Внедрение поддержки конфигурации поставщика в проект на EDT
Предпосылки
- Мы ведем разработку крупного проекта в EDT (написан на базе 1С:БП, но по сути, практически полностью самописная конфигурация). Разработка ведется полностью в EDT + gitlab. Конфигурация полностью снята с поддержки.
- Параллельная команда разработала собственную конфигурацию, которую надо встроить в нашу конфигурацию
Как бы мы решали эту задачу, работая в конфигураторе – добавили бы еще одну конфигурацию поставщика и поддерживали ее. Как правильно поступить в гите – об этом статья.
Дисклеймер
- Все написано на основании собственного опыта, вероятнее всего есть более правильные решения, буду рад, если вы поделитесь идеями в комментариях, как улучшить предложенную схему.
- Чтобы не нарушать NDA, для примера будем использовать репозиторий простой конфигурации на базе БСП. (Надеюсь, автор репозитория не будет сильно против). В качестве «Конфигурации поставщика» будет нечто небольшое, состоящее из справочника и регистра сведений. Наша задача пройтись по процессу, а не решить реальную задачу.
- Данная статья написана для тех кто уже работает с EDT и Git, или планирует переход на данный стек. Мы не будем останавливаться на вопросах зачем делать свою конфигурацию на поддержке другой (чтобы иметь возможность обновлять функционал от поставщика), не будем сравнивать функциональность с конфигуратором, решать что лучше или хуже (личное мнение - пока, на конфигураторе удобнее), глубоко вникать в суть работы с Git и его терминологию (на этот счет написано достаточно много статей и дублировать их тут особого смысла нет).
Цель статьи - пошагово рассказать в практическом примере, как организовать возможность разработки собственного продукта на поддержке конфигурации от стороннего вендора, подсветить возможные "подводные камни", показать, на что стоит обращать внимание. - Конечно, такой вариант разработки не подходит для текущего сопровождения типовых баз. Если Вы дорабатываете типовую конфигурацию от 1С для конечных пользователей, лучше использовать "классические механики", точечно включая возможность изменения для конкретных объектов конфигурации, максимально сохраняя поддержку. Описанная методика в большей степени, подходит для разработки собственного тиражного продукта, или для "инхаус-разработки"
- Мы рассмотрим подход к разработке, декларируемый Вендором. Возможно, есть иные, более удобные, в каких-то ситуациях, подходы, однако мы рассмотрим именно тот, который показала Фирма 1С.
- Предполагаем, что Читатель знает, как выполнить те же действия (добавить еще одну конфигурацию поставщика), используя конфигуратор, знает, что из конфигурации поставщика нужно в его проекте, а что нет)
Внедрение
Существует известная проблема о том, что EDT не работает с поставкой в "классическом" для нас, 1С-ников, понимании. То есть, мы не можем менять правила поддержки объектов конфигурации поставщика, не можем создавать собственные поставки и так далее. На смену этим практикам приходит git.
Итак, первое, изучим видео от 1С:
Организация командной разработки в 1C:EDT - расширенная часть

Здесь в общих чертах описан подход, которым мы будем руководствоваться далее.
Кратко: нам необходимо создать в репозитории проекта отдельную ветку, в которой будет храниться конфигурация поставщика. Затем, с помощью слияния веток, мы будем переносить необходимый функционал в свой проект. При необходимости, сможем обновить ветку с конфигурацией поставщика и снова слить с нашим проектом. Звучит несколько сложнее, чем то к чему мы привыкли (на самом деле и на практике все посложнее), однако необходимо разобрать этот вопрос для полноценной работы в стеке Git + EDT.
Создание ветки вендора, подготовка репозитория
Мы находимся в ситуации, когда у нас уже есть проект, есть коммиты в гите и необходимо внедрить поддержку конфигурации поставщика.
Первое, что нам необходимо сделать – создать новую ветку в репозитории, в которой будет храниться конфигурация поставщика. Для этого нам не подойдет интерфейс EDT, т.к. EDT может создавать только дочерние коммиты на основании существующих, нам же необходим так называемый root-коммит, то есть, коммит не имеющий "предка". Переходим в каталог локального репозитория и создаем новую ветку с root-коммитом. Выполняем команду
git checkout --orphan VendorBranch
здесь:
- git checkout – команда гиту переключиться на ветку;
- --orphan – ключ указывающий, что новая ветка будет создана root-коммитом;
- VendorBranch – имя новой ветки.
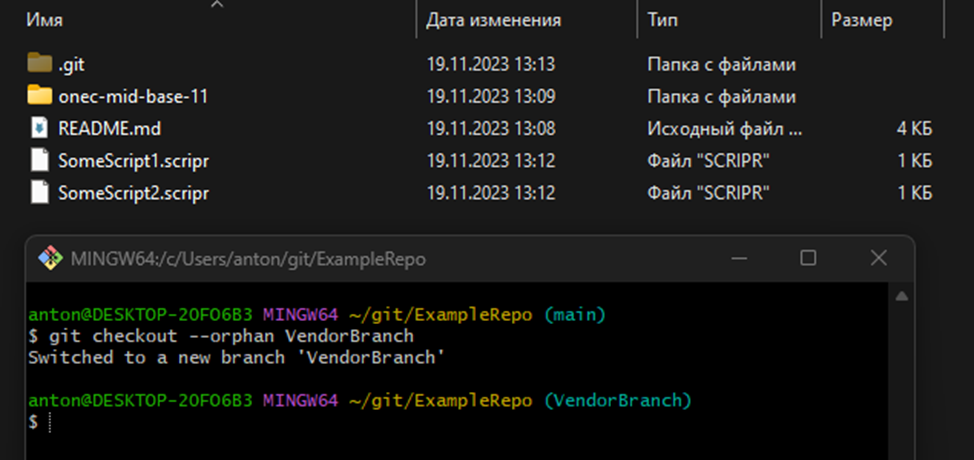
Возвращаемся в EDT и в панели Навигатор видим, что здесь тоже переключилась ветка.
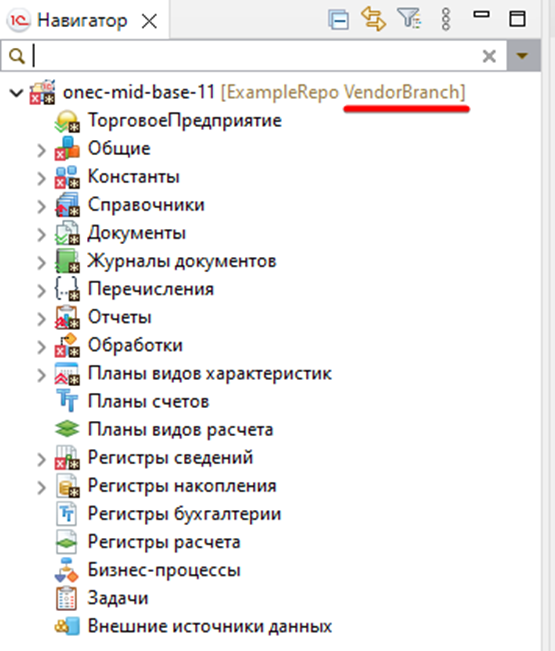
Теперь нам надо первым коммитом в этой ветке создать проект конфигурации поставщика, поэтому нам нужен пустой репозиторий гита, т.е. в каталоге должен остаться один файл - скрытый ".git". Для этого нам необходимо удалить текущий проект и все что могло относиться к нему
Долгий способ
Можно удалить все через графический интерфейс EDT, но это дольше и можно упустить некоторые моменты. Сначала надо удалить сам проект:
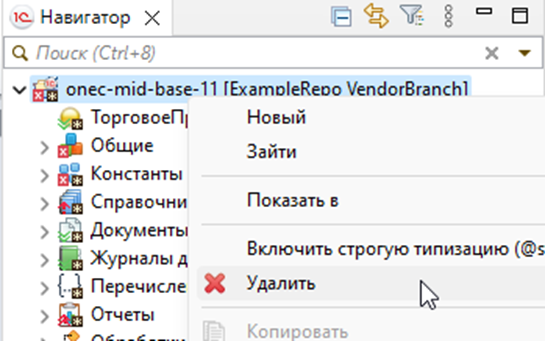
Удаляем вместе с содержимым проекта: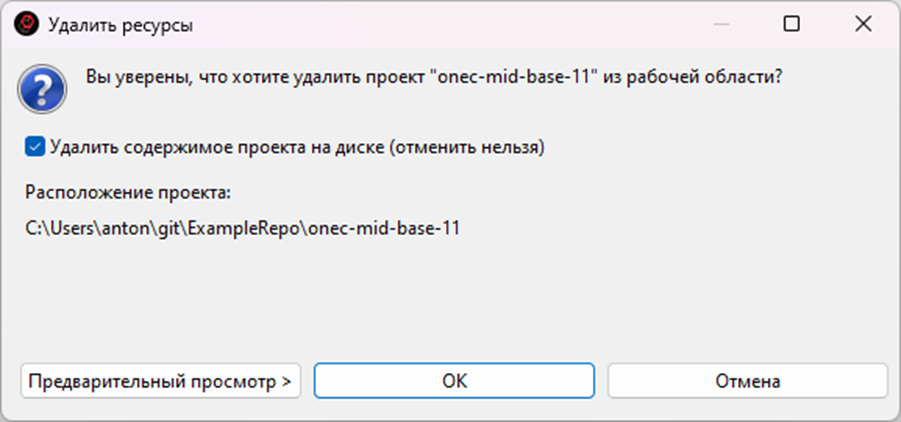
После удаления, если перейти в перспективу «Файлы», увидим, что проект в EDT отображается, как пустой:
Если проверить каталог локального репозитория, мы увидим, что проекта в нем нет. Но остались файлы, которые не были включены в конфигурацию – это могут быть «README.md»: проекты внешних отчетов и обработок, проекты расширений, или, например, файлы скриптов CI/CD-контура (или любые другие сопроводительные файлы). Эти файлы тоже надо удалить. Иначе в дальнейшем, они могут нам мешать обновлять версию конфигурации поставщика.
Поэтому, надо удалить эти файлы из проводника, консоли и т.д.
Удаляем файлы.
Быстрое удаление
Гораздо быстрее и надежнее происходит очищение репозитория средствами гита. Для этого достаточно ввести консольную команду, выполняющую полный сброс репозитория.
git reset --hard
Теперь, в результате обоих способов, мы имеем пустой проект в EDT, готовый к загрузке новой конфигурации поставщика. В каталоге репозитория должен остаться только один файл – скрытый “.git”
Загрузка конфигурации
Для того чтобы загрузить конфигурацию поставщика: создадим новую базу, загрузим в нее конфигурацию и снимем конфигурацию с поддержки.
----------
Почему конфигурация снимается c поддержки
В моем примере, конфигурация снимается с поддержки, т.к. нам необходимо иметь возможность вносить изменения в объекты конфигурации вендора для ее внедрения в механизмы исходной. Если этого не сделать, объекты (как ни странно) останутся на поддержке и после слияния с основной конфигурацией, это затруднит дальнейшую разработку.
Если же конфигурация поставщика не будет меняться (например, если добавляется отдельный самостоятельный блок функционала) этого можно не делать. Однако, в будущем, если все же, изменения потребуются, надо будет изменить правила поддержки именно в ветке с конфигурацией вендора, иначе при очередном мерже веток, объект снова "встанет на замок", а обновить конфигурацию будет не возможно, т.к. EDT сообщит об ошибке:
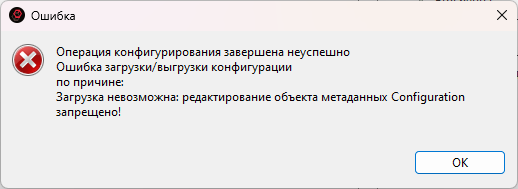
Придется снова зайти в конфигуратор, настроить правила поддержки и только после этого снова запускать отладку. В общем, во избежание кучи мелких, неприятных проблем, правила поставки надо настраивать изначально, в ветке с конфигурацией вендора, или вовсе отключить ее (поддержку)
----------
Закроем конфигуратор, вернемся в EDT и импортируем эту конфигурацию в проект с таким же именем, какое установлено у основного проекта.
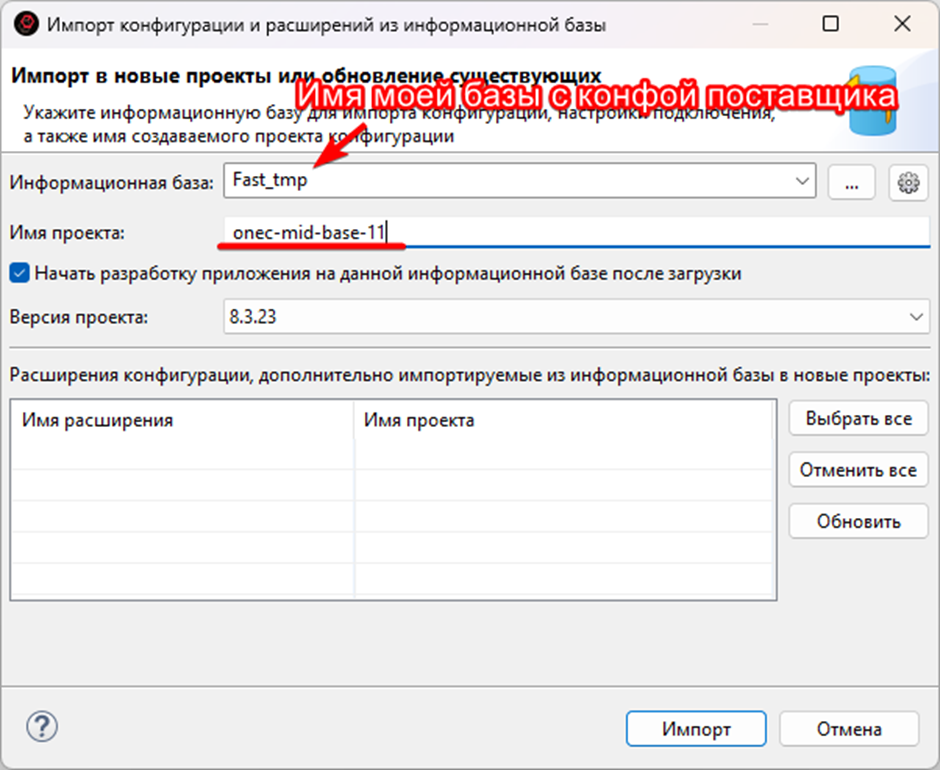
Нажимаем «Импорт» и получаем проект
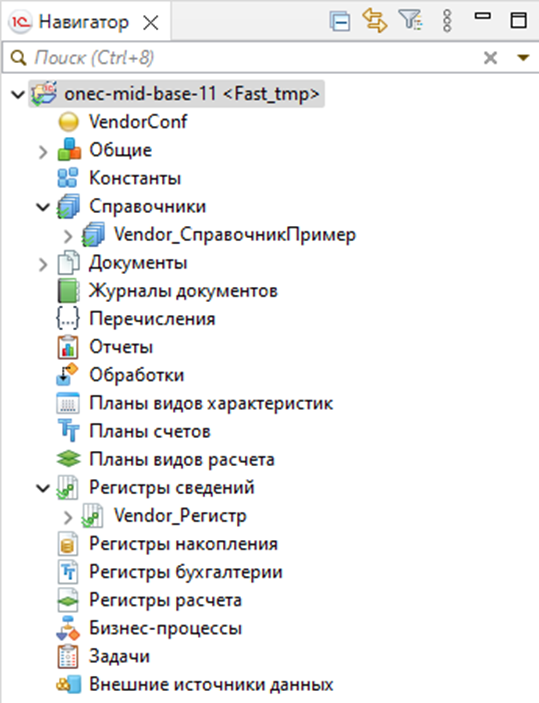
Сейчас, как видим, проект не связан с репозиторием. Идем в контекстное меню «Групповая разработка» – «Общий проект»
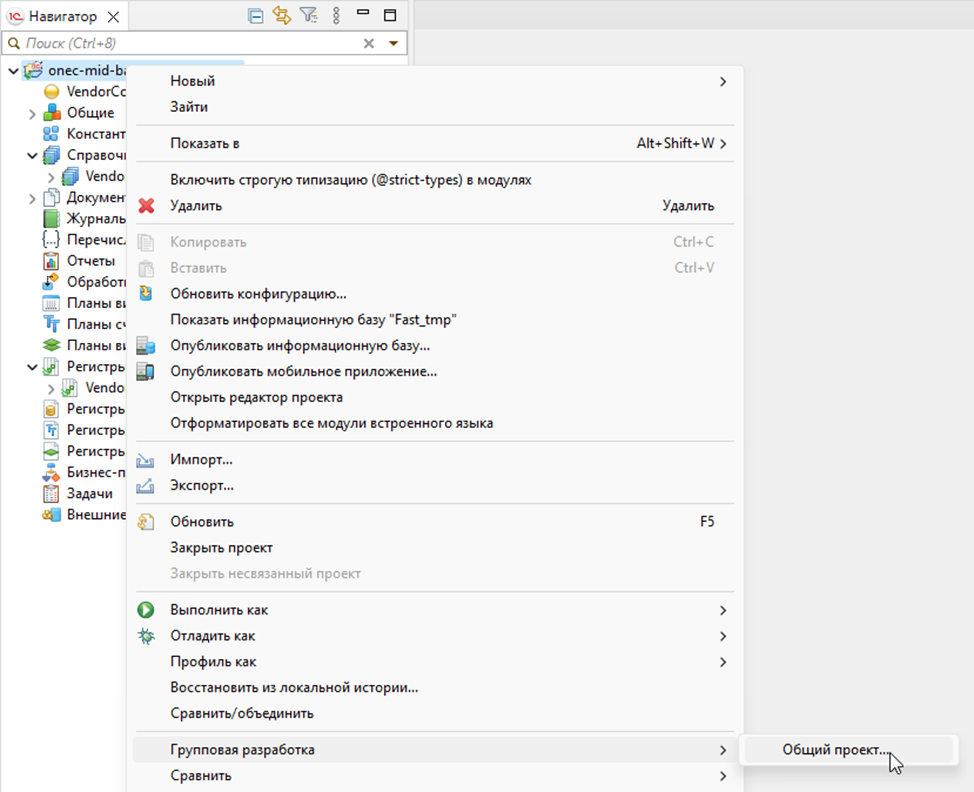
Здесь, указываем репозиторий
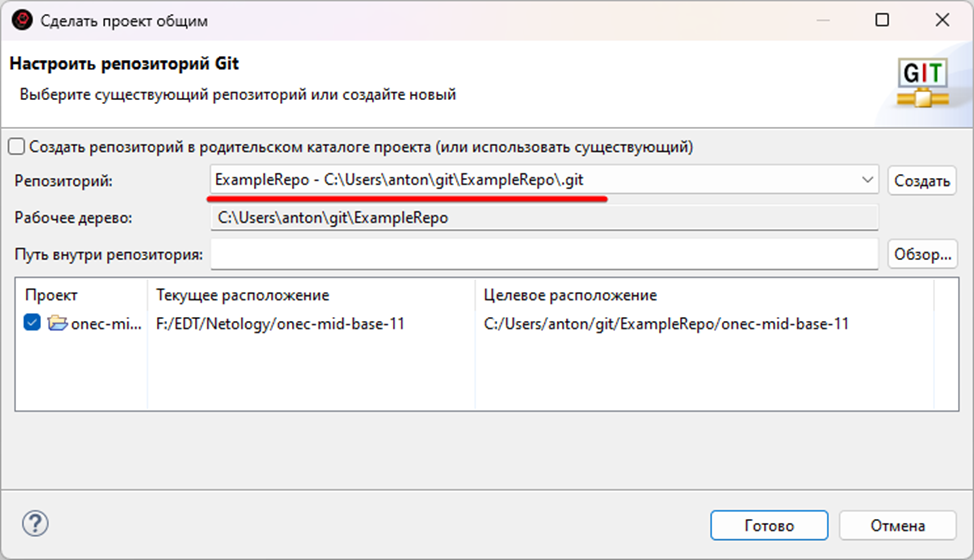
Проект был связан с репозиторием
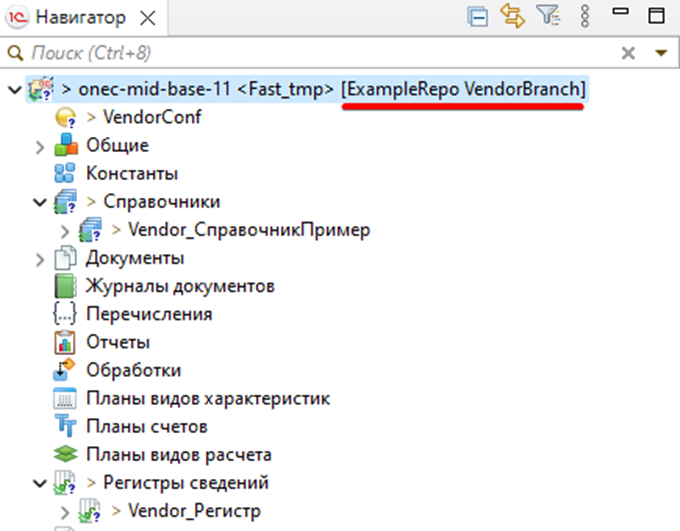
Теперь, необходимо закоммитить проект в репозиторий. В перспективе Git, добавляем все файлы в индексированные и создаем коммит.
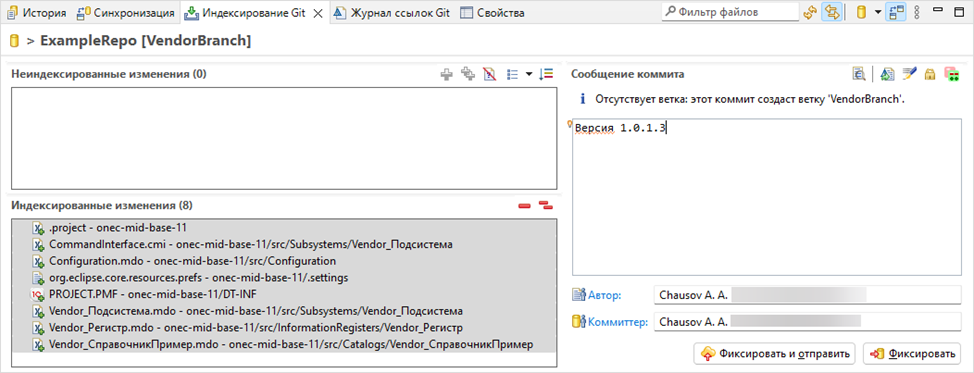
В итоге, у нас есть отдельная ветка, содержащая конфигурацию поставщика.
Слияние в основной проект
Дальнейшие шаги могут зависеть от выбранного вами flow разработки. Например, наиболее привычный для меня вариант - создать отдельную ветку под задачу внедрения конфигурации поставщика в проект и выполнить слияние через нее, затем создать мерж реквест на перенос в основную ветку. Пойдем по этому, но чуть упрощенному, пути. Основная идея: нам надо выполнить слияние текущей версии и конфигурации поставщика.
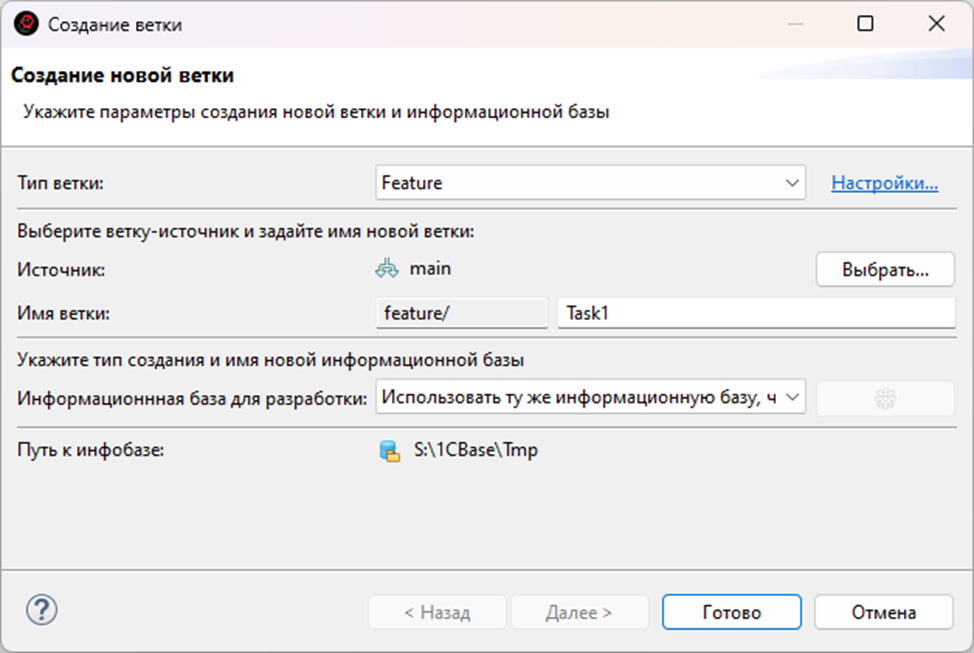
Итак, я переключусь на основную ветку (main), и создам от нее «feature/Task1» для слияния с конфигурацией поставщика.
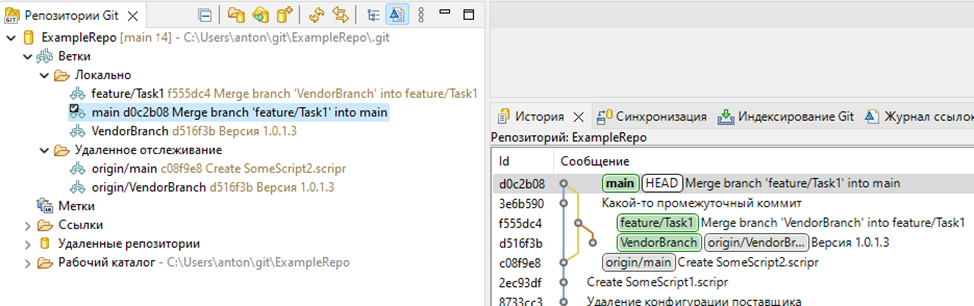
На перспективе Git можем увидеть, как сейчас выглядит дерево репозитория: есть дерево основного проекта и «отдельно висящий» коммит конфигурации вендора
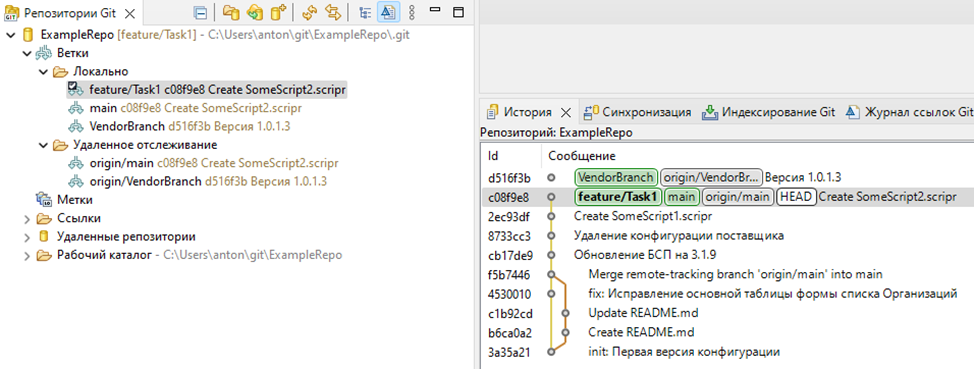
Далее, нам необходимо слить feature/Task1 с VendorBranch – можем выбрать ветку в панели «Репозитории Git» - в этом случае происходит слияние с последним коммитом ветки, или же выбрать конкретный коммит в дереве
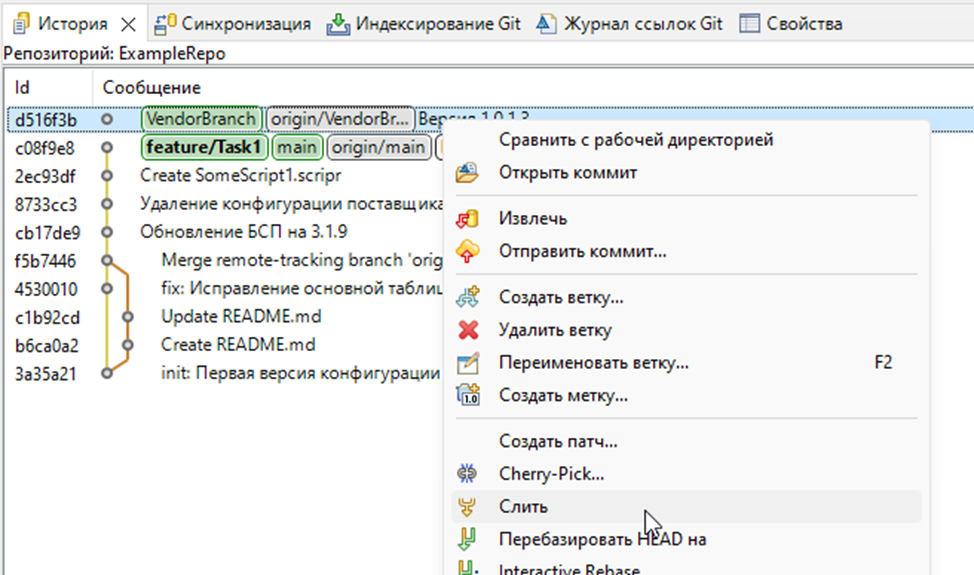
В настройках слияния (как показала практика) удобнее выбрать стратегию сопоставления объектов «По UUID», т.к. если есть совпадающие по наименованию объекты, не всегда нужно их сливать в один (с другой стороны, если это, например модули БСП, то их надо сливать, поэтому тут, вероятно, лучше поэкспериментировать для конкретно вашего случая)
Так же, как и сказано в видео от 1С, ставим флаг «Открыть редактор сравнения/объединения (даже при отсутствии потенциальных проблем)» - нам нужно будет настроить, как минимум, слияние свойств конфигурации
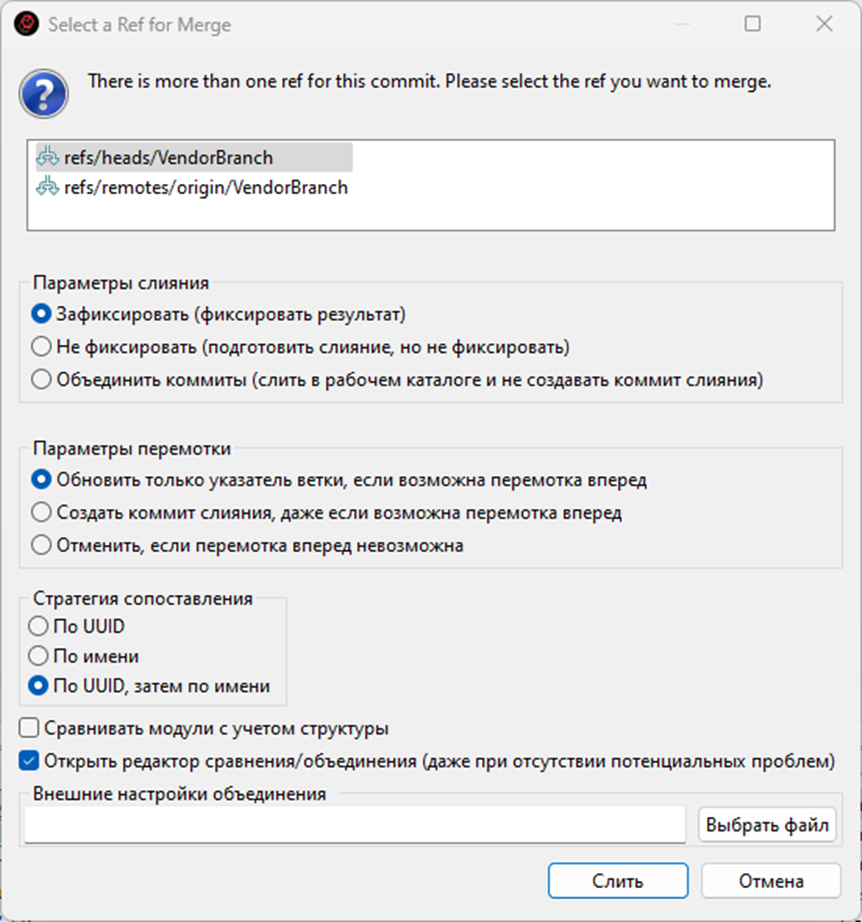
В дереве слияния по умолчанию, установлен фильтр «потенциальные проблемы»
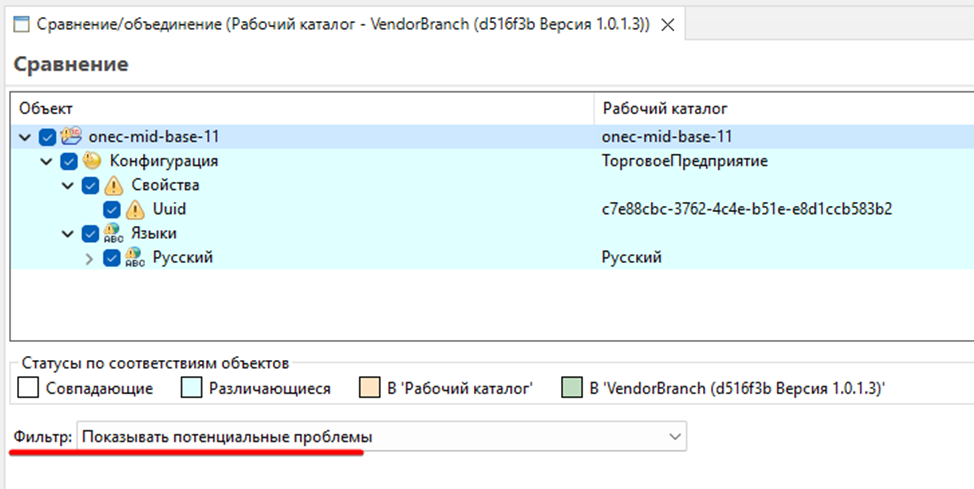
Но для нас важно проанализировать не только их, но все отличия конфигураций. Для этого, установим фильтр "Без фильтра"
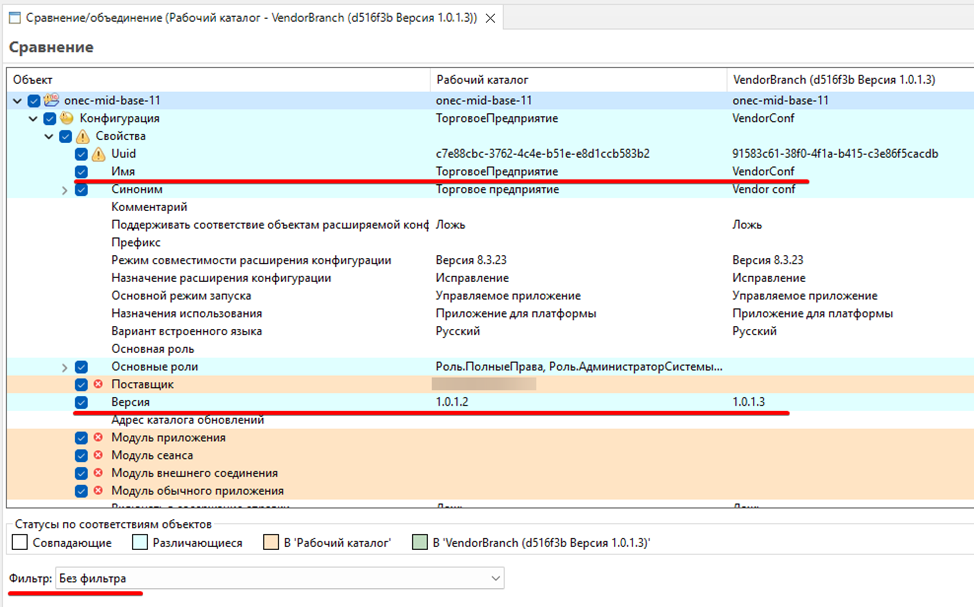
Скорее всего, не понадобится переносить такие свойства, как "Версия", "Имя", "Синоним конфигурации", информация о поставщике и т.д. (конечно, для каждой конфигурации, набор свойств следует проанализировать отдельно, на основе того, что требуется в конкретном проекте) Чаще всего, вам могут пригодиться только изменения в модулях.
Настройте слияние объектов и нажмите на кнопку «Объединить», выполните объединение и убедитесь, что все необходимые объекты созданы, код обновлен корректно.
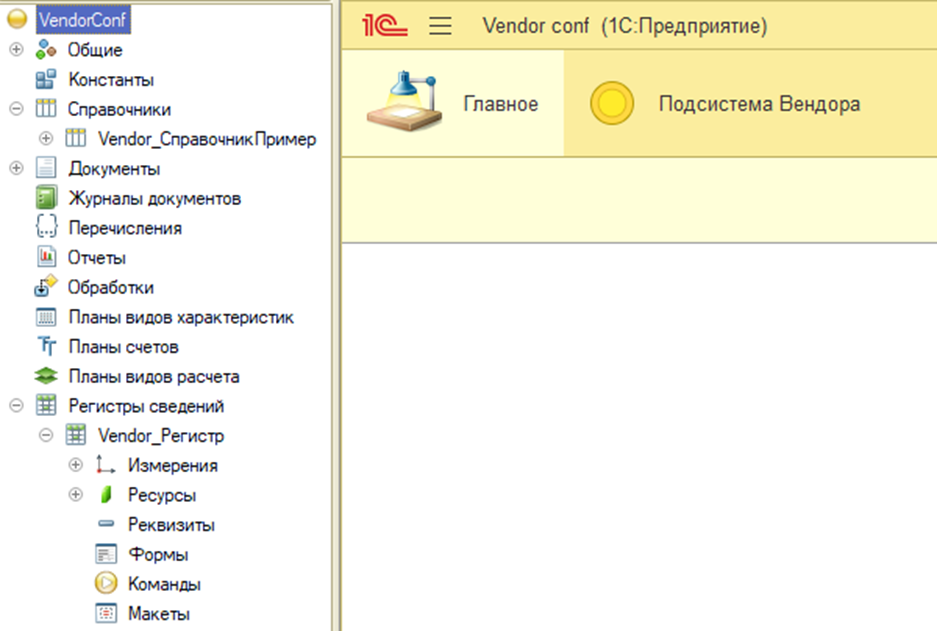
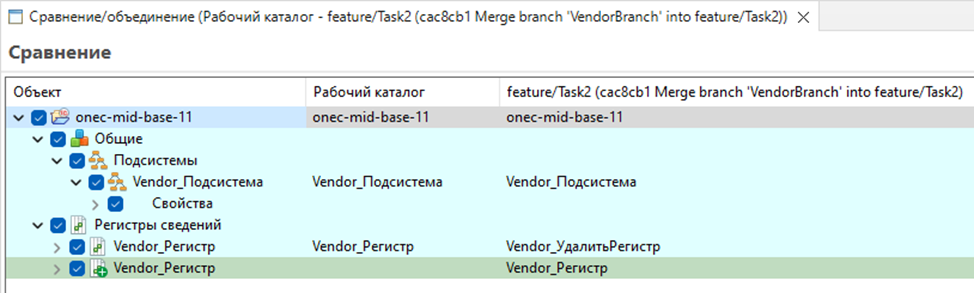
Проверьте, что объекты из конфигурации поставщика появились в дереве конфигурации (если конфигурация их содержала, конечно), а в пользовательском режиме отображаются все необходимые объекты, функционал работает корректно. В нашем примере - появились подсистема, справочник, и регистр.
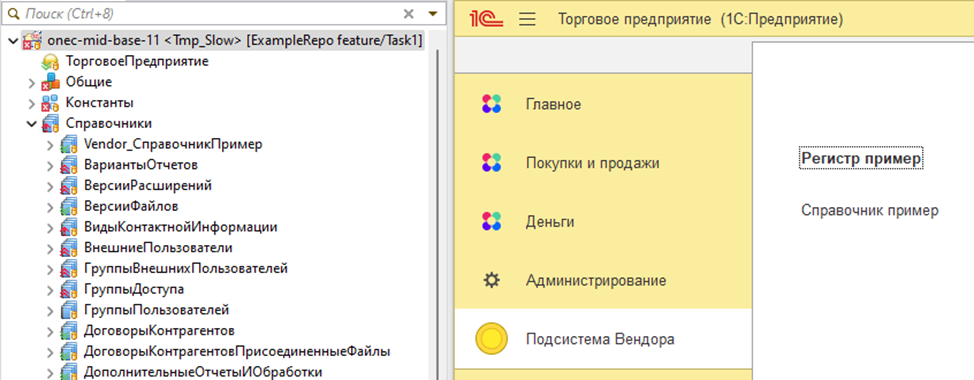
Конфигурация внедрена корректно, можно переносить доработки в основную ветку, согласно вашему flow.
Обновление конфигурации вендора
Конечно, внедрить конфигурацию – это хорошо, однако, очевидно, мы создавали отдельную ветку для вендора не просто так, а чтобы иметь возможность ее обновлять.
По этому, следующая тема, которую нам надо рассмотреть – это обновление конфигурации.
Обновление ветки поставщика
Переключаемся на ветку VendorBranch и запускаем Конфигуратор
Нам необходимо обновить проект новой версией конфигурации поставщика. Конфигурация, как мы помним, снята с поддержки, поэтому, для сохранения идентификаторов объектов метаданных мы обновим ее при помощи полной загрузки.
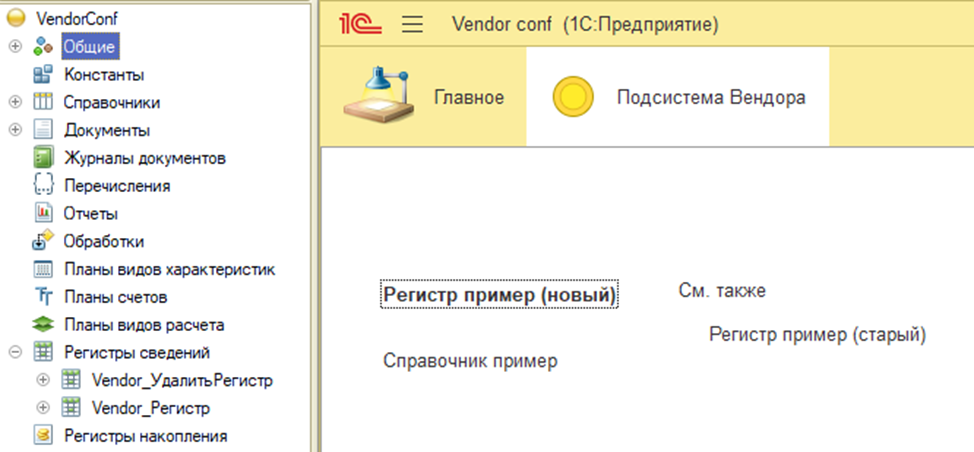
Почему не подходит сравнение-объединение? Если в конфигурации было изменено имя объекта метаданных и создан новый с тем же именем (например, меняем имя регистра на «Vendor_УдалитьРегистр» и создаем новый с именем «Vendor_Регистр»), то при сопоставлении новый и старый могут быть сопоставлены по имени и данные будут перенесены некорректно. Поэтому, пока лучшее решение, чем полная загрузка конфигурации найдено не было (может, коллеги в комментариях подскажут метод лучше?)
Итак, загружаем в базу данных новую версию конфигурации поставщика, снимаем ее с поддержки, обновляем конфигурацию БД.
Закрываем конфигуратор, переходим в EDT и переключаемся на ветку VendorBranch. В панели Приложения импортируем конфигурацию из базы в проект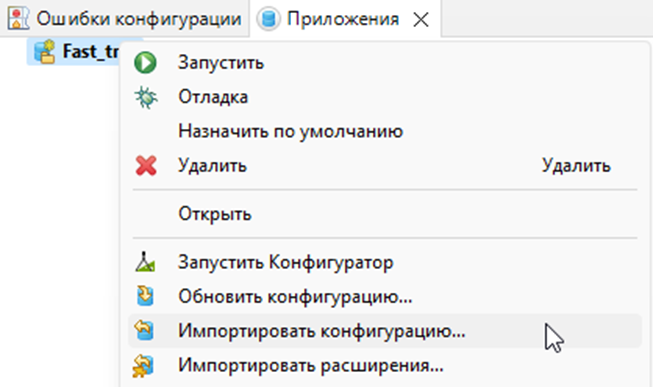
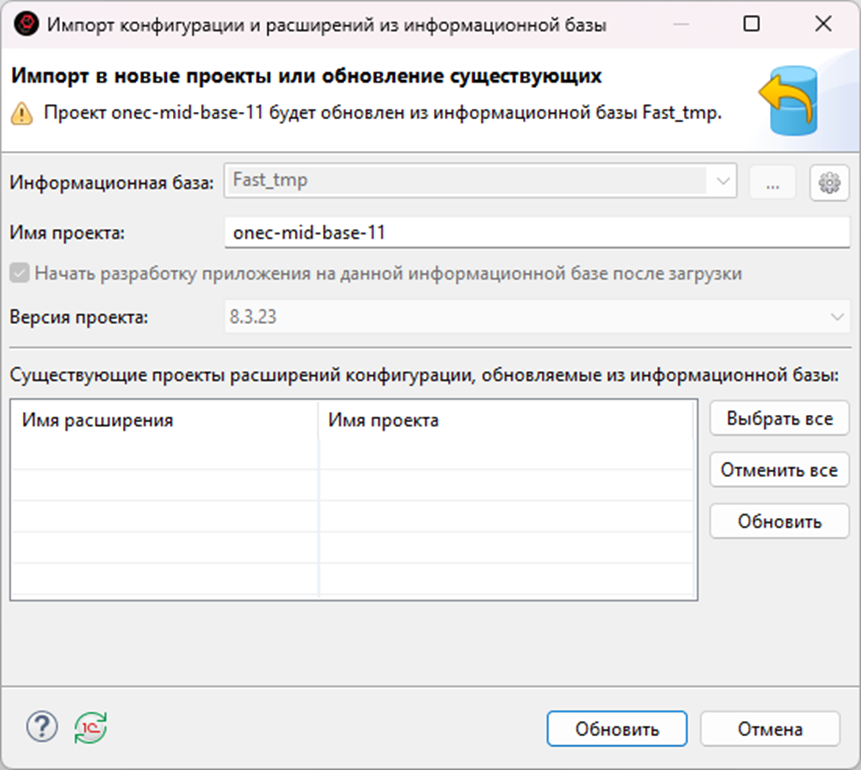
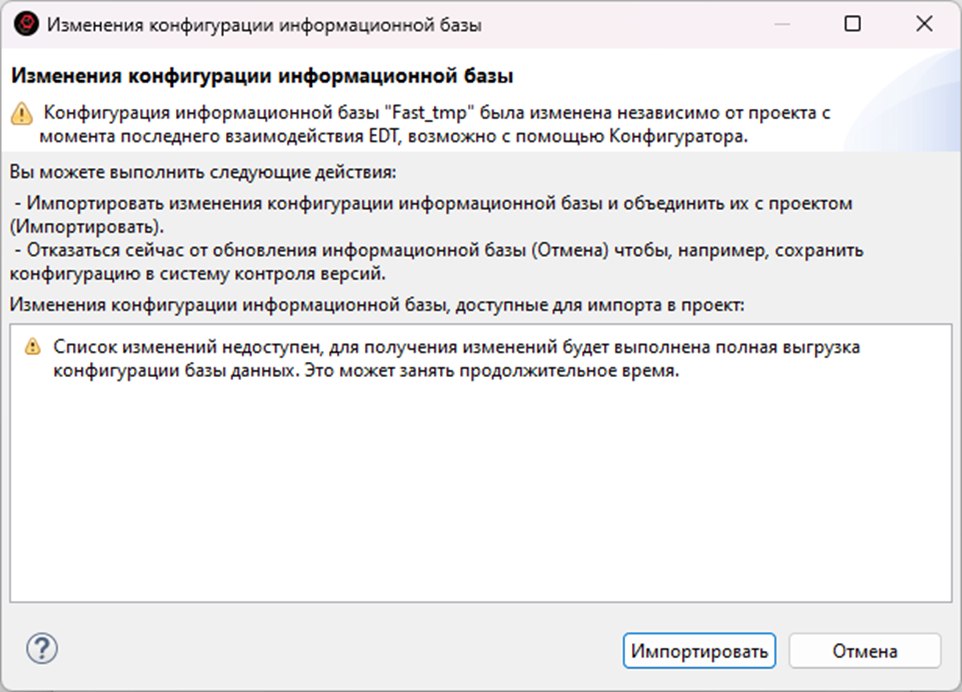
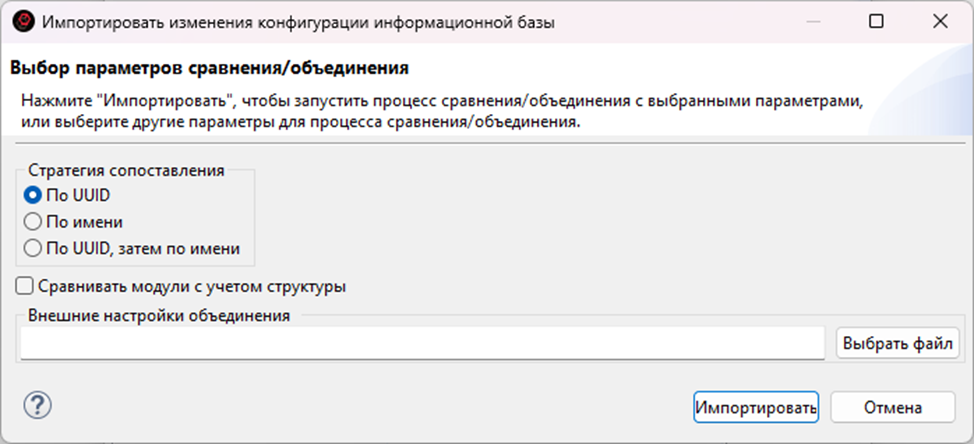
Здесь, так же, в стратегии сопоставления, сопоставляем по UUID, чтобы новый регистр не сопоставился со старым по наименованию (в реальном проекте, к сожалению, такой артефакт случился)
Убедимся, что изменения «затягиваются» в проект
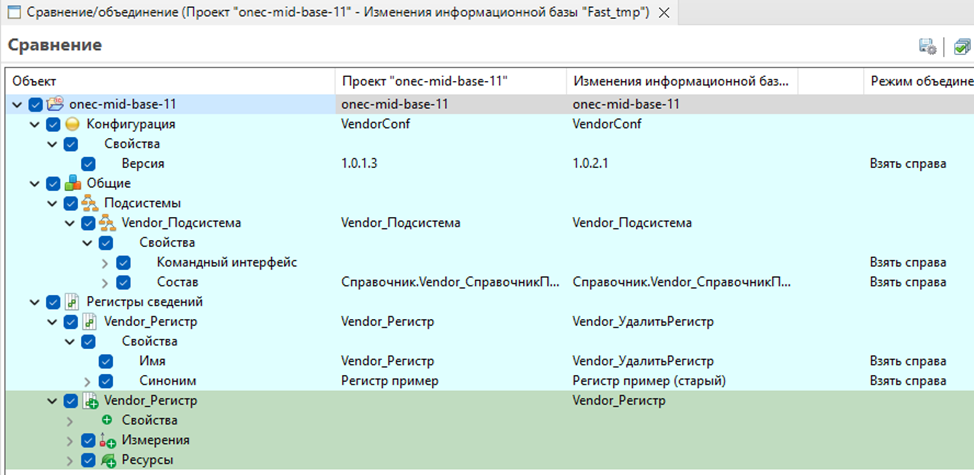
Коммитим изменения в репозиторий
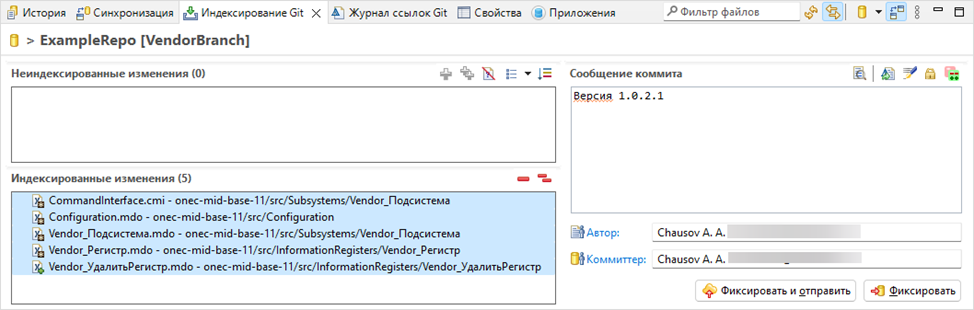
Ветка обновлена. Осталось перенести изменения в проект.
Слияние в основной проект
По большому счету, слияние при обновлении не отличается от слияния при первой загрузке, все действия аналогичны. Но опять же, надо следить за тем, что объекты сопоставляются правильно.
В том числе, объекты БСП. Например, в реальной задаче вылезла проблема с модулем БСП ПодсистемыКонфигурацииПереопределяемый – в основном проекте у него один UUID, в конфигурации поставщика – другой. Сопоставить можно по имени, но в этом случае, некорректно сопоставляются переименованные объекты конфигурации (Регистр – УдалитьРегистр) – решение этой проблемы пока не придумалось.
Что ж, создаем новую ветку от основной и сливаем ее с необходимой версией вендора
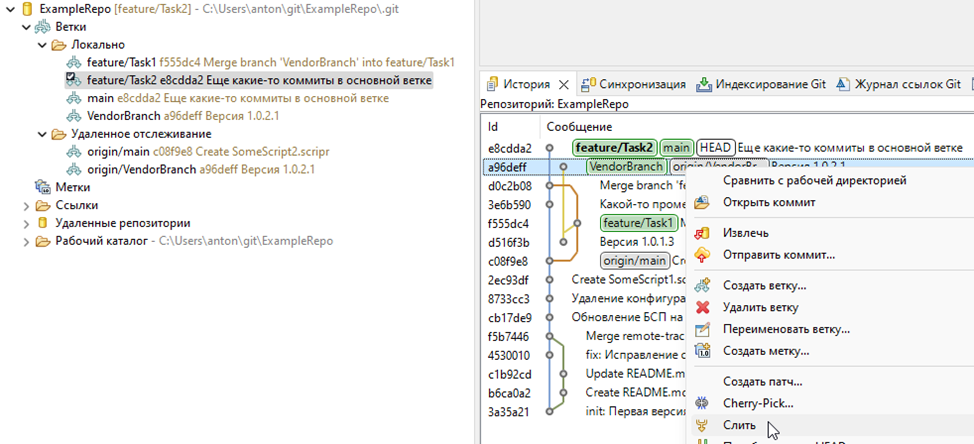
Сравниваем по UUID и открываем редактор сравнения даже при отсутствии проблем. Разрешаем конфликты, если они есть, и объединяем ветки
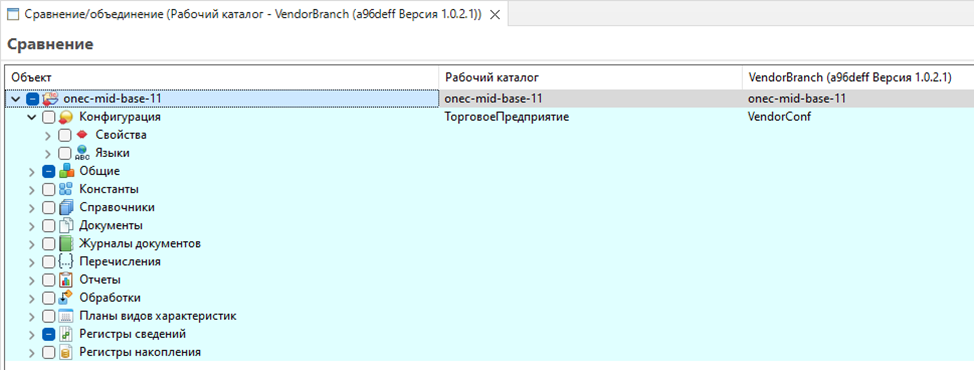
Проверяем, что все объединилось корректно
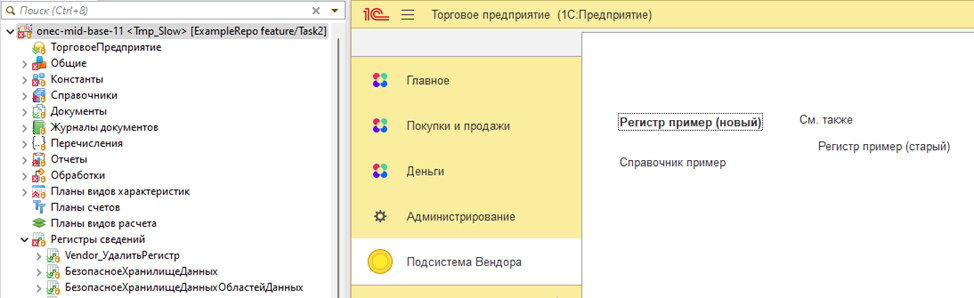
И если нас все устраивает, переносим изменения в основную ветку согласно flow разработки. Если сливать в интерфейсе EDT, это выглядит примерно так. Регистры сопоставляются корректно.
Дерево репозитория после всех махинаций выглядит так
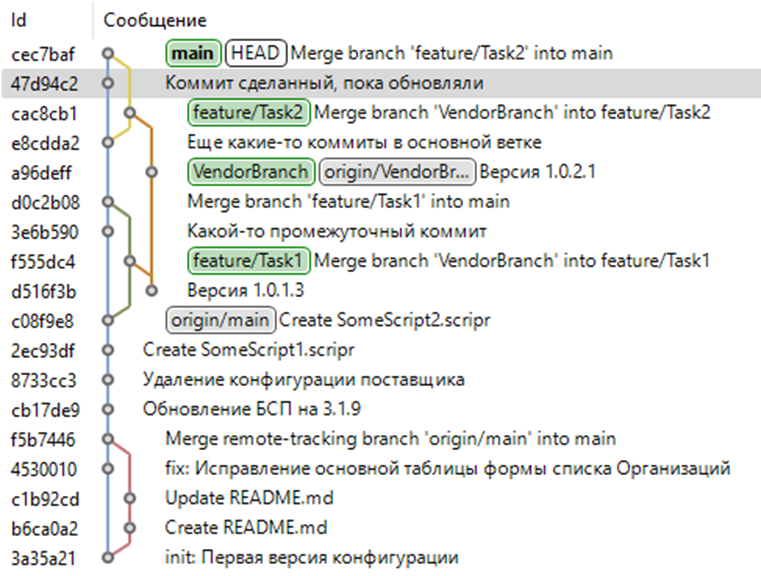
Голубая ветка – main
Коричневая (или оранжевая?) – ветка вендора
Зеленая – фича-ветка при первом слиянии
Желтая – фича-ветка при обновлении.
Выявленные проблемы, которые пока не понятно как решить
В основном, все проблемы связаны с сопоставлением объектов конфигураций. Не понятно, какую стратегию применить.
|
Проблема |
Текущее решение |
|---|---|
| Изменение uuid в типовых объектах (БСПшных) | Менять uuid вручную на тот, который указан в основном проекте. Если не найду более подходящее решение – видится логичным просто заскриптовать это изменение. |
| Объект был удален и добавлен новый с таким же именем (в данном случае появляется дубль, мешающий объединению) |
Менять uuid вручную на тот, который указан в основном проекте |
| Удаление объектов в конфигурации поставщика (при слиянии они не удаляются в основном проекте, надо чистить вручную) |
После слияния с основным проектом, запустить отдельно базу с конфигурацией вендора, найти удаленные объекты, убедиться, что они удалены в основном проекте, или удалить вручную |
| Объекты БСП заменяют собой существующие Пример - ПодсистемыКонфигурацииПереопределяемый |
Всегда объединять вручную |
| Настроенные при внедрении объекты метаданных (например, определяемые типы) после обновления надо контролировать. При слиянии веток их тип заменяется на указанный в ветке поставщика |
Наверняка, у этих проблем есть (или, может, появится) более простое решение. Было бы интересно послушать мнение коллег.
Заключение
Думаю, если изначально разрабатывать конфигурацию на поддержке поставщика, проблем должно быть меньше (хотя бы, проблем с uuid объектов конфигурации поставщика)
Субъективно, механика поддержки в конфигураторе, пока, сильно выигрывает. Но при необходимости поддерживать конфигурацию поставщика, работая в EDT можно. Удобно ли это – не во всех сценариях. Телодвижений, конечно, больше.
Надеюсь, инструкция будет полезна тем, кто столкнется с такой задачей в будущем.
Вступайте в нашу телеграмм-группу Инфостарт