Все, о чем я буду рассказывать в этом докладе, отражено на этой диаграмме – здесь показано, что представляет собой DevOps с точки зрения процесса. Эту картинку придумали не мы, её можно найти в Google по ключевому слову DevOps. И я сейчас попытаюсь провести вас по всем этапам этого процесса.
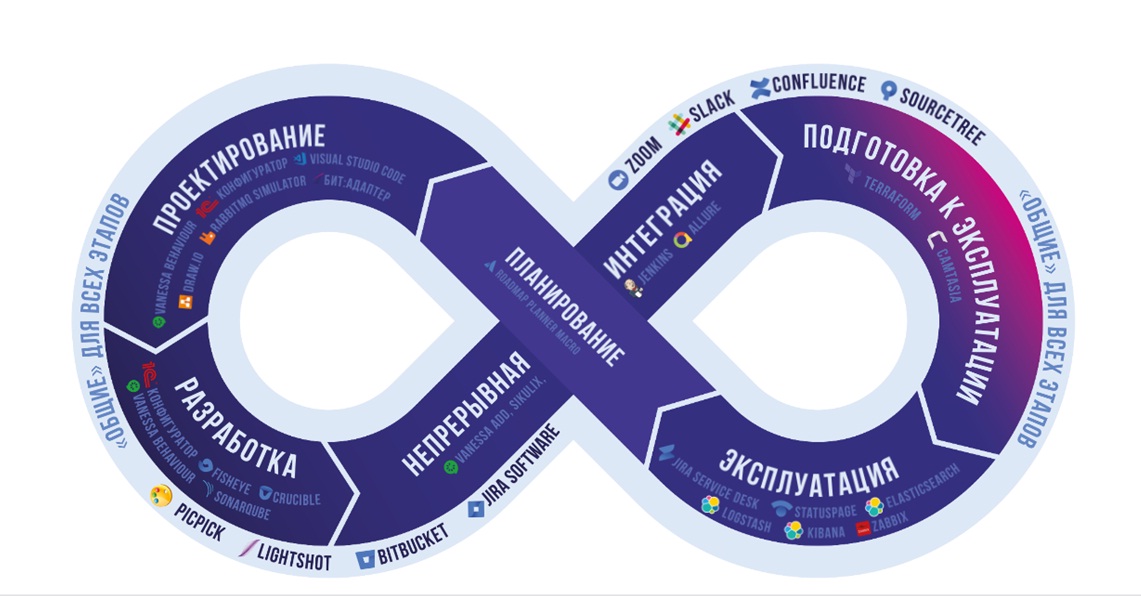
Первое, на что надо обратить внимание при рассмотрении этой диаграммы – это то, что в принципе нельзя сказать: где процесс начинается, и где он заканчивается. Мы традиционно начнем с планирования, но нужно понимать, что в реальной практике одного этапа планирования обычно не хватает, перепланировать приходится по многу раз – это процесс, который постоянно идет по циклу.
Также по поводу планирования – сразу скажу, что мне повезло меньше, чем коллегам, которые выступали на этой секции до меня и рассказывали, что они при проектировании новой системы все обследовали, продумали все внутренние взаимосвязи и дальше пошли, не ошибаясь. У нас с планированием так никогда не получалось, и у других коллег на реальных проектах я тоже не видел, чтобы все было настолько гладко. Но, конечно, круто, если у кого-то это получается.
Сравнение подходов – Waterfall vs Scrum.
Первый вопрос, который я хочу затронуть, это – «Какой подход правильнее применять на проекте?»

Основная идея подхода Waterfall (водопад) – это то, что мы:
- Сначала обследуем, проектируем;
- Потом разрабатываем, с предположением, что мы все верно спроектировали, ни разу нигде и никогда не ошибившись;
- И дальше все сразу запускаем в эксплуатацию.
В реальной жизни это, конечно, немного не так. На любом проекте при запуске в эксплуатацию мы, так или иначе, сталкиваемся с суровой реальностью, и неизбежно начинается перепланирование, перепроектирование, дополнительная разработка и т.д. Но, тем не менее, до этапа эксплуатации вполне можно себе представить проект, который именно так и идет.
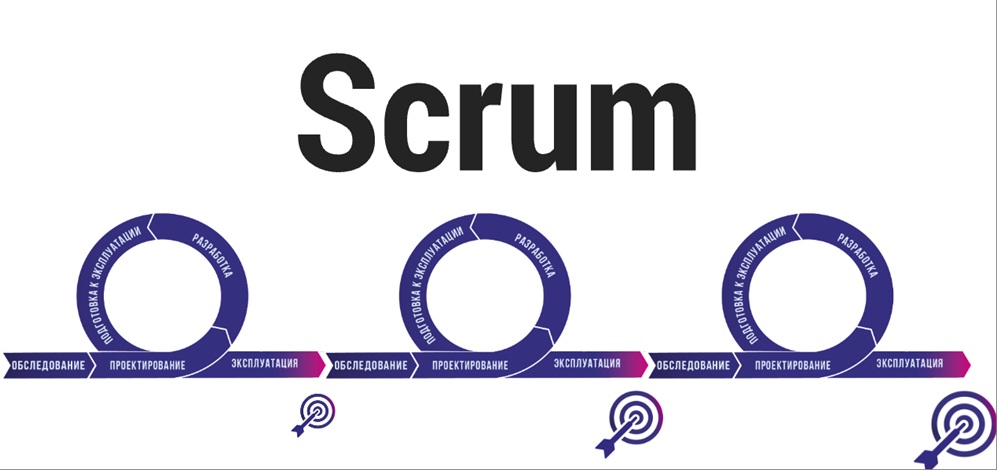
В подходе Scrum мы видим все те же самые виды работ, но они происходят циклично, по спирали.
Подчеркиваю, что Scrum – это не та методология, которую все ищут для того, чтобы что-то сделать, не проектируя систему. Или что-то сделать, не думая. Думать в Scrum приходится больше. Например, учитывая, что консультанты во франчайзи работают в среднем около 1.5 лет, на этапе обследования большого проекта, который будет длиться 2 года, ты можешь делать самые смелые предположения о том, как будут «выкручиваться» твои коллеги на этапе эксплуатации, потому что это будешь точно не ты. Но если мы говорим про Scrum, то у тебя есть, по сути, только 2 недели, спустя которые, независимо от того, прав ты был или ошибался, все узнают истину, включая тебя. По большому счету, это способ, чтобы проектная команда и отвечала за то, что она делает, и проверяла на практике все гипотезы, которые возникают.

Когда правильнее применять водопадный подход? Я считаю, что есть два условия, при одновременном наличии которых он нужен.
- Первое условие – это когда готовый продукт проекта изменить очень сложно (или даже невозможно).

Например, программное обеспечение бортового компьютера космического аппарата Аполлон. Здесь на слайде показано не само устройство, а макет его схемы. Если кто читал, то при проектировании этого ПЗУ использовался узелковый метод записи с ферритовыми кольцами, ненамного отличающийся от того, которым пользовались в своей письменности племена инков. Если в этом программном коде вы где-нибудь в середине найдете баг, то исправить его будет действительно сложно – даже на земле. Чтобы его переделать, нужно будет все расплести и заплести заново. На YouTube есть масса фильмов о том, как разрабатывалось данное программное обеспечение – там на магнитофонной ленте была записана программа для управления, которая в нужном месте позиционировала иглу, чтобы девушки, которые все это плели, в этом месте продевали провод через кольцо.
Здесь по Agile пойти не получится. Что бы вы ни делали, рефакторинг (быстрый и дешевый, во всяком случае) здесь невозможен.

И, конечно, по «водопадной модели» разрабатывается большинство крупных объектов реального мира (их часто приводят в качестве аналогии при проектировании программного обеспечения) – это строительство зданий, самолеты, подводные лодки и т.д.
- Второе условие, при котором «водопадная модель» работает – это когда проект имеет относительно низкую сложность, когда команда действительно с первого раза имеет шанс, хорошо напрягшись и используя свой опыт, IQ и смекалку, спроектировать систему в целом правильно.

А если система сложная и превышает возможности проектной команды, то спроектировать ее с первого раза не получится. Все сложные проекты, как бы формально они не управлялись – это всегда итерационный, эволюционный подход – мы сделали, проверили гипотезу, не получилось, что-то переделали, проверили еще раз.
Итак, есть два условия, когда нужно применять Scrum:
- Когда готовый продукт проекта можно относительно быстро и дешево изменить.
- И второе условие – это высокая сложность проекта. Если проект достаточно сложный, который невозможно реализовать с первого раза в силу ряда факторов (например, слишком много неизвестных, или слишком сложные зависимости между разными факторами), тогда это эволюционный, итеративный подход, именно тот, который применяет окружающий нас мир – живая природа и эволюция.

Почему сейчас подход Scrum применяется все чаще? Основная причина – это то, что мир изменился. Когда-то для разработки программного обеспечения нужно было исписать много бумаги, чтобы потом было меньше итераций – они все равно будут, но их будет меньше. Да, это дорого, но мы понимаем, что переделывать еще дороже.
Сейчас ситуация другая – самый дешевый способ проверить гипотезу – это проверить гипотезу. Берете софт, внедряете в реальную жизнь, смотрите результат. Поскольку инкремент у вас за две недели будет небольшой, то глобально вы ничего не сломаете – вы просто таким образом проектируете систему.
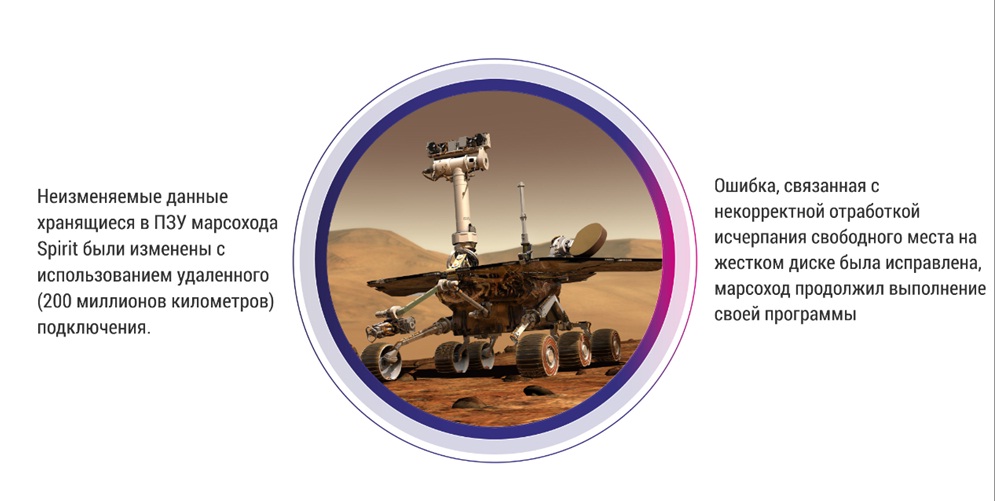
В качестве примера эффективного применения Scrum можно привести доработку программного обеспечения для управления марсоходом Spirit. Там была интересная ошибка. Марсоход находился на расстоянии 200 миллионов километров от Земли, и в его ПЗУ был баг. Но администраторы с использованием удаленного подключения на расстоянии 200 миллионов километров смогли изменить данные, которые хранятся в ПЗУ марсохода, и он продолжил выполнение своей миссии.

На слайде показано, как выглядит устройство, для которого потребовалась эта перепрошивка – здесь 3 Мб памяти, оно реально маленькое. Однако, 3Мб памяти – это в 45 раз больше, чем та память, которая была в ПЗУ космического аппарата Аполлон. Если бы на Аполлоне нужно было бы 3Мб памяти, то узелковое письмо заняло бы 1,2 м3 по сравнению с этой маленькой пластинкой, которая к тому же, перезаписывается, и которую нет проблем отрефакторить даже на большом расстоянии от Земли. К счастью (или, к сожалению) мы на Марс никаких программ на 1С не запускаем, поэтому нам внести изменения в наш код проще. У нас нет проблем с большим пингом на 200 миллионов километров.

Есть ли случаи, когда нельзя применять Scrum?
Его нельзя применять на тех проектах, когда заказчик не заинтересован в том, чтобы что-то запустить или улучшить. Если у заказчика нет такой цели (а это часто бывает, особенно с государственными заказчиками и крупными холдингами, когда им просто пришла разнарядка что-то внедрить) – они внедряют, но им все равно, как запустится система, и как она будет работать. Они просто формально выполняют то распоряжение, которое есть.

Когда мы пытаемся применять Scrum на таких проектах, мы получаем систему Шрёдингера, которая эксплуатируется и не эксплуатируется одновременно.

В виде вымышленной истории расскажу об одном таком проекте. На нем нам удалось запустить систему в течение двух месяцев, причем, после запуска в ней ежедневно работали сотни пользователей в течение полугода. Тем не менее, заказчик упорно утверждал, что система не введена в эксплуатацию. Мы получили классическую ситуацию, когда система и работает и не работает одновременно.
Когда мы показывали заказчику, что системой пользуются, что в нее заходят пользователи – он утверждал, что это не важно, потому что акта ввода в эксплуатацию подписано не было.
- Ну, вот же, есть акт – подпишите.
- Его нельзя подписать, нам нужно, чтобы у вас был протокол тестирования.
- Так вот же, наши тесты, отчеты о тестировании, все интерактивно.
- Нет, так не пойдет, они не согласованы.
- Так давайте мы все протоколы составим, и вы их подпишите.
- Нет, так нельзя, нам нужно ТЗ.
А ТЗ не было из-за того, что проект был сделан по Scrum.
Там возникло недопонимание, суть которого в том, что холдинг заказчика (несколько десятков заводов) решил внедрить систему управления ИТ-проектами, но для него была проблема написать ТЗ. А тут он прочитал, что в Scrum ТЗ не нужно и решил, что это ему подходит. Этапы проекта стали называться спринтами, и мы, применив некоторые лайфхаки, смогли в течение первых двух месяцев ввести систему в опытную эксплуатацию (не просто для целей тестирования, а именно для того, чтобы в реальной жизни приносить реальную ценность). Но дальше все уперлось. В итоге, не смотря на то, что заказчику изначально говорили, что ТЗ не будет написано, его холдинг без согласованного ТЗ принять работу не согласился.
Поэтому в таких случаях, когда заказчику не нужен результат, применять Scrum не стоит, применяйте что-нибудь другое, или вообще не работайте. Это каждый выбирает для себя, конечно.
Этапы и инструменты DevOps
Планирование

От введения перехожу к следующей части. Теперь моя цель – показать вам на реальных примерах в нашей системе, как мы работаем и какие инструменты используем.
Дорожная карта
Первый инструмент – это дорожная карта, с нее мы начинаем планирование.
Для создания дорожных карт мы используем плагин в своей Wiki-системе Confluence.
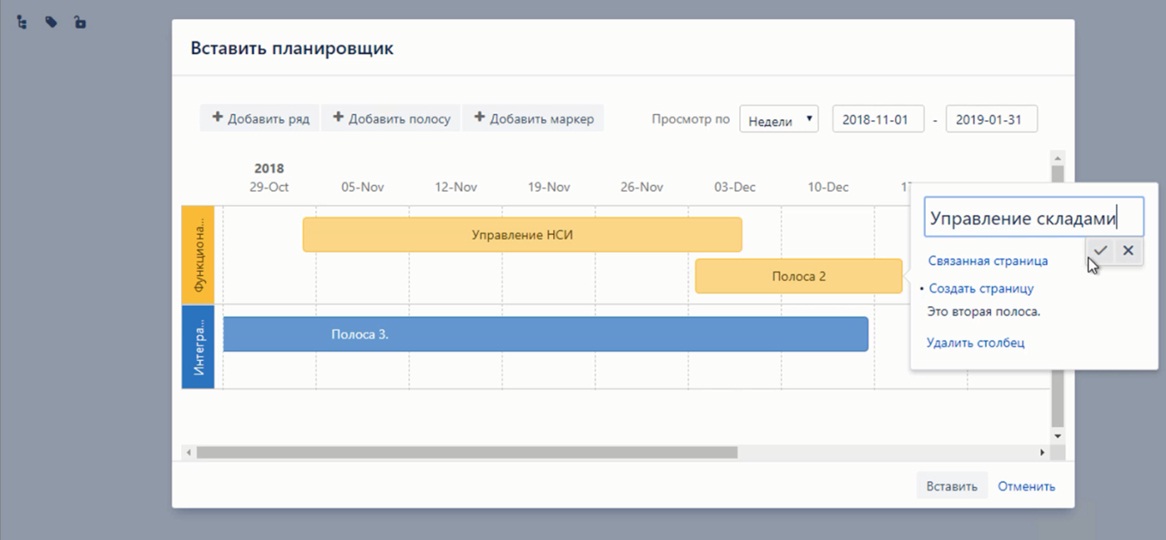
Дорожная карта – это общий вид на проект сверху: что, когда мы будем делать, какие блоки, в какое время будут запускаться. Надо понимать, что мы не испытываем иллюзий, не считаем, что с первого раза угадаем все с точностью до дня и времени суток. Тем не менее, с помощью дорожной карты мы можем на каждый этап проекта построить наши планы и бюджет.
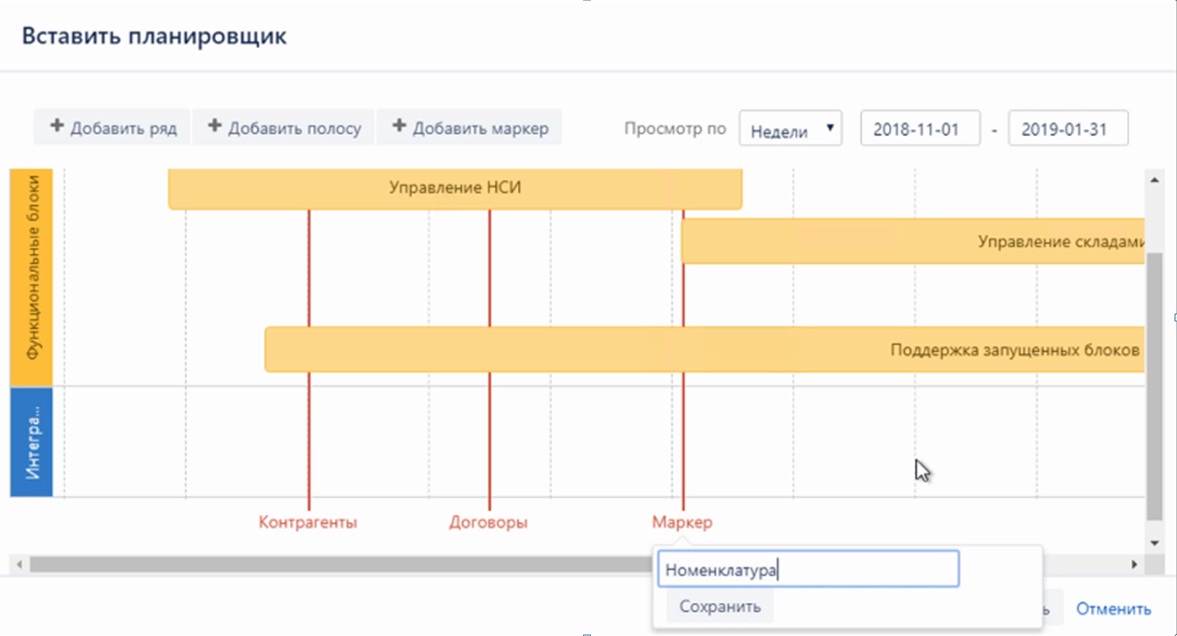
Сейчас спрашивают, с чего начинать, когда нужно «кусочно» запустить систему? Ответ – в любой непонятной ситуации запускайте НСИ, она точно потребуется. Потому что в любом случае будет ситуация, когда часть блоков уже запущена на новой платформе, а часть работает по-старому. Не важно, что это – 1С, Axapta, SAP, самописная конфигурация или программа на Delphi или FoxPro. В любом случае, между старой и новой системой будет нужен обмен, и пока вы не сделаете единую НСИ, вы этот обмен не запустите. Как только мы запускаем единую НСИ – и у нас, и у заказчика сразу исчезают иллюзии относительно чистоты и структуры этих справочников, относительно того, что их реквизиты осмысленно заполнены, нет дублей и т.д.
Ежедневный Scrum
Следующий этап с точки зрения планирования – это ежедневный Scrum. Он у нас проходит в двух режимах.
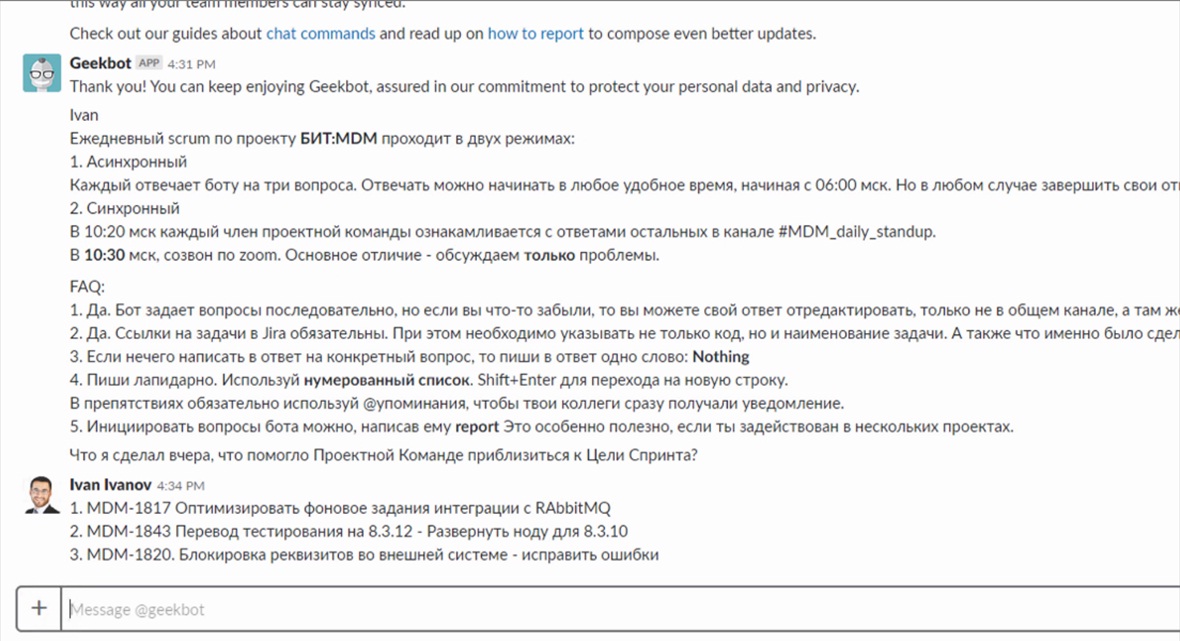
Первый режим – асинхронный. Для этой цели в Slack есть специально обученный бот, который нравится мне тем, что никогда не болеет и всегда делает то, что говорят. Если в какое-то время должен случиться стендап – он случается. В асинхронном режиме бот каждому из участников проектной команды задает три сакраментальных вопроса и, более того, эти вопросы повторяет до тех пор, пока человек не ответит. Обычно мы настраиваем бота, чтобы он начал опрашивать участников проектной команды за четыре часа до начала стендапа, чтобы каждый в комфортном режиме смог ответить на эти вопросы.
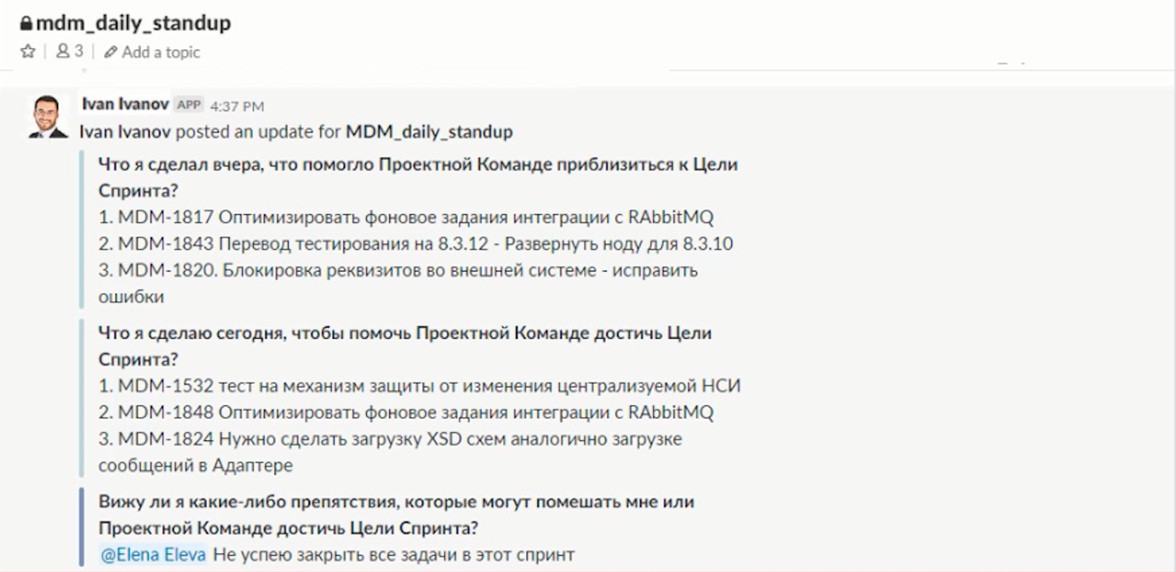
И потом, за 10 минут до начала совещания, в единый канал публикуется отчет бота – в нем каждый участник проектной команды может увидеть, кто, что отвечал, у кого какие препятствия для работы есть – все это можно заранее проанализировать.
Дальше идет синхронная часть – это уже живой диалог (как правило, видеоконференция Zoom) между участниками команды, которые у нас являются удаленными разработчиками.
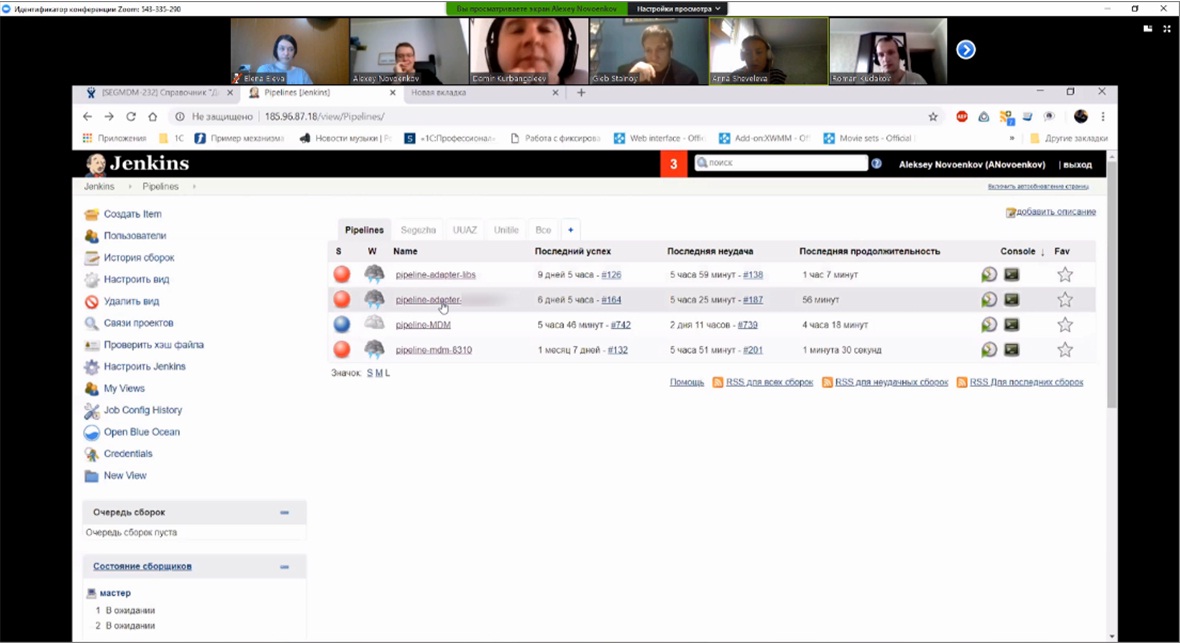
Обычно мы начинаем с разбора логов нашего Jenkins – для проектирования мы используем BDD-тесты, которые позволяют в автоматическом режиме проверять, не упала ли конфигурация.
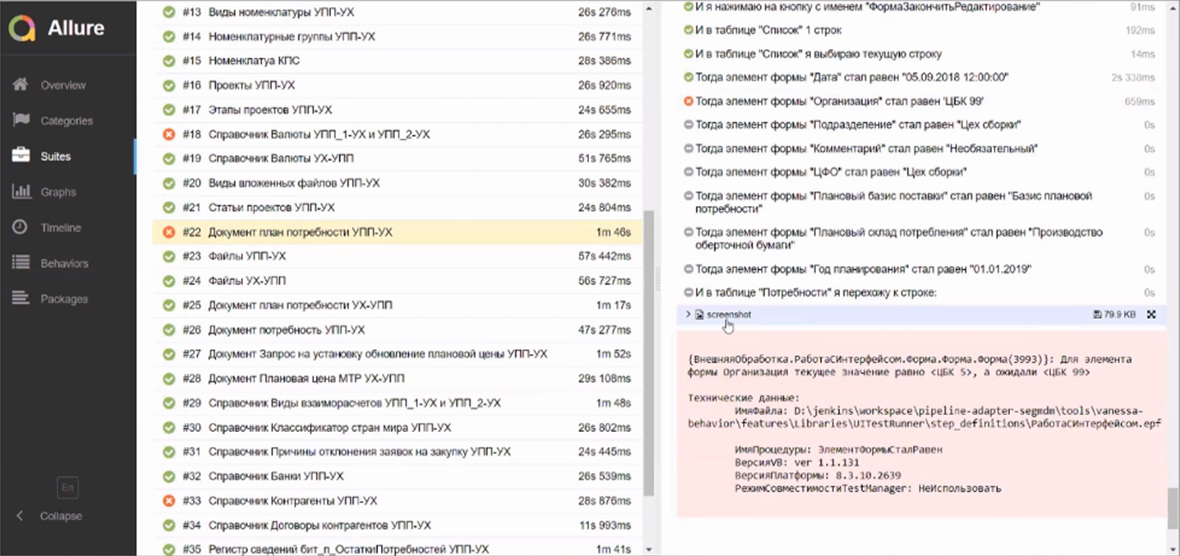
С помощью отчета Allure можно увидеть, какой из тестов упал – и даже проанализировать, на каких частях постановки задачи алгоритм не сработал. Более того, в момент падения сохраняется скриншот, который также можно проанализировать.
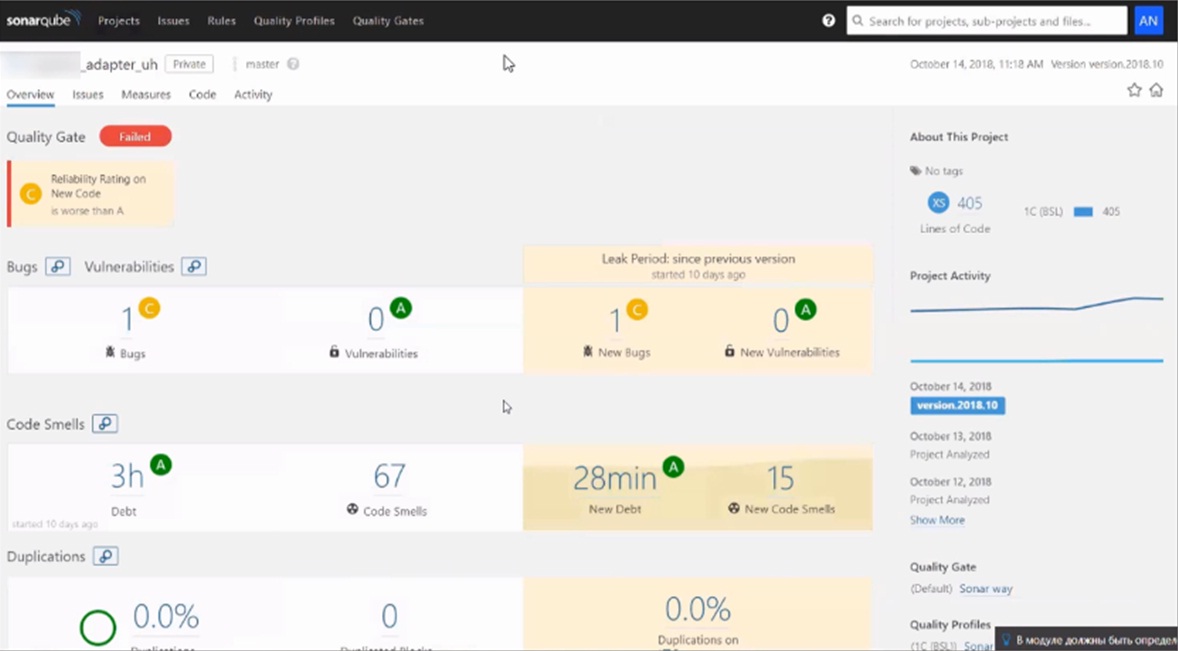
Далее мы смотрим результаты работы Sonar Cube – это анализ качества кода. В этом инструменте наглядно видно, что изменилось по сравнению с предыдущим днем.
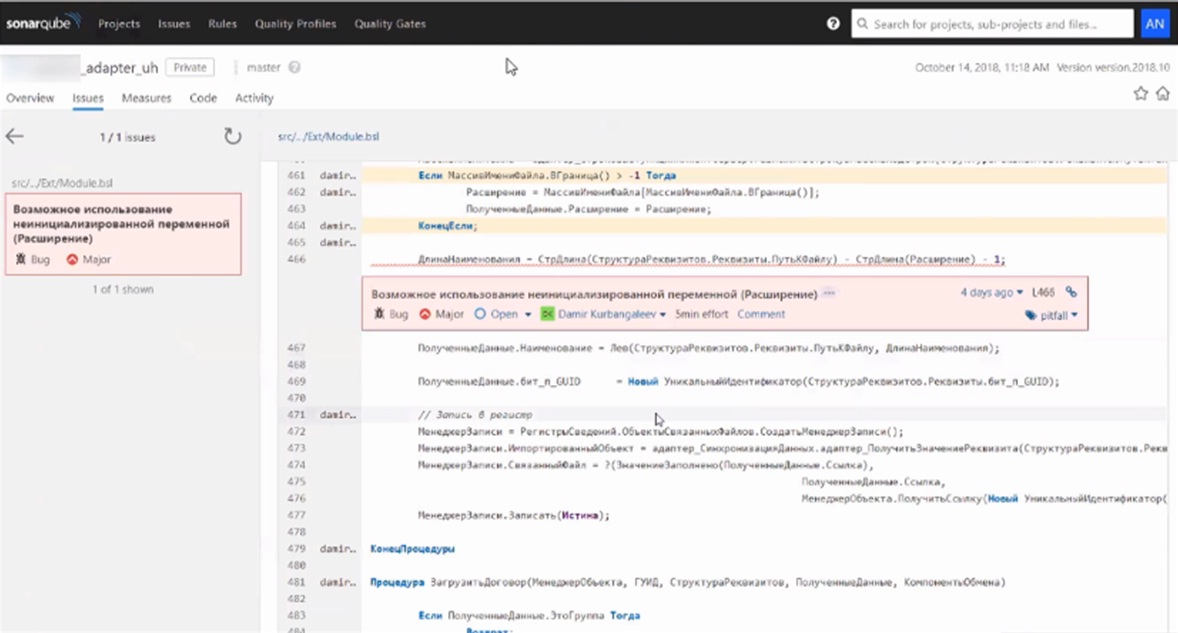
Можно сразу определить «героев» – понять, кто, какую ошибку допустил. Это сильно повышает качество кода и позволяет избежать совсем глупых ошибок.
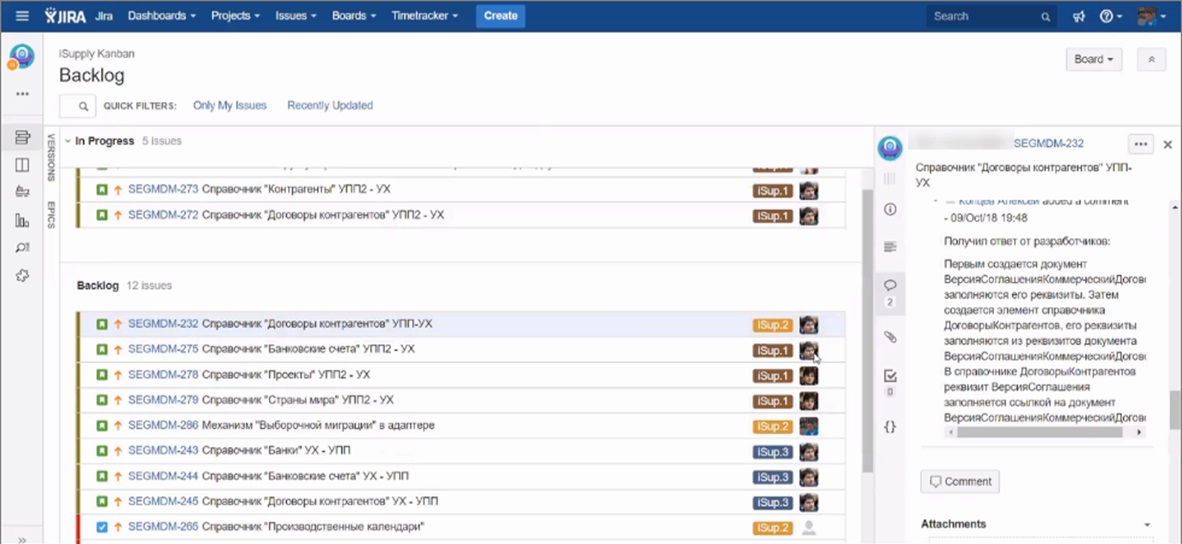
Дальше идет рассмотрение Scrum-доски, где обозначено, кто, что сейчас делает. И в результате происходит перепланирование задач – это всем понятные и привычные вещи, которые мы делаем всегда, даже не в Scrum.
Проектирование

Переходим к проектированию.
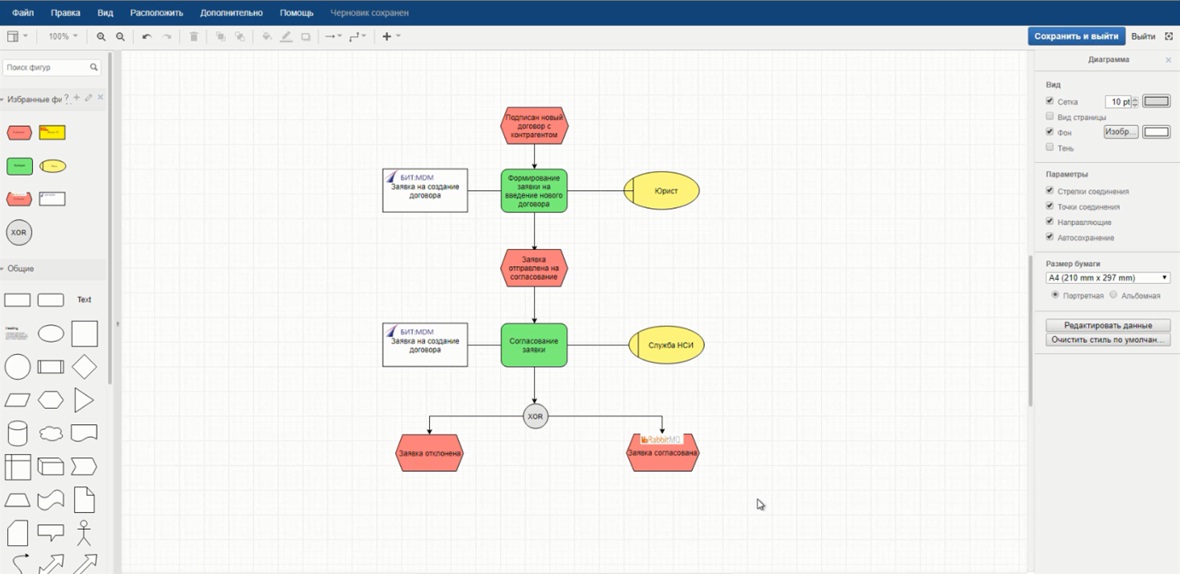
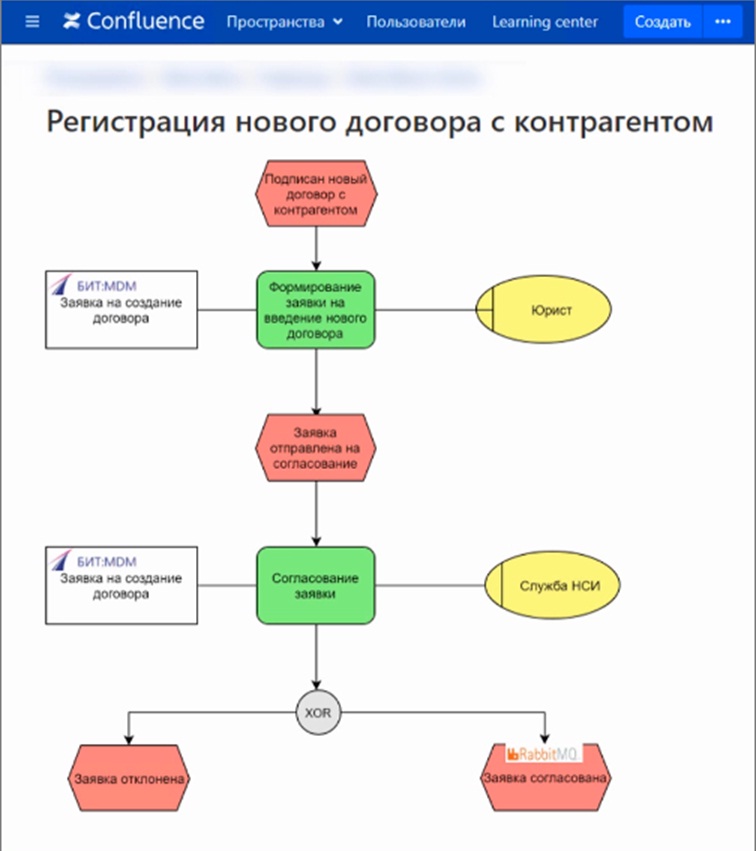
Проектирование у нас начинается просто – после того, как есть дорожная карта, мы для каждого ее блока описываем бизнес-процесс и делаем это в той же самой системе Confluence – используется плагин draw.io. Схема строится так же, как и в Visio, только ее версионирование происходит вместе со статьей. Это чрезвычайно удобно – у тебя всегда есть последняя версия документации, и никакие файлики на Google Disk загружать не нужно. Кроме того, в Wiki-системе Confluence мы можем реализовать четкую перелинковку между статьями, а также связь с задачами Jira.
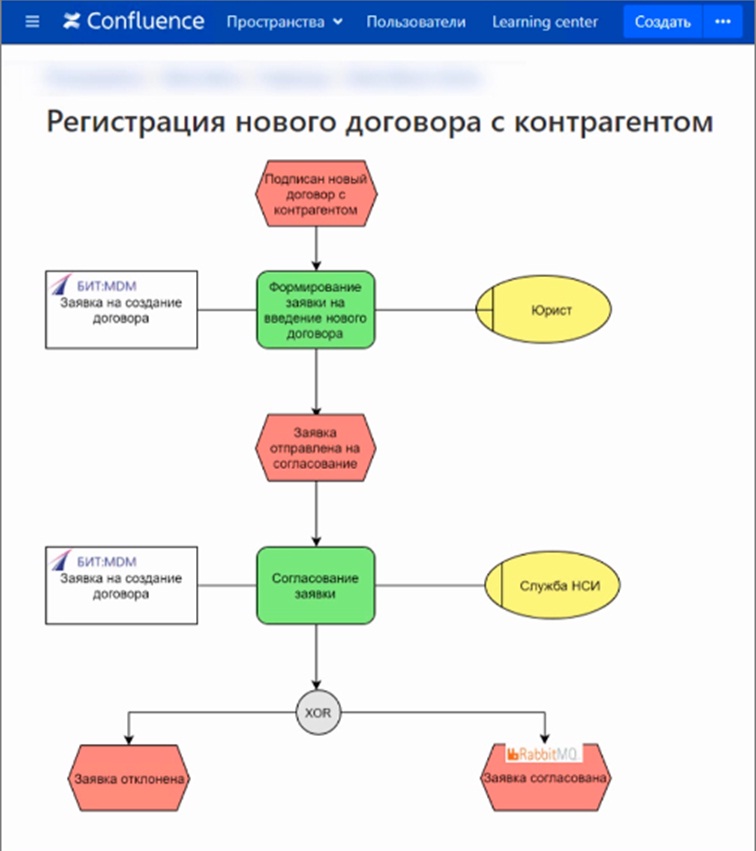
Обратите внимание на формат описания – это eEPC (Extended Event Driven Process Chain– поток процессов, управляемый событиями), мы его используем повсеместно. С помощью этих диаграмм мы описываем, какие функции, какой ролью пользователя выполняются. Такая архитектура позволяет описать события не только с точки зрения бизнеса, но и с точки зрения программной логики. В частности, здесь на диаграмме вы можете увидеть надпись RabbitMQ – это тот инструмент, брокер сообщений, который мы используем для обмена.

Основной вопрос, который задают приверженцы линейного подхода диаграммы Ганта в «каскаде» – это «А как же архитектура?».
Архитектуру надо спланировать в любом случае, иначе все будет плохо. И, в принципе, несмотря на то, что официального определения ИТ-архитектуры нет, есть много определений, которые я считаю подходящими. Здесь я привел два, которые мне нравятся.
Архитектура – это очень важная вещь (что бы это ни было).
ИТ-архитектура – это те решения, которые одновременно важны и которые трудно изменить.
Исходя из этих определений, мы в своих решениях стараемся быть гибкими и избегаем важных решений, которые не могут быть изменены.

Мы используем подход к проектированию ИТ-систем, который позволяет быстро и дешево изменять ранее внедренные ИТ-системы – это т.н. «эволюционная архитектура». Для более подробного изучения этого подхода есть две книги, которые я рекомендую.
- Первая книга переведена на русский язык, вышла достаточно давно, и ее точно стоит прочитать. Она называется «Создание микросервисов», но там не только и не столько про микросервисы.
- Вторую книгу, «Построение эволюционной архитектуры», я на русском языке не нашел, но она еще более интересна. Правда, некоторые затронутые там проблемы с точки зрения 1С-ника не совсем актуальны. Например, целая глава посвящена разбору ситуации, когда бизнес-пользователи ругаются на то, что система по 200 раз на дню меняется, и просят, чтобы изменения были не такими частыми – в качестве решения предлагается собирать релизы, а не делать Continuous Deployment. Я не думаю, что эта проблема скоро станет актуальной в мире 1С, но в любом случае, это интересно узнать с точки зрения развития. А все остальные проблемы, затронутые в книге, в принципе, абсолютно для нас актуальны.
Разработка

Следующий этап – это разработка.
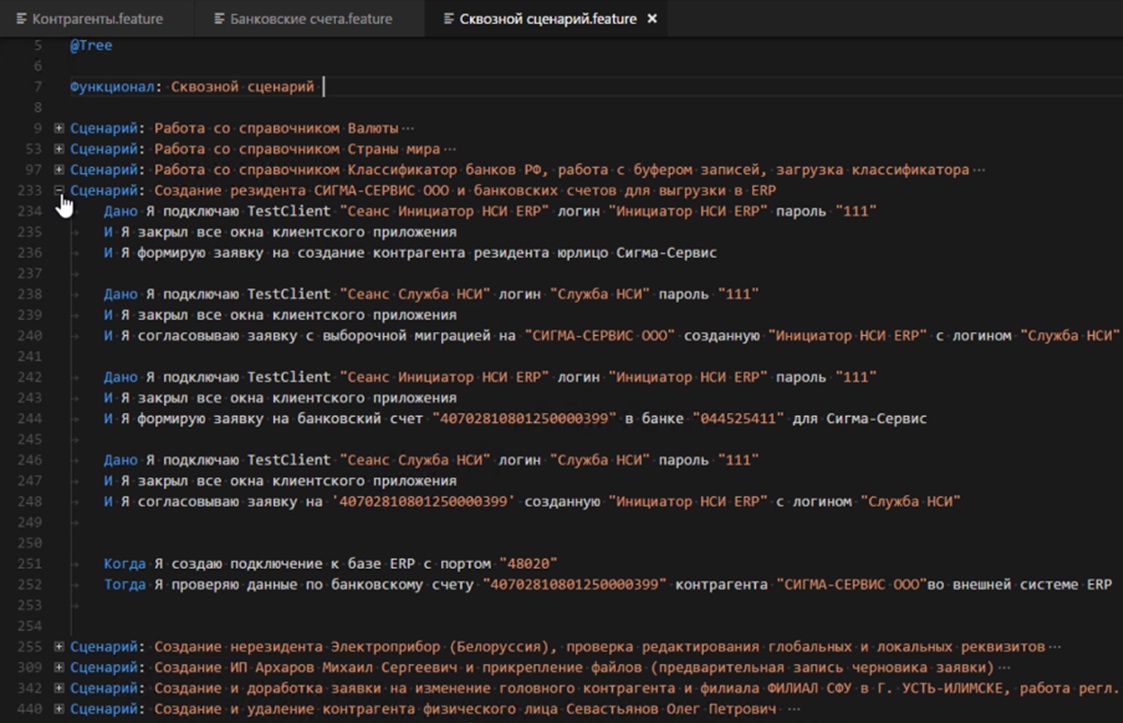
Вот так выглядит постановка задачи на языке Gherkin. Мы описываем сценарии пользовательского поведения, которые, с одной стороны, понятны бизнес-консультанту (аналитику), с другой стороны, понятны пользователям, и, самое главное, они понятны программе.
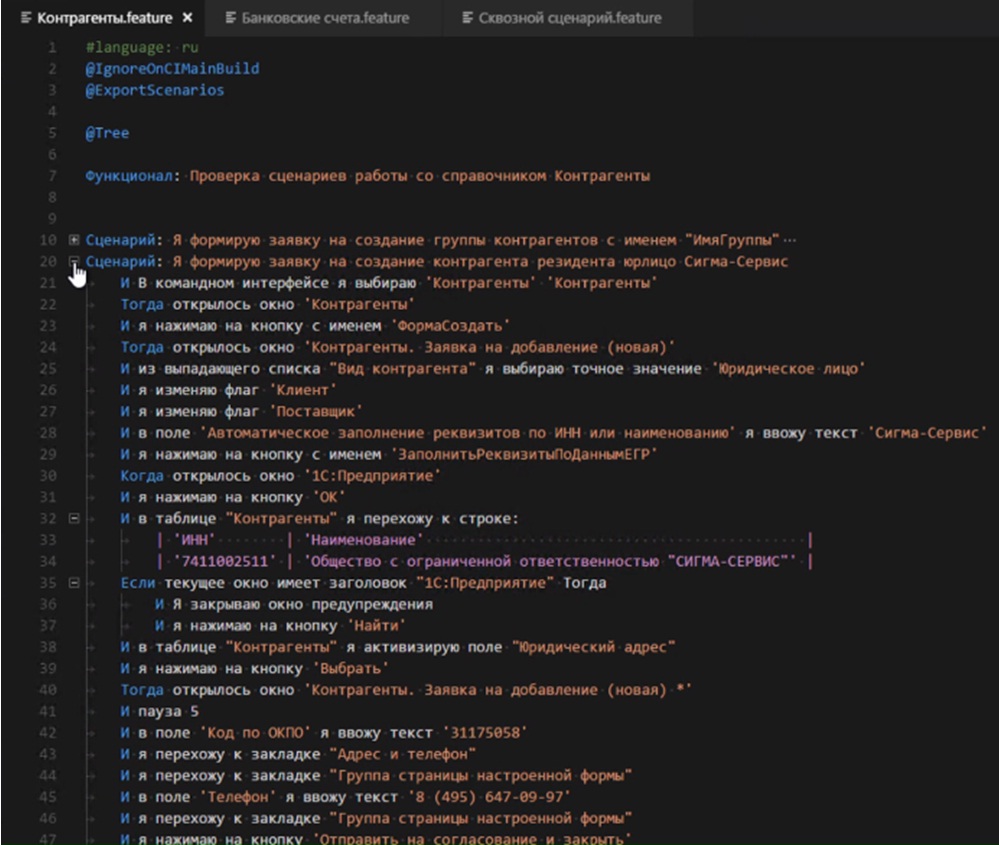
В отличие от обычного ТЗ, с помощью этой постановки мы автоматически валидируем тот код, который делаем. Мы сделали постановку, ее согласовали, и нам не нужен отдел тестирования – система сама себя тестирует и выдает информацию о том, где есть несоответствие между постановкой и программным кодом.
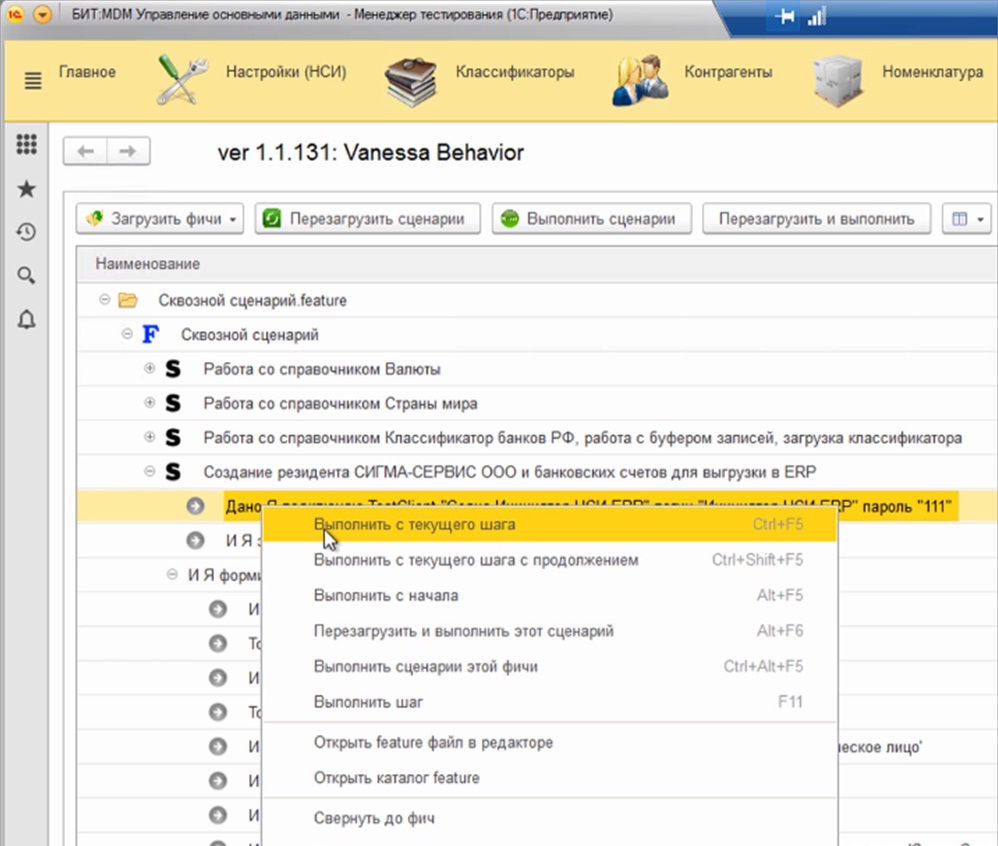
Для запуска тестирования мы запускаем основную конфигурацию в режиме менеджера тестирования, в ней открываем обработку Vanessa Behavior и загружаем в нее сценарии пользовательского поведения (либо в виде каталога с тестами, либо в виде сводного файла сценария).

При запуске выбранного сценария, по мере прохождения шагов, начинают запускаться подчиненные системы в режиме клиента тестирования – заполняются окна, проводятся документы и проверяются результаты – в отчетах, в диалоговых окнах, в связанных системах.
Здесь, например, мы тестируем функциональность нашей MDM-системы, которая отвечает за централизованное управление НСИ, и нам нужно проверить, что элемент справочника, который мы в ней завели, оперативно попадает в другую внешнюю систему. Поэтому мы подключаемся к этой внешней системе и проверяем, что элемент справочника туда доехал, и в нем заполнились те реквизиты, которые должны были заполниться и не заполнились те, которые не должны.
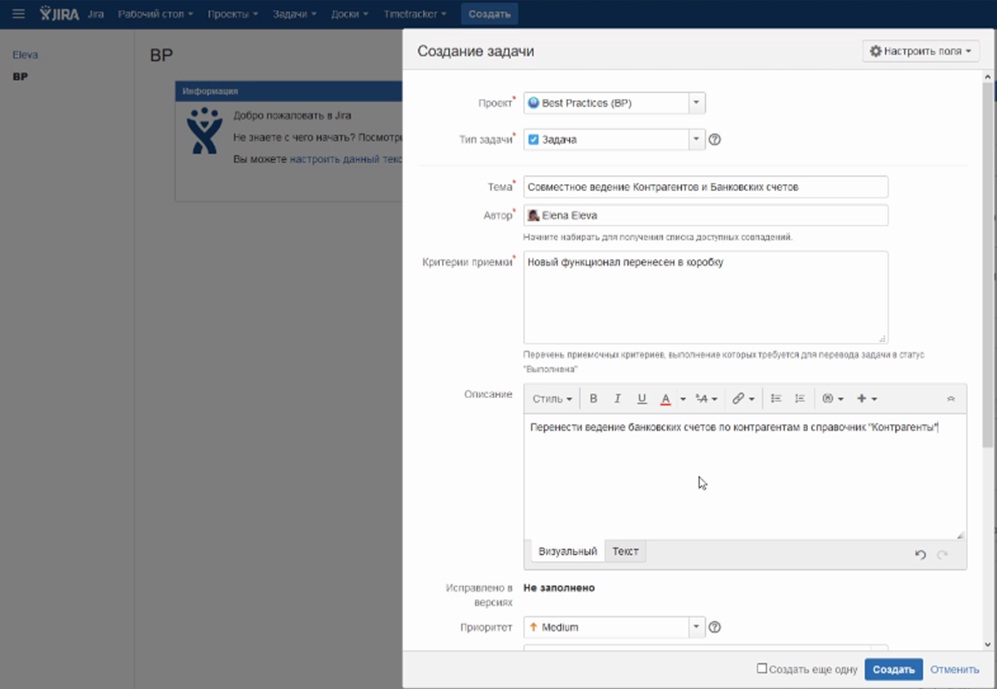
Здесь показывается, как мы работаем в Jira. Для каждой задачи в Jira можно создать отдельную ветку на Git-сервере (у нас это BitBucket).
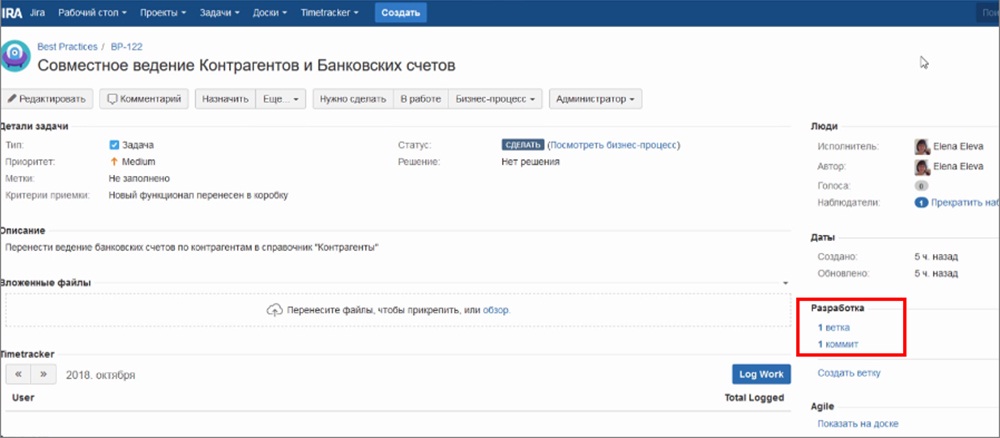
А при разработке (пользовательских сценариев или кода конфигурации) к этой ветке можно привязать коммиты, связанные с задачей. Таким образом, каждый коммит может быть связан с конкретной задачей.
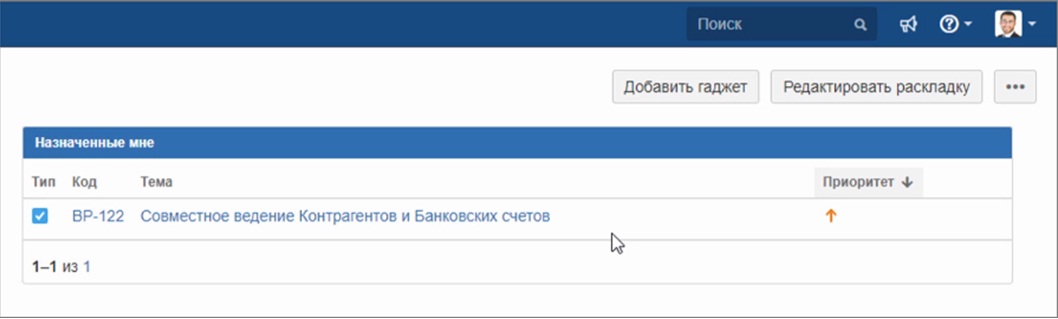
Получив задачу в Jira, исполнитель может сразу увидеть связанные с ней правки пользовательских сценариев, или даже реального ТЗ, почитать переписку. Все то же самое происходит с точки зрения кода. Так как код – это тоже текст, то можно посмотреть, какой код менялся в конфигурации – причем, посмотреть в режиме сравнения. Все это позволяет делать Git.
Переписку по задаче можно прочитать не только в Jira, но и в Slack при оперативном общении, можно посмотреть, в каких статьях Wiki-системы упоминается эта задача (например, если при ее реализации используются какие-то особенно сложные алгоритмы). Этот комплекс инструментов очень сильно упрощает поддержку и изменение системы – мы не боимся рефакторить. При рефакторинге система по-любому упадет, но, в отличие от традиционного подхода, мы знаем, в каком месте она упадет, а значит, сможем это оперативно исправить. Мы не ждем, пока пользователи нам сами скажут, что наша система не работает.
Непрерывная интеграция

Чтобы все это работало в автоматическом режиме, мы используем Jenkins – это сервер тестирования, который помогает нам автоматически запускать сборки.
У нас есть ночные сборки.
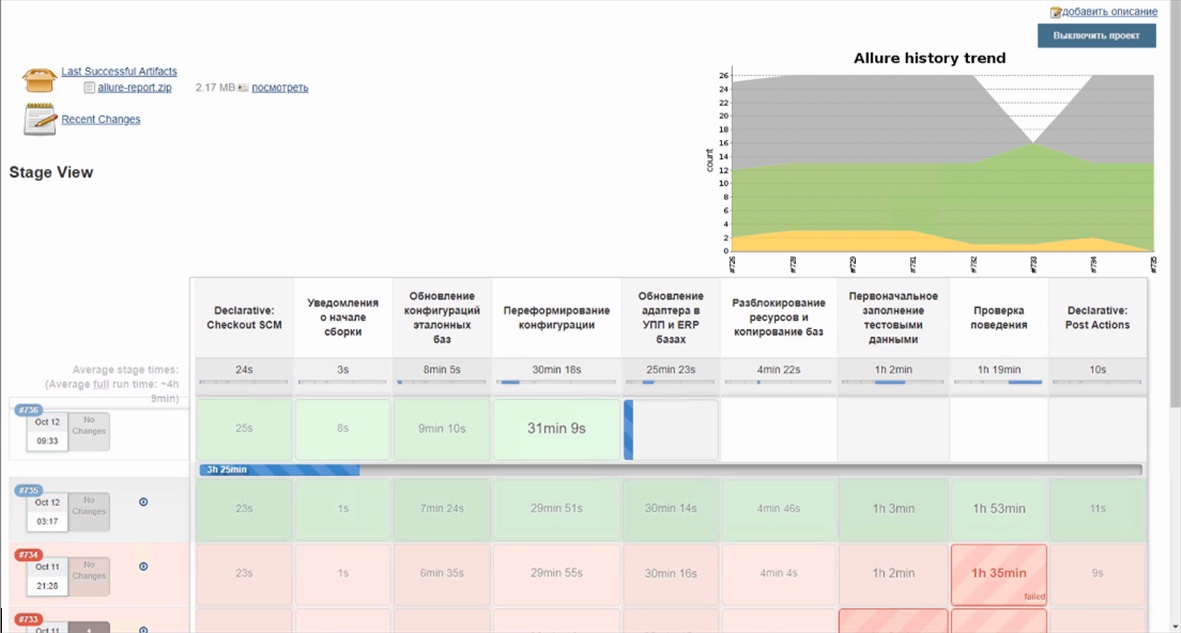
Специально для этой презентации мы собрали зеленый Pipeline. Поскольку у нас нет возможности организовать Git-Flow, и мы пока не перешли с конфигуратора на EDT, то он обычно красный. В ближайшее время мы планируем в качестве эксперимента перевести на EDT разработку наших коробочных продуктов – БИТ:Адаптер и БИТ:MDM. Я думаю, что у нас это даже получится.
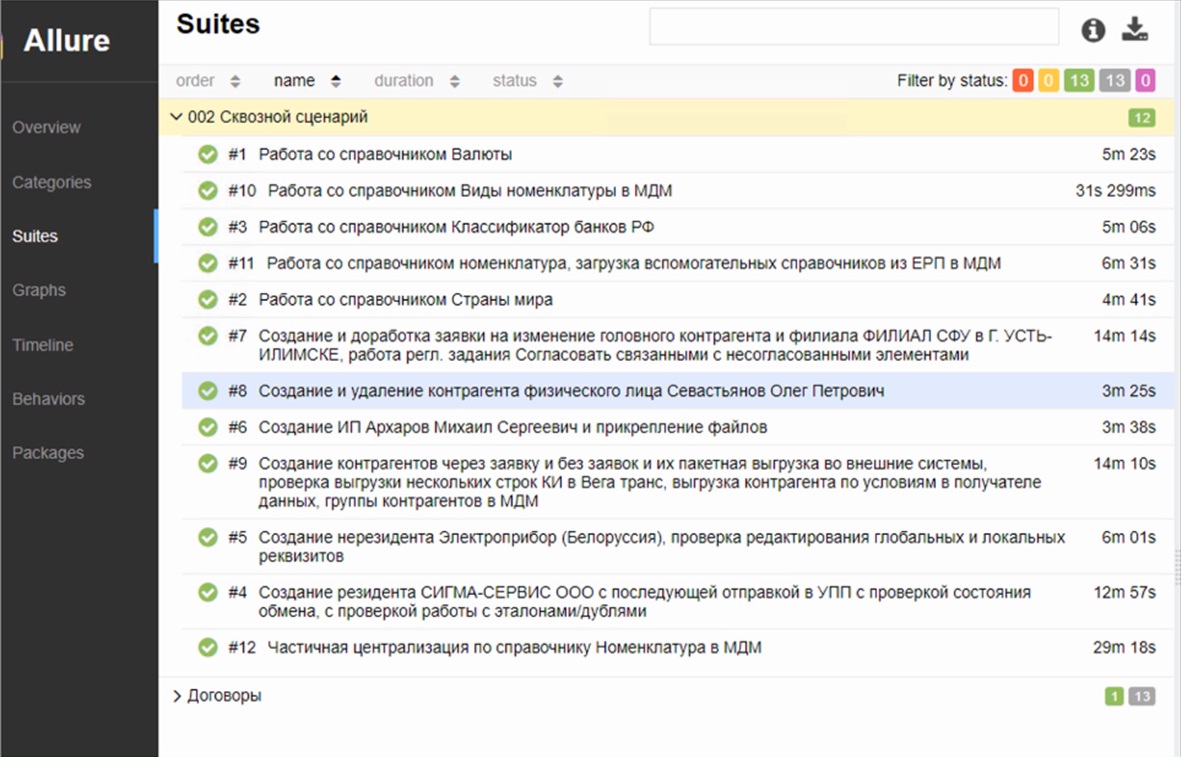
В качестве плагина к Jenkins у нас используется Allure – этот сервер отчетов, который позволяет удобно и наглядно видеть результаты и их анализировать.
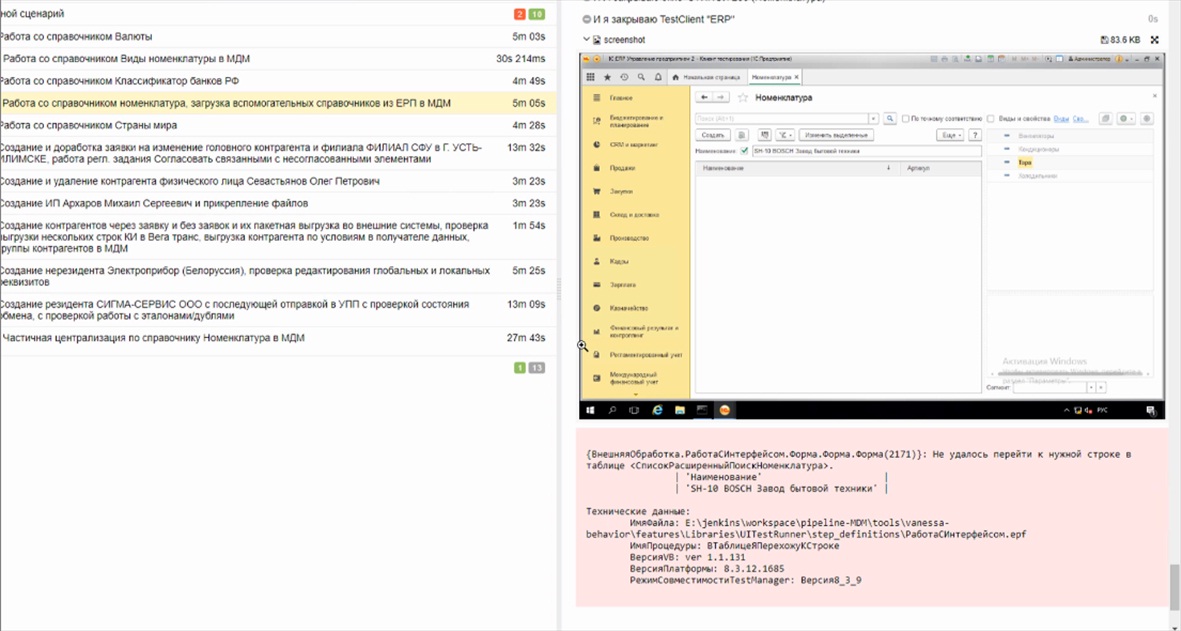
Можно увидеть шаг, на котором произошло падение, и проанализировать скриншот этого момента (он формируется системой автоматически).
Подготовка к эксплуатации

Следующий этап – это подготовка к эксплуатации.
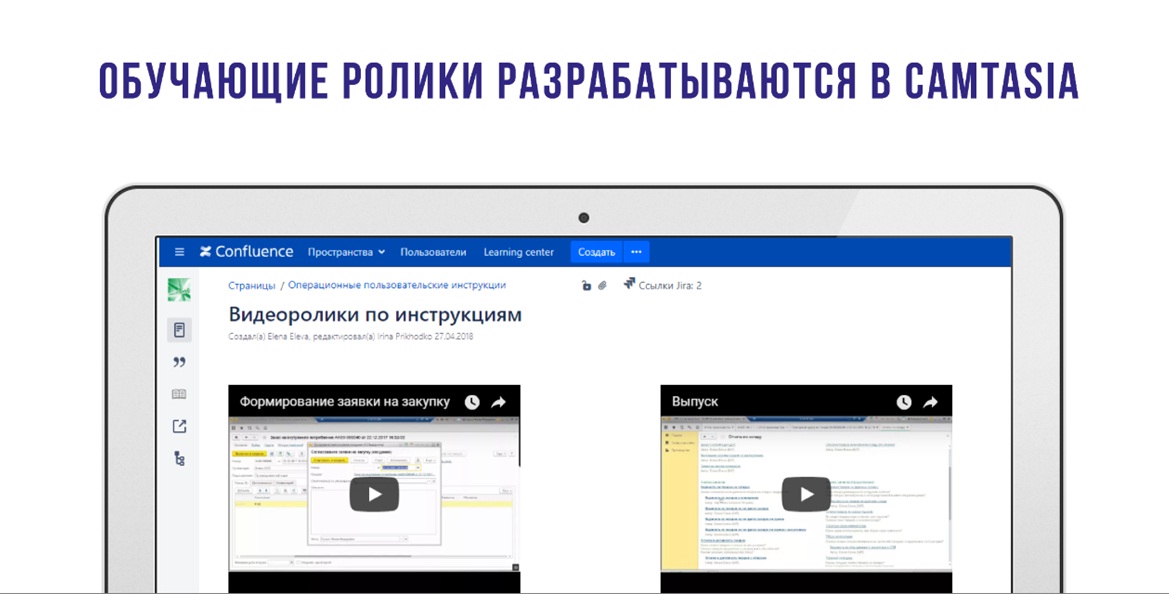
Мы из своей практики поняли, что разрабатывать печатные инструкции даже в Wiki-системе непродуктивно, потому что пользователи их все равно не читают. Поэтому для обучения у нас есть два способа, которые я рекомендую:
- Для типовой функциональности – «ИТС – это наше все»;
- А если функциональность разработанная – то нужны видеоролики.
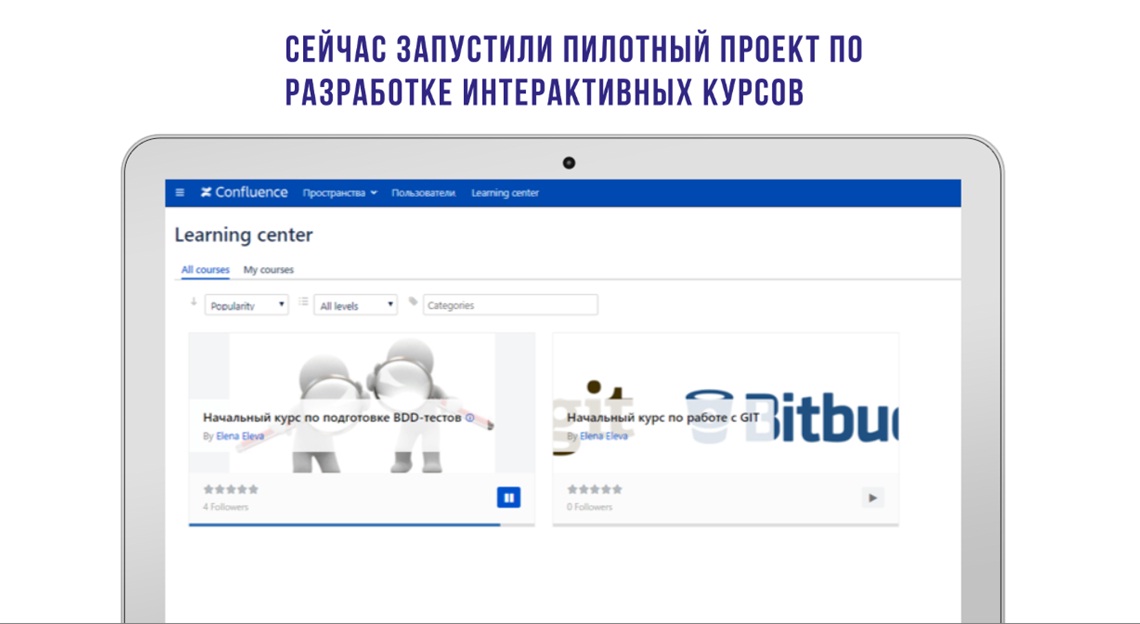
В частности, для новых сотрудников, мы разрабатываем курсы по BDD-тестам и работе с Git.
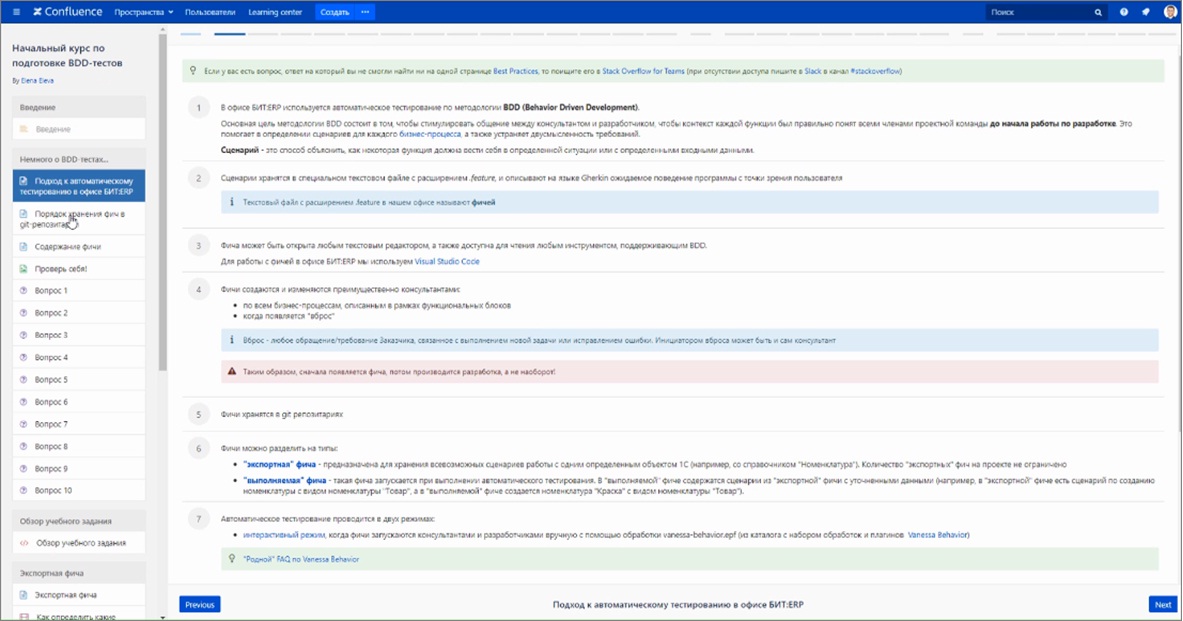
Есть интерактив – видео и статьи.
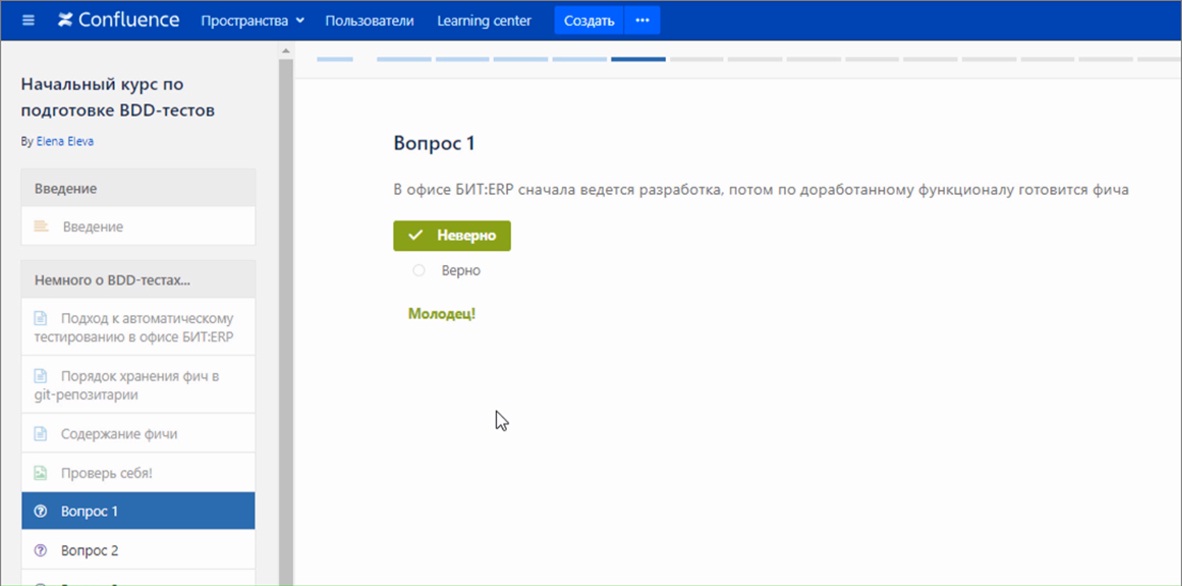
И есть тестирование.
Эксплуатация

И последний этап, про который я расскажу – это эксплуатация.
На этом этапе особую важность приобретает грамотно построенный сервис-деск. У нас для этого также используется продукт из стека Atlassian – Jira Service Desk. Причем, наш офисный сервис-деск содержит в себе информацию не только по ИТ-инфраструктуре, но и по работе всевозможных бэк-офисных подразделений, включая бухгалтерию, финансы, кадры.
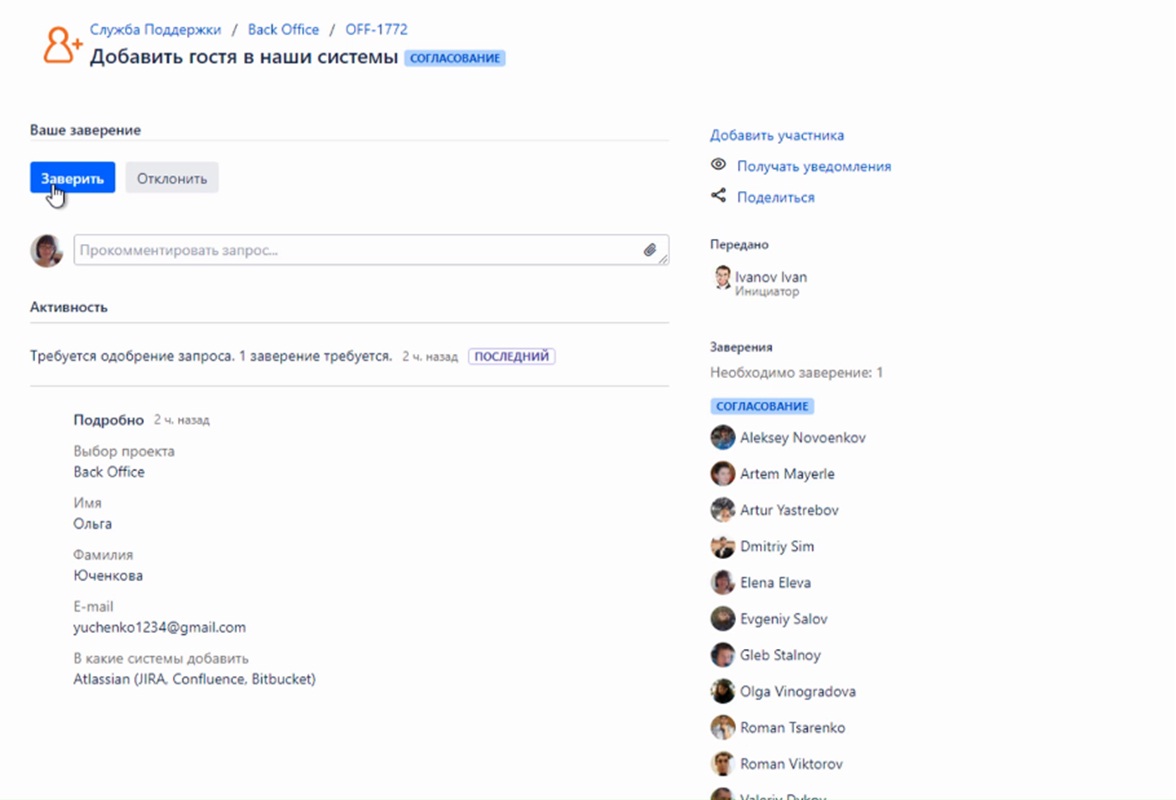
Здесь показывается, как происходит добавление нового сотрудника клиента к нашему проекту. Процесс полностью автоматизирован, происходит согласование, и клиент получает автоматическое письмо о том, что у него теперь есть доступ к Jira, Confluence и Bitbucket со ссылкой на инструкции и видеоролики, как с этим всем работать.
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2018 EDUCATION.