






Доброго времени суток! В настоящей публикации хочу поделиться опытом изучения и применения XDTO. Изложенное представляет собой конспект проделанной работы. Традиционно вначале условлюсь:
- статья отражает приобретенный самостоятельно опыт и результаты попытки разобраться в тематике, а не является сугубо теоретическим материалом, претендующим на какую-либо "академичность"
- предварительно я не осведомлялся "как это реализовано в типовых"
- возможно имеются более оптимальные реализации и понимание, хотелось бы узнать
Практическая цель изучения заключалась в том, чтобы научиться переносить данные между базами различных конфигураций. Собрал три кейса (состав описан ниже). В конечном счете удалось разобраться как это сделать. Отдельно уточню, не использовал каких-либо примеров, в т.ч. из тиражных решений. Предпринята попытка разобраться на основе знания технологий XML, ознакомления со стандартом XSD и главы 16 руководства. Так сказать, на абордаж, поэтому прошу воспринять материал соответственно. Прикреплено две базы (источник-приемник) и несколько схем, нарисованных мной для структурирования понятого.
Однако реализовать что-то и понять почему это выполняется именно так, не одно и то же. Остались вопросы, вэлком к обсуждению.
1. Схема, т.н. XSD, лежит в основе, загружается во вкладку XDTO-пакеты. Написать ее можно в обычном блокноте, достаточно просто. Формат XSD описывают два увесистых даташита, размещены на сайте консорциума w3c. Спустя некоторое время изучения я понял два обстоятельства: далеко не все возможности стандарта используются платформой и не обязательно уметь создавать схемы вручную (в большинстве случаев пожалуй достаточно будет возможностей, предоставляемых в конфигураторе).
2. Импорт XSD в дерево метаданных. Вот тут меня ожидали первые сюрпризы. Для одного и того же файла XML с данными можно написать более одной XSD, все будут валидировать файл. Но для пакета XDTO нужно знать, что xs:simpleType это подветка "Типы значений", xs:complexType подветка "Типы объектов". При этом, например, оба описания
<xs:element name="Документ_ПрисвоениеИНН_ДокументыЗаявителя">
<xs:complexType>
<xs:sequence>
<xs:element name="ВидДокумента" type="xs:string"/>
<xs:element name="Описание" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
и
<xs:sequence>
<xs:element name="ВидДокумента" type="xs:string"/>
<xs:element name="Описание" type="xs:string"/>
</xs:sequence>
</xs:complexType>
определят следующий элемент
1С примет корректно схему по второму образцу. Почему, осталось вопросом. Объяснение конечно какое-то должно быть, думаю кроется в стандарте.
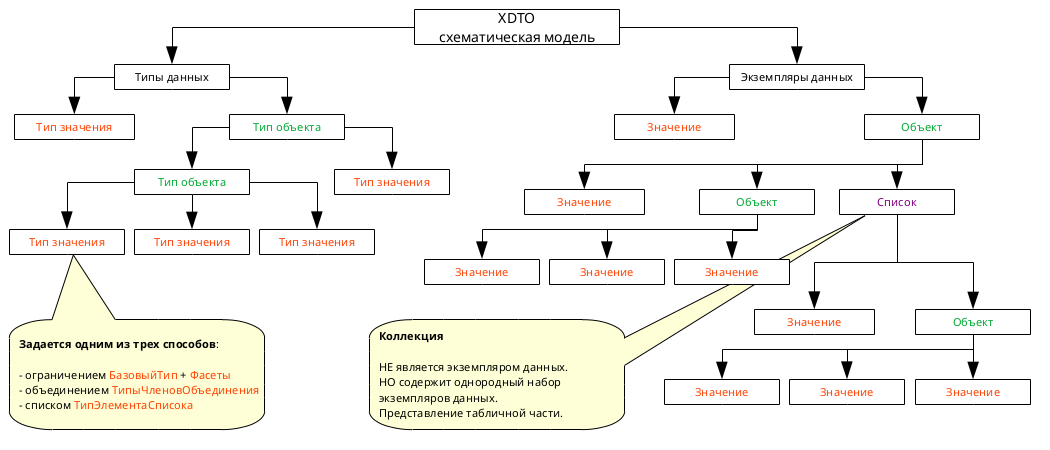
3. Общее понимание модели XDTO. Попытался это выразить на рисунке ниже. На данный момент осталось непонятным назначение подветки "Свойства" в пакете (ветка XDTO-пакеты), для каких целей и как ее использовать.
4. Работа с типами, фабрикой, организация переноса данных между конфигурациями. Насколько мне стало понятно, одной из основ концепции (с точки зрения интеграции) XML, XSD, XDTO лежит типизация. В конечном счете иерархия какого-либо набора данных сводится к примитивным и/или простым типам. И это, думается, "кошмар" для 1С-ника. Например, когда к нам приходят данные в виде <Калибр>200-02</Калибр> в XSD должно быть описано что это: число, строка, значение перечисления. А также, что в нашей системе "Калибр" нужно поместить в реквизит "ДиаметрИзделия" такого-то объекта. Но это еще не все, о чем нужно позаботиться и с чем можно столкнуться. Например вызов
п1 = "nonNegativeInteger"; п2 = "http://www.w3.org/2001/XMLSchema"; ИзXMLТипа(п1, п2);
возвращает Неопределено, а вот
п1 = "decimal"; п2 = "http://www.w3.org/2001/XMLSchema"; ИзXMLТипа(п1, п2);
уже ожидаемое Тип("Число"). Коллеги, возможно это понятный результат и кто-то воскликнет "очевидно же!". Но для меня это на данный момент отнесено в категории "знать и учитывать при разработке" и "не понятно, даже могу объяснить почему должно быть по-другому".
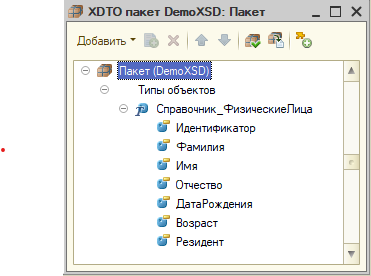
5. Перенос данных между двумя разными справочниками, документами. При организации переноса справочник-справочник или документ-документ с реквизитами примитивных и простых типов, без табличных частей, трудностей не возникло. Первый кейс. Вот как выглядел мой пакет:

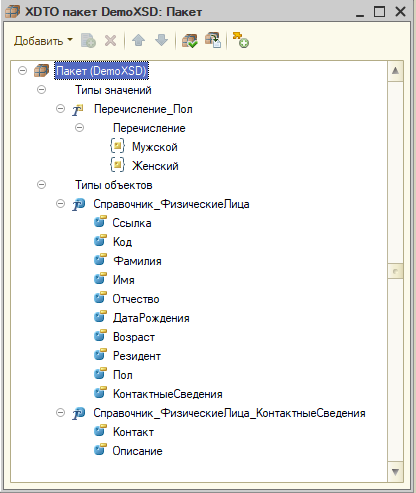
Простой пример, в сети и методичках достаточно таких примеров. Пошел второй кейс - перенос тех же объектов, но уже с реквизитами-перечислениями, табличными частями. На этом этапе пакет выглядел так:
Прежде, чем это сделать возник стопор. Как? Оперировать категориями привычной объектная модель данных 1С здесь не получилось. Для понимания, нарисовал такую простенькую схему:
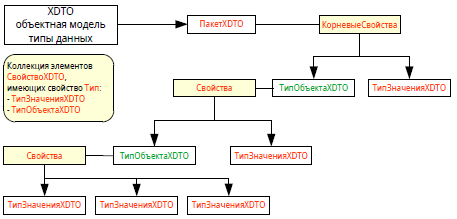
Что пришлось здесь понимать.
Во-первых, перечисление. В XML это <Пол>Мужской</Пол>, т.е. тип строка. Как при загрузке понять, что value это значение перечисления? Вот здесь типизация и типы значений по схеме. При десериализации мы находим, что данное свойству соответствует прикладной тип "ПеречислениеСсылка.Пол".
Во-вторых, табличная часть. Разыменование здесь не применимо. Для табличной части создан отдельный тип объекта "Справочник_ФизическиеЛица_КонтактныеСведения", указываемый в качестве типа объекта "КонтактныеСведения". Тогда мозаика сложилась. Не совсем очевидно при подходе "в лоб". Согласитесь, при объектной и запросной техниках работы мы привыкли работать с табличными частями как с неотъемлемой частью объекта. На прикладном уровне так и есть, хотя физически хранится раздельно. Да и в модель типов метаданных, признаю, укладывается ровно. В общем, некоторую заминку у меня вызвало додумывание необходимости оформить табличную часть как отдельный объект, а не пытаться настроить как-то "внутри владельца".
6. Почему все не так наглядно, как при использовании встроенного сериализатора. Все тривиально, когда мы используем "бортовой" сериализатор. Платформа безошибочно запишет/прочитает экземпляр данных справочника, документа и т.д. Когда же мы читаем объект, тип которого (как мы допускаем) отсутствует в дереве метаданных конфигурации, то обо всем нужно заботиться самим. Очередная схема. Нарисовал для наглядности собственного же понимания, использовал как шпаргалку:

Вот здесь меня ожидал еще один сюрприз. Называется он СписокXDTO. Используется для представления однотипного набора данных, в данном случае табличной части. За гранью понятого для меня так и остался факт того, что мы не можем обращаться к коллекции как элементу объекта XDTO. Почему существует два метода (ПолучитьXDTO и ПолучитьСписок). При этом не обнаружил иной возможности определить, что свойство это список, кроме как проанализировать значения верхней и нижней границы. Либо проверять возврат одного из двух методов, но при списке ПолучитьXDTO уходит в исключение, хотя должно давать Неопределено -> и тогда понимаем что это список (версия платформы 8.3.17.109).
Кстати еще о списке и XSD. Неявная трансляция свойства типа объекта пакета в СписокXDTO происходит, если из XSD заехало определение элемента комплексного типа, с указанием значений атрибутов minOccurs и maxOccurs. Когда unbounded - список, иначе - просто фасет. Вот этот прием (во втором кейсе) некоторое время выносил мозг до того, как быть освоенным. На мой взгляд такая дефиниция несуразна.
Последний сюрприз (пора с ними заканчивать) назвал ожидание и реальность. Третий кейс. Пакет:
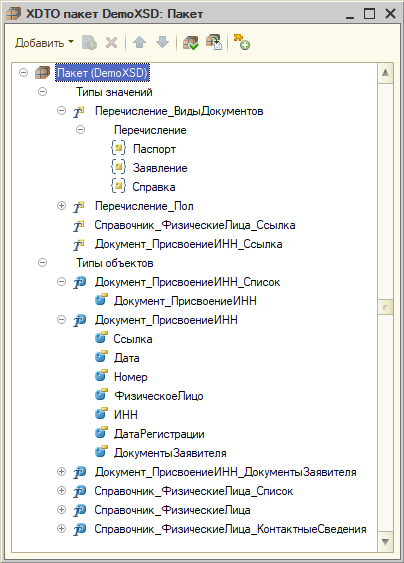
В этой задаче мне необходимо было решить задачу переноса списков экземпляров базы данных справочника, документа. Ожидание: предполагал, что на транспорт можно будет передавать экземпляры по мере формирования. Реальность: создаем контейнер. Отдельный "списочный" тип с unbounded-свойством, а типом которого уже будет наш объект. Снова типизация.
ПОДВОДИМ ИТОГ
Поставленные задачи удалось решить. Кому будет интересно, отправлю пары источник-приемник (в dt) по трем кейсам. Пишите в телегу. Для чего публикую? Хотелось бы поделиться опытом, а еще больше получить его. Поэтому прошу все дельные комментарии, конструктивные советы, подтверждения/опровержения, сильные/слабые стороны в комментариях. Материал имеется еще. Внимания заслуживает механика выгрузки/загрузки, кодирование, приемы. Возможно, кто-то поделится этим в обсуждениях.
Благодарю за внимание!
Вступайте в нашу телеграмм-группу Инфостарт