На 1С можно все, но зачем?

Начать свой доклад я хотел бы с моей любимой картинки. Она выражает ключевую мысль, которую я собираюсь до вас донести: «вот так, с помощью нехитрых приспособлений буханку белого (или черного) хлеба можно превратить в троллейбус».
Эта картинка выражает две проблемы:
- Первая – это когда человека, который совсем не 1С-ник и терпеть 1С не может, заставили программировать на 1С. И вот он, пытаясь что-нибудь изобрести, прикручивает сюда различные инструменты, чтобы реализовать задачу, для которой в 1С и так все есть.
- Или наоборот, когда человек слишком 1С-ник, и готов, не используя внешние средства, реализовать целиком на 1С поисковый движок или 3D-игру – мы все на Инфостарте такие примеры видели, там чего только ни делается. Это тоже крайность.
И дело здесь не в том, что 1С не потянет какую-то задачу. Она потянет всё, у нас замечательная платформа для быстрой разработки бизнес-ориентированных приложений. Но современные реалии таковы, что универсального средства на все случаи жизни не бывает.
- Если у вас есть топор, то его нужно использовать для того, чтобы рубить лес. Вы, конечно, можете им побриться или хлеб нарезать, но это не очень удобно, тяжело и, в целом, неправильно.
- Если у вас один разработчик, вам не нужен Agile или DevOps.
- Если у вас три разработчика, которые разрабатывают три 1С-системы, вам не нужна совместная разработка.
- Можно буханку хлеба превратить в троллейбус… но зачем? Для решения специализированных задач нужно использовать специализированные инструменты.
Однако прежде чем рассказать вам о преимуществах такого инструмента, как ClickHouse, мы разберем ситуации, когда он не нужен.
Теоретические основы
Для начала придется чуть-чуть погрузиться в терминологию, чтобы все-таки понимать, о чем я собираюсь рассказывать.
Первым делом вспомним, что такое OLAP и OLTP. Казалось бы, это – две избитых сущности, о которых все слышали:
- OLAP – это On-Line Analytical Processing;
- А OLTP – On-Line Transaction Processing.
OLAP – для чтения, OLTP – для записи данных.
Но фактически OLAP и OLTP – это всего лишь подходы к проектированию, причем, даже не СУБД, а конкретного прикладного решения. Более того, в рамках прикладного решения на одной платформе и одной СУБД может быть применён как OLAP, так и OLTP подход. В современном мире это происходит всё чаще. Далеко ходить не надо:
- В 1С мы знаем, что у нас есть агрегаты по регистру продаж – это классический OLAP-инструмент.
- Также к OLAP в 1С часто относят регистр бухгалтерии, т.к. его структура ориентирована по большей части на быстрое извлечение данных, а проведение, в основном, отложенное (в ERP, например).
- Но в целом, 1С – это больше инструмент ввода данных. Все наши регистры, справочники, документы – это все OLTP.
При этом в современных условиях у нас все чаще возникают OLAP-задачи, на которые платформа 1С в базовом ее виде не рассчитана.
Итак, что же такое OLAP? Термин OLAP – это не всегда означает кубы, это просто специализированное хранение данных, поддерживающее агрегацию. OLAP – это когда нажали кнопку и появился отчет. Не так, что: нажали кнопку, увидели котиков, а потом появился отчет. А сразу – нажали кнопку, и появился отчет. Нажали еще три раза – провалились до проводки. И никто ничего не ждет. OLAP – это когда без котиков. ClickHouse – это OLAP решение.
Какую таблицу можно считать большой?
Я считаю, что ClickHouse нужен только для больших таблиц, когда у вас реально есть что-то большое.
Провокационный вопрос – какую таблицу можно считать большой? У кого есть большие таблицы? Как вы считаете:
- Миллион записей – это большая таблица?
- А десять миллионов?
- А сто миллионов?
Вы все неправы. Большая таблица или нет – это определяется сугубо потребностями пользователя.
- Для кого-то миллион записей – это очень большая таблица. Если по ней миллионы запросов в секунду и все реально жалуются, что работать невозможно, тогда это – действительно большая таблица. С такой таблицей надо работать по всей терминологии OLAP, по всей терминологии BigData.
- А если в таблице 100 миллионов записей, но она никого особо не интересует, и по ней один запрос в год – это маленькая таблица. Вы можете сложить ее в csv-файлик и обращаться к ней только тогда, когда это вам действительно нужно.
Таблицу можно считать большой только тогда, когда к ней большое количество запросов и скорость обработки данных в ней не устраивает конечных пользователей. Универсальным способом определения больших таблиц является APDEX – независимо от того, BigData у нас или нет. Реальный размер никакого значения не имеет.
Когда ClickHouse не нужен
Сжатие таблиц СУБД

Разберем вырожденный пример: у вас есть большая таблица, у которой не выполняется APDEX. Пользователи жалуются, все недовольны, и бизнес говорит: «Что же вы за ИТ-шники, если ничего не можете сделать?». И вы пытаетесь что-то сделать.
Что имеет смысл попробовать в первую очередь?
ClickHouse? Нет. Основная суть моего доклада состоит в том, что нужно использовать средства, соответствующие конкретным задачам. Если бы я сразу начал рассказывать про ClickHouse, смысл был бы неполным. ClickHouse – это космос, который решит все. Но сразу в этот космос погружаться не стоит, есть вполне земные инструменты, которые можно использовать.
Вынужден предупредить, что то, о чем я буду рассказывать, приводится здесь исключительно ради академического интереса, в целях обучения. Ничего подобного с базой 1С, конечно же, делать нельзя, потому что есть лицензионное соглашение, которое мы этими действиями нарушаем.
Но, тем не менее, в первую очередь, когда у вас есть большая таблица, вам ее, конечно, нужно сжать.
Подсознательно мы все привыкли воспринимать сжатие, как что-то плохое, когда нет места на диске и т.д. Но в современных реалиях это не совсем так. Более того, многие СУБД (включая наш ClickHouse) сжимают данные по умолчанию. Сжатие – это хорошо, оно должно быть.
И дело даже не в том, что места на диске мало. Просто в большинстве высоконагруженных систем дисковая подсистема остается узким «горлышком». Мы вынуждены с ней работать, и она нас пока что останавливает. Да, появились SSD, стало лучше, но запись на диск все равно еще не настолько быстро работает, как память и процессор.
Сжатие позволяет сократить операцию записи, расплатившись за это ресурсами процессора. А процессорное время – это сейчас как раз самый простой ресурс:
-
- Процессор стоит дешево, он виртуализируется, его ядра можно докидывать и перераспределять – на скорость работы это влияет существенно.
- А дисковая подсистема – это, как правило, просто большое хранилище. Добавили туда диски или убрали – на скорость работы не влияет.
На слайде приведен пример кода для сжатия таблицы SQL-сервера. Здесь в строке, где указано DATA_COMPRESSION=:
- ROW – это не совсем сжатие.
- PAGE – это сжатие более полноценное. Всем рекомендую второй способ.
Если у вас была большая таблица, которая «тупила», а процессор при этом был загружен на 15%, то после выполнения одной только этой инструкции есть шанс, что вы получите ускорение в производительности ваших запросов в 5-10 раз. Плюс – сэкономите место.
Одна важная деталь – такой подход требует лицензии SQL Server уровня Enterprise (если мы говорим про Microsoft SQL Server).
Секционирование таблиц
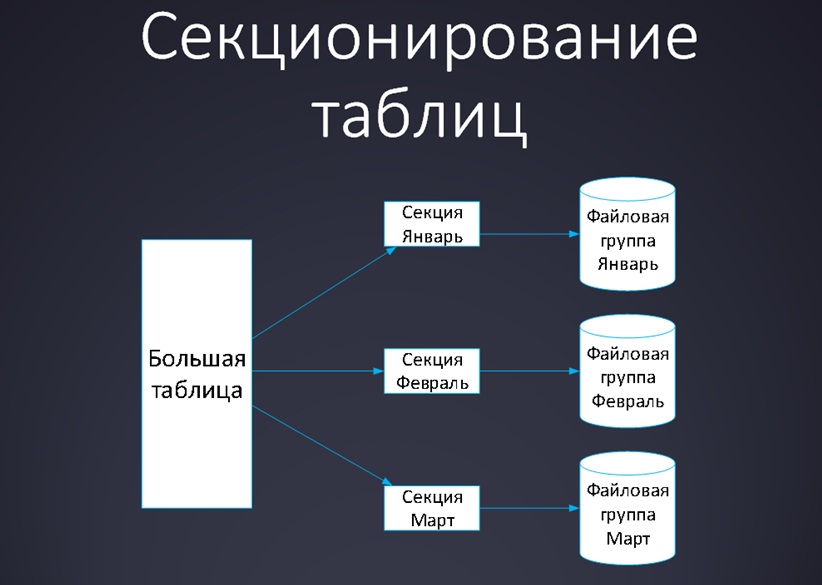
А что делать, если вы сжали таблицу, но быстрее не стало? Или стало быстрее, но ненамного?
Мы можем применить секционирование – разделить таблицу на секции и разложить их по разным дисковым подсистемам, чтобы после этого работать только с одной частью этой таблицы. Эта идея стара как мир – у вас была большая таблица, а стало 10 маленьких.
Как работает секционирование?
- Определяется функция, в соответствии со значениями которой данные будут разделяться на секции. Например: эта секция – январь, эта – февраль, эта – март.
- После применения этой функции разные секции таблицы можно разложить на разные файловые группы и даже на разные диски.
- Логически с таблицей можно работать, как с единым целым.
- Но при этом вы всегда работаете только с теми данными, которые вам нужны: если вся работа ведется в январе, соответственно, вы обращаетесь только к одной секции; если вам нужен март, то к другой.
Все замечательно, все быстро – пишется три команды SQL, происходит реструктуризация.
Кубы, InMemory
Но что делать, если секционирование тоже не помогло, и пользователи все равно жалуются? Здесь, конечно, можно сразу перейти к ClickHouse, но это – тяжелая артиллерия, торопиться ее применять не стоит.
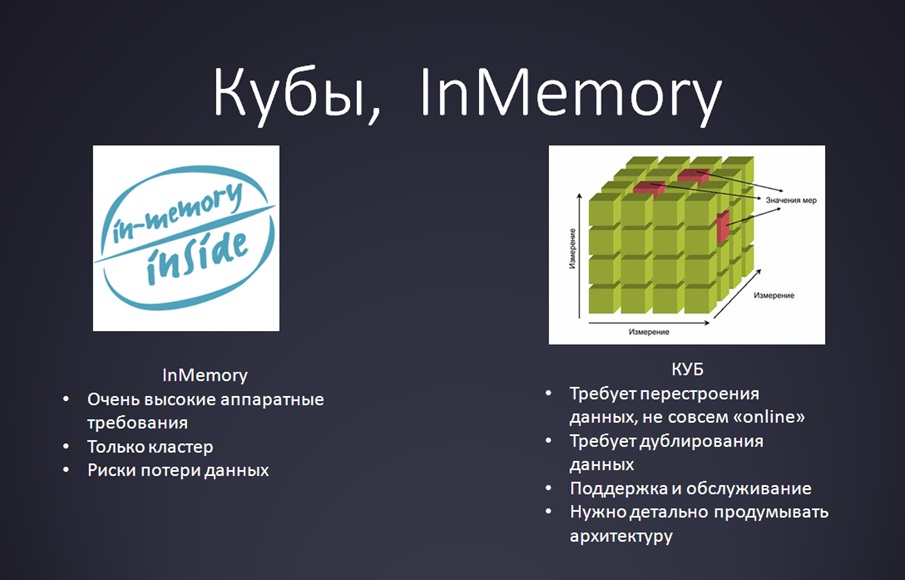
Прежде всего, имеет смысл рассмотреть традиционную технологию, тем более, если у вас уже используется MS SQL Analysis Services или какие-то BI-решения, или есть компетенции по OLAP. Вы можете взять кубы или воспользоваться InMemory технологиями различного рода – сейчас их, слава богу, много, можно найти даже OpenSource-решения.
- С кубами есть несколько проблем:
- Если у вас был один гигабайт данных, и вы их развернули в куб, то данных стало 10 Гб.
- Работать стало быстрее, но вы эти кубы регулярно перестраиваете.
- Вы добавляете туда новые измерения, а потом выясняется, что вы что-то спроектировали неправильно.
- Соответственно, поскольку куб требует регулярного перестроения – это не совсем online.
- Технология InMemory подразумевает, что:
- Ваши данные изначально очень хорошо организованы с точки зрения структуры;
- У вас есть много памяти;
- И эта память кластеризуется (если одна нода упала, во второй все осталось).

Загрузчик данных из 1С в BI-системы
Решение «Экстрактор данных 1С в BI» автоматически выгружает данные из 1С 8.3 в ClickHouse, PostgreSQL, Microsoft SQL для интеграции с BI. Работает с типовыми и кастомными конфигурациями 1С. Доступна бесплатная 5-дневная демо-версия.
Вступайте в нашу телеграмм-группу Инфостарт