






{kind=link}
1. Настройка сервера
Во-первых нам нужен только сервер, остальные службы, которые к нему относятся и возможно кто-то ими пользуется, нам только тормозят работу. Останавливаем и отключаем такие службы, как FullText Search (у 1С собственный механизм полнотекстового поиска), Integration Services и иже с ними.
Оставляем только:
SQL Server (sqlservr.exe)
SQL Server Agent (SQLAGENT.exe)
SQL Writer (sqlwriter.exe)
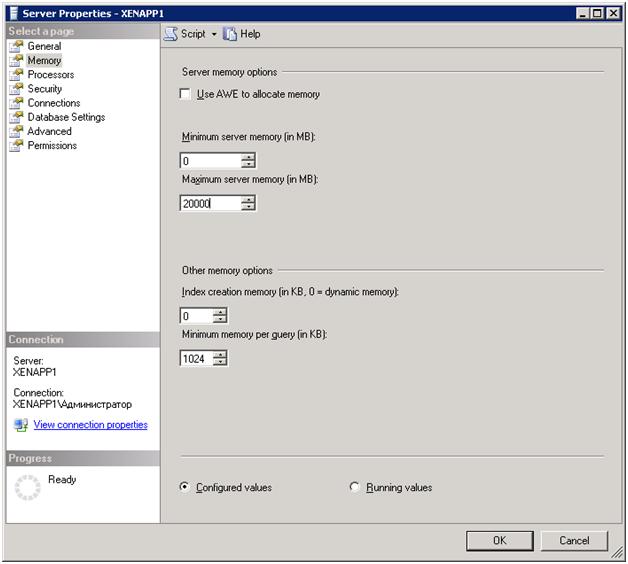
Далее в свойствах сервера, через Server Management Studio устанавливаем:

Максимально отведенное серверу количество памяти из расчета:
[Общее количество оперативной памяти сервера] – [4ГБ под систему(2ГБ если Win2003)] – [1,5 ГБ * количество процессов rphost (если SQL и 1С на одном сервере вращаются.)] Например если у нас на сервере всего 36 ГБ оперативной памяти, стоит Windows 2008 и запущено 8 процессов rphost то рассчет идет так: 36 - 4 - 1.5*8 = 20 ГБ ставим ограничение для SQL.
Это необходимо для того, чтобы sql сервер рассчитывал на этот объем и чистил память заблаговременно, т.к. если поставить неограниченный объем, и сервер попробует получить память, которой нет, он начинает крепко задумываться над своим поведением и крайне медленно отвечать на запросы.
Далее:

Максимальное количество потоков (Maximum worker threads) ставим 2048, по умолчанию стоит 0 и с таким значением сервер не создает больше 255 потоков, а этого ему не хватает (установлено опытным путем, что при большом количестве одновременных транзакций сервер реально начинает быстрее работать). Также выставляем галку повышенного приоритета сервера (Boost priority).
Собственно с глобальными настройками все. Теперь переходим к настройкам рабочей базы данных (или нескольких баз, если такое имеет место быть).
2. Настройка рабочей базы данных
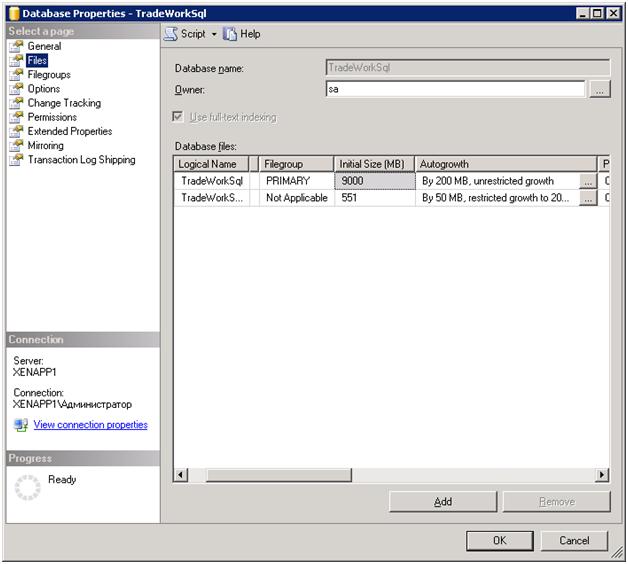
Заходим в свойства нужной нам базы данных:

Если база еще не развернута из .dt файла, и вы знаете примерный ее размер, то первичному файлу размер инициализации лучше сразу указать >= размера базы, но это дело вкуса, он все равно вырастет при развертке. А вот Автоувеличение размера надо обязательно указать примерно по 200 МБ на базу и по 50 МБ на лог, т.к. значения по умолчанию – рост по 1МБ и по 10% очень сильно тормозят работу сервера, когда ему при каждой 3й транзакции надо файл увеличивать. Также, если не используетет RAID массив, то хранение файла базы и файла лога лучше указать на разных физических дисках. Ну и ограничить лог 2-4 ГБ, чтоб сильно не пух.
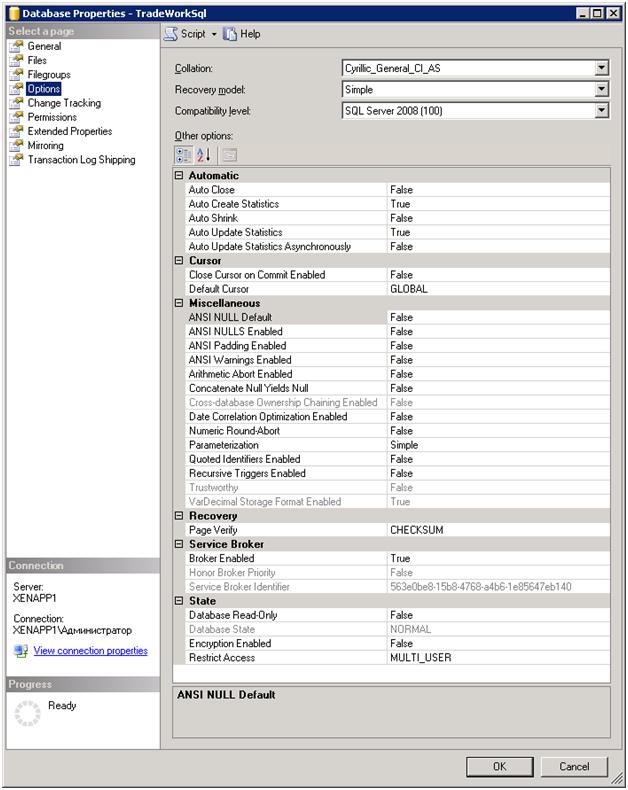
Остальные настройки как на скришоте:

С настройками базы все. Осталось настроить регламентные задания.
3. Настройка регламентных заданий
Сначала создаем Maintenance Plan в разделе Management:

Дефрагментацию индексов и сбор статистики нужно производить ежедневно, т.к. если фрагментированость индексов > 25%, это резко снижает производительность сервера. Дефрагментация и обновление статистики делается быстро и не требует отключения пользователей. Насколько ваши индексы фрагментированы можно посмотреть очень хорошей и многофункциональной обработкой Гилева Вячаслава, с названием Lock1C.epf, и которую он убрал со своего сайта из-за наезда 1С-ников за нарушение какого-то пункта лицензионного с., но хорошему админу гугл всегда в помощь J . Также желательно делать полную переиндексацию, с блокировкой БД, хотя бы раз в неделю, естественно после полной переиндексации сразу же делается дефрагментация индексов и обновление статистики.
Настройка бэкапа средствами SQL.
Ту все просто, добавляем 2 новых задания Agent'у:
Full BackUp, с периодичностью 1 раз в сутки и 2мя шагами T-SQL скриптов:
1. BACKUP DATABASE [<ИмяБД>] TO DISK = N'<ПутьКПапке>\Backup\<ИмяБД>.bak' WITH NOFORMAT, INIT, NAME = N'<ИмяБД>-Full Database Backup', SKIP, NOREWIND, NOUNLOAD, STATS = 10
GO
2. USE [<ИмяБД>]
GO
DBCC SHRINKFILE (N'<ИмяБД>_log' , 0)
GO
И второе задание с периодичностью 1 раз в 1-2 часа Differencial BackUp и с одним T-SQL скриптом:
BACKUP DATABASE [<ИмяБД>] TO DISK = N'<ПутьКПапке>\Backup\<ИмяБД>Diff.bak' WITH DIFFERENTIAL , NOFORMAT, INIT, NAME = N'<ИмяБД>-Differential Database Backup', SKIP, NOREWIND, NOUNLOAD, STATS = 10
GO
Такой бэкап делается, даже при активной работе пользователей, 4-6 минут и практически не сказывается на быстродействии сервера.
Да, и добавим очистку процедурного после переиндексации (раз в неделю), в задание, кторое у же появилось в агенте после сохранения Maintenance Plan добавляем еще один шаг:
DBCC FREEPROCCACHE
GO
Не забыв поменять в настройках первого шага после завершения не выходить, а перейти к следующему. Спс gilv за подсказку.
Вот, собственно, и все. По поводу бэкапа средствами 1С: //infostart.ru/public/65849/ - Full BackUp и выгрузку 1С можно делать одновременно.

DatabaseCompressionTool — сжатие и свертка любой базы 1С
Инструмент DatabaseCompressionTool (DCT) позволяет безопасно сжать и свернуть любую базу 1С, освободив сотни гигабайт и увеличив производительность системы. Доступна демо-версия для оценки эффективности.

Вступайте в нашу телеграмм-группу Инфостарт