
{kind=link}
В статье «Использование нарастающих итогов в партионном учете и не только» рассматривался вопрос получения всех реквизитов движений партионного учета (списания) для всей номенклатуры только одного документа. Зачастую построение движений партионного учета (списание) в организациях выполняется уже после ввода всех документов прихода и расхода товаров, сразу для всех документов расхода. Ниже рассматривается вариант решения данной задачи.
Для начала вспомним запрос, позволяющий решать аналогичную задачу для одного документа:
SELECT
ТаблицаНоменклатуры.Номенклатура,
tab1.Партия,
CASE
WHEN
( SUM( ISNULL( tab2.КоличествоОстаток, 0 ) ) + MAX( ISNULL( tab1.КоличествоОстаток, 0 ) ) ) > MAX( ТаблицаНоменклатуры.Количество )
THEN
MAX( ТаблицаНоменклатуры.Количество ) - SUM( ISNULL( tab2.КоличествоОстаток, 0 ) )
ELSE
MAX( ISNULL( tab1.КоличествоОстаток, 0 ) )
END AS КоличествоСписания
FROM ТаблицаНоменклатуры
LEFT JOIN РегистрНакопления.ОстаткиНоменклатуры.Остатки AS tab1
ON ТаблицаНоменклатуры.Номенклатура = tab1.Номенклатура
LEFT JOIN РегистрНакопления.ОстаткиНоменклатуры.Остатки AS tab2
ON ( tab1.Номенклатура = tab2.Номенклатура ) AND ( tab1.Партия > tab2.Партия )
GROUP BY ТаблицаНоменклатуры.Номенклатура, tab1.Партия
HAVING SUM( ISNULL( tab2.КоличествоОстаток, 0 ) ) < MAX( ТаблицаНоменклатуры.Количество );
Вполне логичным решением для задачи обобщения данного запроса на случай множества документов вроде бы является следующий запрос:
SELECT
ТаблицаДокументов.Документ,
ТаблицаДокументов.Номенклатура,
tab1.Партия,
CASE
WHEN
( SUM( ISNULL( tab2.КоличествоОстаток, 0 ) ) + MAX( ISNULL( tab1.КоличествоОстаток, 0 ) ) ) > MAX( ТаблицаДокументов.Количество )
THEN
MAX( ТаблицаДокументов.Количество ) - SUM( ISNULL( tab2.КоличествоОстаток, 0 ) )
ELSE
MAX( ISNULL( tab1.КоличествоОстаток, 0 ) )
END AS КоличествоСписания
FROM ТаблицаДокументов
LEFT JOIN РегистрНакопления.ОстаткиНоменклатуры.Остатки AS tab1
ON ТаблицаДокументов.Номенклатура = tab1.Номенклатура
LEFT JOIN РегистрНакопления.ОстаткиНоменклатуры.Остатки AS tab2
ON ( tab1.Номенклатура = tab2.Номенклатура ) AND ( tab1.Партия > tab2.Партия )
GROUP BY ТаблицаДокументов.Документ, ТаблицаДокументов.Номенклатура, tab1.Партия
HAVING SUM( ISNULL( tab2.КоличествоОстаток, 0 ) ) < MAX( ТаблицаДокументов.Количество );
Но на самом деле этот запрос является ошибочным. Основная проблема этого запроса это отсутствие «истории» списания партий по предыдущим строкам запроса. Поясню на следующем примере: допустим, мы имеем два документа и три партии, две из которых полностью списываются на первый документ, а одна - на второй. В приведенном выше запросе для первого документа списание пройдет правильно, а вот для второго документа количество с первой и второй партии будут списаны еще раз, так как нет информации какие именно партии и в каком количестве были списаны для предыдущего документа.
Однако, надо заметить, вопрос хранения «истории» уже решался - для правильного списания партий для одного документа и всего набора номенклатуры тоже необходима «история» предыдущих «списаний». В качестве механизма «сохранения истории» было применено вычисление «нарастающего итога» по таблице партий (в сумме «нарастающего итога» присутствовует информация о цифрах из предыдущих партий, что и позволяет учитывать «историю» по таблице партий). Следовательно, для получения возможности учитывать «историю» для «ТаблицыДокументов» нам необходима возможность получения по ней «нарастающего итога».
Таким образом, для получения запроса, дающего возможность «использовать историю» как для таблицы партий, так и для таблицы документов, необходима возможность получения нарастающих итогов для двух таблиц в рамках одного запроса. Теоретическая часть решения данной проблемы уже была описана ранее мною в статье «Вычисление нарастающего итога для N таблиц в рамках одного запроса». Здесь я приведу только конечный запрос:
SELECT
tab_doc_1.Документ,
tab_doc_1.Номенклатура,
SUM( tab_doc_2.Количество)
\
CASE
WHEN
COUNT( DISTINCT tab_part_2.Партия ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_part_2.Партия )
END AS ДокСуммаПредыдущих,
tab_part_1.Партия,
SUM( tab_part_2.КоличествоОстаток )
\
CASE
WHEN
COUNT( DISTINCT tab_doc_2.Документ ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_doc_2.Документ )
END AS ПартСуммаПредыдущих
FROM ТаблицаДокументов AS tab_doc_1
LEFT JOIN ТаблицаДокументов AS tab_doc_2
ON tab_doc_1.Документ > tab_doc_2.Документ
LEFT JOIN ТаблицаПартий AS tab_part_1
ON tab_doc_1.Номенклатура = tab_part_1.Номенклатура
LEFT JOIN ТаблицаПартий AS tab_part_2
ON ( tab_part_1.Номенклатура = tab_part_2.Номенклатура ) AND ( tab_part_1.Партия > tab_part_2.Партия )
GROUP BY tab_doc_1.Документ, tab_doc_1.Номенклатура, tab_part_1.Партия
ORDER BY tab_doc_1.Документ, tab_doc_1.Номенклатура, tab_part_1.Партия
В данном запросе есть вычисление «нарастающего итога» для двух таблиц, есть соединение «таблицы документов» и «таблицы партий» (каждая строка из «таблицы документов» соединяется со всеми строками из «таблицы партий»). Однако для окончательного решения вопроса нахождения всех реквизитов для движений списания осталось решить несколько вопросов. Во-первых, для каждого отдельного документа из «таблицы документов» важен не весь список партий, а только некоторые из них, партии с которых будет производиться списания по номенклатуре данного конкретного документа. Следовательно, необходимо получить выражение, ограничивающее список партий для каждого конкретного документа. Во-вторых, необходимы формулы, по которым будут рассчитываться значения числовых реквизитов движений списания (количество и сумма списания).
Сначала рассмотрим решение вопроса об ограничении списка партий для каждого конкретного документа.
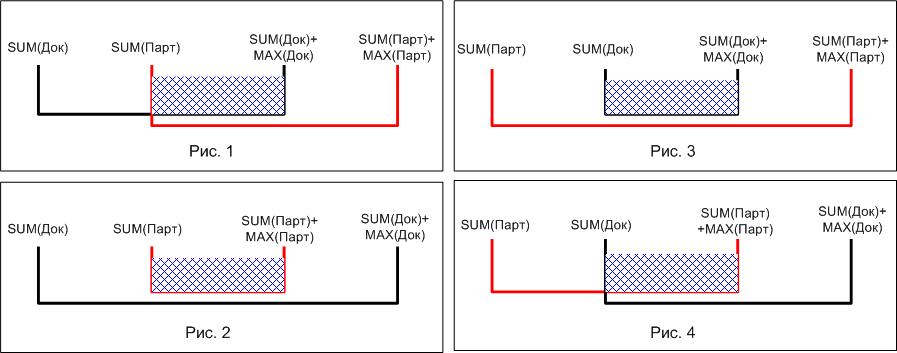
Для дальнейшего правильного понимания всех нюансов проиллюстрируем «взаимоположения» документов и партий следующим рисунком:

На рисунках изображены все возможные варианты «взаимоположения» документов из таблицы документов и партий из таблицы партий. Для упрощения приняты следующие сокращения:
SUM(Док) - сумма по всем предыдущим документам;SUM(Док)+MAX(Док) - нарастающий итог по документам;
SUM(Парт) - сумма по всем предыдущим партиям;
SUM(Парт)+MAX(Парт) - нарастающий итог по партиям;
Первично вернемся к запросу для одного документа и рассмотрим его выражение для ограничения списка партий:
HAVING SUM( ISNULL( tab2.КоличествоОстаток, 0 ) ) < MAX( ТаблицаНоменклатуры.Количество )
Учитывая то, что для множества документов необходимо учитывать предыдущую «историю» получим следующее выражение для ограничения списка партий «сверху» (отсекаем партии, которые будут участвовать в списаниях для документов, следующих после данного конкретного документа):
SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) < SUM( ISNULL( tab_doc_2.Количество, 0 ) ) + MAX( tab_doc_1.Количество )
Так как одна и та же партия может участвовать в списаниях для нескольких соседних документов, то кроме ограничения для списка партий «сверху» понадобиться также ограничение и «снизу» (ограничение «снизу» отсекает партии, которые были полностью списаны в движениях по документам, предшествующих данному конкретному документу). В запросе для одного документа это ограничение отсутствовало так как «точкой отсчета» для партий всегда являлся 0 (то есть можно было записать «SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) > 0», что не имело бы смысла).
Выражение для ограничения списка партий «снизу» имеет следующий вид:
SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) > SUM( ISNULL( tab_doc_2.Количество, 0 ) ) - MAX( tab_part_1.КоличествоОстаток)
Полное выражение для ограничения списка партий приведено в следующем запросе:
HAVING
( SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) < SUM( ISNULL( tab_doc_2.Количество, 0 ) ) + MAX( tab_doc_1.Количество ) )
AND
( SUM( ISNULL( tab_doc_2.Количество, 0 ) ) - MAX( tab_part_1.КоличествоОстаток) < SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) )
<ПРЕДУПРЕЖДЕНИЕ. Так как в выражении для ограничения списка партий применяется ограничение «сверху» и «снизу» для одной и той же величины, то возникает естественное желание оптимизации с помощью оператора BETWEEN. Единственная проблема здесь - данный оператор включает как верхнюю, так и нижнюю границы в область сравнения (фактически оператор сравнения «>» заменяется на «>=»). В результате это приводит к возникновению «пустых» движений - в выходной таблице запроса могут появиться строки с нулевыми значениями для количества и суммы списания.>
Теперь перейдем к выражению для получения количества списания для каждой конкретной партии. Прежде всего, опять запишем аналогичное выражение для случая одного документа:
CASE
WHEN
( SUM( ISNULL( tab2.КоличествоОстаток, 0 ) ) + MAX( ISNULL( tab1.КоличествоОстаток, 0 ) ) ) > MAX( ТаблицаНоменклатуры.Количество )
THEN
MAX( ТаблицаНоменклатуры.Количество ) - SUM( ISNULL( tab2.КоличествоОстаток, 0 ) )
ELSE
MAX( ISNULL( tab1.КоличествоОстаток, 0 ) )
END
Затем перепишем выражение в следующем виде:
CASE
WHEN
( SUM( ISNULL( tab2.КоличествоОстаток, 0 ) ) + MAX( ISNULL( tab1.КоличествоОстаток, 0 ) ) )
>
MAX( ТаблицаНоменклатуры.Количество )
THEN
MAX( ТаблицаНоменклатуры.Количество )
ELSE
SUM( ISNULL( tab2.КоличествоОстаток, 0 ) ) + MAX( ISNULL( tab1.КоличествоОстаток, 0 ) )
END
-
SUM( ISNULL( tab2.КоличествоОстаток, 0 ) )
Последний запрос был переписан для иллюстрации того факта, что для вычисления количества списания для данной партии по данной номенклатуре используется разность между «верхней границей» (выражение под CASE) и «нижней границей». Рассмотрим обе эти «границы» более подробно. Для начала еще раз вернемся к рисунку, иллюстрирующему «взаимоположение» документов и партий (см. выше). Для случая одного документа и нескольких партий варианты «взаимодействия» ограничиваются рисунками с номерами 1 и 2. Как видно «нижняя граница» для случая одного документа всегда будет постоянна - одна и та же партия участвует только в списании по одному документу, так что варианты, иллюстрированные на рисунках 3 и 4, для случая одного документа отсутствует (точнее вырождаются в варианты, изображенные на рисунках 1 и 2 соответственно так как «нижняя граница» самой первой партии всегда равна 0). «Верхняя граница» определяется условием превышения нарастающего итога по таблице партий над общим количеством номенклатуры.
Для случая, когда в запросе присутствует множество документов со своими списками номенклатуры, ситуация остается примерно такой же, как и для случая одного документа. Выражение для количества списания также определяется разностью «верхней» и «нижней» границ. Добавляется только несколько отличительных моментов. Во-первых, необходимо учитывать «историю» как для таблицы партий, так и для таблицы документов. Следовательно, в выражении для «верхней границы» должна появиться «история» (сумма по предыдущим документам), а не просто выражение для количества. Во-вторых, в случае множества документов в перечень «взаимоположений» документов и партий полноценно появляются и варианты, проиллюстрированные на рисунках 3 и 4 (необходимо учитывать, что одна партия может участвовать в списании для нескольких документов). Выражение для количества списания в случае множества документов приведено в следующем запросе:
CASE
WHEN
( SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) + MAX( ISNULL( tab_part_1.КоличествоОстаток, 0 ) ) )
>
( SUM( tab_doc_2.Количество ) + MAX( tab_doc_1.Количество ) )
THEN
( SUM( tab_doc_2.Количество ) + MAX( tab_doc_1.Количество ) )
ELSE
( SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) + MAX( ISNULL( tab_part_1.КоличествоОстаток, 0 ) ) )
END
-
CASE
WHEN
SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) )
<
SUM( tab_doc_2.Количество )
THEN
SUM( tab_doc_2.Количество )
ELSE
SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) )
END
Приведем теперь весь запрос для получения реквизитов движений:
SELECT
tab_doc_1.Документ,
tab_doc_1.Номенклатура,
tab_part_1.Партия,
(
CASE
WHEN
( SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) + MAX( ISNULL( tab_part_1.КоличествоОстаток, 0 ) ) )
>
( SUM( tab_doc_2.Количество ) + MAX( tab_doc_1.Количество ) )
THEN
( SUM( tab_doc_2.Количество ) + MAX( tab_doc_1.Количество ) )
ELSE
( SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) + MAX( ISNULL( tab_part_1.КоличествоОстаток, 0 ) ) )
END<> -
CASE
WHEN
SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) )
<
SUM( tab_doc_2.Количество )
THEN
SUM( tab_doc_2.Количество )
ELSE
SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) )
END
) AS КоличествоСписания
FROM ТаблицаДокументов AS tab_doc_1
LEFT JOIN ТаблицаДокументов AS tab_doc_2
ON tab_doc_1.Документ > tab_doc_2.Документ
LEFT JOIN ТаблицаПартий AS tab_part_1
ON tab_doc_1.Номенклатура = tab_part_1.Номенклатура
LEFT JOIN ТаблицаПартий AS tab_part_2
ON ( tab_part_1.Номенклатура = tab_part_2.Номенклатура ) AND ( tab_part_1.Партия > tab_part_2.Партия )
GROUP BY tab_doc_1.Документ, tab_doc_1.Номенклатура, tab_part_1.Партия
HAVING
( SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) < SUM( ISNULL( tab_doc_2.Количество, 0 ) ) + MAX( tab_doc_1.Количество ) )
AND
( SUM( ISNULL( tab_doc_2.Количество, 0 ) ) - MAX( tab_part_1.КоличествоОстаток) < SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) )
ORDER BY tab_doc_1.Документ, tab_doc_1.Номенклатура, tab_part_1.Партия
Добавляя деление на соответствующие корректирующие множители (см. «Вычисление нарастающего итога для N таблиц в рамках одного запроса») получаем следующий запрос:
SELECT
tab_doc_1.Документ,
tab_doc_1.Номенклатура,
tab_part_1.Партия,
CASE
WHEN
(
SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) /
CASE
WHEN
COUNT( DISTINCT tab_doc_2.Документ ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_doc_2.Документ )
END + MAX( tab_part_1.КоличествоОстаток )
)
>
(
SUM( ISNULL( tab_doc_2.Количество, 0 ) ) /
CASE
WHEN
COUNT( DISTINCT tab_part_2.Партия ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_part_2.Партия )
END + MAX( tab_doc_1.Количество )
)
THEN
(
SUM( ISNULL( tab_doc_2.Количество, 0 ) ) /
CASE
WHEN
COUNT( DISTINCT tab_part_2.Партия ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_part_2.Партия )
END + MAX( tab_doc_1.Количество )
)
ELSE
(
SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) /
CASE
WHEN
COUNT( DISTINCT tab_doc_2.Документ ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_doc_2.Документ )
END + MAX( tab_part_1.КоличествоОстаток )
)
END
-
CASE
WHEN
(
SUM( ISNULL( tab_doc_2.Количество, 0 ) ) /
CASE
WHEN
COUNT( DISTINCT tab_part_2.Партия ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_part_2.Партия )
END
)
>
(
SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) /
CASE
WHEN
COUNT( DISTINCT tab_doc_2.Документ ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_doc_2.Документ )
END
)
THEN
(
SUM( ISNULL( tab_doc_2.Количество, 0 ) ) /
CASE
WHEN
COUNT( DISTINCT tab_part_2.Партия ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_part_2.Партия )
END
)
ELSE
(
SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) /
CASE
WHEN
COUNT( DISTINCT tab_doc_2.Документ ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_doc_2.Документ )
END
)
END AS КоличествоСписания
FROM ТаблицаДокументов AS tab_doc_1
LEFT JOIN ТаблицаДокументов AS tab_doc_2
ON ( tab_doc_1.Номенклатура = tab_doc_2.Номенклатура ) AND ( tab_doc_1.Документ > tab_doc_2.Документ )
LEFT JOIN ТаблицаПартий AS tab_part_1
ON tab_doc_1.Номенклатура = tab_part_1.Номенклатура
LEFT JOIN ТаблицаПартий AS tab_part_2
ON ( tab_part_1.Номенклатура = tab_part_2.Номенклатура ) AND ( tab_part_1.Партия > tab_part_2.Партия )
GROUP BY tab_doc_1.Документ, tab_doc_1.Номенклатура, tab_part_1.Партия
HAVING
(
SUM( ISNULL( tab_doc_2.Количество, 0 ) ) /
CASE
WHEN
COUNT( DISTINCT tab_part_2.Партия ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_part_2.Партия )
END + MAX( tab_doc_1.Количество )
>
SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) /
CASE
WHEN
COUNT( DISTINCT tab_doc_2.Документ ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_doc_2.Документ )
END
)
AND
(
SUM( ISNULL( tab_doc_2.Количество, 0 ) ) /
CASE
WHEN
COUNT( DISTINCT tab_part_2.Партия ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_part_2.Партия )
END
<
SUM( ISNULL( tab_part_2.КоличествоОстаток, 0 ) ) /
CASE
WHEN
COUNT( DISTINCT tab_doc_2.Документ ) = 0
THEN
1
ELSE
COUNT( DISTINCT tab_doc_2.Документ )
END + MAX( tab_part_1.КоличествоОстаток )
)
ORDER BY tab_doc_1.Документ, tab_doc_1.Номенклатура, tab_part_1.Партия
Полученный запрос является корректным и работающим. Получена возможность вычисления нарастающего итога для двух таблиц одновременно, получены выражения как для ограничения списка партий, так и для числового значения количества списания.
Однако осталась еще одна очень важная деталь - соотношения моментов времени ввода документов и партий. В случае одного документа список партий получался просто - находились все партии, по которым есть остаток на дату документа. Но в случае множества документов необходимо находить подобный «остаток партий» для каждой строки из «таблицы документов», то есть накладывать еще одно ограничение для списка партий для каждого конкретного документа. Казалось бы, что может быть проще - напишем простое ограничение на соотношение моментов времени документа и партии:
SELECT
...
FROM ТаблицаДокументов AS tab_doc_1
LEFT JOIN ТаблицаДокументов AS tab_doc_2
ON ( tab_doc_1.Номенклатура = tab_doc_2.Номенклатура ) AND ( tab_doc_1.Документ > tab_doc_2.Документ )
Данное ограничение будет великолепно работать, но вот только в случае списания по методу FIFO. В случае списания по методу FIFO в «истории» для списка партий учитываются только партии, которые стоят по времени раньше данной текущей партии. Таким образом, накладывая ограничение из предыдущего запроса, мы получаем корректное значение «истории» для партии (если данная партия по времени ввода меньше данного документа, то и все партии из «истории» также заведомо меньше). Однако для случая списания по методу LIFO все несколько иначе: в «истории» партии учитываются значения для партий, которые идут позже. Таким образом, даже накладывая ограничение из предыдущего запроса, мы получим ошибочные значения в «истории» партий (в «истории» могут учитываться партии, которые были введены позднее данного документа). Следовательно, необходимо также накладывать ограничение на «историю» партий. Правильное выражение для учета соотношений моментов времени для документов и партий приведено в следующем запросе:
SELECT
...
FROM ТаблицаДокументов AS tab_doc_1
LEFT JOIN ТаблицаДокументов AS tab_doc_2
ON ( tab_doc_1.Номенклатура = tab_doc_2.Номенклатура ) AND ( tab_doc_1.Документ > tab_doc_2.Документ )
LEFT JOIN ТаблицаПартий AS tab_part_1
ON ( tab_doc_1.Номенклатура = tab_part_1.Номенклатура ) AND ( tab_doc_1.Документ > tab_part_1.Партия )
LEFT JOIN ТаблицаПартий AS tab_part_2
ON ( tab_part_1.Номенклатура = tab_part_2.Номенклатура ) AND ( tab_part_1.Партия > tab_part_2.Партия ) AND ( tab_doc_1.Документ > tab_part_2.Партия )
GROUP BY tab_doc_1.Документ, tab_doc_1.Номенклатура, tab_part_1.Партия
Но и этот вариант запроса имеет свои огрехи для случая списания по методу LIFO (а также в некоторых «спорных» случаях даже для списания по методу FIFO). Устранением этих «огрехов» я постараюсь заняться в следующих своих статьях. Пока же, в качестве разминки, предлагаю читателям самостоятельно найти проблемные места данного запроса.
Окончательный вариант запроса вместе с тестовым примером приведен в присоединенном к данной статье файле выгрузки. Конфигурация реализует управляемое приложение и разработана на релизе 8.2.14.528.