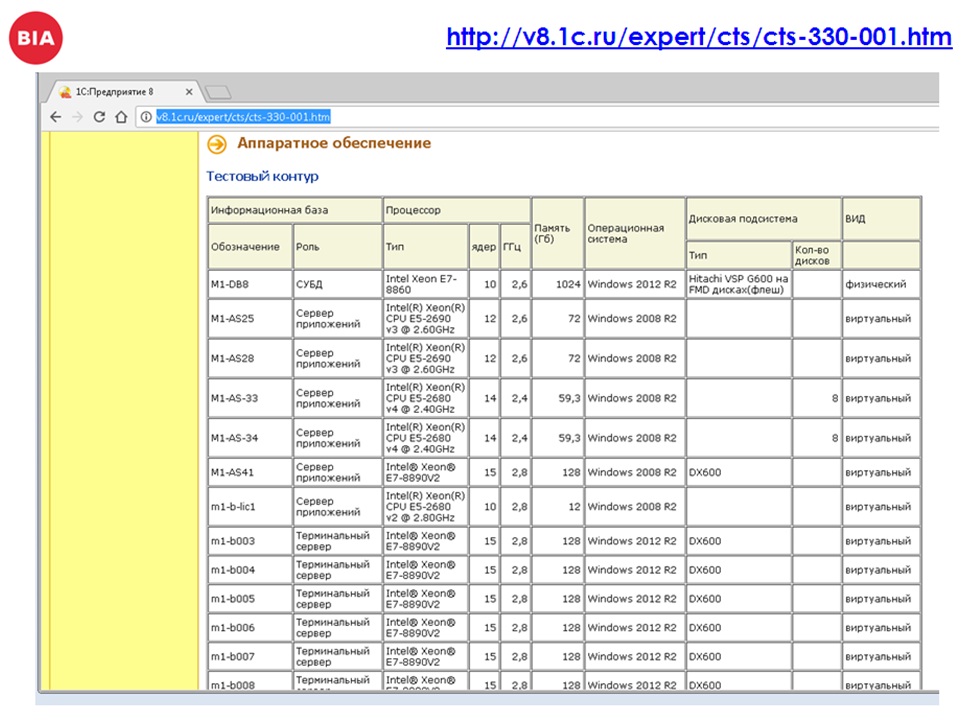
Кому интересно, описание железа, использованного на проекте, есть на сайте 1С http://v8.1c.ru/expert/cts/cts-330-001.htm
Возвращаемся к теме HiLoad.
В чем же особенности при такой высокой интенсивности работы?

Основная проблема – это высокая чувствительность базы к качеству запросов. Любой запрос, даже достаточно качественный, при многократном количестве его выполнений теряет свое качество и это может критически сказываться на системе.
Например:
- 3 тыс. пользователей;
- у каждого третьего раз в секунду срабатывает обработчик ожидания;
- В этом обработчике выполняется запрос, который потребляет 0.1 секунды CPU.
Соответственно, для того, чтобы вам обеспечить работоспособность этого потока запросов, вам нужен сервер минимум на 100 ядер. При этом он все равно будет загружен на 110% и работать не сможет (формула немного утрированная, но суть отражает верно).
Что мы делаем для того, чтобы снизить эту чувствительность? Мы буквально тюнингуем самые частовыполняемые запросы, добиваемся максимальной эффективности и минимального потребления ресурсов.
Периодически снимаем трассу всех запросов – собираем не долго, буквально 10-15 минут. За одну секунду такого сбора в трассе получается порядка одного гигабайта данных. Мы группируем эти запросы, "вырезая" имена временных таблиц, смотрим, какие из них самые часто выполняемые и самые «тяжелые». Решаем, что с самыми «тяжелыми» запросами делать дальше – переписать либо попробовать вообще от них отказаться.
- Самый оптимальный запрос – это отсутствие запроса. Поэтому, если удается отказаться (достаточно часто бывают и такие ситуации) – это для нас очень хорошо.

Вторая проблема, которую я хочу отметить, – это "Рост".
- За счет того, что бизнес развивается;
- Увеличивается документооборот;
- Увеличивается количество пользователей;
- Усложняется сам учет.
Плюс к этому разработчики каждые две недели выкатывают сотни строк кода. И это действительно проблема. Вы можете очень долго все тестировать, ревьюить код, но ошибки все равно проскакивают.
В итоге достоверно спрогнозировать, что будет через полгода, год очень сложно…
Поэтому у нас уже профессиональная деформация – мы все постепенно становимся параноиками – пытаемся все зарезервировать, замасштабировать, добиться того, чтобы везде был запас по железу.
Перефразируя цитату про бэкапы: «Вы либо УЖЕ параноик, либо ЕЩЁ НЕ параноик». Конечно, в хорошем смысле этого слова))
Про резервирование и отказоустойчивость.
Придерживаемся следующих принципов:
- кластеризация СУБД и 1С;
- наличие «холодного» и «горячего» резерва;
- запас прочности по железу, как СУБД так и серверов 1С.
Как это выглядит в жизни на примере кластера СУБД:
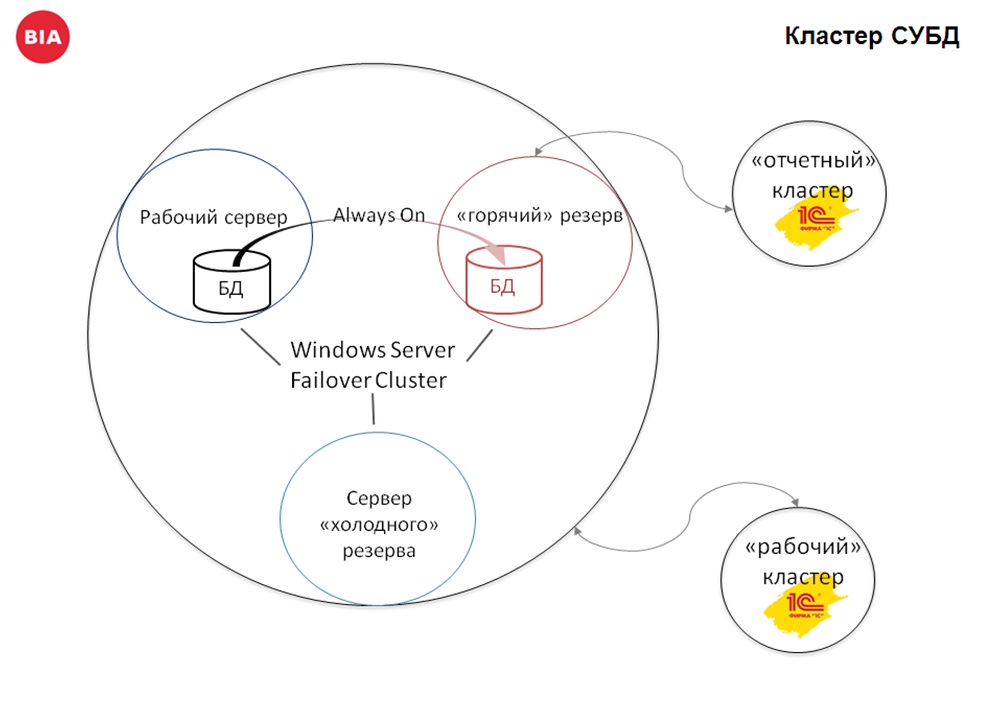
Кластер СУБД собран из трех серверов, за кластеризацию отвечает windows server failover cluster. На одном из серверов рабочая база, на другом вторичный узел репликации AlwaysOn. Это типовая возможность MS SQL Server. База - реплика доступна только на чтение.
У заказчика эта копия отдельно подключена к серверу 1С и в неё можно интерактивно зайти, сформировать отчет, найти нужную информацию. С обычными (толстыми) формами это делается достаточно просто, а вот с управляемыми формами будут проблемы. При их открытии в первый раз платформа пытается сделать запись в таблицу _SystemSettings и получает от сиквел-сервера ошибку.
В копию AlwaysOn, по СОМ соединению, подключаются отчеты, которые пользователь формирует в рабочей базе. А сам запрос отчета выполняется в копии, тем самым распределяя нагрузку.
Третий сервер кластера СУБД сейчас просто в резерве, но долгое время там также была копия базы, только реплика делалась средствами 1С. Это тот же механизм на планах обмена, что использовался при переходе на 8.3.
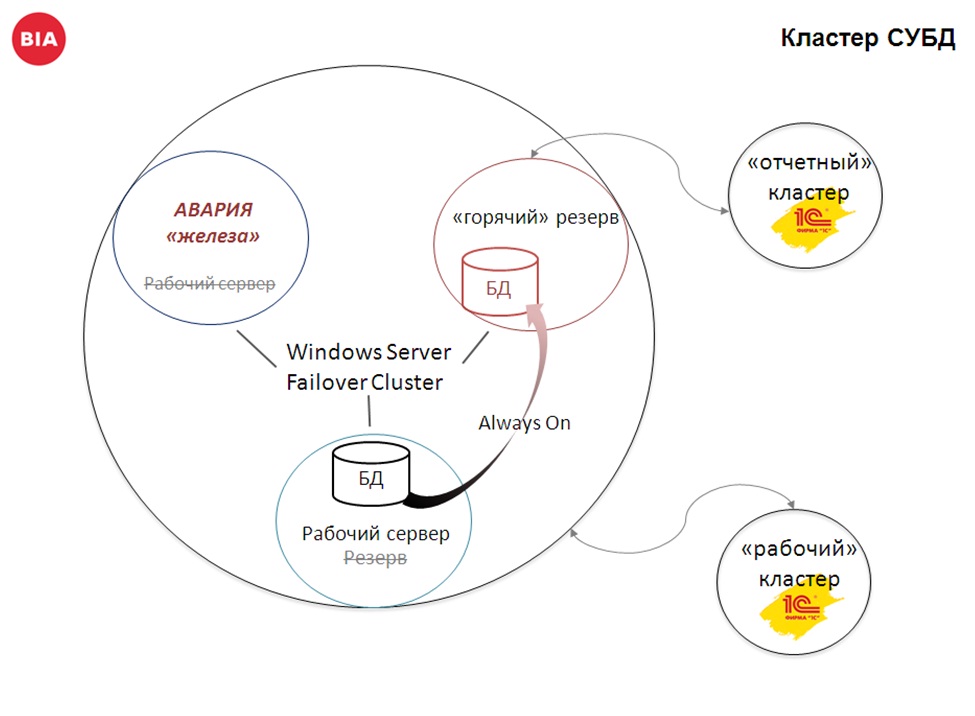
Что эта схема позволяет сделать?
- При проблемах на рабочем сервере (например, у вас планка памяти сгорела или еще что-то), Windows Failover Cluster Server просто мигрирует вашу базу данных на другой сервер:
- Второй момент – если у вас проблема с самой базой данных (например физическое повреждение дисков), тогда можно в качестве рабочей базы использовать базу Always On:
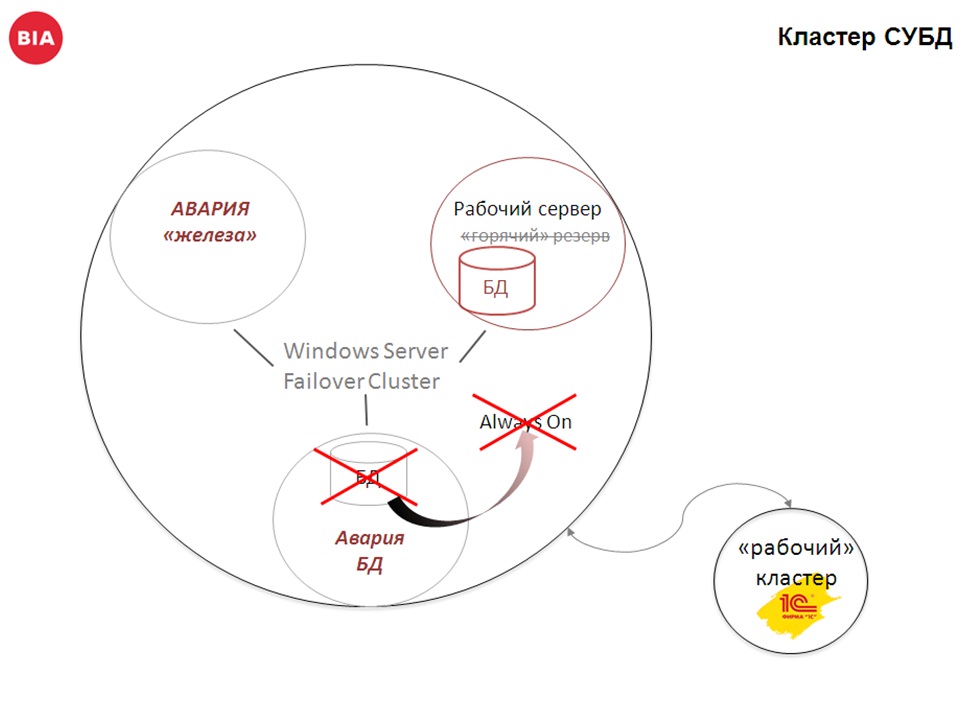
Переключение происходит быстро, единственный момент, необходимо перезапустить службу 1С.
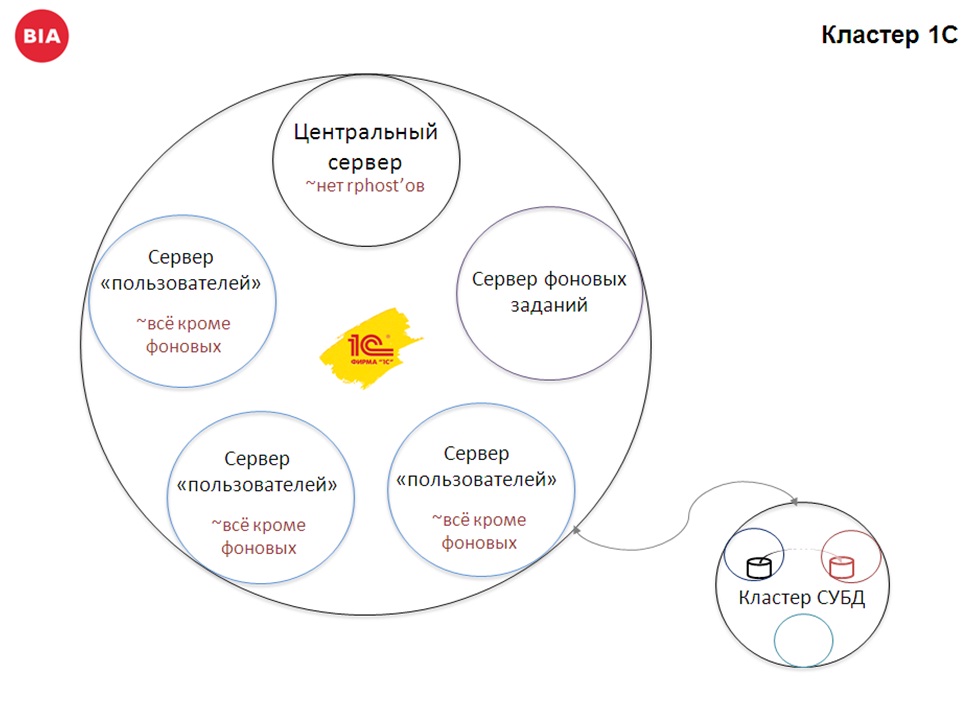
А это уже кластер 1С – он состоит из 5 серверов. Его основные особенности:
- На центральном сервере мы отказываемся от rphost (эта особенность у нас сохранилась еще со времен 8.2).
- Отдельный сервер отдан под фоновые задания. Их у нас тоже достаточно много.
- И оставшиеся три сервера отданы под пользователей. Там не только пользователи – там все, кроме фоновых.
При этом сами сервера имеют запас по железу, и если один из них выходит из строя, то оставшиеся четыре продолжают работать.
Такая схема позволяет нам защищаться от ошибок и пользователей, и разработчиков, и, в том числе, от ошибок железа.
Кстати про косяки в коде, следующая часть доклада как раз им и посвящена.
Разработчики, как и везде, совершают примерно схожие ошибки. Работа с составными типами данных, попытка обойтись без регистров, излишняя универсальность.
Но есть еще другая сторона баррикад… А именно Заказчики.

Текущие реалии таковы, что сейчас модно говорить об Agile и DevOps. Почему это модно?
Ответ прост. Бизнес хорошо понимает, что новая фишка нужна чем раньше, тем лучше. Раньше предоставишь новую услугу, привлечешь больше клиентов, займешь бо'льшую долю рынка.
Основным принципом становиться высокая скорость разработки при приемлемом уровне качества. Повторюсь, ПРИЕМЛИМОЕ качество… Т.е. у вас не будет ни идеальной, ни близкой к ней архитектуры.
Плюс к этому, если на очередной итерации доработок заказчик, вдруг, меняет курс партии на 180 градусов, вы, как исполнитель, должны быстренько переобуться и так же быстренько всё переделать.
Вывод простой, вероятность просчетов и ошибок повышается. Это не хорошо и не плохо, просто к этому надо быть готовыми. И тот же DevOps уделяет внимание возможности быстро "фиксить" ошибки.
И что меня постоянно смущает, так это отношением к косякам и ошибкам..
И то возникающее недоумение, когда ты говоришь «Я вот это сделал так, потому, что текущая архитектура уже устарела» или «Мне нужен такой то функционал для решения ошибок и просчетов». Первая реакция, которая обычно следует: «Что? Нет! Это не кошерно! Просто всё перепишите заново.».
Ну не бывает так в жизни. В жизни вы всегда ищите компромисс. Используя тот же принцип – обеспечить работоспособность минимальными затратами.

Про ошибки я хотел бы отдельно заметить две важных вещи, два основных мифа:
- Идеальной архитектуры не бывает. Если она и бывает, то только в какой-то конечной замкнутой неразвивающейся среде (возможно, даже никому уже давно не нужной).
- Второй момент – все ошибаются. Ошибки – это нормально. Перефразируя доктора Хауса – все «косячат», это наша с вами человеческая природа. И к этому надо быть готовым.
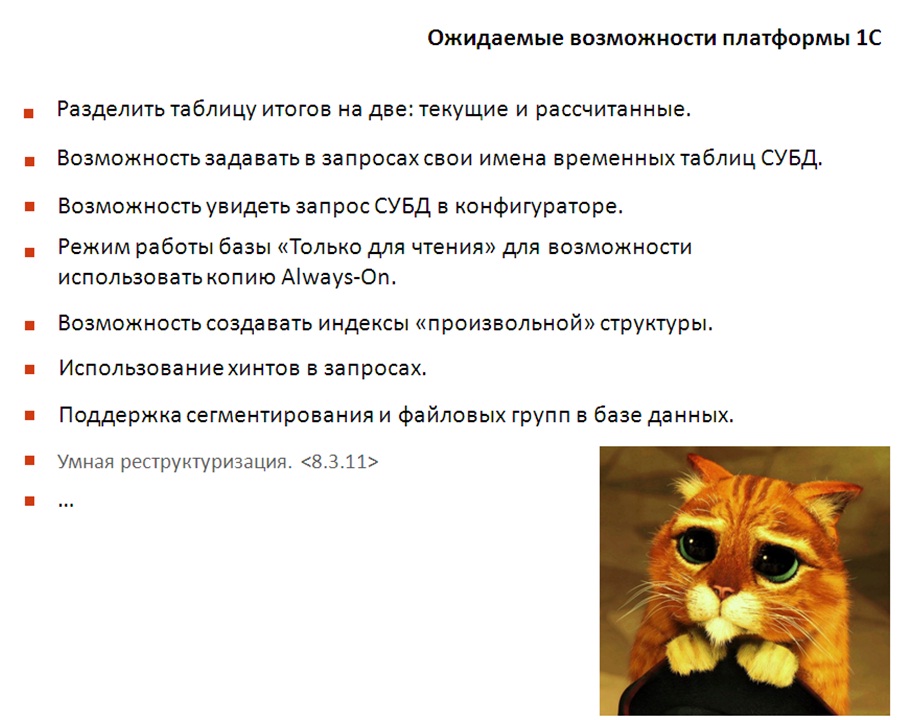
Хотелось бы поговорить про то, чего нам не хватает со стороны платформы 1С на таких масштабных проектах. На слайде перечислены «хотелки» из реальных кейсов, из попыток решить какие-то конкретные задачи, какие-то проблемы. На самом деле все уже придумано и давно есть во взрослых СУБД.
Тут не все "хотелки", тут только приоритетные по нашему мнению. Это то, что нам реально требовалось в ходе решения различных задач.
Отдельные из этих пунктов – холиварные, возникают из-за «бурления масс». Например:
- Использование хинтов в запросах;
- Или возможность создавать индексы произвольной структуры.
Основной довод против – всё, что надо, в платформе уже есть, надо просто всё это знать и уметь.
И самые главные: «НАДО было думать раньше!» «Вы пытаетесь исправить костылем чей то косяк…» фу-фу-фу…
Я даже не говорю о том, что есть какие то реальные задачи, которые этого требуют.., ладно, упростим ситуацию и согласимся с упреками оппонентов: нам это нужно только для того, чтобы компенсировать ошибки... Но ошибки – это ведь нормально, мы про это уже говорили. Да, в идеале надо все переписать с нуля, но в жизни так не бывает. В жизни вы обычно добиваетесь какого-то компромисса и ищете возможность сделать это максимально эффективно, быстро, качественно. Удовлетворить заказчика, в конце концов.
Мое мнение, что ошибки это норма, и это не может быть доводом против расширения возможностей. Наоборот, надо готовиться к тому, что объемы ошибок и их "качество" будет только возрастать.
Заключение
Лично от меня. Отдельная огромная просьба к компании 1С – пересмотреть свое лицензионное соглашение в части использования средств СУБД.
Вместо того, что бы всем сообществом открыто рассматривать опыт применения тех или иных механизмов СУБД, учиться на ошибках друг друга, получать подсказки от разработчиков платформы…
Вместо этого сообщество начинает обрастать секретами Полишинеля, каждый копается в своем муравейнике и изобретает свой велосипед. Это не полезно ни для бизнеса, ни для платформы 1С:Предприятие.
Мое мнение, текущее соглашение мешает развитию 1С:Предприятие, особенно на масштабных и сложных проектах.
Сообществу нужна универсальная платформа для всего и всех, а не только для разработки типовых.
Спасибо за внимание!
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2017 COMMUNITY.

Вступайте в нашу телеграмм-группу Инфостарт