






{kind=link}
Итак, есть УПП версии 1.3, включенный РАУЗ и печальный факт того, что расчет себестоимости выполняется от двух часов и более. Ну и "бешенные" пользователи, которые "для проверки" запускают расчет себестоимости в конце/начеле месяца более чем часто.
Прежде чем бежать за новым железом (которое в общем и целом не виновато) и прежде чем уходить с головой в изучение индексов СУБД, можно немного оптимизировать код УПП, который позволит существенно поднять производительность.
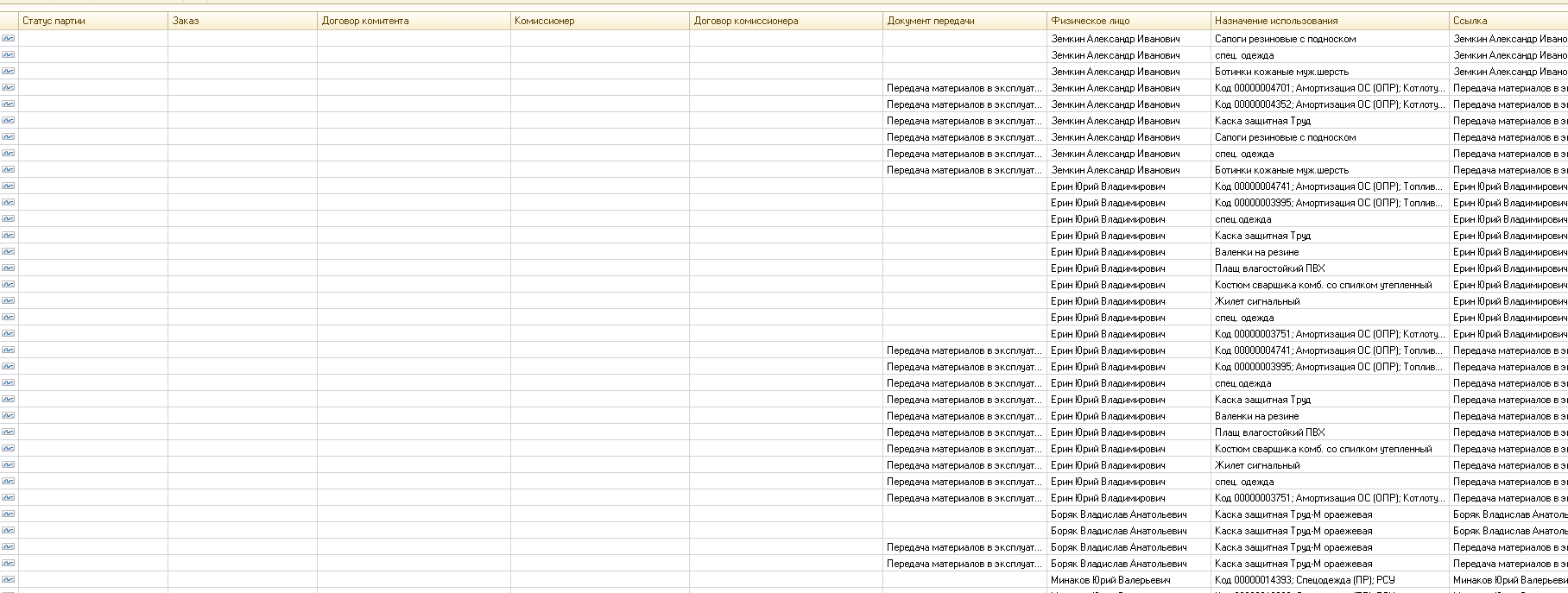
Итак, не погружаясь особо в дебри теории, просто примем за аксиому, что последовательность измерений независимого (без регистратора) регистра сведений влияет на то, как в конечном счете будут построены индексы SQL. При включенном РАУЗ и большом количестве материальных затрат используется регистр сведений "АналитикаУчетаПартий". Измерения "из коробки" выглядят следующим образом:

Если посмотреть в базу УПП и проанализировать содержимое регистра (это для моего конкретного случая, у кого-то может быть другая картина заполнения), то видно, что 80% содержания регистра занимают вот такие вот записи:

Т.е. статусы партий, заказы, договоры коминтента и т.д. не используются. Т.о. индексы которые создаются как самое 1С, так и SQL сервером в данном случае бестолковые, т.к. тратят процессорное время на то, что бы делать выборку по не заполненным полям. Поэтому, в моем случае последовательность измерений пыла переделана следующим образом:

Ну и дополнительно по измерению "ФизЛицо" необходимо включить индексирование. Собственно, вышеописанные действия по анализу содержимого регистров и перемещению измерений можно применить к регистрам сведений "АналитикаУчетаЗатрат" и "АналитикаВидаУчета". Единственное, что стоит помнить, это то что в регистре не стоит ставить галку "индексировать" более чем у 5 измерений (почему так - тоже лучше читать в специальных умных книжках).
Вышеописанные простые действия позволили ускорить расчет себестоимости выпуска на 20 минут. Это конечно хорошо, но, мало. Поэтому, следующим этапом будет небольшая оптимизация кода. Большая часть работы РАУЗ сосредоточена в общем модуле "РасширеннаяАналитикаУчета". Изучение работы документа "Расчет себестоимости" с включенным замером производительности показал, что очень большим тормозом (из-за большого количества вызовов) является функция "ЗаполненыНастройкиАналитикиУчета". Смотрим на содержимое функции:
Функция ЗаполненыНастройкиАналитикиУчета()
ТекстЗапроса = "
|ВЫБРАТЬ ПЕРВЫЕ 1
| НастройкиАналитикиУчета.Код
|ИЗ
| Справочник.НастройкиАналитикиУчета КАК НастройкиАналитикиУчета
|ГДЕ
| НастройкиАналитикиУчета.УправленческийУчет
| ИЛИ НастройкиАналитикиУчета.РегламентированныйУчет
|
|";
Запрос = Новый Запрос;
Запрос.Текст = ТекстЗапроса;
РезультатЗапроса = Запрос.Выполнить();
Возврат (Не РезультатЗапроса.Пустой());
КонецФУнкции // ЗаполненыНастройкиАналитикиУчета()
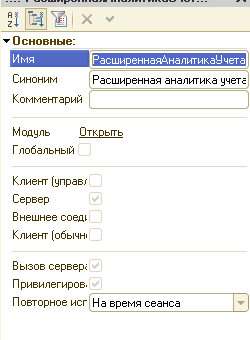
Что тут видим. у нас более 300 тыс. раз вызывается простеньких запрос к СУБД с простой выборкой. Всё это хорошо, но, это время. Нужно что-то делать. А делать мы будем повторное использование возвращаемых значений. Так же, не останавливаюсь подробно на том - что это и зачем. Можно почитать в умных книжках. Сейчас просто делаем новый общий модуль, для которого устанавливаем следуюющие свойства:

и переносим в этот модуль вышеописанную функцию (просто копипастим не забыв добавить в конец объявления процедуры директиву "экспорт"), а в типовом модуле расширенной аналитики учета делаем следующее:
Функция ЗаполненыНастройкиАналитикиУчета()
Возврат РасширеннаяАналитикаУчетаПовторноеИспользование.ЗаполненыНастройкиАналитикиУчета();
КонецФУнкции // ЗаполненыНастройкиАналитикиУчета()
Что нам это даст? А даст очень простую вещь - обращение к СУБД будет произведено только один раз. Все остальные обращения к функции "ЗаполненыНастройкиАналитикиУчета" будут приводить к тому, что возвращаемое значение будет получаться не путем обращения к SQL базе, а из кэша сервера 1С Предприятие. Дальнейшее изучение расчета седестоимости выявило то, что повторно использовать значения можно еще для двух функций "ШаблонИзмеренийКлючаАналитики" и "ПолучитьСоздатьКлючАналитики".
Вынос указанных выше функций в повторное использование вкупе с небольшой оптимизацией регистров (суть оптимизации так же описал выше) привело к тому, что расчет себестоимости при включеном РАУЗ стал занимать не 2 часа, а 5-7 минут.
Доп. информация: оптимизировал работу на УПП 1.3.49.2.
Созданный модуль "РасширеннаяАналитикаУчетаПовторноеИспользование" имеет следующие функции (настройки модуля на картинке выше):
Функция ЗаполненыНастройкиАналитикиУчета() экспорт
ТекстЗапроса = "
|ВЫБРАТЬ ПЕРВЫЕ 1
| НастройкиАналитикиУчета.Код
|ИЗ
| Справочник.НастройкиАналитикиУчета КАК НастройкиАналитикиУчета
|ГДЕ
| НастройкиАналитикиУчета.УправленческийУчет
| ИЛИ НастройкиАналитикиУчета.РегламентированныйУчет
|
|";
Запрос = Новый Запрос;
Запрос.Текст = ТекстЗапроса;
РезультатЗапроса = Запрос.Выполнить();
Возврат (Не РезультатЗапроса.Пустой());
КонецФУнкции // ЗаполненыНастройкиАналитикиУчета()
Функция ШаблонИзмеренийКлючаАналитики(ИмяРегистра) экспорт
ТекстЗапроса = "
|ВЫБРАТЬ
| НастройкиАналитикиУчета.УправленческийУчет КАК УпрУчет,
| НастройкиАналитикиУчета.РегламентированныйУчет КАК РеглУчет,
| НастройкиАналитикиУчета.ЗначениеПоУмолчанию КАК Значение,
| НастройкиАналитикиУчета.Код КАК Измерение
|ИЗ
| Справочник.НастройкиАналитикиУчета КАК НастройкиАналитикиУчета
|ГДЕ
| НастройкиАналитикиУчета.Родитель = &Родитель
| И НастройкиАналитикиУчета.Предопределенный
| И (Не НастройкиАналитикиУчета.ЭтоГруппа)
|
|УПОРЯДОЧИТЬ ПО
| НастройкиАналитикиУчета.Наименование
|
|";
Запрос = Новый Запрос;
Запрос.Текст = ТекстЗапроса;
Запрос.УстановитьПараметр("Родитель", Справочники.НастройкиАналитикиУчета[ИмяРегистра]);
РезультатЗапроса = Запрос.Выполнить();
Возврат РезультатЗапроса.Выгрузить();
КонецФункции
// Экспериментальный вызов. Может так случиться, что или глюков добаваит, или
// требуемого прироста производительности не даст. Если что, нужно отменить вызов данной процедуры
// из модуля расчиренной аналитики и раскомментироватьс тарый код и закомментировать новый.
Функция ПолучитьКлючАналитики (ИмяРегистра, СтруктураИзмерений) экспорт
МенеджерЗаписи = РегистрыСведений[ИмяРегистра].СоздатьМенеджерЗаписи();
ЗаполнитьЗначенияСвойств(МенеджерЗаписи, СтруктураИзмерений);
МенеджерЗаписи.Прочитать();
Если МенеджерЗаписи.Выбран() Тогда
Возврат МенеджерЗаписи.Ссылка;
Иначе
Возврат неопределено;
конецЕсли;
КонецФункции
Измененные функции модуля "РасширеннаяАналитикаУчета"
Функция ЗаполненыНастройкиАналитикиУчета()
// -- Begin -- Sokolov_DN -- 20141005
// Для уменьшения тормозов: можно вызов засунуть в повторное использование и читать из кэша.
// Всё равно вызов непараметризуемый
Возврат РасширеннаяАналитикаУчетаПовторноеИспользование.ЗаполненыНастройкиАналитикиУчета();
// -- End -- Sokolov_DN -- 20141005
КонецФУнкции // ЗаполненыНастройкиАналитикиУчета()
Функция ШаблонИзмеренийКлючаАналитики(
ИмяРегистра,
СтруктураКлючиАналитики
)
Перем ШаблонИзмерений;
ИмяСтруктурыИзмерений = "Шаблон" + ИмяРегистра;
Если СтруктураКлючиАналитики = Неопределено
ИЛИ Не СтруктураКлючиАналитики.Свойство(ИмяСтруктурыИзмерений, ШаблонИзмерений) Тогда
Если Не ЗаполненыНастройкиАналитикиУчета() Тогда
ЗаполнитьНастройкиАналитикиПоШаблону();
КонецЕсли;
Если ИмяРегистра = "АналитикаУчетаПрочихЗатрат" Тогда
ШаблонИзмерений = ШаблонИзмеренийИзМакета(ИмяРегистра);
Иначе
// -- Begin -- Sokolov_DN -- 20141005
// Для уменьшения тормозов: можно вызов засунуть в повторное использование и читать из кэша.
// постоянно выбираем из фиксированного справочника, поэтому лучше закэшировать и оставить базу в покое
ШаблонИзмерений = РасширеннаяАналитикаУчетаПовторноеИспользование.ШаблонИзмеренийКлючаАналитики(ИмяРегистра);
// -- End -- Sokolov_DN -- 20141005
КонецЕсли;
Индексы = ШаблонИзмерений.Индексы;
Индексы.Добавить("УпрУчет");
Индексы.Добавить("РеглУчет");
Если СтруктураКлючиАналитики <> Неопределено Тогда
СтруктураКлючиАналитики.Вставить(ИмяСтруктурыИзмерений, ШаблонИзмерений);
КонецЕсли;
КонецЕсли;
Возврат ШаблонИзмерений;
КонецФункции // ШаблонИзмеренийКлючаАналитики()
Функция ПолучитьСоздатьКлючАналитики(
СтруктураИзмерений,
МассивИзмерений,
ИмяСправочника,
ИмяРегистра,
СтруктураКлючиАналитики
)
ЭлементКлючАналитики = Неопределено;
// Попробуем получить ключ аналитики из кэша.
Если СтруктураКлючиАналитики <> Неопределено Тогда
ЭлементКлючАналитики = ПолучитьКлючАналитикиИзТаблицы(
СтруктураИзмерений,
ИмяРегистра,
СтруктураКлючиАналитики
);
КонецЕсли;
Если Не ЗначениеЗаполнено(ЭлементКлючАналитики) Тогда
// Возвращаем пустую ссылку на ключ аналитики затрат, если все измерения не заполнены,
// так как такая логика (указывать пустую ссылку) предусмотрена при формировании движений
// в общем модулей УправлениеПроизводствомДвиженияПоРегистрам
Если ИмяРегистра = "АналитикаУчетаЗатрат" Тогда
ЕстьЗаполненныеИзмерения = Ложь;
Для Каждого Измерение Из СтруктураИзмерений Цикл
ЕстьЗаполненныеИзмерения = ЕстьЗаполненныеИзмерения ИЛИ ЗначениеЗаполнено(Измерение.Значение);
КонецЦикла;
Если НЕ ЕстьЗаполненныеИзмерения Тогда
Возврат Справочники[ИмяСправочника].ПустаяСсылка();
КонецЕсли;
КонецЕсли;
// -- Begin -- Sokolov_DN -- 20141005
// нижестоящий кусочек так же закэшируем. Посмотрим: какой прирост будет
ЭлементКлючАналитики = РасширеннаяАналитикаУчетаПовторноеИспользование.ПолучитьКлючАналитики(ИмяРегистра,СтруктураИзмерений);
Если ЭлементКлючАналитики = неопределено тогда
// -- End -- Sokolov_DN -- 20141005
// Заполним измерения регистра, т.к. после чтения они пустые.
// -- Begin -- Sokolov_DN -- 20141005
//А вот тут таки надо убранный выше менеджер сделать
МенеджерЗаписи = РегистрыСведений[ИмяРегистра].СоздатьМенеджерЗаписи();
ОбновитьПовторноИспользуемыеЗначения();
// -- End -- Sokolov_DN -- 20141005
// Заполним измерения регистра, т.к. после чтения они пустые.
ЗаполнитьЗначенияСвойств(МенеджерЗаписи, СтруктураИзмерений);
// Создадим новый элемент справочника - ключ аналитики.
СправочникОбъект = Справочники[ИмяСправочника].СоздатьЭлемент();
СправочникОбъект.Наименование = ПолучитьПолноеНаименованиеКлючаАналитики(
МассивИзмерений,
МенеджерЗаписи
);
СправочникОбъект.Записать();
ЭлементКлючАналитики = СправочникОбъект.Ссылка;
МенеджерЗаписи.Ссылка = ЭлементКлючАналитики;
МенеджерЗаписи.Записать(Ложь);
КонецЕсли;
// Добавим новый ключ аналитики в кэш.
Если СтруктураКлючиАналитики <> Неопределено Тогда
ДобавитьКлючАналитикиВТаблицу(
СтруктураИзмерений,
ИмяРегистра,
ЭлементКлючАналитики,
СтруктураКлючиАналитики
);
КонецЕсли;
КонецЕсли;
Если ЭлементКлючАналитики = Неопределено Тогда
ЭлементКлючАналитики = Справочники[ИмяСправочника].ПустаяСсылка();
КонецЕсли;
Возврат ЭлементКлючАналитики;
КонецФункции // ПолучитьСоздатьКлючАналитики()
Вступайте в нашу телеграмм-группу Инфостарт