Нормализация БД – просто и доступно.
Вместо предисловия.
Поводом к написанию данной статьи послужил тот факт, что несмотря на то, что мы уже давно живем в 21 веке, тема нормализации отношений БД в публичных источниках до сих пор не раскрыта. Если обратиться к википедии, то становится ясно, что ничего не ясно. Не проясняет ситуацию ни яндекс, ни гугл. Данный вакуум понимания/не понимания был обнаружен случайно. Однажды, в процессе общения на ИС выяснилось, что посоветовать прочесть собеседнику, что-нить адекватное на эту тему не удалось. К тому же выяснилось, что различные источники трактуют нормальные формы по своему. В свое время, в 1998 году мне повезло познакомиться со школой «Третьякова Сергея Робертовича» и его концепцией третьей нормальной формы. С тех пор я искренне считал, что вопрос закрыт.
Нормализация — это процесс организации данных в базе данных, включающий создание таблиц и установление отношений между ними в соответствии с правилами, которые обеспечивают защиту данных и делают базу данных более гибкой, устраняя избыточность и несогласованные зависимости.
Нормализация и проектирование
Проектирование баз данных, как правило, играет одну из ключевых ролей в большинстве проектов. Грамотно спроектированная база позволяет без особых проблем вносить изменения, изменять структуру системы.
Цели нормализации:
- Исключение некоторых типов избыточности. Избыточность данных приводит к непродуктивному расходованию свободного места на диске и затрудняет обслуживание баз данных.
- Устранение некоторых аномалий обновления. Например, если данные, хранящиеся в нескольких местах, потребуется изменить, в них придется внести одни и те же изменения во всех этих местах. Несогласованность информации в базе данных — это настоящий кошмар, который почти всегда приводит к возникновению ошибок. Если вы забудете хотя бы об одной таблице, которую нужно обновить, то все данные станут не достоверными.
- Устранение некоторых аномалий выборки. Например, если данные, хранящиеся в нескольких местах, потребуется выбрать, то выборка одних и тех же данных из разных источников может дать различные результаты.
- Упрощение процедуры применения необходимых ограничений целостности. Отношения, определенные с помощью первичных и внешних ключей позволяют организовать СУБД автоматический контроль согласованности данных, в том числе позволяют реализовать каскадное обновление связанных по внешнему ключу полей в соответствующих таблицах. Разработка проекта базы данных, который является достаточно «качественным» представлением реального мира, интуитивно понятен и может служить хорошей основой для последующего расширения;
Нормализация как таковая не имеет целью уменьшение или увеличение производительности работы или же уменьшение или увеличение физического объёма базы данных. Однако качественная модель, разработанная на основе принципов нормализации ведет к уменьшению физического объема базы данных и обеспечивает приемлемый уровень производительности.
Зачем нужны принципы нормализации?
- Целостная система принципов нормализации позволяет различным разработчикам получать на выходе идентичные схемы баз данных, при условии, что на вход они получили идентичные задания. То есть реализуется принцип единообразия.
- Появляется возможность автоматизировать процесс анализа результата проектирования для выявления рекомендаций, замечаний и грубых ошибок.
- В условиях неопределенности нормализация позволяет создавать системы с широкими потенциальными возможностями для последующего развития. В ходе эволюционных модернизаций любая система рискует оказаться в тупике, преодолеть, который можно только революционным путем. Приверженность принципам нормализация позволяет развивать систему без серьезных потрясений и накладных затрат на радикальные изменения структуры.
- Нормализованная структура базы данных поддерживает целостность данных на уровне структуры.
- Оптимальная структура базы данных обеспечивает максимальную производительность системы, сочетая простоту и функциональность.
- Принципы нормализации создают основу для общения между архитекторами системы и разработчиками, разработчиками и заказчиками приложений.
- Осознание принципов позволяет выявить скрытые проблемы в уже работающих системах и помогает принять взвешенные решения для устранения недостатков.
Существует несколько правил нормализации баз данных. Каждое правило называется «нормальной формой». Если выполняется первое правило, говорят, что база данных представлена в «первой нормальной форме». Если выполняются два первых правила, считается, что база данных представлена во «второй нормальной форме» Если выполняются три первых правила, считается, что база данных представлена в «третьей нормальной форме». Есть и другие уровни нормализации, однако для большинства приложений достаточно нормализовать базы данных до третьей нормальной формы.
Как таковые первая и вторая нормальные формы не являются целью оптимизации – это промежуточные этапы для приведения схемы базы данных к третьей нормальной форме. В то время как первая и вторая нормальные формы позволяют реализовать схему базы данных различным набором связанных таблиц. Строгая третья нормальная форма предполагает только один вариант решения задачи проектирования схемы базы данных. с заданной функциональностью. Таким образом, различные программисты одну и туже задачу решают одним и тем же способом, что в значительной мере облегчает коммуникации между разработчиками и архитекторами. К тому же, единообразие позволяет проверять качество проектирования схемы баз данных с помощью автоматизированных средств разработки.
В дальнейшем для решения задач производительности или обеспечения простоты может быть проведена денормализация схемы базы данных. Опытный разработчик баз данных такую денормализацию выполняет на лету в своей голове, однако для этого нужен достаточно большой опыт практического применения принципов нормализации в течении нескольких лет. К сожалению, принципы проектирования 1С не соответствуют принципам проектирования по третьей нормальной форме. Для приобретения навыков проектирования можно взять базу данных mySQL и реализовать на её базе несколько web-приложений.
Пример ошибок нормализации
Не будем далеко ходить. Для примера возьмем наш горячо любимый Инфостарт, с которым вечно, что-то не так. Давайте обратим внимание на показатели рейтинга. В один и то же момент времени они показывают разные значение: 179, 183. Как такое может быть? Отчет очень простой - данные об одном и том же атрибуте хранятся в трех различных местах. Можно себе представить, что твориться внутри, если снаружи основной ключевой показатель выглядит таким образом?
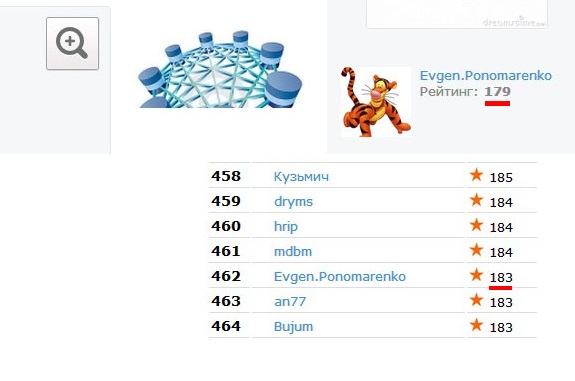
С одной стороны понятно стремление Доржи идти вперед. Но с другой - как можно заниматься редизайном без реинжениринга? Может быть сначала стоило провести рефакторинг базы данных, не трогая визуализации? Да, это затратно и с точки зрения пользователей - бессмысленно. Но может быть стоит хотя бы начать? Понятно, что все уже устали и тех. поддержка в том числе. Но без порядка - нет развития, проект все время будет упираться в "неожиданные" трудности. Но это моё личное мнение.
Продолжим...
Первая нормальная форма
Первая нормальная форма относится только к одной таблице.
Таблица находится в первой нормальной форме (сокращённо 1НФ), если все его атрибуты атомарны, то есть если ни один из его атрибутов нельзя разделить на более простые атрибуты.
Первая и главная нормальная форма требует от таблицы (а точнее, от ее проектировщика) следования следующим правилам:
- Каждый столбец в строке должен быть атомарным, т.е. столбец может содержать одно и только одно значение для заданной строки.
- Каждая строка в таблице обязана содержать одинаковое количество столбцов
- Каждый столбец в строке должен быть строго типизирован
- Каждая строка должна иметь независимый первичный ключ. Нельзя использовать в роли первичного ключа атрибуты внешнего мира, такие как табельный номер сотрудника, наименование города и т.д. Первичный ключ – это номер цифровой последовательности
Первичный ключ — один или несколько столбцов, уникально идентифицирующих строку в таблице. Значения в столбце, объявленном как первичный ключ, не может дублироваться в нескольких строках. Колонку первичного ключа обозначаем префиксом «PK»
Не стоит использовать для первичного ключа комбинацию столбцов, используйте только генератор последовательностей СУБД – и будет вам Счастье.
Вторая нормальная форма
Вторая нормальная форма относится только к двум таблицам.
- Таблицы должна соответствовать первой нормальной форме.
- Определите главную таблицу по правилам отношения «один ко многим»,
- В зависимой таблице добавьте внешний ключ.
Внешний ключ — один или более столбцов в таблице, значения которых соответствуют значениям некоторых столбцов в другой таблице (как правило, ее первичным ключам). Внешние ключи нужно стараться использовать везде и всегда, когда между двумя таблицами существует взаимосвязь. Технически, современные системы поддерживают автоматический контроль ссылочной целостности при использовании внешних ключей. Колонку внешнего ключа обозначаем префиксом «FK»
Третья нормальная форма
Третья нормальная форма относится ко всем таблицам задачи в комплексе. Анализируемые таблицы не должны содержать избыточную информацию в не ключевых полях. Все таблицы должны быть связаны между совой по принципу «один ко многим»
- Таблицы должны соответствовать второй нормальной форме.
- В зависимой таблице внешний ключ должен быть not null.
- Все поля стремятся быть not null
- Избавиться от избыточной информации, содержащейся в не ключевых столбцах. Другими словами не ключевая информация должна храниться только в одной таблице в одном поле
Если содержимое группы полей может относиться более чем к одной записи в таблице, подумайте о том, не поместить ли эти поля в отдельную таблицу.
Связь между таблицами «один к одному»
В связи "один к одному" строке таблицы А может сопоставляться только одна строка таблицы Б и наоборот. Связь "один к одному" создается, если для обоих связанных ключей определены ограничения первичного ключа и уникальности.
Этот тип связи обычно не используется, так как большую часть связанных таким образом данных можно хранить в одной таблице. Связь "один к одному" можно использовать для следующих целей:
- Изоляция части таблицы из соображений безопасности.
- Хранение кратковременных данных, которые можно легко удалить вместе со всей таблицей.
- Хранения данных, которые относятся только к части основной таблицы.
Само по себе использование связи один к одному есть нарушение требований к третьей нормальной форме и может применяться как средство осознанной денормализации для решения задач оптимизации технических проблем.
Связь между таблицами «один ко многим»
Связь "один ко многим" — единственно возможная в рамках требований третьей нормальной формы. В этом типе связей у строки таблицы А может быть несколько совпадающих строк таблицы Б, но каждой строке таблицы Б может соответствовать только одна строка из таблицы А. С логической точки зрения возможны два случая:
Случай первый:
Таблица А – это справочник; Таблица Б – это таблица фактов. Внешний неуникальный ключ из таблицы Б ссылается на первичный ключ таблицы А.
Случай второй:
Таблица А – это главная таблица; Таблица Б – это зависимая таблица. Внешний не уникальный ключ из таблицы Б ссылается на первичный ключ таблицы А.
Однако с физической точки зрения выглядит это одинаково: Несколько строк из таблицы Б ссылаются на одну строку таблицу А. К тому же внешний ключ таблицы Б не может быть null.
Это главное правило определяющее направление внешней связи.
Связь между таблицами «многие ко многим»
В связи "многие ко многим" строке таблицы А может сопоставляться несколько строк таблицы Б, и наоборот. Наличие такой связи в системе таблиц говорит об ошибках проектирования.
Такие связи устраняются либо путем определения третьей таблицы, которая называется таблицей соединения, первичный ключ которой состоит из внешних ключей А и Б, либо пересмотром всех отношений связанных таблиц.
Пример нормализации
| Для начала возьмем следующие данные: |
| ФИО | Табельный номер | Паспортные данные | Город проживания | Дети сотрудника |
| Иванов Е. Г. | 00001 | ВМ 045345 | Харьков | Иванова Татьяна 13.06.2009 Иванов Михаил 20/03/10 |
|
Петрова Елена Николаевна |
00002 | ТК 45645 | Харьков | Наталья Федоровна |
| Хлебникова Ольга Александровна | 00003 | 567897 | Москва |
Первая нормальная форма
|
Для первой нормальной формы таблица примет вид: Таблица: «Сотрудники» |
| PK_ИД | Фамилия | Имя | Отчество | Табельный номер | Серия паспорта | Номер паспорта | Город проживания | Дата рождения ребенка | Фамилия ребенка | Имя Ребенка | Отчество Ребенка |
| 1 | Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | Харьков | 13.06.2009 | Иванова | Татьяна | |
| 2 | Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | Харьков | 20.03.2010 | Иванов | Михаил | |
| 3 | Петрова | Елена | Николаевна | 00002 | ТК | 45645 | Харьков | Наталья | Федоровна | ||
| 4 | Хлебникова | Ольга | Александровна | 00003 | 567897 | Москва |
- В качестве первичного ключа выбрано поле «Ид», источником для которого является штатный генератор последовательности СУБД.
- Колонка ФИО разбита на три атомарных колонки «Фамилия», «Имя», «Отчество». Это позволяет контролировать заполненность полей, убирать пробелы, задавать алгоритм буквицы, формировать сокращения с помощью простых штатных средств SQL.
- Табельный номер сотрудника не используется в качестве первичного ключа, так как он относится к атрибуту внешнего мира и может со временем измениться, что может привести к массивным каскадным обновлениям.
- Дата рождения ребенка определена типом колонки «дата», что ведет к однозначности интерпретации данных
Вторая нормальная форма
|
Для второй нормальной формы таблицы примут вид: |
Таблица «Сотрудники»
| PK_ИД | Фамилия | Имя | Отчество | Табельный номер | Серия паспорта | Номер паспорта | FK_Город проживания | Дата рождения ребенка | Фамилия ребенка | Имя Ребенка | Отчество Ребенка |
| 1 | Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | 101 | 13.06.2009 | Иванова | Татьяна | |
| 2 | Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | 101 | 20.03.2010 | Иванов | Михаил | |
| 3 | Петрова | Елена | Николаевна | 00002 | ТК | 45645 | 101 | Наталья | Федоровна | ||
| 4 | Хлебникова | Ольга | Александровна | 00003 | 567897 | 102 |
Таблица «Города»
| PK_ИД | Город |
| 101 | Харьков |
| 102 | Москва |
| 103 | Житомир |
- В качестве первичного ключа выбрано поле «Ид», источником для которого является штатный генератор последовательности СУБД.
- В таблице «Сотрудники» появился внешний ключ «FK_Город проживания». В данном колонке могут быть использованы только значения из таблицы «Города»: 101,102,103. В данном примере используются только Ид Харькова и Москвы.
Третья нормальная форма
|
Таблица «Сотрудники» имеет следующие недостатки |
| PK_ИД | Фамилия | Имя | Отчество | Табельный номер | Серия паспорта | Номер паспорта | FK_Город проживания | Дата рождения ребенка | Фамилия ребенка | Имя Ребенка | Отчество Ребенка |
| 1 | Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | 101 | 13.06.2009 | Иванова | Татьяна | |
|
2 |
Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | 101 | 20.03.2010 | Иванов | Михаил | |
| 3 | Петрова | Елена | Николаевна | 00002 | ТК | 45645 | 101 | Наталья | Федоровна | ||
| 4 | Хлебникова | Ольга | Александровна | 00003 | 567897 | 102 | null | null | null | null |
- В строках 1,2 дублируются не ключевые поля
- В строке 4 данные о ребенке остаются не заполненными по причине того, что у данного сотрудника нет ни одного ребенка. Отсутствующая серия паспорта в строке 4 говорит о возможной неполноте данных, отсутствие данных о наличие ребенка носит объективный характер.
Таким образом таблицу сотрудники можно разбить на две таблицы «Сотрудники» и «ДетиСотрудников» итого получаем:
Таблица «Города»
| PK_ИД | Город |
| 101 | Харьков |
| 102 | Москва |
| 103 | Житомир |
Таблица «Сотрудники»
| PK_ИД | Фамилия | Имя | Отчество | Табельный номер | Серия паспорта | Номер паспорта | FK_Город проживания |
| 1 | Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | 101 |
| 2 | Петрова | Елена | Николаевна | 00002 | ТК | 45645 | 101 |
| 3 | Хлебникова | Ольга | Александровна | 00003 | null | 567897 | 102 |
Таблица «ДетиСотрудников»
| PK_ИД | FK_ИД Сотрудника | Дата рождения ребенка | Фамилия ребенка | Имя Ребенка | Отчество Ребенка |
|
1001 |
1 |
13.06.2009 | Иванова | Татьяна | null |
| 1002 | 1 | 20.03.2010 | Иванов | Михаил | null |
| 1003 | 2 | null | null | Наталья | Федоровна |
- Добавляем Внешний ключ «FK_ИД Сотрудника» типа «один ко многим».
- Для сотрудника с табельным номером 00003 строка в таблице «ДетиСотрудников» полностью отсутствует.
- Остальные не заполненные поля отражают лишь неполноту данных по ребенку сотрудника. Данное поле можно запретить вводить пустым, и тогда наши таблицы будут соответствовать строгой третьей нормальной форме. А можно «смягчить» данное требование. Оно нам было нужно только во время нормализации структуры базы данных. Ограничение на полному данных можно перенести из задач СУБД в задачи приложения.
Нормализация с точки зрения 1С
С точки зрения нормализации в 1С этот процесс выглядит довольно «прозрачно». Программисты интуитивно принимают следующие решения: Таблица «Города» реализуется как справочник «Города», Таблица «Сотрудники» реализуется как справочник «Сотрудники» с реквизитом «Город» типа СправочникСсылка.Города и табличной частью «ДетиСотрудника». В данном случае данный факт можно считать преимуществом 1С, так как процесс разработки скрывает от программиста излишнюю сложность. Если бы не одно большое НО. В табличной части, равно как и в регистре сведений отсутствует первичный ключ. Все бы ничего, но проблемы возникают во время интеграции с реляционными СУБД, в частности при обмене данными с web-сайтом на базе mySQL. Решается проблема с помощью искусственного первичного ключа в табличной части или регистре сведений.
Денормализация с точки зрения 1С
С моей точки зрения большим технологическим прорывом стало появление в 1С регистра накопления. Сама по себе строгая нормальная форма несет в себе порядок в процессе проектирования, но доведенная до абсурда способна тормознуть любой проект своими ограничениями. Во-первых, строгая третья нормальная форма хороша только для статических систем. Для динамических систем, которые меняются во времени, такие ограничения лишают программные комплексы необходимой гибкости. К примеру, в SAP нельзя внести контрагента, пока не заполнишь все обязательные поля, вплоть до телефона директора. Во-вторых, регистр накопления реализует OLAP технологии на уровне платформы, так как регистр накопления имеет измерения, ресурсы и временную ось. Структура регистра накопления позволяет значительно увеличить производительность за счет заранее посчитанных итогов, а штатные средства отчетов позволяют реализовывать принципы drill-down, drill-up в рамках единой среды.
В принципе, регистры накопления и регистры сведений – единственное отличие от третьей нормальной формы.
К сожалению, отсутствие ограничений на уровне платформы дает программисту слишком большую степень свободы и ведет накоплению ошибок проектирования. По этому, на мой взгляд, знать 1С программисту принципы нормализации обязательно. Более того, отсутствие привычки "задумываться о нормализации" во время проектирования приводит к тому, что разработчики умудряются использовать не по назначению справочники, документы и регистры.
Область применения принципов нормализации
В принципе, методика нормализации подходит для объектов справочники и документы. Принципы проектирования регистров выходят за рамки данной статьи. Одно могу сказать точно - наличие в конфигурации свыше 50 регистров накопления свидетельствует об отсутствии концептуальной целостности в частности и об отсутствии модели учета как таковой. К сожалению, а может быть к счастью здесь просто не паханое поле.
Первая нормальная форма, без первичного ключа хорошо подходит для обсуждения и фиксации требований с заказчиков. Обычно заказчик легко идет на обсуждение задач в формате первой нормальной формы, тем более, что экселевская обработка таких данных естественным образом справляется с сортировкой и автофильтрацией.
Третья нормальная форма хороша для общения между архитекторами, консультантами и программистами. По крайней мере, умение читать структуру базы данных и видеть её ограничения позволяет согласовать приемлемое решение с учетом текущего момента.
Чек лист последовательности проектирования базы данных
Для тех, кто ещё только делает первые шаги в проектировании баз данных будет полезна типовая последовательность выполнения работ:
- Определить таблицы объектов
- Определить атомарные поля
- Определить типы полей
- Определить первичные ключи
- Определить внешние ключи
- Определить индексы полей
- Определить уникальность полей
- Определить признаки полей null/not null
- Определить дополнительные ограничений полей
- Выполнить нормализацию до 3-й нормальной формы
- Выполнить денормализацию с учетом ограничений по производительности
Методология IDEF1Х и программный продукт ERWin
|
На основании своего опыта могу сказать, что в моем конкретном случае использование AllFusion Data Model Validator (ERwin Examiner) приведет к сокращению трудозатрат приблизительно на 1000 человеко-часов при перепроектировании и настройке баз данных моей фирмы. Билл Кларк, администратор БД компании FunMail |
В свое время компания Computer Associates в рамках серии продуктов ERwin реализовала стандарт IDEF1X.
IDEF1X является методом для разработки реляционных баз данных и использует условный синтаксис, специально разработанный для построения концептуальной схемы структуры данных предприятия, независимой от конечной реализации базы данных и аппаратной платформы.
Сущность предметной области в IDEF1X описывает собой совокупность или набор экземпляров похожих по свойствам, но однозначно отличаемых друг от друга по одному или нескольким признакам. Каждый экземпляр является реализацией сущности. Таким образом, сущность в IDEF1X описывает конкретный набор экземпляров реального мира, в отличие от сущности в IDEF1, которая представляет собой абстрактный набор информационных отображений реального мира.
Поддержка нормализации в ERWin. ERWin не содержит полного алгоритма нормализации и не может проводить нормализацию автоматически, однако его возможности облегчают создание нормализованной модели данных. В первую очередь ERwin Examiner позволяет провести инспекцию структуры базы данных на предмет соответствия её общепринятым нормам проектирования в автоматическом режиме.
AllFusion Data Model Validator 7.1 (ранее: ERwin Examiner 4.1)
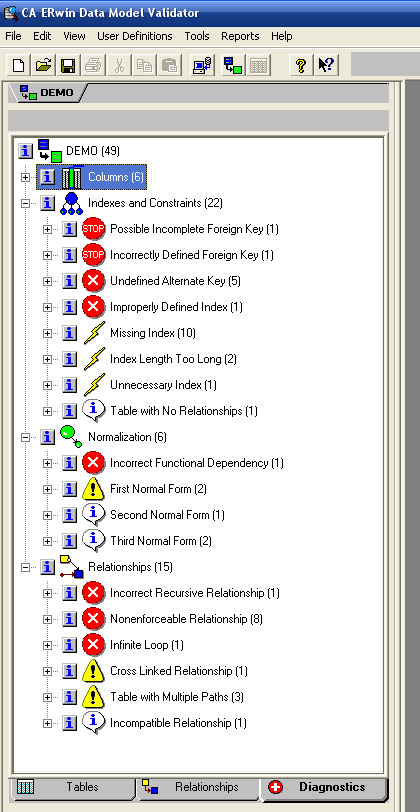
Обработка "СтруктураКонфигурацииIDEF1c.epf"
ERwin examiner позволяет провести анализ модели данных на основе экспертных данных заложенных в программу разработчиками. Не смотря на то, что средства ERwin не могут сказать как нужно делать, они могут сказать как делать не нужно. Использование средств валидации схем баз данных позволяет на собственном опыте решения практических задач впитать лучший опыт разработки.
Методология IDEF1X включает в себя графическое представление отношений между сущностями. Являясь проекцией стандарта IDEF1 на физический уровень баз данных, который позволяет вести как прямую разработку структуры базы данных в терминах конкретной СУБД так и обратный реинжениринг, методология IDEF1X позволяет переносить модели из одной СУБД в другую.
Для целей документирования структуры данных платформы 1С мной была разработана нотация IDEF1c. Простая и очевидная текстовая структура вот уже 5 лет помогает закрывать бреши в технологическом обеспечении платформы 1С. Данный инструмент не претендует на полноту - это скорее попытка начать диалог на эту тему заинтересованных разработчиков.
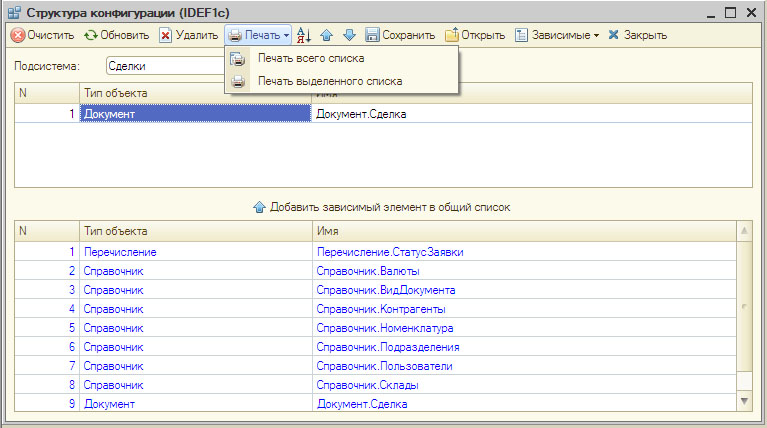
Операции:
- Подсистема - Выбор "подсистемы" для анализа объектов конфигурации. При смене подсистемы, объекты дописываются в конец списка.
- Очистить - Очистить список объектов для последующего добавления объектов конфигурации.
- Обновить - Добавить в конец списка объекты указанной подсистемы.
- Добавить зависимый элемент в общий список - Переместить из нижнего списка зависимых объектов в список объектов конфигурации для дальнейшей печати.
- Удалить - Удалить текущий объект из списка.
- Печать всего списка - Печать всего списка объектов конфигурации.
- Печать выделенного списка - Печать только выбранных элементов из списка объектов
- Сохранить - Сохранить список объектов конфигурации в xml-файле, для последующего использования
- Открыть - Загрузить спискок объектов конфигурации из xml-файла.
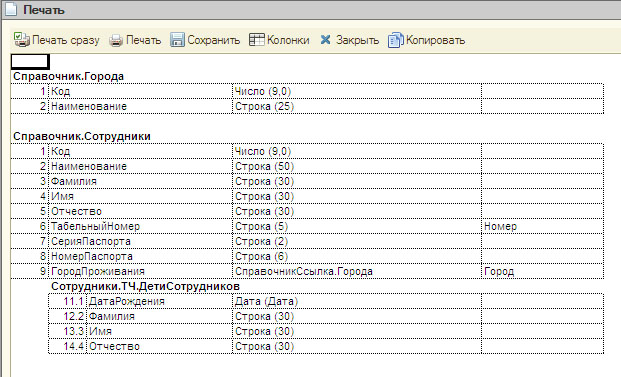
Данная обработка работает в обычной и управляемых формах, версия платформы 8.2.13.219 и выше. Может использоваться как внешняя обработка, что делает её удобным инструментом для исследовальских работ чужих конфигураций.
Вступайте в нашу телеграмм-группу Инфостарт