Давайте начнем с того, что представим, что мы пытаемся разрабатывать наше решение качественно, пишем для него тесты и запускаем их на выполнение перед каждым релизом.
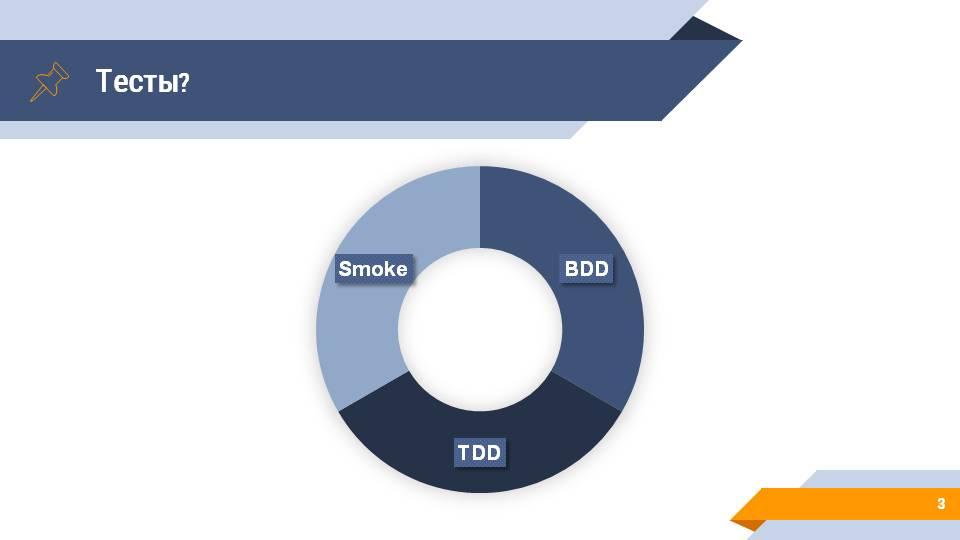
Какие тесты вообще могут у нас быть?
Тесты условно можно разделить на три группы:
-
Smoke-тесты (дымовые тесты). Это какие-то обработки или скрипты, которые выполняют рутинные действия над вашей конфигурацией – открывают все формы, пытаются провести все документы. На основании этих действий вы можете понять, есть у вас какие-то ошибки в базовой функциональности или нет.
-
Модульные тесты служат для проверки маленьких компонентов системы. Например, проверить что вызов функции с определенными параметрами вернет ожидаемый результат.
-
BDD или сценарные тесты. Если говорить про 1С, то чаще всего под сценарными тестами подразумевается нажатие кнопок на интерфейсе и проверка того, что на форме отображаются правильные данные – например, что документ провелся корректно, без сообщений об ошибок, всплывающих окон и т. д. Но это не всегда так. Есть классический пример сценарного теста выглядящий так: «Если у меня на счету 300 долларов и я подхожу к банкомату и пытаюсь снять 200 долларов, тогда банкомат дает мне 200 долларов наличными». Это тоже сценарий, все это тоже можно автоматизировать и переложить в тесты.
Проблемы при запуске тестов на рабочей машине
Какие могут быть проблемы, когда вы пытаетесь запустить эти тесты?
-
Когда вы на своей рабочей машине запускаете тестирование с помощью какого-либо фреймворка (например, это может быть Vanessa Automation), и параллельно пытаетесь писать код в своем любимом редакторе, то в какой-то момент – бац! У вас всплывает модальное окно, которое вы не можете закрыть, и вам приходится выполнять какие-то действия над ним, чтобы продолжить свою работу. Такие проблемы очень часто отвлекают. Ладно бы это всегда были просто окна, но могут быть вообще непонятные артефакты – куски выпадающих списков, отдельные кнопки, прорисовывающиеся сквозь ваш интерфейс.
-
Кто хоть раз пытался запустить на своем компьютере несколько экземпляров какого-либо тестового фреймворка, сталкивался с тем, что они начинают друг другу мешать. Несколько Vanessa Automation начинают воевать друг за друга – тест-менеджеры цепляют чужие тест-клиенты, инструменты снятия скриншотов захватывают не те окна.
-
Также могут быть проблемы из-за взаимодействия с сетевыми интерфейсами.

Через некоторое время вы начинаете выглядеть как этот котик. Вас все бесит, у вас ничего не получается. Это начинает очень сильно напрягать, и вы начинаете думать о том, что нет смысла пытаться масштабироваться, потому что даже на вашей текущей локальной машине все работает очень плохо.
Каким образом эту проблему можно решить?
Docker. Решение проблемы путем изоляции

Первый, и, наверное, самый простой вариант – это попытаться изолировать различные экземпляры запущенных приложений.
Есть расхожая шутка о том, что любую проблему вашего приложения можно решить, поместив его в Docker:
-
упали тесты - запихните приложение в Docker, они станут зелеными;
-
продалбываете сроки – запихните приложение в Docker;
-
не понятен список задач по проекту... Думаю, вы поняли общий смысл.
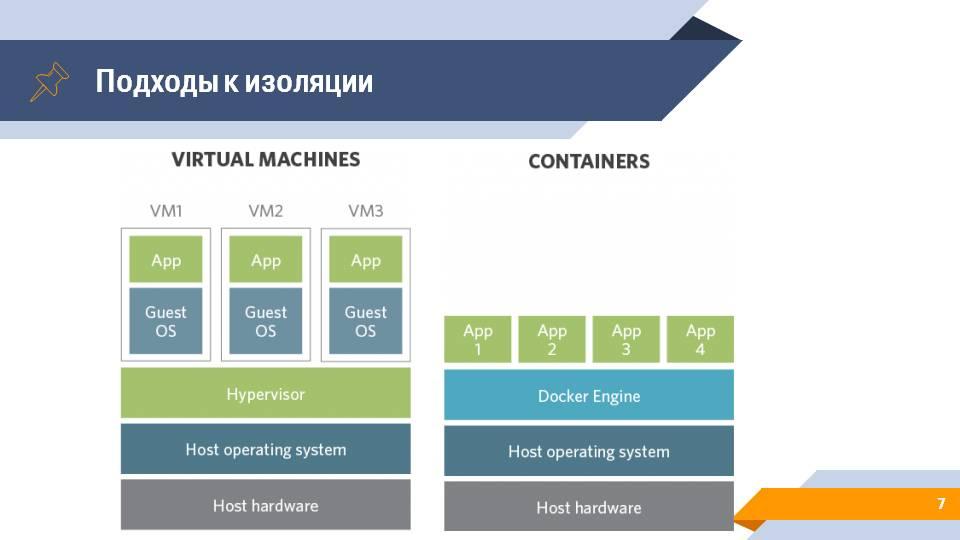
Что вообще такое Docker? Docker – это один из инструментов виртуализации.
Виртуализацию глобально можно разделить на два способа реализации.
-
Первый – это виртуальные машины. На самом нижнем уровне у вас есть какое-то железо, на этом железе стоит операционная система с гипервизором, который занимается тем, что запускает новые операционные системы, в которых уже выполняются ваши клиентские приложения.
-
Второй вариант – это контейнеризация. Мы убираем слой гипервизора и заменяем его на слой оркестратора контейнеров, работающих непосредственно поверх операционной системы. В качестве такого средства можно использовать движок Docker. И уже этот движок запускает отдельные изолированные экземпляры вашего приложения с необходимым окружением, необходимыми библиотеками, но без полноценного эмулирования операционной системы..
Docker Swarm. Реализация масштабирования
У Docker есть довольно простая встроенная возможность объединить несколько узлов, несколько ваших машин в так называемый Docker swarm cluster.
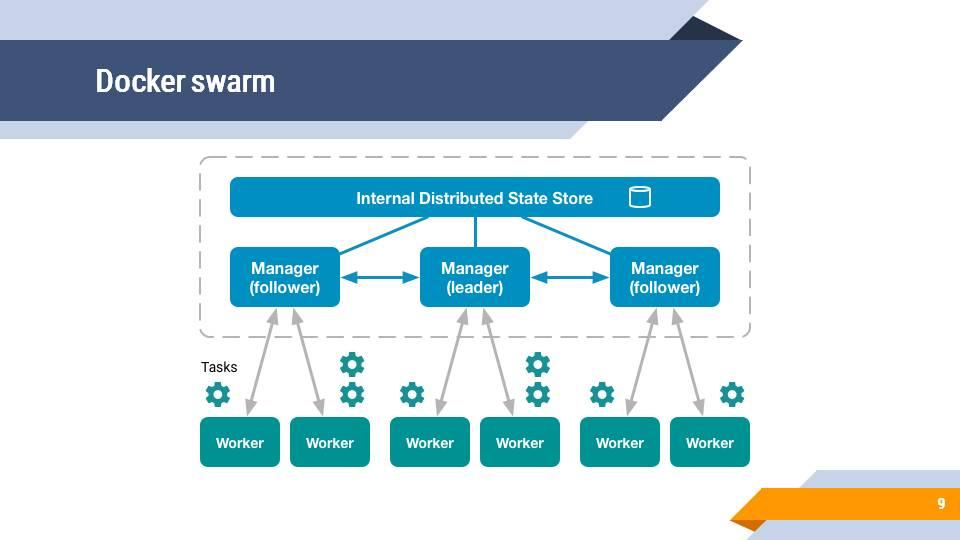
Принципиально это выглядит примерно так – пунктирными линиями обведена некая управляющая система, в которой есть хранилище данных и несколько менеджеров - управляющих улов.
Менеджеры соединены с воркерами, которые выполняют задачи – по сути, запускают контейнеры, в которых выполняются приложения, скрипты и т. д.
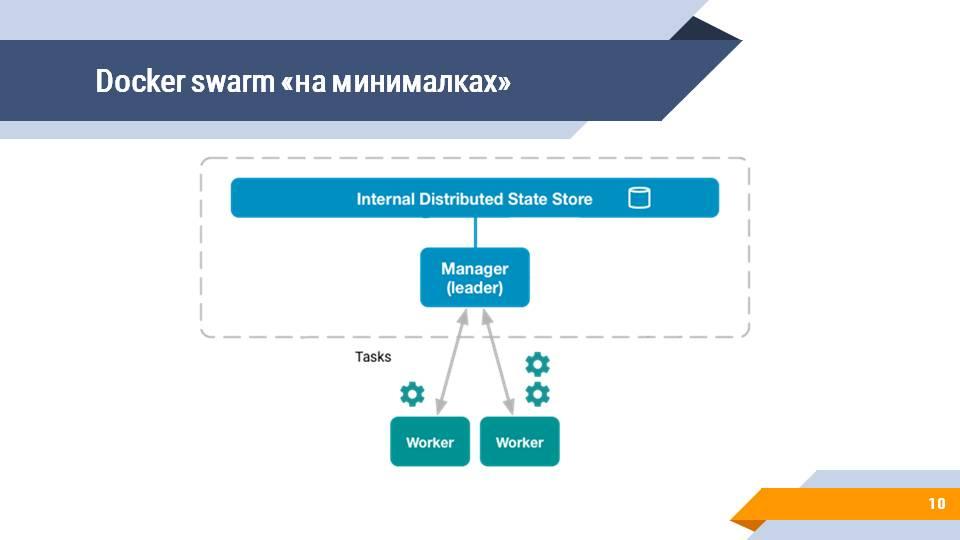
Но все мы знаем, что все системы первоначально запускаются на локальной машине (до того, как у вас есть сервера), поэтому в самом простом варианте Docker Swarm у вас есть один менеджер и один-два воркера. Зачастую и воркеров нет, и вы все задачи запускаете сразу на менеджере. Docker Swarm такой режим тоже поддерживает.

Создать docker machine и включить ее в docker swarm cluster несложно – это можно сделать с помощью доступной на GitHub утилиты docker-machine, которая позволяет буквально в два скрипта создать docker swarm cluster и подключить к нему новую машину.
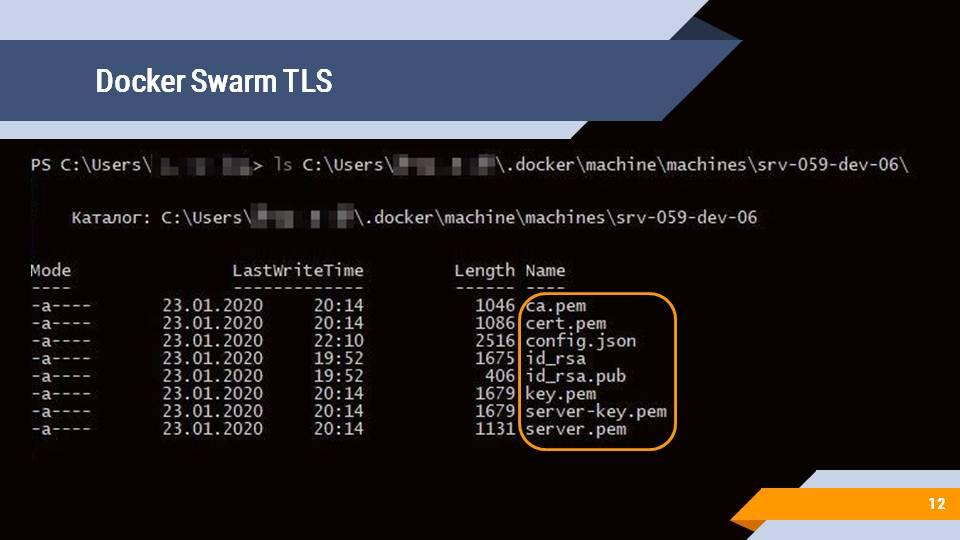
После создания docker machine вы также получите набор ключей и сертификатов, чтобы обеспечивать доступ и управление созданными docker machine с использованием TLS-аутентификации.
Те, кто пользуются Docker for windows, могли заметить в настройках системы галочку «Expose daemon on tcp://localhost:2375 without TLS» (публиковать службу на порту 2375 без TLS).
На реальных рабочих станциях или продакшен-контуре так делать категорически нельзя. Если вы будете использовать docker с этой галочкой, это значит, что абсолютно любой человек в локальной сети может постучаться на порт 2375 к вашей машине и запустить на ней абсолютно что угодно – например, запустить контейнер со смонтированным целиком корневым каталогом вашего диска, выполнить над файлами какие-то действия - скопировать их, зашифровать, удалить.
Система Cloud Provider. Агенты по запросу
Следующая технология, которая поможет нам в масштабировании – это система Cloud Provider.
Я думаю, вы слышали о Google Cloud, об Amazon Cloud – это некая система, в которую вы можете отправить запрос вида: «Дай мне виртуальную машину на два ядра и 4Гб оперативной памяти». Происходит некая магия, и через некоторое время вы получаете либо удаленный доступ к только что созданной виртуальной машине по SSH или RDP и можете начинать с ней работать.
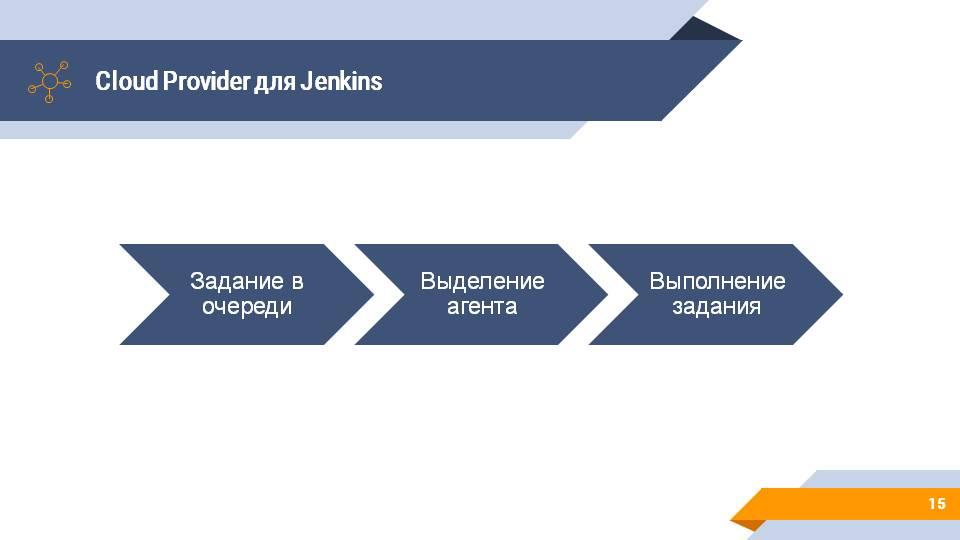
Этот же подход Cloud Provider можно применять на вашем сервере сборок. Например, на Jenkins. У него есть довольно много вариантов подключения различных провайдеров – будь то просто Amazon, Google, Kubernetes или просто docker.
Схема работы с облачным провайдером несколько меняется, но смысл остается тот же. Jenkins отслеживает ваши задания на сборку. Под эти задания выделяет вам build-агента и на этом build-агенте начинают выполняться задания.
Docker Swarm plugin.
Если мы объединим концепции Cloud Provider и Docker Swarm и попытаемся применить ее к Jenkins, то мы можем найти плагин под названием Docker Swarm.
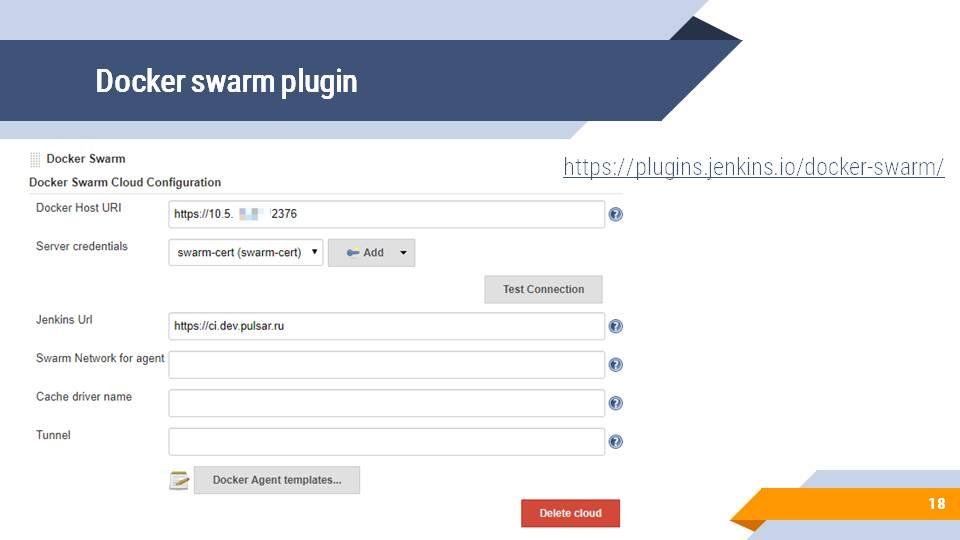
Его конфигурирование довольно простое – в настройках Jenkins появляется новая закладка, в которой вы указываете:
-
Docker Host URI – где у вас живет master вашего docker swarm cluster;
-
Server credentials – параметры подключения к нему.
И все, для подключения больше ничего не нужно.
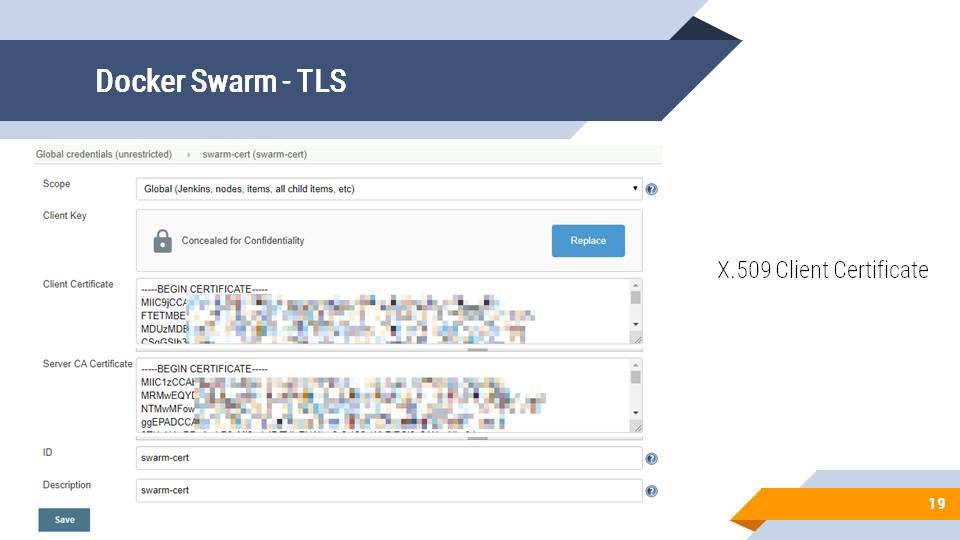
Параметры подключения – это TLS-ключи и сертификаты, которые требуются для поднятия защищенного соединения. Файлы, которые создались после инициализации docker machine, вы можете положить в сохраненные значения и секреты Jenkins и использовать для авторизации.

Следующий шаг настройки провайдера - это добавление так называемых docker templates - шаблонов для будущих build-агентов. Шаблон содержит информацию о docker-образе, на основе которого будет создан build-агент, команде инициализации, настройке рабочего каталога, пользователя, дополнительных переменных среды, конфигурация сетевых интерфейсов и много чего еще. Но для старта вам хватит настройки имени образа, команды инициализации и монтирования каталогов.
Что можно сделать, когда у вас есть такой Cloud Provider?
Для начала вы можете запустить базовый агент на основе образа eeacms/jenkins-slave-dind (Docker in Docker), в котором можно выполнить произвольные команды, запустить другие docker-контейнеры или собирать docker-образы, в том числе для 1С.
Самое главное – это указать правильные параметры запуска. Страшный скрипт, который нарисован в центре, генерируется автоматически, не нужно его запоминать. Его можно подсмотреть в справке, доступной по нажатию на кнопку с синим знаком вопроса справа от поля, и просто скопировать.
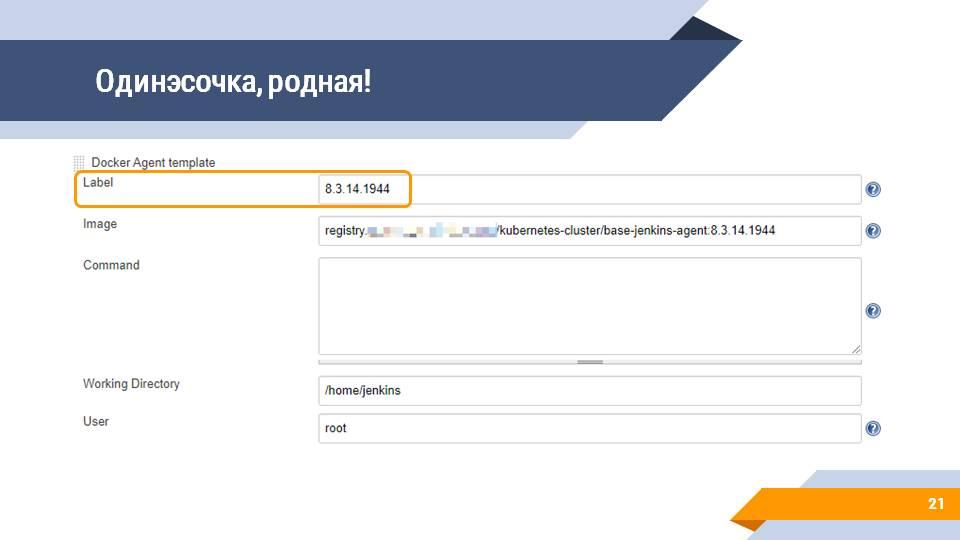
Конечно же, вы можете использовать Docker, чтобы запускать в нем тесты. Вы можете создать docker-образ с 1С нужной вам версии, указать, его в качестве build-агента в настройках облачного провайдера docker swarm, настроить метку агента (например, под версию платформы). И теперь ваши тесты будут запускаться в Docker, причем в агенте, который будет подниматься только на тот промежуток времени, когда он вам нужен.
Сборочная линия Jenkinsfile в Docker для 1С
Как может выглядеть сборочная линия для 1С, которая запускается в Docker?

Она будет выглядеть примерно так же, как и любая другая сборочная линия, только вам нужно перед этим решить три вопроса.
-
Вам нужно разобраться с тем, какие данные нужно передавать между различными шагами вашей сборки. Если вы работали с постоянным build-агентом, вы могли привыкнуть к тому, что если вы обратитесь по пути C:\jenkins\artifacts\somedata\file – то вы этот файл оттуда достанете. В случае Docker у вас такой возможности не будет, потому что у вас маленький изолированный контейнер, который ничего не знает про окружение, на котором он запустился, и про то, куда он может достучаться. Эту проблему нам могут помочь решить различные шаги архивации для передачи артефактов между шагами и между сборками.
-
Второй момент – это работа с внешними ресурсами. Docker обычно запускается в Linux-окружении на Linux-ядре, и в Linux есть определенные особенности по настройке сетевых путей. Если вы работаете с Windows, вы открываете проводник, пишете //ИмяКомпьютера/СетеваяПапка и она у вас сразу открывается. Если у вас есть доменная авторизация, вам даже никакой логин/пароль вводить не нужно. А в случае Docker вам нужно лезть в файлы с конфигурацией сетевых устройств, либо в файлы с конфигурацией автомонтирования и там прописывать пути, куда нужно стучаться, и куда это нужно монтировать, и параметры авторизации, и т.д. Одним из простых способов решения этой проблемы являтеся установка перед вашими статичными внешними ресурсами (внешними файлами, которые вам нужно вытащить) простенького HTTP-сервера (например, Nginx или Apache, если вы умеете его конфигурировать, или даже IIS), который и будет отдавать эти старичные данные по HTTP.
-
И третье – это, конечно же, нужно написать Dockerfile для 1С.
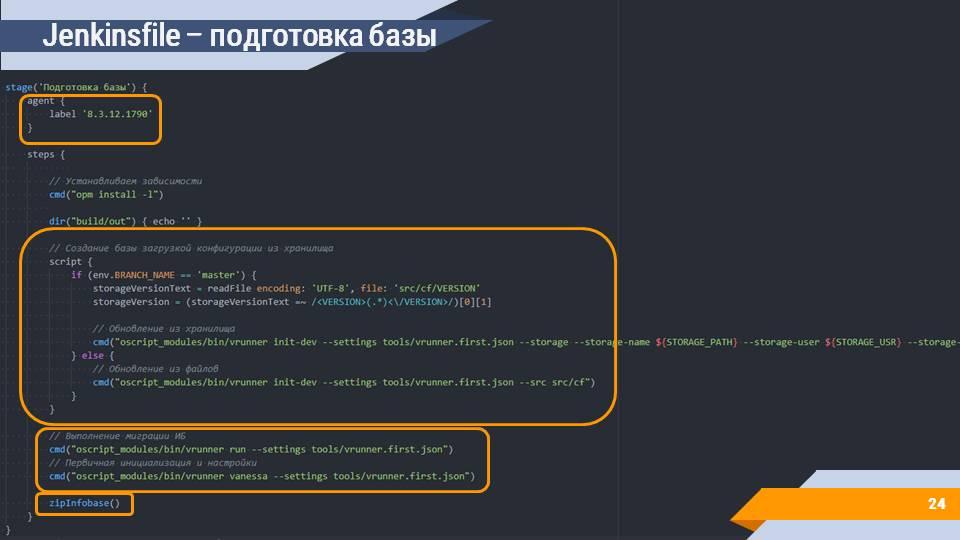
Сама сборочная линия выглядит довольно привычно для тех, кто хоть раз ее писал для 1С.
-
Мы говорим о том, что наша сборка выполняется на каком-то определенном агенте. В данном случае используется метка с версией платформы. Такую метку мы задали для нашего build-агента с docker-образом 1С.
-
Выполняются типичные шаги по подготовке базы к запуску тестов. Это инициализация базы загрузкой конфигурации из хранилища и запуск первичных шагов по ее инициализации - первоначальный запуск, ожидание окончания миграции, подавление окна с проверкой на лицензионность, какие-то дополнительные действия, специфичные для вашей базы.
-
И самое главное - после того как мы подготовили информационную базу, ее нужно заархивировать, чтобы передать дальше по шагам.
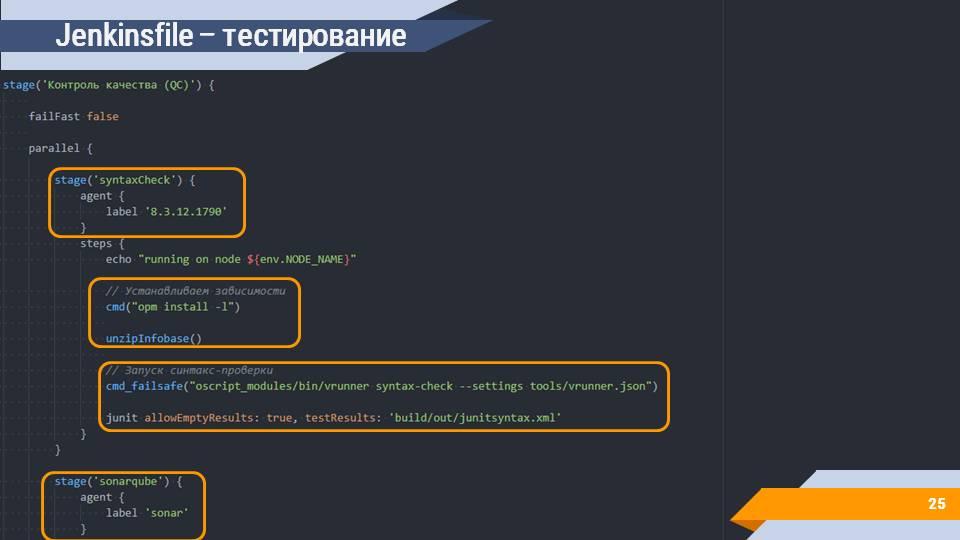
На следующем шаге в этом примере организуется контроль качества.
Преимущество агентов, поднимающихся по запросу – это то, что вы можете параллельно запускать несколько шагов или даже разных сборок. В примере выше параллельно запускается несколько шагов:
-
на шаге «syntaxCheck» мы эту информационную базу разархивируем – кладем в определенный каталог и выполняем дальнейшие операции – например, запуск синтаксического контроля, который делает конфигуратор, но с выводом информации в формате JUnit, чтобы красиво отображать ее в Jenkins.
-
здесь же может быть шаг sonar, при желании - с передачей результатов из “1С:Автоматизированная проверка конфигурации”;
-
вы можете сразу запустить сценарные тесты;
-
вы можете запустить любое количество других шагов, начиная от модульных тестов, заканчивая любой автоматизированной операцией над вашим решением.
Все это можно делать параллельно, и все это не будет мешать друг другу, даже если будет запускаться физически на одной машине. Конечно же при условии наличия свободных ресурсов.
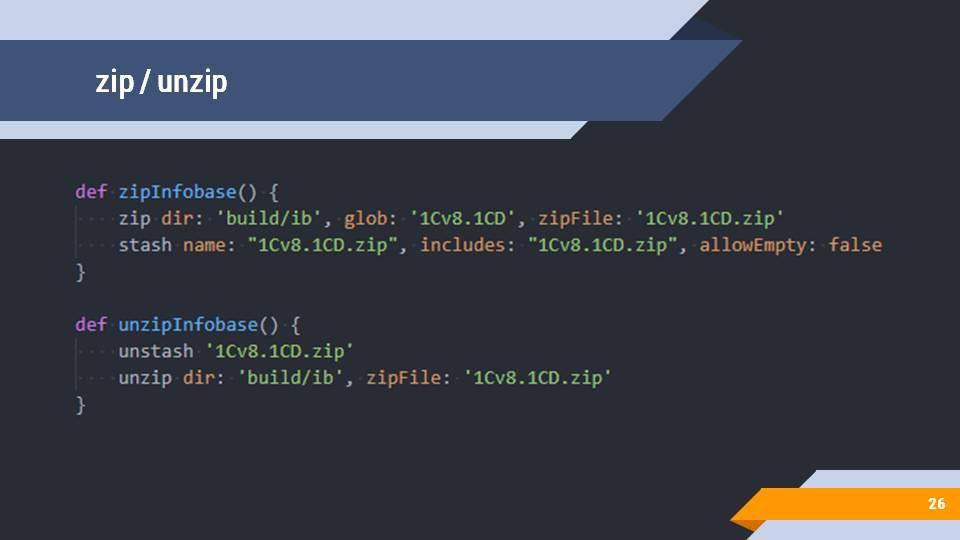
Сами задачи по архивированию и разархивированию – это тоже штатная функциональность Jenkins, просто упакованная в функции-обертки без лишних параметров. Это архивация каталога, где лежит информационная база, и помещение его в stash – специальное хранилище, которое можно использовать для передачи данных между шагами.
Разархивация – это получение файла из stash и его распаковка в папку с информационной базой.
Проблемы самостоятельного создания Dockerfile для 1С

С Dockerfile несколько сложнее. Есть несколько проблем, к которым нужно быть готовым, когда вы начинаете решать задачи построения Docker-образа для 1С.
-
Один из главных навыков – это умение гуглить ошибки. Когда вы начинаете работать с новым языком, вы начинаете сталкиваться с новыми неизвестными для вас ошибками. Эти ошибки могут быть по-разному отформатированы, в них может присутствовать дерево вызовов, служебная информация. В случае 1С вы привыкли к внешнему виду ошибок и беглым взглядом на сообщение сразу можете понять, где эту ошибку искать, вы в целом знаете методики и подходы к расследованию ошибок. В незнакомых языках и приложениях каждая новая ошибка - это вызов и проверка вашего навыка вычленения информации и поиска решения в интернете. Когда вы будете собирать образы для Docker или писать собственные Dockerfile, то у вас тоже будут различные ошибки – от команд Linux, от различных установщиков пакетов, от самого Docker. И вам нужно понимать, что из выводимой информации является текстом ошибки и понимать, как сформулировать запрос Google, чтобы получить решение этой проблемы.
-
Так как Docker – это в первую очередь система, которая применяется на Linix-машинах, вам нужны какие-то базовые знания Linux. Вам не нужно знать детально о том, как работает ядро, как собираются модули, детально разбираться в процессах сбора библиотек из исходников. Вам нужно понимание базовых команд, переходы между каталогами, копирование файлов, перемещение, переименование, запуск приложений и т.д.
-
И третье – это зависимости. В случае 1С, зависимости – это очень сложная штука, потому что, даже несмотря на то, что 1С имеет пакетный режим запуска, чтобы она запустилось в Linux, на машине должно быть установлено очень много дополнительных библиотек. Про это попозже чуть подробнее поговорим.
Готовый Dockerfile для 1С

К счастью, проблемой помещения 1С в Docker занимается довольно много людей. В частности, этой проблемой начала заниматься наша компания. Мы развиваем проект на GitHub под названием onec-docker от пользователя jugatsu.
Мы взяли его разработку за основу и развили ее в своем форке https://github.com/firstBitSemenovskaya/onec-docker. Часть доработок переносится в апстрим, к jugatsu, часть остается в форке, но главное, что все доработки доступны и открыты.
Если вы зайдете на страницу репозитория на GitHub и переключитесь на ветку feature/first-bit, то вы увидите скомбинированный результат работы jugatsu и нас по тому, как завернуть 1С в docker и как подключить ее к Jenkins.
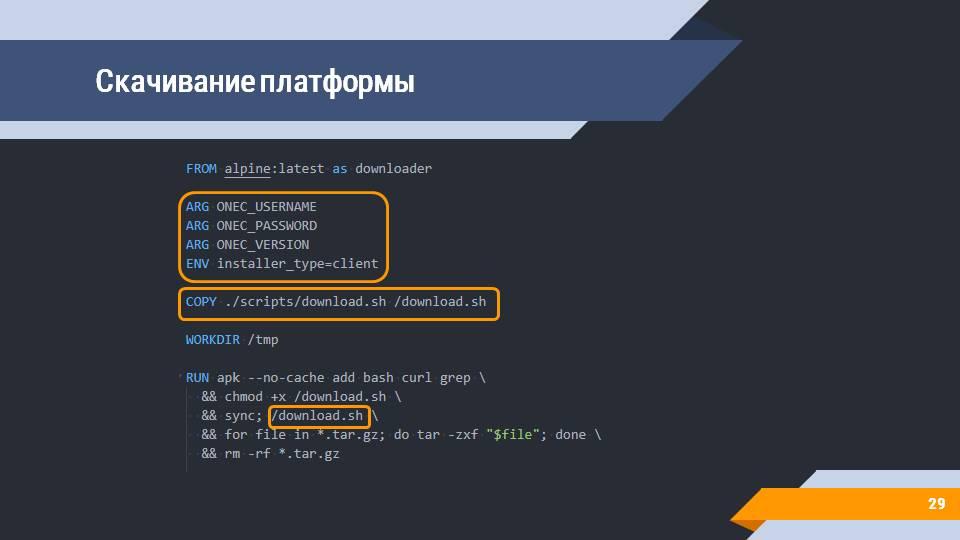
Что же внутри?
Любая работа с платформой начинается с вопроса: откуда взять дистрибутив? Есть несколько подходов к этому – вы можете положить дистрибутив в локальный каталог, а потом его копировать, либо же вы можете (кодом) зайти на сайт releases.1c.ru и оттуда скачать релиз (естественно, у вас должны быть параметры авторизации и понимание того, какой тип клиента вы хотите установить).
В репозитории есть скрипт, который по переданным аргументам скачает в ожидаемую папку все дистрибутивы платформы – на слайде показан вариант скачивания платформы для debian-систем.

Следующий шаг – установка зависимостей и 1С. В этих образах автоматически ставятся все зависимости, описанные на ИТС, а также дополнительные зависимости, обнаруженные jugatsu и нами.
Вам всего лишь нужно будет выполнить команды по сборке этого образа и по установке клиента 1С – на слайде показано, как стандартным дебиановским приложением dpkg устанавливается сервер, клиент и общие зависимости.
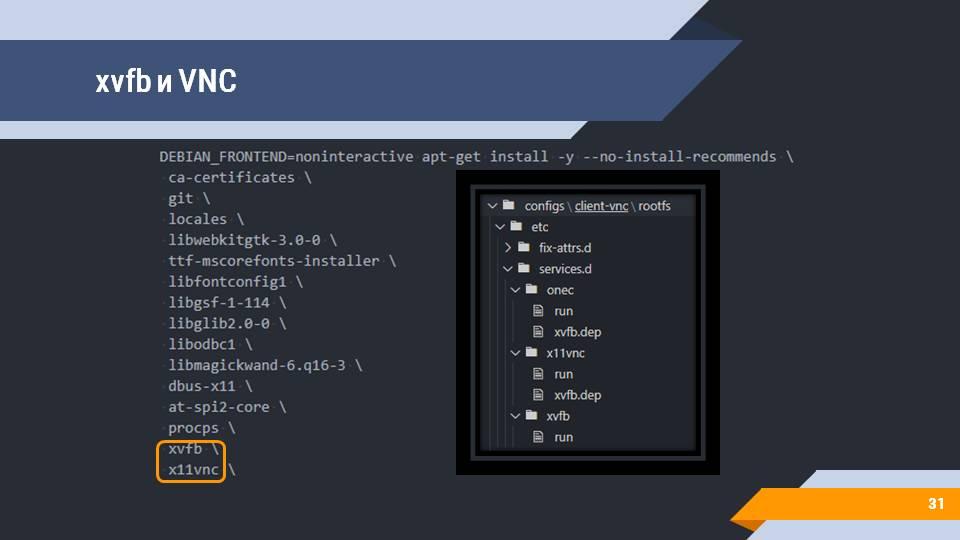
1С – штука сложная, и помимо тех зависимостей и странных библиотек, которые нужны для работы, ей еще нужно графическое окружение. То есть, даже несмотря на то, что чаще всего вы хотите просто запустить конфигуратор и выгрузить, например, конфигурацию в файлы, или выгрузить саму информационную базу в виде dt-ника, 1С все равно нужно поднятое графическое окружение.
Эта задача здесь также решена через xvfb (X virtual framebuffer) и окружение xfce4. Вы можете подключиться к контейнеру через любой vnc-клиент и посмотреть, что же конкретно происходит в моменты прохождения тестов.
Все конфигурационные файлы по подключению подсистемы для графического интерфейса лежат в репозитории и вам ничего дополнительно конфигурировать не нужно.
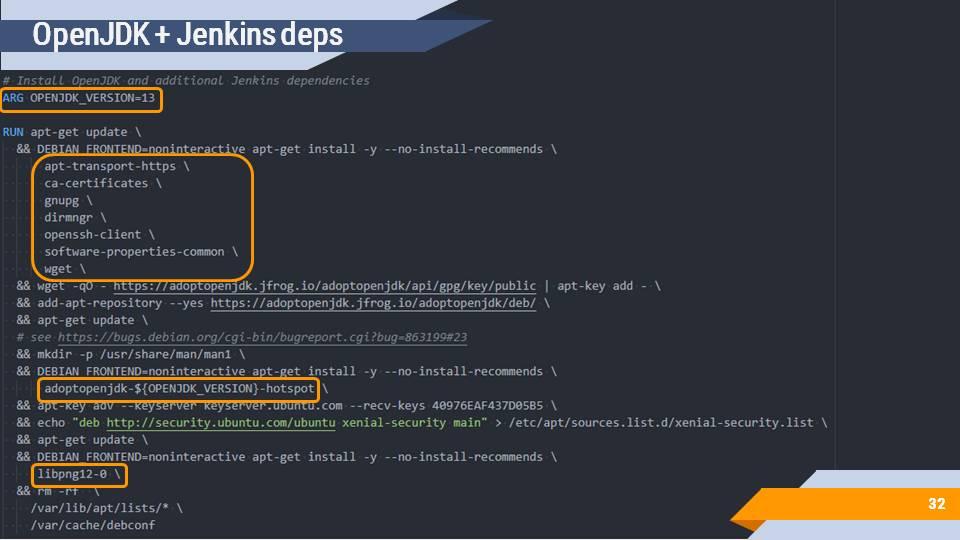
Так как мы пытаемся запустить нашу 1С-ку на Jenkins, нам нужно к этому Jenkins как-то присоединиться. А поскольку агент Jenkins – это приложение, написанное на Java, поэтому для работы вашего агента в docker-контейнере должна быть установлена Java.
Эта задача здесь тоже решена:
-
скачивается Java 13-й версии (дистрибутив от AdoptOpenJDK), хотя в принципе достаточно и 8-й версии, но 8-я потихоньку устаревает, поэтому идем вперед;
-
устанавливаются дополнительные зависимости для Java;
-
и ставится сама Java.
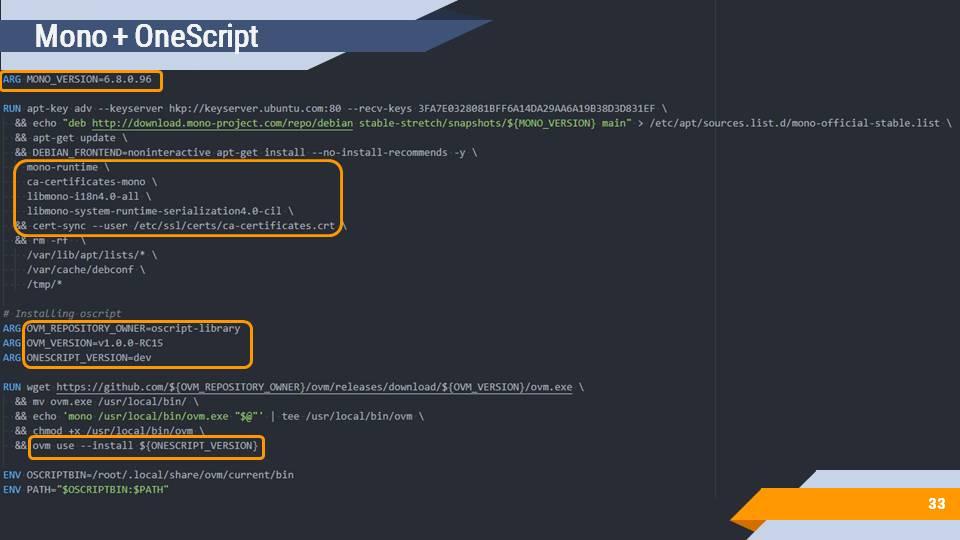
Следующий шаг – это Mono (среды исполнения, необходимой для работы OneScript) и дополнительных зависимостей.
После этого скачивается менеджер версий ovm, который устанавливает сам OneScript.
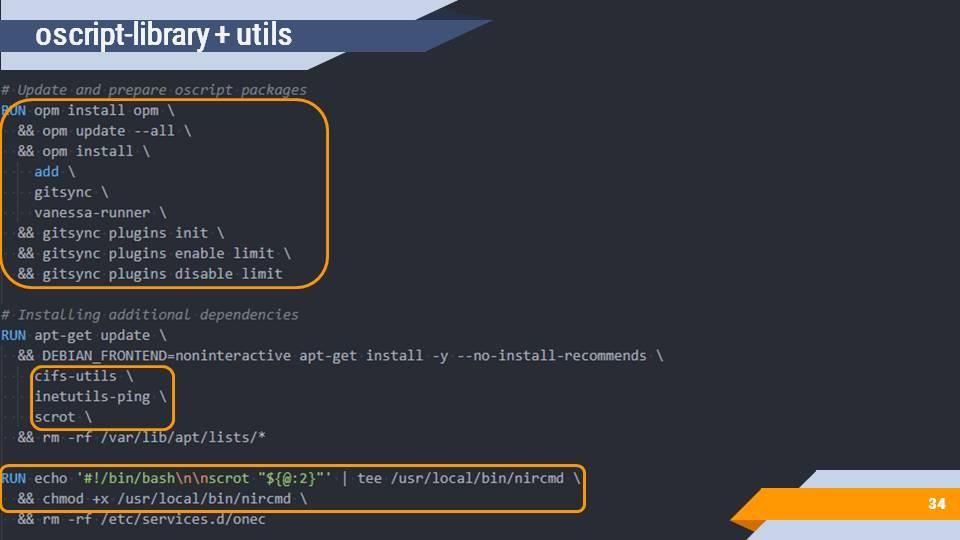
И заключительным шагом ставятся библиотеки для OneScript – это gitsync, vanessa-runner, add – то, что обычно используется для сборки и тестирования на Jenkins.
После выполнения всех этих шагов у вас получается образ, в котором есть:
-
графическое окружение;
-
платформа 1С:Предприятие;
-
Java и настройки для подключения к Jenkins;
-
OneScript, позволяющий запускать тесты, gitsync и т.д.
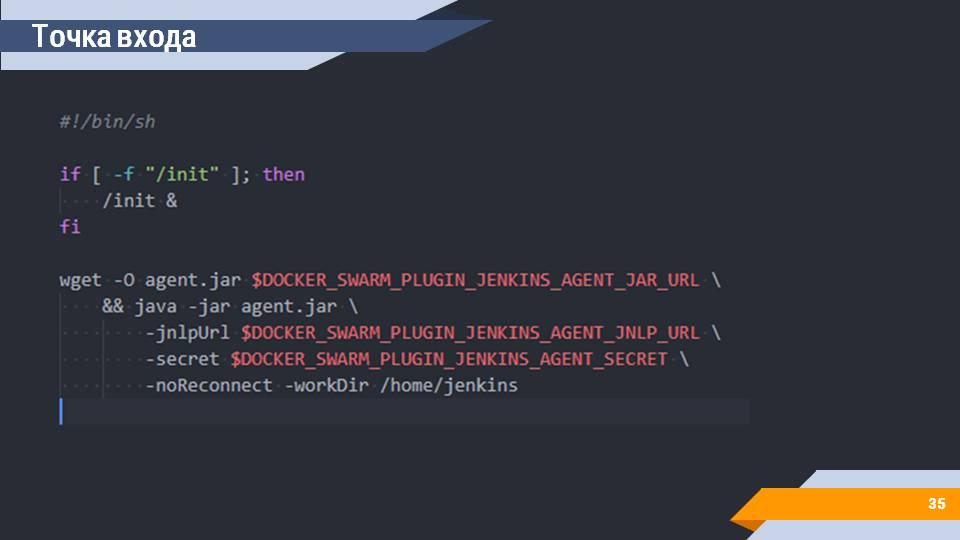
В любом Dockerfile есть такое понятие, как «Точка входа». Это тот скрипт, который будет исполняться, когда вы запускаете docker-контейнер.
В случае этого образа точкой входа является инициализация графической подсистемы и подключение к Jenkins. Автоматически скачивается файл для подключения в качестве агента. Конфигурируется. Все переменные среды автоматически передаются самим сервером Jenkins при запуске контейнера. И вам ничего дополнительно настраивать не нужно.
Сборка и хранение Docker-образа
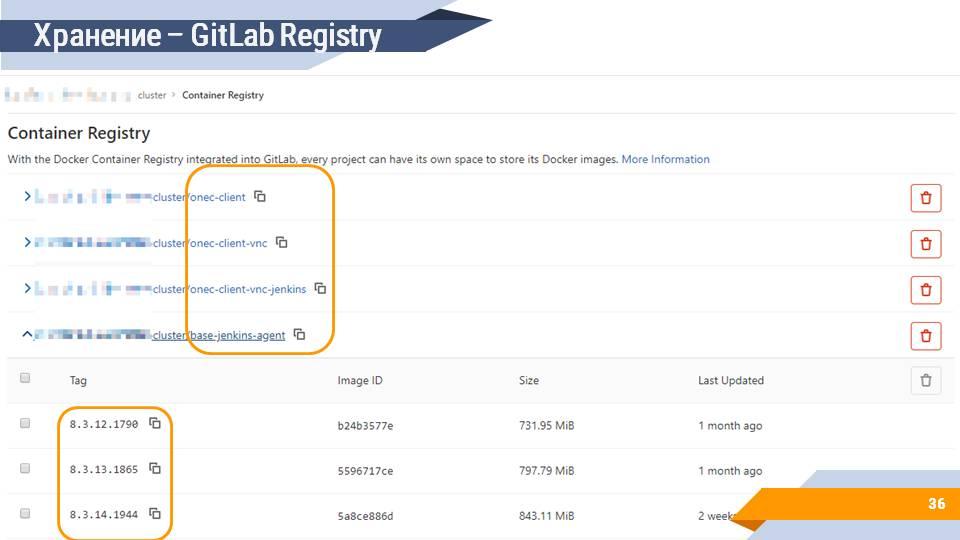
Собранные образы нужно где-то хранить. Вы, конечно, можете использовать бесплатное хранилище hub.docker.com, но нужно помнить, что вы не имеете права распространять дистрибутивы платформы, соответственно, вам нужно будет эти образы делать приватными и закрывать логином/паролем. При этом у hub.docker.com есть лимит на количество приватных образов. Если же вы пользуетесь, например, GitLab, то у GitLab есть собственное хранилище Docker-образов, в котором вы можете разместить все ваши собранные образы и иметь историю по версиям и по сборкам.
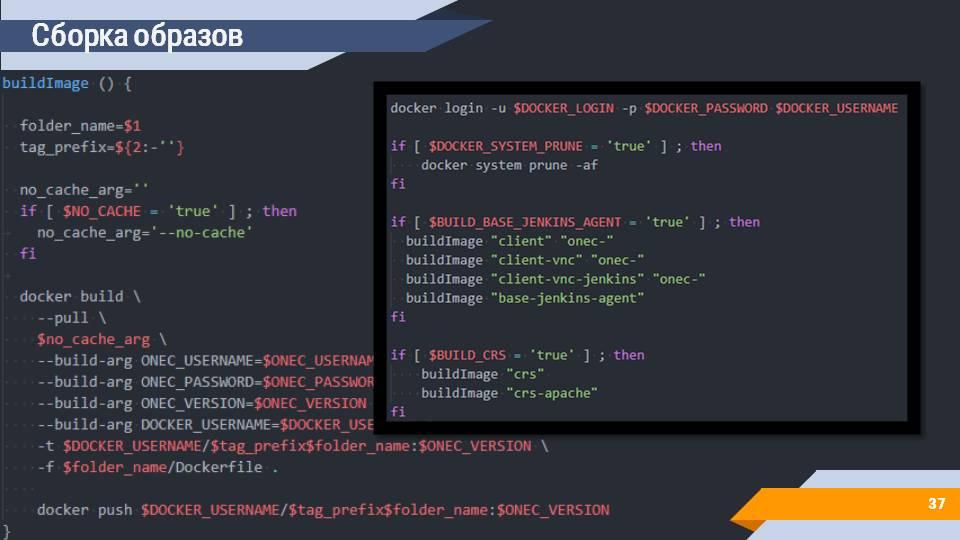
Сборку образов вы можете реализовать с помощью скриптов. Данный скрипт, например, делает docker build, передает все нужные аргументы командной строке и на выходе отправляет собранный docker-образ в ваше хранилище образов.
На слайде выделена вторая часть скрипта, которая позволяет собрать в этом репозитории все слои, которые нужны для 1С, а также слои, которые используются для хранилища и Apache.
Последовательность и возможные способы комбинации слоев вы можете подсмотреть в файле Layers.md в корне репозитория.
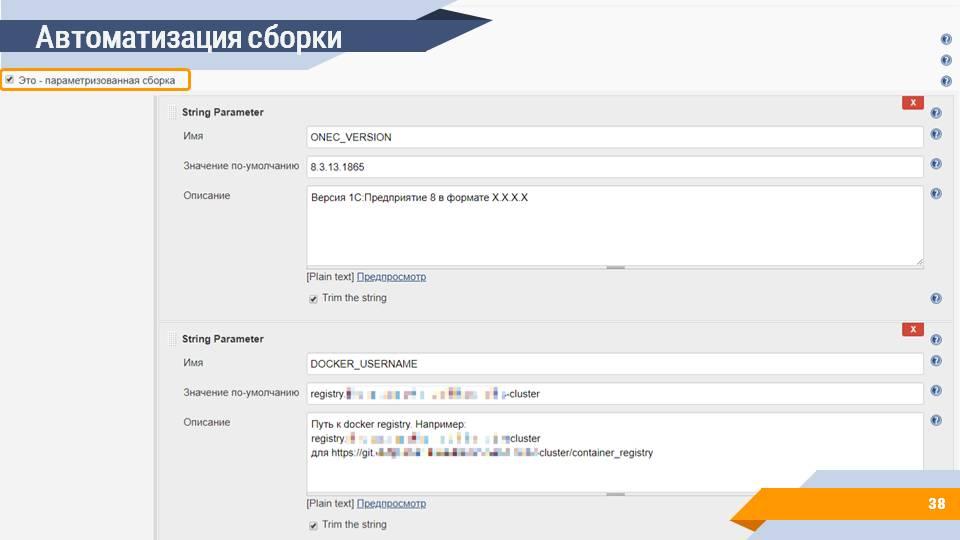
Естественно, эту сборку можно автоматизировать. На сервере сборок можно создать отдельную задачу, которая и будет заниматься сборкой нужных образов.
В Jenkins есть такое понятие, как параметризируемая сборка – сборка, которой на вход помимо самого скрипта передаются дополнительные параметры, которые пользователь может указать в пользовательском интерфейсе. Например:
-
версия платформы 1С:Предприятие, которую вы собираете;
-
параметры авторизации;
-
путь к docker registry – информация о том, куда этот образ нужно отправлять;
-
дополнительные флаги сборки
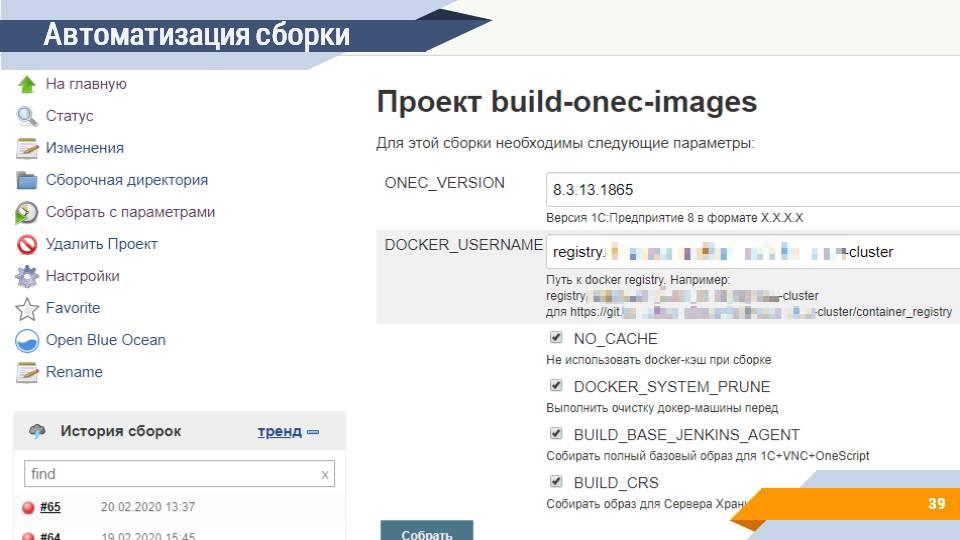
И на выходе вы по одной кнопке можете, устанавливая и снимая те или иные галочки, и задавая параметры, автоматически примерно за 45 минут (среднее время сборки на нашем сервере) получить готовый Docker-образ. Аналогичным образом можно собрать образы с EDT на борту для запуска расширенной валидации или сбора покрытия.
Схема работы
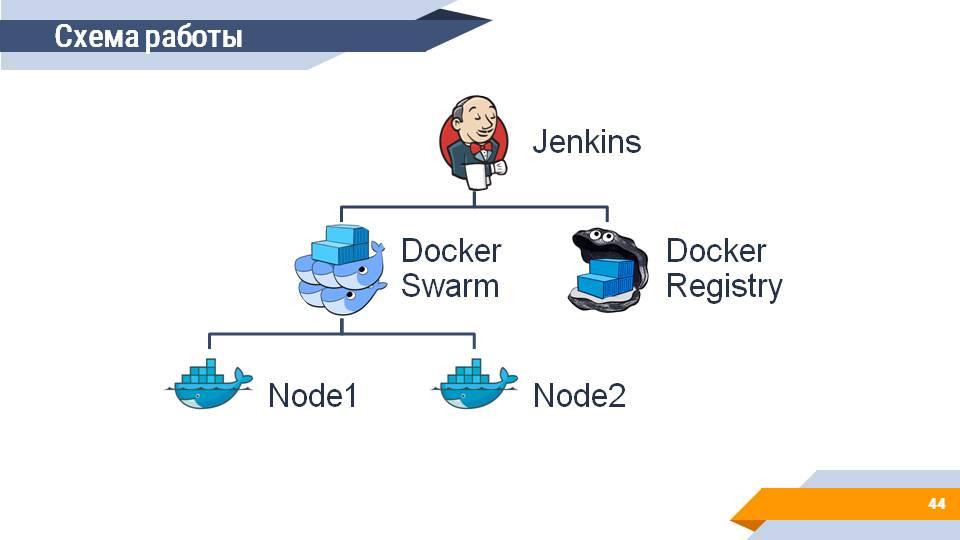
Каким же образом будет выглядеть ваша система, если у вас получится все это запустить?
Во главе системы располагается сервер сборок (Jenkins), который:
-
собирает и получает информацию о собранных 1С-ных образах из Docker Registry;
-
запускает на подключенном Docker Swarm кластере агенты для сборочной линии, на которых выполняются ваши тесты.
Что вы в этом случае получите? Довольно простой механизм масштабирования. Неважно, появилась ли у вас новая рабочая станция или полноценный сервер - буквально одной командой в терминале вы добавляете машину в Docker Swarm Cluster и она сразу же становится доступной для запуска сборок.
Бонус. Оркестрация серверами хранилищ
И в качестве бонуса – я бы еще хотел сказать про сервер хранилищ.
Проблема с доступом к сетевым ресурсам по UNC-путям чаще всего первым делом стреляет на хранилищах. Мы привыкли к тому, что хранилище – это файловая шара, которая под windows подключается без каких-либо проблем, вы просто указываете в конфигураторе каталог размещения //ИмяСервера/СетеваяПапка и все работает.
В случае Linux и Docker вы такую штуку сделать не сможете, потому что вам этот каталог, опять-таки, нужно сначала смонтировать.
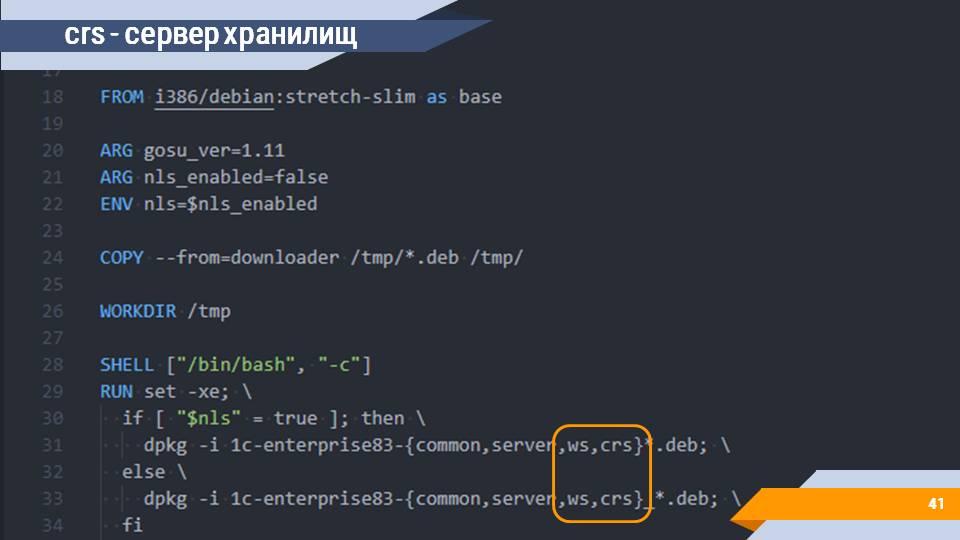
Решением этой проблемы является поднятие где-то у вас в контуре сервера хранилища с доступом по HTTP.
И эту задачу вы тоже можете решить с помощью Docker, собрав соответствующий Docker-контейнер (образ crs – сервер хранилищ).
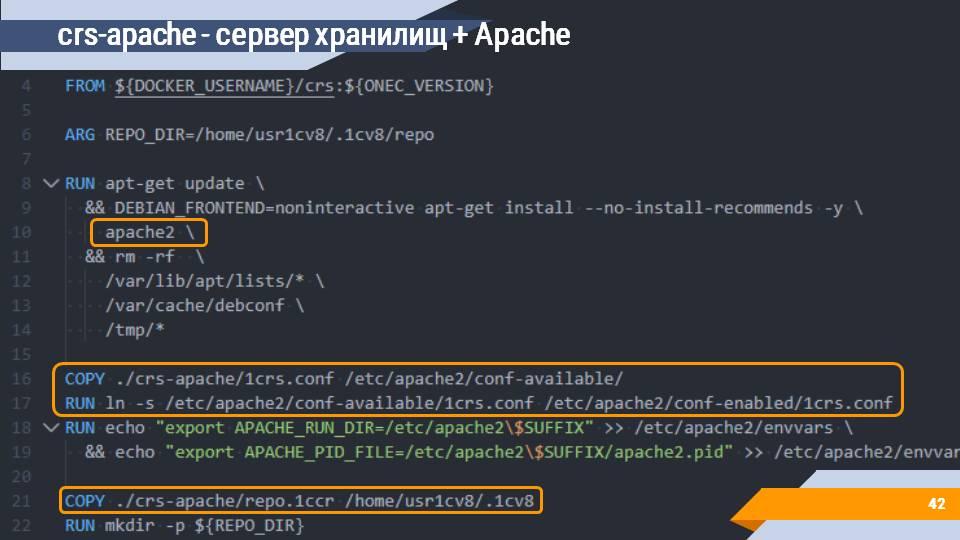
Поверх сервера хранилища устанавливается Apache с настройкой всех нужных конфигурационные файлов и публикации (образ crs-apache).

У ваших клиентов могут использоваться разные версии 1С, а при использовании сервера хранилищ разработчики ограничены в возможности подключения - должна использоваться строго та версия платформы, что и на сервере хранилищ. Чем больше таких клиентов и разных версий 1С, тем больше будет серверов хранилищ. И этим тоже нужно как-то управлять и желательно давать простую точку подключения для разработчиков.
-
Один из простых вариантов - настройка перед серверами хранилищ веб-сервера Nginx, выступающего простым маршрутизатором трафика - запрос по такому-то адресу нужно отправлять на такой-то сервер хранилищ.
-
Вариант посложнее - завернуть все это дело в Kubernetes. В Docker же уже завернули.
Мы сейчас работаем над тем, чтобы представить довольно красиво и просто конфигурируемое решение на базе helm chart, которое позволит каждое ваше хранилище развернуть внутри Kubernetes с помощью одного скрипта, автоматически конфигурирующего все, что нужно. Конечная цель – это получить что-то вроде crs.mycompany.com/ИмяГруппы/ИмяПроекта.
На этом у меня все, спасибо за внимание.
Вопросы:
-
Сколько у тебя месяцев ушло на то, чтобы все это осознать и освоить?
-
Почти весь последний год (мы начали в феврале 2019 года) мы занимаемся переносом в Kubernetes наших внутренних сервисов. Сейчас у нас там работает несколько систем – GitLab, SonarQube, Redmine, Jenkins. После того как мы подняли там инфраструктуру управления проектами и общую инфраструктуру разработчика, следующим шагом стала задача масштабирования тестов (тестовых контуров и запусков). Конкретно этой задачей мы занимаемся с конца декабря 2019. И этот доклад – это, по сути, компиляция тех доработок репозитория jugatsu, которые пришлось сделать, чтобы запустить это в Jenkins (с декабря 2019 по март 2020).
-
Почему Docker Swarm, раз у вас есть Kubernetes?
-
Docker Swarm и его плагин для Jenkins оказался очень удобной отправной точкой в условиях ограниченных серверных ресурсов. К Jenkins (а точнее к Docker Swarm Cluster) подключено несколько обычных машин разработчиков, и важным ограничением стал вопрос простоты и скорости настройки новой машины. Подключить рабочую станцию к сворму оказалось намного проще и быстрее, чем разворачивать на ней полноценный узел Kubernetes. Возможно в будущем мы откажемся от использоваться Docker Swarm и переведем 1сные сборки в Kubernetes, но пока нас устраивает текущее решение.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Kazan.

Вступайте в нашу телеграмм-группу Инфостарт