


















{kind=link}
1. Предыстория.
1 мая 2020 года. Готовлюсь к экзамену 1С Специалист-консультант по Бюджетированию в ERP. Копаюсь в отладке, пытаясь понять, почему не работает отчет. И вдруг обнаруживаю, что в 1С ERP, присутствует перевод на Английский. Причем вполне рабочий. Причем уже больше года (как выяснилось при дальнейшем рассмотрении). Открываю 1С Управление торговлей, и вижу, что нет перевода на Английский. И тут я понимаю, что экзамен может подождать, а заняться чем-то интересным ждать не может.
2. Первые шаги.
Взяв одинаковые версии УТ (11.4.11.100) и ERP (2.4.11.100) принялся колдовать.
1. В 1С Управление торговлей снял конфигурацию с поддержки (Хотя это делать было не обязательно). Добавил Английский язык.
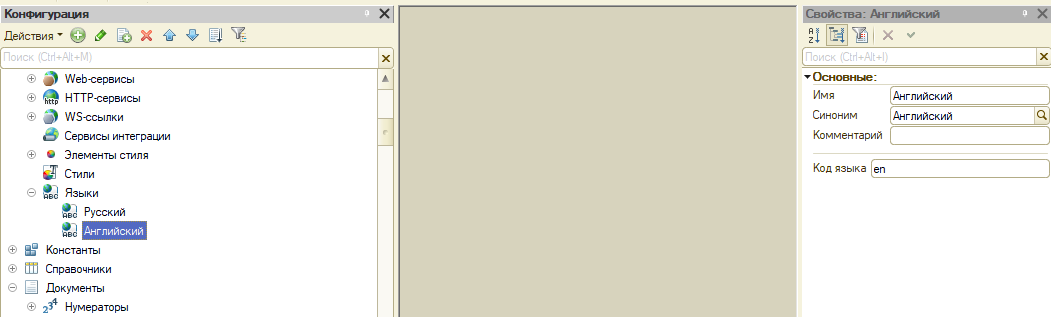
В 1С ERP выбрал Правка - Редактирование текстов интерфейса. Включил всю конфигурацию + Поиск в НСтр(NStr).
Выгрузка файла с расположением кода заняла более 4 гигабайт в формате MXL. Без расположения - 258 мегабайт.
Заполнился огромный список результатов.

Думая, что сейчас я загружу этот список в 1С Управление торговлей, и будет 1C Trade Management.
Однако при загрузке поймал ошибку
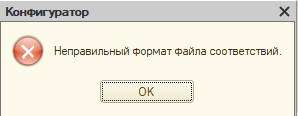
Потратив около часа на поиск причины возникновения ошибки обнаружил, что при выгрузке выгружаются значения
| Русский (ru) | Английский (en) |
А загрузчик ожидает получить
| ru | en |
Исправив это недоразумение, я перешел к загрузке.
Однако заполнился минимум значений из файла с переводом на английский язык.
3. Формирование собственного файла с переводом.
Решив использовать очень популярную конфигурацию 1С Переводчик я скачал ее с пользовательского портала. Загрузил. И ничего не получилось.
Посмотрел внимательно видео на Youtube, повторил, и опять ничего не получилось. Точнее файл загрузил. Но словарь не заполнился. Соответственно переводить нечего, а т.к. время было уже 3 часа утра, принял решение идти спать.
На утро возникла светлая мысль, перейти к анализу в python, для удобства выбрал Juputer notebook.
Первое, что сделал - это сформировал в голове идею.
Мне необходимо выгрузить все тексты интерфейса + НСтр из 1С Управление торговлей, и уже для них искать переводы.
Для анализа использовал пакет Pandas в Python.
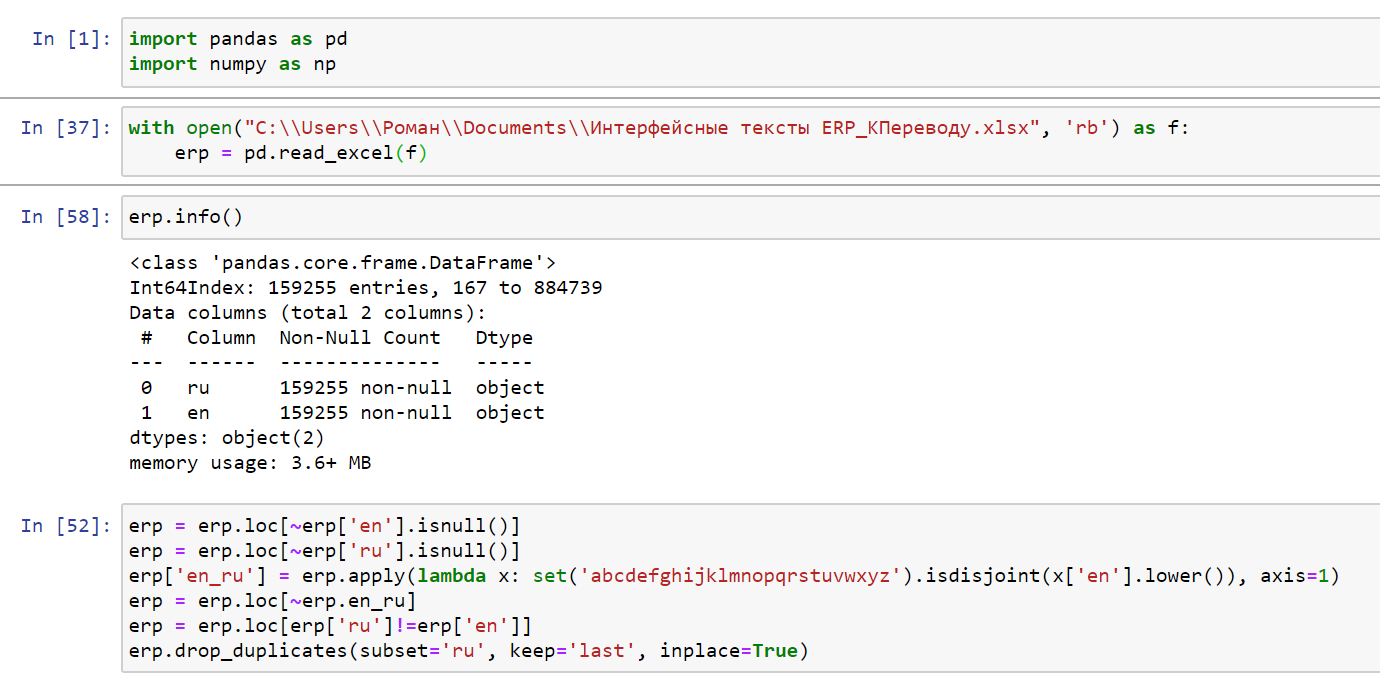
Сначала подгрузил нужные библиотеки Python.
Далее перешел к очистке выгруженных переводов, а именно.
Строчки, в которых отсутствует перевод на Английский, строки, в которых отсутствует перевод на русский. (Да, такие были).
Строчки, в которых текст на русском, и на английском был одинаковым.
Далее, для меня было откровением, что были чудесные переводы. Когда к примеру число 2 переводилось на английский как 3 :)
Так и откровенно полное нарушение смысла задумки.

И в конце важным условием было избавится от дубликатов. Я понимаю, что в разных местах, возможно стоило бы переводить по разному, но для данного этапа я принял для себя данное решение.

Далее примерное подобные действия выполнил для выгрузки текстов интерфейса + НСтр из конфигурации 1С Управление торговлей.
Добавив к фильтрам на удаление проверку, не пытаюсь ли я произвести перевод для поля содержащего только цифры.
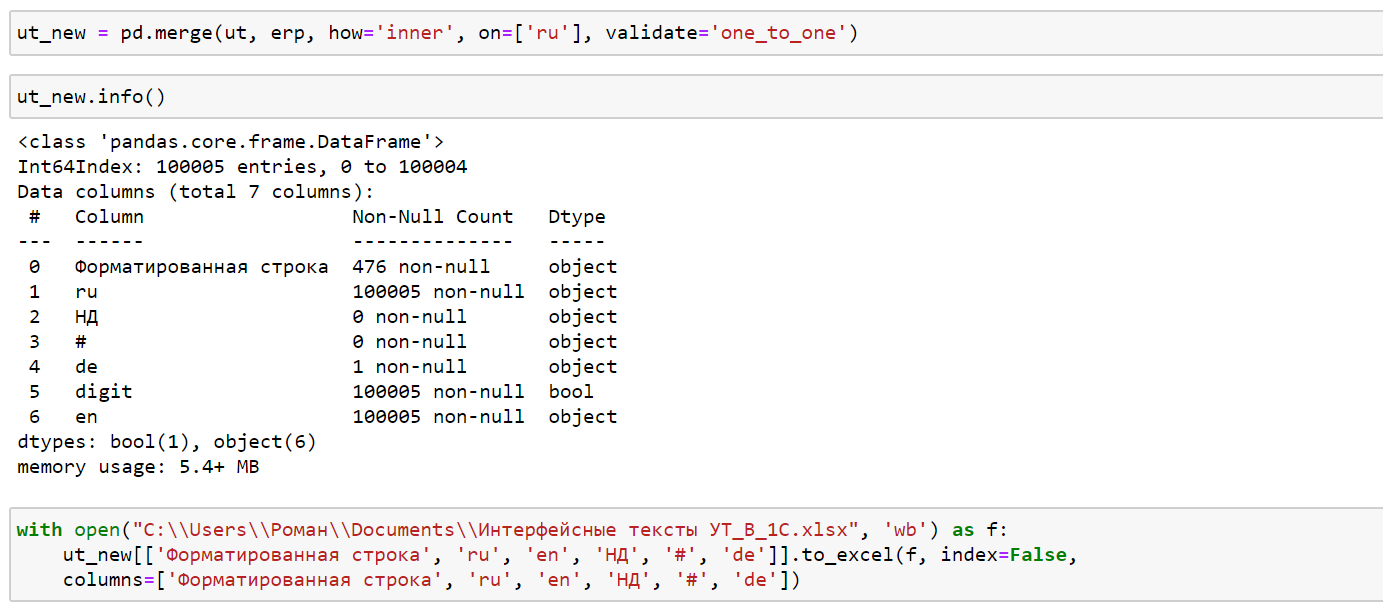
Далее произвел объединение двух датасетов, по внутреннему соединению, с проверкой, что в результате не возникло ситуации, когда одному русскому переводу соответствует более 1 перевода на английском языке. По непонятной мне причине заполнение текстов в этом случае просто не отрабатывает.
Сохранил результат в файл excel, для дальнейшей обработки. С помощью 1С перевел файл excel в mxl и произвел загрузку.
На этом этапе я был уверен, что у меня получился готовый программный продукт, хоть сейчас его внедрять в Евросоюзе.
С интерфейсами было все хорошо. А вот с печатными формами была беда. По непонятной причине отсутствовал перевод всех полей типа текст.
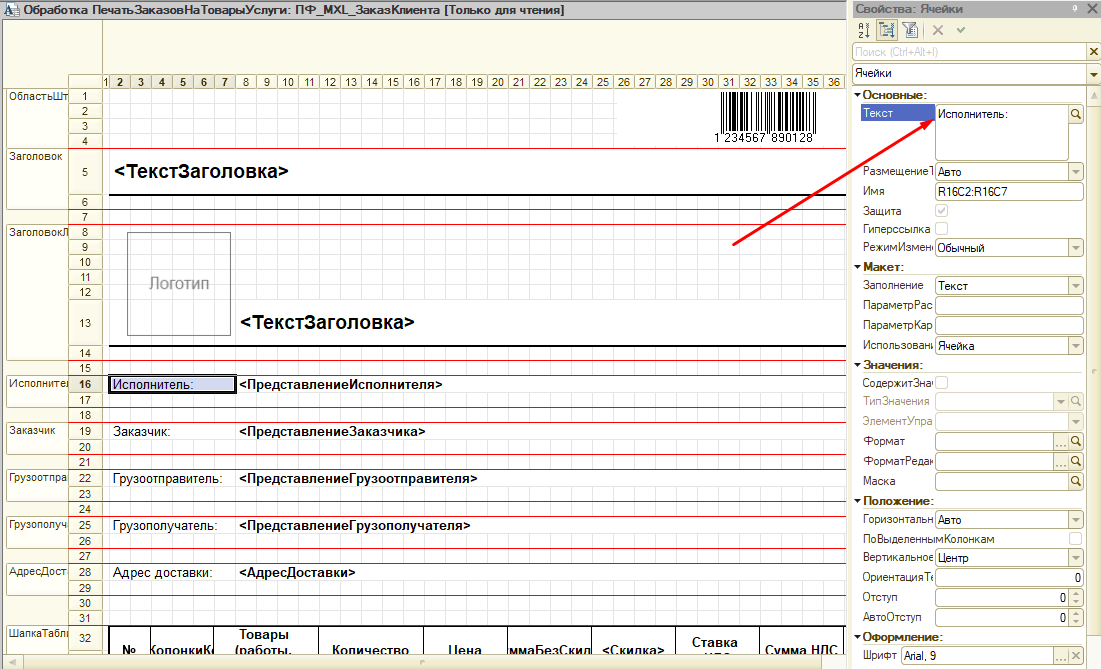
А победа была так близка.
При попытке поправить элемент поля текст, данная строка подсвечивалась серым, и перевод естественно не удавался.

4. Перевод текстов макетов.
3 мая.
Попробовав различные версии платформы, я не смог найти работающий вариант. Но разработчики ERP смогли обойти это недоразумение, и я смогу.
Я понял, что нужна будет отладка, много отладки. И перевел разработку в PyCharm
В Jupyter notebook сохранил результат объединения в csv файл

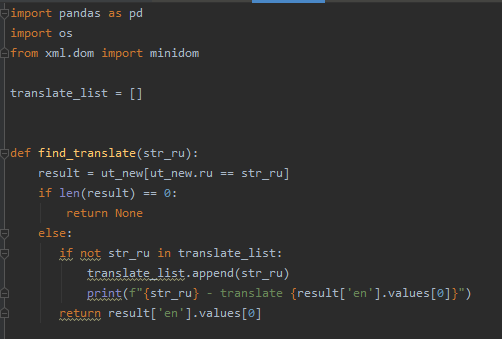
Произвел импорт необходимых библиотек.
Создал функцию, которая будет возвращать перевод, + дополнительно выводить отладку, впервые найденных возможных переводов.

Загрузил результат перевода, с которым я работал в Jupyter notebook
Выгрузил конфигурацию 1С Управление торговлей в файлы. Конфигурация - Выгрузить конфигурацию в файлы.
И произвел поиск всех файлов, которые содержат имя Template.xml, эти файлы и есть mxl файлы, переведенные в xml вид.
А далее начинается треш. Я до этого много работал с XML в 1С, а в Python столкнулся в первый раз. Сначала воспользовался модулем ElementTree, который отлично справляется с поиском. Но при модификации xml файла, считает, что пространства имен, объявленные в xml файле имеют не совсем идеальные префиксы, и выполняет присвоение новых префиксов. Плюс удаляет старые, неиспользуемые префиксы.
В результате, при загрузке текстов модулей, 1С ругается, что не знает используемые пространства имен.
<line width="1" gap="false">
<v8ui:style xsi:type="v8ui:SpreadsheetDocumentCellLineType">Solid</v8ui:style>
</line>
Исправив эти ошибки, начали появляться артефакты в макетах СКД, и я понял, что надо более деревянный инструмент, который будет только добавлять требуемый мне текст.
И этим инструментом оказался minidom.
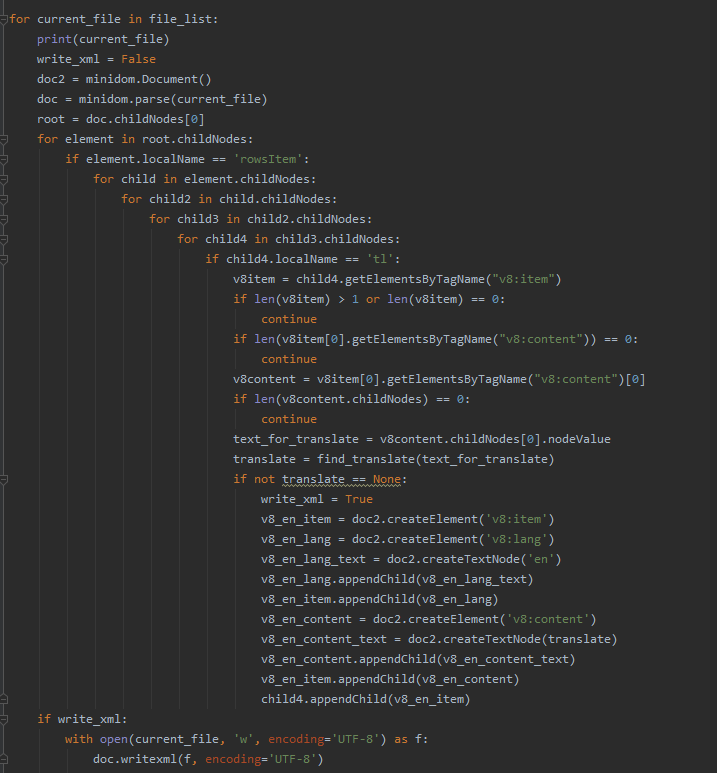
Путем разбора полетов, я понял, что в xml меня интурусуют тэги tl

, внтри которых мне нужно проанализировать, есть ли перевод на английский, и если нет, то, поискав в базе переводов, добавить его. Очень приятно, что данная библиотека не меняет пространства имен. И загрузка прошла без ошибок.
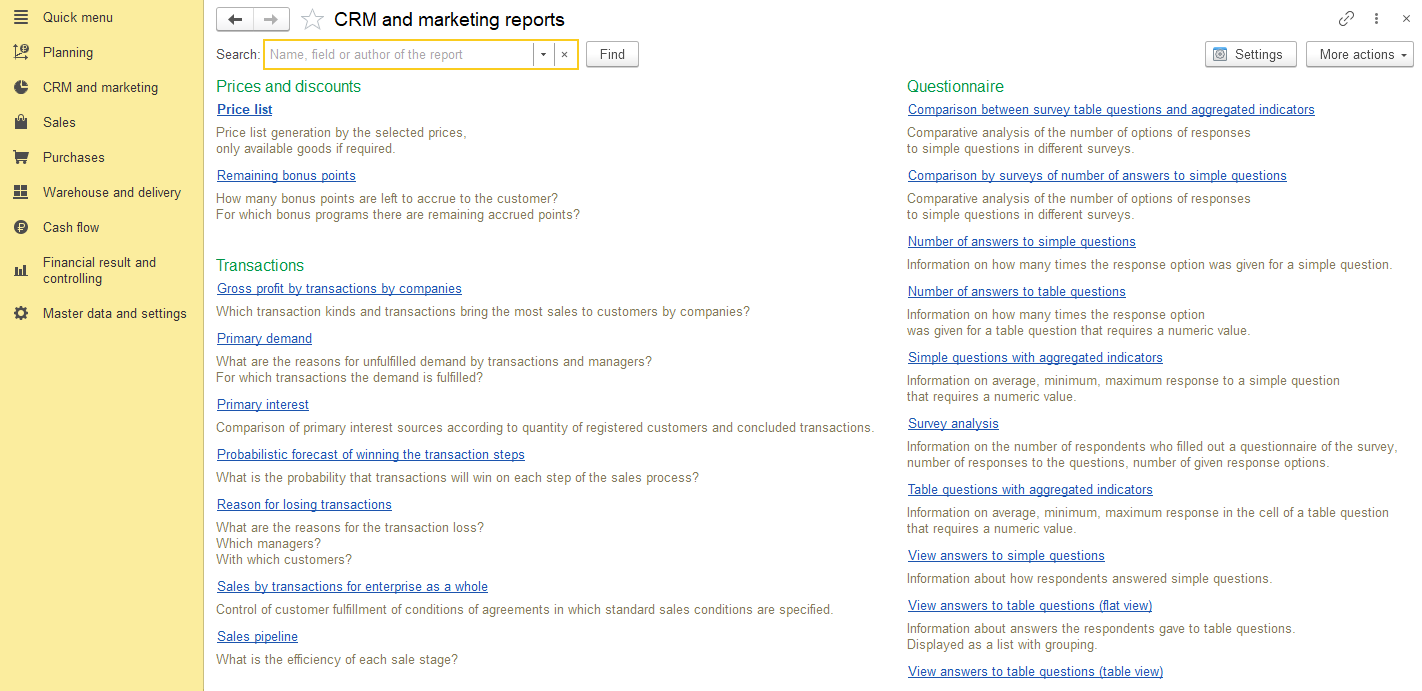
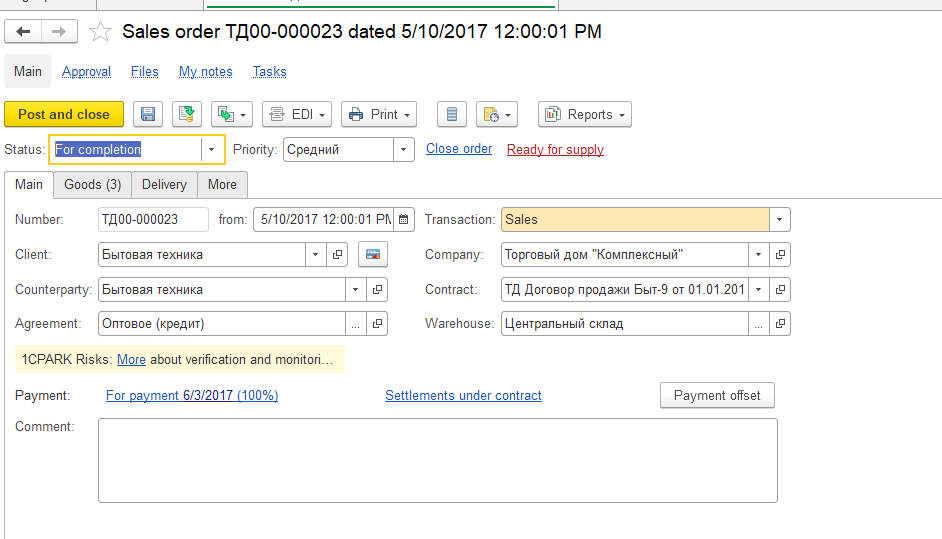
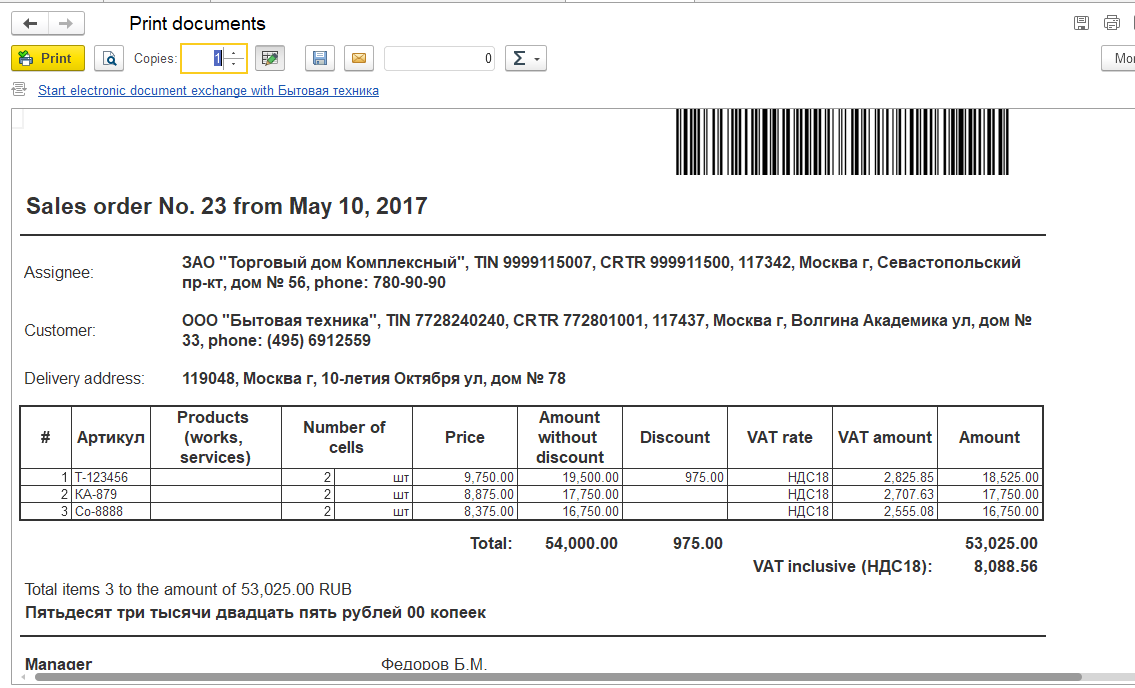
Основной функционал переведен на английский язык.
И оно работает.
Это было очень приятное отвлечение, от основных рабочих задач. 3 дня самоизоляции пролетели незаметно.
Вступайте в нашу телеграмм-группу Инфостарт