На 1С можно все, но зачем?

Начать свой доклад я хотел бы с моей любимой картинки. Она выражает ключевую мысль, которую я собираюсь до вас донести: «вот так, с помощью нехитрых приспособлений буханку белого (или черного) хлеба можно превратить в троллейбус».
Эта картинка выражает две проблемы:
- Первая – это когда человека, который совсем не 1С-ник и терпеть 1С не может, заставили программировать на 1С. И вот он, пытаясь что-нибудь изобрести, прикручивает сюда различные инструменты, чтобы реализовать задачу, для которой в 1С и так все есть.
- Или наоборот, когда человек слишком 1С-ник, и готов, не используя внешние средства, реализовать целиком на 1С поисковый движок или 3D-игру – мы все на Инфостарте такие примеры видели, там чего только ни делается. Это тоже крайность.
И дело здесь не в том, что 1С не потянет какую-то задачу. Она потянет всё, у нас замечательная платформа для быстрой разработки бизнес-ориентированных приложений. Но современные реалии таковы, что универсального средства на все случаи жизни не бывает.
- Если у вас есть топор, то его нужно использовать для того, чтобы рубить лес. Вы, конечно, можете им побриться или хлеб нарезать, но это не очень удобно, тяжело и, в целом, неправильно.
- Если у вас один разработчик, вам не нужен Agile или DevOps.
- Если у вас три разработчика, которые разрабатывают три 1С-системы, вам не нужна совместная разработка.
- Можно буханку хлеба превратить в троллейбус… но зачем? Для решения специализированных задач нужно использовать специализированные инструменты.
Однако прежде чем рассказать вам о преимуществах такого инструмента, как ClickHouse, мы разберем ситуации, когда он не нужен.
Теоретические основы
Для начала придется чуть-чуть погрузиться в терминологию, чтобы все-таки понимать, о чем я собираюсь рассказывать.
Первым делом вспомним, что такое OLAP и OLTP. Казалось бы, это – две избитых сущности, о которых все слышали:
- OLAP – это On-Line Analytical Processing;
- А OLTP – On-Line Transaction Processing.
OLAP – для чтения, OLTP – для записи данных.
Но фактически OLAP и OLTP – это всего лишь подходы к проектированию, причем, даже не СУБД, а конкретного прикладного решения. Более того, в рамках прикладного решения на одной платформе и одной СУБД может быть применён как OLAP, так и OLTP подход. В современном мире это происходит всё чаще. Далеко ходить не надо:
- В 1С мы знаем, что у нас есть агрегаты по регистру продаж – это классический OLAP-инструмент.
- Также к OLAP в 1С часто относят регистр бухгалтерии, т.к. его структура ориентирована по большей части на быстрое извлечение данных, а проведение, в основном, отложенное (в ERP, например).
- Но в целом, 1С – это больше инструмент ввода данных. Все наши регистры, справочники, документы – это все OLTP.
При этом в современных условиях у нас все чаще возникают OLAP-задачи, на которые платформа 1С в базовом ее виде не рассчитана.
Итак, что же такое OLAP? Термин OLAP – это не всегда означает кубы, это просто специализированное хранение данных, поддерживающее агрегацию. OLAP – это когда нажали кнопку и появился отчет. Не так, что: нажали кнопку, увидели котиков, а потом появился отчет. А сразу – нажали кнопку, и появился отчет. Нажали еще три раза – провалились до проводки. И никто ничего не ждет. OLAP – это когда без котиков. ClickHouse – это OLAP решение.
Какую таблицу можно считать большой?
Я считаю, что ClickHouse нужен только для больших таблиц, когда у вас реально есть что-то большое.
Провокационный вопрос – какую таблицу можно считать большой? У кого есть большие таблицы? Как вы считаете:
- Миллион записей – это большая таблица?
- А десять миллионов?
- А сто миллионов?
Вы все неправы. Большая таблица или нет – это определяется сугубо потребностями пользователя.
- Для кого-то миллион записей – это очень большая таблица. Если по ней миллионы запросов в секунду и все реально жалуются, что работать невозможно, тогда это – действительно большая таблица. С такой таблицей надо работать по всей терминологии OLAP, по всей терминологии BigData.
- А если в таблице 100 миллионов записей, но она никого особо не интересует, и по ней один запрос в год – это маленькая таблица. Вы можете сложить ее в csv-файлик и обращаться к ней только тогда, когда это вам действительно нужно.
Таблицу можно считать большой только тогда, когда к ней большое количество запросов и скорость обработки данных в ней не устраивает конечных пользователей. Универсальным способом определения больших таблиц является APDEX – независимо от того, BigData у нас или нет. Реальный размер никакого значения не имеет.
Когда ClickHouse не нужен
Сжатие таблиц СУБД

Разберем вырожденный пример: у вас есть большая таблица, у которой не выполняется APDEX. Пользователи жалуются, все недовольны, и бизнес говорит: «Что же вы за ИТ-шники, если ничего не можете сделать?». И вы пытаетесь что-то сделать.
Что имеет смысл попробовать в первую очередь?
ClickHouse? Нет. Основная суть моего доклада состоит в том, что нужно использовать средства, соответствующие конкретным задачам. Если бы я сразу начал рассказывать про ClickHouse, смысл был бы неполным. ClickHouse – это космос, который решит все. Но сразу в этот космос погружаться не стоит, есть вполне земные инструменты, которые можно использовать.
Вынужден предупредить, что то, о чем я буду рассказывать, приводится здесь исключительно ради академического интереса, в целях обучения. Ничего подобного с базой 1С, конечно же, делать нельзя, потому что есть лицензионное соглашение, которое мы этими действиями нарушаем.
Но, тем не менее, в первую очередь, когда у вас есть большая таблица, вам ее, конечно, нужно сжать.
Подсознательно мы все привыкли воспринимать сжатие, как что-то плохое, когда нет места на диске и т.д. Но в современных реалиях это не совсем так. Более того, многие СУБД (включая наш ClickHouse) сжимают данные по умолчанию. Сжатие – это хорошо, оно должно быть.
И дело даже не в том, что места на диске мало. Просто в большинстве высоконагруженных систем дисковая подсистема остается узким «горлышком». Мы вынуждены с ней работать, и она нас пока что останавливает. Да, появились SSD, стало лучше, но запись на диск все равно еще не настолько быстро работает, как память и процессор.
Сжатие позволяет сократить операцию записи, расплатившись за это ресурсами процессора. А процессорное время – это сейчас как раз самый простой ресурс:
-
- Процессор стоит дешево, он виртуализируется, его ядра можно докидывать и перераспределять – на скорость работы это влияет существенно.
- А дисковая подсистема – это, как правило, просто большое хранилище. Добавили туда диски или убрали – на скорость работы не влияет.
На слайде приведен пример кода для сжатия таблицы SQL-сервера. Здесь в строке, где указано DATA_COMPRESSION=:
- ROW – это не совсем сжатие.
- PAGE – это сжатие более полноценное. Всем рекомендую второй способ.
Если у вас была большая таблица, которая «тупила», а процессор при этом был загружен на 15%, то после выполнения одной только этой инструкции есть шанс, что вы получите ускорение в производительности ваших запросов в 5-10 раз. Плюс – сэкономите место.
Одна важная деталь – такой подход требует лицензии SQL Server уровня Enterprise (если мы говорим про Microsoft SQL Server).
Секционирование таблиц
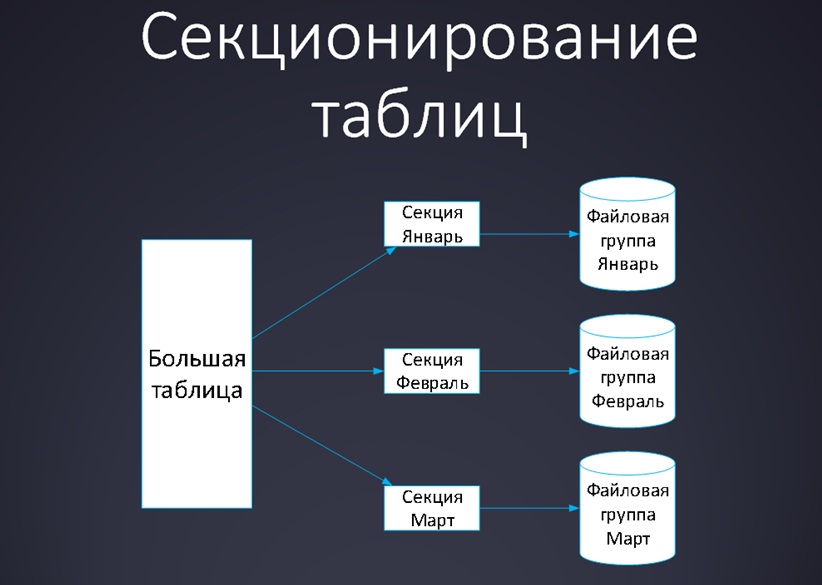
А что делать, если вы сжали таблицу, но быстрее не стало? Или стало быстрее, но ненамного?
Мы можем применить секционирование – разделить таблицу на секции и разложить их по разным дисковым подсистемам, чтобы после этого работать только с одной частью этой таблицы. Эта идея стара как мир – у вас была большая таблица, а стало 10 маленьких.
Как работает секционирование?
- Определяется функция, в соответствии со значениями которой данные будут разделяться на секции. Например: эта секция – январь, эта – февраль, эта – март.
- После применения этой функции разные секции таблицы можно разложить на разные файловые группы и даже на разные диски.
- Логически с таблицей можно работать, как с единым целым.
- Но при этом вы всегда работаете только с теми данными, которые вам нужны: если вся работа ведется в январе, соответственно, вы обращаетесь только к одной секции; если вам нужен март, то к другой.
Все замечательно, все быстро – пишется три команды SQL, происходит реструктуризация.
Кубы, InMemory
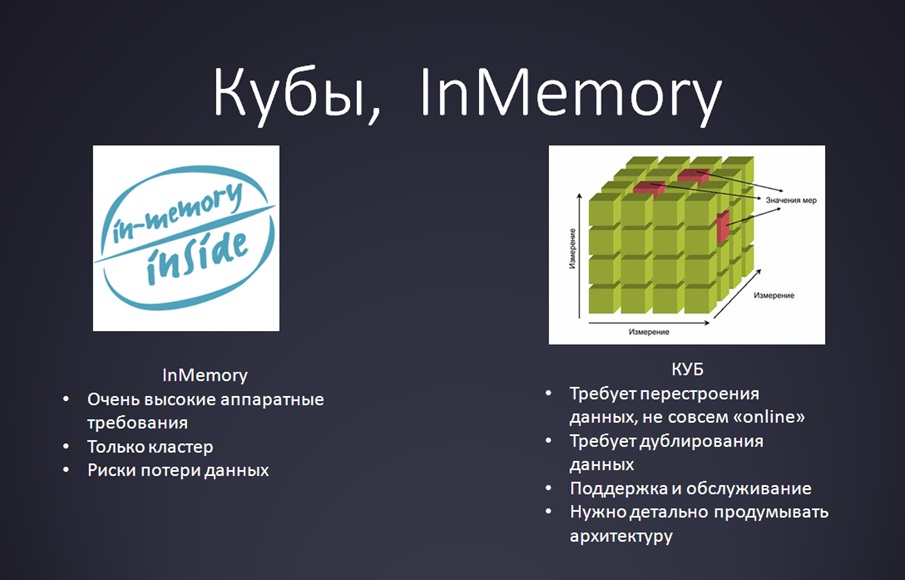
Но что делать, если секционирование тоже не помогло, и пользователи все равно жалуются? Здесь, конечно, можно сразу перейти к ClickHouse, но это – тяжелая артиллерия, торопиться ее применять не стоит.
Прежде всего, имеет смысл рассмотреть традиционную технологию, тем более, если у вас уже используется MS SQL Analysis Services или какие-то BI-решения, или есть компетенции по OLAP. Вы можете взять кубы или воспользоваться InMemory технологиями различного рода – сейчас их, слава богу, много, можно найти даже OpenSource-решения.
- С кубами есть несколько проблем:
- Если у вас был один гигабайт данных, и вы их развернули в куб, то данных стало 10 Гб.
- Работать стало быстрее, но вы эти кубы регулярно перестраиваете.
- Вы добавляете туда новые измерения, а потом выясняется, что вы что-то спроектировали неправильно.
- Соответственно, поскольку куб требует регулярного перестроения – это не совсем online.
- Технология InMemory подразумевает, что:
- Ваши данные изначально очень хорошо организованы с точки зрения структуры;
- У вас есть много памяти;
- И эта память кластеризуется (если одна нода упала, во второй все осталось).
При этом кубы и InMemory технологии – это не совсем простые и легкие решения, поэтому они не получили большого распространения и сейчас потихоньку отмирают.
В результате, как один из вариантов, появляется ClickHouse.
Когда нужен ClickHouse?

Итак, когда ClickHouse действительно нужен?
Когда вы уже достигли предела (SQL-таблички большие и с ними ничего сделать не получается, а кубы и InMemory вас не устраивают) – вот тогда вы действительно уже можете задуматься о специализированном продукте, позволяющем решить те проблемы, про которые вы раньше считали, что их решить невозможно. Возможно все. Слово «невозможно» в современном ИТ-мире для бизнеса произносить нежелательно. Можно «порыться» в Linux World, на GitHub, и вы найдете там множество технологий, о которых даже не задумывались.
Когда нужен ClickHouse:
- Когда данных реально много, а штатные средства уже не помогают.
- И самое главное – когда по этим данным нужна агрегированная информация.
Типичный пример – это журнал регистрации. Он у всех большой, по нему хочется хранить историю, хочется получать логи.
Ну, и загрузите их в ElasticSearch – это замечательная СУБД для того, чтобы закинуть туда кучу хлама и потом в этом хламе найти одну запись. Он стал уже стандартом де-факто для этого. Даже среди 1С-ников его, наверное, многие уже используют.
А о ClickHouse мы говорим тогда, когда нам нужна агрегация данных, когда вам нужно собирать кучу информации о каких-либо частых, но мелких событиях, и потом анализировать эту информацию статистическими методами.
Например, если вам по тому же журналу регистрации нужно построить статистику:
- Сколько было ошибок на протяжении последних 5 лет;
- Какова статистика этих ошибок;
- Какие документы вводят пользователи;
- Сколько времени в среднем проводится такой-то документ.
Тогда вам, действительно, ClickHouse будет полезен. Вы сможете закинуть в него весь тот хлам, который у вас занимает пару терабайт, и строить потом из этого дашборды или делать какие-то графики. В куб вы это закинуть не сможете, потому что у вас данные появляются регулярно, а вы хотите видеть текущие ошибки.
Столбцовые (колоночные) СУБД
Вот так работают обычные реляционные СУБД:

Мы привыкли, что в традиционных СУБД данные в таблицах хранятся по строкам. И чтение-запись также происходит по строкам. Конечно, мы не перебираем все строки подряд, а находим нужную строку по индексу, подтягиваем ее связи и т.д., но, тем не менее, мы работаем со строками.
За счет чего у ClickHouse получается такая скорость обработки?
А теперь давайте «перевернем сознание» и посмотрим на эту же табличку с другой стороны:
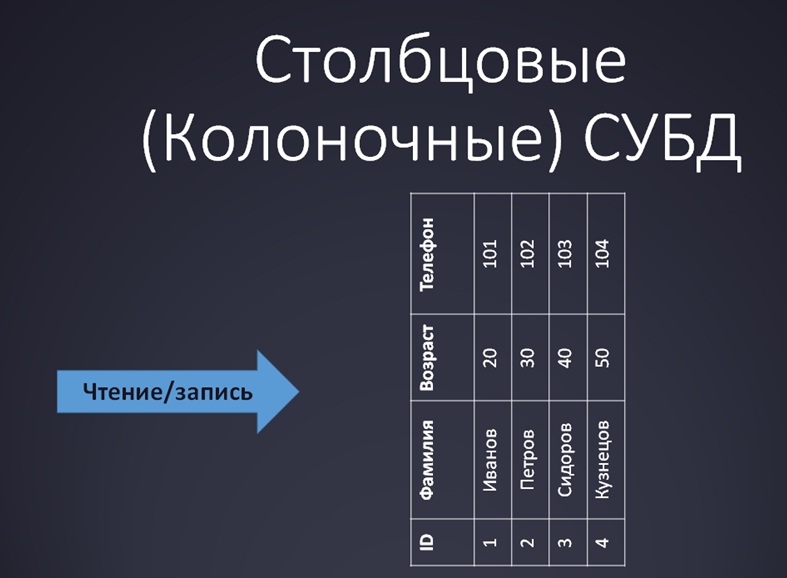
И дальше у вас и чтение, и запись будут производиться по колонкам. Вот и вся модификация. Ничего нового, ничего супер-мега-крутого больше не придумали.
Что достигается за счет такой модификации структуры?
- Данные можно сжать.
- Про нормализацию можно забыть. Зачем была нужна нормализация? Чтобы отделить колонки друг от друга, не хранить данные в пластах. Здесь эта проблема исчезает полностью.
- При выборке данных с диска в память считывается сразу много данных, чтобы с этим работать. Это реально ускоряет запросы в десятки раз.
Столбец vs Строка

- Если вы загрузили данные в столбцовую СУБД, считайте, что вы уже их уменьшили в среднем в 10 раз. В пике – в 20. Реально – то, что раньше весило 10 Гб, стало весить один гигабайт, может быть даже 500 Мб.
- Плюс к этому таблицу можно сжать.
- А также стало быстрее производиться чтение – поскольку это OLAP-решение, оно рассчитано на быстрое чтение.
Правда, с записью в ClickHouse проблематично.
«Яндекс» использует запись порциями (BULK INSERT), когда берем файл, закидываем его в СУБД, и она его успешно парсит. ClickHouse успешно парсит csv и другие форматы файлов.
Представители

В мире данная технология уже давно не новость. ClickHouse – это далеко не первый ее представитель. Весь мир уже давно использует столбцовые СУБД, успешно с ними живет, выпускает специализированные решения:
- Самый известный представитель – это HP Vertica. Она появилась уже лет 15 назад и активно используется по всему миру, в том числе и в России. Стоит очень дорого, как и все с лейблом HP.
- В рамках Facebook родились Cassandra и Hive:
- Cassandra мы воспринимаем как что-то маленькое и очень быстрое;
- Hive люди в основном ассоциируют с Hadoop, с каким-нибудь «монстром». Но тоже очень быстро работает.
- Недавно к этой технологии присоединился Google со своим BigQuery.
- И, неожиданно, компания SAP, которую я не очень люблю, тоже пошла в этом отношении технологически вперед. Теперь база SAP – это уже по большей части столбцовая СУБД. Кроме того, еще и с InMemory. Так что тут мы немного отстали.
- Наш ClickHouse.
- И еще я сюда включил Oracle и Microsoft, базы которых не относятся к столбцовым СУБД, но они эту тему также признали:
- У Oracle недавно появилось Hybrid columnar compression –это позиционируется, как некое сжатие таблички.
- А SQL Server поддерживает Columnstore index – это некое специализированное хранение.
Поэтому можно сказать, что и в SQL, и в Oracle также есть столбцовое хранение.
Быстрее некуда
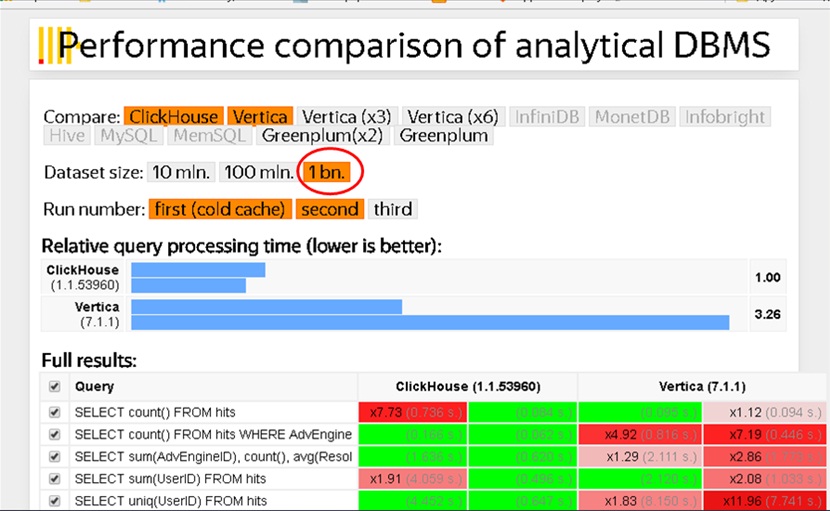
Красивая картинка с сайта Яндекса – сравнение скорости работы HP Vertica и ClickHouse. Не всему здесь, конечно, можно верить, но я думаю, что больше, чем в 2 раза нас не обманывают.
Слева показатели ClickHouse, а справа – HP Vertica, самая скоростная, самая дорогая.
Я бы хотел акцентировать внимание на цифре, которая обведена на слайде. Один миллиард записей. Кто-нибудь делал запросы к таблице в один миллиард записей на SQL сервере? Кто-нибудь считал Count(*) по таблице из одного миллиарда записей?
Те, кто работал с таблицами, состоящими хотя бы из миллиона записей, наверное, представляют, что это такое, и понимают, сколько времени это занимает.
А здесь – посмотрите внимательно – 0.1 секунда, 0.06 секунд. Здесь речь идет не о минутах и не о часах.
Я могу сказать, что у меня на MS SQL для таблицы в миллиард записей Count(*) выполнялось где-то около часа. А здесь оно выполняется в районе долей секунды. Поэтому ClickHouse и MS SQL – это в принципе несопоставимые решения по скорости. Это абсолютно разный класс СУБД, несмотря на то, что ClickHouse – это SQL-решение, и вы в нем можете использовать тот же синтаксис запросов.
Чудес не бывает!
Конечно, чудес не бывает. У ClickHouse много ограничений, которые делают его специализированным решением, а не «универсальной СУБД»:
- Например, у ClickHouse нет операций Delete и Update. Главный разработчик сказал «а зачем?» ClickHouse изначально разрабатывался для проекта Яндекс.Метрика – там просто нужна статистика по операциям. Человек кликнул на сайте, это записалось в базу. Модифицировать и удалять этот клик бессмысленно, поэтому Delete и Update нет.
- Дальше – драйвер ODBC появился недавно, и в нём много проблем. Появился совсем недавно. Сейчас он уже худо-бедно работает, его можно использовать, можно даже к Excel подключиться и что-то туда передать, но к 1С, как к внешнему источнику, пока еще не подключим.
- Не особо быстрый INSERT – это общая проблема столбцовых СУБД. Данные в ClickHouse вообще лучше помещать пакетами (использовать BULK INSERT)
- Как и во многих специализированных OpenSource решениях (в NoSQL, например), транзакций нет. Потому что транзакция и СУБД – это отдельная песня. В современном мире транзакции не очень любят.
- А также множество других ограничений:
- Не совсем стандартный SQL;
- Разные движки таблиц;
- Работает только под Linux.
Для чего можно использовать ClickHouse простому 1С-нику?
Лично мне ClickHouse нужен был всего в нескольких кейсах. Пока эта технология не появилась, я отвечал бизнесу: «Это невозможно». Мне всегда очень стыдно, когда я говорю «невозможно» или не могу этого сделать – для меня важно, что мы можем сделать все, даже если это не очень серьезные задачи.
Для чего можно было бы использовать ClickHouse:
- Первое – это анализ логов, получение любых статистических показателей из журнала регистрации. Наверное, ни для кого не секрет, что журнал регистрации в 1С имеет много недостатков:
- В новом формате из него можно успешно читать данные, но когда 1С в него пишет, пользователям приходится ждать из-за блокировок. Поэтому новый формат можно использовать, только если у вас небольшая база.
- В реальном HighLoad выживает только старый формат журнала регистрации, но в этом виде получить из него какие-то данные, кроме последнего дня, вы не сможете.
ClickHouse – это реальный способ хоть как-то работать с данными журнала регистрации. Либо, если вам по нему нужен только поиск, используйте ElasticSearch.
- Второе – это анализ любых операций.
- Третье – это KPI, статистика работы пользователя. Никто никогда не пытался вести в 1С статистику работы пользователя просто потому, что для этого не было инструментов. Теперь такой инструмент есть – это ClickHouse.
- И еще одна задача, более жизненный бизнес-кейс, это – динамика остатков. Дальше я про него детальнее расскажу.
Варианты использования с 1С
Анализ журнала регистрации
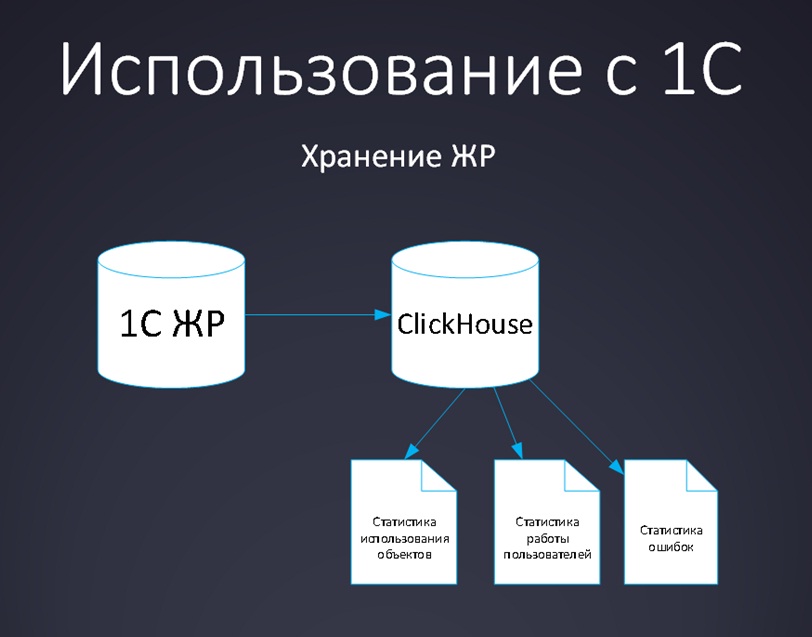
Итак, что мы делали с журналом регистрации:
- Брали журнал регистрации из 1С;
- Загружали его в ClickHouse;
- И потом из 1С обращались уже к ClickHouse, и выводили его данные в отчеты.
У ClickHouse есть замечательный HTTP-интерфейс: вы пишете через него запросы, они обрабатываются, и никаких проблем это не вызывает.
Отчет «Динамика остатков»
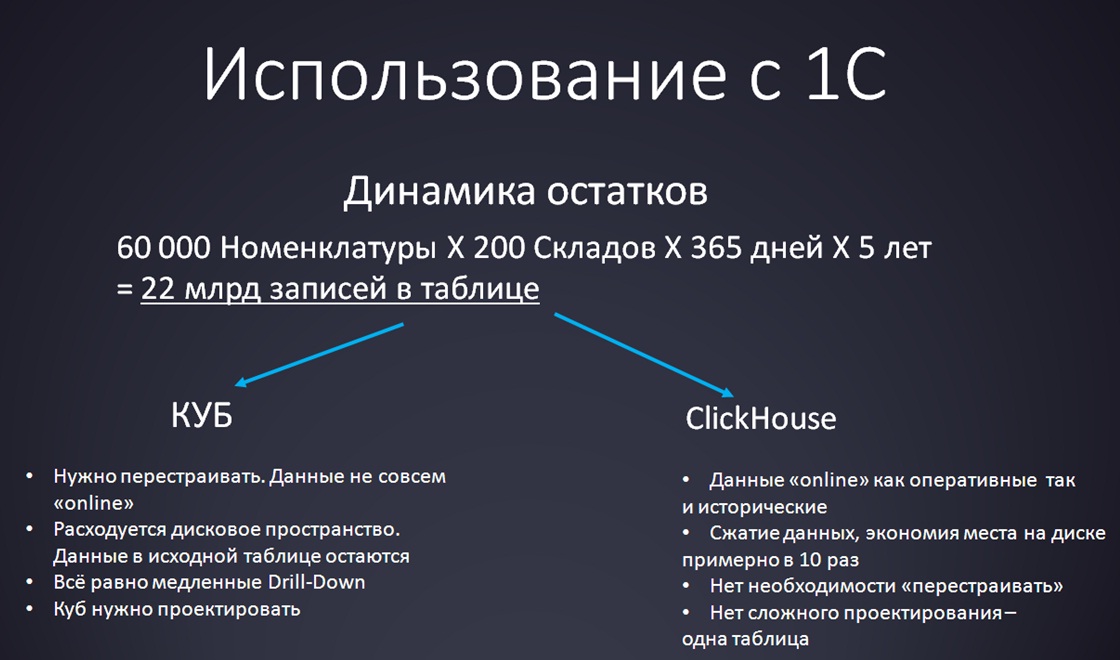
Итак, наиболее жизненный вариант применения ClickHouse – отчет «Динамика остатков». Это достаточно традиционная задача, которую обычно никто не относит к вопросу «больших данных». В любой более-менее нормальной организации аналитики пытаются строить такие отчеты.
Но вы представьте:
- У нас есть 60 000 позиций номенклатуры. Это немного – обычная торговая компания.
- 200 складов – это тоже немного.
- И мы хотим всего лишь проанализировать динамику остатков по каждой номенклатуре на каждом складе за каждый день в течение пяти лет.
Итого мы получаем 22 миллиарда записей.
В 1С построить такой отчет нереально, все представляют, что это такое. Если и получится это сделать, то только с учетом сторонних средств.
Рассмотрим два варианта – куб или ClickHouse.
- Кто уже решал подобные задачи при помощи кубов знают традиционные проблемы:
- Данных много, место на диске расходуется неоправданно быстро.
- Типичный случай: вы проектируете куб, определили его измерения, а потом через день хотите добавить еще одно измерение. Приходится переделывать хранилище данных, чистить его, загружать заново. Не очень приятная операция – кто занимался, может быть, знает.
- Регулярно требуется долгое перестроение.
- Проходит оно не всегда удачно.
- Конечные пользователи будут удивляться: «А почему у меня там данные за вчерашний день?», «А всегда нужно использовать два источника?», «Как только я хочу “провалиться” до товара – все начинает тупить». Неудивительно, что начинает тупить, потому что когда происходит Drill Down, идет обращение к исходной таблице, а в ней 22 млрд записей.
- ClickHouse решает большую часть этих проблем:
- Вы получаете остатки в режиме online. Можно видеть в базе как текущие остатки, которые туда регулярно подгружаются (мы настроили интервал обновления данных – 5 минут).Так и исторические данные за предыдущие 10-20 лет.
- Весь этот объем ClickHouse вполне успешно обрабатывает за короткое время.
- При этом самих данных становится меньше. Если при помещении в куб данных становится в 10 раз больше, то ClickHouse их, наоборот, сожмет.
- И дальше вам не нужно будет больше ничего перестраивать.
- И не нужно ничего проектировать.
Установка ClickHouse

Как видите, вся инструкция по установке влезла на один слайд. Сама по себе установка предельно проста:
- Главное – не надо бояться Linux-а. Я тоже совсем не линуксоид, но это нестрашная система. Можно скачать готовый образ Linux и развернуть его на виртуалке. Все это делается за 5 минут.
- С помощью трех волшебных строчек скачиваете установочный файл ClickHouse из репозитория и все обновляете.
- Дальше стартуете сервис.
- И проверяете его работу через HTTP-интерфейс.
Несмотря на то, что ClickHouse существует только под одну платформу (и это его минус), установка под Linux происходит быстрее, чем мы с вами привыкли под Windows. И уж тем более, ClickHouse поставить гораздо быстрее, чем MS SQL. Поверьте, это реально так, причем, то же самое можно сказать про любую «страшную» стороннюю СУБД.
Создание таблицы
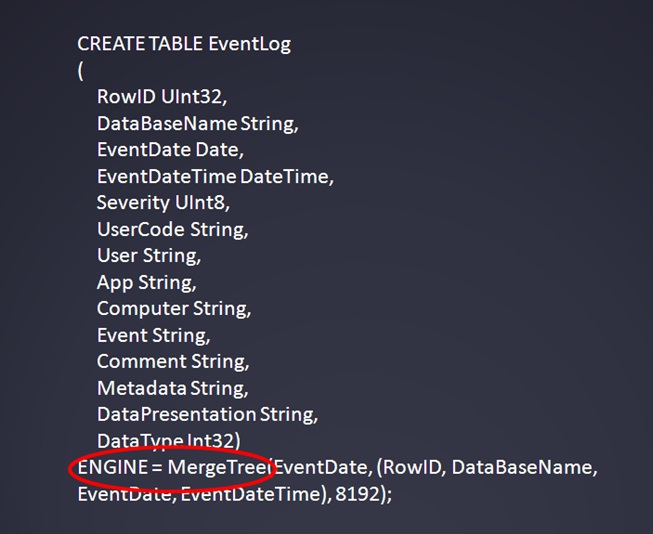
Команда по созданию таблицы из командной строки выглядит примерно так, как на слайде.
- Синтаксис команды стандартный, как и в нормальном SQL – CREATE TABLE.
- Самое важное тут – ENGINE=MergeTree. Это так называемый «движок таблицы». Для Web-разработчиков указывать движок – дело привычное, но для нас с вами не особо.
- MergeTree – это единственный нормальный движок ClickHouse. Как я понимаю, в «Яндексе» используют и развивают в основном его, и именно он работает быстро.
- Другие движки могут использоваться для промежуточных данных. Например, в «Яндексе» при массовой загрузке рекомендуют грузить данные сначала в движок Log а потом уже внутри ClickHouse преобразовывать в MergeTree.
- Параметры, указываемые при создании:
- Первый параметр – столбец с датой. Он обязательно должен быть в создаваемой таблице.
- Второй параметр – первичный ключ.
- Третий параметр очень специфичен, нигде в документации по ClickHouse я не нашел, что он значит, и его лучше не менять.
Создать таблицу можно как программно, так и из командной строки.
Чтение и запись
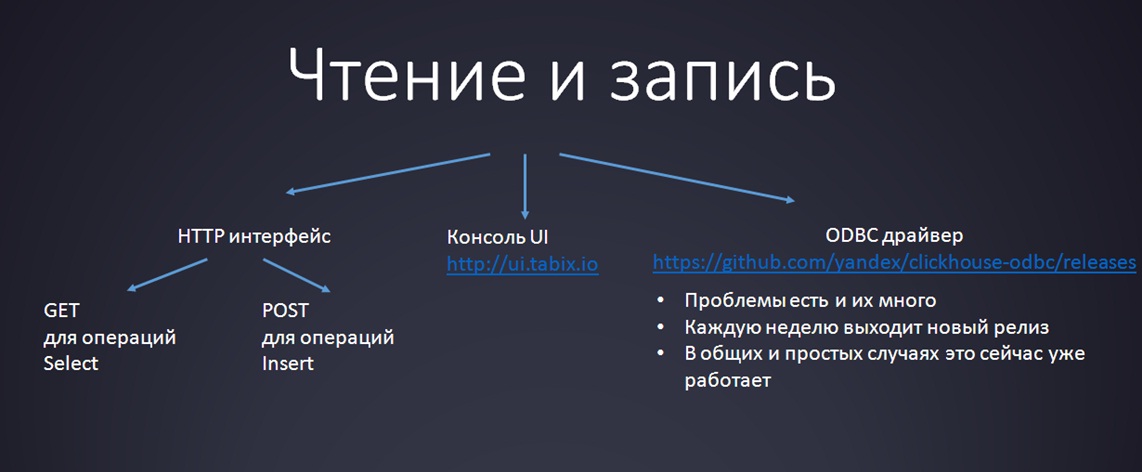
Есть несколько вариантов взаимодействия с ClickHouse, но нас интересует всего три:
- У ClickHouse есть ODBC-драйвер, про который я уже сказал.
- Он активно развивается, каждую неделю выходит новый релиз, который исправляет одни баги и приносит другие. Он уже почти работает, им можно пользоваться, но для ограниченного круга задач.
- Подключить его к 1С в качестве внешнего источника данных пока что вряд ли получится (у меня, во всяком случае, на момент подготовки к докладу не получалось), но интеграция с Excel вполне возможна.
- Есть неплохая UI консоль с минималистичным интерфейсом, написанная на JavaScript. Просто открываете ссылку http://ui.tabix.io, вводите свои настройки подключения, подключаетесь и наслаждаетесь жизнью. Особенно, если, как и я, не любите командную строку.
- Также у ClickHouse есть универсальный кроссплатформенный HTTP-интерфейс. Работать с ним просто:
- Для операций SELECT используются элементарные GET-запросы.
- Для операций INSERT – чуть более сложные POST-запросы. Это, наверное, стандартная типовая логика. Но вообще INSERT нужно делать через BULK INSERT.
Пример обращения к ClickHouse из 1С
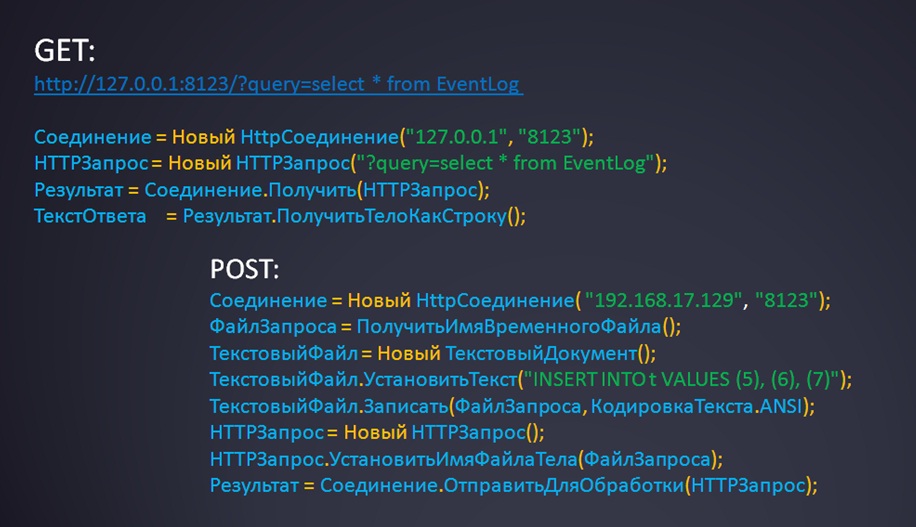
Чтобы «грело душу», приведу пример кода на 1С. Тут нет ничего сложного – все, кто использовал HTTP-соединение из 1С, все знают, как это происходит:
- GET-запрос для SELECT – это обычно Соединение.Получить().
- И POST-запрос для INSERT – Соединение.ОтправитьДляОбработки().
Еще раз повторюсь, для POST это всего лишь пример. В реальности если у вас скопился журнал регистрации на сотни гигабайт, так вы его не загрузите, нужно использовать BULK INSERT. Сама команда будет похожая, но вы сформируете CSV-файлик, который потом передадите в ClickHouse.
- Сам парсинг журнала регистрации 1С у нас производится в стороннем приложении, оттуда и поступает команда BULK INSERT.
- А потом в 1С мы только читаем данные из ClickHouse и строим отчеты.
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2017 COMMUNITY.
Готовое решение для автоматической выгрузки данных из 1С 8.3 в базу данных ClickHouse, PostgreSQL или Microsoft SQL для работы с данными 1С в BI-системах:
«Экстрактор данных 1С в BI» работает со всеми типовыми и нестандартными конфигурациями 1С 8.3 и упрощает работу бизнес-аналитиков, программистов, финансовых и технических директоров.
Простое подключение к системам BI позволит вести углубленный анализ данных и эффективно отлаживать бизнес-процессы.

Вступайте в нашу телеграмм-группу Инфостарт