


Для обеспечения высокой доступности и восстановления при аварии мы используем SQL Server AlwaysOn кластер с синхронными репликами.
При этом сам кластер находится в облаке AWS с репликами в разных датацентрах в рамках одного региона. Если на активном сервере происходит сбой кластер автоматически обнаруживает проблему и переводит пользовательский траффик на другой сервер без потери данных.
Основной недостаток этой конфигурации - необходимость записать данные на все синхронные реплики кластера до окончания транзации. В нашей конкретной ситуации, операции записи примерно на 40% медленнее, чем если бы это был одиночный сервер.
Кроме того, любые задержки в сети или дополнительная нагрузка на основном или вторичном сервере напрямую влияют на скорость записи пользовательских транзаций.
С чем мы и столкнулись в данной ситуации. Был добавлен новый процесс, который записывал большой массив данных и оказал непропорциональное влиятие на общую производительность сервера.
В статистике ожиданий SQL Server видно, что WRITELOG ожидание увеличилось незначительно, а то время как HADR_SYNC_COMMIT ожидание увеличилось многократно.
WRITELOG ожидание / затраты текущего сервера на запись в журнал транзаций.
HADR_SYNC_COMMIT аналогичное ожидание, но на стороне синхронной реплики.
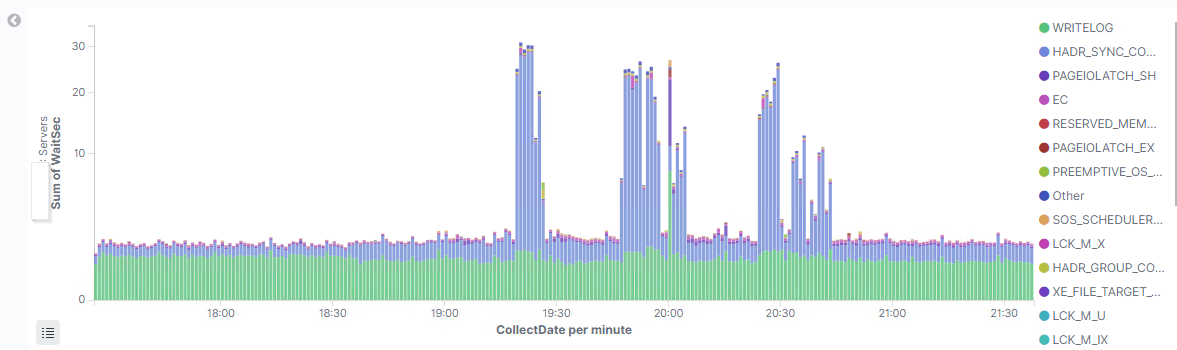
(визуализация данных с помощью ElasticSearch+Kibana - Мониторинг здоровья MS SQL Server)
т.е. явно проблемы с передачей данных вторичному серверу.
Причин может быть множество - проблемы с сетью, загруженность вторичного сервера, медленный диск с журналом транзакций на вторичном сервере, и т.д.
Мы не выявили ни одной из этих проблем и решили попробовать включить сжатия траффика между сихронными репликами.
По умолчанию, сжатие не используется для сихронных реплик, но включено для асинхронных.
Обычно сжатие не рекомендуется для сихронных реплик, т.к. это может потребовать дополнительных ресурсов процессора и оказать в целом негативное влияние.
После нескольких экспериментов мы обнаружили, что сжатие траффика не оказывает негативного влияния конкретно в нашей ситуации, но позволяет решить текущую проблему.
Подозреваю, что не последнюю роль играет тип серверов, который мы используем для баз данных - виртуальные машины z1d типа используют один из самых быстрых процессоров доступных в AWS облаке.
Сжатие траффика позволило уменьшить объем передаваемых данных между репликами примерно на 70%, что также положительно сказалось на затратах - траффик между датацентрами AWS не бесплатный даже в рамках одного региона.

Какой я сделал вывод для себя?
Я бы, наверное, не стал рекомендовать использовать сжатие траффика всеми по умолчанию.
Все зависит от конкретной конфигурации и должно быть проверено на реальной работающей системе в контролируемой манере.
Но, если вы это протестировали и результат устраивает, то это отличный способ снизить объем передаваемого траффика, что может быть особенно полезно если сеть между репликами медленная.
Для тестирования можно воспользоваться следующими командами:
-- получить список текущих trace flag-ов
DBCC TRACESTATUS;
-- включить trace flag для всех процессов
DBCC TRACEON (9592, -1);
-- отключить trace flag для всех процессов
DBCC TRACEOFF (9592, -1);
Для включения этого параметра на постоянной основе лучше его добавить в командную строку:
