





Работа «задним числом»
1С – одна из немногих учетных систем, которая настолько лояльна к пользователю, что позволяет ему работать «задним числом». Такая работа интуитивно понятна, позволяет исправлять ошибки «в прошлом», получать корректные ретроспективные отчеты и многое другое, но порождает ряд проблем, главная из которых – восстановление последовательности проведения документов.
Большинство западных систем учета таких возможностей не предоставляют, ограничивая пользователя только оперативной работой. При возникновении потребности исправить ошибки «в прошлом» пользователю доступны механизмы полного сторнирования ошибочной операции и ввод корректных данных, но все это будет отражено в текущем периоде. Это не всегда удобно, да и в отчетах нет «чистой» ретроспективы. Однако таким образом наши западные коллеги ушли от проблем с последовательностью ввода документов.
В платформе 1С есть объект метаданных «Последовательности», предназначенный для отслеживания актуальных границ последовательности документов, а также для восстановления последовательности. Само восстановление последовательности технически выглядит просто - проведение документов, входящих в эту последовательность, по порядку. Платформа, да и типовые конфигурации 1С, умеют это делать, и в ситуации небольшого объема данных, либо низкой интенсивности работы пользователей это работает неплохо. Однако в HiLоad системах восстановление последовательности становится большой проблемой:
- Типовое восстановление последовательности выполняется в 1 поток очень долго.
- Необходимо организовывать регулярный запуск восстановления последовательности силами пользователей.
- Восстановление последовательности зачастую полностью блокирует работу пользователей с документами, входящими в эту последовательность.
- …
В своей практике я сталкивался с ситуацией, когда восстановление последовательности документов, вводимых в систему за 24 часа, при использовании типовых инструментов занимало более 24 часов…
Решение этих проблем привело к созданию универсального алгоритма многопоточного восстановления последовательностей.
Многопоточное восстановление последовательности
Разработанный алгоритм восстановления последовательности:
- полностью универсален и может быть использован в любой конфигурации 1С практически без доработок;
- позволяет избежать блокировки работы пользователей во время восстановления последовательности;
- адаптируется к изменениям первичных данных, рассчитан на одновременную работу с пользователями;
- самостоятельно отслеживает момент, когда последовательность нужно начать восстанавливать;
- позволяет гибко настроить уровень многопоточности работы, управлять нагрузкой на кластер серверов и СУБД.
Рассмотрение алгоритма ведется на примере решения классической задачи восстановления последовательности.
Постановка задачи
В типовой конфигурации организован учет расхода электроэнергии по показаниям приборов учета (ПУ). Приборы учета – это элементы справочника "Приборы учета", работа с ними ведется в следующих документах:
- Монтаж ПУ
- Ввод показаний ПУ
- Демонтаж ПУ
Документы работы с ПУ должны вводиться с соблюдением логики (к примеру, нельзя ввести показания или демонтировать прибор учета, который не был смонтирован). При проведении документа логика проверяется и, если она нарушена, пользователю выдается соответствующее предупреждение. В каждом из перечисленных документов есть табличная часть «Показания», в которой, кроме прочего, фиксируется:
- Прибор учета
- Показание прибора учета
Расход электроэнергии рассчитывается при проведении документов «Ввод показаний» и «Демонтаж» как разница между показанием прибора учета в текущем документе и предыдущим показанием ПУ.
 В типовой конфигурации есть последовательность «РаботаСПриборамиУчета» с одним измерением «ПриборУчета».
В типовой конфигурации есть последовательность «РаботаСПриборамиУчета» с одним измерением «ПриборУчета».
Я намеренно не привожу пример реализации данного алгоритма в рамках одной из типовых конфигураций фирмы 1С. Такое описание неизбежно скатилось бы к рассмотрению особенностей конкретного прикладного решения. Я же хочу донести принцип работы алгоритма.
Общее описание алгоритма решения задачи
Перед нами поставлена классическая задача по организации автоматического восстановления последовательности проведения документов. Если пользователь внес показания «задним числом», то все последующие за моментом изменения данных документы необходимо перепровести для корректного расчета в них расхода электроэнергии.
Принцип работы алгоритма по восстановлению последовательности простой, он работает в 2 этапа:
- Создание заданий на восстановление последовательности при записи документов.
- Обработка заданий в несколько параллельных потоков.
Для реализации алгоритма нам нужно будет:
- Встроить конфигурацию «Универсальные механизмы: пакеты данных».
- Реализовать создание заданий на восстановление последовательности.
- Настроить параметры многопоточной обработки этих заданий.
- Написать функцию – обработчик для одного задания.
При реализации алгоритма мы будем придерживаться подходов, исключающих любые изменения кода типовых модулей. Такая «нетравматичная» доработка позволит в будущем обновлять базовую типовую конфигурацию без лишних трудозатрат.
1. Встраивание конфигурации «Универсальные механизмы: пакеты данных»
Отказоустойчивая многопоточная работа алгоритма будет организована с использованием конфигурации «Универсальные механизмы: пакеты данных». Эта конфигурация может быть внедрена в любую конфигурацию на платформе 1С 8.3 без доработок. Она полностью независима и самодостаточна.
Для понимания принципа работы описываемого алгоритма рекомендуется ознакомиться с особенностями работы конфигурации «Универсальные механизмы: пакеты данных» в этой статье.
2. Создание задания на восстановление последовательности
При записи документов, входящих в последовательность, мы будем создавать задания на восстановление последовательности. При этом нам нужно создавать задания как на аналитику документа до его записи, так и на аналитику после записи. Это нужно, чтобы не потерять задание на восстановление последовательности по прибору учета, который, к примеру, был удален из табличной части документа.
Задания будут фиксироваться в разрезе Ключа последовательности. Ключ последовательности – это структура, содержащая набор измерений последовательности, по которой проходит (или проходил) записываемый документ. Ссылки на сам документ задание содержать не будет.
В нашем случае ключ последовательности состоит из одной ссылки на прибор учета. В прикладных задачах ключ последовательности может быть составным. К примеру, если речь идет о последовательности партий товаров, то измерениями ключа могут быть:
- Организация
- Склад
- Номенклатура
Если же речь идет о последовательности взаиморасчетов, то измерениями ключа могут быть:
- Организация
- Контрагент
- Договор
Один документ при записи может создавать несколько заданий, если этот документ двигает последовательность в нескольких разрезах.
Само задание – это пакет данных. В качестве данных пакета выступает структура – ключ последовательности. Создание заданий – пакетов данных – мы вынесем в новые подписки на события «ПередЗаписью» и «ПриЗаписи» документов, входящих в последовательность. Это позволит не изменять код типовых модулей.
Код обработчика «ПередЗаписью» документов последовательности
Процедура ПередЗаписью(Источник, Отказ, РежимЗаписи, РежимПроведения)
// Получим ключи последовательности, по которым проходил документ до записи
КлючиПоследовательностиДоЗаписи = Новый Массив;
Если НЕ Источник.ЭтоНовый() Тогда
ТекстЗапроса =
"ВЫБРАТЬ
| РаботаСПриборамиУчетаПоказания.ПриборУчета
|ИЗ
| «+Источник. Метаданные().Имя+».Показания КАК РаботаСПриборамиУчетаПоказания
|ГДЕ
| РаботаСПриборамиУчетаПоказания.Ссылка = &Ссылка";
Запрос = Новый Запрос(ТекстЗапроса);
Запрос.УстановитьПараметр("Ссылка", Источник.Ссылка);
Выборка = Запрос.Выполнить().Выбрать();
Пока Выборка.Следующий() Цикл
Ключ = Новый Структура;
Ключ.Вставить("ИдентификаторКлюча", Строка(Выборка.ПриборУчета.УникальныйИдентификатор()));
Ключ.Вставить("ПриборУчета", Выборка.ПриборУчета); // измерения последовательности
КлючиПоследовательностиДоЗаписи.Добавить(Ключ);
КонецЦикла;
КонецЕсли;
ДополнительныеСвойства.Вставить("КлючиПоследовательностиДоЗаписи", КлючиПоследовательностиДоЗаписи);
КонецПроцедуры // ПередЗаписью()
В процедуре мы выбираем те разрезы, по которым отражался документ в последовательности до записи. Структура Ключ – это и есть ключ нашей последовательности. Мы формируем массив ключей и сохраняем его в дополнительных свойствах объекта, чтобы когда (и если) мы дойдем до записи документа, мы могли получить полный список ключей последовательности, «задетых» документом.
Важно! Помимо прочего в ключе последовательности мы формируем уникальный строковый идентификатор ключа:
Ключ.Вставить("ИдентификаторКлюча", Строка(Выборка.ПриборУчета.УникальныйИдентификатор()));
Он нам пригодится позднее. По сути это уникальная строка, сформированная из измерений ключа последовательности. Если ключ последовательности содержит не одно измерение, а несколько, идентификатор ключа нужно собирать вот так:
ИдентификаторКлюча = «»+Измерение1.УникальныйИдентификатор()+Измерение2.УникальныйИдентификатор();
Ключ.Вставить("ИдентификаторКлюча", ИдентификаторКлюча);
Теперь рассмотрим порядок создания заданий на восстановление последовательности в подписке «ПриЗаписи» документов, входящих в последовательность.
Код обработчика «ПриЗаписи» документов последовательности
Процедура ПриЗаписи(Источник, Отказ)
// 1. Создадим полную таблицу ключей последовательности, которые затронула запись этого документа
// 1.1. Новые ключи последовательности
ТаблицаКлючей = Источник.Показания.Выгрузить(,"ПриборУчета");
ТаблицаКлючей.Колонки.Добавить("ИдентификаторКлюча", Новый ОписаниеТипов("Строка",,Новый КвалификаторыСтроки(200,ДопустимаяДлина.Переменная)));
Для каждого СтрКлюч из ТаблицаКлючей Цикл
СтрКлюч.ИдентификаторКлюча = Строка(СтрКлюч.ПриборУчета.УникальныйИдентификатор());
КонецЦикла;
// 1.2. Ключи последовательности, по которым проходил документ до записи
КлючиПоследовательностиДоЗаписи = ДополнительныеСвойства["КлючиПоследовательностиДоЗаписи"];
Для каждого КлючДоЗаписи из КлючиПоследовательностиДоЗаписи Цикл
СтрКлюч = ТаблицаКлючей.Добавить();
ЗаполнитьЗначенияСвойств(СтрКлюч, КлючДоЗаписи);
КонецЦикла;
// 2. Для каждого ключа из таблицы ключей нужно создать задание на восстановление последовательности - новый ПАКЕТ ДАННЫХ.
// При этом не будем создавать пакет для ключей, для которых уже создан пакет, ожидающий обработки.
// 2.1. Найдем наш способ обработки
ИмяСпособаОбработки = "Восстановление последовательности работы с ПУ";
СпособОбработки = Справочники.ум_СпособыОбработкиПакетов.НайтиПоНаименованию(ИмяСпособаОбработки);
Если НЕ ЗначениеЗаполнено(СпособОбработки) Тогда
ВызватьИсключение "Не найден способ обработки пакетов """+ИмяСпособаОбработки+"""!";
КонецЕсли;
// 2.2. Отбросим ключи, по которым уже есть пакеты по нашему способу в статусе "К обработке".
// Ключ последовательности - в поле ДополнительнаяИнформация пакета.
ТекстЗапроса =
"ВЫБРАТЬ
| ТаблицаКлючей.ИдентификаторКлюча,
| ТаблицаКлючей.ПриборУчета
|ПОМЕСТИТЬ ТаблицаКлючей
|ИЗ
| &ТаблицаКлючей КАК ТаблицаКлючей
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| ТаблицаКлючей.ИдентификаторКлюча,
| ТаблицаКлючей.ПриборУчета
|ИЗ
| ТаблицаКлючей КАК ТаблицаКлючей
| ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ум_ПакетыДанных КАК ум_ПакетыДанных
| ПО (ум_ПакетыДанных.СпособОбработки = &СпособОбработки)
| И (ум_ПакетыДанных.Состояние = &КОбработке)
| И ТаблицаКлючей.ИдентификаторКлюча = ум_ПакетыДанных.ДополнительнаяИнформация
|ГДЕ
| ум_ПакетыДанных.ИдентификаторПакета ЕСТЬ NULL
|
|СГРУППИРОВАТЬ ПО
| ТаблицаКлючей.ПриборУчета,
| ТаблицаКлючей.ИдентификаторКлюча";
Запрос = Новый Запрос(ТекстЗапроса);
Запрос.УстановитьПараметр("ТаблицаКлючей" , ТаблицаКлючей);
Запрос.УстановитьПараметр("СпособОбработки" , СпособОбработки);
Запрос.УстановитьПараметр("КОбработке" , Перечисления.ум_СостоянияПакетаДанных.КОбработке);
// 3. Создадим ПАКЕТЫ ДАННЫХ - задания на восстановление последовательности по нашим ключам
Выборка = Запрос.Выполнить().Выбрать();
Пока Выборка.Следующий() Цикл
// Данные пакета - разрезы последовательности, по которым будет восстанавливаться последовательность
ДанныеПакета = Новый Структура;
ДанныеПакета.Вставить("ИдентификаторКлюча" , Выборка.ИдентификаторКлюча);
ДанныеПакета.Вставить("ПриборУчета" , Выборка.ПриборУчета); // измерения последовательности
Результат = ум_ПакетыДанныхСерверПривилегированный.СоздатьНовыйПакетДанных(ДанныеПакета, ИмяСпособаОбработки, ,ДанныеПакета.ИдентификаторКлюча, "Прибор учета: "+Выборка.ПриборУчета);
Если Результат.ОшибкаЗаписиПакета Тогда
ВызватьИсключение Результат.ОписаниеОшибки;
КонецЕсли;
КонецЦикла;
КонецПроцедуры
Разберем представленный код по пунктам:
№ 1. Создаем полную таблицу ключей последовательности
Таблица содержит как ключи, по которым новая версия документа будет входить в последовательность, так и ключи, по которым документ участвовал в последовательности в своей предыдущей версии.
№ 2. Определяем, для каких ключей нужно создать задания
Задания нужно создавать только для тех ключей последовательности, для которых задания не были созданы ранее. Поиск уже созданных заданий (пакетов данных) мы будем осуществлять по строковому идентификатору ключа. Данный идентификатор мы помещали в поле ДополнительнаяИнформация пакета данных при его создании. При этом нас интересуют ТОЛЬКО пакеты данных, которые еще не обработаны. Если по нашему ключу последовательности есть уже обработанные или обрабатывающиеся в данный момент задания, – нужно создавать новое задание.
№ 3. Сохранение заданий
Создание задания – пакета данных – выполняется стандартным для конфигурации «Универсальные механизмы: пакеты данных» образом. Данные пакета – это ключ последовательности. Строковый идентификатор ключа мы помещаем в поле ДополнительнаяИнформация пакета данных для того, чтобы избежать дублирования заданий.
3. Настройка многопоточной обработки заданий
Мы настроили механизм создания заданий на восстановление последовательностей. Теперь при работе пользователей или программной записи документов, входящих в последовательность, генерируются пакеты данных по способу обработки «Восстановление последовательности работы с ПУ».
Настроим способ обработки пакетов «Восстановление последовательности работы с ПУ». Для этого откроем в клиенте 1С справочник «Способы обработки пакетов» и создадим в нем новый элемент. Заполним его как показано на рисунке ниже.
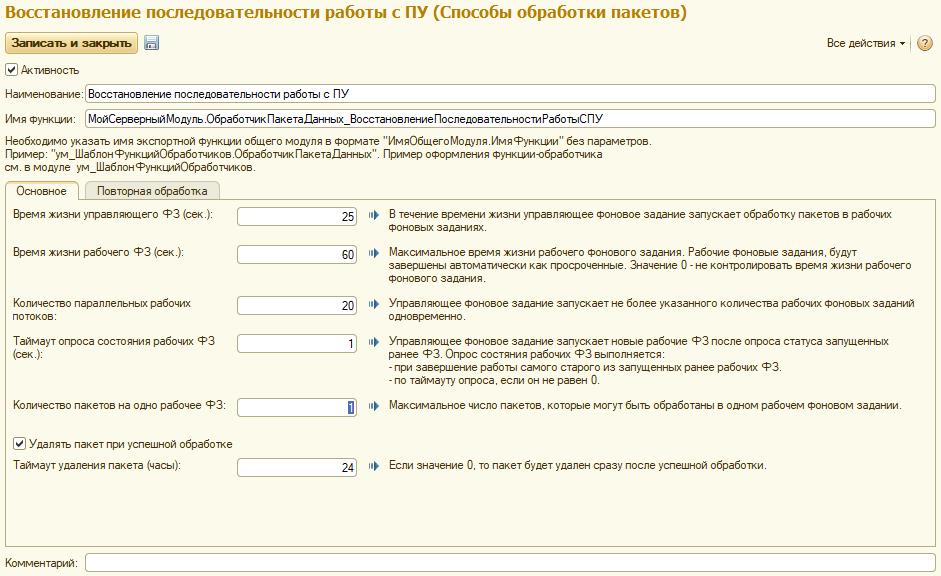
Наименование способа обработки «Восстановление последовательности работы с ПУ» значимо, т.к. ранее (при создании пакета данных) мы указывали способ обработки пакета, который искали по его наименованию.
В поле «Имя функции» мы укажем имя функции, которая будет заниматься обработкой одного пакета данных. Ее мы создадим чуть позже.
Время жизни управляющего потока – мы указали 25 секунд. Такой тайминг был указан исходя из того, что интервал запуска регламентного задания обработки пакетов был установлен 30 секунд.
Подробную информацию о настройке тайминга многопоточной обработки данных можно прочитать в инструкции по эксплуатации конфигурации «Универсальные механизмы: пакеты данных».
Время жизни рабочего ФЗ – указано значение 60 секунд. Данное значение не означает, что пакет данных обязательно будет обрабатываться 60 секунд. Это означает, что по истечении 60 секунд система завершит рабочее фоновое задание, т.к. оно стало иметь признаки «зависания».
Количество параллельных рабочих потоков – мы указали 20 параллельных потоков. Значение здесь необходимо указывать, исходя из характеристик «железа» сервера 1С и СУБД с учетом нагрузки, которую создают пользователи системы.
Также заполним вкладку «Повторная обработка» следующим образом:
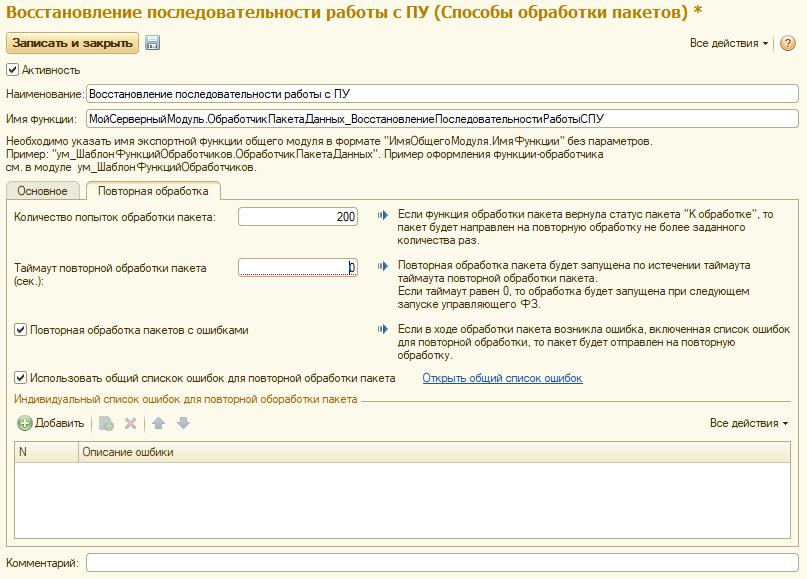
Количество попыток обработки пакета – здесь мы указали значение 200. По сути, этот параметр определяет время, в течение которого система будет пытаться обработать наш пакет данных. Количество попыток (200) * интервал запуска регламентного задания (30 секунд) = 100 минут. Т.е. мы предполагаем, что за 100 минут и за 200 попыток последовательность по данному ключу должна быть восстановлена. Если этого не произойдет – пакету данных будет присвоен статус «Ошибка». Разбор возникшей ситуации должен быть произведен администратором системы.
Таймаут повторной обработки – система должна обрабатывать наш пакет повторно без таймаута в максимальном темпе.
Также мы указали повторную обработку пакетов с ошибками из общего списка ошибок. По умолчанию в этот список входят ошибки блокировки данных, а также ошибки работы кластера серверов 1С.
4. Функция – обработчик пакета данных
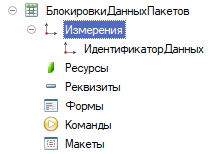 Для того чтобы наша система заработала, нам необходимо создать один новый регистр сведений. Данные в этот регистр сведений мы не будем писать НИКОГДА. Он нужен нам только для того, чтобы организовать блокировки в обработчике пакета данных.
Для того чтобы наша система заработала, нам необходимо создать один новый регистр сведений. Данные в этот регистр сведений мы не будем писать НИКОГДА. Он нужен нам только для того, чтобы организовать блокировки в обработчике пакета данных.
Структура регистра приведена на рисунке. Это не периодический регистр сведений с одним измерением «ИдентификаторДанных» типа Строка(36). Работа с регистром будет описана ниже.
Теперь приступим к самому интересному – обработке пакета данных. Для этого в серверном модуле МойСерверныйМодуль создадим экспортную функцию – обработчик пакета данных.
Функция ОбработчикПакетаДанных_ВосстановлениеПоследовательностиРаботыСПУ(Данные, ПараметрыПакетаДанных, ПараметрыСпособаОбработки) Экспорт
МассивПроведенныхДокументов = Новый Массив; // это будет результат обработки пакета
Пока МассивПроведенныхДокументов.Количество() < 10 Цикл // Зададим размер порции для этого пакета данных
// 1. Получим один первый документ, который нужно провести для восстановления последовательности по ключу пакета
// Для этого в запросе выполним следующие действия:
// 1.1 Получим 1 НАШ ДОКУМЕНТ по НАШЕМУ КЛЮЧУ последовательности, который нужно провести следующим.
// 1.2 Получим перечень ключей последовательности, по которым проходит НАШ ДОКУМЕНТ кроме НАШЕГО КЛЮЧА.
// 1.3 Посмотрим, а не нужно ли подождать восстановления последовательности по другим ключам. Найдем, есть ли по
// другим ключам документы в последовательности, которые нужно провести ранее НАШЕГО ДОКУМЕНТА.
ТекстЗапроса =
"ВЫБРАТЬ ПЕРВЫЕ 1
| РаботаСПриборамиУчета.Регистратор,
| РаботаСПриборамиУчета.Регистратор.ВерсияДанных КАК ВерсияДанных,
| РаботаСПриборамиУчета.Период,
| РаботаСПриборамиУчета.ПриборУчета,
| РаботаСПриборамиУчета.МоментВремени
|ПОМЕСТИТЬ ДокументПоНашемуКлючу
|ИЗ
| Последовательность.РаботаСПриборамиУчета КАК РаботаСПриборамиУчета
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Последовательность.РаботаСПриборамиУчета.Границы КАК РаботаСПриборамиУчетаГраницы
| ПО РаботаСПриборамиУчета.ПриборУчета = РаботаСПриборамиУчетаГраницы.ПриборУчета
| И РаботаСПриборамиУчета.МоментВремени > РаботаСПриборамиУчетаГраницы.МоментВремени
|ГДЕ
| РаботаСПриборамиУчета.ПриборУчета = &ПриборУчета
| И РаботаСПриборамиУчета.Регистратор.Проведен
|
|УПОРЯДОЧИТЬ ПО
| РаботаСПриборамиУчета.МоментВремени
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| РаботаСПриборамиУчета.ПриборУчета
|ПОМЕСТИТЬ КлючиДругихПоследовательностейДокумента
|ИЗ
| ДокументПоНашемуКлючу КАК ДокументПоНашемуКлючу
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Последовательность.РаботаСПриборамиУчета КАК РаботаСПриборамиУчета
| ПО ДокументПоНашемуКлючу.Регистратор = РаботаСПриборамиУчета.Регистратор
| И ДокументПоНашемуКлючу.ПриборУчета <> РаботаСПриборамиУчета.ПриборУчета
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| ДокументПоНашемуКлючу.Регистратор,
| ДокументПоНашемуКлючу.ВерсияДанных
|ИЗ
| ДокументПоНашемуКлючу КАК ДокументПоНашемуКлючу
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| РаботаСПриборамиУчета.ПриборУчета,
| РаботаСПриборамиУчета.Регистратор
|ИЗ
| КлючиДругихПоследовательностейДокумента КАК КлючиДругихПоследовательностейДокумента
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Последовательность.РаботаСПриборамиУчета КАК РаботаСПриборамиУчета
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Последовательность.РаботаСПриборамиУчета.Границы КАК РаботаСПриборамиУчетаГраницы
| ПО РаботаСПриборамиУчета.ПриборУчета = РаботаСПриборамиУчетаГраницы.ПриборУчета
| И РаботаСПриборамиУчета.МоментВремени > РаботаСПриборамиУчетаГраницы.МоментВремени
| ПО КлючиДругихПоследовательностейДокумента.ПриборУчета = РаботаСПриборамиУчета.ПриборУчета,
| ДокументПоНашемуКлючу КАК ДокументПоНашемуКлючу
|ГДЕ
| РаботаСПриборамиУчета.Регистратор.Проведен
| И РаботаСПриборамиУчета.МоментВремени < ДокументПоНашемуКлючу.МоментВремени";
Запрос = Новый Запрос(ТекстЗапроса);
Запрос.УстановитьПараметр("ПриборУчета", Данные.ПриборУчета); // изменерния последовательности
МассивРезультатов = Запрос.ВыполнитьПакет();
РезультатНашДокумент = МассивРезультатов[2];
РезультатДругиеКлючи = МассивРезультатов[3];
// 2. Проверим, возможно последовательность восстановлена
Если РезультатНашДокумент.Пустой() Тогда
РезультатОбработки = Новый Структура;
РезультатОбработки.Вставить("СостояниеПакетаДанных" , Перечисления.ум_СостоянияПакетаДанных.Обработан);
РезультатОбработки.Вставить("Сообщение" , "Проведено " + МассивПроведенныхДокументов.Количество() + " документов (см. результат).
|Последовательность восстановлена!");
РезультатОбработки.Вставить("РезультатОбработки" , МассивПроведенныхДокументов);
Возврат РезультатОбработки;
КонецЕсли;
// 3. Посмотрим, может нужно подождать восстановления других ветвей последовательности
Если НЕ РезультатДругиеКлючи.Пустой() Тогда
РезультатОбработки = Новый Структура;
РезультатОбработки.Вставить("СостояниеПакетаДанных" , Перечисления.ум_СостоянияПакетаДанных.КОбработке);
РезультатОбработки.Вставить("Сообщение" , "Проведено "+МассивПроведенныхДокументов.Количество()+" документов.
|Ожидание восстановления последовательности в смежных ветвях (см. результат).");
РезультатОбработки.Вставить("РезультатОбработки" , РезультатДругиеКлючи.Выгрузить());
Возврат РезультатОбработки;
КонецЕсли;
Выборка = РезультатНашДокумент.Выбрать();
Выборка.Следующий(); // Получим наш документ
// 4. Заблокируем наш документ от проведения в ТОЛЬКО в других пакетах данных.
НачатьТранзакцию();
Блокировка = Новый БлокировкаДанных;
ЭлементБлокировки = Блокировка.Добавить("РегистрСведений.БлокировкиДанныхПакетов");
ЭлементБлокировки.УстановитьЗначение("ИдентификаторДанных", Строка(Выборка.Регистратор.УникальныйИдентификатор()));
ЭлементБлокировки.Режим = РежимБлокировкиДанных.Исключительный;
Блокировка.Заблокировать();
// 5. Проверим не изменили ли документ за время с момента чтения последовательности и установки блокировки данных.
ОбъектДокумент = Выборка.Регистратор.ПолучитьОбъект();
Если НЕ ОбъектДокумент.ВерсияДанных = Выборка.ВерсияДанных Тогда
ОтменитьТранзакцию();
Продолжить;
КонецЕсли;
// 6. Пытаемся провести документ
Попытка
ОбъектДокумент.Записать(РежимЗаписиДокумента.Проведение);
Исключение
ОтменитьТранзакцию();
// Определимся с характером возникшей ошибки
Если ОбъектДокумент.ДополнительныеСвойства.Свойство("ЭтоОшбикаПоследовательности") и ОбъектДокумент.ДополнительныеСвойства.ЭтоОшбикаПоследовательности Тогда
// это ошибка последовательности - остановим обработку порции данных
РезультатОбработки = Новый Структура;
РезультатОбработки.Вставить("СостояниеПакетаДанных" , Перечисления.ум_СостоянияПакетаДанных.Обработан);
РезультатОбработки.Вставить("Сообщение" , "Ошибка восстановления последовательности для документа "+Выборка.Регистратор+"
|"+ОбъектДокумент.ДополнительныеСвойства.ОписаниеОшибкиПоследовательности+"
|Проведено "+МассивПроведенныхДокументов.Количество()+" документов (см. результат).");
РезультатОбработки.Вставить("РезультатОбработки" , МассивПроведенныхДокументов);
Возврат РезультатОбработки;
Иначе
// Это иная ошибка - оставим её для разбора
ВызватьИсключение ОписаниеОшибки();
КонецЕсли;
КонецПопытки;
ЗафиксироватьТранзакцию();
МассивПроведенныхДокументов.Добавить(Выборка.Регистратор);
КонецЦикла;
// 7. Порция данных обработана - завершаем обработку пакета данных
РезультатОбработки = Новый Структура;
РезультатОбработки.Вставить("СостояниеПакетаДанных" , Перечисления.ум_СостоянияПакетаДанных.Обработан);
РезультатОбработки.Вставить("Сообщение" , "Проведено "+МассивПроведенныхДокументов.Количество()+" документов (см. результат).
|Обработка порции данных текущего пакета завершена.");
РезультатОбработки.Вставить("РезультатОбработки" , МассивПроведенныхДокументов);
Возврат РезультатОбработки;
КонецФункции
Эта небольшая функция (150 строк кода с комментариями) выполняет весь объем работ по восстановлению последовательности. В функции мы пытаемся провести документы из последовательности по нашему ключу в нужном порядке. В начале процедуры мы определяем массив:
МассивПроведенныхДокументов = Новый Массив; // это будет результат обработки пакета
В этом массиве хранится информация о проведенных при обработке этого пакета документах.
А здесь мы, по сути, указали размер порции данных, которую обработает данный пакет:
Пока МассивПроведенныхДокументов.Количество() < 10 Цикл // Зададим размер порции для этого пакета данных
В одном пакете мы запланировали проведение не более 10 документов. Требования к размеру порции просты: документов должно быть столько, чтобы фоновое задание обрабатывало их не более времени жизни рабочего фонового задания (60 секунд). При этом нам не нужно, чтобы порция была слишком большой.
При решении прикладных задач размер порции может определяться не количеством документов, а, к примеру, длительностью обработки текущего пакета. Также можно не ограничивать размер порции вовсе, но в этом случае будет тяжело управлять многопоточной обработкой. Придется отказаться от контроля времени жизни рабочего фонового задания (указывается в способе обработки пакетов). Но с другой стороны это максимально повысит производительность нашего алгоритма восстановления последовательности.
Далее мы в цикле выбираем из последовательности по одному документу для проведения, анализируем ситуацию «вокруг» документа и проводим его, если для этого наступили благоприятные условия.
№ 1. Получение следующего документа для проведения
Здесь заложена основная суть работы алгоритма. При помощи простого запроса мы:
- выясняем, какой документ нам нужно провести, чтобы продвинуть последовательность по ключу последовательности данного задания;
- смотрим, не будет ли проведение этого документа преждевременным? Если данный документ двигает последовательность в разрезе других ключей, то нужно убедиться, что последовательности по корреспондирующим ключам восстановлены вплоть до нашего документа.
Данный запрос очень легкий, время его выполнения и нагрузка на север минимальны. В результате выполнения он возвращает 2 таблицы:
- Таблица со следующим документом в последовательности по нашему ключу.
- Таблица документов по корреспондирующим ключам, восстановления последовательности по которым нам нужно дождаться.
№ 2. Проверим, возможно, последовательность восстановлена
Если не был найден следующий документ для восстановления последовательности по нашему ключу, то последовательность восстановлена. В этом случае мы закрываем наше задание на восстановление последовательности – возвращаем структуру результата, в которой говорим, что пакет успешно обработан.
Если документ для проведения найден – производим анализ условий для проведения документа.
№ 3. Посмотрим, может нужно подождать восстановления других ветвей последовательности
Если таблица документов по корреспондирующим ключам не пустая – данную ветвь последовательности восстанавливать преждевременно. Нужно дождаться пока корреспондирующие последовательности будут восстановлены вплоть до нашего документа. Это произойдет (уже происходит в параллельных потоках) при обработке пакетов по этим ключам.
Для того, чтобы наш пакет «подождал» обработку других пакетов, мы завершаем обработку нашего пакета с указанием результирующего статуса «К Обработке». Это означает, что при следующем запуске процедуры обработки пакетов (в нашем случае – раз в 30 секунд), этот пакет будет вновь принят к обработке. С учетом заданных нами параметров многопоточной обработки наш пакет будет повторно принят к обработке не более 200 раз в течение 100 минут.
Если же нам ничего ждать не надо, то приступим к проведению нашего документа.
№ 4. Заблокируем наш документ
Мы выяснили, что наш документ можно проводить, и это приведет к продвижению последовательности. Однако данный документ возможно уже пытается провести процедура обработки другого пакета данных в параллельном фоновом задании (ведь наш документ может двигать последовательность по нескольким ключам).
Для того чтобы избежать лишних действий, наложим блокировку на проведение данного документа ТОЛЬКО в других потоках. Наложить блокировку на документ невозможно, поэтому мы наложим блокировку на уникальный идентификатор данного документа в нашем специальном регистре сведений. Эта операция заблокирует документ для других потоков, но не пользователей.
Мы специально не «оборачиваем» процедуру блокировки в попытку. Если возникнет ошибка блокировки, то она будет обработана механизмом повторной обработки пакетов – по сути пакет подождет, пока блокировка ему будет предоставлена.
№ 5. Сверка версий документа
Мы смогли заблокировать наш документ. Получим объект нашего документа, и сравним версию нашего объекта с версией, которая была актуальна на момент выполнения запроса в п № 1. Ведь пока мы выполняли запрос и анализировали его результат, документ уже мог быть проведен в параллельном фоновом задании или пользователем вручную.
Если данные устарели – мы идем на новый круг цикла – запрашиваем новую актуальную порцию данных.
№ 6. Проведение документа
Мы убедились, что работаем с актуальной версией объекта документа. Теперь мы можем провести документ.
Здесь есть определенное упрощение. Часто типовые конфигурации содержат специальные процедуры для проведения документа только с целью восстановления определённой последовательности. Такие процедуры не проводят документ «целиком», перезаписывая весь объем его движений, а лишь обновляют движения документа только по одному разделу учета, что ускоряет процесс. Такую процедуру легко найти, если посмотреть типовую однопоточную обработку восстановления последовательности. Будет правильней здесь вызывать для нашего документа именно такую специальную процедуру, однако и приведенный выше код также будет работать корректно.
При проведении документа мы обязательно анализируем результаты проведения. Если документ провелся успешно и не возникло логических ошибок при восстановлении последовательности, то мы идем на следующий шаг цикла, добавив этот документ в массив проведенных документов.
Если же при проведении возникла ошибка – мы её анализируем.
Если это логическая ошибка восстановления последовательности, например:
- ввод показания прибора учёта, который не был смонтирован,
- ввод нового показания ПУ, которое меньше предыдущего,
- и пр.,
то мы останавливаем обработку данного пакета. При этом пакет обработан успешно, т.к. последовательность по нашему ключу восстановлена до максимально возможного момента.
При решении прикладных задач ошибки логики могут выглядеть иначе:
- не хватило партий (если мы что-то делаем с остатками на складе),
- нет остатков по взаиморасчетам (если наша последовательность – взаиморасчеты),
- и пр.
Пользователь увидит, что последовательность восстановлена не полностью при анализе отчетов или выполнении других действий. Когда он исправит ситуацию (изменит документы) – будут созданы новые задания, которые «доведут работу» до конца.
В приведенном примере мы исходим из того, что при осуществлении проверок проведения у объекта документа в дополнительных свойствах устанавливается флаг «ЭтоОшбикаПоследовательности», если причиной ошибки проведения была логическая ошибка. В типовых конфигурациях информирование о логической ошибке (нехватке партий или остатков взаиморасчетов) происходит иначе. Может не вызываться исключение, но могут быть иные признаки. Здесь разработчик должен организовать выявление этой ошибки самостоятельно.
Если это иная ошибка, например, синтаксическая ошибка в исполняемых модулях – мы вызываем исключение с описанием этой ошибки. Статус пакета будет автоматически установлен в «Ошибка» и описание этой ошибки будет доступно администратору.
№ 7. Порция данных обработана
Если мы дошли до этого места, значит, последовательность еще не восстановлена, однако порция данных этого пакета уже обработана. Мы завершаем обработку пакета данных, статус пакета устанавливаем «Обработан». Восстановление последовательности по данному ключу будет продолжено в других пакетах, т.к. при перезаписи документов (при обработке этого или других пакетов или работе пользователя) уже было создано новое задание по этому же ключу.
Как это работает
Рассмотрим пример работы алгоритма на простейшем примере. Есть несколько документов, которые участвуют в движении последовательности по двум разным ключам.
ШАГ 1
На первом шаге работы алгоритма будут запущены два рабочих фоновых задания для восстановления последовательности по ключу 1 и 2.

ШАГ 2
После проведения первых документов в каждом ФЗ анализируется ситуация со следующим документом в последовательности. Восстановление последовательности по ключу 1 предполагает проведение документа № 4, что нецелесообразно. Этот документ «задевает» последовательность по ключу 2, которая еще не восстановлена. Как итог – обработка пакета с заданием по ключу 1 завершается.
Фоновое задание по ключу 2 успешно продолжает проводить документы.
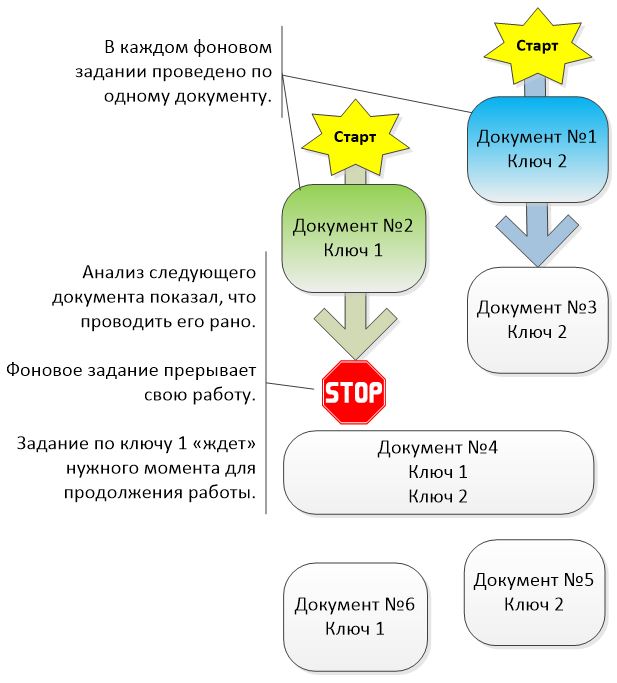
ШАГ 3
Фоновое задание провело документ № 3. Анализ документа № 4 показал, что его можно провести, т.к. последовательность по корреспондирующему ключу 1 восстановлена вплоть до документа № 4. Документ № 4 проводится, продвигая последовательности как по ключу 2, так и по ключу 1.
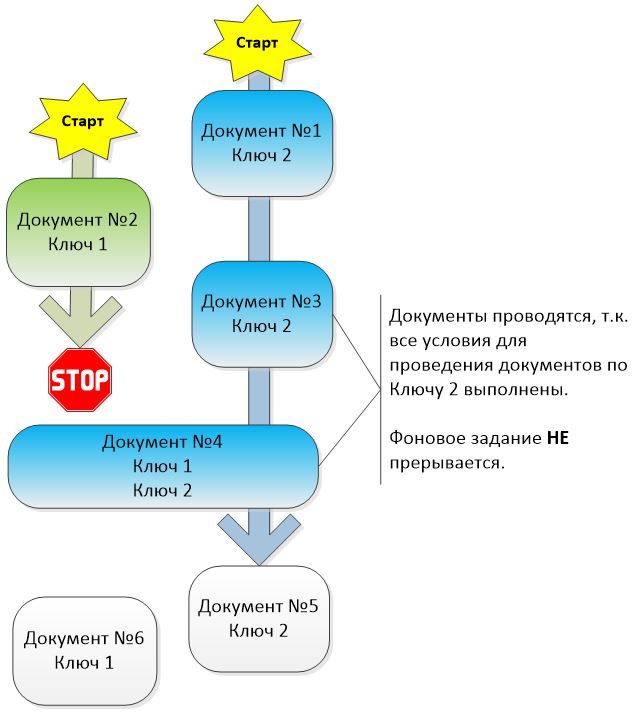
ШАГ 4
Фоновое задание по ключу 2 продолжает свою работу, не прерываясь. В это время по ключу 1 была начата обработка пакета в новом фоновом задании. Восстановление последовательности по ключу 1 будет начато сразу с документа № 6.
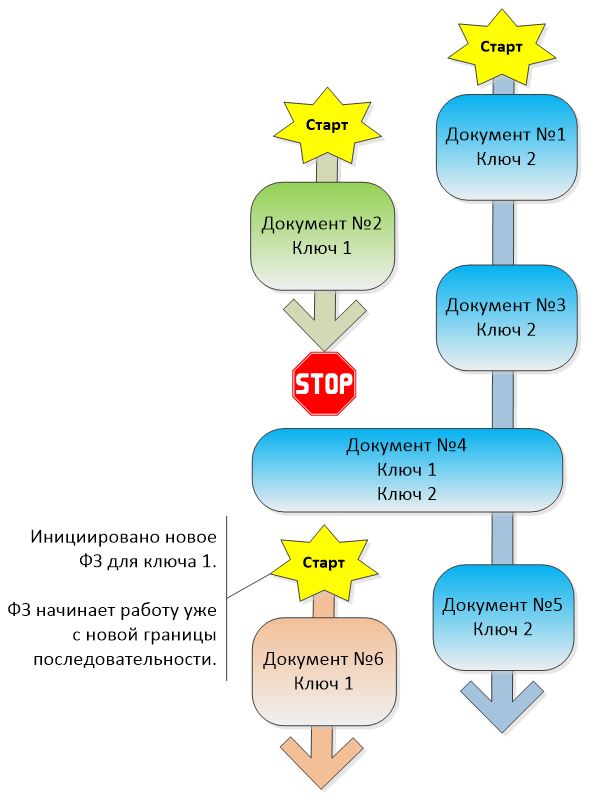
Что получилось в итоге:
- Организовано многопоточное отказоустойчивое восстановление последовательности.
- Все изменения конфигурации не коснулись типовых объектов. Мы практические не усложнили процесс обновления конфигурации.
- Ни в одном месте алгоритма мы не накладываем блокировок на саму последовательность или на любой другой объект, используемый при оперативной работе пользователя.
- Запись документов пользователем и в пакетах данных производится одновременно. Пользователь может увидеть замедление работы системы, но вероятность получения ошибки блокировки данных минимальна.
- Алгоритм самостоятельно адаптируется к изменяющимся первичным данным. Мы не рассчитываем граф проведения документов, который будет регулярно устаревать. Определение действий для каждого задания ведется с учетом актуальной учетной ситуации.
- Инициация процесса восстановления последовательности происходит автоматически по факту совершения пользователем действий в учетной системе.
Ограничения
Данный алгоритм показывает очень хорошую производительность только при выполнении трех условий.
1. Данные в учетной системе должны позволять их многопоточную обработку.
Приведу небольшой пример. Есть проблема проведения складских документов по партиям в организации, у которой:
- есть один склад, по которому идет большая часть движений,
- номенклатурный ряд небольшой, и документы оперируют одними и теми же позициями.
В этой ситуации эффекта от внедрения многопоточного восстановления последовательности не будет, т.к. сами данные не позволяют такую обработку эффективно организовать.
2. Последовательность должна корректно разделять данные на независимые ветви.
Измерения последовательности должны успешно разделять данные в системе учета на разрезы, которые могут быть обработаны независимо.
Рассмотрим ситуацию восстановления последовательности складского учета в организации с множеством складов и различной номенклатуры. Первичные данные однозначно позволяют распараллелить процесс восстановления последовательности (к примеру, по складам). Однако сама последовательность имеет только одно измерение – «Организация». В данной ситуации говорить о многопоточной обработке также не приходится.
3. Нет технологических ограничений многопоточной обработки.
Проведение документов, входящих в последовательность, должно быть организовано таким образом, чтобы не возникало избыточных блокировок. Данное ограничение практически всегда устранимо.
Чаще всего блокировки возникают при записи движений регистров накопления. А точнее при обновлении записей в таблице итогов регистров накопления. Данную проблему легко устранить включением для регистров накопления режима разделения итогов.
 При включении режима разделения итогов нужно организовать регламентное обслуживание базы данных, включающее в себя регулярный пересчет итогов. Для конфигураций 1С, основанных на БСП (почти все современные конфигурации) это уже решенная задача.
При включении режима разделения итогов нужно организовать регламентное обслуживание базы данных, включающее в себя регулярный пересчет итогов. Для конфигураций 1С, основанных на БСП (почти все современные конфигурации) это уже решенная задача.
Если разделения итогов оказалось мало, нужно произвести рефакторинг процедур проведения документа.
Вступайте в нашу телеграмм-группу Инфостарт