
{kind=link}
Изначально стало понятно, что входящих документов много разных видов, и каждый вид документа нужно обрабатывать, согласно индивидуальному сценарию, последовательно выполняя операции над файлами на каждом из следующих этапов используя результат предыдущих шагов.
Сначала, согласно универсальной таблице оценки задач сначала показалось что это "изъян", однако в итоге это оказалось - что "вроде изъян".
Изначально задача стояла такая, есть сканы документов, необходимо данные сканы привязать к карточкам документов.
Есть документы которые исходящие и печатаются в наших системах, на них мы можем разместить штрих код;
Есть документы входящие, для поступающих документов, на которые можно наклеить штрих код внеся
информацию по нему, в систему, для последующей автоматической обработки.
Однако был уже большой архив документов, которые не имели штрих кода.
Обратив внимание как сотрудники привязывают эти документы, была высказана гипотеза, что это можно сделать сильно проще.
Задачи распознавать табличные части документов у нас не стояло, по этому коммерческое на Adobe Flexicapture, мы внимательно посмотрели, и оставили до лучших времен.
Мы для себя поставили задачу что нам достаточно 95 процентов документов, привязанных автоматически,
для тех документов, которые у нас реализовано удобное рабочее место для обработки документов.
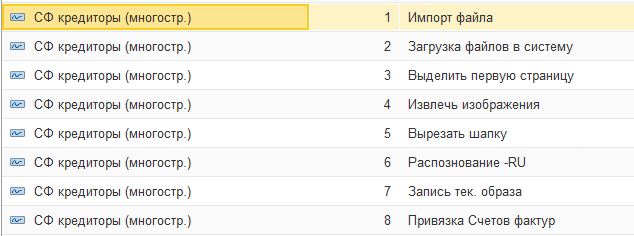
Примеры шагов, которые были реализованы:
- Импорт файлов в систему;
- Разбиение файлов на страницы;
- Извлечение первой страницы из файла;
- Извлечение изображений из PDF;
- Преобразование PDF в JPG;
- Вырезать область документа;
- Извлечение текста из изображения;
- Извлечение реквизитов документа из текстового образа документа;
- Выполнение привязки документов по реквизитам;
- Распознавание штрих кода;
Пример готового сценария:

Что и как можно использовать, для реализации данных шагов:
У всех приложений справка вызывается, стандартным ключом: -h или -help;
1. Image Magic - всем известный консольный редактор, может много чего;
справка достаточно подробная; заострять внимание надолго не буду информации в сети много:
Пример команды:
convert.exe $Источник -rotate 180 -trim -crop 1800x600+50+50 -resize 150%% $Получатель
Параметры:
- rotate - поворот на N количество градусов;
- crop - команда обрезки изображений, в формате Ширина x Высота + Отступ слева + отступ сверху;
- resize - увеличение на процент;
- trim - обрезать пустые области;
2. X-PDF tools - группа приложений позволяющих производить определенные операции;
Сайт проекта: https://www.xpdfreader.com/download.html
Состав:
pdfinfo - получает информацию о pdf файле;
pdftotext - если в PDF есть текстовый слой, то его можно извлечь данным приложением;
pdfimages - если в PDF есть изображения, как например скан документа - в этом случае можно извлечь данное изображение, не применяя Image Magic, по скорости выше, и без изменения картинки;
pdftopng - аналогично по функциональности тому что делает ImageMagick, преобразует из PDF в цельную картинку, но мне как то лучше зашло, не удалось добиться от ImageMagick вменяемого преобразования в pdf, что бы хорошо распознавался текст, может я в танке, может ImageMagick , но данная приблуда проблему решила;
pdftohtml - преобразует pdf в html, нормально преобразует только pdf с текстовым слоем, это когда надо извлечь не только текст, но и сохранить структуру файла;
Примеры:
pdfimages -j $Источник $Получатель
Параметр -j - задает сохранение в jpeg;
pdftopng $Источник $Получатель
3. TESSERACT OCR - вот это вообще пуля, не серебряная жаль,
однако тег #распознавание текста с изображений, бесплатно без смс и регистрации, скачать онлайн
поставить можно.
Результат стабильно хороший, я в ему почти всегда даю шапки документов, затем
извлекаю дату, номер и инн, в абсолютных числах что к чему не скажу - лень матушка цифры собирать, но по ощущениям, процентов 98 реквизитов распознается доступно для извлечения регулярками;
Сайт проекта: https://github.com/tesseract-ocr/tesseract/wiki
Пример запуска:
Английский: "tesseract.exe" $Источник $Получатель
Русский: "tesseract.exe" $Источник $Получатель -l rus
Если кому то надо, что бы было куда жаловаться на результаты, то тогда вполне можно использовать, это:
но это за денежку, но можно жаловаться.
4. PDFTK - используется для разделения или объединения файлов на страницы;
Сайт проекта: https://www.pdflabs.com/tools/pdftk-the-pdf-toolkit/
pdftk $Источник cat 1 output $Получатель - извлечь первую страницу;
pdftk $Источник burst output $Получатель - разбить pdf на страницы;
pdftk $КаталогФайлов *.pdf cat output $Получатель - склеить все файлы из каталога в один файл;
5. Распознавание штрих кодов;
Использовал, компоненту из публикации: //infostart.ru/public/877003/
Сайт проекта на Github, там можно посмотреть какие есть еще параметры.
https://github.com/zxing/zxing
Ахтунг ахтунг: требуется установленная Java!
Приведу пример запуска, может кому пригодится: