-
Постановка задачи
-
Выбор инструментов
-
Ограничение Gitsync на TCP, HTTP и что с этим делать
-
Структура каталогов и репозиториев
-
Настройки хранилища
- Установка Git
-
Настройка репозитория
-
Создание или эмуляция удаленного репозитория
-
Пример связи коммитов с задачами и пользователями гит-сервера
-
Атрибуты коммитов, устанавливаемые gitsync
-
Пишем скрипт выгрузки
-
Регулярная выгрузка по расписанию
-
Что мы получаем при использовании Gitlab, Upsource, Crucible и т.д.
-
Хранение внешних обработок, тестов, документации в репозитории
-
Методы облегчения конфигурации, репозитория и ускорения выгрузки
-
О гит-клиентах
Данная публикация предназначена для коллег, которые понимают какую пользу принесет доступ к истории и коду конфигурации в 1С. Здесь внимание акцентируется не столько на преимуществах применения git при разработке на 1С, сколько на практических приемах работы. За описанием преимуществ здорового образа жизни разработчика можно обратиться к следующим публикациям :
- Git-flow В 1С
- Использование git для доработки типовых конфигураций 1С
- Разработка через автоматизацию, в помощь типовому 1С-нику
- Еще один Git-flow В 1С
Как по своей практике, так и из общения с коллегами знаю, что во многих компаниях есть разработчики 1С, которые хотели бы наладить процесс, подобный описанному в публикациях выше. Но главной сложностью является нехватка полных работающих пошаговых инструкций. Публикаций, описывающих возможности инструментов и преимущества работы с git или даже процесса gitflow много, но работающих инструкций крайне мало. Лучшей пошаговой инструкцией, которую я до сих пор видел является следующий документ "Развертывание проекта разработки 1С с использованием системы контроля версий Git” авторства Станислава Ганиева. К сожалению его содержимое было спрятано от индексации поисковиками форматом “docx”. Рекомендую прочитать его, а также справку по возможностям основного применяемого здесь инструмента на Гитхабе: https://github.com/oscript-library/gitsync
Здесь же хотелось бы дать более развернутую инструкцию, методические и технические советы на основе опыта применения git при работе с типовыми конфигурациями, в том числе 1С: ERP, связи коммитов с задачами в таск-трекере и проведения код-ревью.
Постановка задачи
Нам необходимо
- Обеспечить регулярный запуск задачи по выгрузке каждой закладки в хранилище в отдельный коммит в git.
- Корректно настроить репозиторий для работы с большими конфигурациями и хранилищем конфигурации с большим количеством закладок.
- Возможность обработать случай некорректного комментария закладки в хранилище, не позволяющего связать коммит с задачей в таск-трекере, и приостановить процесс дальнейшей обработки хранилища до исправления ситуации.
- Возможность отловить случай, когда в результате выгрузки не появилось новых изменений изменений, и не выполнять шаги, которые должны выполняться только при наличии изменений (автотестирование, сборка и т.д.).
- Обработать исключительные ситуации: не удалось переключиться на нужную ветку репозитория, не удалось создать временный каталог для выгрузки хранилища и т.д.
- Обозначить основные правила для использования репозитория git в связке с таск-трекером и системами код-ревью.
- Обозначить основные методы и действия по дальнейшему развитию описанного здесь функционала: хранение в репозитории внешних по отношению к конфигурации файлов, ускорение выгрузки больших конфигураций, подключение Jenkins или другого сервера сборок к процессу.
Выбор инструментов
Сейчас для выгрузки хранилища в git есть несколько вариантов:
- Gitsync. Имеет пожалуй наибольшее количество примеров применения. Поставляется в составе одноименной библиотеки OneScript. Использует ряд других библиотек. Внутри имеет стройный код. Для работы с хранилищем требует доступ на чтение самих файлов хранилища, то есть не поддерживает доступ к хранилищу через tcp и http. Проблема не большая так как доступа на чтение через расшаренную папку будет достаточно. Gitsync будет использован для этой публикации.
- 1С:ГитКонвертер. Привлекает то, что создается сотрудниками фирмы 1С. Но на данный момент с одной стороны крайне плохо документирован. С другой стороны разобраться в его коде и структурах данных самостоятельно достаточно сложно. Рекомендуется создание отдельной серверной базы для него, чтобы нормально отрабатывало регламентное задание. В данный момент показалось целесообразным разбираться с нем больше в целях обучения, нежели в применении на практике. Кроме того не ясно, будет ли развитию ГитКонвертера уделяться должное внимание с учетом грядущего EDT. И не создавался ли он изначально только для конвертации в формат EDT.
- Gitter. И его изначальный вариант. Судя по репозиторию проекта и публикациям на Инфостарте разобраться с ним сложности не составит.
- Самостоятельная выгрузка средствами платформы. Из преимуществ: свобода в оптимизации алгоритмов выгрузки. Например всегда выгружать в каталог репозитория не применяя промежуточный временный каталог как это делает gitsync (в режиме полной, а не инкрементальной выгрузки). Как при этом сопоставлять пользователей хранилища с их e-mail-ами (для последующего просмотра изменений в Gitlab/Fisheye/Bitbucket в привязке к пользователям) и как отслеживать последнюю выгруженную версию хранилища можно посмотреть в исходниках каждого из проектов, перечисленных выше. Разумеется в этом случае уже не обойтись простым скриптом.
OneScript - думаю в представлении не нуждается. Кроссплатформенный движок для запуска скриптов, написанных на языке 1С. При использовании VSC есть отладка, есть подсветка синтаксиса, контекстная подсказка. Конечно он лучше чем платформозависимые bat или sh скрипты. И более быстр в освоении для разработчика 1С, чем аналоги на других языках.
Планировщик Windows - простейший инструмент запуска заданий по расписанию. Начинать лучше именно с него. Если есть необходимость только регулярной выгрузки хранилища без последующих действий, то можно на нем и остановиться. Если же цель поставить процесс сборки, тестирования, подготовки релизов, то нужно применять что-то более подходящее : Jenkins, Bamboo, TeamCity..
Upsource, Gitlab, Jira и Crucible - это то, на что мы будем ориентироваться, чтобы не рассматривать выгрузку на локальный диск как самоцель. Эти инструменты позволяют организовать командную работу, код-ревью, связь задач с коммитами. Подробно рассматривать их настройку не будем, но затронем с точки зрения результатов выгрузки.
Ограничение Gitsync на TCP, HTTP и что с этим делать
Gitsync до версии 2.4.3 (последней на данный момент) не позволяет подключаться к хранилищу по tcp и http. Если в качества пути к хранилищу ему указать что-то вроде tcp://host:port/storagename то он просто сообщит о некорректном пути. В качестве пути к хранилищу можно указывать только путь к локальному каталогу или общей папке. В версии 3.0 ожидается возможность подключения по TCP.
Сейчас же простейший путь - запускать Gitsync на той же машине, на которой расположено хранилище. Или расшарить папку в которой находится хранилище дав права только на чтение и указывать при выгрузке этот путь. Прав на запись при этом не требуется, поэтому не нужно бояться, что вместо подключения по tcp разработчики начнут использовать подключение через шару.
Также можно копировать/реплицировать хранилище с сетевого/исходного каталога в специально предназначенный для обработки гитсинком локальный каталог. В этом случае мы получим возможность более свободно работать с этим хранилищем в дальнейшем.
Структура каталогов и репозиториев
Наш скрипт выгрузки будет независим от структуры каталогов. Пути будут передаваться в него как параметры. Но структура каталогов определяет насколько комфортно и правильно будет происходить работа с репозиторием впоследствии.
Определимся с тем, что нам вообще нужно/можно хранить:
- Исходный код конфигурации
- Документацию, связанную с конфигурацией
- Внешние отчеты и обработки
- Исходный код внешних отчетов и обработок (их выгрузка на исходники).
- Файлы тестов, если используется тестирование.
- Сами скрипты запуска выгрузки и скрипты сборок для CI, если он есть.
Теперь подумаем как это удобно и/или правильно хранить
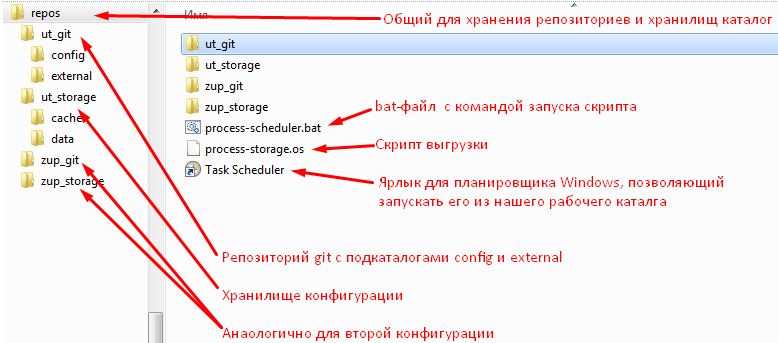
Где разместим репозитории и хранилища
Для удобства разместим все хранилища 1C, передаваемые на вход gitsync, и репозитории git в одном каталоге. Ведь фактически хранилища - это тоже репозитории кода 1С, просто по другому упакованные. Расположение же всех хранилищ 1С в одном каталоге удобно с точки зрения работы с хранилищем 1С через tcp или http. В этом случае их нахождение в одном каталоге - требование сервера хранилищ.
Где разместим скрипт выгрузки
Можно встретить рекомендацию хранить скрипты обслуживания репозитория непосредственно в самом репозитории.
Но наш скрипт для синхронизации будет универсальным и подходящим под любые репозитории. Фактически он является “библиотечной” сущностью для репозиториев конкретных конфигураций. Поэтому хранить его в репозитории конкретной конфигурации 1С было бы неправильно - пришлось бы копировать один и тот же файл в разные репозитории и менять его также. Представьте себе такую копипасту в репозиториях ERP, ЗУП, БП прочего зоопарка ))
Вообще при использовании git для таких ситуаций придуманы подмодули (submodules). Если кратко - создается отдельный репозиторий для “библиотеки”. Он подключается в другие репозитории как сабмодуль и его после этого можно автоматически обновлять во всех репозиториях, куда он подключен. Таким образом изменения скрипта можно выполнять в одном месте и перед действиями с другими репозиториями обновлять этот “общий код” специальной командой.
Сейчас же примем более простое решение - хранить скрипт выгрузки независимо от репозиториев. Меняется он редко и необходимость версионирования вообще под вопросом. Поместим его в тот же самый общий для хранилищ и репозиториев каталог.
Где разместим связанные с конфигурацией файлы
Этот вопрос уводит нас в сторону коллективной работы непосредственно с репозиторием и сложен для тех, кто еще плотно не работал с git. Поскольку внешние файлы не хранятся в хранилище 1С возможно только независимое от хранилище их помещение в репозиторий разными разработчиками. Для этого вопроса выделен подраздел Хранение внешних обработок, тестов, документации в репозитории этой публикации.
Сейчас же просто примем следующий факт: внутри каждого репозитория будет создан каталог config для исходников конфигурации и каталог external для внешних файлов.
Хранить ли внешние файлы в каталоге external каждый должен решить сам. Но иметь его нужно обязательно! Иначе решив в определенный момент все же работать с репозиторием git более плотно всей командой или просто автоматически складывать в репозиторий что-то кроме самой конфигурации, мы столкнемся с необходимостью перемещать исходники конфигурации из корня репозитория в подкаталог config. это будет очень некрасиво выглядеть с точки зрения истории файлов в git. И то в случае если git вообще определит факт перемещения, а не воспримет это как удаление и создание новых файлов, увеличив тем самым размер репозитория. Хранить же внешние файлы в корне репозитория вместе с исходниками конфигурации некрасиво и чревато их удалением при выгрузке конфигурации.
Таким образом, решение о хранении внешних файлов мы пока не принимаем, но заранее создаем для них отдельный каталог и отдельный каталог для конфигурации. Итого структура каталогов для написания этой публикации выглядит следующим образом:
Настройки хранилища
Работать далее будем только с одним хранилищем, со вторым работа будет идти аналогично (на скриншоте выше наше рабочее хранилище называется ut_storage)
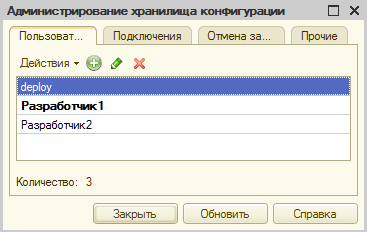
Создадим пользователей Разработчик1 и Разработчик2 , они будут выполнять роль реальных разработчиков.
Gitsync позволяет выгружать версию хранилища средствами платформы и средствами Tool1CD. Tool1CD позволяет очень быстро разбирать сами файлы хранилища без необходимости авторизации в нем.
Выбор между Tool1CD и платформенной выгрузкой следует делать исходя из следующей информации.
- Применение Tool1CD может создать дополнительные трудности при переходе например на Linux. Для OneScritp требуется только Mono, для Tool1CD потребуется еще и Wine.
- Для использования выгрузки средствами платформы потребуется создать в хранилище служебного пользователя. Через него Gitsync будет получать доступ к истории хранилища. Этому пользователю в настройках прав можно снять все галочки - он необходим только для чтения хранилища, никаких изменений ему разрешать не нужно:
На момент публикации выгрузка средствами платформы работает некорректно, но поведение скоро должно быть исправлено: https://github.com/oscript-library/gitsync/issues/153 . Я бы предпочел пользоваться именно платформенной выгрузкой. Для этого во всех командах gitsync export нужно добавлять следующие параметры : -useVendorUnload --storage-user Пользователь --storage-pwd Пароль
То есть вместо команды
gitsync export "C:\data\repos\ut_storage" "C:\data\repos\ut_git\config" -tempdir "C:\data\repos\temp"
использовать такую
gitsync export "C:\data\repos\ut_storage" "C:\data\repos\ut_git\config" -tempdir "C:\data\repos\temp" -useVendorUnload --storage-user deploy --storage-pwd deploy
Сейчас сделаем выбор в пользу выгрузки средствами Tool1CD. Пользователя deploy удалять не будем. Посмотрим на что повлияет наличие служебного пользователя в дальнейшем.
Установка Git
При установке git рекомендую устанавливать следующие опции:
Use git and optional unix tools from the Windows Command Prompt
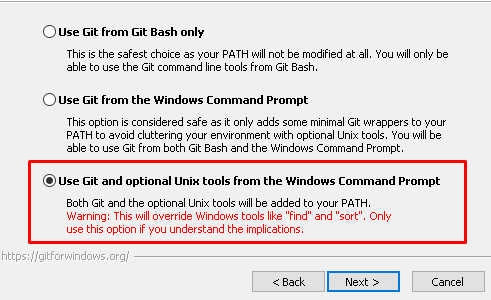
Это позволит удобно использовать не только сам git, но и инструменты вроде grep. Даже если сейчас они не нужны, то потом пригодятся. В частности именно grep из этой поставки предлагается использовать при анализе технологического журнала с помощью регулярных выражений на Windows: Подготовка к 1С:Эксперту: анализ технологического журнала 1С с помощью регулярных выражений
Checkout as-is, commit as-is
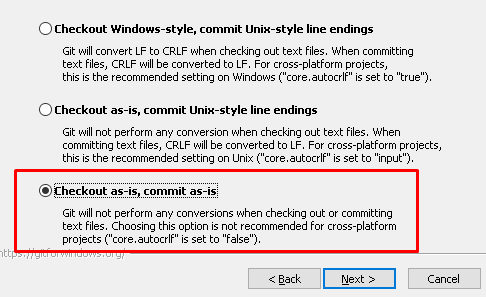
Для целей работы с типовыми конфигурациями 1С это лучший вариант. Нам не нужно преобразовывать концы строк. Хранить тексты модулей 1С можно так как их выгрузила платформа. Если не делать преобразований в текстах модулей при коммитах/чекаутах, то вероятность получить какие-либо ошибки при последующей загрузке будет ниже. Кроме того преобразования окончаний строк только замедляют работу системы.
Важно не снимать флаг Enable Git Credential Manager.
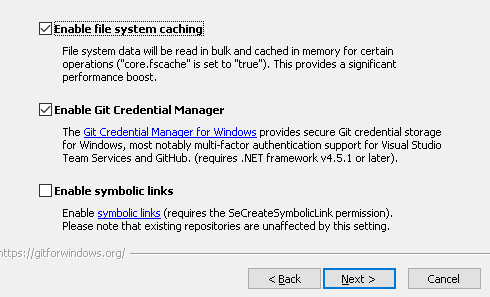
Это позволит один раз задать параметры авторизации на гит-сервере для пользователя Windows и затем использовать этого пользователя при автоматическом запуске процесса выгрузки хранилища для отправки изменений на гит-сервер. Ниже, в разделе про регулярный автоматический запуск выгрузки, будет приведен скриншот, как именно используется этот механизм.
Настройка репозитория
Инициализация репозитория
Инициализацию репозитория для целей выгрузки хранилища через gitsync можно выполнить через команду gitsync init <ПутьКХранилищу> <ПутьККаталогу выгрузки>
Однако у нас каталогом выгрузки является подкаталог ut_git\config и если выполнить команду для этого подкаталога, то gitsync сообщит что репозиторий еще не создан и инициализирует репозиторий прямо в каталоге config.
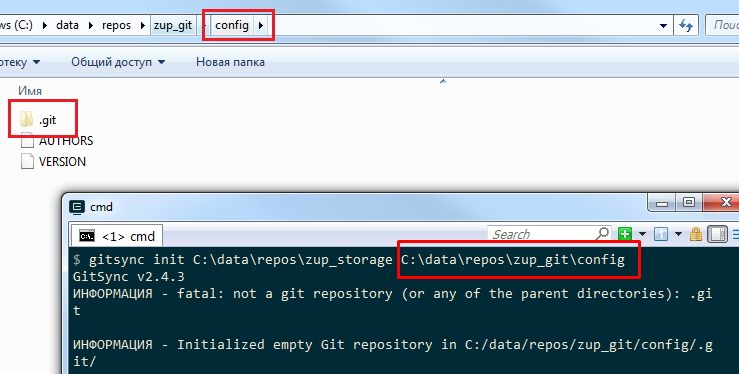

Можно конечно после этого перенести каталог .git на уровень выше - в корневой каталог репозитория.
Но можно поступить и иначе. Сначала выполнить инициализацию репозитория просто средствами git выполнив команду git init находясь в корне каталога , который мы хотим сделать репозиторием:
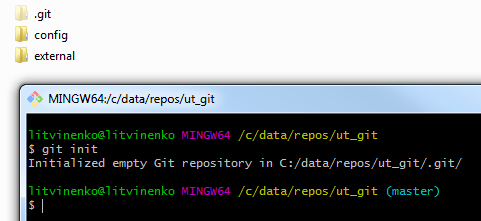
Затем выполнить команду gitsync init <ПутьКХранилищу> <ПутьККаталогу выгрузки>
В этом случае репозиторий повторно инициализирован не будет, а будут созданы только нужные нам файлы
AUTHORS и VERSION :
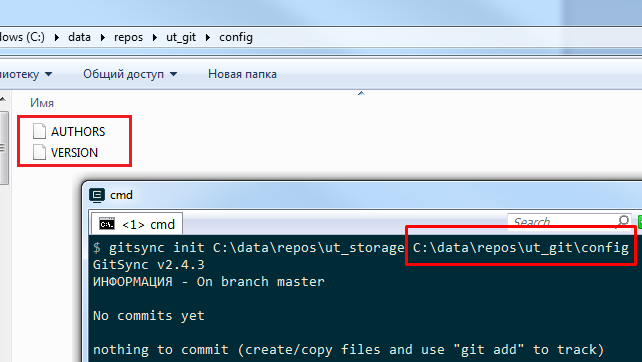
Назначение этих файлов описано в документации к gitsync. VERSION хранит последнюю успешно выгруженную версию. Если между тегами <VERSION> и </VERSION> ничего нет, то при попытке выгрузки хранилища gitsync будет выдавать ошибку.
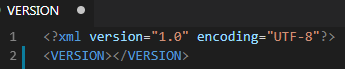
Сюда мы будем вставлять версию, после которой хотим начать выгрузку хранилища в git. Это та версия, которая отображается при просмотре истории хранилища

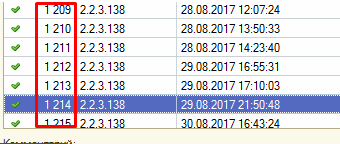
Если конфигурация крупная, проект уже имеет большую историю, то имеет смысл не выгружать в git отдельно каждую закладку “с начала времен”. Можно или даже нужно начать с одной из последних версий, например указав в файле VERSION версию 1213
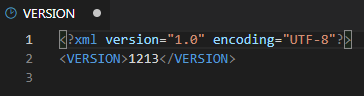
в репозиторий при запуске gitsync уйдет версия 1214 и коммит в git будет будет содержать все изменения до нее включительно. Это аналогично операции сокращения хранилища до этой версии, только результат этого “сокращения” хранилища будет выгружен в виде одного коммита в репозиторий git. Дальше пойдет выгрузка версии 1215. И это уже будет полноценный процесс фиксации изменений. Изменения будут зафиксированы относительно версии 1214. Далее будут фиксироваться изменения версии хранилища 1216 относительно 1215.
Сейчас же я будут делать выгрузку с первого коммита, поэтому в файле указываю значение 0.
Если будет происходить выгрузка в Gitlab , Github, Bitbucket или Fisheye то файл AUTHORS очень важно заполнить правильными e-mail-ами,. По этим адресам будет производиться сопоставление авторов коммитов и пользователей этих сервисов. В дальнейшем будет продемоснтрировано, что именно e-mail важен для установки этой связи.
Созданный автоматически файл надо подправить:
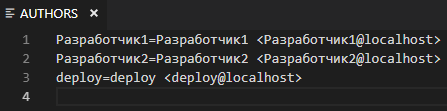

Во первых, мы не удаляли пользователя deploy из хранилища. Сейчас нам не нужна строка с пользователем deploy - он служебный, и коммитов из под него не будет. Если есть другие служебные пользователи, то их также следует исключить из файла. Затем, используя флаг -check-authors при выгрузке через gitsync мы сможем убедиться, что не обрабатываем коммиты от служебных пользователей.
Во вторых стоит прописать правильные имена и адреса пользователям:

Создание ветки develop
На случай последующего выделения ветки master для хранения только тех слепков конфигурации, которые уходят в продуктовую базу или на случай выделения отдельного хранилища для продуктовой базы рекомендую создавать как минимум две ветки: master и develop (или dev). Конечно можно обойтись веткой master и переехать на develop потом, или наоборот создать только develop. Но мне нравится идея сразу создать задел на будущее развитие системы.
Про то, что такое ветки, для чего нужны и как с ними работать можно прочитать здесь: https://git-scm.com/book/ru/v1/Ветвление-в-Git-Основы-ветвления-и-слияния. Ближайшим аналогом работы с ветками в классическом процессе разработки на 1С является технология разветвленной разработки конфигураций.
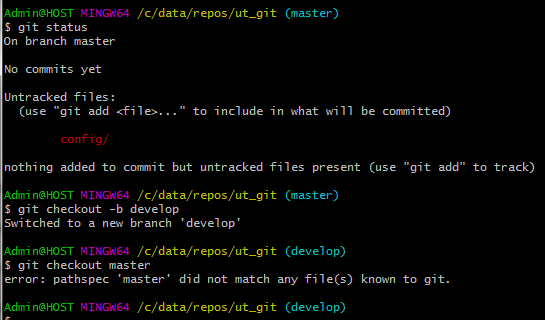
После инициализации репозитория у нас якобы уже появилась ветка master. Но это не так. Ветка появляется в репозитории git только после первого коммита в нее. Сейчас у git есть только намерение поместить в ветку под именем master какие-то изменения. Если мы переключимся на другую ветку с инструкцией по ее созданию (git checkout -b имя_ветки) то попытка переключиться обратно на master приведет к ошибке - этой ветки нет :
Так как мы упрямо хотели создать ветку master, то выполним теперь команду создания этой ветки (checkout -b). Выполним команду коммита наших первых изменений в ветку master , тем самым создав ее в репозитории и только затем создадим ветку develop :
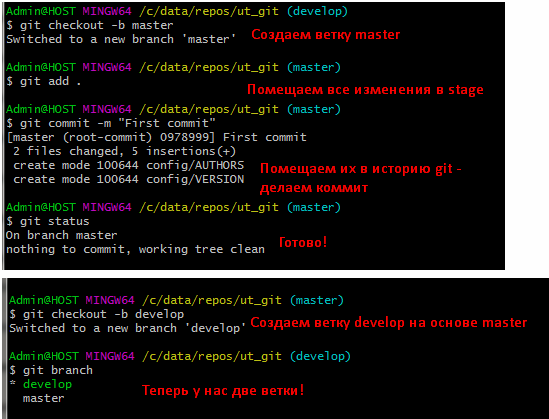
Дальше всю работу будем вести с веткой develolp. Если остались вопросы о целесообразности создания “метрвой” ветки master, то считайте, что мы ее создали для тренировки ))
Настройка .gitignore
Файл .gitignore определяет какие файлы не будут отслеживаться гитом, о каких изменениях он не будет сообщать и какие файлы не будут попадать в его историю. Настройку этого файла желательно делать до первой выгрузки конфигурации из хранилища. Потому что если будет произведен хотя бы один коммит с этими файлами, то всё….. они навсегда в истории гита. Они влияют на размер репозитория и есть в его логах. Их всегда можно восстановить из истории.
Все, чего мы добьемся указав их в gitignore впоследствии - это избежим помещения их последующих изменений в репозиторий. Для огромный файлов конфигураций поставщика это целесообразно, потому что git хранит упакованные слепки файлов. Новая версия бинарного файла cf добавляет много к размеру репозитория.
Но лучше сразу не допускать их хранения. Если репозиторий будет использоваться только для быстрого доступа к истории исходного кода и файлов проекта, для достижения публичности кода и/или проведения код-ревью, то рекомендую поместить в файл .gitignore как минимум следующие строки:
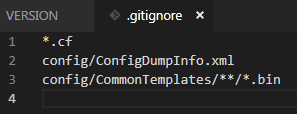
*.cf - для того, чтобы не хранить в истории конфигурацию поставщика
config/ConfigDumpInfo.xml - для таких конфигураций как ERP файл огромен и нам не нужно каждый раз любоваться на его изменения
config/CommonTemplates/**/*.bin - для того, чтобы не хранить в истории драйверы оборудования.
Остановимся на последней строке подробнее.
Почему нельзя написать просто *.bin ? Потому что XDTO пакеты также выгружаются платформой в файлы с расширением bin. Сюрприз от разработчиков платформы.
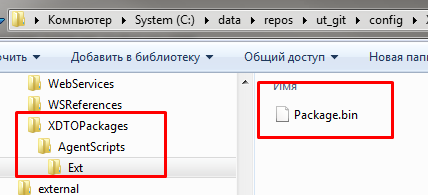
В данном же случае исключаются только бинарные файлы из общих макетов, которые в основном являются драйверами оборудования. Выражение **/* в gitignore означает “в указанном каталоге и всех его подкаталогах”.
config/CommonTemplates/*.bin - проигнорирует бин файлы только непосредственно в директории шаблонов,
config/CommonTemplates/**/*.bin - как в самой директории шаблонов, так и во всех ее подкаталогах.
Можно настроить более гибкие фильтры на файлы bin если воспользоваться документацией по формату файла .gitignore
Если выгрузка используется для последующей загрузки , то config/CommonTemplates/**/*.bin следует убрать. Возможно что и конфигурацию поставщика стоит оставить.
После создания и заполнения .gitignore необходимо применить изменения. Их нужно сделать как в ветке master, так и в ветке develop.

Первая выгрузка
Сделаем ее из консоли. Все по документации по gitsync (https://github.com/oscript-library/gitsync). Но сразу создадим временный каталог C:\data\repos\temp для выгрузки , чтобы увидеть одну важную особенность gitsync - он не удаляет временные файлы после выгрузки:
gitsync export "C:\data\repos\ut_storage" "C:\data\repos\ut_git\config" -tempdir "C:\data\repos\temp"
gitsync export - команда выгрузки
"C:\data\repos\ut_storage" - выгружаемое хранилище
"C:\data\repos\ut_git\config" - куда выгружаем
-tempdir "C:\data\repos\temp" - указываем временный катало для выгрузки
Начинает работать выгрузка, которая использует временный каталог :

Еще до завершения работы gitsync можно увидеть в мониторе производительности как после выгрузки git, получив от gitsync команду commit, помещает файлы в свою историю:
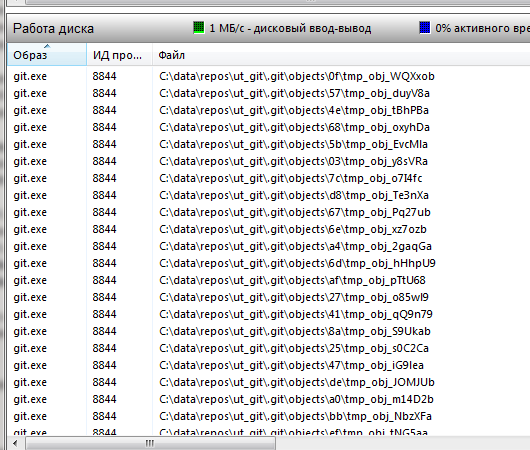
Первый коммит выполняется очень долго. Десятки тысяч файлов для УТ и сотни тысяч для ERP каждый по отдельности помещается в историю git. Последующие выгрузки будут происходить много быстрее.
В итоге получаем нашу “закомитченную” выгрузку:
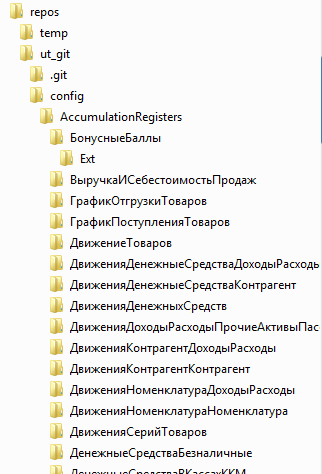
Временные файлы gitsync
После того как выгрузка завершилась можно увидеть что временный каталог с выгрузкой сохранился:
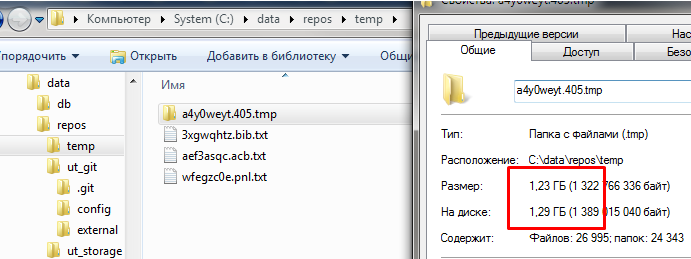
На ERP он будет занимать около 5 ГБ. По умолчанию gitsync создает временные каталоги с разными именами в каталоге временных файлов операционной системы. И в случае с Windows они остаются там надолго. Если систему не перезагружать (а ведь сервера редко перезагружаются) этими временными файлами можно забить весь диск. Что собственно и происходит на практике, если не позаботиться об этих файлах самостоятельно. Поэтому мы всегда будем указывать отдельный каталог временных файлов для выгрузки и затем самостоятельно чистить его.
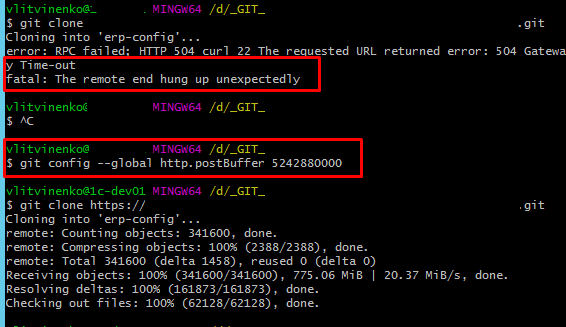
Настройки git на загрузку больших объемов данных
Еще один пример из практики. В git выгружалась конфигурация ERP, затем отправлялась в удаленный репозиторий. Однажды из-за сбоя виртуального сервера, репозиторий, в который производилась выгрузка, был потерян. В этом случае его можно восстановить командой git clone, вытянув с удаленного. Но команда не сработала. Произошел таймаут при загрузке. Причина в том, что гит вытягивает конфигурацию кусочками , не превышающими заданный буфер. По умолчанию этот буфер мал и накладные расходы на повторные обращения к гит-серверу слишком велики, они приводят к таймауту.
Поэтому целесообразно увеличить буфер для этой цели командой приведенной на скриншоте ниже. Сделать это стоит либо сразу, либо потом, когда возникнет такая необходимость. Наверняка это стоит сделать в случае, если вы используете сервер сборок, который регулярно вытягивает конфигурацию с удаленного репозитория. Главное про эту настройку знать ))
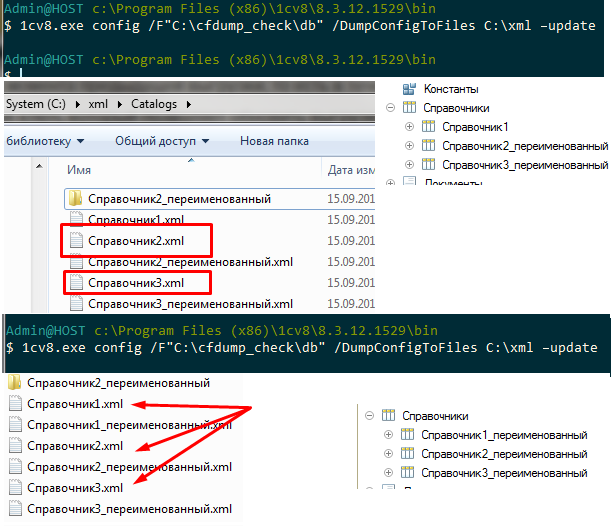
Кириллические названия файлов
По умолчанию git преобразует и экранирует кириллические буквы в именах файлов :
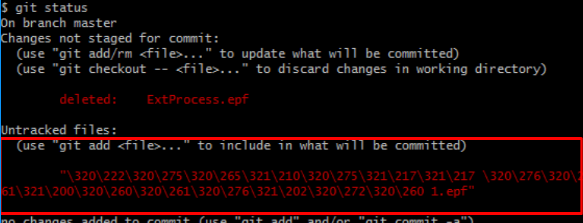
Чтобы такого не происходило, следует для репозитория выполнить команду
git config --local core.quotepath false
или в целом для всей системы
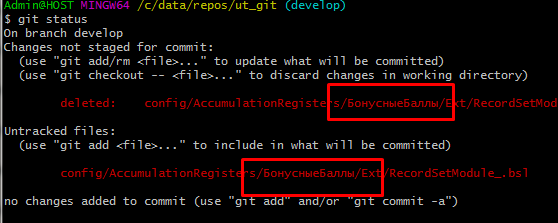
git config --global core.quotepath false
Последняя команда будет распространяться на все репозитории, для которых явно не задана настройка core.quotepath ture.
Теперь кириллические символы отображаются правильно:
Создание или эмуляция удаленного репозитория
Создаем “эмуляцию”
Удаленный репозиторий не обязательно поднимать на серверах компании, взрывать мозг докер-контейнерами и даже не обязательно регистрироваться на Gitlab.com/Github.com. Git-позволяет использовать другой локальный репозиторий как удаленный. Для нас это будет выглядеть как эмуляция удаленного репозитория. Хотя для Git это вовсе не так и заложено в самой его сути - любой репозиторий, удаленный или находящийся рядом с вашим на том же жестком диске, абсолютно равноправный и каждый из них может быть удаленным (remote) для другого.
Для создания “эмулирующего” удаленного репозитория выполним в каком либо пустом каталоге команду git init --bare
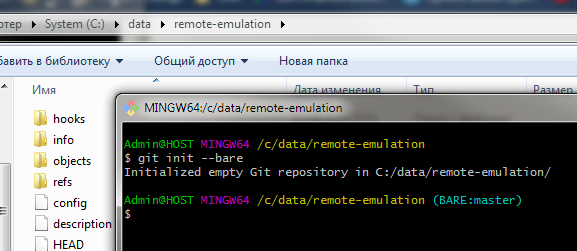
Ключ --bare необходим вот для чего. Если создать репозиторий без этого ключа , то он будет обладать рабочей директорией. Рабочая директория - это одно из тех пространств с которым работает git. Файлы из нее перемещаются сначала в область stage а затем коммитятся в историю git. (если еще нет полного понимания понятий working directory , staging area / index , то рекомендую прочитать про это в замечательной книге про git : https://git-scm.com/book/ru/v1/Введение-Основы-Git )
Так вот, если в нашем “удаленном” репозитории есть рабочий каталог и выполнено переключение на ветку develop, то отправка в эту ветку из ветки develop другого репозитория через git push работать не будет. Git разумно считает что если выполнен чекаут на эту ветку значит с файлами этой ветки сейчас ведется работа и отказывается их перезатереть. Команда push отработает либо если в удаленном репозитории текущей веткой является отличная от develop, либо если репозиторий создан с ключем --bare. При создании репозитория этот ключ говорит гиту, что этот репозиторий специальный - без рабочей директории. Именно так создаются репозитории на githab и gitlab. После создания репозитория прямо в его корне можно увидеть то, что в других репозиториях находится в скрытом каталоге .git :
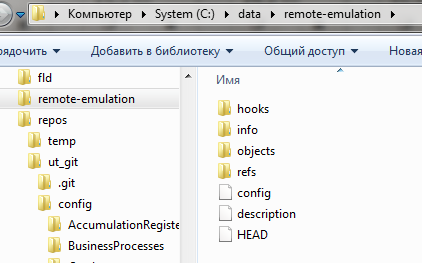
Теперь у нас есть такой каталог, который мы будем указывать как один из удаленных (remote) для нашего репозитория
Создаем облачный репозиторий
Для создания облачного удаленного репозитория зарегистрируемся gitlab. Он предоставляет возможность хранить анонимные репозитории объемом до 10 Гб, что подойдет даже для ERP. Создавать публичный репозиторий для типовых конфигураций 1С разумеется нельзя.
Зарегистрируемся под двумя адресами, ранее использованными в файле AUTHORS :
vladimirov_super_puper_dev@mail.ru
aleksandrov_super_puper_dev@mail.ru
В GitLab специально дадим пользователям другие имена, чтобы показать связь только через e-mail.
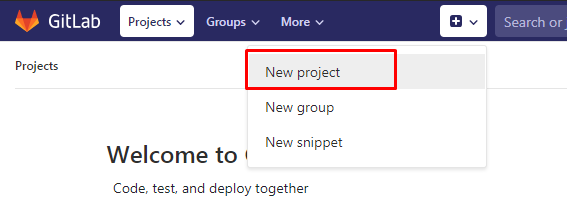
Сначала создаем пользователя vladimirov_super_puper_dev@mail.ru и создаем новый проект-репозиторий:

Укажем ему удобное для нас имя, которое будет определять какой полный путь к репозиторию мы будем указывать при назначении его удаленным для нашего репозитория:
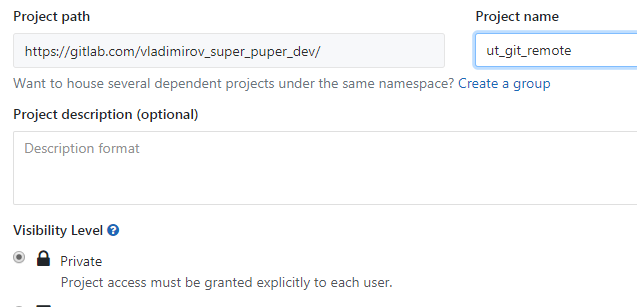
ГитЛаб подсказывает нам как теперь отправить изменения из имеющегося репозитория в этот удаленный репозиторий. Но здесь ошибка, для приватных репозиториев нужно обязательно добавлять пользователя и собачку перед gitlab.com. Правильная команда будет приведена далее:
Зарегистрируем теперь второго пользователя с почтой aleksandrov_super_puper_dev@mail.ru, дадим ему безумное имя, чтобы впоследствии показать, что связь устанавливается по почтовым адресам, а не именам :

Теперь от имени пользователя-владельца репозитория подключим членов команды к этому репозиторию, поиск пользователя GitLab можно выполнить по его имени :
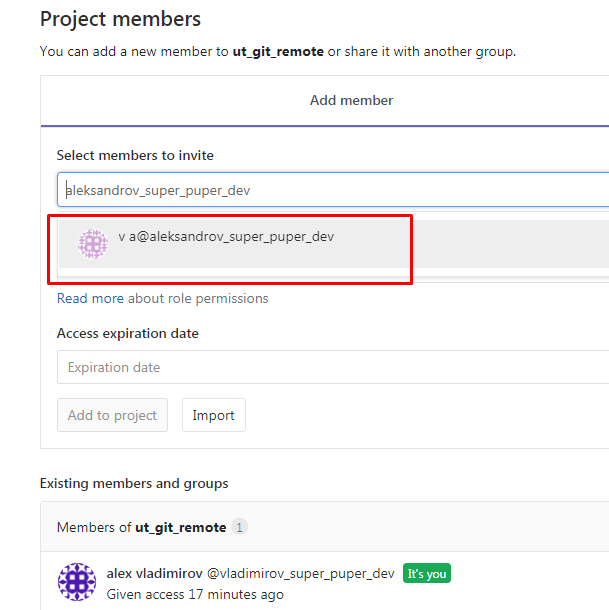
Дадим добавленному в члены команды пользователю роль Developer :
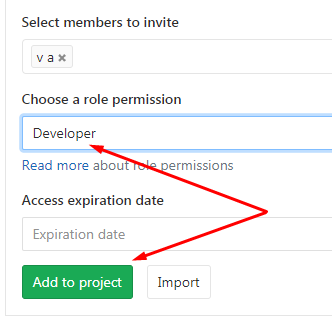
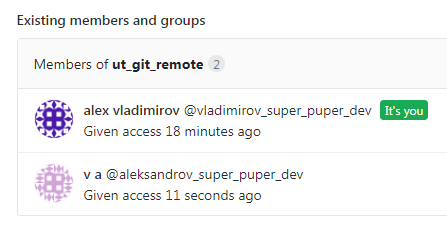
Так выглядит один из способов организации совместной работы в GitLab. Подробно про права и правила GitLab сейчас не будем. Цель у нас проста - просто выполнить git push в этот удаленный репозиторий и связать коммиты с авторами и задачей на разработку.
Создадим и задачу, с которой будем осуществлять и проверять связь изменений в нашей системе 1С в дальнейшем:
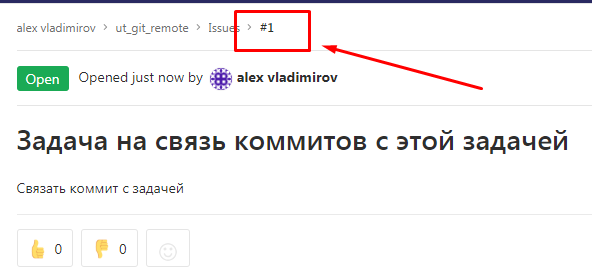
Задаче присвоен номер #1:
Связываем наш репозиторий с “удаленными” и отправляем изменения в них
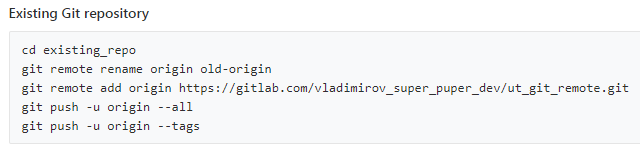
Связать наш репозиторий с удаленным можно командой
git remote add origin https://vladimirov_super_puper_dev@gitlab.com/vladimirov_super_puper_dev/ut_git_remote.git
На практике именно такую команду и следует выполнять и позже мы откорректируем настройки нашего репозитория для работы только с одним удаленным репозиторием. Но у нас теперь два “удаленных” репозитория один из которых мы создали на своем же жестком диске. Воспользуемся этим, чтобы показать интересную особенность git.
В команде связи с удаленным репозиторием origin - это просто имя-синоним по которому мы будем обращаться к адресу https:///vladimirov_super_puper_dev@gitlab.com/vladimirov_super_puper_dev/ut_git_remote.git. Можно вообще обходиться без этой команды связи и использовать всегда адрес https:///vladimirov_super_puper_dev@gitlab.com/vladimirov_super_puper_dev/ut_git_remote.git .
Мы же добавим два удаленных репозитория с разными синонимами:

Обратите внимание на запись во втором варианте. Git - из мира Linux и ему часто нужны прямые слэши.
В файле настроек репозитория ut_git\.git\config при этом появляются такие строки :

При необходимости сменить синонимы удаленных репозиториев, их пути или другие настройки нашего репозитория можно править напрямую этот файл.
При первой отправке ветки в удаленный репозиторий ее обязательно нужно связать с ее “удаленным” аналогом. Делается это с помощью ключа -u или его более расширенного варианта --set-upstream c указанием удаленного репозитория (его синонима или полного пути) и имени удаленной ветки:
При отправке изменений в gitlab система запросит пароль и сохранит его в своем хранилище паролей. Нужно сразу сказать что этот пароль может “слетать” с разной периодичностью. Поэтому при настройке выгрузки через планировщик Windows под своим аккаунтом иногда можно обнаружить, что выгрузка перестала работать.
Альтернативой является использование SSH ключа (я еще этим не пользовался). Или выгрузка с применением Jenkins в котором можно сохранять пароль.
После ввода паролей в случае с большими конфигурациям 1С начнется длительный процесс отправки:
Для определенности далее будем использовать только удаленный репозиторий на Гитлаб назвав его просто origin. Откроем файл .git/config, установим синоним origin для репозитория gitlab и для ветки develop укажем имя репозитория origin. Конечно, как и для всего в git, для этой операции существует соответствующая команда. Но сейчас мы просто изменим конфигурационный файл:

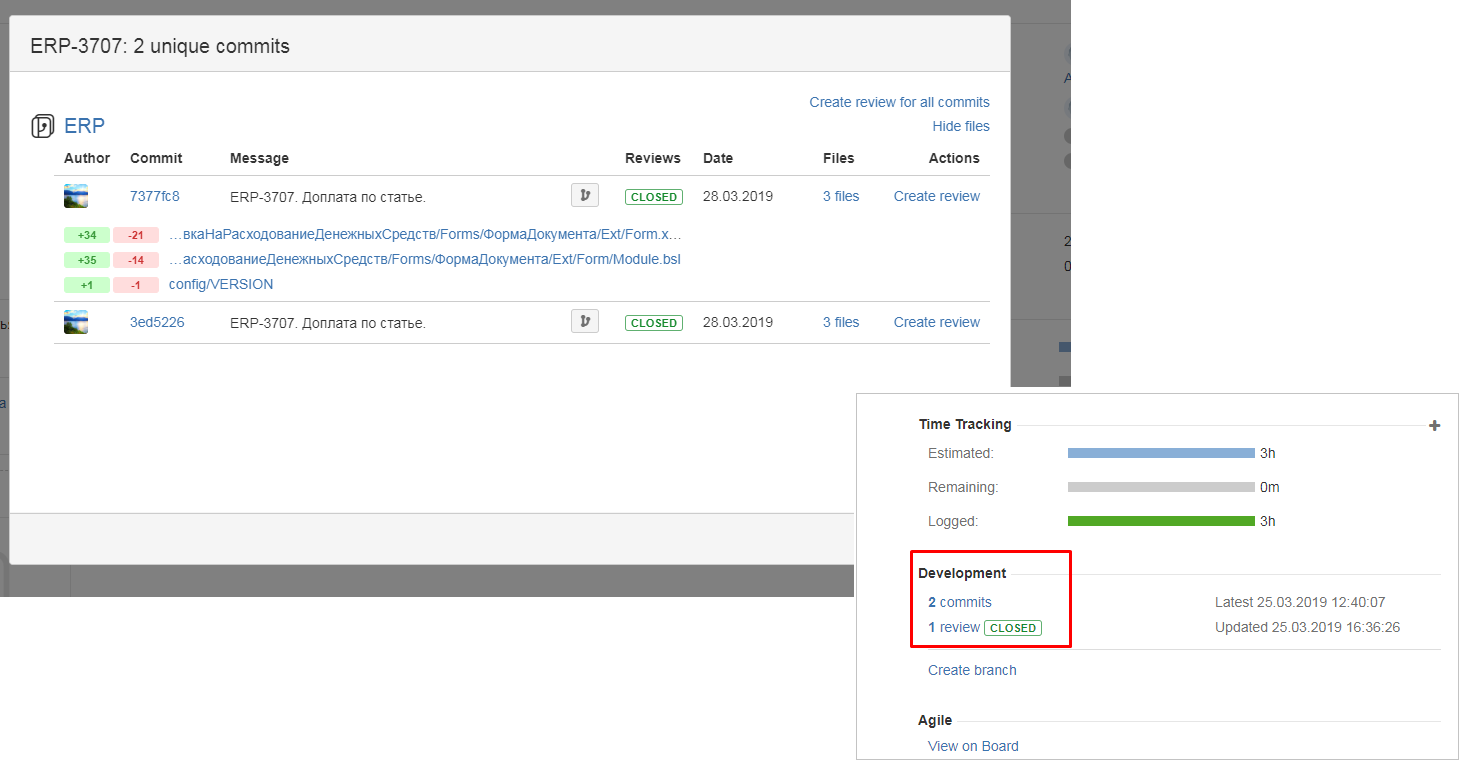
Пример связи коммитов с задачами и пользователями гит-сервера
Сделаем от каждого из наших двух разработчиков помещение изменений в хранилище. Для связи с задачей в GitLab в начале комментария нужно написать #НомерЗадачи. В конце публикации будет приведен пример работы через Fisheye или Bitbucket , когда решетку ставить не нужно.
Для закладки важно правильно указывать именно комментарий. Его gitsync передает в качестве комментария к коммиту. Метки закладок в хранилище 1С роли не играют.

Выполним уже известную нам команду :
gitsync export "C:\data\repos\ut_storage" "C:\data\repos\ut_git\config" -tempdir "C:\data\repos\temp"
или, если используется выгрузка средствами платформы, то команду
gitsync export "C:\data\repos\ut_storage" "C:\data\repos\ut_git\config" -tempdir "C:\data\repos\temp" -useVendorUnload --storage-user deploy --storage-pwd deploy
а после нее отправим изменения на Гитлаб , теперь уже достаточно будет одной простой команды
git push
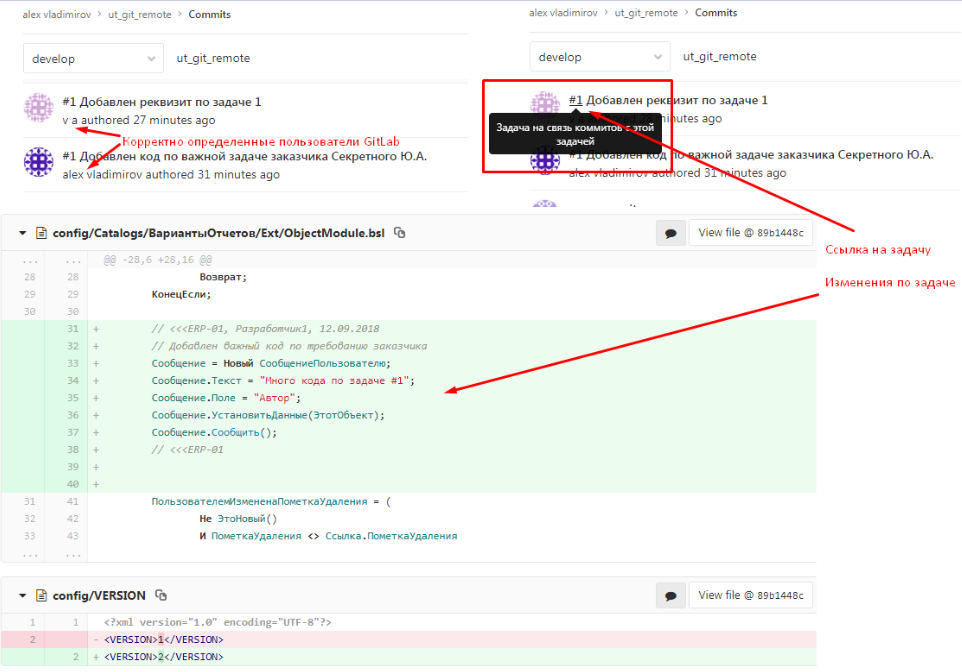
В GitLab появится два коммита имеющих автоматически созданную ссылку на ранее созданную задачу.
Несмотря на различные имена в файле AUTHORS и имена пользователей Гитлаба установлена корректная связь с пользователями Гитлаба через e-mail :
Атрибуты коммитов, устанавливаемые gitsync
Важной деталью является то, что gitsync устанавливает время коммитов в git в соответсвии со временем закладок в хранилище.
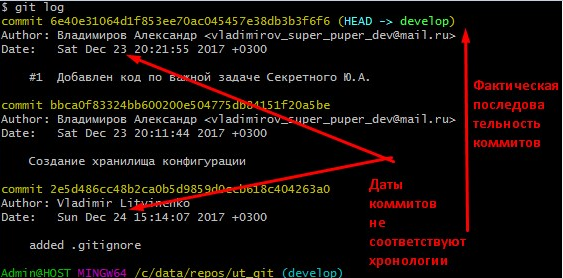
Поэтому, если мы работаем со старым хранилищем и сначала поместили в git файл .gitignore и структуру каталогов, а затем начали выполнять коммиты из старого хранилища, то может так оказаться так, что операции, фактически выполненные позже (выгрузка из хранилища) в логах гита, числятся как операции выполеннные раньше, чем фактически совершенный первый коммит. На скриншоте .gitignore помещен 24 числа, а коммит фактически выполненный после него числится 23-им числом. При этом данные даты являются просто атрибутами коммитов , как и почтовые ящики авторов. При этом git log показывает фактическую хронологию снизу в верх :
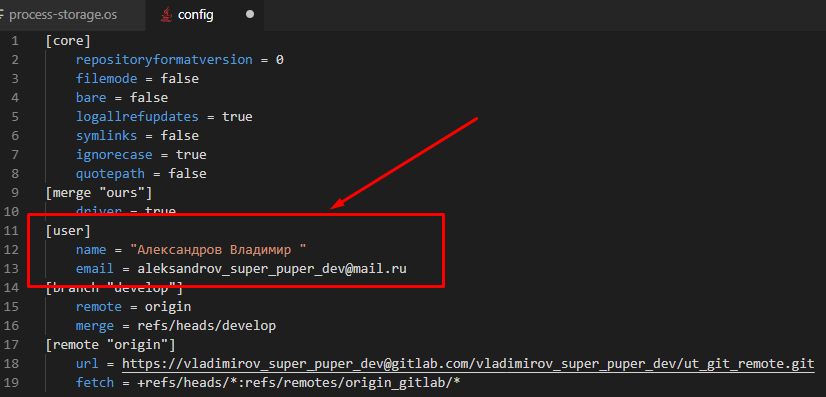
Также в файле config перед коммитом gitsync подменяет автора , на определенного через файл AUTHORS. Это то, благодаря чему устанавливается корректная связь авторов коммитов пользователями в Fisheye, Gitlab и так далее. Поэтому зайдя в этот файл настрек репозитория можно увидеть такую ситуацию:
Скрипт выгрузки
Переходим к написанию скрипта выгрузки.
В него в качестве параметров нам нужно передавать
- путь к хранилищу конфигурации (--storage-path)
- путь к репозиторию (--repository-dir). Но помня, что внутри репозитория есть отдельный каталог для выгрузки будем также передавать...
- подкаталог для выгрузки (--configuration-subdir)
- путь к каталогу временных файлов, для самостоятельной очистки этого каталога по окончанию выгрузки (--temp-dir)
- флаг необходимости отправки в удаленный репозиторий в случае успешного завершения прочих шагов (--push-to-remote)
Также, если будет использоваться выгрузка средствами платформы, входными параметрами можно сделать имя служебного пользователя хранилища и его пароль.
Скрип писался для того, чтобы он мог запускаться в том числе из Jenkins. Если ограничиться планировщиком Windows, как мы сделаем в этой публикации, то параметр управляющий отправкой в удаленный репозиторий будет не нужен. Можно было бы всегда вызывать команду git push , которая ничего бы не сделала, если выгрузка не привела к изменениям и отправлять было бы нечего. Но у Jenkins есть свой шаг - отправка в remote в случае успеха шагов сценария. Поэтому задействуем параметр --push-to-remote. Вызывая скрипт из bat-файла планировщиком Windows будем устанавливать его в ON. Если же вы встроите скрипт в Jenkins в сценарий с последующей отправкой при успехе выгрузки, то параметр надо установить в OFF.
Для разбора переданных в скрип параметров удобно применять библиотеку cmdline http://oscript.io/library/package/cmdline
В ходе выполнения скрипта нам потребуется часто выполнять запуск команд операционной системы. OneScript поддерживает метод ЗапуститьПриложение. Этот метод позволяет получить код возврата. Но нам будет удобно использовать библиотеку 1commands https://github.com/oscript-library/1commands , которая позволяет создавать объект Команда и получать консольный вывод выполняемых команд.
Итого в нашем скрипте появляются строки импортирующие библиотеки :
#Использовать cmdline
#Использовать 1commands
Чтобы не дублировать код, создавая объект “Команда” каждый раз при запуске команд системы создадим метод, позволяющий не только запускать команды, но и логировать их выполнение выводя сообщения в консоль. Сообщения эти потребуются во время отладки скрипта и при просмотре логов работы скрипта, при его запуске например из Jenkins. Для запуска через планировщик Windows они будут бесполезны.
Также будем передавать в метод ожидаемый код возврата наших команд, и если ожидаемый код возврата не совпадает с фактическим - будем прерывать выполнение.
Функция ВыполнитьКоманду(СтрокаКоманды,
РабочийКталог,
ОжидаемыйКодВозврата = 0,
СообщениеДоВыполнения = "",
ОсновноеСообщениеОбУспехе = "",
ОсновноеСообщениеОбОшибке = "",
СообщатьВыводКоманды = Ложь)
ВыводКоманды = "";
Команда = Новый Команда;
Команда.УстановитьРабочийКаталог(РабочийКталог);
Команда.УстановитьСтрокуЗапуска(СтрокаКоманды);
Команда.УстановитьПравильныйКодВозврата(ОжидаемыйКодВозврата);
Команда.ПоказыватьВыводНемедленно(Ложь);
Если ЗначениеЗаполнено(СообщениеДоВыполнения) Тогда
Сообщить(СообщениеДоВыполнения);
КонецЕсли;
Попытка
Команда.Исполнить();
ВыводКоманды = Команда.ПолучитьВывод();
Если СообщатьВыводКоманды Тогда
Сообщить("Выполнена команда: " + СтрокаКоманды);
Если ЗначениеЗаполнено(ВыводКоманды) Тогда
Сообщить("Вывод команды: " + ВыводКоманды);
КонецЕсли;
КонецЕсли;
Если ЗначениеЗаполнено(ОсновноеСообщениеОбУспехе) Тогда
Сообщить(ОсновноеСообщениеОбУспехе);
КонецЕсли;
Исключение
ВызватьИсключение ОсновноеСообщениеОбОшибке + Символы.ПС
+ "Выполнена команда: " + СтрокаКоманды + Символы.ПС
+ "Код возврата " + Команда.ПолучитьКодВозврата() + Символы.ПС
+ "Вывод команды: " + Команда.ПолучитьВывод();
КонецПопытки;
Возврат ВыводКоманды;
КонецФункции
Как мы уже видели выше, при отправке изменений на GitLab и, как увидим ниже, при использовании продуктов Atlassian, крайне важно в комментарии корректно указывать номер задачи. Иначе не произойдет связи коммитов с задачами в соответствующих системах учета задач на разработку. Создадим метод - шаблон для проверки комментария. Пока наполним его простейшей проверкой на длину строки. На практике же нужно делать более сложные проверки. Вплоть до обращения через API к Jira/GitLab для проверки наличия задачи по номеру :
// Реализацию необходимо заменить на свою, например проверять наличие # и номера
// задачи в начале комментария для связи коммитов с задачами в таск-трекере
Функция КомментарийКоммитаНекорректен(Комментарий)
КомментарийНекорректен = СтрДлина(Комментарий) < 5;
Возврат КомментарийНекорректен;
КонецФункции
Теперь переходим к основному коду скрипта. Вначале распарсим переданные параметры испольуя объекты библиотеки cmdline и сделаем отладочный вывод значений параметров в консоль. Формируя команду запуска gitsync дополнительно зададим параметры -verbose для более подробного вывода и -check-authors , чтобы он проверял наличие автора закладки в файле AUTHORS:
КодВозврата = -1;
ЭтотСценарий = ТекущийСценарий();
ТекущийКаталог = ЭтотСценарий.Каталог;
РазделительПути = ПолучитьРазделительПути();
Парсер = Новый ПарсерАргументовКоманднойСтроки();
Парсер.ДобавитьИменованныйПараметр("--storage-path");
Парсер.ДобавитьИменованныйПараметр("--temp-dir");
Парсер.ДобавитьИменованныйПараметр("--repository-dir");
Парсер.ДобавитьИменованныйПараметр("--configuration-subdir");
Парсер.ДобавитьИменованныйПараметр("--push-to-remote");
Параметры = Парсер.Разобрать(АргументыКоманднойСтроки);
ПутьКХранилищу = Параметры["--storage-path"];
КаталогРепозитория = Параметры["--repository-dir"];
КаталогФайловКонфигурацииВнутриРепозитория = КаталогРепозитория + РазделительПути + Параметры["--configuration-subdir"];
ПутьКоВременнымФайлам = Параметры["--temp-dir"];
ОтправлятьВУдаленныйРепозиторий = ВРег(Строка(Параметры["--push-to-remote"]));
КомандаЗапускаGitsyncШаблон = "gitsync export ""%1"" ""%2"" -limit 1 -tempdir ""%3"" -verbose on -check-authors";
КомандаЗапускаGitsync = СтрШаблон(КомандаЗапускаGitsyncШаблон,
ПутьКХранилищу,
КаталогФайловКонфигурацииВнутриРепозитория,
ПутьКоВременнымФайлам);
// Для сценариев Jenkins самостоятельно выполняюдих отправку изменений параметр нужно задавать как OFF
Если ОтправлятьВУдаленныйРепозиторий = "ON" Тогда
ОтправлятьВУдаленныйРепозиторий = Истина;
ИначеЕсли ОтправлятьВУдаленныйРепозиторий = "OFF" Тогда
ОтправлятьВУдаленныйРепозиторий = Ложь;
Иначе
ВызватьИсключение "Должен быть задан параметр --push-to-remote ON или --push-to-remote OFF";
КонецЕсли;
// Вывод переменных
Сообщить("--------------------------------------------------------");
Сообщить("ПАРАМЕТРЫ ИСПОЛНЕНИЯ ПОЛУЧЕННЫЕ ПО ПАРАМЕТРАМ КОМАНДНОЙ СТРОКИ:");
Сообщить("ПутьКХранилищу = " +ПутьКХранилищу);
Сообщить("КаталогРепозитория = " + КаталогРепозитория);
Сообщить("КаталогФайловКонфигурацииВнутриРепозитория = " + КаталогФайловКонфигурацииВнутриРепозитория);
Сообщить("ПутьКоВременнымФайлам = " + ПутьКоВременнымФайлам);
Сообщить("КомандаЗапускаGitsync = " + КомандаЗапускаGitsync);
Сообщить("ОтправлятьВУдаленныйРепозиторий = " + Строка(ОтправлятьВУдаленныйРепозиторий));
Сообщить("--------------------------------------------------------");
Параметр -limit 1 в команде запуска gitsync заставляет его обработать только одну следующую закладку в хранилище. Он играет важную роль - позволит нам проверять комментарий каждой закладки в отдельности и останавливаться, если комментарий к ней неверен. Также он позволит добиться отправки коммита в удаленный репозиторий и только потом, при следующем запуске скрипта, перейти к следующей закладке в хранилище. Это особенно важно, если код-ревью или тестирование является частью процесса разработки и проводится до подготовки кода к релизу. Если параметр не передать, то gitsync будет выгружать все закладки, накопившиеся с прошлого запуска. На ERP выгрузка может занимать от 15 минут до 1 часа. Если за час несколько разработчиков сделало несколько коммитов, то ждать несколько часов, прежде чем изменения пойдут на ревью или тестирование не эффективно. Отправка коммитов по очереди позволяет распараллелить процесс выгрузки, ревью и тестирования.
Временный каталог будем самостоятельно удалять в конце скрипта. Поэтому в начале скрипта проверим его наличие и если его нет - создадим. Может оказаться так, что скрипт запущен под пользователем с недостаточными правами или путь к нему передан некорретный. Поэтмоу подстрахуемся и если каталог создать не удалось - прервем выполнение :
// Создаем каталог временных файлов, если он не существует
ОбъектПроверкиСуществованияКаталога = Новый Файл(ПутьКоВременнымФайлам);
Если НЕ ОбъектПроверкиСуществованияКаталога.Существует() Тогда
СоздатьКаталог(ПутьКоВременнымФайлам);
КонецЕсли;
Если НЕ ОбъектПроверкиСуществованияКаталога.Существует() Тогда
ВызватьИсключение "Не удалось создать каталог временных файлов "+ПутьКоВременнымФайлам;
КонецЕсли;
Переключимся на ранее созданную ветку develop на случай если в репозитории по какой-то причине велась работа с другой веткой. Например мы смотрели изменения в ней. Если переключение не удалось, то код возврата будет не равен 0 и мы прервем выполнение.
// Переключаемся на ветку разработки
ВыполнитьКоманду("git checkout develop",
КаталогРепозитория,
0,
"",
"Переключились на ветку develop",
"Не удалось переключиться на ветку develop",
Истина);
Перейдем к вопросу проверки корректности комментария в процессе выполнения скрипта.
Gitsync имеет параметр -stop-if-empty-comment. Однако этот параметр не позволит нам обрабатывать появление некорректного комментария самостоятельно. Кроме того нам нужно не просто проверять комментарий на пустоту, но и например проверять правильность указания номера задания в нем, его длину , формат и т.д. Затем можно добавить отправку оповещения на почту при обнаружении ошибок.
Можно использовать хуки https://git-scm.com/book/en/v2/Customizing-Git-Git-Hooks. Но для этого надо научиться работать с хуками и кроме того разделить логику работы алгоритмов между скриптом и хуком.
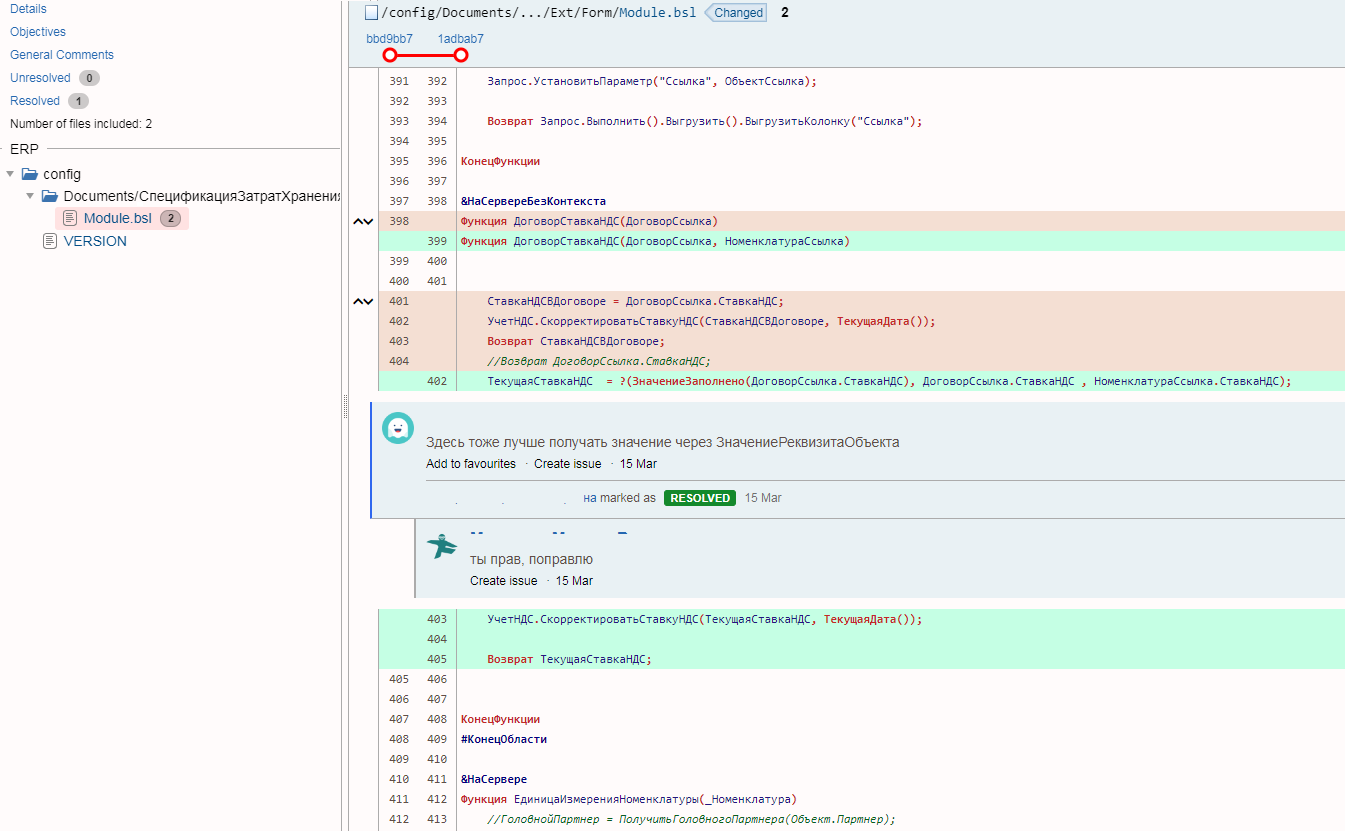
Предлагаю следующий вариант. Мы позволим gitsync выполнить выгрузку и коммит. После этого проверим корректен ли коммит. Если некорректен - будем выполнять нужные нам действия. В данном случае просто прерывать алгоритм с исключением. В следующий раз, чтобы gitsync не делал выгрузки следующей закладки проверим последний коммит перед началом выгрузки. Таким образом проверка на корректность комментария будет стоять до запуска gitsync и после запуска. Выполнять оповещение ответственных лиц нужно только после запуска.
Комментарий будем получать как консольный вывод команды git log -1 --pretty=format:"%s”
Исправление ситуации с неверным комментарием можно провести одним из упомянутых зеленым текстом способов :
// Проверка на пустой комментарий предыдущего коммита. В gitsync есть флаг -stop-if-empty-comment,
// но через собственную проверку мы получаем возможность обрабатывать факт пустого комментария по своему
// Например отправить письмо ответственному сотруднику
//
// После выявления ошибки последний комментарий необходимо исправить вручную, возможные варианты действий:
// 1) непосредственно через git командой git commit --amend, затем необходимо выполнить push вручную
// 2) исправив комменентарий в хранилище, откатить последний коммит (сделав обратный последнему) через
// команду git revert HEAD --no-edit, одновременно с этим будет уменьшена версия в файле VERSION,
// после чего можно будет провести повторную выгрузку
КомментарийПоледнегоКоммита = ВыполнитьКоманду("git log -1 --pretty=format:""%s""", КаталогРепозитория);
Если КомментарийКоммитаНекорректен(КомментарийПоледнегоКоммита) Тогда
ВызватьИсключение "Последний коммит создан с пустым или слишком коротким комментарием.
|Выгрузка последующих коммитов из хранилища преостановлена.";
КонецЕсли;
Теперь перейдем к вопросу проверки наличия изменений после отработки gitsync. Если новых закладок в хранилище не было, то никаких ошибок выгрузки не будет. Код вовзрата будет 0. Можно было бы делать push в remote и в этом случае. Но что если мы захотим подключить следующий шаг - запуск сборки, тестирования и т.д? Целесообразно проверять есть ли изменения. Они будут если хеш последнего коммита до запуска выгрузки и хеш последнего коммита после запуска выгрузки отличаются. Поэтому перед запуском выгрузки получим хеш последнего коммита и после выгрузки сравним его с новым.
Хеш будем получать как консольный вывод команды git log -1 --pretty=format:"%H”
ХешПоследнегоКоммитаДоВыгрузки = ВыполнитьКоманду("git log -1 --pretty=format:""%H""", КаталогРепозитория);
Сообщить("Хеш последнего коммита до выгрузки = " + ХешПоследнегоКоммитаДоВыгрузки);
// Запускаем gitsync
ВыполнитьКоманду(КомандаЗапускаGitsync,
КаталогРепозитория,
0,
"Запускаем gitsync",
"",
"Выполнение gitsync завершилось с ошибкой",
Истина);
// Проверка на пустой комментарий после нового коммита
КомментарийПоледнегоКоммита = ВыполнитьКоманду("git log -1 --pretty=format:""%s""", КаталогРепозитория);
Если КомментарийКоммитаНекорректен(КомментарийПоледнегоКоммита) Тогда
ВызватьИсключение "Текущий коммит создан с пустым или слишком коротким комментарием.
|Отправка в удаленный репозиторий коммитов с таким комментарием запрещена.";
КонецЕсли;
// Проверка на новый коммит в репозитории
ХешПоследнегоКоммитаПослеВыгрузки = ВыполнитьКоманду("git log -1 --pretty=format:""%H""", КаталогРепозитория);
Сообщить("Хеш последнего коммита после выгрузки = " + ХешПоследнегоКоммитаПослеВыгрузки);
Если ХешПоследнегоКоммитаДоВыгрузки = ХешПоследнегоКоммитаПослеВыгрузки Тогда
// Вызываем исклюение, иначе шаг выполнения этого скрипта в Jenkins будет считаться
// успешным и далее пойдет отправка в удаленный репозиторий средствами Jenkins.
// Далее будет подключаться автотестирование. Если отправлять нечего, то последующие
// шаги в Jenkins, включая автотестирование выполняться не должны.
// Для уверенности в том, что отключение вызова исключения не приведет к попытке
// отправки в удаленный репозиторий, установим флаг отправки в Ложь
ОтправлятьВУдаленныйРепозиторий = Ложь;
ВызватьИсключение "В резульате выгрузки в репозитории не было выполнено никаких изменений,
|отправка изменений в удаленный репозиторий не будет выполнена";
КонецЕсли;
И наконец после того как убедились в том что комментарий корректен, изменения в результате выгрузки были - произведем последние действия - отправку в удаленный репозиторий и удаление временных файлов
// Отправляем в удаленный репозиторий
Если ОтправлятьВУдаленныйРепозиторий Тогда
ВыполнитьКоманду("git push origin develop",
КаталогРепозитория,
0,
"Выполняем отправку изменений на удаленный репозиторий",
"Выполнена отправка коммита в удаленный репозиторий",
"Не удалось выполнить отправку в удаленный репозиторий");
КонецЕсли;
// Удаляем временные файлы
УдалитьФайлы(ПутьКоВременнымФайлам);
Сообщить("Выполнено удаление временных файлов");
ВАЖНО! Хорошей практикой, а иногда и необходимостью, является выполнение команды git pull (что равносильно последовательному выполнению git fetch и git merge) перед выполнением git push. Она позволит сначала получить актуальные изменения из удаленного репозитория и остановиться, если перед отправкой потребуется ручное вмешательство и объединение изменений. Но в данном случае мы только отправляем в удаленный репозиторий изменения и никогда не принимаем их из него, поэтому git pull не нужен. Если же работать в репозитории и с внешними файлами проекта, то эту команду будет нужно добавить.
Кроме того очень важно понимать, что и как будет происходить при выполнении этой команды или указанной замены для нее из пары команд fetch и merge. Также очень полезно понимание родственной им команды rebase и наиболее часто применяемой при работе с 1С при выполнении git pull и git push операции fast forward. Без понимания этих процессов переходить к коллективной работе с git будет рискованно. Наиболее наглядные материалы по этой теме из встреченных мной в сети находятся по этим ссылкам:
https://webdevkin.ru/posts/raznoe/izuchaem-git-merge-vs-rebase-dlya-nachinayushhix
https://webdevkin.ru/posts/raznoe/kak-skleit-kommiti-git
http://gearmobile.github.io/git/fast-forward-git/
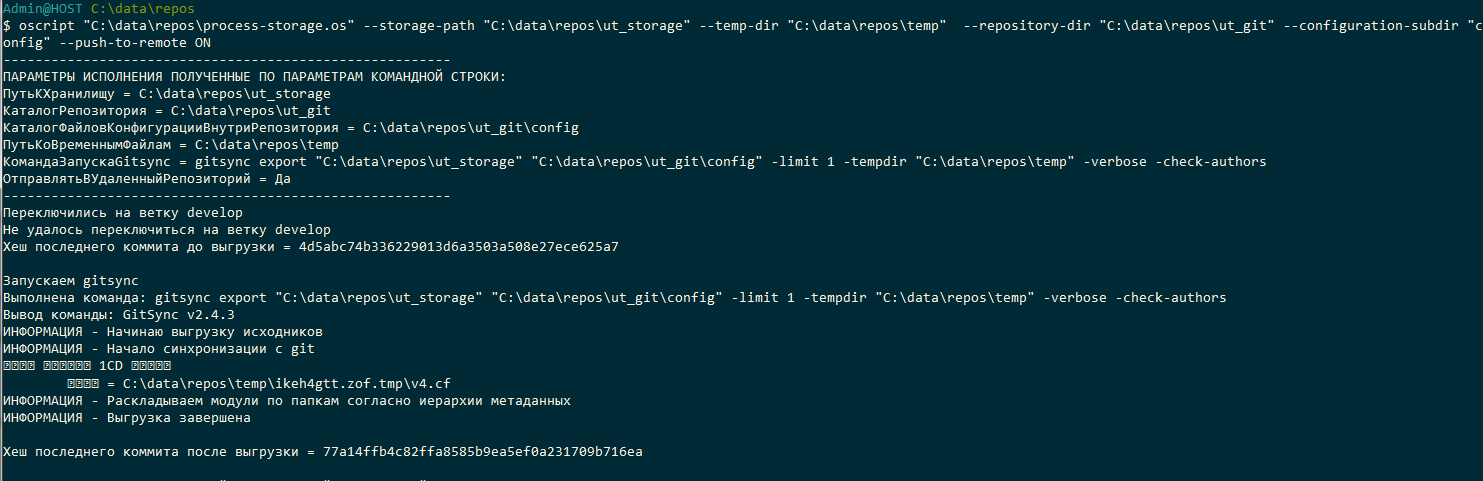
Наконец запустим скрипт следующей командой и убедимся в том, что он работает корректно:
oscript "C:\data\repos\process-storage.os" --storage-path "C:\data\repos\ut_storage" --temp-dir "C:\data\repos\temp" --repository-dir "C:\data\repos\ut_git" --configuration-subdir "config" --push-to-remote ON
Регулярная выгрузка по расписанию
Для регулярного запуска будем использовать планировщик Windows. Это не лучшее решение. Дальше будут указаны преимущества использвоания Jenkins вместо планировщика, но чтобы не превращать публикацию в четвертый том “Войны и мира” сейчас эту тему развивать не будем.
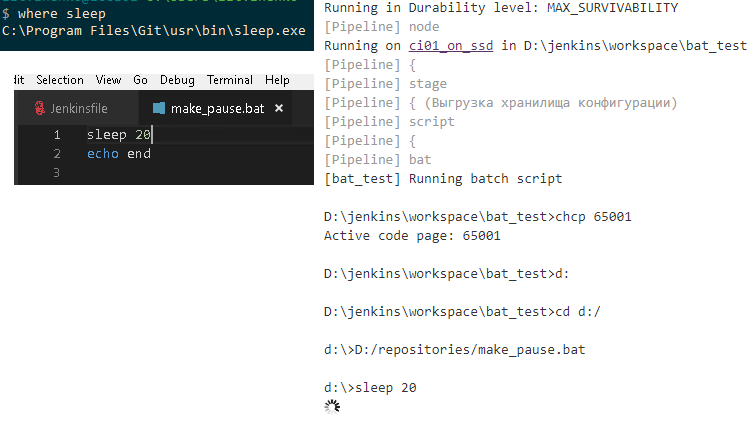
Для запуска через планировщик полезно написать BAT-файл, который будет содержать в себе две строки:
chcp 65001
oscript "%~dp0process-storage.os" --storage-path "%~dp0ut_storage" --temp-dir "%~dp0temp" --repository-dir "%~dp0ut_git" --configuration-subdir "config" --push-to-remote ON
Вместо %~dp0 при запуске система будет подставлять путь расположения bat-файла. Кончено в батнике можно прописать и абсолютные пути, но по практике это менее удобно. Вся конфигурация в этом случае оказыватся прибита гвоздями к конкретным папкам.
Создадим задачу со следующими настройками :
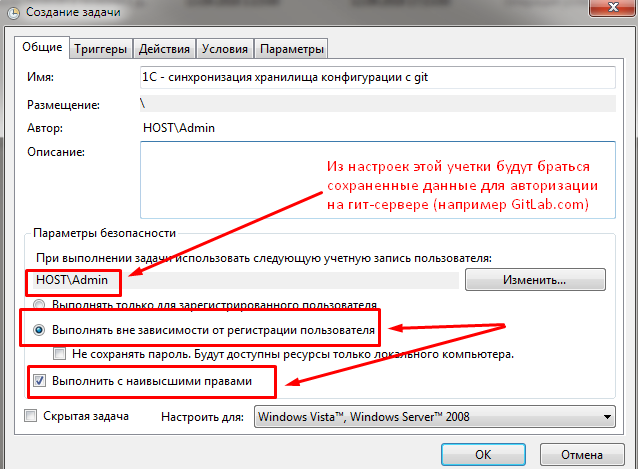
Учетные данные для авторизации на гит-сервере будут браться задачей из хранилища паролей указанного для задачи пользователя:
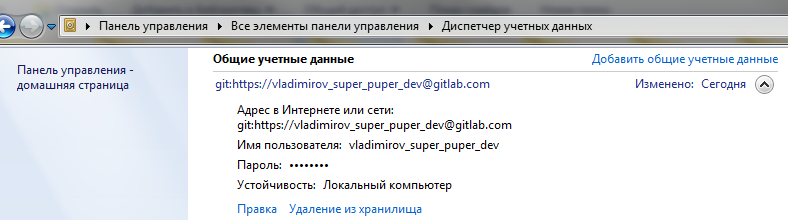
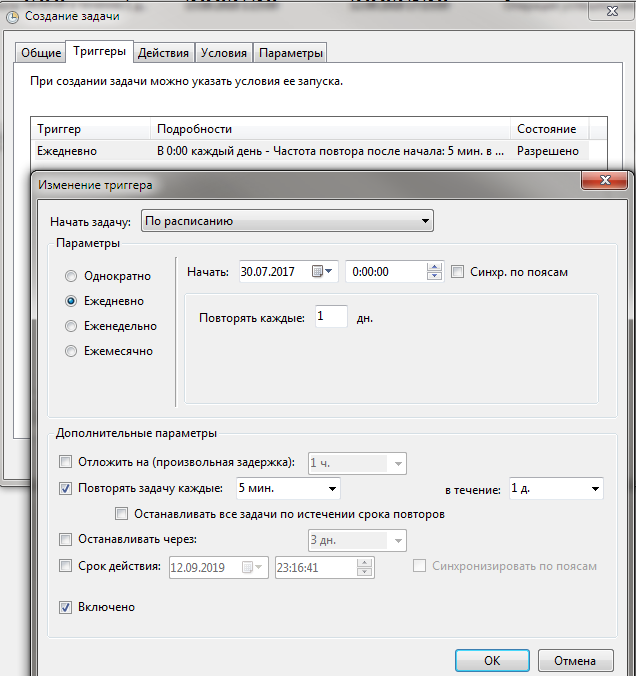
Укажем запуск каждые 5 минут. Можно и чаще, если это требуется для более оперативной работы:
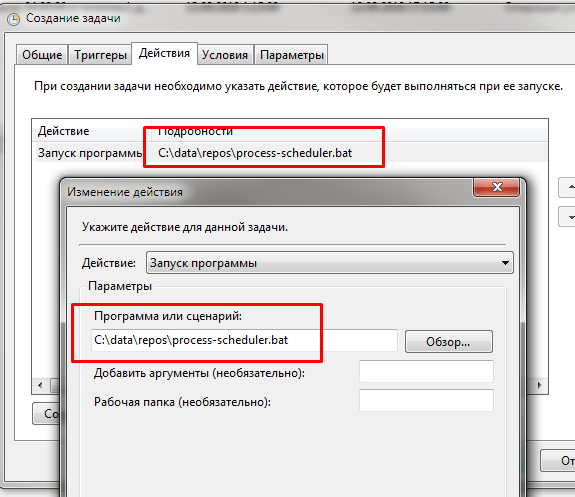
Запускать будем наш bat-файл. Это проще, чем прописывать здесь длинную строку запуска скрипта, параметры и текущий каталог для запуска:
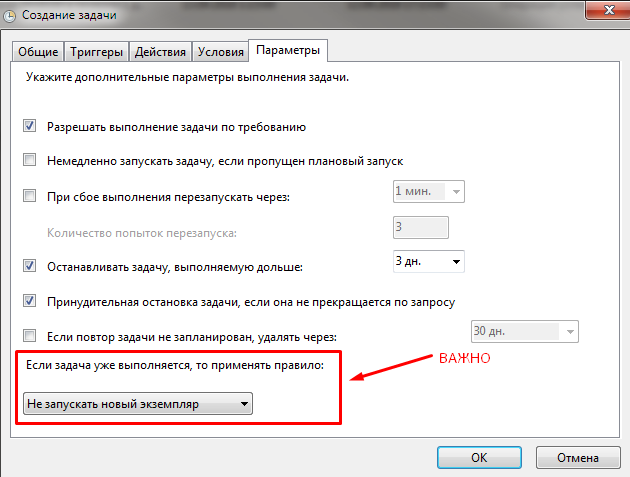
Укажем что в один момент времени может выполняться только одна задача:
Лог можно будет увидеть в журнале задач :
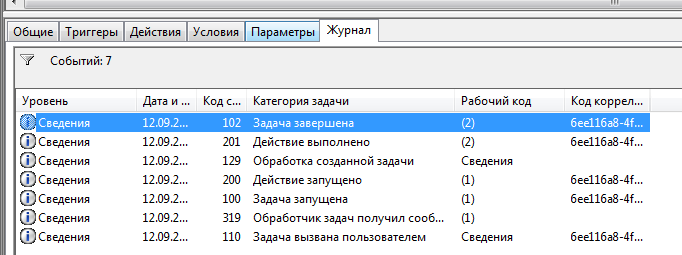
Запуск сделанный с такими настройками как мы задавали на первой вкладке всегда будет выполняться в фоне. Это хорошо, если скрипт выполняется на той же машине , на которой работают разработчики. Мигающие окна не будут никому мешать. Но при этом если параметры авторизации слетят в хранилище паролей указанного пользователя, то в диспетчере задач можно будет увидеть такую ситуацию:

git требует авторизации, но окна отображаются в фоне и добраться до них невозможно. Авторизация при этом требуется на этапе отправки в удаленный репозиторий. В этом случае все процессы oscript , git , git-credential-manager надо завершить и выполнить команду git push вручную.
Также эта проблема с успехом обходится при применении Jenkins. В Jenkins есть хранилище паролей (правда эти пароли сохраняются в явном виде во временные текстовые файлы при работе сценариев). Кроме того применяя Jenkins мы получаем возможность:
- Не останавливаться только на выгрузке и подключить следующие шаги - тестирование, подготовку релиза.
- Распараллеливать процесс выгрузки и тестирования, передавать выполненные изменения в задачу тестирования не мешая при этом дальнейшей синхронизации хранилища и git-репозитория.
- Увидеть логи выполнения скрипта (консольный вывод) и статистику выполнения. На скриншоте ниже красные сборки - это обращения к хранилищу не получившие изменения или упавшие по другой причине. Синие - получившие изменения и успешно выполнившие отправку в удаленный репозиторий
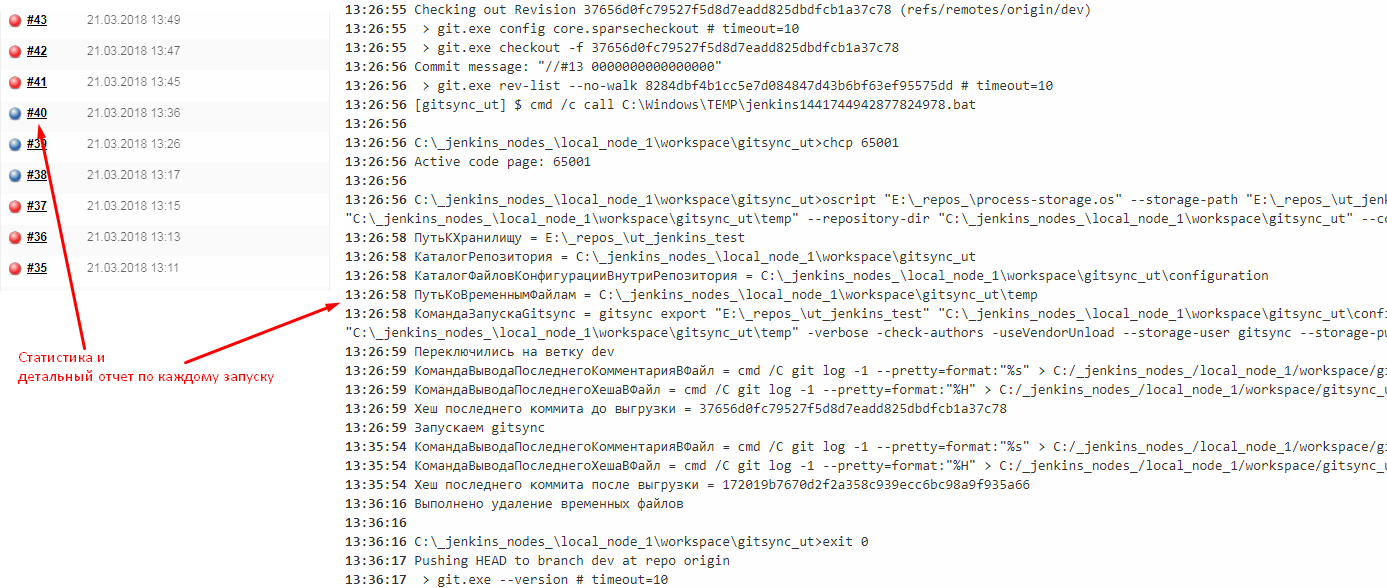
Однако это уже тема для другой публикации. Для изучения Jenkins очень рекомендую курс Jenkins Essential Training , а в применении к 1С курс "Разработка по промышленным стандартам на платформе 1С:Предприятие. Часть 2"
Что мы получаем при использовании Gitlab, Upsource, Crucible и т.д.
Подключение указанных систем к нашим процессам позволяет устанавливать удобную и красивую связь между задачами в системе учета задач, изменениями исходного кода и проводимыми ревью кода.
Продукты Atlassian
При интеграции Crucible, Fisheye и Jira символ # перед номером задачи писать необязательно. Связь с задачей все равно будет установлена автоматически благодаря системе нумерации проектов в Jira (код проекта = префикс задачи).
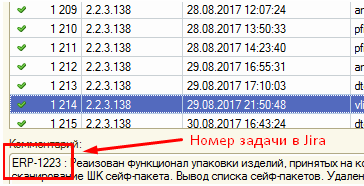

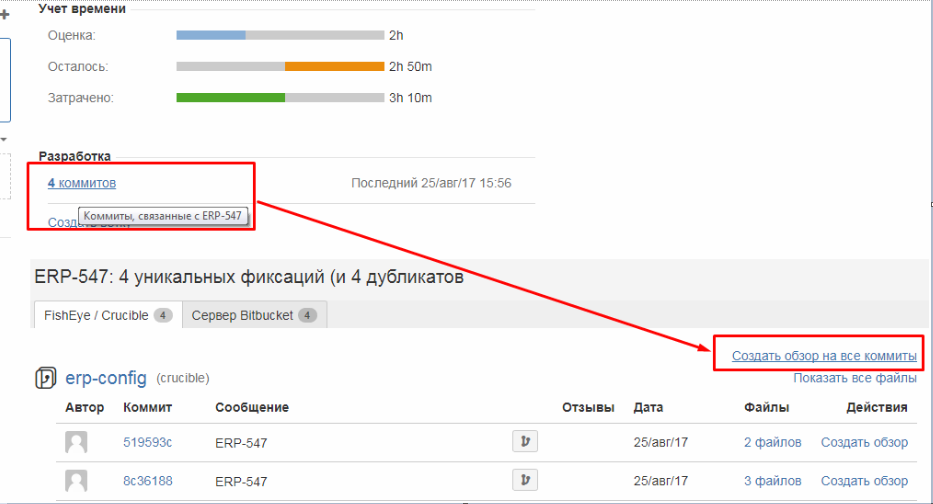
Также мы получаем возможность одним кликом мыши из задачи в Jira просмотреть изменения кода, связанные с задачей и вторым кликом создать код-ревью по задаче в целом, а не по каждому коммиту в отдельности:
Аналогичный процесс уже описывался Андреем Овсянкиным во время выступления на конференции Infostart : //infostart.ru/public/548028/
GitLab
При выгрузке в Gitlab так вероятно не получится и для связи коммитов с задачами, как мы видели выше, нужно писать #НомерЗадачи Текст комментария
Кроме того система код-ревью через мердж-реквесты, принятая в GitLab, плохо подходит для проведения поскоммитных ревью, неизбежных выгрузке изменений из хранилища в Git. В итоге GitLab при работе с хранилищем 1С не позволяет удобно проводить ревью задачи в целом. Ревью же каждого коммита в отдельности - штука затратная по времени и нервам. Ведь ошибка из коммита №1 по задаче может быть уже исправлена в коммите №4 по той же задаче. А просматривать коммиты вероятно придется последовательно.
Пока что у меня нет решения как можно удобно проводить ревью по всем коммитам в рамках задачи используя GitLab. Если у кого-то есть решение, пожалуйста, поделитесь в комментариях.
Upsource
Этот шикарный по отзывам многих разработчиков инструмент от JenBrains позволяет выполнять посткоммитное ревью. Рекомендую к ознакомлению следующие материалы, чтобы сделать вывод, подходит ли он вам :
Интеграция с таск-трекерами: https://www.jetbrains.com/help/upsource/2.0/issue_tracker_integration.html
Автоматизация создания код-ревью: https://blog.jetbrains.com/upsource/2018/07/26/orderly-code-reviews-in-upsource
Хранение внешних обработок, тестов, документации в репозитории
Файлы тестов, документации, внешних обработок (см. Precommit1C) в идеале должны быть консистентны с исходным кодом конфигурации. А значит в идеале должны храниться в том же репозитории. Однако при этом есть разумное требование - каждый коммит в git должен быть связан только с одной задачей. Конечно сам git не требует делать именно так. Но нарушение этого правила может привести к бардаку и все преимущества от применения системы контроля версий потеряются.
Предположим, что мы храним внешние по отношению к исходникам конфигурации файлы в том же репозитории. И теперь выполняется последовательность действий
- Разработчик 1 положил изменения в хранилище 1C по одной задаче
- Разработчик 2 положили в каталог внешних обработок изменения по другой задаче
- Началась выгрузка изменений из хранилища и закончилась, выполняется коммит. С точки зрения Разработчика 1 он должен был относиться только к его задаче.
- Аналогично с точки зрения разработчика Разработчик выполнявший вторую задачу еще не собирался делать коммит внешних обработок, но они уже слились в одном коммите с изменениями по задаче 2 уехали в Bitbucket/Gitlab.
Поэтому при хранении внешних обработок, файлов тестирования лучше создать отдельный репозиторий для каждого разработчика. И перед отправкой своих изменений в общий репозиторий (git push) получать изменения из удаленного репозитория (git pull). В этом случае коммиты связанные с выгрузкой и коммиты связанные со внешними обработками не будут сливаться вместе. Так мы приближаемся к процессу git-flow со всеми его рисками в виде конфликтов при мерджах.
Разумеется это также приведет к необходимости выделения большого репозитория для каждого разработчика (около 5 гигабайт на 1С: ERP и еще больше в случае хранения внешних файлов проекта). Также это повышает вероятность того, что файлы исходников хранилища в репозиториях разработчиков случайно или намеренно будут внесены нежелательные изменения и они уедут в общий репозиторий.
Другим возможным решением является выделение отдельного репозитория для внешних отчетов и обработок. Но в этом случае у нас меньше возможности поддерживать соответствие репозитория конфигурации и репозитория внешних файлов.
Лучшее решение для внешних обработок - придерживаться одного источника исполняемого кода и, если код обработки не требует постоянного изменения, добавлять обработки в состав конфигурации. Для документации же и тестов все равно придется применять один из вышеописанных подходов.
Методы облегчения конфигурации, репозитория и ускорения выгрузки
Работая с большими типовыми конфигурациями размер выгрузки, время выгрузки и размер репозитория может стать проблемой. Могу предложить несколько подходов к оптимизации этого процесса.
Конечно главный из них - использование SSD дисков. Десятки тысяч мелких файлов, с которыми ведется работа, скажут спасибо за такой подарок и начинают обрабатываться быстрее. По практике полная (не инкрементальная) выгрузка каждого коммита ERP без SSD диска занимает 45 - 60 минут, с SSD диском 15-20 минут. Для небольших конфигураций время кончено буде меньше. Например для УТ 11 оно составляло 5 минут. В этом случае оптимизировать время выгрузки наверное не имеет смысла.
Лучший прием для уменьшения времени выгрузки (но не размера репозитория) - это использование инкрементальной выгрузки, поддерживаемой gitsync. О ней можно прочитать здесь : https://github.com/oscript-library/gitsync. Как указано в документации, в течение дня происходит инкрементальная выгрузка, благодаря информации, содержащейся в файле ConfigDumpInfo.xml. Неактуальные файлы удаленных / переименованных объектов метаданных при этом не удаляются. Ночью надо сделать отдельную полную выгрузку, перед ее выполнением удалив файл ConfigDumpInfo.xml. Я этот прием не использовал, так как в этом случае неудобно отслеживать факт переименования объектов метаданных. Да и доведя время выгрузки до 5-15 минут в этом уже не было необходимости.
Следующие приемы также уменьшают размер выгрузки. Если вы решаете оптимизировать размер конфигурации описанными ниже способами , то лучше это сделать до создания репозитория. После его создания и первого коммита все файлы все равно будут в его истории и их изменение или удаление не приведет ни к чему кроме как увеличению репозитория. Конечно немного ускорится выгрузка очередной версии хранилища. Но в объеме занимаемого дискового пространства выигрыш будет небольшой. Итак:
1) Снять с поддержки типовую конфигурацию. Если конфигурация находится на поддержке , то cf - файл поставщика хранится в каждой конфигурации, подключенной к хранилищу, и в самом хранилище. Если мы ведем доработку типовой конфигурации по всем правилам (префиксация новых объектов, проведение код-ревью, работа с объектами без префиксов по всем правилам работы с типовыми объектами) то лишние замки и желтые квадраты на типовых объектах нам итак не нужны.
Тем более что снятие замка требует захвата корня конфигурации. Да и применение KDiff3 заставляет забыть о том, что такое страх изменения типовых модулей. Не устаю советовать этот инструмент. Коллеги, используйте уже его! ))
При обновлении на новый релиз достаточно делать это только в одной конфигурации подключенной к хранилищу. В несколько шагов:
а) Захватываем все типовые объекты
б) Сравниваем объединяем с постановкой на поддержку.
в) Проводим обновление конфигурации как находящейся на поддержке.
г) Снимаем с поддержки.
д) Помещаем изменения в хранилище и готовим релиз.
2) Следующий метод - заменить неиспользуемые драйверы в общих макетах на пустые файлы. Огромное количество бинарников перестанет при этом каждый раз выгружаться.
3) Очистить старые макеты регламентированной отчетности. Это одни из самых крупных файлов в составе конфигураций и хранятся в ней годами. Не обязательно их удалять, можно просто очистить содержимое табличных документов. Их очистка не помешает обновлению на новые релизы, так как их не будет в списке дважды измененных объектов - макеты 5-летней давности не обновляются.
4) Быть осторожнее с ролями. Если роли назначить права на все объекты а затем их снять, то в выгрузке из ERP роль будет занимать до 16-20 мегабайт. И никак средствами конфигуратора от этого больше не избавиться. На УТ можно увидеть как роль вместо 1 килобайта начинает занимать 7 мегабайт. Править такие файлы после этого для уменьшения размера придется в текстовом или XML редакторе а затем делать загрузку в конфигурацию командой частичной загрузки файлов конфигурации :

О гит-клиентах
На больших конфигурациях графические клиенты вроде SourceTree или GitKraken часто зависают. Особенно при работе с объемными коммитами, вызванными переходом на новую редакцию или релиз типовой конфиуграции, созданием хранилища и т.д. SourceTree не рекомендую использовать. Прежде чем сделать какие-то действия, в том числе коммиты, этот клиент делает собственный индекс файлов. Выполняется это долго на больших конфигурациях. И если сделать коммит или другое действие не дождавшись индексирования, то можно потерять часть изменений. Много лучше себя ведет более простой клиент SmartGit.
Для большинства операций рекомендую использовать консольный клиент. Он быстрый и главное он достаточен для выполнения большинства нужных для 1С операций. Использование консоли позволяет также правильно использовать терминологию. Многие графические клиенты ее искажают даже в английском варианте, не говоря уже о локализованных на русский язык версиях.
Содержимое прикрепленного файла
- Файл скрипта .os
- Bat-файл с командой запуска
- .gitignore
Вступайте в нашу телеграмм-группу Инфостарт