
Предыдущая статья на тему фоновой обработки данных, в основном описывала механизм отслеживания выполнения процесса обработки. В этой статье я предлагаю Вашему вниманию дальнейшее ее развитие - многопоточную обработку данных на примере перепроведения документов. Фоновые процессы, также как и в первом варианте, запускаются из модуля внешней обработки, так что обработка должна быть добавлена через механизм дополнительных отчетов и обработок. Отслеживание процесса тоже присутствует, но оно не является главным предметом статьи.
Общее описание механизма
Процесс начинается с запуска основного фонового задания (такой упрощенный менеджер потоков), в которое передаются все необходимые параметры. Далее формируется выборка объектов для обработки (документов). Выполняется обход выборки и выбирается первая порция документов (согласно переданному параметру «КоличествоДокументовВПорции»).
Затем происходит разбивка порции документов на независимые наборы, которые могут обрабатываться параллельно, не мешая друг другу. Именно этот момент самый интересный.
Далее выполняется запуск необходимого количества потоков для обработки каждого набора документов (согласно переданному параметру «КоличествоПотоков»).
После запуска всех потоков, в цикле происходит получение состояния фоновых заданий потоков, принимаются сообщения и прогресс выполнения от фоновых заданий и перенаправляются основному сеансу для вывода пользователю.
После завершения выполнения всех фоновых заданий выбирается следующая порция документов, и так далее, пока не будут обработаны все документы.
Самым интересным шагом в данной последовательности является деление выбранной порции на наборы не связанных друг с другом документов. Сразу оговорюсь, мой вариант не является окончательным. Он скорее показывает, как можно решить подобную задачу, и является плацдармом для дальнейшего развития механизма. На некоторых из тестируемых баз он позволяет создать достаточно ровную разбивку, на некоторых большая часть документов попадают в первый или во второй набор. Для реального проекта конечно следует использовать более сложную и «умную» разбивку.
Суть моей разбивки следующая. Не допускается попадание в разные наборы документов, которые создают движения по одним и тем же комбинациям измерений: номенклатура + характеристика + склад. Причем важны как приходные так и расходные документы, так как важно соблюсти последовательность проведения в рамках выше указанных измерений.
Сразу о минусах моей разбивки
- Разбивка выполняется по данным регистра «Товары организаций», следовательно, она актуальна только для конфигураций из семейства ЕРП (ЕРП, КА, УТ).
- В моем примере документы обязательно должны быть проведены, так как выборка формируется по данным регистра «Товары организаций» и используются элементы справочника «КлючиАналитикиУчетаНоменклатуры». Если исходные документы не проведены, выборку необходимо формировать другим способом.
- Учитываются только возможное пересечение товарного состава. Можно учитывать еще и пересечения по партнерам и договорам для документов закупки и реализации.
- Для определения зависимостей я использую элементы справочника «КлючиАналитикиУчетаНоменклатуры». В моем примере не ведется учет по сериям и обособленный учет товаров. Поэтому ключи аналитики как раз и являются объектами разделения по указанным выше измерениям. Если учет по сериям или обособленный учет присутствуют, ключи аналитики получаются с более детальной разбивкой, и опираться на них не совсем правильно. Регистр накопления «Свободные остатки», имеет среди измерений только: номенклатура, характеристика и склад. Если в разные наборы попадут документы с разными ключами аналитики, но с одинаковыми наборами измерений: номенклатура, характеристика и склад, будут возможны пересечения.
Реализация
Код модуля формы я приводить не будут, концептуально он не отличается от кода модуля формы из предыдущей статьи. В форме задается период и значения параметров: КоличествоДокументовВПорции, КоличествоПотоков. Также динамически создаются прогрессы выполнения отдельных потоков согласно параметру «КоличествоПотоков», для более удобного отслеживания выполнения. Прогрессы отображают состояния выполнения потоков и обрабатываемый документ в текущей порции. По состоянию общего (первого) прогресса можно судить об общем проценте выполнения задачи:
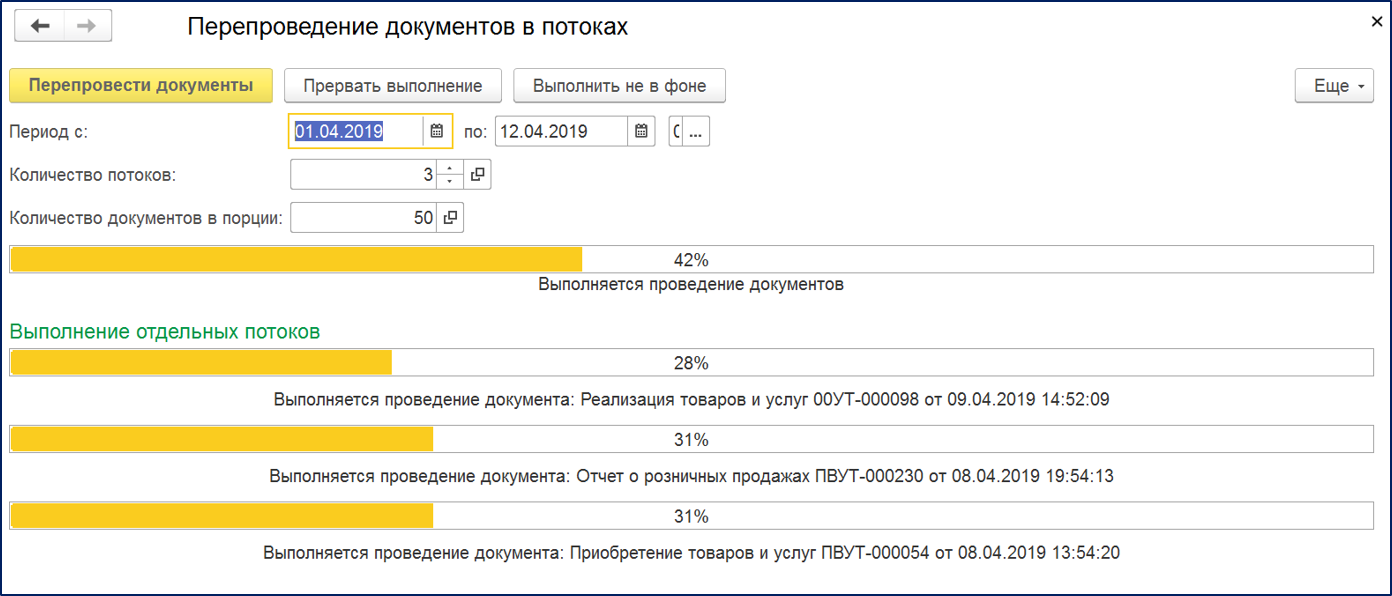
Процедуры модуля обработки
Не буду приводить код процедур: «СведенияОВнешнейОбработке»и «ВыполнитьКоманду». В них ничего особенного нет. Отмечу только, что относительно предыдущего варианта появилась дополнительная команда «ВыполнениеПотокаВФоне». Она необходимо для запуска отдельных потоков из основного фонового задания (менеджера потоков).
Точка входа основного фонового задания, это процедура «ВыполнитьПерепроведениеВПотоках»
Процедура ВыполнитьПерепроведениеВПотоках(ДатаНачала, ДатаОкончания, КоличествоПотоков, КоличествоДокументовВПорции)
Запрос = новый Запрос("ВЫБРАТЬ
| КОЛИЧЕСТВО(РАЗЛИЧНЫЕ ТоварыОрганизаций.Регистратор) КАК ВсегоДокументов
|ИЗ
| РегистрНакопления.ТоварыОрганизаций КАК ТоварыОрганизаций
|ГДЕ
| ТоварыОрганизаций.Период >= &ДатаНачала
| И ТоварыОрганизаций.Период <= &ДатаОкончания
| И НЕ ТоварыОрганизаций.Регистратор ССЫЛКА Документ.ПередачаТоваровМеждуОрганизациями
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| ТоварыОрганизаций.АналитикаУчетаНоменклатуры КАК Аналитика,
| ТоварыОрганизаций.Регистратор КАК Документ,
| ТоварыОрганизаций.Период КАК Период
|ИЗ
| РегистрНакопления.ТоварыОрганизаций КАК ТоварыОрганизаций
|ГДЕ
| ТоварыОрганизаций.Период >= &ДатаНачала
| И ТоварыОрганизаций.Период <= &ДатаОкончания
| И НЕ ТоварыОрганизаций.Регистратор ССЫЛКА Документ.ПередачаТоваровМеждуОрганизациями
|
|СГРУППИРОВАТЬ ПО
| ТоварыОрганизаций.АналитикаУчетаНоменклатуры,
| ТоварыОрганизаций.Регистратор,
| ТоварыОрганизаций.Период
| УПОРЯДОЧИТЬ ПО
| Период,
| Документ");
Запрос.УстановитьПараметр("ДатаНачала", НачалоДня(ДатаНачала));
Запрос.УстановитьПараметр("ДатаОкончания", КонецДня(ДатаОкончания));
Результат = Запрос.ВыполнитьПакет();
Выборка = Результат[0].Выбрать();
Выборка.Следующий();
ВсегоДокументов = Выборка.ВсегоДокументов;
ТЗСвязи = Результат[1].Выгрузить();
//Новая таблица для данных текущей порции
ТЗСвязиВПорции = новый ТаблицаЗначений;
ТЗСвязиВПорции.Колонки.Добавить("Аналитика", новый ОписаниеТипов("СправочникСсылка.КлючиАналитикиУчетаНоменклатуры"));
ТЗСвязиВПорции.Колонки.Добавить("Документ");
ТЗСвязиВПорции.Колонки.Добавить("Период", новый ОписаниеТипов("Дата"));
ТЗСвязиВПорции.Колонки.Добавить("ЭтоПриход", новый ОписаниеТипов("ВидДвиженияНакопления"));
ДокументовВТекПорции = 0;
ТекущийДокумент = Неопределено;
НомерПорции = 0;
Для каждого СтрокаСвязи Из ТЗСвязи Цикл
Если ТекущийДокумент <> СтрокаСвязи.Документ Тогда
//Если количество документов равно размеру порции, выполняем обработку данных
Если ДокументовВТекПорции = КоличествоДокументовВПорции Тогда
НомерПорции = НомерПорции + 1;
ОбработатьПорциюДокументов(ТЗСвязиВПорции, КоличествоПотоков, ДокументовВТекПорции);
ДлительныеОперации.СообщитьПрогресс(Формат(КоличествоДокументовВПорции*НомерПорции/ВсегоДокументов*100, "ЧЦ=3; ЧДЦ="), "Выполняется проведение документов, порция: "+Строка(НомерПорции+1));
ТЗСвязиВПорции.Очистить();
ДокументовВТекПорции = 0;
ТекущийДокумент = Неопределено;
КонецЕсли;
ТекущийДокумент = СтрокаСвязи.Документ;
ДокументовВТекПорции = ДокументовВТекПорции + 1;
КонецЕсли;
НоваяСтрока = ТЗСвязиВПорции.Добавить();
ЗаполнитьЗначенияСвойств(НоваяСтрока, СтрокаСвязи);
КонецЦикла;
//Обработка последней порции документов
ОбработатьПорциюДокументов(ТЗСвязиВПорции, КоличествоПотоков, ДокументовВТекПорции);
КонецПроцедуры
В процедуре формируется выборка из регистра «Товары организаций» в разрезе регистраторов и ключей аналитики номенклатуры. Выполняется сортировка выборки по периоду и регистратору. Далее происходит обход выборки и формирование новой таблицы значений «ТЗСвязиВПорции», в которую помещаются данные для текущей порции. Когда количество документов равняется параметру «КоличествоДокументовВПорции», вызывается процедура «ОбработатьПорциюДокументов». Затем обход продолжается и формируется следующая порция и так далее для всей исходной выборки.
Процедура ОбработатьПорциюДокументов(ТЗСвязиВПорции, КоличествоПотоков, ВсегоДокументов)
ДанныеДляПотоков = новый Массив;
СтрокаРаспределения = "";
Для Поток = 1 По КоличествоПотоков Цикл
СписокДокументов = ПолучитьДокументыДляПотока(ТЗСвязиВПорции, Поток=КоличествоПотоков, ВсегоДокументов/КоличествоПотоков);
СтруктураДокументов = новый Структура;
СтруктураДокументов.Вставить("ИмяПотока", "Поток "+Строка(Поток));
СтруктураДокументов.Вставить("Документы", СписокДокументов);
ДанныеДляПотоков.Добавить(СтруктураДокументов);
Если НЕ СтрокаРаспределения = "" Тогда
СтрокаРаспределения = СтрокаРаспределения + "; ";
КонецЕсли;
СтрокаРаспределения = СтрокаРаспределения + "Поток "+Строка(Поток)+": "+СписокДокументов.Количество();
КонецЦикла;
Сообщить(СтрокаРаспределения);
ЗапуститьВыполнениеВПотоках(ДанныеДляПотоков);
КонецПроцедуры
Для каждого потока выполняется вызов функции «ПолучитьДокументыДляПотока». Полученные данные помещаются в структуру. Формируется массив структур данных для выполнения в потоках. В информационных целях формируется строка распределения документов по потокам и отправляется основному сеансу. После того, как сформированы все данные вызывается процедура «ЗапуститьВыполнениеВПотоках» для запуска фоновых заданий.
Функция ПолучитьДокументыДляПотока(ТЗСвязи, ЭтоПоследнийПоток, КоличествоДокументовВПотоке)
СписокДокументов = новый ТаблицаЗначений;
СписокДокументов.Колонки.Добавить("Документ");
СписокДокументов.Колонки.Добавить("Период", новый ОписаниеТипов("Дата"));
//Для последнего потока выбираются все оставщиеся документы
Если ЭтоПоследнийПоток Тогда
СписокДокументов = ТЗСвязи.Скопировать();
СписокДокументов.Свернуть("Документ,Период");
Возврат СписокДокументов;
КонецЕсли;
НомерЦепочкиДокументв = 0;
Пока ИСТИНА Цикл
Если СписокДокументов.Количество() > КоличествоДокументовВПотоке
ИЛИ НомерЦепочкиДокументв = 1 И СписокДокументов.Количество()/КоличествоДокументовВПотоке > 0.7
ИЛИ НомерЦепочкиДокументв = 2 И СписокДокументов.Количество()/КоличествоДокументовВПотоке > 0.80
ИЛИ НомерЦепочкиДокументв = 3 И СписокДокументов.Количество()/КоличествоДокументовВПотоке > 0.85
ИЛИ НомерЦепочкиДокументв = 4 И СписокДокументов.Количество()/КоличествоДокументовВПотоке > 0.90
ИЛИ НомерЦепочкиДокументв >= 5 И СписокДокументов.Количество()/КоличествоДокументовВПотоке > 0.95 Тогда
Прервать;
КонецЕсли;
Если ТЗСвязи.Количество() > 0 Тогда
//Выборка первого документа
ПервыйДокумент = ТЗСвязи[0].Документ;
НоваяСтрока = СписокДокументов.Добавить();
НоваяСтрока.Документ = ТЗСвязи[0].Документ;
НоваяСтрока.Период = ТЗСвязи[0].Период;
ТЗСвязи.Удалить(ТЗСвязи[0]);
//Поиск аналитик по документу
СтрокиДокумента = ТЗСвязи.НайтиСтроки(новый Структура("Документ", ПервыйДокумент));
РекурсивныйПоискДокументов(СтрокиДокумента, СписокДокументов, ТЗСвязи);
Иначе
Прервать;
КонецЕсли;
НомерЦепочкиДокументв = НомерЦепочкиДокументв + 1;
КонецЦикла;
Возврат СписокДокументов;
КонецФункции
Процедура РекурсивныйПоискДокументов(СтрокиДокумента, СписокДокументов, ТЗСвязи)
МассивАналитик = новый СписокЗначений;
Для Каждого СтрокаДокумента Из СтрокиДокумента Цикл
МассивАналитик.Добавить(СтрокаДокумента.Аналитика, СтрокаДокумента.ЭтоПриход);
ТЗСвязи.Удалить(СтрокаДокумента);
КонецЦикла;
//Обход всех аналитик и поиск документов с этими аналитиками
Для Каждого Аналитика Из МассивАналитик Цикл
ДокументыПоАналитики = ТЗСвязи.НайтиСтроки(новый Структура("Аналитика", Аналитика.Значение));
Если ДокументыПоАналитики.Количество() = 0 Тогда
Продолжить;
КонецЕсли;
НайденныйСписокДокументов = новый Массив;
//Обход всех документов и добавление их в набор
Для Каждого ДокументПоАналитике Из ДокументыПоАналитики Цикл
Если СписокДокументов.Найти(ДокументПоАналитике.Документ, "Документ") = Неопределено Тогда
НайденныйСписокДокументов.Добавить(ДокументПоАналитике.Документ);
НоваяСтрока = СписокДокументов.Добавить();
ЗаполнитьЗначенияСвойств(НоваяСтрока, ДокументПоАналитике);
КонецЕсли;
ТЗСвязи.Удалить(ДокументПоАналитике);
КонецЦикла;
//Рекурсивный вызов поиска для каждого найденного документа
Для Каждого ДокументПоАналитике Из НайденныйСписокДокументов Цикл
СтрокиДокумента = ТЗСвязи.НайтиСтроки(новый Структура("Документ", ДокументПоАналитике));
Если СтрокиДокумента.Количество() > 0 Тогда
РекурсивныйПоискДокументов(СтрокиДокумента, СписокДокументов, ТЗСвязи);
КонецЕсли;
КонецЦикла;
КонецЦикла;
КонецПроцедуры
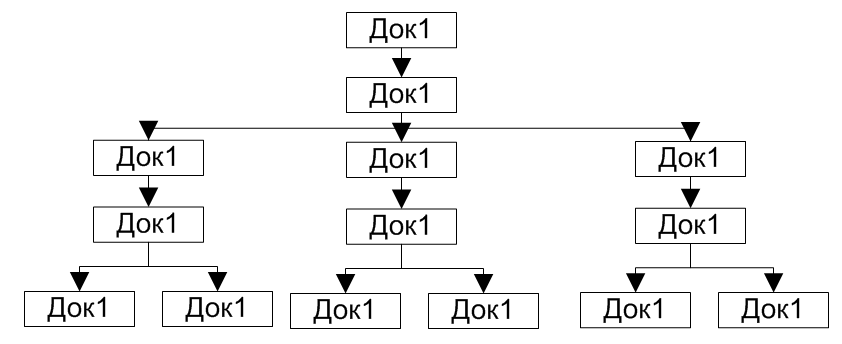
В этих двух процедурах происходит выборка набора связанных документов из порции. На самом деле, все очень просто.
Выбирается первый документ:
Документ записывается в список набора документов, строка удаляется из порции.
Выбираются аналитики учета по номенклатуре для выбранного документа:
Строки удаляются из порции.
Для каждой аналитики выбираются все документы, где они еще используются:
Документы записываются в список набора документов, найденные строки удаляются из порции.
Для каждого документа опять выбираются все аналитики учета по номенклатуре:
Происходит рекурсивный вызов процедуры «РекурсивныйПоискДокументов», и так далее. В итоге из порции выбираются все связанные друг с другом документы.
Далее, если количество документов в наборе меньше порогового значения, выбирается следующий документ, и строится цепочка зависимых от него. Пороговые значения я подобрал экспериментально, чтобы получить наиболее ровное разделение.
Для последнего потока выбираются все оставшиеся документы.
Процедура ЗапуститьВыполнениеВПотоках(ДанныеДляПотоков)
МассивИДЗаданий = новый Массив;
//Запуск потоков на выполнение и формирование массива идентификаторов запущенных потоков
Для Каждого ДанныеДляПотока ИЗ ДанныеДляПотоков Цикл
ПараметрыПроцедуры = Новый Структура("ДополнительнаяОбработкаСсылка, ИдентификаторКоманды, СтруктураДанных");
ПараметрыПроцедуры.ДополнительнаяОбработкаСсылка = ДополнительнаяОбработкаСсылка;
ПараметрыПроцедуры.ИдентификаторКоманды = "ВыполнениеПотокаВФоне";
ПараметрыПроцедуры.СтруктураДанных = ДанныеДляПотока;
НастройкиЗапуска = ДлительныеОперации.ПараметрыВыполненияВФоне(Новый УникальныйИдентификатор);
НастройкиЗапуска.НаименованиеФоновогоЗадания = ДанныеДляПотока.ИмяПотока;
НастройкиЗапуска.ОжидатьЗавершение = 0;
Поток = ДлительныеОперации.ВыполнитьВФоне("ДополнительныеОтчетыИОбработки.ВыполнитьКоманду", ПараметрыПроцедуры, НастройкиЗапуска);
МассивИДЗаданий.Добавить(Поток.ИдентификаторЗадания);
КонецЦикла;
//Проверка выполнения созданных фоновых заданий и перенаправление сообщений из потоков основному сеансу
Пока Истина Цикл
ВсеЗаданияВыполнены = Истина;
ТекущийПоток = 0;
Для Каждого ИдентификаторЗадания ИЗ МассивИДЗаданий Цикл
ТекущийПоток = ТекущийПоток + 1;
СостояниеЗадания = ДлительныеОперации.ОперацияВыполнена(ИдентификаторЗадания,, Истина, Истина);
ЗавершитьЗадание = Ложь;
//Проверка и перенаправление сообщений
Если ТипЗнч(СостояниеЗадания.Сообщения) = Тип("ФиксированныйМассив") Тогда
Для Каждого СтрокаСообщения Из СостояниеЗадания.Сообщения Цикл
Если СтрНачинаетсяС(СтрокаСообщения.Текст, "{") Тогда
Иначе
Сообщить("Поток "+ТекущийПоток+": "+СтрокаСообщения.Текст);
Если Лев(СтрокаСообщения.Текст, 6) = "Ошибка" Тогда
ЗавершитьЗадание = Истина;
КонецЕсли;
КонецЕсли;
КонецЦикла;
КонецЕсли;
//Проверка и перенаправление прогресса
Если ТипЗнч(СостояниеЗадания.Прогресс) = Тип("Структура") Тогда
Если СостояниеЗадания.Прогресс.Свойство("Процент") ИЛИ СостояниеЗадания.Прогресс.Свойство("Текст") Тогда
ПроцентВыполнения = 0;
ТекстВыполнения = "";
Если СостояниеЗадания.Прогресс.Свойство("Процент") Тогда
ПроцентВыполнения = СостояниеЗадания.Прогресс.Процент;
КонецЕсли;
Если СостояниеЗадания.Прогресс.Свойство("Текст") Тогда
ТекстВыполнения = СостояниеЗадания.Прогресс.Текст;
КонецЕсли;
Сообщить("["+ТекущийПоток+"]"+ПроцентВыполнения+"_"+ТекстВыполнения);
КонецЕсли;
КонецЕсли;
Если СостояниеЗадания.Статус = "Выполняется" Тогда
ВсеЗаданияВыполнены = Ложь;
КонецЕсли;
Если ЗавершитьЗадание Тогда
ДлительныеОперации.ОтменитьВыполнениеЗадания(ИдентификаторЗадания);
КонецЕсли;
КонецЦикла;
Если ВсеЗаданияВыполнены Тогда
Прервать;
КонецЕсли;
КонецЦикла;
КонецПроцедуры
В цикле происходит формирование и запуск фоновых заданий для каждого потока. В каждое фоновое задание передается сформированный ранее набор документов для обработки. Формируется массив с идентификаторами фоновых заданий.
Далее в цикле выполняется обход всех сформированных фоновых заданий. Проверяется состояние задания, выбираются сформированные сообщения и прогресс выполнения. Все данные передаются в основной сеанс. После завершения работы всех фоновых заданий, процедура завершает работу и происходит выборка новой порции документов.
Обратите внимание, данные о прогрессах выполнения потоков отправляются основному сеансу в виде сообщения определенной структуры. Прогресс отправлять нельзя, так как потоков много и будут теряться промежуточные значения.
Функция ПерепровестиДокументы(ДокументыДляПроведения)
ТекущийДокумент = 0;
ВсегоДокументов = ДокументыДляПроведения.Количество();
ДлительныеОперации.СообщитьПрогресс(0, "");
Для каждого СтрокаТЗ Из ДокументыДляПроведения Цикл
ДокументОбъект = СтрокаТЗ.Документ.ПолучитьОбъект();
Попытка
ДокументОбъект.Записать(РежимЗаписиДокумента.Проведение);
Исключение
Сообщить("Ошибка проведения документа: " + СтрокаТЗ.Документ);
Возврат Истина;
КонецПопытки;
ТекущийДокумент = ТекущийДокумент + 1;
Если НЕ (ТекущийДокумент % 5) Тогда
ДлительныеОперации.СообщитьПрогресс(Формат(ТекущийДокумент/ВсегоДокументов*100, "ЧЦ=3; ЧДЦ="), "Выполняется проведение документа: " + СтрокаТЗ.Документ);
КонецЕсли;
КонецЦикла;
ДлительныеОперации.СообщитьПрогресс(Формат(ТекущийДокумент/ВсегоДокументов*100, "ЧЦ=3; ЧДЦ="), "Выполняется проведение документа: " + СтрокаТЗ.Документ);
Возврат Ложь;
КонецФункции
В процедуре отдельного потока ничего не обычного нет. Происходит обход и проведение набора документов. После каждого пятого документа формируется прогресс выполнения, который будет обработан основным фоновым заданием (менеджером потоков). В случае ошибки формируется сообщения с указанием документа, в котором произошла ошибка.
Вот, собственно, и все основные механизмы. Обработка тестировалась на различных конфигурациях УТ 11.4 и ЕРП 2.4 на версии платформы 8.3.14.1630. В прикрепленных файлах внешняя обработка со всеми описанными механизмами.
Параметры: КоличествоПотоков и КоличествоДокументовВПорции необходимо подбирать экспериментально в зависимости от каждой конкретной базы и производительности сервера. Чем меньше порция, тем более ровную разбивку можно получить, но больше дополнительных затрат на создание фоновых заданий. Если в первый набор порции попадает больше трети всех документов, нет смысла разбивать порцию более, чем на три потока (все равно система будет ожидать выполнение первого потока).
Мне удавалось ускорить проведение в 2,5 раза при значении параметров:
- КоличествоПотоков = 3
- КоличествоДокументовВПорции = 50
Пишу на всякий случай. На файловых базах ничего работать не будет! Так как можно запустить одновременно только один дополнительный поток. Ну это наверно всем известно)).
Ссылка на первую статью.
Вот ссылка на более серьезное и универсальное решения многопоточной обработки данных.
Спасибо за внимание, если есть вопросы или комментарии, пишите.
Всем, кто едет на конференцию INFOSTART EVENT 2019, желаю вынести как можно больше полезной информации. Ну и до встречи на конференции ))
Вступайте в нашу телеграмм-группу Инфостарт


{kind=link}