
Технологический журнал – это самый главный лог, который позволяет нам узнавать, что происходит вообще с системой на базе 1С.
В целом, можно сказать, что технологический журнал – это настраиваемый событийный лог работы процессов платформы 1С.
Каждый процесс кластера серверов, тонкий, толстый и веб-клиенты могут выводить информацию о своей работе в файл лога технологического журнала.

Важно понимать основные принципы «приготовления» технологического журнала:
-
технологический журнал – настраивается, платформа просто так его не пишет;
-
технологический журнал – это событийный лог, каждая его запись – это какое-то событие;
-
события технологического журнала связаны между собой.
Технологический журнал дает много пищи для размышлений 1С-никам, а пища, как известно, должна быть сбалансированной и полезной. Именно поэтому я сегодня хочу рассказать о рецептах приготовления технологического журнала, чтобы мы его не боялись и активно использовали в своей работе.
Настройка ТЖ

Чтобы начать «готовить» технологический журнал, нужно понимать, что его настройки и перечень выводимых событий задаются в xml-файле logcfg. Этот файл имеет определенную структуру и порядок. Файл logcfg.xml может быть размещен в нескольких каталогах:
-
Если разместить файл настроек logcfg.xml в каталоге C:\Program Files\1cv8\conf, где расположена платформа 1С – тогда эта настройка будет действовать для всех платформ.
-
Если у вас установлено несколько версий платформы, вы можете включить технологический журнал для отдельной платформы, разместив файл настроек в каталоге, C:\Program Files\1cv8\Х.Х.Х.Х\bin\conf – тогда настройки будут применяться для определенной версии платформы.
-
Возникают случаи, когда нужно получать технологический журнал работы конкретного пользователя операционной системы. В этом случае файл настроек технологического журнала размещается в каталоге C:\Users\username\AppData\Local\1C\1cv8\conf – тогда настройки будут применяться для определенного пользователя платформы. Это очень полезно, когда нужно расследовать какие-то проблемы при работе определенного пользователя – особенно для приложений, работающих в режиме толстого клиента, когда у нас на сервере не остается контекст события и приходится обращаться к клиентскому технологическому журналу где и выводится контекст.
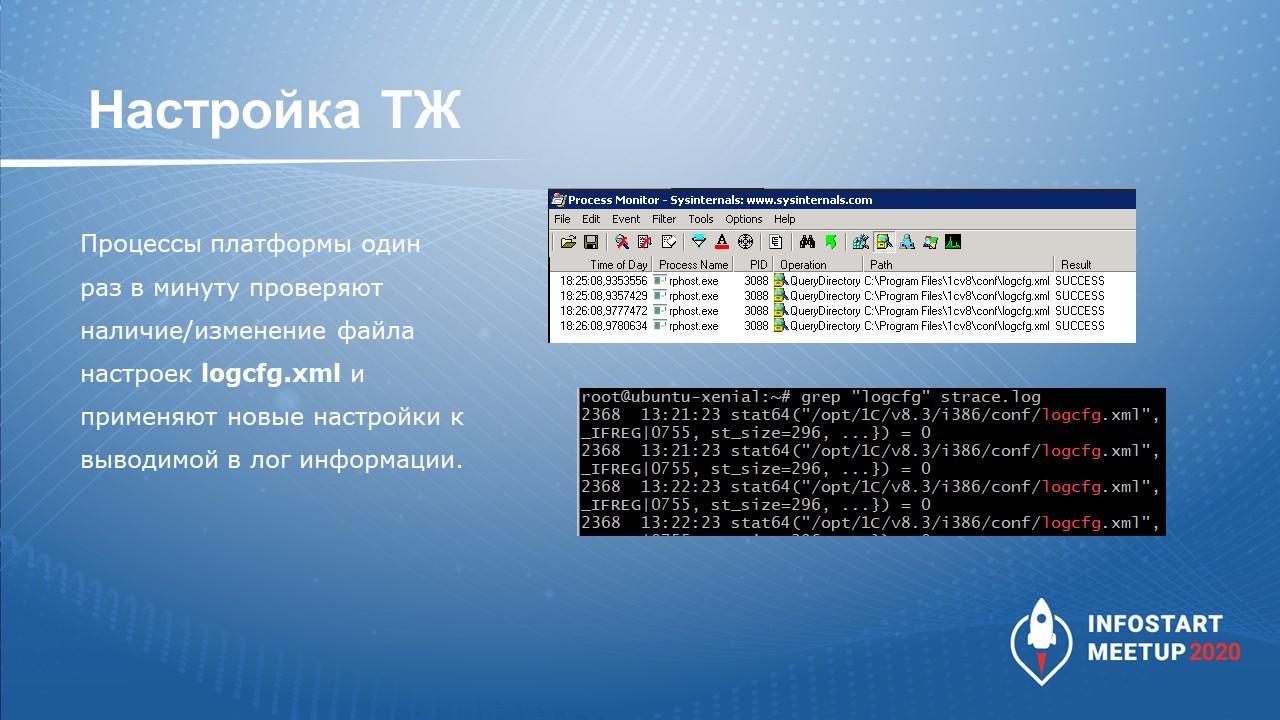
Как только мы разместили файл настроек logcfg.xml в определенных каталогах, процессы платформы 1С раз в минуту проверяют его наличие/изменение, и при нахождении этого файла, согласно его настройкам, запускается процесс вывода специфической и нужной нам информации в логи.
Это позволяет нам быстро включать или отключать технологический журнал, а также прямо на ходу менять его настройки. Это очень полезно, этим нужно пользоваться.
Важная особенность – чтобы процессы платформы 1С могли выполнять запись в каталог с файлами технологического журнала, нужно обеспечить им необходимые права доступа.

Файл настроек logcfg.xml имеет определенную структуру, которая задается через xml-представление. С помощью этой структуры можно строить хитрые логические условия.
-
Например, узлы <event> объединяются между собой через ИЛИ/OR.
-
А вложенные условия узла <event> (например, узлы eq – equal, ne – not equal и другие) объединяются между собой через И/AND.
Это позволит сгруппировать нужные нам условия и получить нужный результат.
В исследовательских задачах можно настраивать сбор всех событий. Однако нужно помнить, что подобная настройка не допустима на рабочих серверах, так как приводит к значительной нагрузке на систему!

При работе с логами технологического журнала есть небольшая проблема – часть информации о записи события хранится не в самих файлах логов, а в названии файла лога технологического журнала и названии его родительского каталога.
На слайде показано, как хранятся файлы логов технологического журнала в каталоге:
-
Мы видим, что родительский каталог файла лога называется rphost_2362 – это значит, что наименование родительского каталога содержит имя процесса, который пишет технологический журнал, и его PID.
-
Имя файла лога формируется по шаблону – [Год][Месяц][День][Час] и внутри файла год, месяц, день и час не указываются. Скорее всего, разработчики решили сэкономить место в технологическом журнале, потому что эта информация дублировалась бы везде, в любой записи технологического журнала.
-
Технологический журнал формирует файлы ежечасно – каждый файл технологического журнала содержит события за один час. Журнал можно настроить так, чтобы он не хранился долго – даже при сборе подробного лога. Платформа сама удаляет устаревшие технологические журналы. Если мы хотим их дальше сохранять, то здесь, конечно же, нужно настраивать механизмы для бэкапа.

Запись события в технологическом журнале обладает следующей структурой:
-
Каждая запись в технологическом журнале начинается с временной отметки события – timestamp, которая формируется по шаблону [Минута]:[Секунда].[Микросекунда] Напоминаю, что год, день и час хранятся в имени файла – такое разделение временной отметки (часть в имени файла, часть в записи события) усложняет работу с ТЖ.
-
Далее, после дефиса, следует длительность события – она также идет в микросекундах.
-
Далее идет имя события.
-
Далее идет уровень этого события в стеке выполнения.
-
Далее перечисляются свойства события через стандартный шаблон – [ИмяСвойства]=[значение]. Количество свойств для разных событий разное, их может быть неограниченное количество.
Для обработки многострочных записей лога, в качестве разделителя записей нужно использовать timestamp.
События ТЖ и взаимосвязь процессов платформы
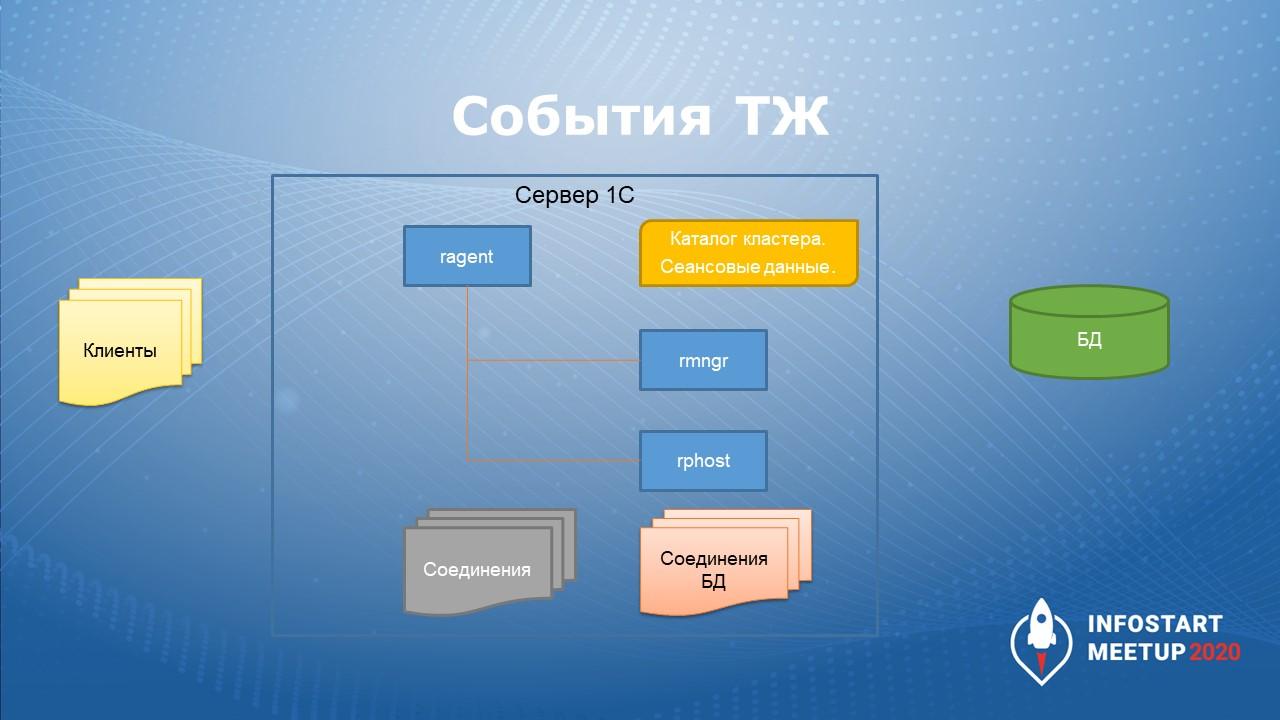
Чтобы перейти дальше к пониманию событий технологического журнала, нужно разобраться, как работает платформа 1С. На слайде схематично изображены компоненты платформы:
-
С одной стороны – клиенты;
-
Посередине – сервер 1С;
-
И за ним – сервер СУБД.
-
Есть пул соединений для доступа сеансов к кластеру серверов.
-
Есть пул соединений с базой данных.
-
Есть каталог кластера, в котором хранятся сеансовые данные.
Сам сервер 1С состоит из нескольких процессов:
-
Основной процесс сервера 1С – ragent, который порождает дочерние процессы rmngr и rphost.
-
Процесс менеджера – rmngr.
-
Рабочий процесс – rphost.
Важно понимать различие сеансов и соединений:
-
Сеанс – определяет активного пользователя информационной базы и поток управления этого пользователя. Сервер хранит связанную с сеансом информацию в сеансовых данных. За это отвечает сервис сеансовых данных.
-
Соединение – является средством доступа сеансов к кластеру серверов платформы 1С. При обращении клиента к серверу сеансу назначается соединение.
При начальном запуске системы клиенты никуда не обращаются, сервер крутится и не выполняет никаких запросов. Но уже в это время в технологическом журнале будут появляться события.
PROC

И первое событие, с которым я хотел бы вас познакомить – это событие PROC. Оно связано с началом, завершением или аварийным завершением процесса платформы 1С.
-
Событие имеет длительность, которая определяет время работы самого процесса
-
Событие PROC фиксируется в момент начала и завершения работы процесса
-
По анализу событий PROC мы можем увидеть, насколько часто у нас запускаются и перезапускаются рабочие процессы. Достаточно оценить количество событий PROC – если их много, то это уже подозрительно. Процессы должны запускаться и работать нормально, они не должны часто рестартовать.
У события PROC есть свойство Txt, в котором указана причина события – старт процесса, получения сигнала о завершении процесса или непосредственное завершение процесса. Здесь мы можем видеть, что процесс был завершен или стартован, указывается признак debug, если включена отладка.

В свойстве Txt события PROC также выводится интересная дополнительная информация.
Например, при проблемах стабильности работы – когда у нас высокая нагрузка и рабочие процессы перестают отвечать друг другу (перестают реагировать на работу подсистемы отслеживания разрывов соединений), у нас могут зафиксироваться вот такие плохие сообщения события PROC:
-
Bad cluster lock;
-
Cluster lock absent.
Эти сообщения означают, что процесс был потерян – потерял блокировку кластера и будет завершен принудительно. Он видит, что потерялся и не видит никакого смысла своего существования дальше и завершает свою работу. Причиной такого поведения обычно бывает потеря TCP-соединений между процессами сервера 1С.
Но причина потери TCP-соединений не всегда в сети – не нужно бежать к админам и кричать на них: «Почему у вас сеть не работает», хотя это проще всего сделать. Это бывает и при большой нагрузке – процесс настолько загружен, что он не успевает ответить. Параметры подсистемы отслеживания разрывов соединений регулируются с помощью параметров командной строки запуска процесса ragent. По умолчанию значения там довольно маленькие, и в большой нагруженной системе вы можете столкнуться с тем, что у вас процессы будут часто падать из-за потери блокировки кластера.
CONN

Важно знать, что все процессы платформы общаются между собой посредством заранее установленных TCP-соединений – они пересылают между собой какие-то запросы: «выполни то», «дай мне это» и прочее. Таким образом реализуется любое клиент-серверное взаимодействие между компонентами платформы 1С (RPC).
Такие события фиксируются в технологическом журнале. Даже если никто не работает в системе, там постоянно будут идти события – PROC и CONN.
Событие CONN – это установка или разрыв клиентского соединения с сервером. Тут под клиентом имеется в виду не пользователь, а клиент со стороны инициатора соединения. В принципе, при любой установке TCP-соединения – что тонкого клиента с рабочим процессом, что рабочего процесса с rmngr – будет фиксироваться событие CONN.
В событиях CONN мы тоже можем видеть свойство Txt, где в произвольной форме, которую трудно парсить, указываются различные интересные сообщения.
Мы видим первое событие CONN, в свойстве Txt которого указано Accepted. Событие говорит о том, что рабочий процесс (process=rphost), акцептовал некое TCP-соединение.
Также могут быть события с Txt=Connected и которых видно, что процесс успешно установил TCP-соединение.
На событиях CONN можно организовать интересный мониторинг, оценивая количество Accepted и Connected. Если таких событий аномально много, это свидетельствует о проблемах связанных с установкой/разрывами соединений.
Соответственно, можно увидеть, кто был клиентом, а кто – сервером. Видите, здесь есть IP-адреса и порты. Мы видим порт 1560 и можем сразу найти рабочий процесс по этому порту и т.д.
В финале, когда соединение TCP закрывается, тоже выводится событие CONN и оно уже имеет длительность, показывая длительность удержания TCP-соединения между процессами.
Также интересный вариант использования событий CONN – это отслеживать моменты, когда пользователи, заходят в систему под своей доменной учетной записью, но работают в 1С под другим именем пользователя. Когда клиент (тонкий или толстый) подключается к рабочему процессу, будет зафиксировано событие CONN – установка соединения. В этом событии будет передано не имя пользователя, а имя его доменной учетной записи. Это позволит точно узнать пользователя, который мог выполнять в системе странные операции под другим пользователем.

В событиях CONN выводится информация подсистемы отслеживания разрывов соединений в кластере. Для таких событий CONN в свойстве Txt будет указано ‘Ping direction statistics’. С помощью этих событий можно собирать полезную информацию, чтобы понять, есть ли у нас проблемы с сетью между компонентами кластера. Подобные CONN выводятся в лог раз в 10 секунд и несут в себе накопленную статистику.
В свойствах таких событий есть следующее:
-
address – ip адрес для которого выполняется сбор статистики.
-
pingTimeout и pingPeriod - таймаут и период опроса в мс. По умолчанию, в платформе стоит возможность сетевого таймаута на 5 секунд. Например, если рабочий процесс не ответит агенту сервера за 5 секунд, то будет считаться, что он потерялся.
-
Свойство packetsTimeOut, помогает сделать вывод о качестве сетевого взаимодействия между компонентами кластера. При нормальной работе, конечно, никаких таймаутов быть не должно. Я здесь специально нашел пример, когда у нас произошла проблема, и процесс rmng фиксировал потери – пять таймаутов.
-
Свойство packetsLost показывает потери пакетов (потеряно четыре пакета – packetsLost=4). Эту информацию довольно сложно интерпретировать, потому что статистика отслеживается в рамках скользящего 10-секундного окна. Пакеты могут оцениваться как потерянные в текущем окне статистики, но в следующем 10-секундном окне на них могут быть получены ответы.
-
Свойство packetsLostAndFound показывает количество пакетов, которые были отправлены в одном окне, а пришли в другом. Оно несколько помогает интерпретировать свойство packetsLost.
-
Можно парсить и мониторить avgResponseTime и maxResponseTime – эти свойства показывают сетевые задержки.
Такие интересные вещи можно взять из событий CONN.
SESN
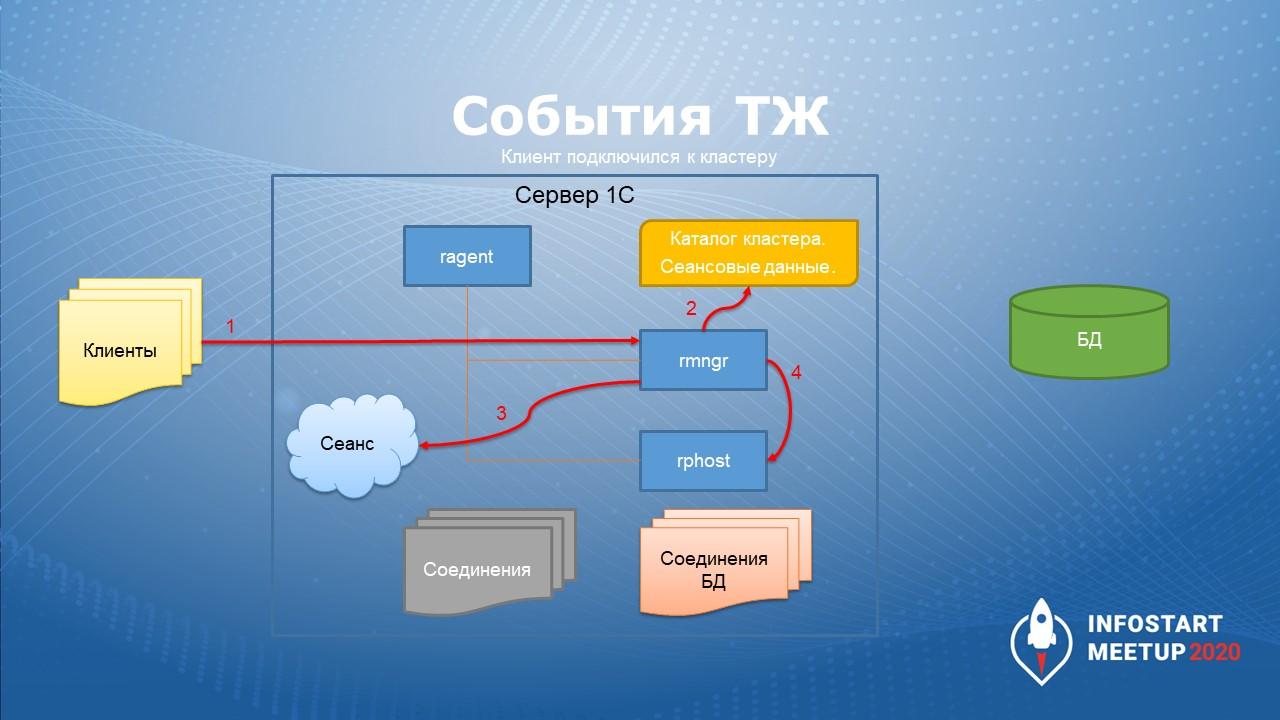
Чтобы пойти дальше по событиям, нужно понять - что происходит, когда клиент подключается к кластеру.
-
Первое – клиент первоначально устанавливает соединение с rmng.
-
Второе – rmng создает сеанс. Сеанс – это некая абстрактная сущность, которая представляет пользователя в системе.
-
Третье – rmng выделяет под сеанс определенные место в сеансовых данных.
-
Четвертое – rmng назначает сеанс на какой-то рабочий процесс rphost
-
Пятое – клиент устанавливает с этим rphost TCP соединение.

При установке сеанса выводится событие SESN – это действия, относящиеся к сеансу работы – начало, завершение сеанса.
Номер сеанса в событии SESN указывается в свойстве «Nmb».
У события SESN есть интересное свойство Func. Оно содержит действие, выполненное сеансом. Обычно это:
-
Start – создание сеанса.
-
Attach – сеансу назначено соединение. Причем в момент фиксации события SESN с Func=Attach оно уже имеет длительность, равную времени использования сеансом соединения. Такое событие выводится уже после того, как сеанс освободил соединение. Если сеанс не удалось создать, SESN не будет, оно выводится уже после завершения всех процедур.
-
Finish – это завершение сеанса. Его длительность показывает, сколько сеанс вообще просуществовал.
Анализируя событие SESN с Func=Attach можно смотреть, насколько долго было назначено соединение сеансу. При этом важно понимать, почему сеансу назначается соединение. Как я уже говорил, сам сеанс ничего не делает. Для выполнения какой нибудь работы (выполнение кода 1С, обращения к базе данных) сеансу нужно назначить соединение из пула соединений - через эти соединения сеанс в общем-то и работает.
Вы, наверное, все сталкивались с ситуацией, когда сеанс можно «кильнуть». Он отлетает, а соединение не убивается. Возможно, что на этом соединении выполняется код, в котором происходит длительный откат транзакции. Сеанс уже завершен, а соединение все еще работает, потому что не может завершиться операция ввода-вывода при обращении к базе данных, например идет откат транзакции.
Событие SESN не очень популярное, но позволяет иногда понять, что происходит с сеансами.
CALL и SCALL

Установили соединение, клиент приступает к работе и нажимает какую-то кнопку. Здесь мы приходим к двум самым важным событиям технологического журнала – это события CALL и SCALL.
Компоненты платформы постоянно общаются между собой, а факт такого общения регистрируется в ТЖ через события CALL и SCALL.
Здесь важно отметить и выделить первый принцип – это парность событий.
Смотрите, здесь на каждой картинке указано два события – SCALL и CALL.
-
SCALL – это исходящий вызов. Когда какой-то компонент (в нашем случае, рабочий процесс rphost) у кого-то что-то запрашивает (в данном случае у rmng) – он делает исходящий вызов, обращается к нему.
-
На стороне приемника в конце обработки этого запроса фиксируется событие CALL. Здесь мы видим, что rphost обратился к rmngr.
Но как же сопоставить эти события? Они действительно парные.
-
В первую очередь, все SCALL и CALL можно склеить между собой через свойство CallID. У событий CALL и SCALL для разных файлов технологических журналов, у разных процессов они будут совпадать.
-
Также в событиях SCALL и CALL можно увидеть очень важное свойство – это t:ClientID или просто ClientID. Возможно, разработчики платформы когда-то запутались и в некоторых событиях осталось t:ClientID, а в других ClientID. До конца не понятно, что значит t – это tcp или thread? Я предпочитаю думать, что это идентификатор потока выполнения, потому что, по сути, это значение также характеризует номер нашего потока выполнения в этом рабочем процессе.
-
Кроме этого, в событии SCALL в новых версиях платформы появилось вспомогательное свойство DstClientID (destination ClientID). Мы видим, что оно тоже равно 194 и видим, что rmng получил запрос, что-то сделал и отдал.

Я уже сказал про комплиментарность и дополняемость друг друга событий CALL и SCALL
Событие CALL – это входящий удаленный вызов (удаленный вызов на стороне приемника вызова).

А событие SCALL – это исходящий удаленный вызов на стороне источника вызова.
По свойствам событие SCALL почти аналогично событию CALL.
Схема процессов серверного вызова без обращения к СУБД
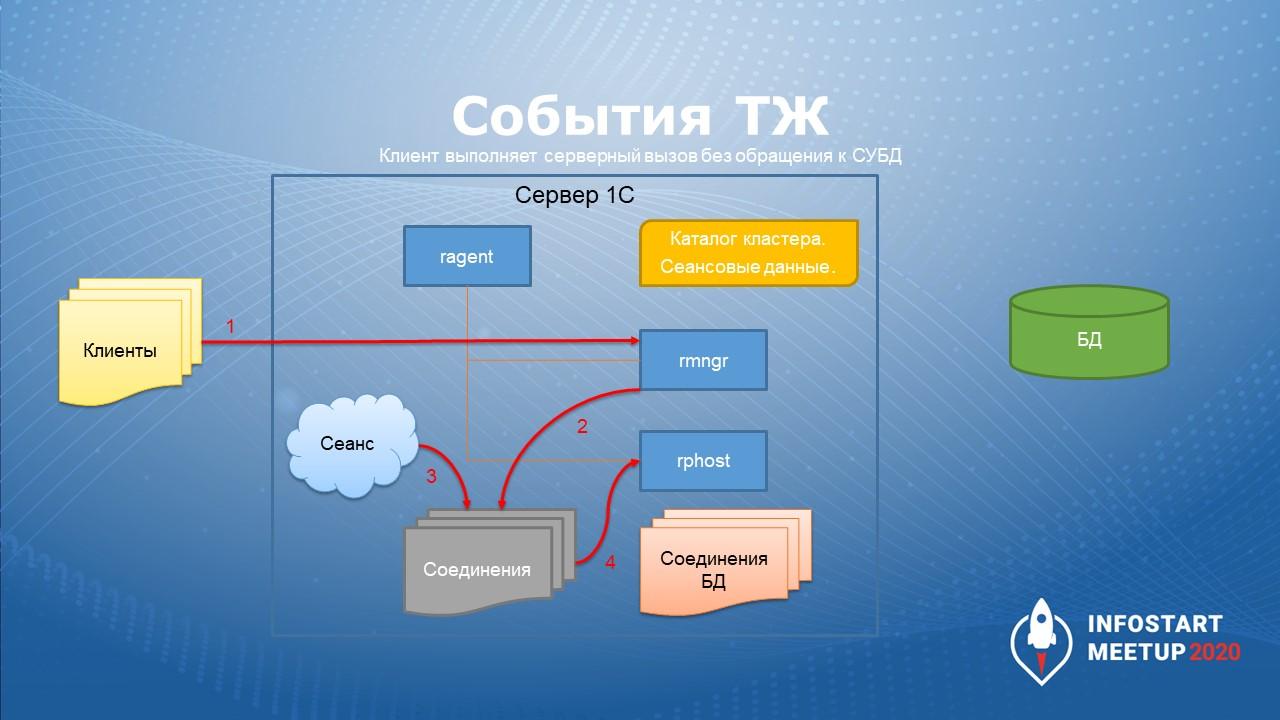
Посмотрим, что происходит, когда клиент выполняет серверный вызов без обращения к СУБД.
-
Предположим, что-то запустилось – например, обращение во внешнюю систему со стороны сервера или клиент нажал кнопку – здесь я условно показал, что вызов от клиента идет в rmng. Конечно, общение клиента происходит с rphost, но rphost в первую очередь обратится в rmng.
-
При этом rmngr назначает сеансу соединение для выполнения серверного вызова – на это уйдут какие-то дополнительные затраты времени. Кроме передачи с клиента на сервер будет еще внутренняя работа компонентов платформы. Иногда бывают случаи, когда сеансу очень долго может назначаться соединение.
-
И только после того, как сеанс получил соединение, он может выполнить какой-то код – обратиться во внешнюю систему, что-то еще.
Схема процессов серверного вызова с обращением к СУБД
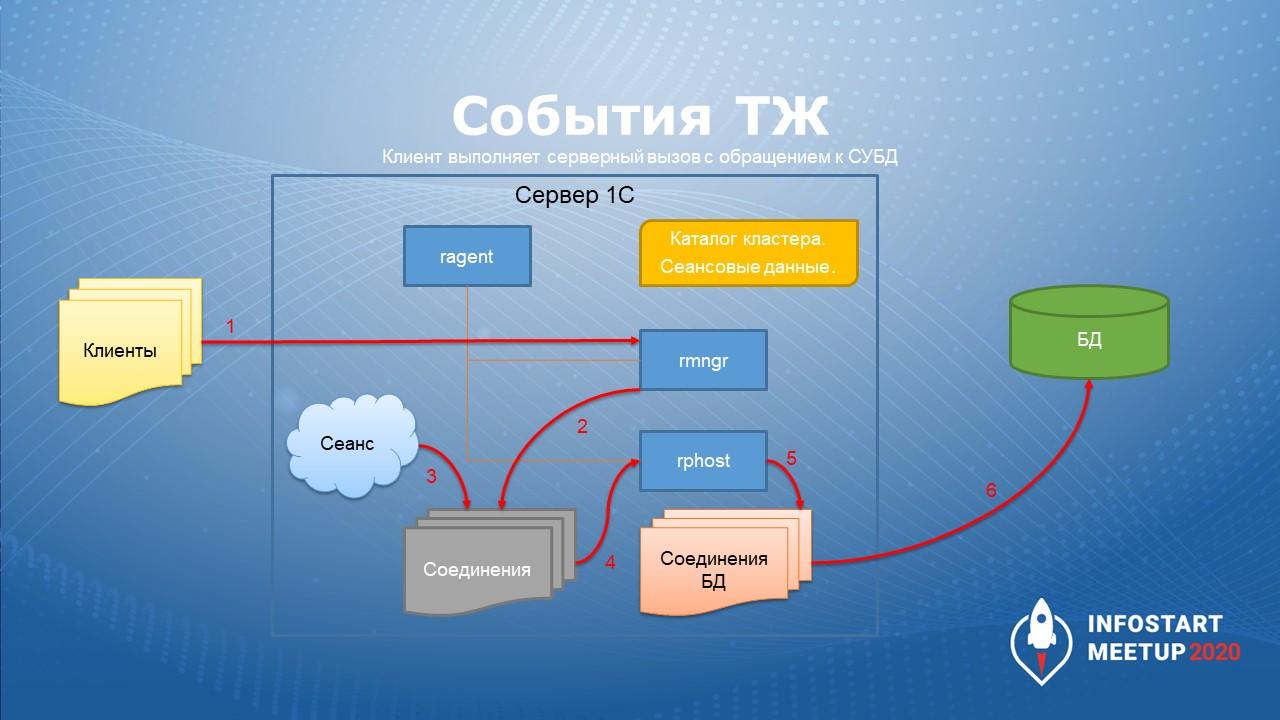
Если клиент выполняет серверный вызов и при этом взаимодействует с СУБД, первоначальная последовательность действий такая же:
-
Клиент обращается к менеджеру кластера (1).
-
Менеджер подбирает соединение для выполнения серверного вызова и назначает его сеансу (2, 3).
-
Рабочий процесс выполняет серверный вызов (4).
-
Если выполняющийся на рабочем процессе код встречает обращение к СУБД (например, запрос), появляется новый пункт – происходит получение соединения с базой данных из пула соединений с базой данных.
-
Когда это соединение получено, выполняется сам запрос на базе данных.
-
Данные приходят в рабочий процесс, обрабатываются дальше и, может быть, отдаются клиенту.
Такая вот незамысловатая схема.
Все стрелки на схемах, приведенных выше – это CALL и SCALL. Их можно отследить по цепочке друг за другом, так как они связаны через свойство CallID – это один из первых принципов событий, связанных между собой.
VRSREQUEST и VRSRESPONSE

Есть еще два тоже очень интересных события – это VRSREQUEST и VRSRESPONSE.
Они характеризуют обращение к серверу за некоторыми внутренними ресурсами платформы. Обращение к серверу описывается событием VRSREQUEST, а ответ сервера – VRSRESPONSE.
Эти события как бы оборачивают CALL / SCALL:
-
сначала фиксируются события VRSREQUEST / VRSRESPONSE, отражающие по факту начало и завершение события и не имеют длительности;
-
и только потом CALL / SCALL, показывающие длительность самого события.
На слайде можно увидеть, что VRSREQUEST – это какой-то запрос с process=apache2. В событии выводятся все HTTP заголовки– по ним видно, что откуда пришло.
Также выводятся два интересных свойства – Pragma: sync=6 и vrs-session: некоторый идентификатор – по сути, идентификатор нашего сеанса. Мы привыкли видеть сеансы в консоли кластера как 1-2-3-4-5, т.е. целые числа, но они также имеют идентификаторы.
Соответственно, через эти свойства событий мы можем опять сопоставить некую цепочку.

Предположим ситуацию – у нас есть веб-сервер, рабочий процесс, менеджер сервера входящие в какой-то кластер 1С.
С веб-клиента пришел запрос для выполнения серверного вызова. Давайте рассмотрим путешествие серверного вызова с веб-клиента на сервер.
-
В первую очередь в ТЖ веб-сервера фиксируется событие VRSREQUEST, у которого есть идентификатор vrs-session.
-
В ТЖ менеджера сервера rmng по этому идентификатору мы можем найти событие SESN, у которого Func=start, тот же самый идентификатор и свойство Nmb=1. Nmb – это номер сеанса. Таким образом можно сопоставить ТЖ между веб-сервером и менеджером сервера rmngr – найти время, когда этот сеанс реально был создан, прочитать его номер сеанса в привычном нам виде и найти его в консоли. Это довольно муторно, но при подробном ТЖ это можно сделать.
-
Веб-сервер обращается к рабочему процессу rphost. В ТЖ рабочего процесса также фиксируется событие VRSREQUEST, которое показывает, что к rphost обратились со стороны. Обратите внимание, что если сравнить его с VRSREQUEST на веб-сервере:
-
у них совпадает vrs-session – это, по сути, тот же идентификатор сеанса vrs-session, который был на веб-сервере;
-
кроме того, совпадает свойство Pragma: sync=6 – счетчик серверных вызовов. Если бы мы попытались склеить между собой VRSREQUEST на веб-сервере и в рабочем процессе по vrs-session – мы бы нашли их, но мы бы не знали, кто друг к другу относится. Только если расставить их по времени, но запросов бывает очень много и это довольно сложно сделать. Поэтому склеивание удобнее производить по свойству sync.
-
При поступлении http-запроса на веб-сервер не только фиксируется событие VRSREQUEST, но и происходит исходящий вызов на рабочий процесс сервера 1С – это событие SCALL. Но пока мы его не видим, потому что события CALL / SCALL выводятся после их завершения, а события VRSREQUEST и VRSRESPONSE выводятся сразу (они не имеют длительности).
В ТЖ рабочего процесса мы видим, что:
-
В 38:02 пришел запрос – зафиксировалось событие VRSREQUEST. Как я говорил, VRSREQUEST фиксируется по факту: пришел запрос – начали выполнение.
-
Далее на протяжении 9.5 секунд что-то происходило – мы к этому вернемся позже.
-
В 38.12 после выполнения серверного вызова фиксируется событие VRSRESPONSE – фиксируется по факту, говоря о том, что «все, я завершил, могу отвечать».
-
В самом конце фиксируется событие CALL, которое показывает время отработки этого серверного вызова – у него длительность как раз 9.5 секунд.
Нужно отметить тот факт, что свойство t:clientID одинаковое у всех записей ТЖ процесса rphost, относящихся к этому вызову: одинаковый у VRSREQUEST, VRSRESPONSE и CALL.
У события CALL есть свойство CallID – оно поможет нам найти для него SCALL в ТЖ веб-сервера:
-
По свойству CallID найдем SCALL, комплиментарный событию CALL рабочего процесса. Этот SCALL также будет иметь длительность 9.5 секунд, даже чуть больше – разницу по времени составляют затраты на передачу данных между рабочим процессом и веб-сервером.
-
И в самом конце на веб-сервере фиксируется событие VRSRESPONSE. То есть мы отправили ответ уже самому веб-клиенту или тонкому клиенту. В свойствах события VRSRESPONSE можно увидеть статус ответа – 200 (при нормальном завершении серверного вызова).
Нас интересует, что же происходило в эти 9.5 секунд. Давайте посмотрим, пройдемся по событиям от первого VRSREQUEST до длительного CALL.

Первым фиксируется VRSREQUEST, за ним идут некоторые исходящие вызовы – SCALL. Эти события друг с другом связаны, потому что t:ClientID у них одинаковый и принадлежат одному процессу кластера.
Мы видим, что исходящие вызовы SCALL уходят на менеджер сервера 1С, это можно понять по значениям свойства MName:
-
getSeanceServers – «Дай мне сервер сеансовых данных».
-
getSeanceParameterSer – «Дай мне параметры моих сеансов».
-
attachSeanceIB – «Приаттачь мой сеанс к соединению».
У всех этих обращений есть длительность, но она незначительна – 9.5 секунд здесь нет.
SDBL и DBPOSTGRS

Идем дальше и находим событие SDBL.
SDBL – это промежуточный язык запросов (по сути, язык запросов 1С), данные которого потом переводятся в синтаксис той СУБД, которую мы используем.
Событие SDBL – это исполнение запросов к модели базы данных платформы 1С. Оно возникает, когда код начинает работать с запросами к СУБД. В данном случае используется СУБД Postgres, что видно из свойства DBMS события SDBL.
Событие SDBL возникает сначала, когда мы еще не обратились к базе данных. Давайте обратим внимание на его интересные свойства.
-
У него есть свойство Trans=1, которое означает, что событие связано с открытой транзакцией. Это должно всегда настораживать – любые события SDBL со свойством Trans=1 и с большой длительностью свидетельствуют о том, что у нас есть длительные транзакции.
-
Свойство Func=BeginTransaction. В этом свойстве указывается вид выполняемого действия. В нашем примере - начало транзакции.
-
Свойство Context, в котором выводится контекст выполнения кода, откуда это событие было вызвано. Здесь мы видим, что в модуле какой-то управляемой формы был вызов кода 1С с инструкцией НачатьТранзакцию().
За ним мы видим событие DBPOSTGRS. Это – событие, которое свидетельствует уже о непосредственном выполнении операторов СУБД (для других СУБД название события иное, но всегда начинается на DB*).
Событие DBPOSTGRS выводится по окончании выполнения непосредственного запроса к СУБД и имеет длительность, которая равна чистому времени выполнения запроса на СУБД. Поэтому если вдруг мы видим в системе очень длительный запрос, к сожалению, мы не сможем оперативно узнать, что там происходит, потому что событие DBPOSTGRS будет выведено в ТЖ по завершении.
В свойствах события есть много полезной информации.
-
Свойство Trans=1, говорит о том, что это запрос в транзакции.
-
Свойство dbpid – это идентификатор соединения с базой данных.
-
Свойство Sql=BEGIN TRANSACTION. Это текст выполненного запроса в терминах СУБД. В нашем примере, это оператор начала транзакции.

Идем дальше. Обратите внимание, что предыдущее событие имеет отметку времени 10:53, а следующее событие только в 11:03 и это тоже событие DBPOSTGRS. Оно имеет длительность две миллисекунды и про него можно сказать следующее:
-
Событие имеет отношение к нашему потоку выполнения, имеет тот же самый идентификатор соединения с базой данных.
-
Оно выполняется в транзакции.
-
В свойстве Sql мы видим какой-то бессмысленный запрос, который в результате вернул ноль строк – это следует из свойства RowAffected=0.
Но куда делись 9.5 секунд? Событий здесь больше нет.
В этом случае, нам придется обратиться к коду.

Мы знаем контекст, идем в код и видим, что между началом транзакции и нашим запросом был просто бесконечный цикл, реализованный не самым лучшим способом.
Это сделано в качестве тестового примера - 9 секунд было потрачено на этот бесконечный цикл.
В общем-то, мы нашли проблему нашего довольно длительного серверного 9-секундного вызова. Если бы мы собирали только события DBPOSTGRS, мы бы ничего не поняли. Мы увидели этот маленький запрос и, наверное, подумали – странно, почему он так долго выполняется. А у нас оказывается был код с бесконечным циклом в транзакции.

Идем дальше по событиям. Бесконечный цикл отработал, код продолжил выполнение. Опять фиксируется событие DBPOSTGRS – видим, что:
-
Оно принадлежит нашему потоку выполнения;
-
Sql=ROLLBACK – откат транзакции.
Это чудесный тестовый код для примера – абсолютно бессмысленный и беспощадный. Мы 9.5 секунд провисели, и потом еще и отменили транзакцию.
Но в этом месте могло бы быть и обращение во внешнюю систему, бесконечный цикл просто эмулирует подобное.
Или может быть ситуация, когда rmngr начинает тупить или делать что-то очень сложное, и мы тратим время на общение между компонентами внутри платформы.

Идем дальше по событиям. Смотрите, здесь идет два события SDBL – опять же, мы возвращаемся к работе с запросами на уровне платформы.
-
Событие SDBL имеет свойство Func=RollbackTransaction и длится 9.5 секунд. Именно оно показывает откат длительной транзакции.
-
Дальше идет интересное событие SDBL, у которого Func=HoldConnection. Это событие фиксируется в тот момент, когда мы отдаем соединение с базой данных в пул. Его длительность будет равна длительности удержания соединения с базой данных.
Конечно, при мониторинге длительных транзакций следует учитывать, что Func в данном случае может быть и CommitTransaction. Т.е. если мы видим SDBL с длительными фиксациями/откатами транзакций – у нас есть проблемы. Так же, если мы видим длительные вызовы SCALL в направлении менеджера – у нас тоже есть проблемы.
Дальше мы видим событие VRSRESPONSE – рабочий процесс говорит: «Все ОК, я готов ответить». Смотрите, здесь у нас Status=200, все завершилось нормально, ошибок нет.
И только потом фиксируется событие CALL, длительность которого 9.5 секунд. Теперь-то мы уже знаем, что там происходило. В свойствах события CALL есть:
-
Context – можно узнать, в каком месте был столь длительный серверный вызов.
-
CallID – через него мы можем выйти на SCALL. Или, наоборот, из длительного SCALL перейти к CALL и двигаться далее.
-
У события CALL есть важное свойство – MemoryPeak. Это свойство показывает максимальный объем потребленной памяти за серверный вызов. В рассматриваемом случае, серверный вызов в пике задействовал всего-то 893 кБ, это немного, но оно может быть и несколько десятков гигабайт.
-
Очень важное свойство CpuTime - время использования ресурсов CPU при выполнении серверного вызова. Из длительности самого CALL-а можно сделать вывод, что из 9.5 секунд, 9.4 секунды серверный вызов занимал ресурсы CPU. То есть почти все время серверного вызова было проведено на потребление ресурсов CPU. Это был бесконечный цикл, который реализован отвратительным образом и очень сильно грузит центральный процессор. В обычной практике серверные вызовы не занимают так много времени CPU, а проводят время на ожидании завершения операций ввода-вывода, поэтому CpuTime будет меньше длительности CALL. Так что возьмите на заметку, обязательно анализируйте длительность, CpuTime и MemoryPeak у событий CALL.
-
По поводу показателя Memory – лучше не отвлекайтесь на него, потому что до сих пор никому достоверно не известно, как работает менеджер памяти в платформе и понимать, почему в этом показателе возникают «минуса». Да, освобождается какая-то память, но, в общем и целом, нет достоверной информации.
Главные показатели для мониторинга серверных вызовов – длительность, CpuTime, MemoryPeak и Context.
Схема взаимодействия событий ТЖ
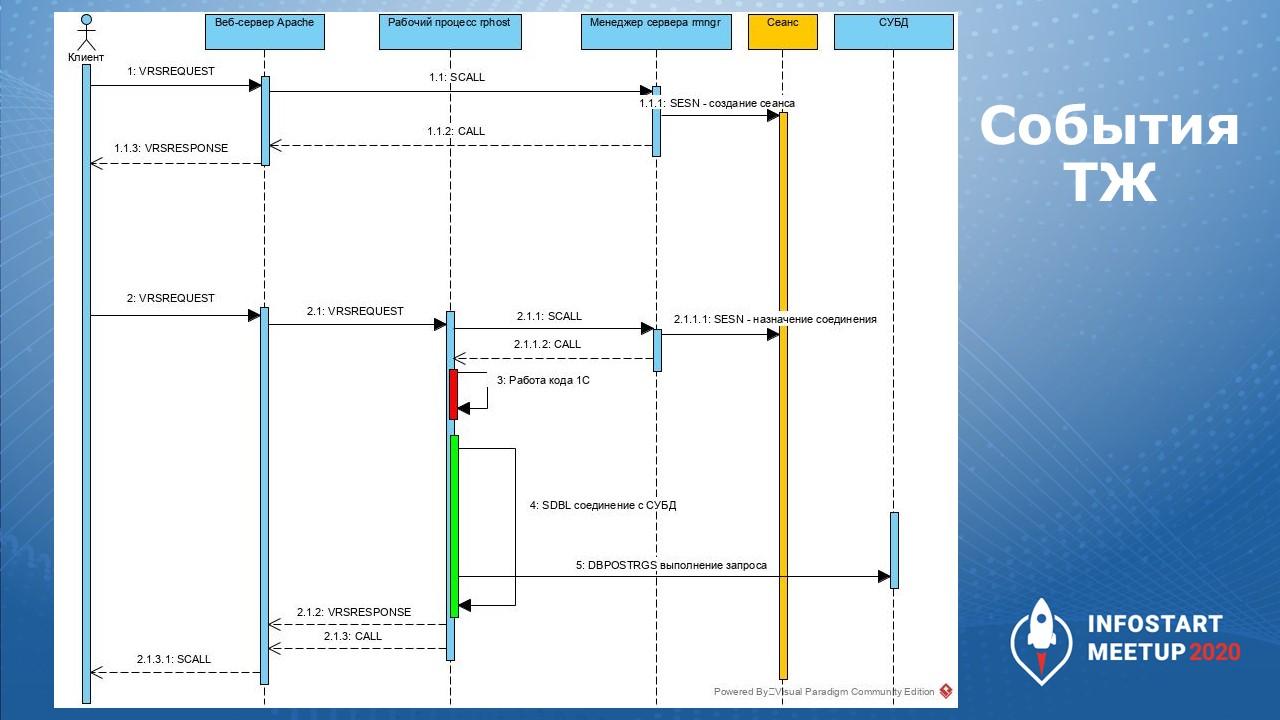
Взаимодействие всех рассмотренных событий между процессами платформы 1С, можно представить схемой показанной на слайде.
Здесь начало стрелок показывает, в ТЖ какого процесса платформы 1С будет выведено событие, а блоки действий показывают длительность событий.
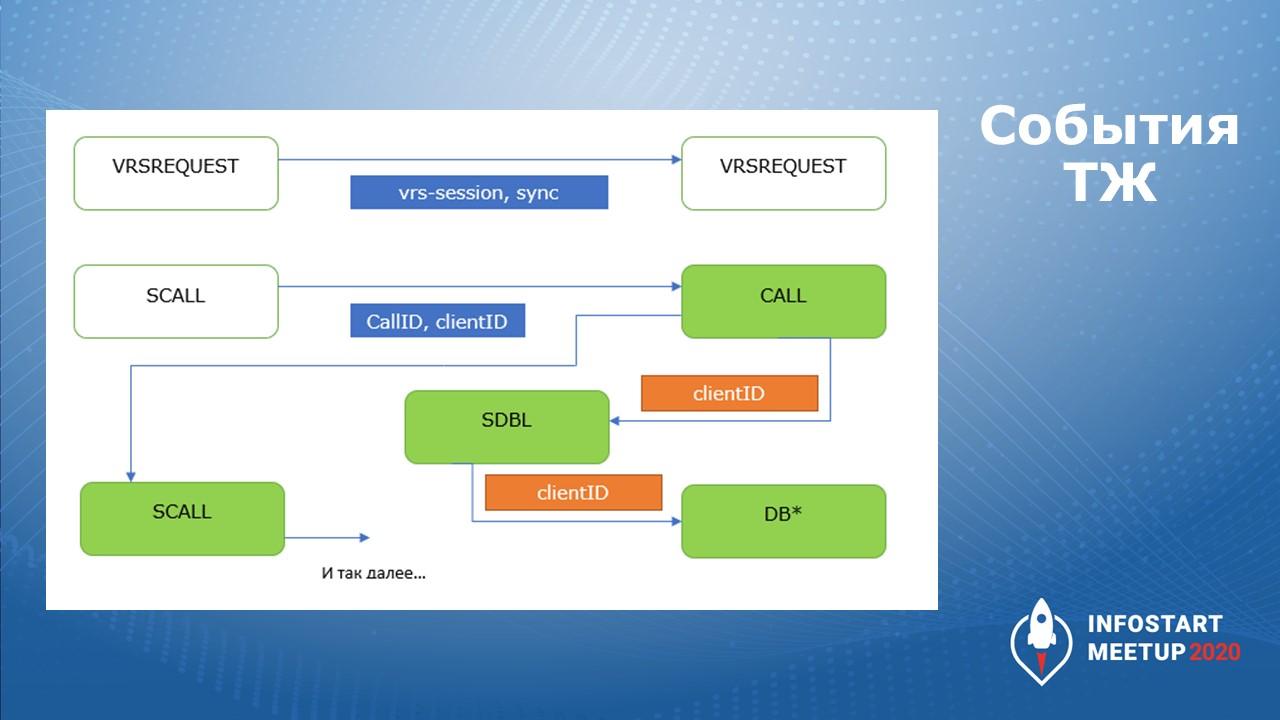
На другой схеме представлены события ТЖ и их свойства, с помощью которых можно строить цепочки зависимых событий.
Особенно важно понимать, как находить комплиментарные события.
-
VRSREQUEST с одного и другого процесса можно найти через vrs-session и sync
-
SCALL и CALL ищутся по CallID и по ClientID.
Событие CALL чрезвычайно важно для понимания работы серверного вызова, потому что является корневым событием для других событий.
Найдя длительный CALL, мы должны расследовать, из каких событий он состоит – отобрать все события с тем же самым ClientID, что у нашего CALL за временной диапазон от момента завершения (вывода CALL в технологический журнал) до момента, когда он начался по факту (то есть вычесть из времени события его длительность). И тогда мы получим полный трейс серверного вызова, увидим, куда было потрачено время – на события SDBL или DB, на какие-то SCALL в rmngr или еще куда-то.
Практическое применение
Понимание взаимосвязи и сущности событий ТЖ – это ключ к возможности решения многих проблем работы 1С.
Если мы будем собирать все события CALL / SCALL, а также VRSREQUEST / VRSRESPONSE, мы можем построить дерево «серверного вызова».
Анализируя дерево серверного вызова, можно найти узлы, в которых серверный вызов провел большую часть времени.
Дополняя эти узлы такими событиями как SDBL / DB* можно выделить время, которое серверный вызов «провел» на СУБД. И уже из событий SDBL / DB* найти проблемные запросы к СУБД.
Однако может быть ситуация, когда проблемным событием окажется CALL процесса менеджера сервера – rmngr. Обычно такие вызовы связаны с работой сервисов менеджера кластера 1С, например, запросы установки управляемой блокировки, работа с сеансовыми данными и т.д.
Хранение ТЖ

Чтобы проанализировать данные, их нужно правильно хранить. В своей практике мы храним логи следующим образом:
-
текущие данные (это 2-7 дней) храним в Elasticsearch;
-
старые данные просто пакуем и отправляем в архивы.
Zip-архивы очень хорошо читаются даже без распаковки. Вывод программы распаковки можно сразу передать или в grep или в тот же Elasticsearch для индексации.
Для индексации логов рекомендую использовать Elasticsearch от Amazon – Open Distro for Elasticsearch. Этот дистрибутив поддерживает много полезных дополнений сразу из коробки – например, систему аутентификации и авторизации.
Напомню, что Elasticsearch это свободная (относительно) NoSQL СУБД с возможностью полнотекстового индексирования, которая хорошо подходит для сбора и анализа логов ТЖ.

Я подготовил репозиторий, в котором выложил всю информацию, о которой я говорил. В репозитории есть:
-
Vagrantfile и docker-compose файл для запуска Elasticsearch и Kibana.
-
Конфигурация ingest pipeline для парсинга технологического журнала.
-
Конфигурация Filebeat для сбора технологического журнала.
-
Дополнительная информация.
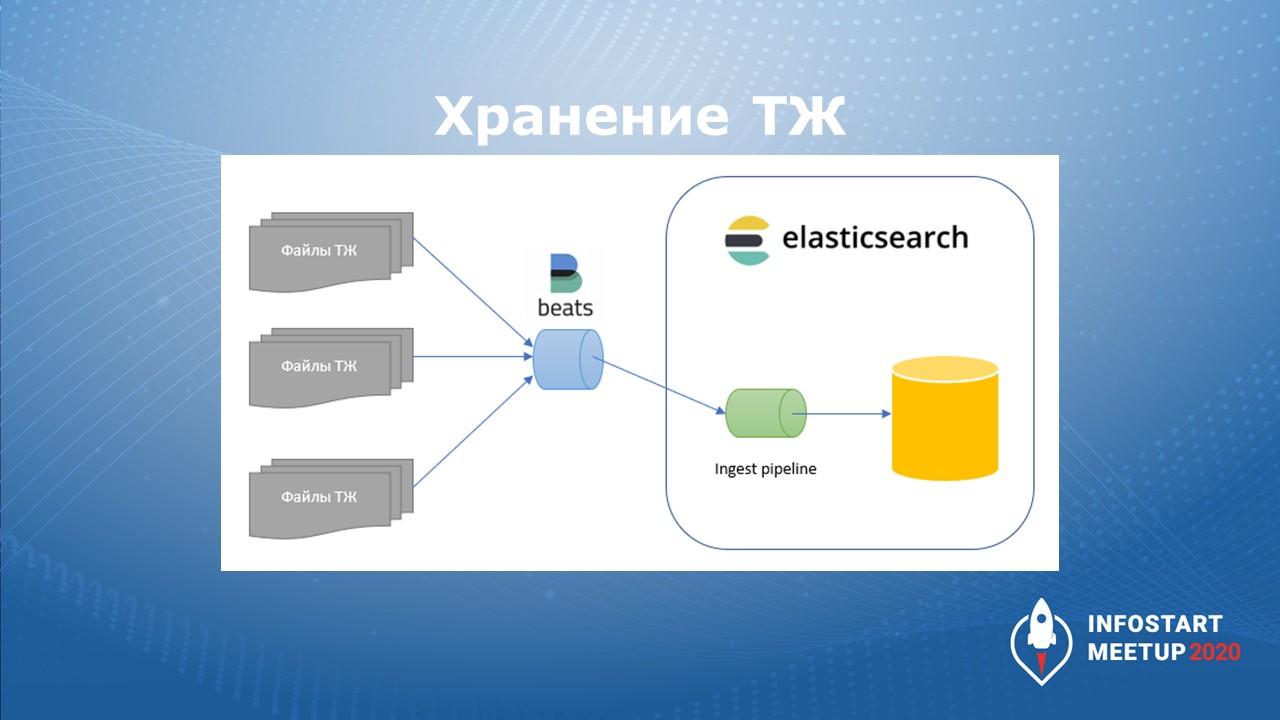
Немного информации о Filebeat. Filebeat – это сборщик логов, который умеет их собирать, нарезать на строки и отправлять в Elasticsearch.
В Elasticsearch есть ingest pipeline, который это все распарсит, разложит на нужные нам события, и мы сможем на ходу с этим работать.
Filebeat можно устанавливать как службу на рабочих серверах платформы 1С или установить на отдельном сервере откуда есть доступ к каталогам ТЖ.
Все это работает без особых проблем на достаточно большой инфраструктуре.
Принципы приготовления технологического журнала

В заключение, хотел бы выделить принципы / рецепты приготовления технологического журнала.
-
Правильная настройка ТЖ – нужно понимать, что хочется получить. События не просто так появляются в технологическом журнале, не нужно просто так включать вывод всех событий.
-
Парность событий – дополнительная информация находится в парном событии.
-
События связаны между собой – это позволяет понять происходящее.
-
Базовые события – нужно знать базовые события: CALL / SCALL, SDBL, DB* , чтобы понимать, что ты хочешь получить.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Ekaterinburg.Online.


Вступайте в нашу телеграмм-группу Инфостарт
