




{kind=link}
Не зная прошлого, невозможно понять подлинный смысл настоящего и цели будущего. / Максим Горький Не знать истории-значит всегда быть ребёнком. / Цицерон
1С Предприятие 7.7 хранит системную информацию в файле SYSLOG\1cv7.mlg в виде текста в формате csv, разделитель ";". Таблицы в виде текста сложно читать. Большой объем информации и событий удобнее анализировать визуально, что мы и попытаемся сделать.
Постановка задачи
- Видеть нагрузку на систему в реальном времени в виде графиков
- по времени выполнения отчетов, документов, обработок
- по времени выполнения процедур и функций
- Быстро фильтровать события
- по ошибкам [если они есть]
- по транзакциям или предупреждениям
- Система аналитики должна работать автономно, не использовать ресурсы рабочего сервера 1С.


Что такое ELK Stack
- Elasticsearch используется для хранения, анализа, поиска по логам.
- Kibana представляет удобную и красивую web панель для работы с логами.
- Logstash сервис для обработки логов и отправки их в Elasticsearch.
- Beats — агенты для отправки логов в Logstash. Будем использовать Filebeat для отправки данных из текстовых логов linux, Winlogbeat для отправки логов из журналов Windows систем.
- Также используем утилиту rsync - для копирования syslog\1cv7.mlg c Windows на Ubuntu
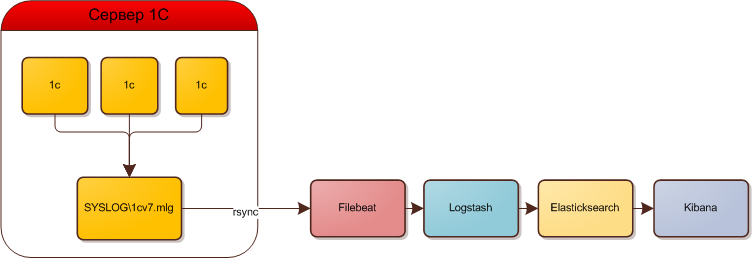
Схематично работу системы изобразим так:

1. Подготовка
Скопируем логи 1с с Windows сервера на Ubuntu с помощью утилиты rsync, входящей в пакет cygwin.com На стороне сервера Ubuntu настраиваем сервис rsync
apt-get install rsync
Настраиваем параметры в /etc/rsyncd.conf
uid = user
gid = root
use chroot = yes
max connections = 50
pid file = /var/run/rsyncd.pid
log file = /var/log/rsync.log
[share]
path = /home/files/ # каталог логов
hosts allow = 192.168.0.1 # адрес сервера 1с
hosts deny = *
#list = true
read only = false
#auth users = s1
#secrets file = /etc/rsyncd.secrets
Создаем bat file на сервере 1с
set BACKUP_DIR=E:\1c\complex\syslog\
cd /d %BACKUP_DIR%
C:\cygwin64\bin\rsync.exe -avz --inplace --append --chmod=u=rw --log-file=c:\bat\rsync.log ./*.mlg s1@192.168.100.2::share/1c/
Обязательно указываем параметр - копировать только изменения для уменьшения трафика. И чтобы не перезаписывать весь файл, иначе в ELK данные будут дублироваться. запускаем
C:\cygwin64\bin\rsync.exe -avz --inplace --append --chmod=u=rw --log-file=c:\bat\rsync.log ./*.mlg s1@192.168.100.2::share/1c/ sending incremental file list 1cv7.mlg sent 298 bytes received 35 bytes 666.00 bytes/sec total size is 68,683,437 speedup is 206,256.57
Проверяем файл в каталоге назначения на сервере Ubuntu Добавляем задание в планировщик заданий с периодом 5 минут.
Установка Java на Ubuntu
Подключаем репозиторий с Java 8, обновляем список пакетов и устанавливаем Oracle Java 8.
add-apt-repository -y ppa:webupd8team/java
apt update
apt install oracle-java8-installer
Проверяем версию явы в консоли.
java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
Установка Elasticsearch
Копируем себе публичный ключ репозитория:
# wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | apt-key add -
Если у вас нет пакета apt-transport-https, то надо установить:
# apt install apt-transport-https
Добавляем репозиторий Elasticsearch в систему:
# echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | tee -a /etc/apt/sources.list.d/elastic-6.x.list
Устанавливаем Elasticsearch на Debian или Ubuntu:
apt update
apt-get install elasticsearch
После установки добавляем elasticsearch в автозагрузку и запускаем.
systemctl daemon-reload
systemctl enable elasticsearch.service
systemctl start elasticsearch.service
Проверяем, состояние сервиса:
systemctl status elasticsearch.service
Если сервис запущен, тогда переходим к настройке Elasticsearch.
Настройка Elasticsearch
Настройки Elasticsearch находятся в файле /etc/elasticsearch/elasticsearch.yml. На начальном этапе нас будут интересовать следующие параметры:
path.data: /var/lib/elasticsearch # директория для хранения данных
network.host: 127.0.0.1 # слушаем только локальный интерфейс
По-умолчанию Elasticsearch слушает все сетевые интерфейсы. Нам это не нужно, так как данные в него будет передавать logstash, который будет установлен локально. Обратите внимание на параметр path.data для директории с данными. Чаще всего индексы будут занимать значительное место. Если останется меньше 10% свободного места elasticsearch уходит в глухой read-only и вывести сервис из этого состояния – ещё та задача. Подумайте заранее, где вы будете хранить логи. Остальные настройки - дефолтные. После изменения настроек, перезапустите службу:
systemctl restart elasticsearch.service
Смотрим, что получилось:
netstat -tulnp | grep 9200
tcp6 0 0 127.0.0.1:9200 :::* LISTEN 14130/java
Elasticsearch работает на локальном интерфейсе - слушает ipv6, про ipv4 ни слова. Но его он тоже слушает, так что все в порядке. Переходим к установке kibana.
Установка Kibana
apt-get install kibana
Добавляем Кибана в автозагрузку и запускаем:
systemctl daemon-reload
systemctl enable kibana.service
systemctl start kibana.service
Проверяем состояние запущенного сервиса:
systemctl status kibana.service
По-умолчанию, Kibana слушает порт 5601. Только не спешите его проверять после запуска. Кибана стартует долго. Подождите минуту и проверяйте.
netstat -tulnp | grep 5601
tcp 0 0 127.0.0.1:5601 0.0.0.0:* LISTEN 27401/node
Настройка Kibana
Файл с настройками Кибана располагается по пути — /etc/kibana/kibana.yml. На начальном этапе можно вообще ничего не трогать и оставить все как есть. По-умолчанию kibana слушает только localhost и не позволяет подключаться удаленно. Это нормальная ситуация, если у вас будет на этом же сервере установлен nginx в качестве reverse proxy, который будет принимать подключения и проксировать их в кибана. Так и нужно делать в продакшене, когда системой будут пользоваться разные люди из разных мест. С помощью nginx можно будет разграничивать доступ, использовать сертификат, настраивать нормальное доменное имя и т.д. Если же у вас это тестовая установка, то можно обойтись без nginx. Для этого надо разрешить Кибана слушать внешний интерфейс и принимать подключения. Измените параметр server.host, Если хотите, чтобы она слушала все интерфейсы, укажите в качестве адреса, например вот так:
server.host: "0.0.0.0"
После этого Kibana надо перезапустить:
systemctl restart kibana.service
Теперь можно зайти в веб интерфейс по адресу http://ubuntu:5601.  Kibana[/caption] В процессе настройки будем подключаться напрямую к Kibana.
Kibana[/caption] В процессе настройки будем подключаться напрямую к Kibana.
Установка и настройка Logstash
apt-get install logstash
Добавляем logstash в автозагрузку:
systemctl enable logstash.service
Запускать пока не будем, надо его сначала настроить. Основной конфиг logstash лежит по адресу /etc/logstash/logstash.yml его трогать не будем настройки будем по смыслу разделять по разным конфигурационным файлам в директории /etc/logstash/conf.d. Создаем первый конфиг input.conf, который будет описывать прием информации с beats агентов.
input {
beats {
port => 5044
}
}
Тут все просто. Указываем, что принимаем информацию на 5044 порт. Этого достаточно. Если вы хотите использовать ssl сертификаты для передачи логов по защищенным соединениям, здесь добавляются параметры ssl. Будем собирать данные из закрытого периметра локальной сети, поэтому использовать ssl нет необходимости. Теперь укажем, куда будем передавать данные. Тут тоже все относительно просто. Рисуем конфиг output.conf, который описывает передачу данных в Elasticsearch.
output {
if [type] == "s1" {
elasticsearch {
hosts => "localhost:9200"
index => "s1-%{+YYYY.MM.dd}"
}
}
else {
elasticsearch {
hosts => "localhost:9200"
index => "unknown_messages"
}
}
#все поступающие данные logstash будет отправлять в системный лог = /var/log/syslog
#Используйте только во время отладки, иначе лог быстро разрастется
#stdout { codec => rubydebug }
}
Здесь все просто — передавать данные в elasticsearch под указанным индексом с маской в виде даты. Разбивка индексов по дням и по типам данных удобна с точки зрения управления этими данными. Потом легко будет выполнять очистку данных по этим индексам. Остается последний конфиг с обработкой входящих данных. Тут начинается самое интересное. Рисуем конфиг filter.conf.
filter {
if [type] == "s1" {
csv {
separator => ";"
columns => ["date1","time2","user","t1","t2","t3","t4","t5","t6"]
}
mutate {
add_field => {
"timestamp" => "%{date1} %{time2}"
}
# remove_field => ["time1", "time2"]
}
date {
match => ["timestamp", "YYYYMMdd HH:mm:ss"]
target => "@timestamp"
}
if "_dateparsefailure" in [tags] {
drop{}
}
if [t3] in ["ИзмененПроведенный","ЗапускОтчета","ВосстановлениеПоследовательности", "OpenSession", "GrbgRuntimeErr" ] {
# пропускаем обработку этих событий
}
else {
kv {
value_split => ":"
field_split => " ;"
source => "t5"
}
mutate {
convert => { "ВремяВыполнения" => "integer" }
}
}
}
}
Первое, что делает этот фильтр - парсит логи с помощью фильтра csv, разбивая на колонки по символу ";" и выделяет значения, которые записывает в поля. Дальше используется модуль date для того, чтобы выделять дату из поступающих логов и использовать ее в качестве даты записи в elasticsearch, если не получается - прерываем обработку. Делается это для того, чтобы не возникало путаницы, если будут задержки с доставкой логов. В системе сообщения будут с одной датой, а внутри лога будет другая дата. Неудобно разбирать инциденты. Потом для колонки t3 используем фильтр kv для выделения Параметр:Значение. Разделителями являются символы " " или ";". Закончили настройку logstash. Запускаем его:
systemctl start logstash.service
Проверьте на всякий случай лог /var/log/logstash/logstash-plain.log, чтобы убедиться в том, что сервис запущен и нет ошибок. Теперь настроим агенты для отправки данных в logstash.
Установка Filebeat для отправки логов в Logstash
В Debian/Ubuntu ставим так:
apt-get install filebeat
После установки рисуем примерно такой конфиг /etc/filebeat/filebeat.yml для отправки логов в logstash.
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/files/1c/*.mlg
fields:
type: s1
encoding: "cp1251"
fields_under_root: true
scan_frequency: 5s
output.logstash:
hosts: ["localhost:5044"]
xpack.monitoring:
enabled: true
elasticsearch:
hosts: ["http://localhost:9200"]
Некоторые пояснения к конфигу: с помощью поля type, указываем тип лога: s1, в зависимости от этого типа меняются правила обработки в logstash. Обязательно указываем кодировку "cp1251", иначе по умолчанию будут грузится кракозябры "utf". Запускаем filebeat и добавляем в автозагрузку.
systemctl start filebeat
systemctl enable filebeat
Проверяйте лог по адресу /var/log/filebeat/filebeat. Он весьма информативет. Если все в порядке, увидите список всех логов в директории /var/log/nginx, которые нашел filebeat и начал готовить к отправке. Если все сделали правильно, то данные уже потекли в elasticsearch. Мы их можем посмотреть в Kibana. Для этого открываем web интерфейс и переходим в раздел Discover. Так как там еще нет индекса, нас перенаправит в раздел Managemet, где мы сможем его добавить.
Добавление индекса в Kibana
Вы должны увидеть индекс, который начал заливать logstash в elasticsearch. В поле Index pattern введите s1-* и нажмите Next Step. На следующем этапе выберите имя поля для временного фильтра, выбирайте — @timestamp, и жмите Create Index Pattern.
Создание индекса с данными
Новый индекс добавлен. Теперь при переходе в раздел Discover, он будет открываться по-умолчанию со всеми данными, которые в него поступают.
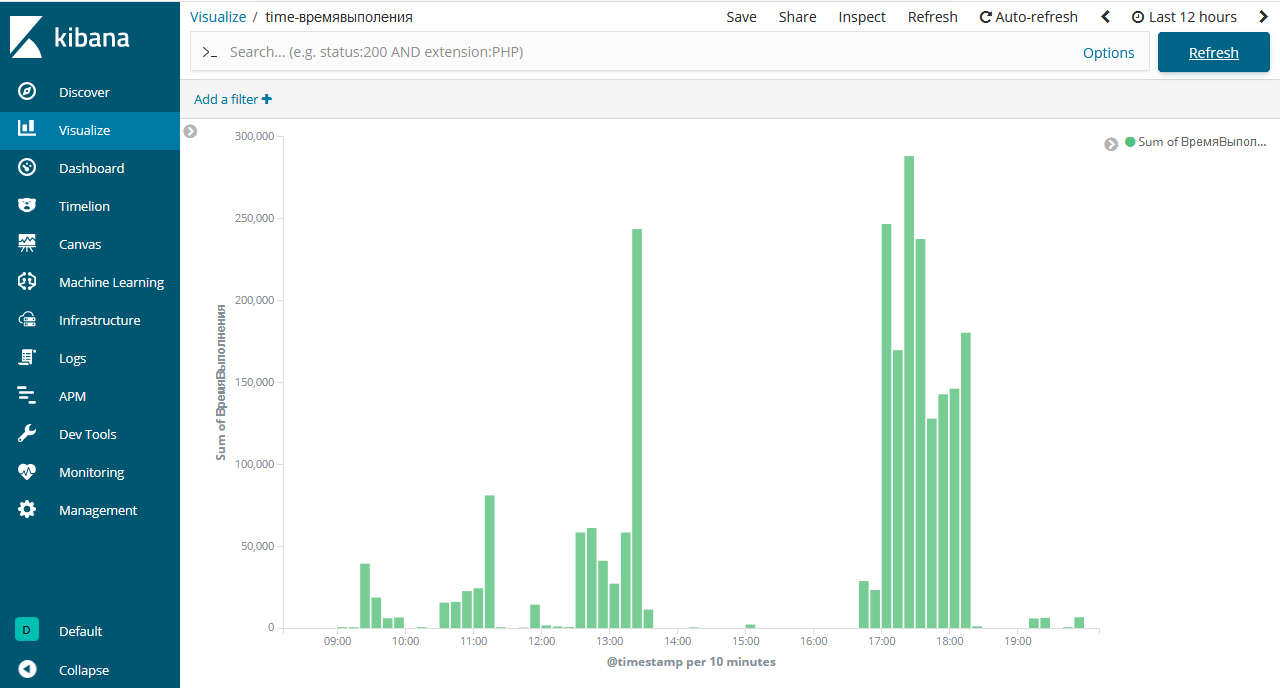
Просмотр логов Elasticsearch в Kibana
Получением логов с linux серверов настроили. Переходим к анализу.
Добавляем счетчики в 1С
Добавим две функции, которые будем вызывать для анализа документов, отчетов и обработок. Функции оформим в виде класса ОбщиеФункции:
Функция Старт(Конт="") Экспорт
Возврат _GetPerformanceCounter();
КонецФункции
Функция Финиш(ВремяНачала, Конт, Имя="", Док="", ТипСобытия="ВнешняяОбработка") Экспорт
Попытка
Путь = Конт.РасположениеФайла();
Исключение
Попытка
// класс
Путь = Конт.ПолучитьПуть();
Исключение
//Путь = "НеопределеннаяОбработка";
ФормаРасш = СоздатьОбъект("РасширениеФормы");
Попытка
ФормаРасш.УстановитьФорму( Конт );
Путь = ФормаРасш.ПолныйТипОбъекта();
Исключение
Путь = "Модуль";
КонецПопытки;
КонецПопытки;
КонецПопытки;
Время= _GetPerformanceCounter() - ВремяНачала;
Сообщение = "Путь:"+Путь+" ВремяВыполнения:"+Время;
Попытка
Сообщение = Сообщение + " Вид:"+Конт.Вид();
Исключение
КонецПопытки;
Если ПустоеЗначение(Имя)=0 Тогда
Сообщение = Сообщение +" Имя:"+Имя;
КонецЕсли;
ЗаписьЖурналаРегистрации(Сообщение, ТипСобытия, , Док, 3);
Возврат Время;
КонецФункции //Финиш
Для замеров проведения добавляем в модуль проведения документа
Процедура ОбработкаПроведения(ВидыДвижений)
оф = СоздатьОбъект("ОбщиеФункции");
t1 = оф.Старт();
...
оф.Финиш(t1, Контекст, "ОбработкаПроведения", ТекущийДокумент(), "Документ");
КонецПроцедуры //ОбработкаПроведения()
Выводы

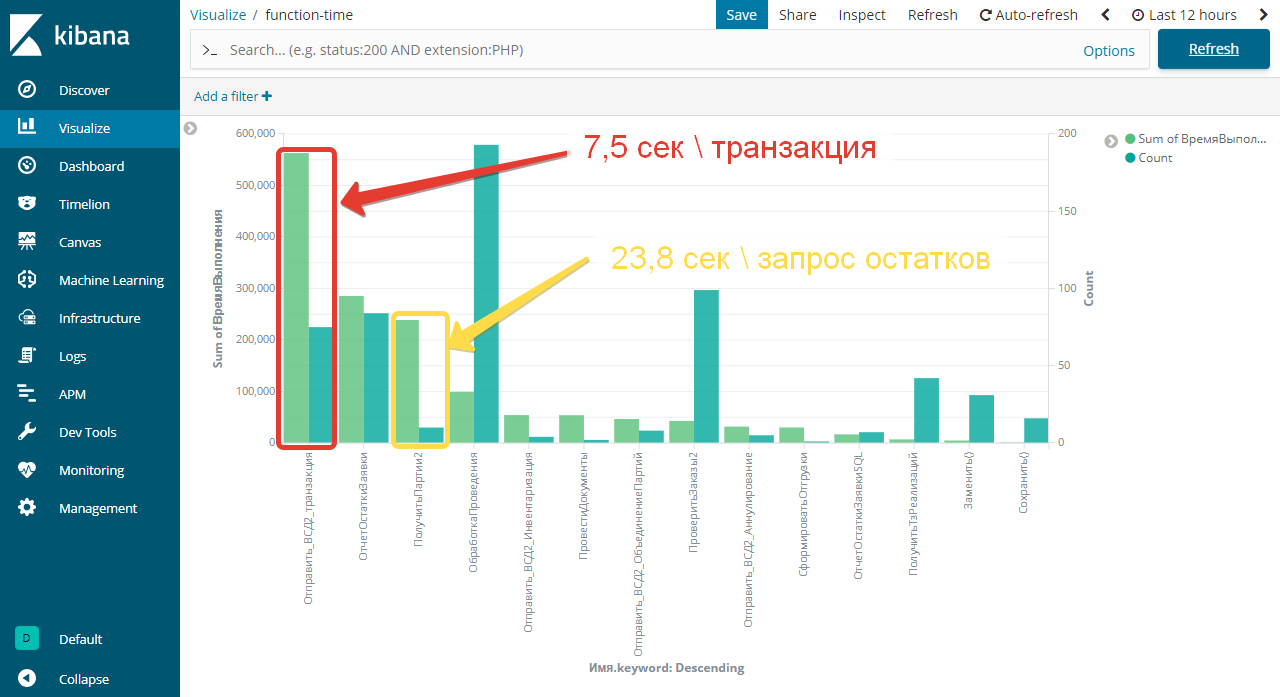
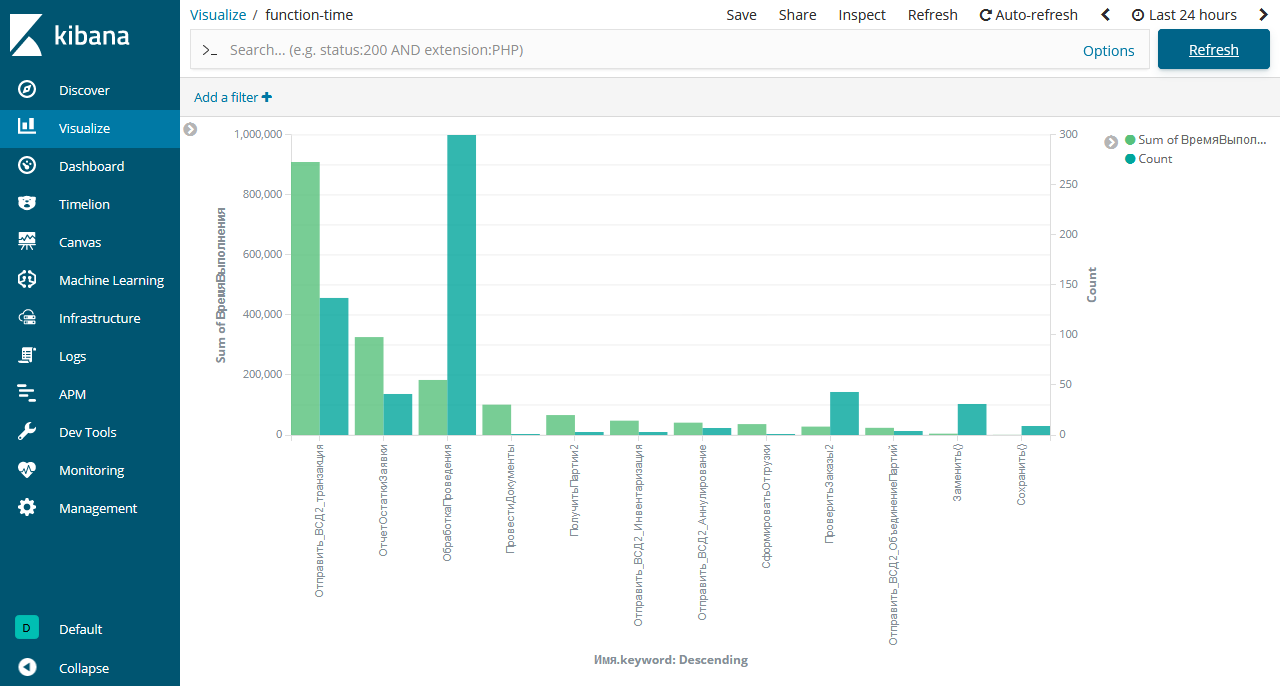
Ветис.API - система с последовательным доступом, на текущий момент не позволяющая обрабатывать несколько запросов одновременно - значит, сначала отправляем запрос, потом дожидаемся ответа, и только после этого можно отправлять следующий запрос. Поэтому 7,5 сек за 1 транзакцию - приемлемый результат, если время одного запроса сильно больше - надо выяснять причину. Время, используемое в запросе остатков = 23,8 сек за 1 запрос в большей степени характеризует сервера Ветис.API и нагрузку на них. Если время 1 запроса остатков сильно больше требуется:
- Сократить период запроса для Ветис.API версии 2.1
- Привести остатки в соответствии с остатками на складе = списать "лишние" остатки.
ELK - мощный OpenSource инструмент. Мы получили инструмент, с помощью которого можно анализировать работу 1С Предприятия 7.7 в рабочем режиме, не замедляя работы системы. Изучение логов помогает определить слабые места системы и увеличить качество обслуживания систем 1С Предприятие 7.7 Оптимизировать желательно зная слабые места = сколько времени выполняется функция и как часто вызывается, помня о золотом правиле: Оптимизируй там где болит, а не там где хочется. В дальнейшем планируем рассказать о создании Dashbord и Visualize на примере 1С Предприятия 7.7.
Ссылки
установка ELK стека и настрока отправки логов Windows
Фильтры в Logstash мощный инструмент
Вступайте в нашу телеграмм-группу Инфостарт