Продолжаем цикл статей по разработке плагина для 1С:EDT для начинающего Java+1C разработчика.
В первой части – //infostart.ru/1c/articles/1311121/ мы рассмотрели, что такое платформа Eclipse, и как создать плагин с помощью конструктора.
Во второй части – //infostart.ru/1c/articles/1319555/ мы создали плагин для валидации.
В этой части мы создадим плагин для квикфикса (автоматического исправления).
С результатом разработки плагина можно ознакомиться в репозитории https://github.com/marmyshev/edt-bsl-validation
Содержание
- Создание плагина для Quick-Fix
- Создание класса для автоматического исправления
- Реализация связи между UI-плагином и плагином проверки
- Функциональность Quick-Fix через ExternalQuickfixModification
- Работа с TextEdit
- Основы работы с EMF для 1С:EDT
- Работа с текстовыми нодами модуля через NodeModelUtils
- Удаление текста из TextEdit
- Вставка текста в TextEdit
- Результат работы плагина
- Видео по созданию плагина для автоматического исправления (Quick-Fix)
Создание плагина для Quick-Fix
Автоматическое исправление (Quick-Fix) – это чисто UI-часть, которая идет отдельно. Мы бы могли по-простому добавить ее в текущий бандл, но давайте сделаем все по-правильному.
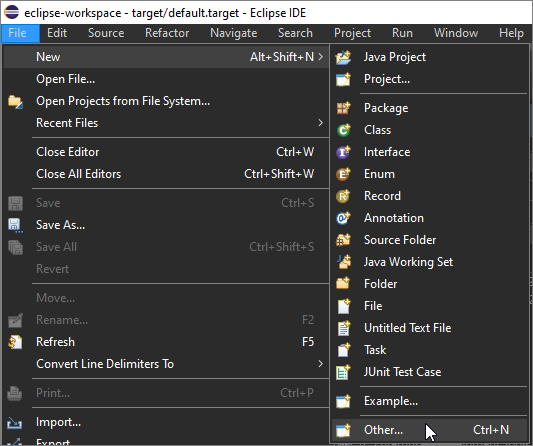
Создадим проект плагина.

Для этого вызовем File-New-Other и выберем, что это будет проект плагина.

Напишем название проекта – org.mard.dt.bsl.validation.ui.
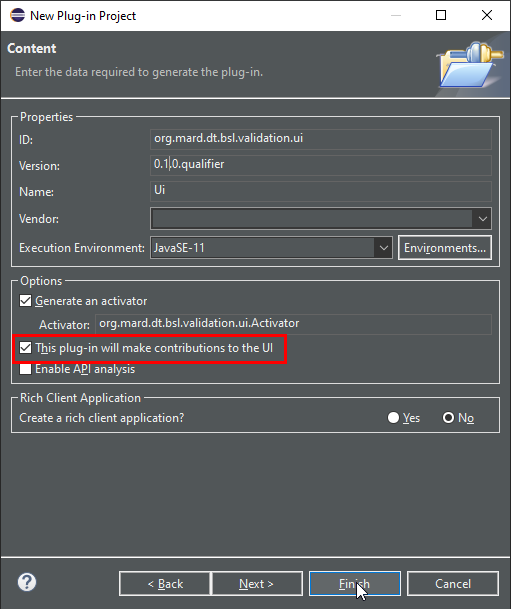
Поставим галочку о том, что бандл у нас будет UI – это нам много чем поможет. Поменяем версию на 0.1.0 и нажмем кнопку Finish.
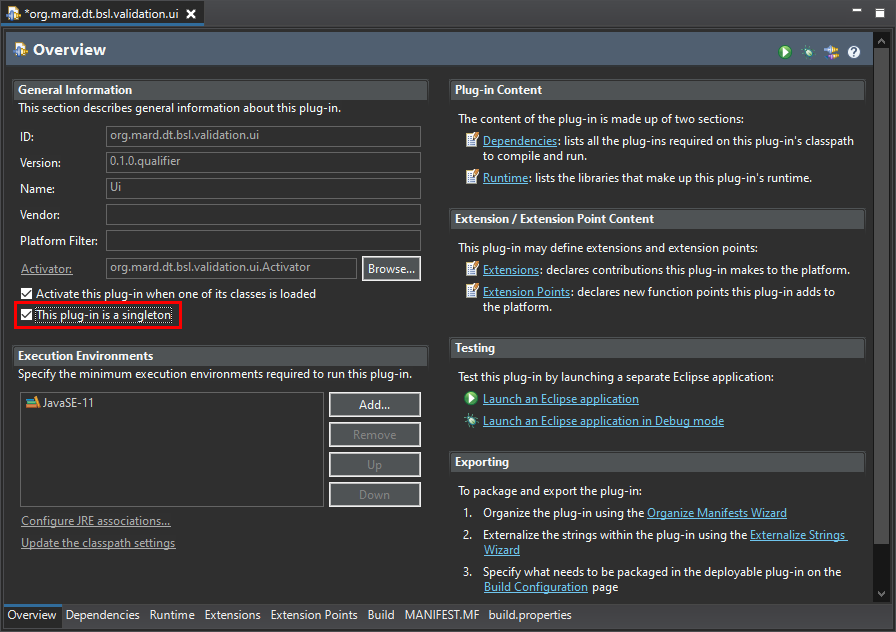
В окне информации о проекте плагина поставим галочку, что plug-in is a singleton.
Создание класса для автоматического исправления
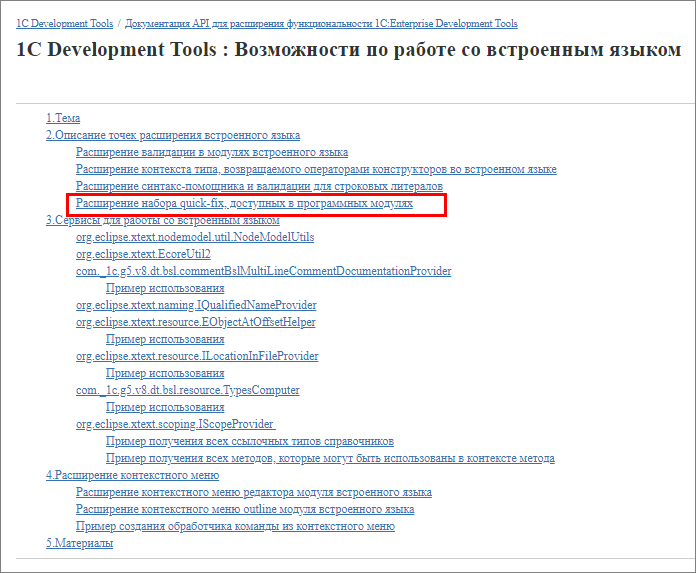
Теперь – аналогично, возвращаемся к разделу документации «Возможности по работе со встроенным языком». И здесь есть раздел про расширение набора квикфиксов.

Здесь приведено описание того, как квикфиксы должны контрибутиться, и приведен пример использования квикфикса.
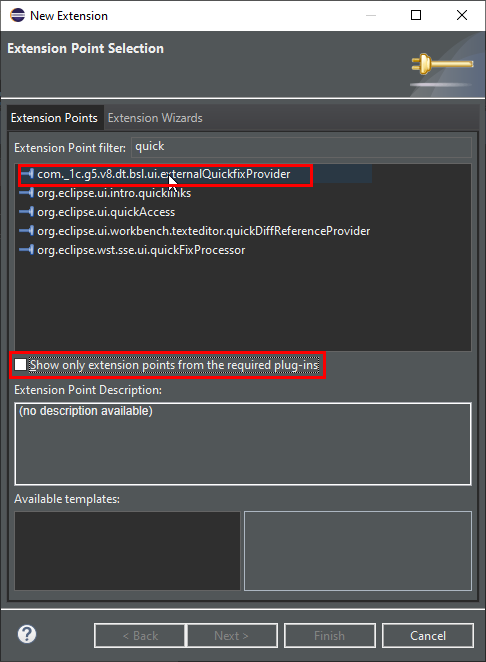
Перейдем на закладку Extensions и попытаемся добавить сюда точку расширения для квикфикса. Набираем quick – ничего похожего на наш квикфикс в доступности нет, снимаем галку «Show only extension points from the required plug-ins» и видим здесь описание externalQuickfixProvider.

Выбираем его, и он сразу предлагает нам добавить все зависимости. Соглашаемся.
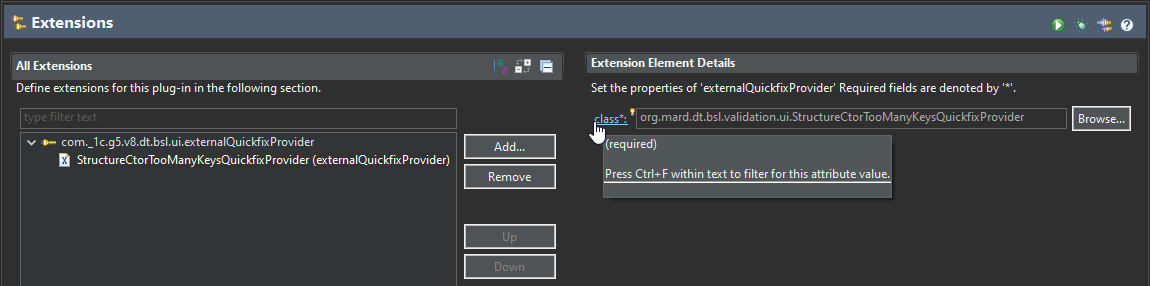
Назовем наш квикфикс StructureCtorTooManyKeysQuickfixProvider. И нажмем гиперссылку class.
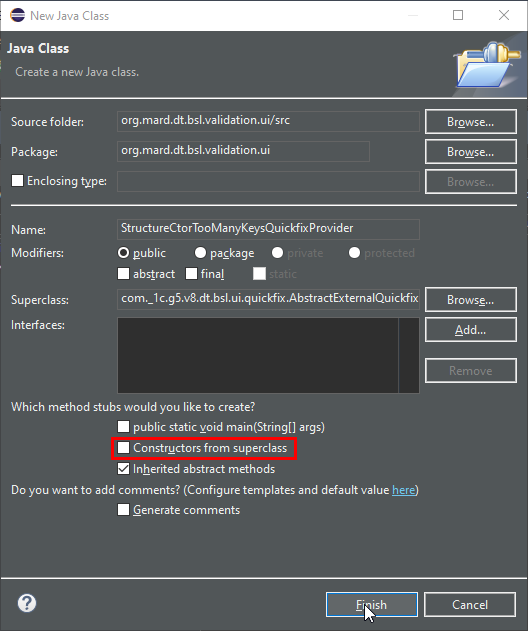
Он предложит нам автоматически создать класс. Снимем галку Constructors from superclass – конструктор нам не нужен. И нажимаем кнопку Finish.

В папке src автоматически появляется файл класса.
Реализация связи между UI-плагином и плагином проверки

Возвращаемся к документации. Здесь говорится, что для класса, который наследуется от AbstractExternalQuickfixProvider нужно добавить метод, у которого будет специальная аннотация @Fix.
Давайте скопипастим этот пример и зададим здесь наши настройки.
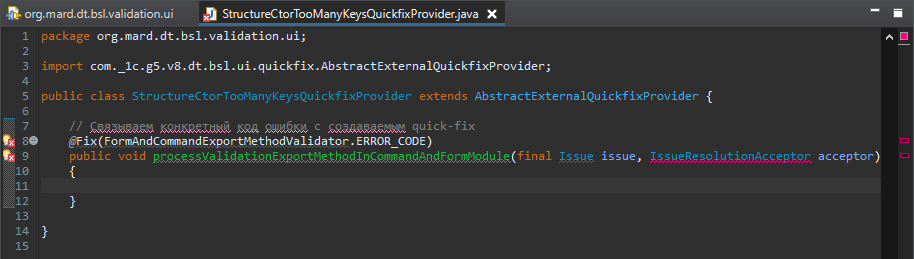
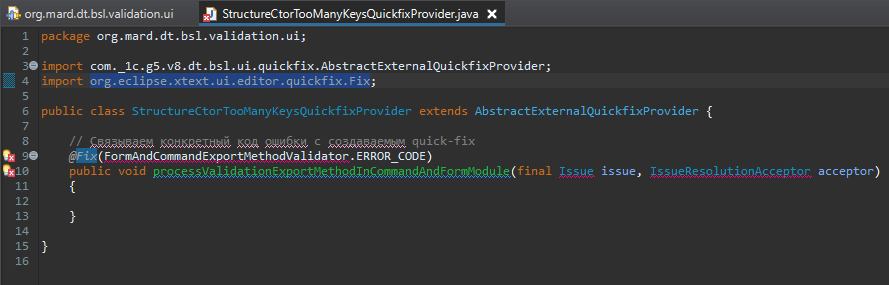
Аннотация @Fix требует импорта org.eclipse.xtext.ui.editor.quickfix.Fix.
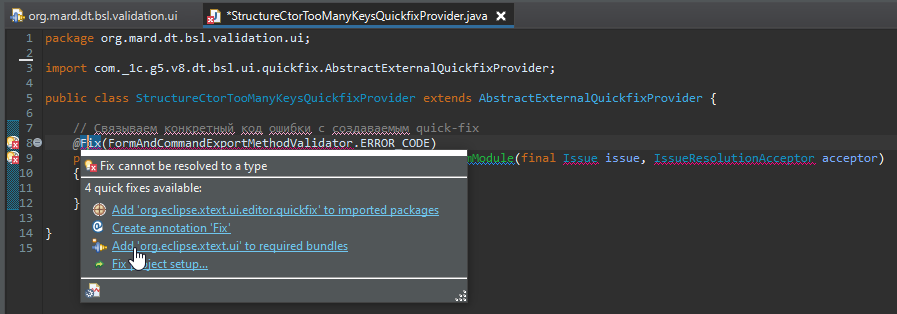
Поэтому добавляем бандл org.eclipse.xtext.ui в зависимости.
Дальше нам нужно указать, к чему относится наш квикфикс – это фикс для определенного ERROR_CODE. Чтобы сделать возможным вызов ERROR_CODE извне возвращаемся в исходники плагина валидации.
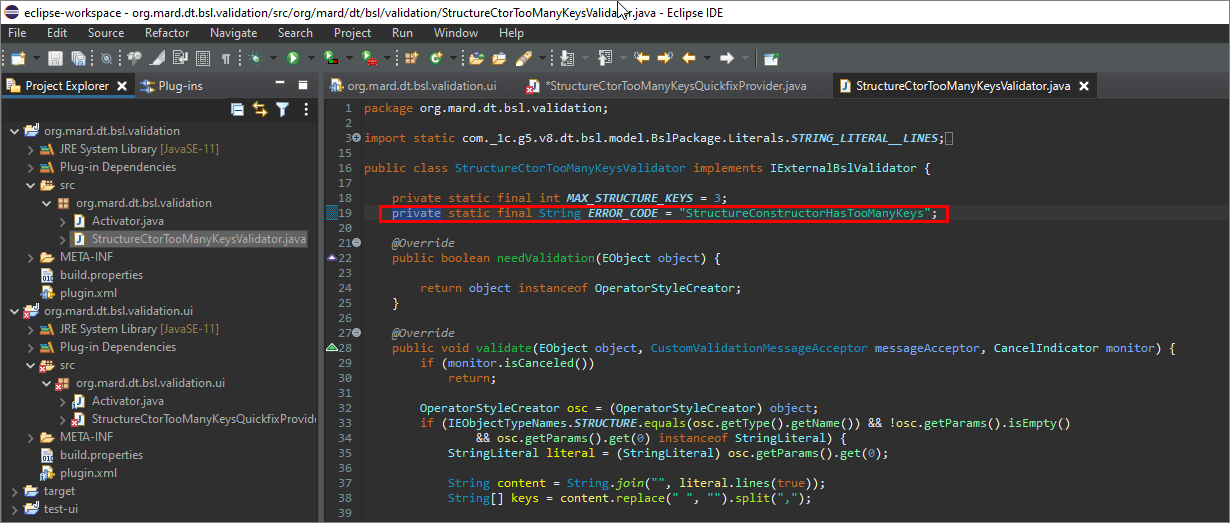
У нас здесь есть константа ERROR_CODE – но она сейчас непубличная.
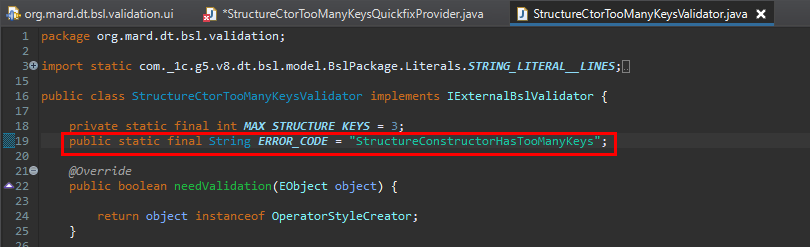
Давайте сделаем ее публичной.

И скопируем имя класса StructureCtorTooManyKeysValidator для обращения к коду ошибки в классе квикфикса.

Теперь нам нужно экспортировать наш пакет org.mard.dt.bsl.validation. Для этого заходим в Runtime, и добавляем пакет в экспорт – у нас здесь он один.

Сразу нажимаем Properties. Здесь вы принимаете решение, какая схема версионирования будет в вашем проекте – по пакетам или по бандлам. Я привык делать версионирование по пакетам. Поэтому у нас будет версионирование по пакетам.
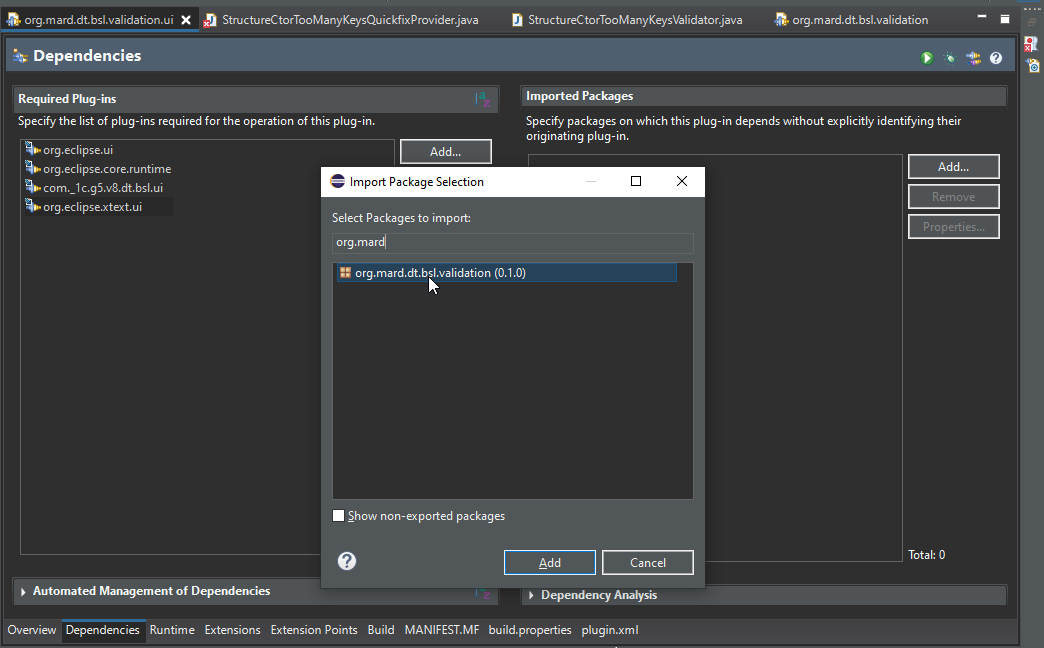
Бандл валидации нужен в зависимостях у нашего же UI-бандла, поэтому указываем его в зависимостях.
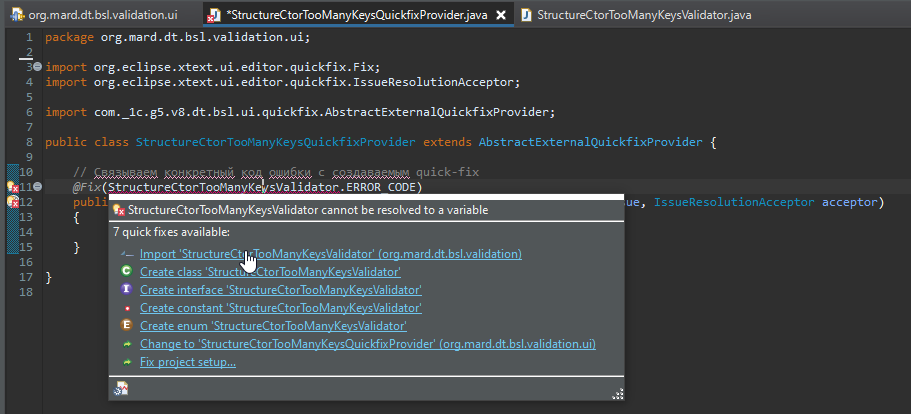
Теперь можно сделать импорт класса сюда автоматически.

Вот такая заготовка для процедуры у нас получилась – давайте оформим ее как следует.
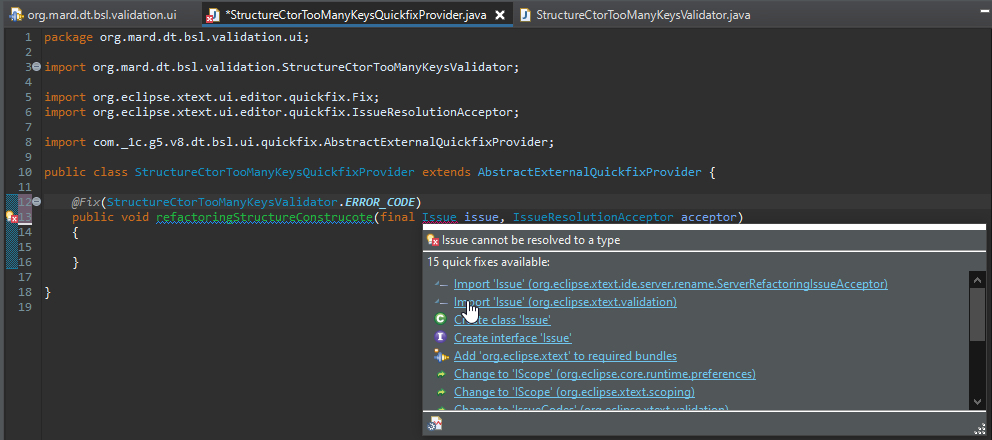
Уберем лишний комментарий, назовем процедуру refactoringStructureConstrucote и добавим в зависимости импорт org.eclipse.xtext.validation.Issue.
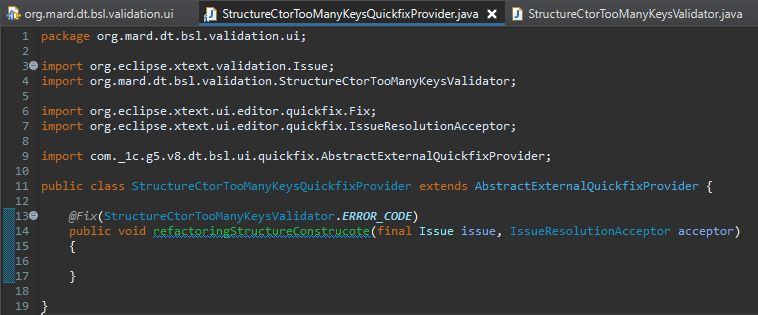
Этим методом мы говорим, что для нашего ERROR_CODE (для ошибок, которые навешиваются), нам нужно повесить какие-то квикфиксы. Их в этой процедуре может быть даже несколько, но для нашей задачи мы сейчас будем создадим один.
Функциональность Quick-Fix через ExternalQuickfixModification

Чтобы упростить процесс, я сейчас сделаю копипаст из заготовки.
Здесь в acceptor для полученного issue мы выводим в качестве title и description «Replace Structure constructor with inserts» (подсказка и ее описание, которые мы видим, когда нажимаем на ошибку).
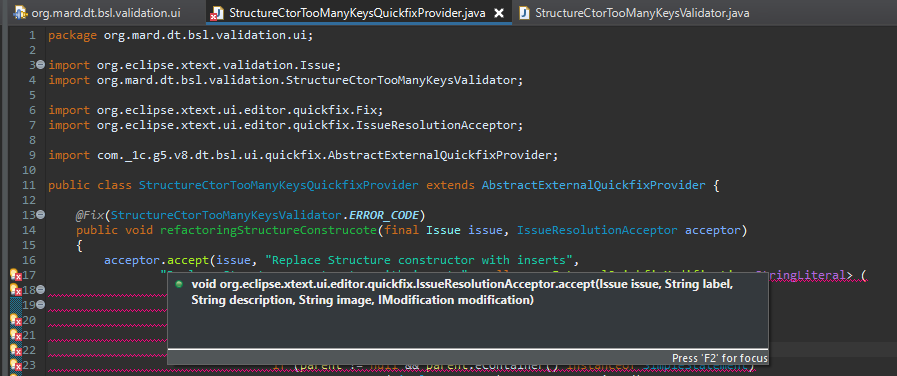
У метода accept есть аргументы:
- первый аргумент – это issue;
- второй аргумент – это title;
- а третий аргумент, description – это может быть очень большое качественное описание того, что делает этот рефакторинг. Здесь я по-простому пока написал, чтоб не заострять внимание.
- дальше – мы должны передать в этот acceptor какой-то modification – то, что будет выполнено в результате нажатия пользователем на это действие.

В документации к EDT можно тоже посмотреть пример реализации квикфикса через acceptor.accept.
Здесь видно, что EDT предоставляет класс ExternalQuickfixModification, который реализует быстрое взаимодействие с моделью и использует специальные механизмы xText для соблюдения консистентности при модификациях в редакторе – чтобы в каждом квикфиксе не прописывать эти механизмы вручную, удобно использовать класс ExternalQuickfixModification.
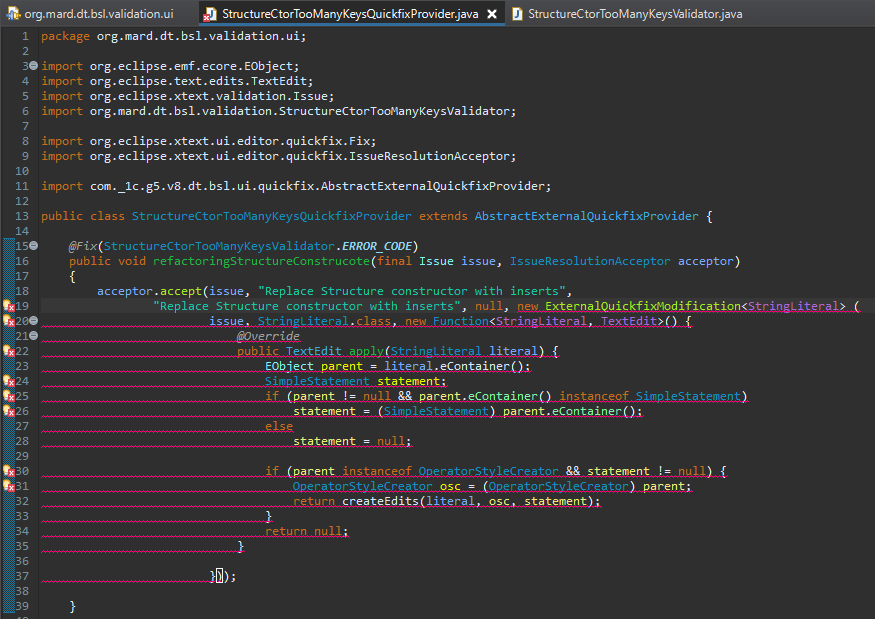
При первом сохранении он нам импортит используемые объекты и сообщает, чего ему еще не хватает.

Нужен bsl.model.StringLiteral для строкового литерала.
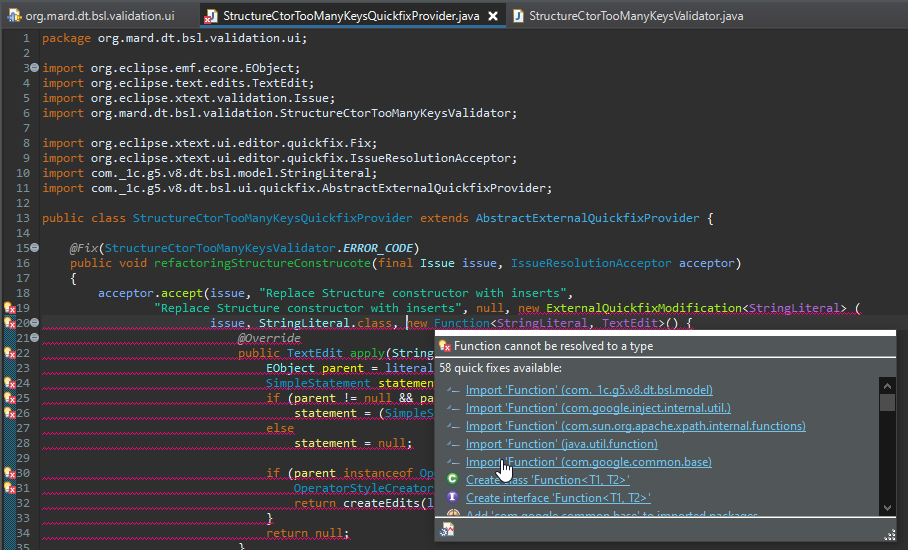
И нужен Function из com.google.common.base – здесь разработчик должен подсказать, с какими типами объектов мы работаем, потому что не всегда понятно, что именно нужно импортировать.

И при сохранении автоматически подтягиваются оставшиеся зависимости.
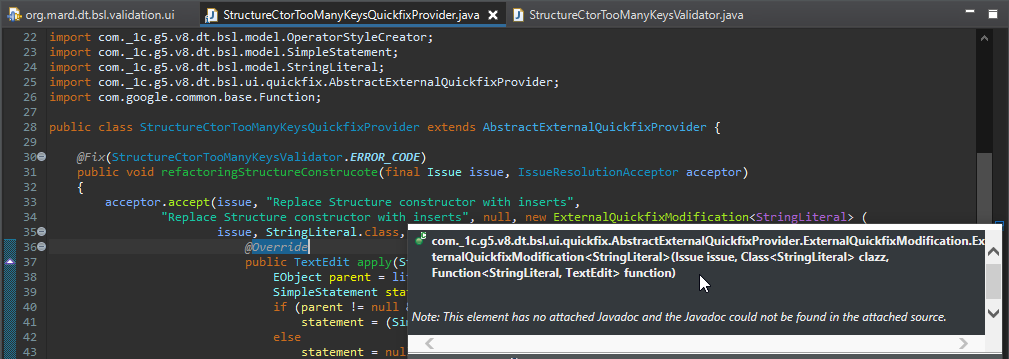
Обратите внимание, что поскольку мы вешали ошибку на строковый литерал, то здесь при создании наследника класса-модификатора ExternalQuickfixModification нам нужно в качестве объекта модификации указать именно класс строкового литерала (StringLiteral.class), чтобы дальше внутри функции, которая выполняет модификацию текста, мы работали уже с конкретным нужным нам инстансом. Эта обертка сразу делает поиск нужного объекта.

Дальше вставляю из заготовки функцию createEdits, которая выполняет модификацию.

И здесь мы тоже все, что нужно заимпортим – укажем, что Expression нам нужен из dt.bsl.model.

А List нам нужен из java.util.
Работа с TextEdit
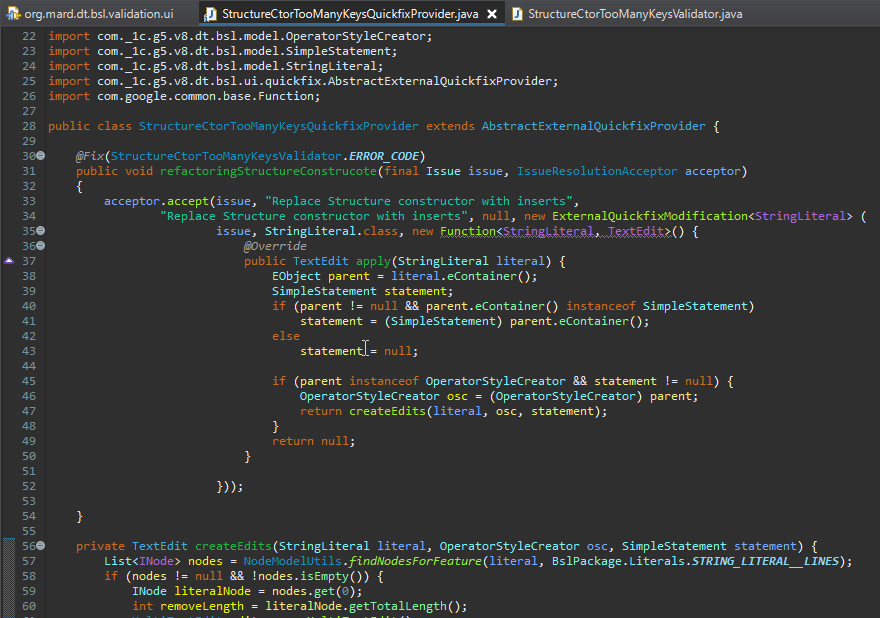
Вроде ошибок больше нет – теперь давайте пройдемся по этому коду.
Смотрите, мы в acceptor добавляем какое-то действие – модификацию, которую будем выполнять.
Мы можем написать этот модификатор сами или можем взять готовый наследник для модификации внутри редактора xtext, который работает сразу с моделью наших объектов (если мы модифицируем сразу несколько объектов) – он может быть сложный, может вызывать какие-нибудь диалоги.
Но в данном случае у нас действие простое – нам нужно взять текущий объект строкового литерала и преобразовать его.
Для этого мы в функции apply должны вернуть модификацию текста – специальный класс TextEdit, который будет содержать информацию о том, что и как модифицировано.
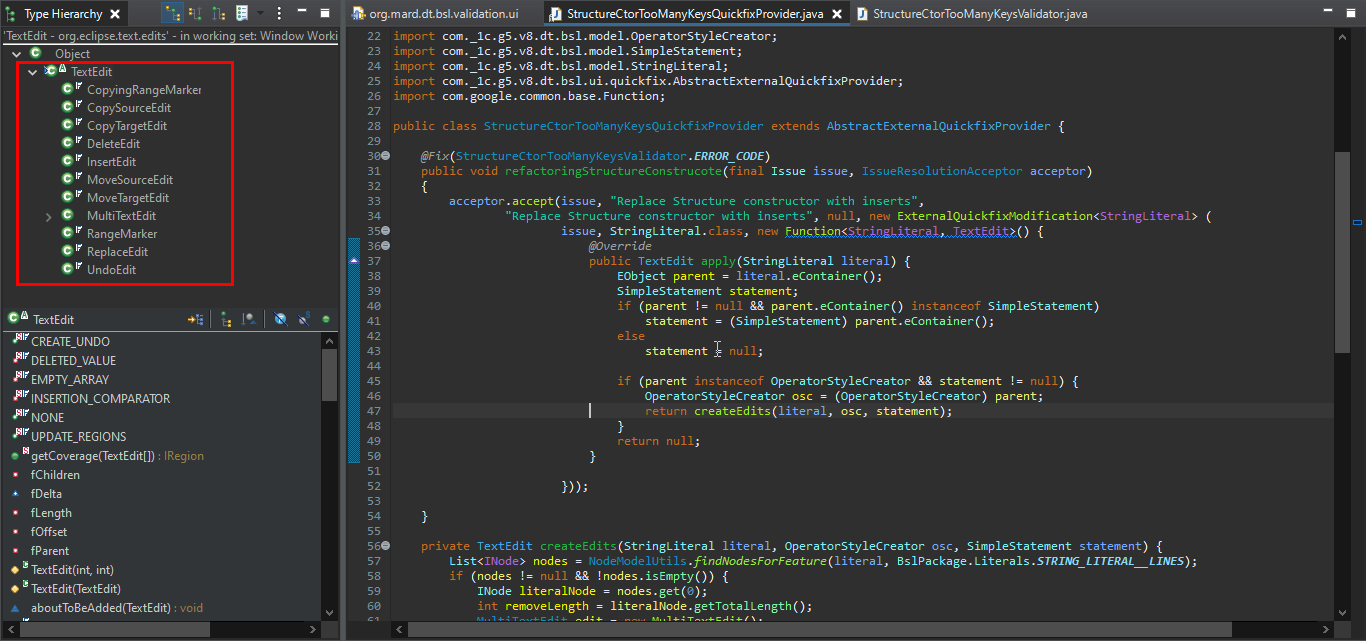
Класс TextEdit – абстрактный, но его наследники могут реализовывать методы CopySourceEdit, DeleteEdit, InsertEdit и, например, MultiTextEdit.
В данном случае нам нужно будет выполнить несколько модификаций:
- во-первых, нам нужно будет для нашей задачи удалить первый строковый литерал (и остальные параметры из конструктора, скорее всего);
- и также сделать вставки в структуру – Структура.Вставить(НашПараметр).
Для упрощения давайте предположим, что мы будем обрабатывать только те случаи, которые относятся к простому присваиванию – только тогда, когда есть переменная, которой мы присваиваем значение нашей новой структуры.
Поэтому мы здесь проверяем, что:
- у строкового литерала контейнер (результат метода eContainer()) является OperatorStyleCreator;
- и что его контейнер (вышестоящий объект) является SimpleStatement (оператором простого присваивания).
После того, как мы это проверили, мы модифицируем наш TextEdit (для упрощения я перенес процесс модификации в отдельную процедуру createEdit).
Основы работы с EMF для 1С:EDT
Если вы хотите хорошо и качественно работать с данными в EDT, вам следует изучить такое большое направление, как EMF (Eclipse Modelling Framework) – это фреймворк, который позволяет создавать различные модели данных, взаимодействовать с объектами, на базе которых построена вся модель данных в EDT, быстро автоматически генерить эти объекты, получать подчиненные объекты по моделям.
Например, с помощью EMF можно получить тело и параметры функции, обойти эти элементы не через API самой функции, а используя общие базовые возможности EMF.
В данном случае контейнер как раз будет являться EObject и получаем мы его методом literal.eContainer(). Вот этот префикс «e» как раз характерен для EMF-ных объектов, они так префиксуют все свои методы – EContent, EClass и все остальное. Это – базовая функциональность EMF.
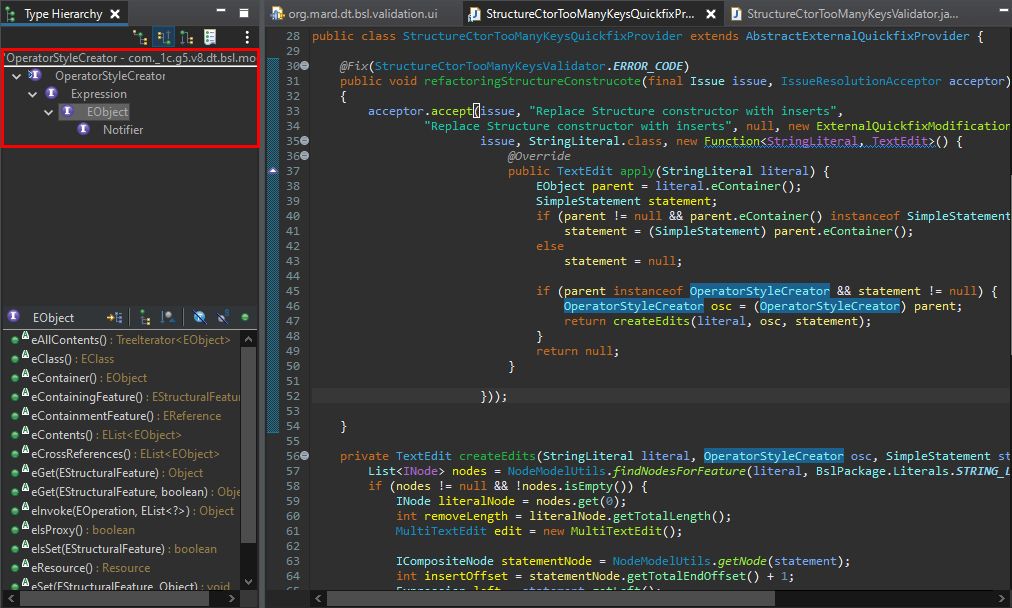
Если мы посмотрим иерархию классов, то мы видим, что OperatorStyleCreator наследуется от Expression и EObject.
И здесь внизу все методы у EObject тоже префиксом «e» – то есть, это базовая функциональность EMF.

А все остальные методы, которые созданы в конкретной модели (например, в модели данных BSL) – они уже имеют обычное название. Как у нашего OperatorStyleCreator есть методы getParams(), getType() и т.д.

А у StringLiteral есть методы getLines() и lines().

Как вообще можно посмотреть, что есть в модели данных, минуя документацию? Во-первых, мы можем просто открыть класс, посмотреть, какие у него есть методы.
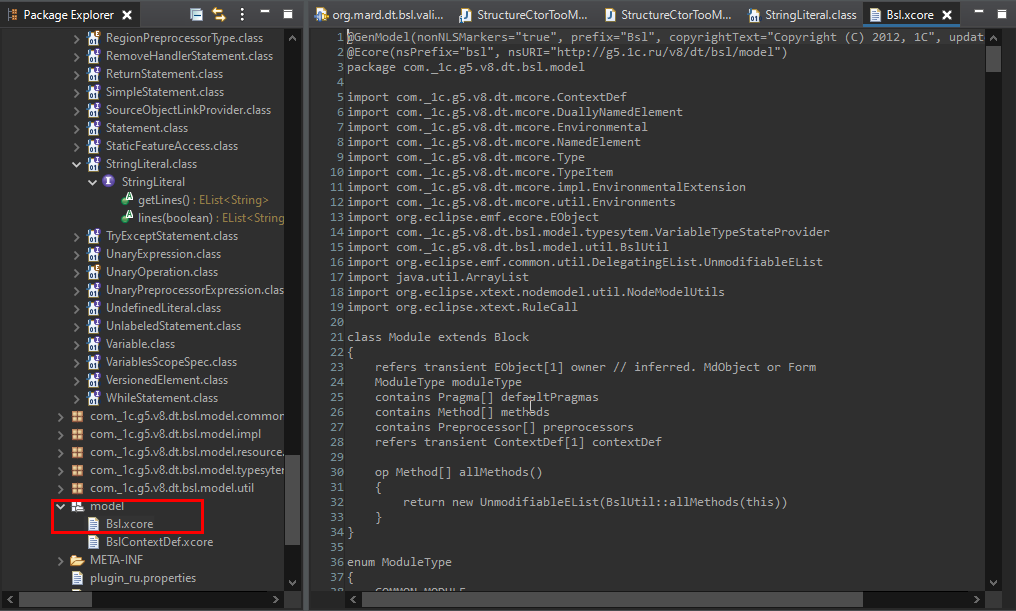
Во-вторых, поскольку EDT использует модели EMF, которые генерятся с помощью фреймворка xCore, то, открыв файл модели BSL.xcore, мы можем увидеть абсолютно все методы всех объектов, которые добавлены в модель BSL. Это очень удобно. Здесь есть модели абсолютно по всем данным EDT – формы, метаданные, любые макеты (СКД, моксель). И это вполне можно изучать. Где-то даже есть комменты. Из многих названий понятно, что от чего наследуется, для чего это нужно. Не так много информации, но она дополнительно будет вам полезна при изучении модели данных BSL.
Работа с текстовыми нодами модуля через NodeModelUtils
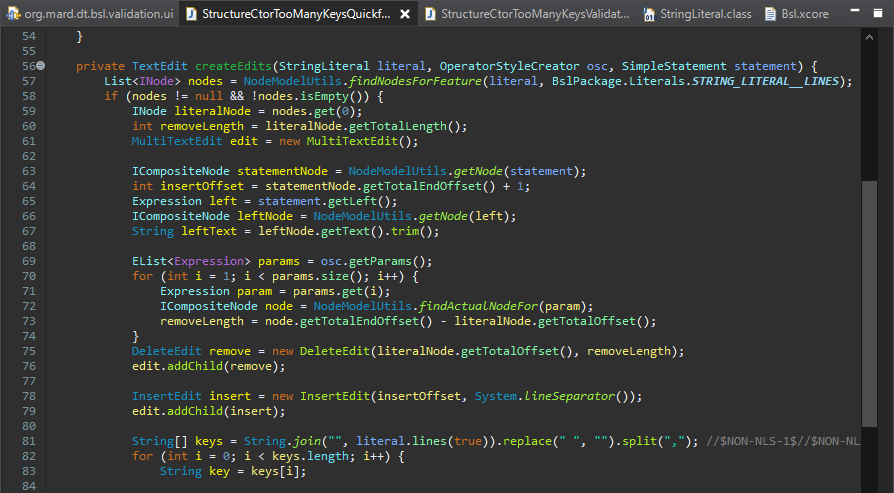
Вернемся к методу createEdits. На что здесь следует обратить внимание?
Мы обходим модель модуля через его API:
- берем строковый литерал,
- для строкового литерала получаем стейтменты,
- у стейтментов получаем подчиненные коллекции стейтментов и т.д.
При этом каждый элемент модели имеет внутреннее соответствие текстового представления.
Мы можем получить внутренние ноды – куски или регионы текста, которые соответствуют определенным элементам модели. Мы можем обходить модель и быстро переключаться к нодам этих элементов модели внутри текста.
Этот маппинг там зашит внутри, и чтобы между этими нодами переключаться есть специальный класс – NodeModelUtils. Посоветую вам просто обратить на него внимание и поизучать его методы.
В данном случае мы говорим о том, что нам нужны все текстовые ноды, которые мы повесили на первый строковый литерал. Эти ноды составные, они могут включать в себя подчиненные и т.д.

Что здесь происходит:
- мы берем первую ноду строкового литерала – это будет основная, полная, верхнеуровневая нода;
- вычисляем ее длину;
- и первое, что мы создаем – это наш MultiTextEdit, высокоуровневый класс, который будет иметь несколько модификаций (несколько наследников, которые нам нужно обработать в тексте).
- далее нам нужно удалить все то, что лежит в конструкторе – мы по нашему строковому литералу нашли первую ноду, и дальше можем удалить первый строковый литерал и все остальные ноды, относящиеся к параметрам.
Удаление текста из TextEdit
Давайте поясню этот момент на тексте модуля.
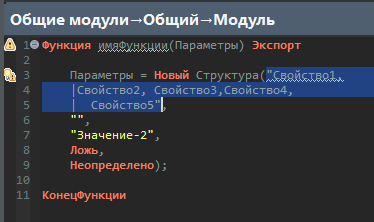
Итак, если мы говорим про первый строковый литерал – у этого литерала есть несколько нод. Нас сейчас интересует первая нода – это обобщенный регион, начиная отсюда и до сюда.
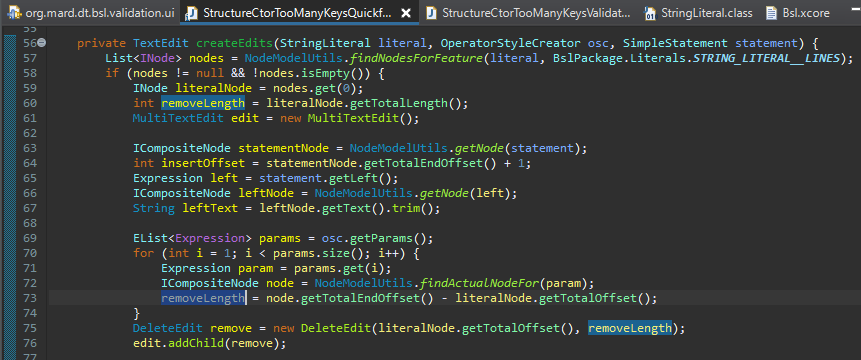
Дальше мы получаем дополнительные параметры конструктора (4 штуки), определяем ноды этих параметров, обходим их в цикле и находим окончание каждой ноды, чтобы сделать удаление.
То есть мы определяем общую длину всех нод, которые относятся к конструктору и удаляем от начального смещения строкового литерала (literalNode.getTotalOffset()) на ту длину, которую определили (removeLength).
Добавляем в наш MultiTextEdit первое удаление (edit.addChild(remove)).
Вставка текста в TextEdit
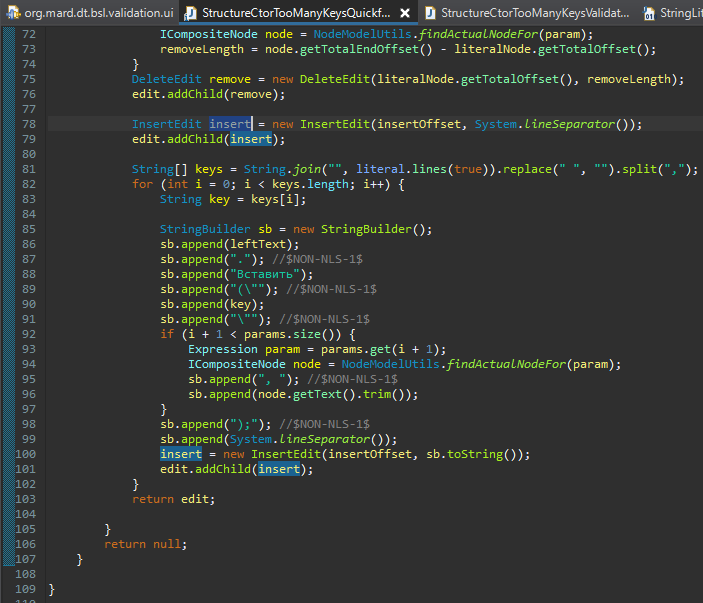
Следующее, что нам нужно сделать – это взять каждый параметр и сделать Параметры.Вставить() для каждого из этих свойств. Какие-то параметры были указаны в конструкторе – мы можем их перенести, чтобы рефакторинг был более умный.
Что мы делаем:
- Мы разбиваем ключи по уже понятному из валидации принципу.
- И обходим – для каждого ключа нам нужно сгенерить код типа «Вставить(ИмяКлюча»
- И дальше мы добавляем здесь это условие, что если у нас в параметрах было какое-то значение для нашего ключа (i+1 это индекс параметра), то мы находим его ноду и делаем «, ЗначениеНоды». Мы прямо берем ноду этого элемента. Нам даже неважно, что было в этом параметре. Нам достаточно просто взять текст и его сюда вставить. Поскольку уровнем выше мы уже весь текст удалили, то следующая вставка будет в то место, которое будет соответствовать значению insertOffset (что по-русски означает смещение).
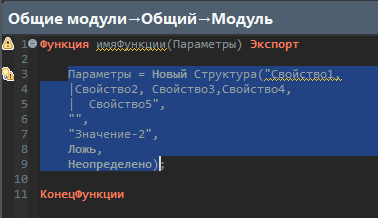
Как мы определили этот insertOffset (куда вставлять)? Мы переключились на ноду, которая описывает весь стейтмент –вот это все до точки с запятой.

Стейтмент statementNode – это семантический элемент, у которого есть левое и правое значение.
В данном случае, как вы помните, мы предварительно здесь проверили, что на вход у нас попадает SimpleStatement, который задает конкретно левое равно правое.
Мы знаем, что справа у нас OperatorStyleCreator. Это нам сама проверка нашла.
А с помощью statement.getLeft() мы получаем текст представления левого значения – для нашего рефакторинга не имеет значения, что слева (переменная, параметр или что-то еще), мы здесь просто взяли всю эту левую часть и ее текст.
Для определения куда вставлять, мы берем конечный Offset всей этой ноды с нашим стейтментом (statementNode.getTotalEndOffset()). И прибавляем к этому значению 1, смещаем курсор за точку с запятой – будем делать вставку в этом месте.

А дальше мы последовательно выполняем вставку текста, который генерится StringBuilder.
Все эти штуки, связанные с редактированием текста, есть в API по редактированию. И их нужно как-то изучать.
Я сейчас показываю вектор, куда смотреть, как изучать это API, а конкретную логику – это необходимо разбираться уже вам самим.
Результат работы плагина
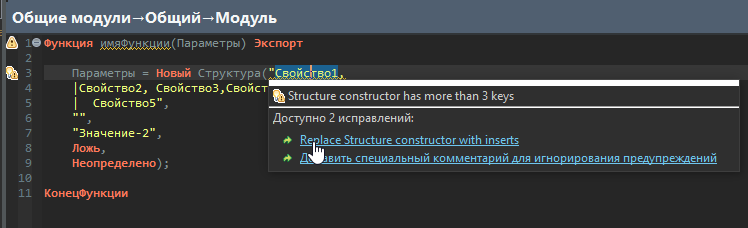
Теперь при наведении у нас добавляется наша проверка.
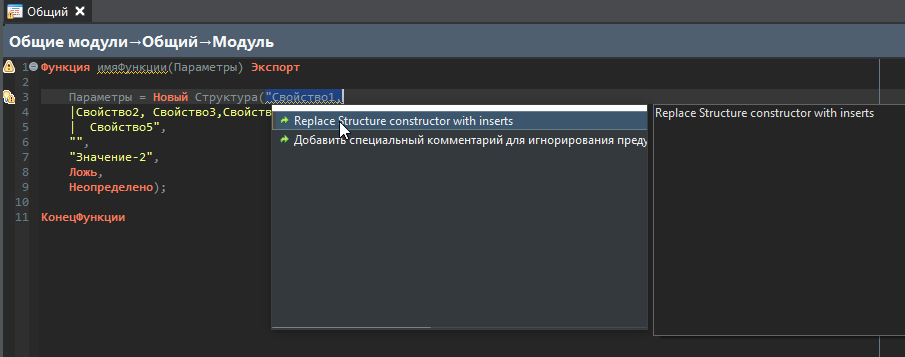
Или при нажатии Ctrl+1 у нас есть меню, которое выводит наш заголовок и детальное описание – я не потрудился детально описать, что мы делаем, но хорошо бы для пользователей сделать пояснение о том, что произойдет, если они выполнят эту модификацию.
Давайте запустим здесь автоматическое исправление.
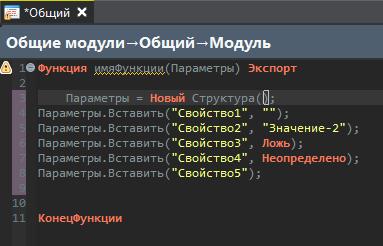
Вроде получилось то, что надо – все наши параметры разбились и перенеслись.
Что здесь еще можно добавить? Например, можно вычислить правильную табуляцию, которая должна быть для текущего объекта. В EDT есть специальные классы, которые тоже позволяют это легко вычислять. Также можно, допустим, по глобальной настройке в редакторе вычислить, что используется в качестве табуляции – табы или пробелы, и это тоже учитывать. Для этого можно посмотреть какие-то готовые примеры квикфиксов, которые есть в самой EDT.
Видео по созданию плагина для автоматического исправления (Quick-Fix)

Итак, мы сделали два плагина для 1С:EDT – один плагин по проверке и второй по автоматическому исправлению.
В следующей части мы рассмотрим, как сделать проект, реализующий поставку обоих этих плагинов для конечных пользователей.
****************
Статья подготовлена совместно с редакцией Инфостарта на основе серии обучающих видео по созданию плагинов для 1С:EDT.
Вступайте в нашу телеграмм-группу Инфостарт