Меня зовут Максим, я тимлид компании Programming Store. У меня будет не технический доклад про EDT+Git, а дискуссионный. Он не о том, как я использую EDT+Git, а про то, почему их вообще надо использовать. И почему заказчики любят, а разработчики ненавидят EDT и Git.

Заказчики любят EDT+Git за прозрачность и контроль качества. А у разработчиков есть две основные причины их не любить – это тормоза и глюки.
Но если развернуть до пунктов, то мы придем к такому чек-листу, как на слайде. Здесь каждый пункт говорит о том, почему конкретно нам нужно перейти на EDT и Git, и как сделать так, чтобы разработчики при этом не страдали.
Буду рассказывать с двух сторон – со стороны менеджера и со стороны программиста, что каждый пункт дает и тому, и другому.
Качество кода и соблюдение стандартов
Первый пункт — это качество кода и соблюдение стандартов.
Практически в каждой команде поддержки и внедрения 1С есть регламент, где написано «Мы соблюдаем стандарты разработки 1С». Но в реальности стандарты 1С мало кто знает, а соблюдают – еще меньше.
Получается, что у нас есть требование, но, если в компании не развернуто АПК или SonarQube, реального контроля нет – даже если мы знаем о проблемах неканонического написания кода, мы можем просто их не заметить. И архитектор, когда проводит ревью, тоже может не заметить.
А EDT даже без внешних плагинов, во-первых, сама анализирует лучше, чем конфигуратор. Если вы напишете «1+Структура», это пройдет проверку синтаксиса в конфигураторе, но не пройдет в EDT – она покажет вам уведомление об ошибке. И там уведомления показываются удобнее, они суммируются и так далее.

Плюс, если нам нужен реальный контроль за качеством кода, нам нужны системы типа Sonar или АПК. Они возвращают конкретные ошибки несоблюдения стандартов конкретному разработчику с указанием на конкретную строку.
У разработчика растет самооценка, потому что ему на ревью меньше прилетает от архитектора – благодаря Sonar он уже почти все вычистил. Если архитектор и находит проблемы, они уже не связаны с неканоническим написанием слова «Из». И у разработчика растет знание стандартов просто потому, что ему 50 раз прилетает одно и то же, он уже запомнил, и в следующий раз пишет по-другому.
И архитектор рад, потому что у нас растет качество кода, ему не нужно искать при ревью неканоническое написание слова «Из» – можно концентрироваться на поиске более серьезных проблем.
То есть если у нас есть требования к качеству – это один из поводов задуматься о том, чтобы начать внедрять EDT, Sonar и АПК.
Нужен GIT
Следующие два пункта – о том, что нам нужен Git. Этот тезис я разделил на два, потому что в первую очередь нам нужно больше хранилищ.

Есть такое мнение, что если у вас на проекте есть отдельно релизное хранилище, отдельно предрелизное хранилище – значит, у вас есть такой человек, который их периодически сравнивает и объединяет. И он этому очень «рад» – мы видим, что он улыбается.

Он делает объединение хранилищ во внерабочее время, потому что в рабочее время все объекты захвачены – ему приходится всех отовсюду выгонять.
А если каждый делает сравнение-объединение сам, значит, мы периодически что-то пропускаем, и у нас залетает часть неготового функционала, или не залетает часть готового, потом это сыпется, хотя вроде в тестовом контуре работало.
Git снимает с нас проблему сравнения хранилищ – там организовать групповую разработку конфигурации удобнее.
-
Во-первых, мы можем развернуть ветки – там каждый работает в своей фиче.
-
При слиянии Git большую часть сольет сам. Какие-то вещи, который не смог разрулить Git, мы разрулим с помощью KDiff3.
-
Если у нас крайний случай, и при слиянии Git есть какие-то проблемы по реквизитам, мы можем запустить в EDT привычное всем сравнение-объединение, но нам не надо будет перезахватывать объекты для того, чтобы выполнить это сравнение-объединение.
-
Если мы удаляем какой-то объект, нам не надо захватывать 100 тысяч ролей.
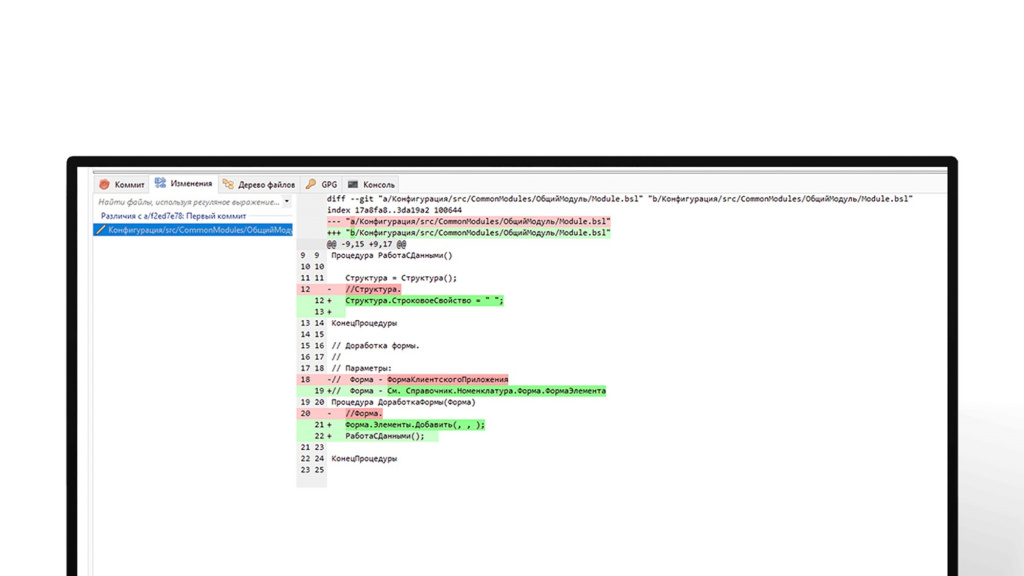
Если при сравнении хранилищ у нас что-то залетело в релизный или тестовый контур, как определить, кто внес эти правки и в каком коммите? Давайте поищем. Начинаем сравнивать версию с версией, версию с версией, версию с версией. Ага, вот здесь.
С Git это гораздо проще. На слайде – кусок скрина из Git Extensions. Здесь изменения у нас указаны построчно – на каждом коммите нам в один клик доступно посмотреть, кто и что менял, в каком файле, какую строку. Нам не надо сравниваться, чтобы узнать это. С помощью Git удобно проводить ревью и искать виновников факапов – снимать с «радостного» человека еще одну задачу.
Еще один момент, в чем Git лучше хранилища – вместо блокировок у нас слияние. Отсутствие блокировок – это основное преимущество Git перед хранилищем, на мой взгляд.
Если у вас с хранилищем работает большая проектная команда, у вас, скорее всего, есть регламент: «Мы не берем корень больше, чем на 20 минут». Или на 15 – у кого на сколько.
В Git нет такой проблемы: каждый может добавлять любые метаданные, какие хочет. Плюс все могут параллельно писать в один модуль, проблем при разработке от этого не будет.
Конечно, проблемы могут возникнуть при слиянии. Но опять же: Git что-то сольет сам; что не сольет Git, нам сольет KDiff3; а что нам не сольет KDiff3, мы сольем сравнением-объединением.

Если у нас постоянные битвы за корень – это сигнал о том, что нам нужно переходить на Git.
Если у нас есть конкуренция за один модуль конфигурации – это тоже сигнал о том, что нам нужно переходить на Git. Из исходников Git каждый может себе отдельно конфигурацию развернуть, и потом эти изменения смержить.
Следующая проблема хранилища в том, что мы можем терять доработки. Бывает, что нас кто-то просит отпустить объект, а у нас код еще не готов, потому что задача, например, на ревью или на согласовании. В результате нам приходится отпустить объект, и мы теряем код – вынуждены его куда-то или вырезать, или поместить неготовый, и отпустить.
А Git бы нас в этом случае спас, потому что наши доработки висели бы в отдельной ветке. Когда надо – мы бы их развернули, достали, стали пользоваться. Если не надо – удалили бы ветку и забыли. Проблемы с недопомещенными изменениями, с зависшими, потерянными изменениями Git тоже классно решает, очень помогает.
Если у нас на проекте есть такие проблемы, как сравнение хранилищ или конкуренция за ресурсы – это повод перейти на Git.
Готовность команды: обучение, торг, смирение, принятие
У нас была конкуренция за объекты; был человек, который все время сравнивал конфигурации, болел из-за этого и страдал; но нам нужно было качество кода. Чтобы решить эти проблемы, мы отказались от хранилища, внедрили EDT и внедрили Git. Но после этого у нас встала разработка:
-
кто-то разрабатывает в конфигураторе и выгружает файлы в Git;
-
кто-то разрабатывает в EDT, но жалуется;
-
кто-то вообще, может быть, уволился.
Почему? Потому что мы не провели обучение, не провели разъяснительную работу и в принципе были не готовы.

Поэтому до того, как отказаться от хранилища и сказать, что мы в него больше не коммитим, а коммитим в Git, нам нужно:
-
Провести обучение – необязательно всех на курсы отправлять, но пару видеоинструкций, пару митапов стоит провести, чтобы показать и рассказать про основные моменты.
-
Написать новые регламенты – не о том, что мы не захватываем корень, а о том, как мы помещаем изменения в Git, и что мы пишем в коммитах.
-
Написать инструкции – как разработчику работать с Git, чтобы у него была подсказка. Мы провели митап, всех всему научили, но на следующий день никто ничего не помнит. Нужны инструкции.
-
Нанять эксперта. Может быть, у нас есть кто-то в команде, может мы наймем со стороны, может, на аутстафе, на аутсорсе – как-нибудь. Эксперт нужен, чтобы адресно дообучать тех, кто забыл, чтобы обновлять те же инструкции и разруливать всякие непонятные глюки. Напомню, две причины, почему люди не любят EDT – это тормоза и глюки. И вот глюки должен решать эксперт. Должен быть кто-то, кто за них отвечает, с кого спросить, если у нас встала разработка.
-
И надо обязательно отодвинуть план на релиз, потому что даже если мы всех обучим, релиз все равно сдвинется – просто учитывайте это при планировании.
Мы всех обучили, наняли эксперта, отодвинули релиз, обновили регламенты, обновили инструкции, отказались от хранилища, запустили Git – но разработка опять встала. Почему? Потому что EDT прожорливый.
Готовность инфраструктуры
Нам нужна более мощная инфраструктура. Если мы этого не учли, у нас снова проблемы. Люди жалуются, люди не могут работать, все очень долго и медленно.

Нам нужно просто обновить конфигурацию, но с EDT это, оказывается, не приключение на 15 минут – поэтому сидим с глазами, полными ужаса, и четвертый час ждем, когда оно обновится.
Причем такая проблема может возникнуть даже на хорошей инфраструктуре.
EDT требует от нас немного другого темпа и ритма. Если в конфигураторе мы могли перезапускать отладку с каждой строкой, то здесь лучше вести отладку через те самые внешние обработки, о которых говорил Виталий Онянов – чтобы не перезапускать конфигурацию, потому что перезапуск будет долгим.

На слайде – системные требования к EDT с сайта «1С». Но, с моей точки зрения, информация в последней колонке – минимальная, плюс я бы рекомендовал умножать все значения на 2. Если там написано 16 гигабайт, я рекомендую 32.
Обратите внимание, 32 гигабайта нужно на каждого разработчика, поэтому:
-
Если мы – менеджер, который планирует запуск, нужно учитывать траты на железо.
-
А если мы – разработчик, перед которым маячит внедрение, кричите: «Дайте мне оперативку! Я не буду работать без оперативки!», потому что иначе с вас все равно будут спрашивать за сроки разработки, и никого не будет интересовать, сколько часов обновлялась база.
Резюмирую:
-
Если у нас готова инфраструктура; готова команда; мы понимаем, что нам нужен Git и требуем качества кода – тогда мы можем беспрепятственно перейти на EDT плюс Git.
-
А если у нас есть требования к качеству кода, есть конкуренция за ресурсы в хранилище, есть проблема со сравнением и объединением хранилищ – нам надо готовиться к инфраструктуре и обязательно обучить команду.
-
Если мы – программист, и нам говорят, что завтра Git – то требуем обучение и инфраструктуру.
-
А если мы – тот программист, который сравнивает хранилища – то требуем обучение, инфраструктуру и Git.
Вопросы и ответы
Сколько времени, по вашей статистике, занимает обучение персонала для перехода на EDT и Git?
Зависит от размера команды и размера проекта. Если у вас какой-то пет-проект или два программиста – может быть, и недели хватит. А если крупный проект – то на раскачку до полной продуктивности нужен месяц.
Это время обучения на человека. Чтобы человек, который никогда не работал в EDT+Git, смог использовать их продуктивно, надо потратить месяц на его вхождение.
Кроме перечисленных инструментов вы использовали дополнительные инструменты, которые помогают работать в EDT и в Git более эффективно? Какие-нибудь плагины или сторонние дополнительные утилиты, которые помогают решать вопрос с объединением конфигурации?
Да, для EDT много плагинов на GitHub. Плюс вы можете писать к ней плагины сами – для этого не нужно лезть глубоко в платформу.
Как вы решаете ситуацию, когда у вас есть типовая конфигурация, вы дорабатываете ее в расширении, потом обновляете типовую конфигурацию. И оказывается, что тот модуль, который был доработан в расширении, в последнем релизе типовой изменился. Как учесть эти изменения в расширении? Как искать эти места и делать правки?
Если у вас эти правки включены под &ИзменениеИКонтроль, то работает стандартная 1С-ная проверка применения расширений.
Насколько я знаю, она срабатывает уже в режиме предприятия. А чтобы знать это заранее?
Нет, можно же запускать ее из конфигуратора. И EDT, насколько я знаю, тоже полноценно работает с расширениями.
Судя по скринам Git Extensions, вы не используете EGit – встроенную в EDT интеграцию с Git. Натыкались на что-то?
Я использую EGit, когда надо сравнить, объединить реквизиты, например, при конфликте – в KDiff3 это мержить неудобно. Когда у нас в один справочник два разных разработчика добавили свои реквизиты, такое объединение доработок удобнее сделать EDT-шным сравнителем.
А вообще можно использовать любые удобные GUI – для Git их написано множество. Кто-то вообще с консолью любит работать – кому как удобно.
Насколько я слышал, те, кто более-менее поработал с EDT, рекомендуют не использовать EGit, а использовать любой другой сторонний клиент. Тогда вопрос: зачем вообще нужен EDT, если можно в конфигураторе также использовать сторонний клиент?
Тогда вам надо каждый раз выгружать файлы для Git.
Да, но это секунда.
Нет, не секунда, зависит от конфигурации.
Мне кажется, что принципиальное различие между работой через конфигуратор и через EDT заключается в том, что в EDT код становится неким объектом, над которым мы можем выполнять те или иные действия. Как следствие – это работа с кодом через Git, возможность анализа этого кода прямо на лету через синтакс-помощник EDT. Более того, плагины EDT вообще открывают безграничные возможности по работе с кодом, как с объектом. И потребность в таких вещах в основном возникает как раз-таки у управленческого персонала – это архитекторы, о которых вы говорили, тимлиды и так далее. И если такие большие возможности открываются, почему же все-таки EDT так плохо заходит?
В моем понимании, основные проблемы EDT – это тормоза и глюки. Разработчикам не хватает инфраструктуры и обучения.
Плюс нужна поддержка, чтобы заходило лучше. Информационная поддержка в плане огласки того, что это круто. И поддержка на местах, чтобы отвечать на возникающие вопросы.
Я среди своих коллег, кто работал в EDT+Git, проводил опрос: кому EDT нравится, а кому не нравится. На вопрос: «Кому EDT не нравится?» – все поднимают руку. И на вопрос «Кто будет работать через EDT дальше?» – тоже все поднимают руку.
Я знаю, что EDT работает с исходниками конфигурации, которые лежат на диске в текстовых и MDO-файлах. Но чтобы это попало к нам в конфигурацию, EDT конвертирует эти исходные коды в формат, которые понимает 1С. После этого запускает 1С, который загружает сконвертированные файлы в основную конфигурацию. И после этого основную конфигурацию помещает в конфигурацию базы данных. Не кажется ли вам, что пока 1С не выкинет конфигуратор вместе с основной конфигурацией из этой цепочки и не сделает некий компилятор, который позволит компилировать исходные коды в бинарник и загружать этот бинарник напрямую прямо в конфигурацию базы данных, EDT так и будет бедным родственником? Когда у нас появится такой компилятор? Понятно, что с исходным кодом мы работаем в Git – у нас нет другого варианта. Но так бы они напрямую попадали в конфигурацию базы данных, минуя несколько этих стадий.
Было бы здорово, если бы привязали Git напрямую к СУБД, чтобы сама структура конфигурации сразу мигрировала в базу.
Таким образом получается, что проблема не в EDT, а в платформе, которая сейчас обросла некими костылями.
Я надеюсь, что это временно.
Вы в докладе рассказывали про плюшки не столько EDT, сколько инструментов статического анализа и Git – такого, какой он есть. А почему заказчики-то любят EDT+Git? Как программист я могу понять, почему я люблю EDT+Git. Я сейчас в основном пишу на EDT, у меня уже Стокгольмский синдромом, я борюсь с ошибками, все нормально. Но заказчику-то какая разница? С его стороны сроки увеличиваются, потому что надо обучить программистов с этим работать. Требования по железу увеличиваются, потому что Java, даже если ты ограничиваешь ей максимальное потребление памяти, будет есть много и упрется в процессор. Почему заказчики-то любят EDT+Git?
Заказчики любят EDT+Git за обширные возможности контроля.
Вообще заказчик не любит программистов в целом. Ему не нужны программисты, они лишние в этом уравнении, он просто хочет делать свой бизнес. Но он вынужден с нами мириться и дружиться – мы нужны ему, чтобы он мог делать свой бизнес.
И EDT+Git – это тот инструмент, с помощью которого ему нас удобнее контролировать.
Возвращаясь к структуре файлов. В отличие от основной конфигурации конфигуратор хранит конфигурацию поставщика в cf-нике в сжатом виде. А чтобы хранить конфигурацию поставщика в EDT, нужны либо сабмодули, либо LFS и прочие штуки. Как это все стыкуется в 1С, чтобы и конфигурацию поставщика потом нормально обновить? Потому что, как минимум, работа через LFS, через трехстороннее сравнение для того, чтобы обновлять конфигурацию поставщика, добавляет много трудностей при работе через EDT. Как в EDT организовать трехстороннее сравнение, учитывая конфигурацию поставщика?
Просто сделайте ветку с типовой конфигурацией в Git и пользуйтесь трехсторонним сравнением в KDiff3.
А когда конфигураций поставщика две или больше? Например, мы разрабатываем конфигурацию «Управление аптечной сетью», у нас две конфигурации поставщика – УТ и «Библиотека интеграции с МДЛП». Обе надо обновлять.
Значит, надо их разделить – сначала УТ+УТ сравниваем трехсторонкой, потом МДЛП+МДЛП и потом уже общий файл сравниваем с нашим, например.
Сперва готовим общую конфигурацию поставщика, новую, если мы ее сами готовим, потом ее сравниваем.
Если EDT – такая тяжелая вещь, почему не сделать для каждого разработчика свое хранилище конфигурации? Через gitsync его выгружать в файлы и файлы уже сливать в Git.
Те, кто хочет Git, но не хочет мириться с EDT, так и работают.
Но в EDT если можно работать с Git без этой лишней прослойки в виде gitsync. Плюс не нужно ловить ошибки на выгрузках и тратить время и ресурсы на администрирование этого процесса.
Насколько больше времени стала занимать у вас реализация задач, когда ваша команда перешла на EDT? Она наверняка стала занимать больше, потому что мы тоже перешли на EDT, и я по своему опыту могу сказать. И готов ли бизнес мириться с дополнительными затратами?
Готов ли бизнес – это вопрос к конкретному бизнесу.
А насколько больше времени стала занимать разработка? Всякие однострочники править, маленькие фичи – станет сильно дольше. Раньше это было 2 минуты – станет 15. Вроде бы в 7 раз, но в контексте того, что вы не делаете больше двух задач в час – а я уверен, что не делаете. Потому что даже когда мы говорим про какие-то однострочники, все равно нужно взять тикет из Jira, отметиться в нем, списаться с аналитиком. Поэтому плюс-минус так.
А если говорить про большие задачи, то там большая часть – это не обновления, а тестирование, проектирование и так далее. И там нивелируется разница.
В целом, да, сроки должны вырасти. Но привести какую-то статистику, насколько конкретно вырастут сроки, я не могу.
Тогда я поделюсь нашим опытом. Когда мы перешли на EDT, то решили, что самая малая однострочная задача должна занимать два часа. Стали закладывать такой резерв на борьбу с EDT, потому что она может глюкнуть, могут возникнуть какие-то тормоза. Причем большие объемные задачи выполняются примерно за такое же время. А именно с маленькими задачами есть определенная проблема, и если много хотфиксов, время разработчика расходуется неэкономно.
Четыре задачи в день – это тоже неплохо. В любом случае, нужно же взять задачу, развернуть ветку, внести код, протестировать, отправить в ветку, отметиться в Jira.
За это бизнес разработчиков и не любит.
Но бизнес же этот контроль сам и придумал.
Хочу прокомментировать по поводу обновления конфигурации вендора – как мы это делаем. Никто же не отменял конфигуратор. Уходим в конфигуратор, делаем проверку применимости. Через KDiff3 лечим все эти &ИзменениеИКонтроль, которые сломались – как правило, они мержатся на автомате в 90% случаев. Потом просто загружаем изменения в ветку EDT и помещаем.
Да, KDiff3 удобно и к Git Extensions привязывать – там все так же в один клик открывается и мержится. Можно его и к конфигуратору для сравнения-объединения подшить.
Чего не хватает в принципе сообществу 1С, чтобы уйти от EDT? Мы же понимаем, что Eclipse тоже далеко не самая современная среда разработки за пределами 1С. Понятно, что для полноценной работы с исходниками нужен визуальный редактор форм и визуальный редактор свойств объектов. А каких еще шагов нам не хватает, чтобы уйти от EDT?
А зачем от него уходить? И куда? Даже 1С:Элемент, на который сейчас все делают ставку – он не взамен, а в дополнение. Он рассчитан на какие-то новые задачи – типа фронтов, мобильных форм и так далее.
Мне кажется, наоборот, люди постепенно будут все больше в EDT уходить.
Я говорю о том, что удобно работать с однострочными задачами просто в VS Code – выгружаешь конфигурацию в исходники и с ними работаешь. Не нужно ничего пересобирать – просто строчку поправил, закоммитил и все. Не секунды, конечно, но значительно быстрее, чем открывать EDT, ждать пока он откроется или еще что-то.
Если платформа станет не компилируемой, например, а интерпретируемой, то почему бы нет? Внес строчку – она уже работает, даже применять не надо.
У нас же есть скрипты по сборке конфигурации, мы даже форму можем представить как код. Осталось только собрать эти все вещи вместе, чтобы получилось что-то цельное, а не разрозненное.
Существующие для VS Code инструменты удобны, чтобы проверить качество, выполнить тесты, собрать конфигурацию, развернуть куда-то. Во всех этих процессах программист не задействован.
Мы можем в VS Code писать и анализировать код, но работать в нем пока не так удобно, как в конфигураторе или в EDT.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2022 Saint Petersburg.


Вступайте в нашу телеграмм-группу Инфостарт