Хочу поделиться опытом, как контролировать качество разработки отчетов, обработок, расширений и конфигурации в целом в 1С.
В рамках доклада я рассмотрю следующие вопросы:
-
Зачем контролировать качество кода.
-
Как и с помощью каких инструментов можно контролировать качество кода в ручном и автоматическом режиме.
-
Как использовать Jenkins, чтобы автоматизировать процессы повышения качества.
-
И поделюсь ссылками, которые будут упомянуты в рамках доклада.
Качество кода и его критерии

Трудно дать точное определение, что такое качество кода, но его можно оценить на основании определенных критериев.

Критерии качества кода следующие – это:
-
соответствие стандартам разработки;
-
отсутствие ошибок в коде;
-
невысокая сложность;
-
низкое количество дублирования в коде;
-
наличие документации и тестов.
В совокупности все эти критерии и образуют общую картину, насколько качественно написано решение.
Зачем контролировать качество кода?
Мы проектируем решения, пишем алгоритмы. Кому будет плохо, если мы это сделаем хуже, но быстрее и дешевле?
Чтобы ответить на этот вопрос, нужно рассмотреть эту ситуацию с разных сторон.

Со стороны заказчика:
-
Уменьшая количество проблем в коде, можно сэкономить деньги и время у бизнеса.
-
Если код написан хорошо, то новые возможности в текущее решение можно внедрить дешевле и быстрее – не нужно переписывать какие-то части кода, переделывать хранение данных с нуля, если это, конечно, не переосмысление проекта или задачи в принципе.

Со стороны исполнителя/подрядчика:
-
Если проект написан качественно, то для разработки и внедрения новой функциональности будет затрачено приемлемое количество времени. Непредвиденных случаев становится меньше, разработчики не будут делать лишнюю работу, за которую не заплатит заказчик.
-
Если проект написан качественно, то в нем можно будет использовать менее квалифицированных сотрудников, так как их компетенций будет вполне хватать, чтобы разобраться в решении и реализовать требуемые от них задачи. Опять же, это экономит деньги у подрядчика.

Со стороны сопровождения/поддержки.
-
Для сопровождения качественного проекта потребуется меньше ресурсов, чем для проекта, который написан по передовой технологии «через пень-колоду».
-
При этом для сопровождения можно использовать менее квалифицированных сотрудников – хотя, конечно, это возможно только при наличии грамотно написанной документации, которую иногда нужно читать.
Подведу маленький итог. Всем сторонам выгодно держать качество разработки на приемлемом уровне:
-
с одной стороны, это возможность заработать больше;
-
с другой стороны, это экономия денег;
-
также стоит отметить, что в какой-то момент некачественное решение нельзя будет дорабатывать в таком виде из-за накопившегося технического долга и сложности написанного кода.
Как контролировать качество кода?

Допустим, мы знаем критерии качественного кода. Но что дальше? Как это качество контролировать?
Для повышения качества кода можно использовать следующие практики:
-
Стандарты разработки 1С и выработанные внутри команды стандарты.
-
Чтение кода.
-
Инструменты автоматизации разработки.
-
Тестирование кода.
-
Документирование проектов и кода.
-
Статический анализ кода.
Расскажу о каждой из этих практик подробнее.
Стандарты разработки

К стандартам разработки можно отнести:
-
Стандарты 1С:Совместимо и сами стандарты 1С с сайта 1С:ИТС. Это очень полезные правила – большинство из них обосновано и помогают сохранить много человеко-часов при разработке.
-
Также есть какие-то внутренние стандарты разработки компании, которые вырабатываются внутри команды. Чаще всего, это какие-то исключительные особенности, либо адаптация стандартов разработки 1С.
-
И последнее – это собственный код-стайл разработчика. По мере накопления опыта, по мере работы в команде, у человека накапливаются какие-то свои стандарты, помогающие делать решения лучше и тратить меньше времени на поиск ошибок.
Чтение кода

Следующая практика – это чтение кода. Сюда входит:
-
Code Review – анализ кода с целью выявить ошибки, плохую архитектуру, отклонения от изначально поставленной задачи
-
Парное программирование – одна из практик экстремального программирования, которая опирается на идею непрерывного чтения кода. Один из программистов разрабатывает, а другой анализирует этот код и дает какие-то комментарии.
-
Разработка в команде, когда контроль кода организуется в группе от 2 до 5 человек. Ведущий группы чаще всего занимается архитектурой в общем, сложными задачами, проводит чтение кода, разделяет задачи на более мелкие и распределяет их между членами команды.
Инструменты автоматизации разработки
Инструментов автоматизации для 1С немало. Они созданы, чтобы минимизировать рутинную работу разработчиков, чтобы они меньше отвлекались от своей основной обязанности – писать качественный код. К этим инструментам можно отнести сами платформы для написания кода – это конфигуратор 1С и EDT. И инструменты автоматизации, расширяющие возможности этих платформ.
Расширение возможностей конфигуратора 1С

Для конфигуратора 1С, как минимум, есть следующие инструменты, которые могут облегчить жизнь. Это:
-
PhoenixBSL;
-
SmartConfigurator;
-
И два платных продукта – TurboConf и Снегопат. Про них я подробно рассказывать не буду, всю необходимую информацию вы можете прочитать на страничках этих проектов. В целом скажу, что продукты хорошие, у них есть определенные плюсы, и есть определенные минусы.
Подробнее расскажу про PhoenixBSL и SmartConfigurator.
PhoenixBSL

PhoenixBSL – это проект, который позволяет упростить работу в конфигураторе 1С за счет использования возможностей движка BSL LS (проект, который реализует Language Server Protocol для языка 1С).
На текущий момент PhoenixBSL предоставляет три основные возможности:
-
Анализ кода на замечания.
-
Форматирование кода.
-
Быстрые исправления кода.
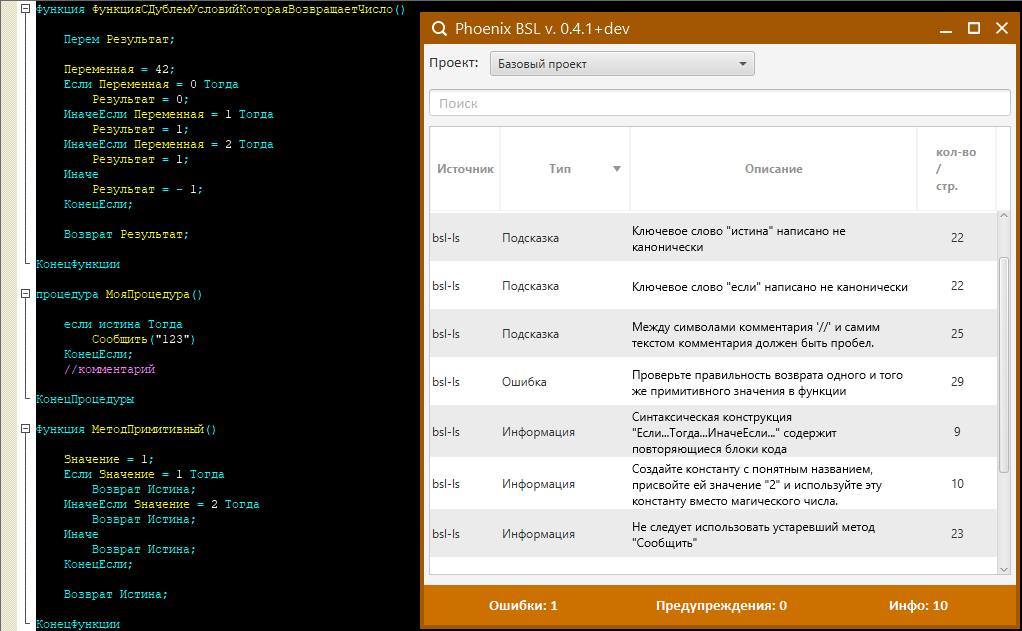
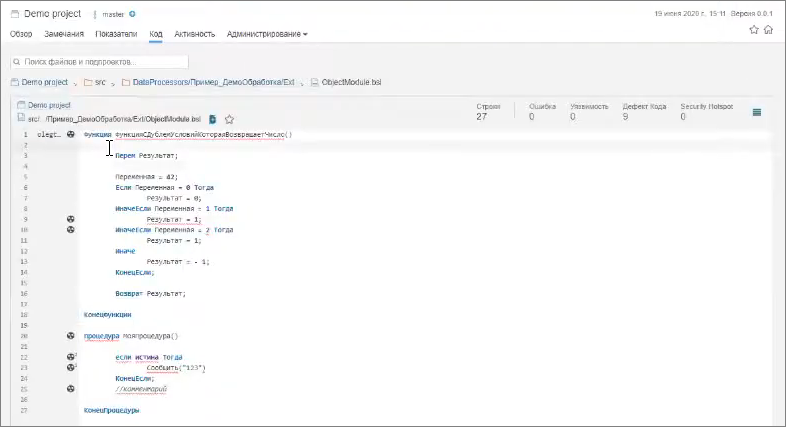
Например, открываем модуль в конфигураторе, по сочетанию клавиш Ctrl+I для выделенного кода вызываем PhoenixBSL и видим результат анализа кода текущего модуля на замечания.
Как видите, здесь есть и ошибки, и какая-то информация, и какие-то подсказки. Если посмотреть детально:
-
Есть условия «Если» с разными ветками. PhoenixBSL нам говорит, что у нас есть дубли, повторяющиеся условия. Смотрите, здесь есть ветка «Переменная = 1 Тогда Результат = 1» и есть ветка «Переменная = 2 Тогда Результат = 1». Это плохо – либо кто-то ошибся, либо это какой-то жесткий копипаст, так не должно быть.
-
Еще PhoenixBSL может отловить, например, использование устаревшего метода «Сообщить», который сейчас использовать не принято – нужно использовать либо функцию из БСП, либо «Новый СообщениеПользователю()».
Возможности проекта BSL LS позволяют PhoenixBSL предоставлять очень много диагностик для анализа кода.

Следующая функциональность PhoenixBSL – это форматирование кода. Я все сдвигаю, чтобы было некрасиво, и нажимаю для выделенного кода Ctrl+K – у меня произошло форматирование кода.

Последняя особенность PhoenixBSL – это быстрые исправления в коде. Допустим, в результате анализа кода на замечания, слово «Истина» у нас оказалось написано не канонически. Я выделяю этот блок, нажимаю Ctrl+J и PhoenixBSL:
-
автоматически исправляет неканонические написания;
-
ставит пробел между комментарием и двумя слэшами;
-
и ставит точку с запятой после оператора «Сообщить».
SmartConfigurator

Следующий инструмент – это SmartConfigurator, проект с набором скриптов для автоматизации ряда действий в конфигураторе. С полным списком его возможностей можно ознакомиться на странице проекта.
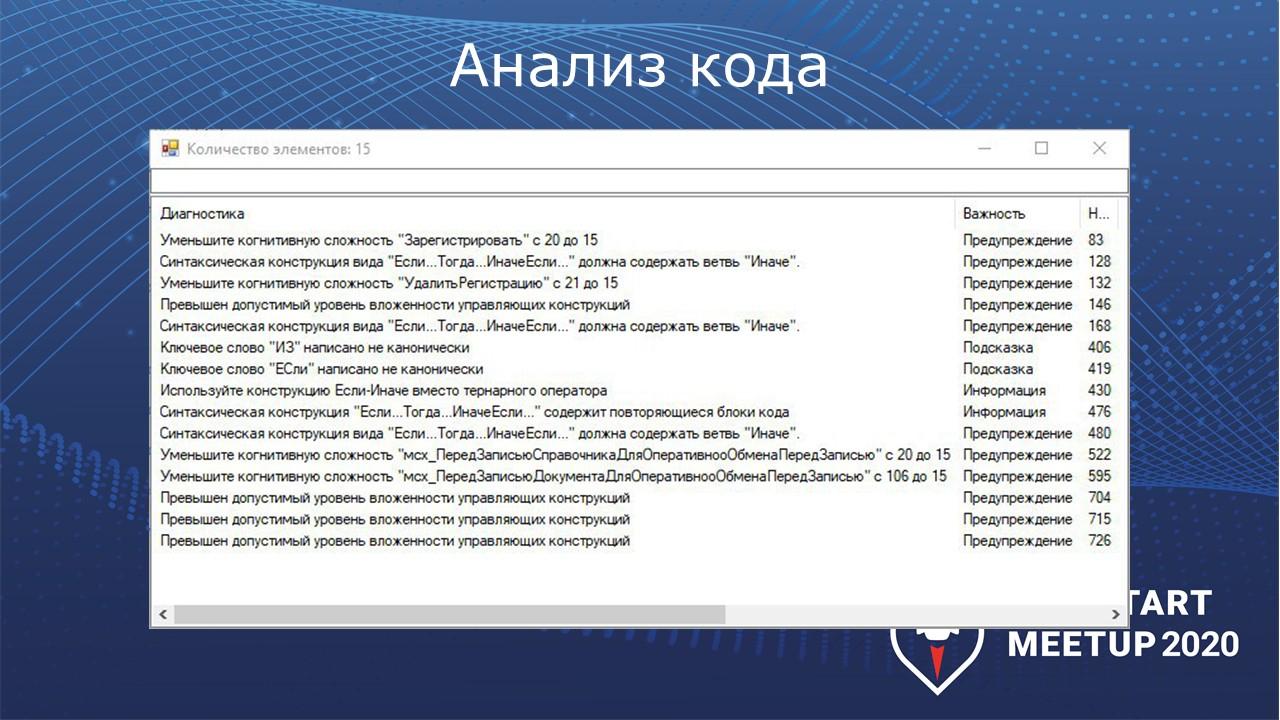
SmartConfigurator также умеет выполнять анализ кода в конфигураторе – он тоже вызывается через хоткей в конфигураторе и открывает окно с замечаниями. Замечания также выводятся с помощью проекта BSL LS.

Здесь тоже есть форматирование кода – оно реализовано с помощью скрипта форматирования OneStyle. Этот скрипт имеет много настроек – вы можете настроить форматирование кода под себя.
Вы видите, что было сверху, что стало снизу. На мой взгляд стало симпатичнее, но, допустим, я пробелы между скобками и параметрами не ставлю. Хотя все это можно под себя подстроить.
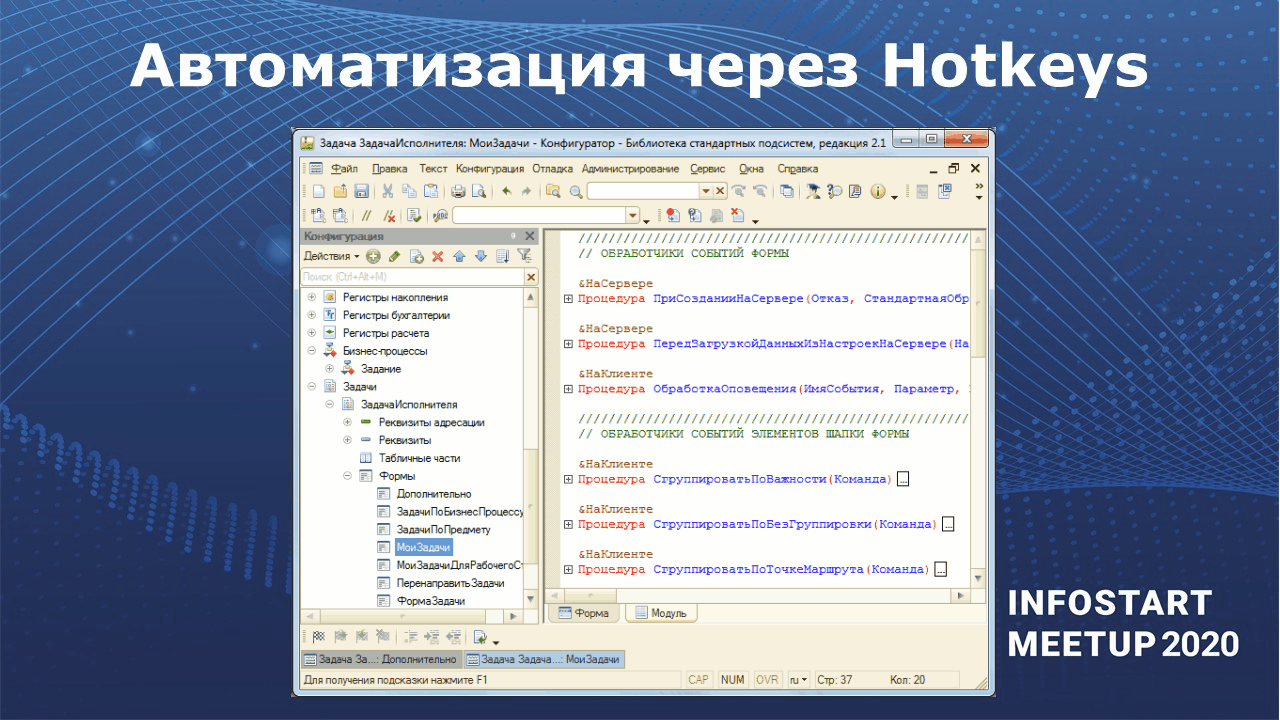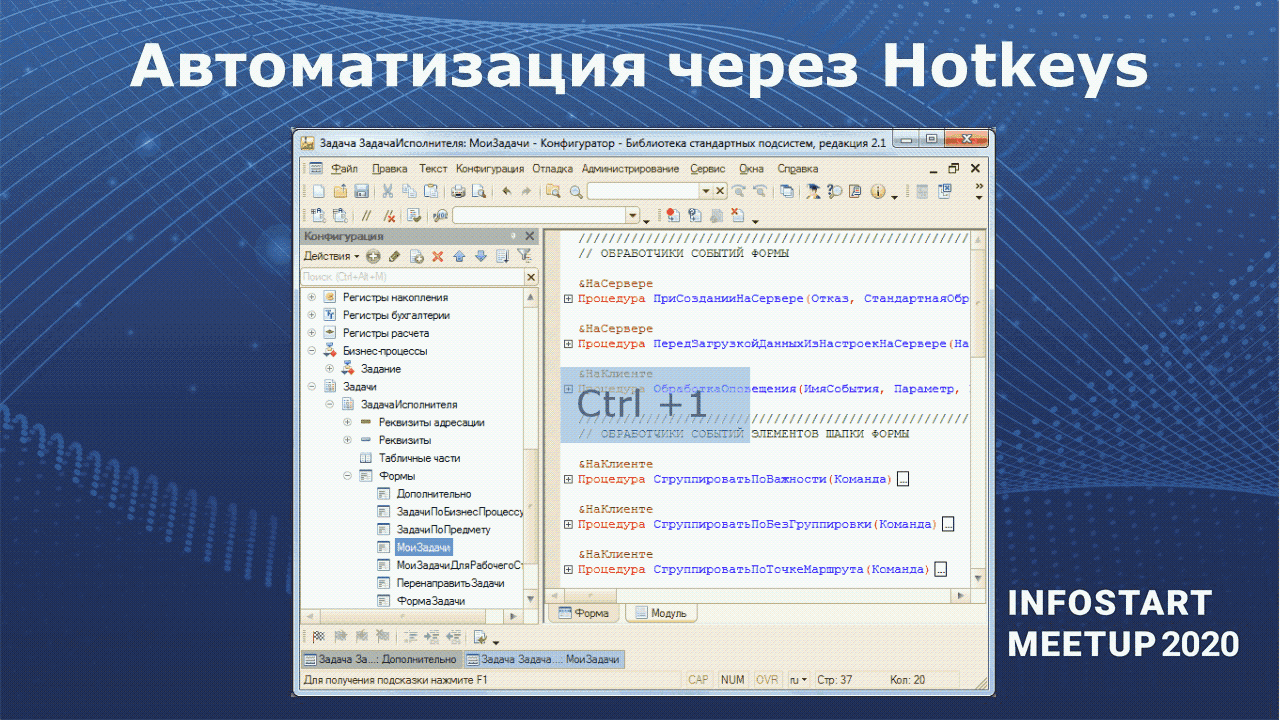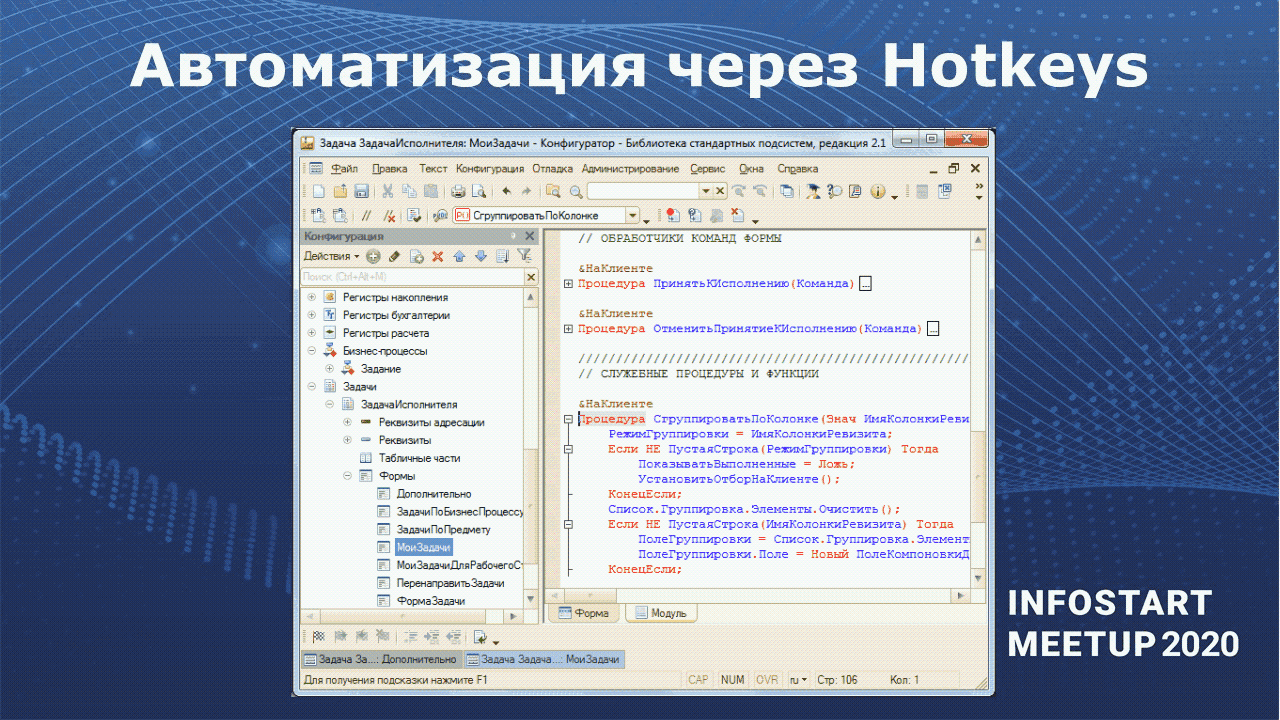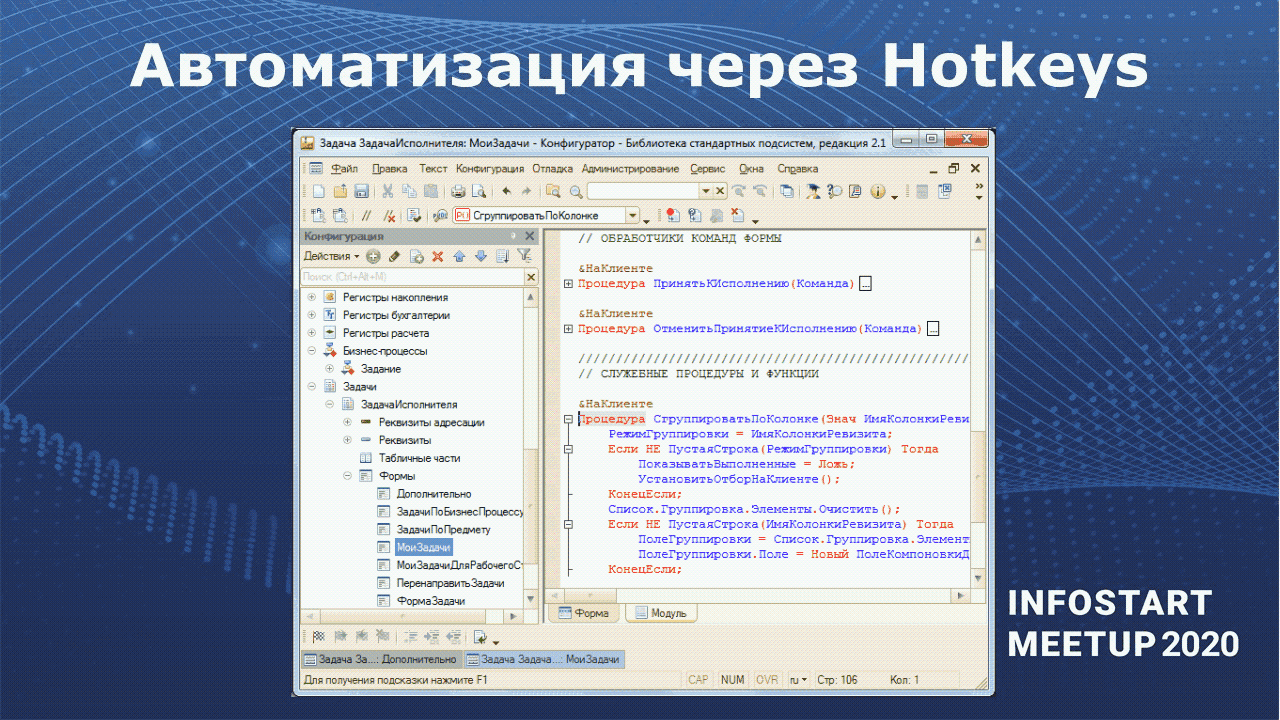
И последняя возможность SmartConfigurator – это хоткеи.
Вы можете назначить свои хоткеи на какие-то действия в конфигураторе. Например, на слайде показано, как через Ctrl+1 вызываются методы текущего модуля.
Расширение возможностей 1C:EDT

Перейдем к 1С:EDT.
1С:EDT – это такой новый конфигуратор от 1С. Помимо встроенных проверок кода (их порядка 94 штук), умеет форматировать код.
Важная особенность – для 1С:EDT можно писать собственные плагины либо использовать какие-то готовые.
Я хочу более подробно рассказать о конкретном плагине, который называется BSL LS validator.
BSL LS Validator
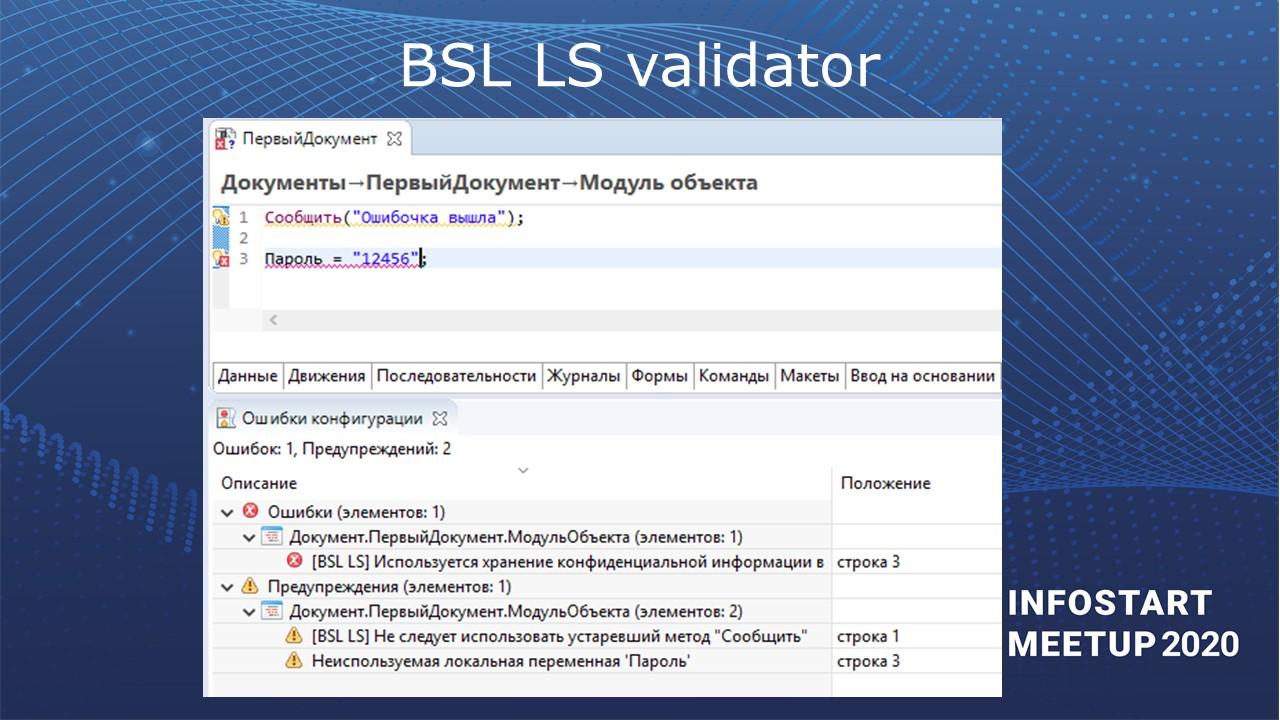
Плагин BSL LS Validator также использует проект BSL LS, чтобы анализировать код на замечания и делать быстрые исправления.
Давайте покажу вам, как это выглядит в EDT.
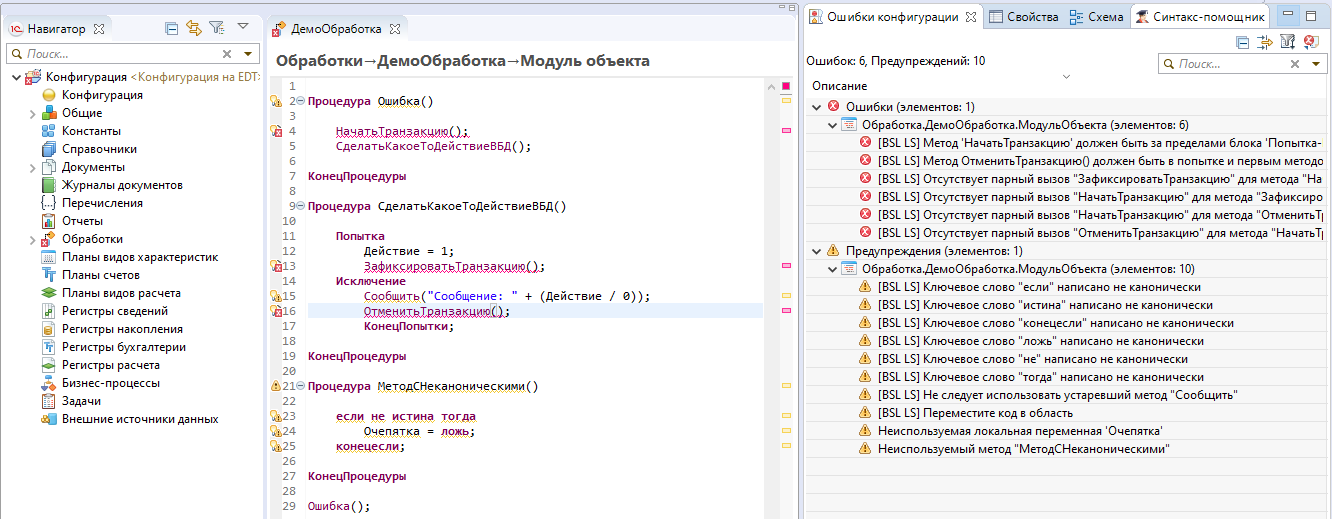
Смотрите, вот у меня есть подготовленный модуль, в нем есть какие-то недочеты, 1С:EDT как елка светится, показывает в модуле какие-то ошибки.
Здесь есть процедура Ошибка(), где вызывается «НачатьТранзакцию()» и дальше переход в какой-то метод, в котором делается Попытка – Исключение – ОтменитьТранзакцию().
EDT нас предупреждает, что:
-
для НачатьТранзакцию() нет парных вызовов ЗафиксироватьТранзакцию() и ОтменитьТранзакцию() – понятно, что это чревато;
-
также подсвечено красным, что ОтменитьТранзакцию не идет первым после исключения – в сообщении у меня происходит деление на ноль, все вылетит, и транзакция не отменится;
-
и EDT информирует нас о коде, который написан не канонически – ключевые слова должны быть написаны заглавными буквами.
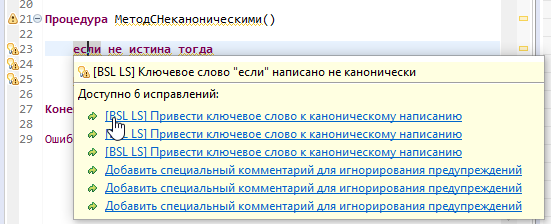
При нажатии на строку с ошибкой доступны быстрые исправления.
Тестирование

Следующая практика – это тестирование.
Тема тестирования в 1С очень «заезжена» за много лет. Я не буду сейчас показывать пирамиду тестирования. Хочу выделить только некоторые инструменты, которые помогут вам сделать ваше решение более качественным. Это:
-
«1С:Сценарное тестирование 3», которое входит в состав продукта КИП;
Предоставляются разнообразные виды тестов – поведенческие (сценарные), модульные, дымовые и т.д. Очень много готовой функциональности, которую вы можете использовать у себя и на основе этого писать тесты.
Документирование

Следующая практика – это документирование. Документирование помогает писать более качественный код и тратить на это меньше времени.
-
Документировать можно подсистемы, модули и архитектуру в целом.
-
Можно формировать техническую документацию.
-
И можно формировать проектную документацию.
AutoDocGen
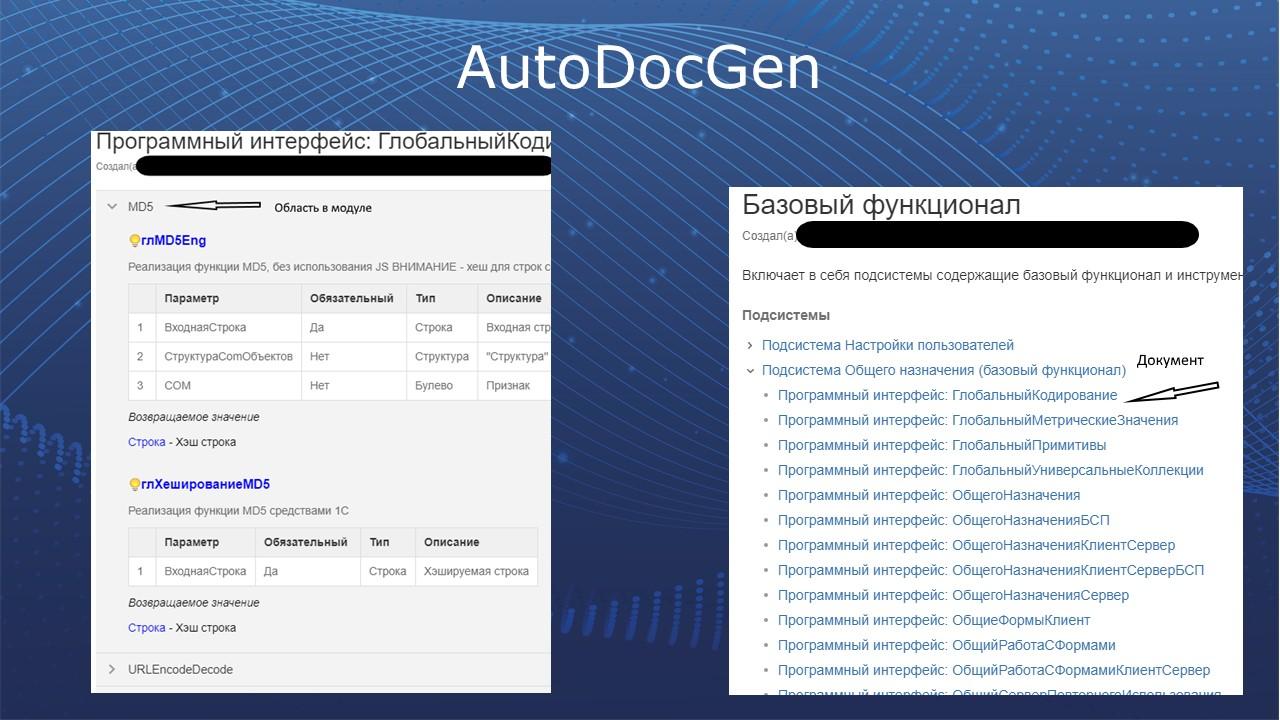
Если говорить конкретно об инструментах документирования, то из инструментов, которые позволяют автоматически сгенерировать описание методов ваших модулей, есть AutoDocGen – это OpenSource-проект, написанный на OneScript, который позволяет на основании исходных данных конфигурации формировать документации в формате HTML, MD, и даже сразу автоматически отправлять документацию в Confluence. На слайде показан скриншот сформированной документации.
Swagger
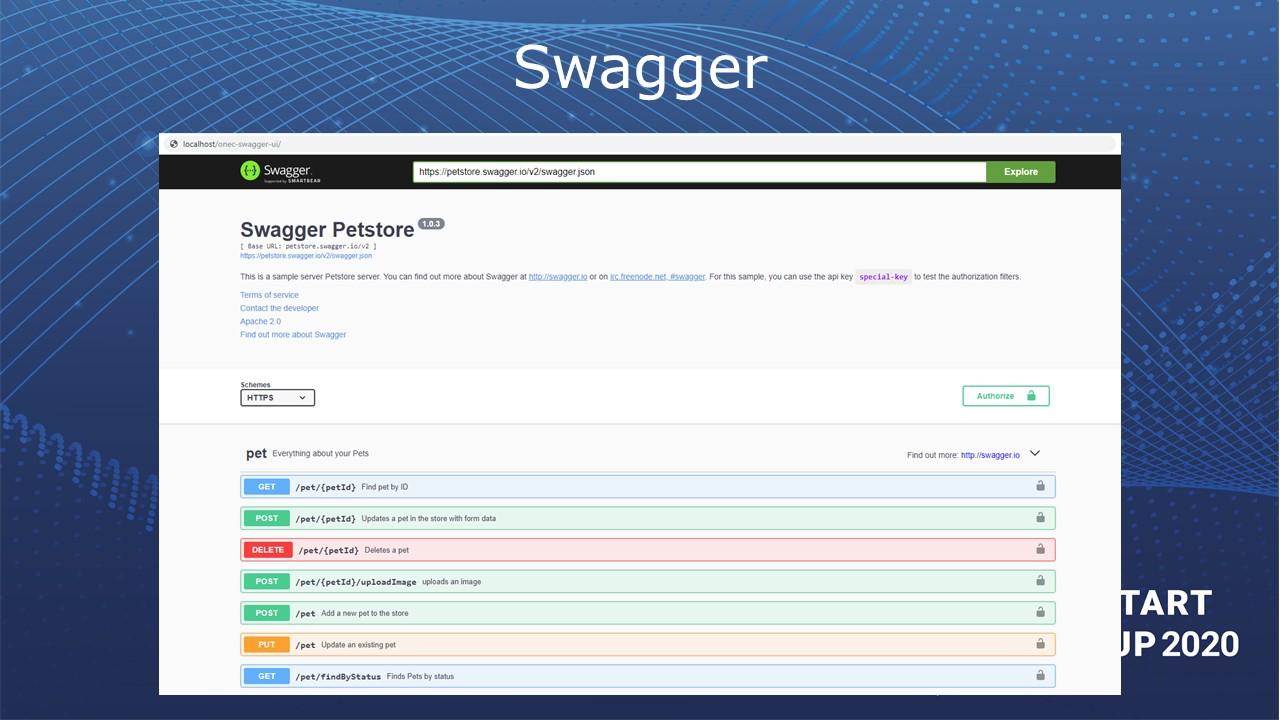
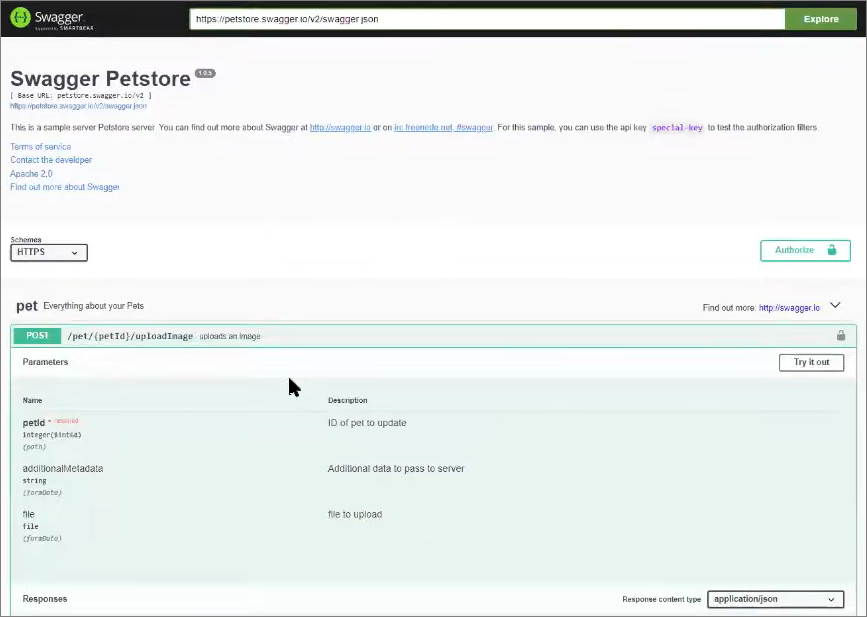
Еще есть инструмент, который называется Swagger. Это инструмент, который реализует спецификацию по описанию REST-API.
Например, HTTP-сервис в 1С предоставляет REST-API, и с помощью Swagger можно составлять документацию по HTTP-методам 1С-ных сервисов.
Позднее я более подробно покажу, как Swagger работает.
Статический анализ кода

Следующая область инструментов – это статический анализ кода.
Статический анализ кода – это анализ кода без его реального выполнения. К платформам анализа кода можно отнести:
-
сам конфигуратор 1С, потому что внутри есть расширенная проверка конфигурации;
-
SonarQube;
-
и «1С:Автоматизированную проверку конфигураций».
Стандартная проверка конфигурации
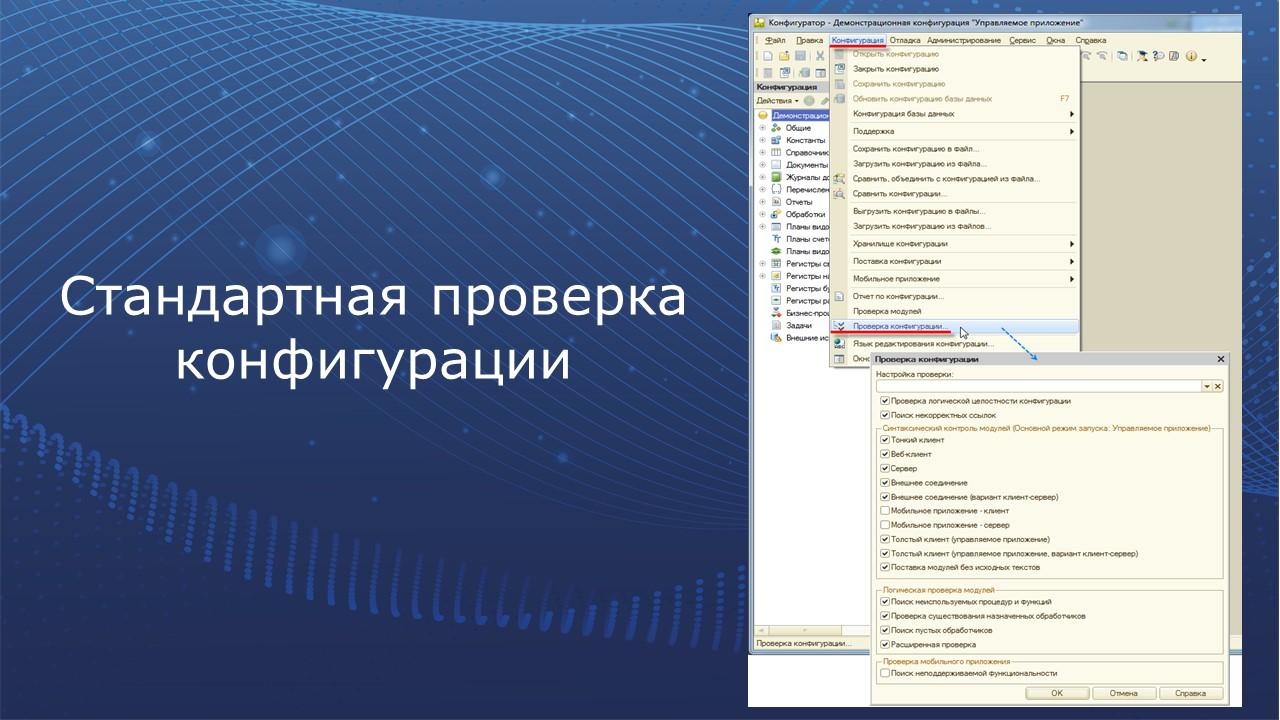
Механизм стандартной проверки конфигурации позволяет выявить ошибки, которые с одной стороны являются не критичными, но с другой стороны, могут вызвать ошибки при работе в определенных режимах. Также могут снизить скорость работы прикладного решения.
Механизм может проводить:
-
проверку логической целостности и поиск некорректных ссылок;
-
контроль синтаксиса модулей в различных режимах, в том числе, в режиме эмуляции сервера либо внешнего соединения;
-
поиск неиспользуемых локальных процедур и функций;
-
поиск пустых обработчиков;
-
и поиск неподдерживаемой функциональности – это очень актуально для мобильных приложений.
1С:АПК
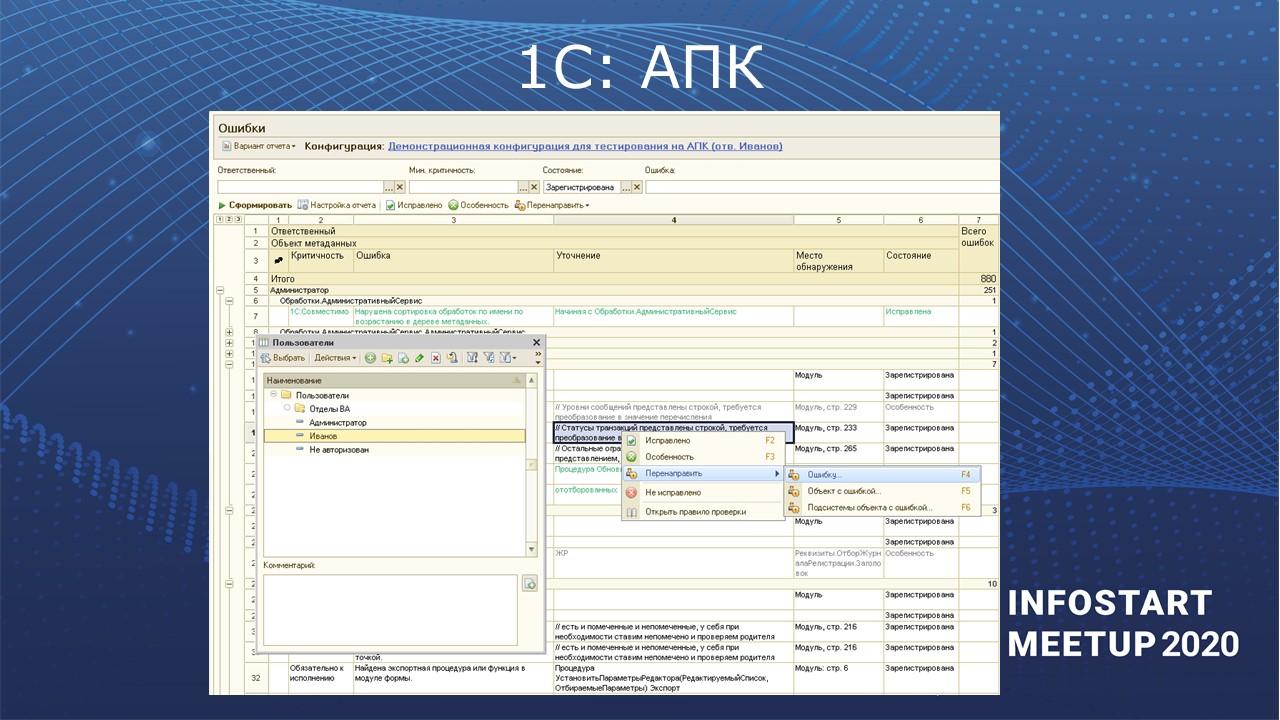
Дальше – «1С:Автоматизированная проверка конфигурации» (1С:АПК). Она позволяет проверять решения 1С на соответствие стандартам разработки 1С:Совместимо и писать какие-то свои проверки.
Решение не плохое, но на мой взгляд, оно уступает платформе SonarQube в своей удобности.
SonarQube

SonarQube – это еще одна платформа для статического анализа кода. У нее есть веб-интерфейс и очень много закладок для анализа и контроля.
Если установить плагин SonarQube 1C (BSL) Community Plugin, то на сервере SonarQube можно анализировать и код 1С.
Автоматизация на Jenkins

Теперь я хочу вам рассказать про автоматизацию всех этих действий, которую можно организовать с помощью Jenkins.
Если кто не знает, Jenkins – это сервер сборок. С его помощью можно настроить запуск каких-то действий, чтобы они при определенных условиях выполнялись автоматически. Как минимум, можно:
-
Генерировать документацию.
-
Тестировать код – запускать юнит-тесты, поведенческие тесты, дымовые тесты.
-
Проверять код статическими анализаторами.
Для вас я подготовил пример и разместил его в репозитории GitHub по адресу https://github.com/otymko/infostart2020-nsk-example
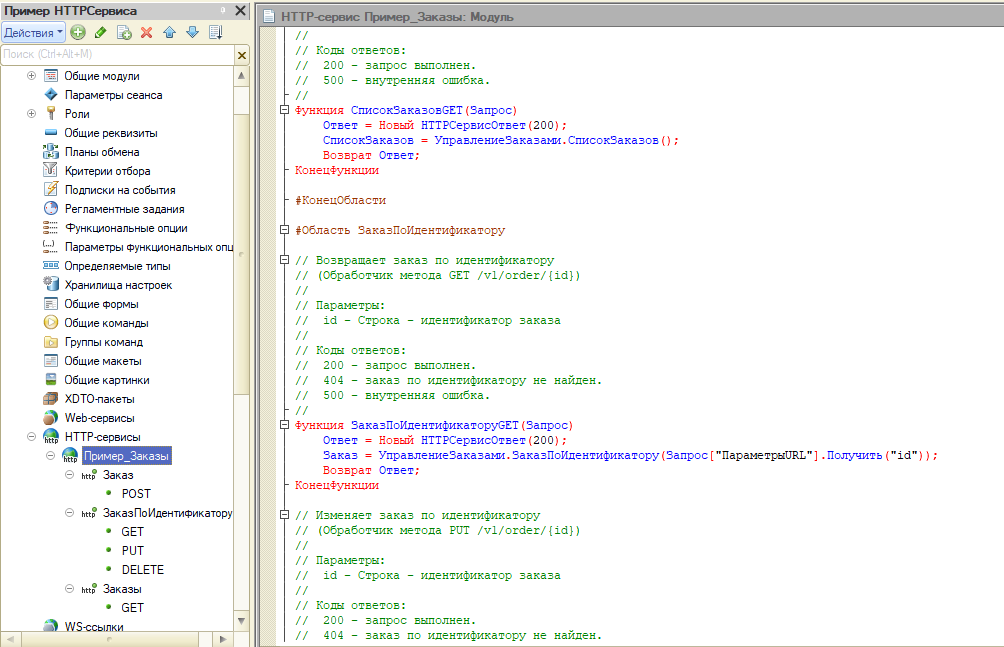
В этом проекте содержится код расширения, которое реализует HTTP-сервис с определенными методами.
-
В модуле этого HTTP-сервиса описана функциональность всех методов с помощью комментариев, оформленных по стандарту.
-
Для проверки работоспособности расширения написан юнит-тест.
-
И мы хотим контролировать качество этого продукта, чтобы тратить на его дальнейшую поддержку меньше времени.
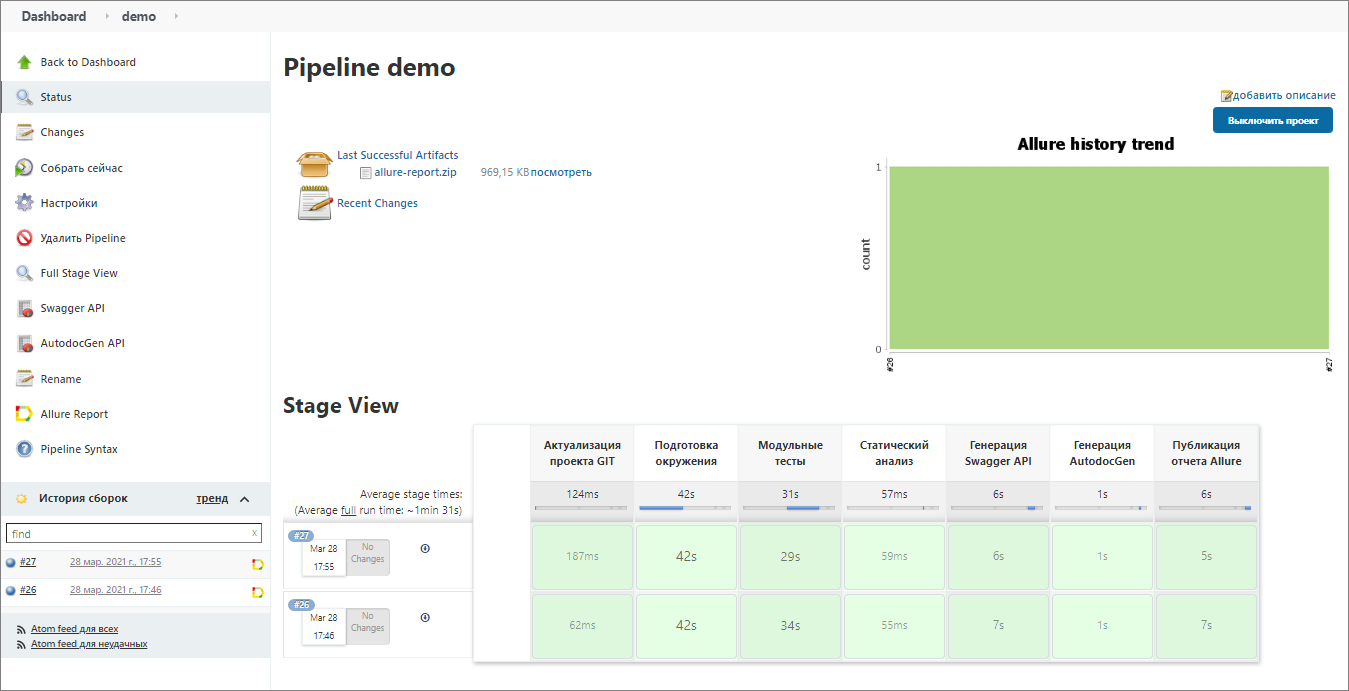
Для этой цели у нас в Jenkins создана задача demo с видом pipeline.
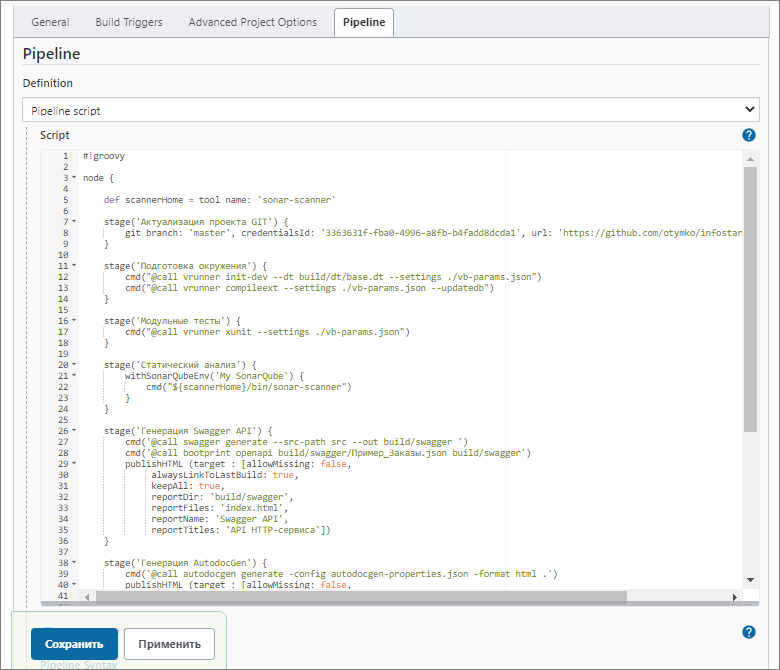
В настройках этой задачи указан определенный pipeline-скрипт.

Я нажму кнопку «Собрать сейчас» и расскажу вам, что этот скрипт делает:
-
На первом шаге он берет с GitHub текущую версию вашего проекта.
-
Следующим шагом он подготавливает окружение. По ходу подготовки окружения, он создает файловую базу и загружает в нее из исходников расширение, которое я только что показывал.
-
Затем запускает модульные тесты – есть один маленький модульный тест, который написан для демонстрации.
-
Потом запускает статический анализ кода – отправляет результаты в SonarQube, который я на компьютере тоже для демонстрации поднял.
-
Далее –с помощью Swagger-а генерирует документацию, которая описывает наш HTTP-сервис.
-
Потом – генерирует документацию модулей этого расширения.
-
И публикует результаты тестирования в Allure, в которой можно все это смотреть и анализировать.
Собирается этот пайплайн порядка двух минут.
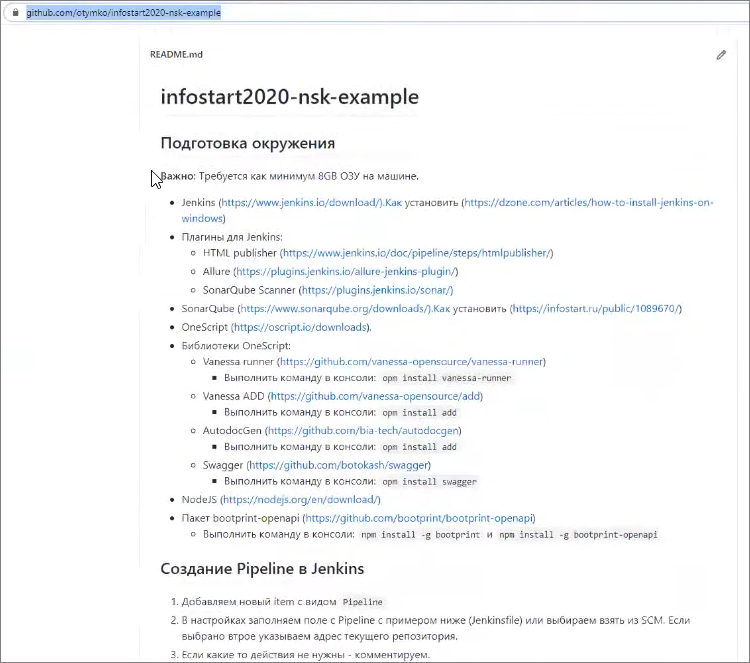
В репозитории на GitHub есть:
-
краткое описание – что вам может потребоваться, чтобы построить у себя такую же сборочную линию.
-
кратко описан пайплайн и даны ссылки на статьи на Инфостарте, где описано, как эту сборочную линию настраивать – нужно будет немного самим поразбираться.
-
и приведен текст Jenkinsfile с комментариями – если вы не хотите что-то пробовать прямо сейчас, вы можете эти блоки закомментировать и запустить.
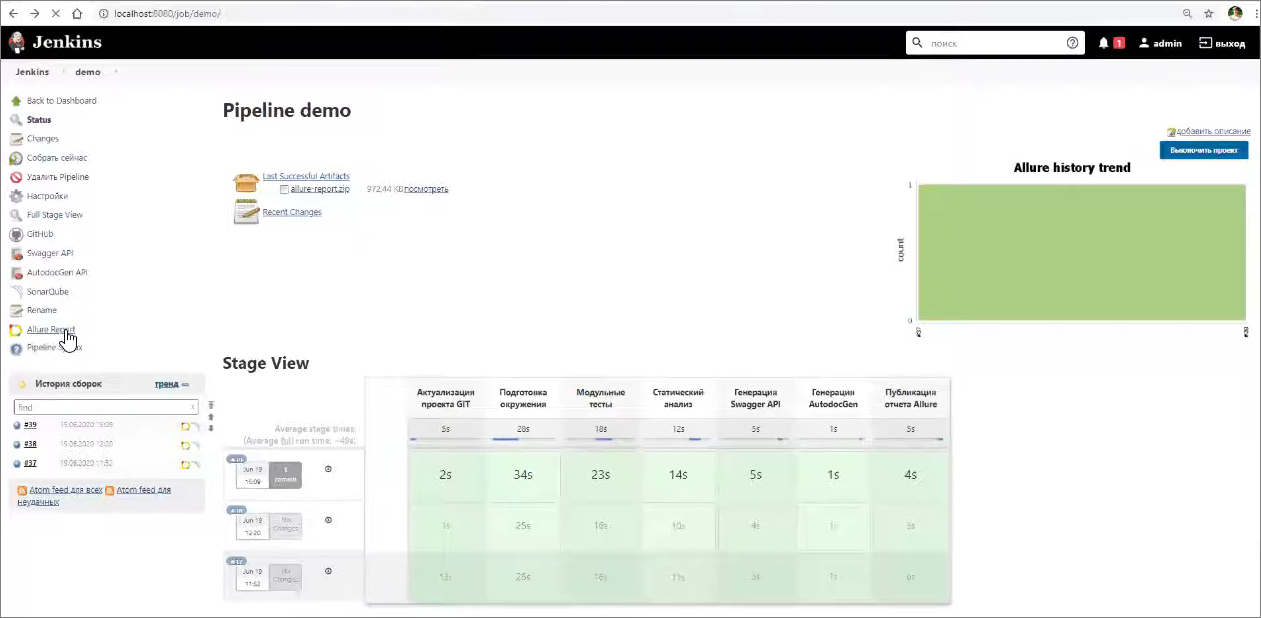
Пайплайн собрался. Мы можем посмотреть результаты прохождения модульных тестов – в меню слева переходим к Allure.
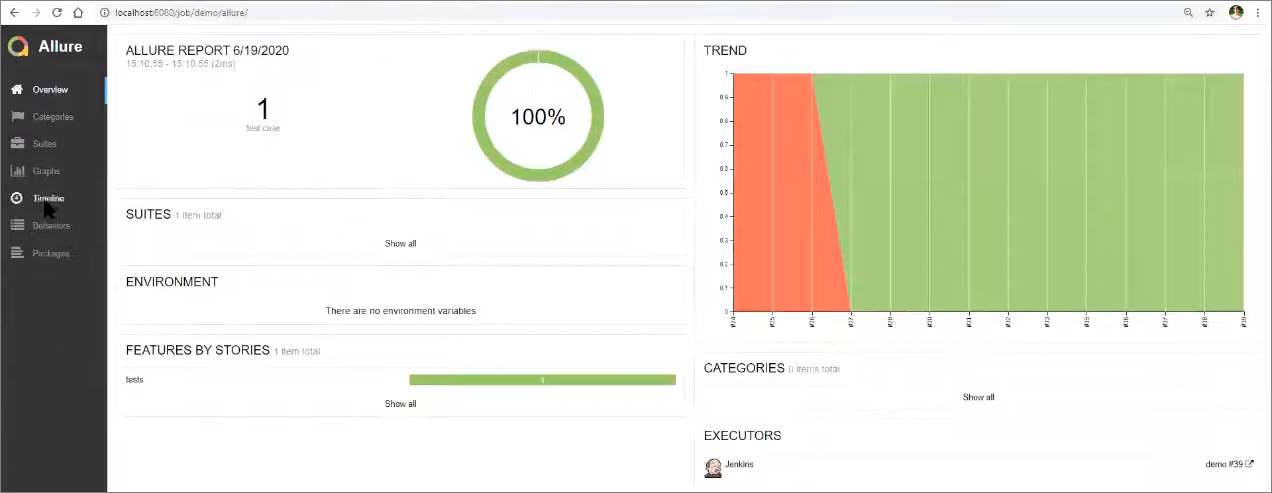
Здесь видно, что сейчас выполнился один тест, который прошел успешно.
Справа на графике показано, что накануне тест падал, потом я его наладил и тест стал проходить.
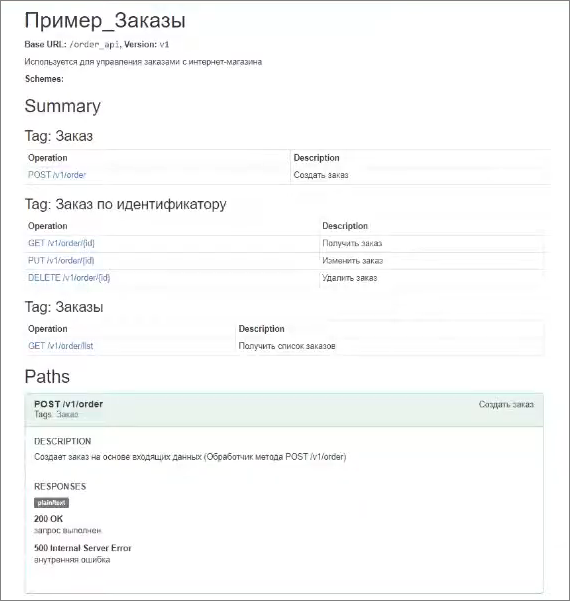
Через Swagger сгенерировалось описание API нашего HTTP-сервиса. Это очень удобно, если вам нужно интегрироваться по HTTP с другим отделом или с другой компанией. Генерируете такую документацию и отправляете – интегрируйтесь с нами, пожалуйста.
Я считаю, что возможность предоставить такую документацию другой команде экономит для всех время и деньги.
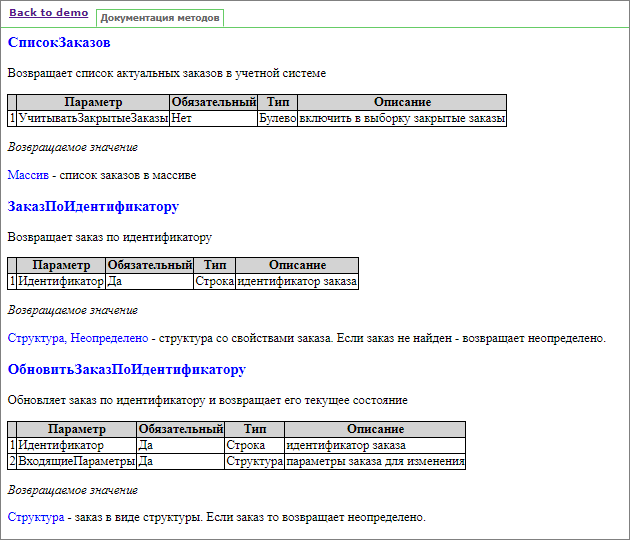
Также сгенерировалась документация общего модуля «Управление заказами», который был в расширении. Здесь видно каждый метод – что он делает и его параметры. Все это в каком-то удобном виде. В примере показано, как описание формируется в HTML, можно формировать в MD – это еще удобнее.
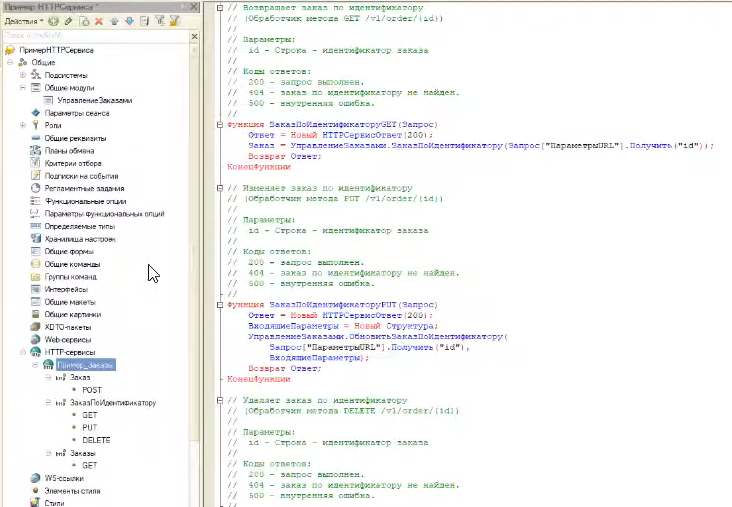
Это описание формируется автоматически за счет того, что комментарии к методам этого модуля оформлены по стандарту – вот так код модуля «Управление заказами» выглядит в конфигураторе.
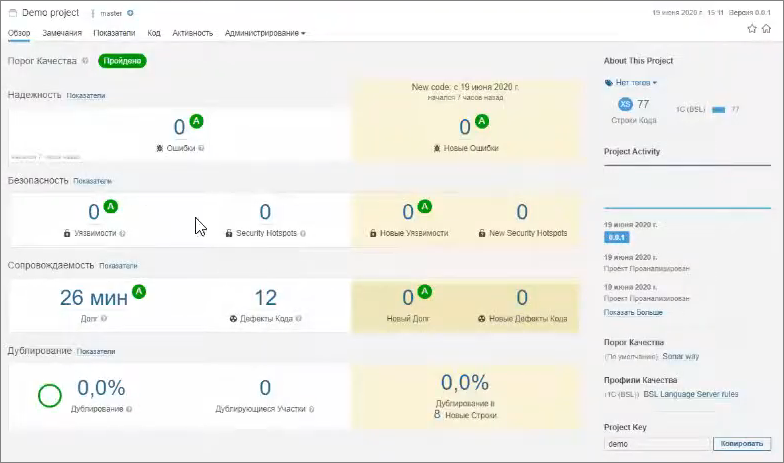
Также я могу перейти SonarQube и посмотреть, как у нас выполнился статический анализ кода.
Здесь видно, что проект проанализировался – он не идеальный, есть какие-то дефекты кода.
Все эти замечания можно просмотреть.

Допустим, в коде используется «магическое число», которое не понятно, что обозначает.
По сравнению с АПК в SonarQube можно в рамках самого кода путешествовать, смотреть, что здесь происходит – можно посмотреть сводку по файлу.
А на главной странице проекта можно отслеживать тенденцию изменения показателей.
По поводу Swagger – есть два варианта использования.
-
Вы можете развернуть серверное приложение Swagger-UI у себя по инструкции, и генерировать для него спецификации по своему проекту.
-
Либо вы можете использовать Swagger через Jenkins, как было показано ранее.
Весь необходимый код, чтобы воспроизвести этот пример, размещен в репозитории на GitHub. Если кто-то хочет настроить у себя аналогичную сборочную линию – может пользоваться этими файлами, как шаблоном.
Поделюсь опытом, что какие приемы автоматизации разработки и тестирования используются у нас в компании:
-
Мы автоматически выгружаем скриптами внешние обработки и отчеты в Git и там их версионируем.
-
Мы используем версионирование правил обмена КД2 – раскладываем большой XML-файл правил на мелкие составляющие и их версионируем. Очень удобно смотреть – кто что изменил и когда.
-
Также у нас положено начало написанию модульных тестов. Есть пара проектов, в которых уже пишутся модульные тесты, прогоняются автоматически через Jenkins перед внедрением.
-
И у нас используется документирование подсистем. Есть пара наших внутренних подсистем, которые документируются с помощью AutoDocGen. Эту документацию удобно передавать для изучения, чтобы вводить кого-то в курс дела.
Итоги

Используя хотя бы минимум практик, о которых я рассказал, можно:
-
начать экономить время на рутинных действиях при разработке;
-
допускать меньше ошибок в коде – либо через PhoenixBSL смотреть ошибки до SonarQube в конфигураторе, либо в SonarQube смотреть текущие ошибки, которые вы допускаете, и их исправлять.
-
в будущем на основании всех этих инструментов вы научитесь писать более правильный, более стабильный код – соответственно, бизнес будет экономить деньги;
-
кроме того, можно оценивать качество проектов в «попугаях». SonarQube показывает текущую сводку и тенденцию изменения качества проекта – это удобная вещь для менеджеров, чтобы оценить, что у нас в конфигурации 1С творится.
Полезные ссылки
Как я и обещал, привожу ссылки, о которых упоминал в докладе.
Первая порция ссылок – инструменты разработки:
-
Демо-репозиторий – https://github.com/otymko/infostart2020-nsk-example
-
PhoenixBSL – https://github.com/otymko/phoenixbsl
-
SmartConfigurator – https://github.com/ret-Phoenix/SmartConfigurator
-
TurboConf – https://turboconf.ru/
-
Снегопат – https://snegopat.ru/
-
dt.bslls.validator – https://github.com/DoublesunRUS/ru.capralow.dt.bslls.validator
-
AutodocGen – https://github.com/bia-technologies/autodocgen
-
Библиотека для OneScript – https://github.com/oscript-library/swagger
-
Swagger – https://swagger.io/
Вторая порция ссылок – инструменты тестирования и проверки качества кода:
-
Сценарное тестирование – https://v8.1c.ru/tekhnologii/tekhnologii-krupnykh-vnedreniy/korporativnyy-instrumentalnyy-paket/
-
Vanessa Automation – https://github.com/Pr-Mex/vanessa-automation
-
Vanessa ADD – https://github.com/vanessa-opensource/add
-
1С:Автоматизированная проверка конфигураций – https://v8.1c.ru/tekhnologii/1s-avtomatizirovannaya-proverka-konfiguratsiy/
-
SonarQube 1C (BSL) Community Plugin – https://github.com/1c-syntax/sonar-bsl-plugin-community
-
SonarQube – https://www.sonarqube.org/
На этом все. Надеюсь, кому-то это окажется полезным.
Вопросы:
Если заказчик не думает о качестве кода и иногда выбирает дешевых исполнителей, как переубедить его выбрать исполнителя качественнее и дороже?
В данном случае все зависит от объема компании. Если эта компания маленькая – ей в любом случае не получится это продать, потому что они не смогут уложиться в бюджет с учетом проверки качества. Если говорить о компаниях побольше – средних и крупных – тут уже дело в убеждениях. Когда у компании распределенная система из 300 магазинов, то в случае маленькой оплошности в обмене вся сеть встанет. Сколько вы денег потратите на ее восстановление – непонятно, зависит от критичности ошибки. Но если вы эту проблему уже исправили, и вам нужно не допустить ее возникновение заново – вы напишете тест и потом сэкономите деньги на том, что одно и то же у вас два раза не случится. Бизнесу можно доказать необходимость проверок только на примерах каких-то ошибок либо простоя. Либо для некоторых компаний это вопрос престижа – мы контролируем качество. Соответственно, стоимость компании за счет этого растет.
Понятно, что главное – напугать бизнес последствиями дешевой некачественной разработки. Но как правило, финансисты все равно выберут деньги. Понятно, что ИТ-шники всегда выберут качество, но ИТ-шники не всегда владельцы бюджета. С другой стороны, когда ты пугаешь некачественным подрядчиком, тебе бизнес может сказать: «я готов платить в два раза больше, но не дай Бог хоть одна ошибка – ты вернешь мне все деньги». Мы часто с этим, как подрядчики, встречаемся: «Вы же эксперты, как это вы ошиблись? Вы телепатически должны знать все наши недоговорки ТЗ и недомолвки на совещаниях. Вы не имеете право на ошибку». Как противостоять такому подходу?
С одной стороны, есть проблемы, которые в любом случае по закону Мерфи когда-то случатся. Соответственно, тестирование дает возможность этой ошибке не повториться. То же самое, что мы можем в логике программы поставить защиту от дурака, ограничить пользователя, чтобы он не совершал ошибки – так же и с кодом. Если у вас произошла какая-то проблема, мы бизнесу гарантируем, что эта ошибка больше не повторится. По поводу того, что бизнес от нас требует заранее предугадывать все недочеты, тут тоже больше работа для РП-шника, который может объяснить, что это потом будет проще сопровождать, потому что, если бизнес не должен работать только на внедрение. Мы-то внедрили, посопровождали какое-то время и ушли. А потом все это остается на плечах бизнеса. И они будут тратить денег намного больше, чем они тратили до этого – в любом случае. Мне кажется, нужно индивидуально подходить к каждому и объяснять, что и как.
Как Swagger натянуть на JSON по RMQ?
Если говорить, по порядку, Swagger – это спецификация описания REST API. RMQ – это просто транспорт из одной точки в другую. Если вопрос в том, как описать сервис RMQ – то я не отвечу, потому что нужно смотреть сам проект RMQ, где описывается его REST-сервер, чтобы с ним общаться. Если мы говорим про решение внутри 1С, то есть готовый скрипт, который формирует JSON-файл, потом отправляет его через HTTP по RMQ в то место, где у вас размещается сервер со Swagger, который через UI отображает ваши API. И там будет подхватываться по определенной ссылке.
Вы выгружаете конфигурацию в Git через «Выгрузить конфигурацию в файлы?»
Если говорить про хранилище, выгрузка автоматизирована – все выгружается через GitSync, потому что люди не должны на это тратить время. Если мы говорим про уже какие-то свои разработки. У меня написаны скрипты, чтобы конфигурации, которые не прикреплены к хранилищу, при определенном триггере выгружались в файлики, чтобы я с ними что-то мог сделать – открыть в Visual Studio Code, либо сгенерировать документацию, либо в том же самом SonarQube это все проверить. Для каких-то своих действий это можно сделать ручками или с помощью скрипта, а для перевода истории хранилища в Git – это все можно автоматизировать. Например, через GitSync или GitConverter.
Сколько времени уходит на разбор проблем, выявленных инструментами проверок?
Если мы говорим про проблемы, которые мы выявили для себя через PhoenixBSL, это в зависимости от их критичности. Если я зашел в модуль, увидел, что там непарное использование транзакций или неправильно в попытке указано ОтменитьТранзакцию, это решается в рамках текущего времени. Единственное, что тут нужно закладывать время на тестирование. Потому что вы поправили, должны еще проверить. А еще лучше – вы должны написать тест, что у вас ничего не упало и все хорошо. Если говорить про SonarQube – тут время не оценить. Это работа ведется непрерывно. Если у вас в команде 5-10 человек – это еще можно сдержать. Если у вас команда больше, а если еще у нас несколько команд, то это работа ведется только непрерывно, ведется определенными людьми, которые это все анализируют. А еще лучше находить и исправлять ошибки при код-ревью, до того, как это попало в SonarQube. Если это уже попало в SonarQube – это значит, этот код уже помещен в хранилище, значит, мы его уже скоро внедрим. Поэтому люди должны заранее это еще посмотреть. Ведущие разработчики должны проанализировать, что у вас там написано. Но бывает часто – рук не хватает на ревью кода.
Получается, для проверки нужен постоянный человеческий ресурс? Автоматическая проверка ничего не решит?
Человек нужен в любом случае, но в SonarQube есть интересная возможность – рассылка отчета. В проекте можно подписаться на замечания, которые назначены тебе. И как только SonarQube что-то твое проанализировал, тебе приходит «письмо счастья». А еще такое же письмо приходит релиз-инженеру, который может увидеть, что у тебя там какие-то критические ошибки, и начинает тебя мучить, пока ты это не исправишь.
Как ускорить SonarQube? Сейчас фоновое задание по обработке УПП отрабатывает за 2.5 часа.
Вы можете анализировать полностью все УПП, либо вы хотите анализировать только свой код. Вы можете ускорить работу SonarQube за счет отключения анализа того, что стоит на замочке. Потом вам нужно понимать, на чем у вас просадка. Вы можете этот проект у себя на компьютере развернуть, и через BSL LS запустить анализ и посмотреть – сколько времени этот анализ занимает у вас. Может быть, проблема с сервером, на котором SonarQube развернут. Может быть, там памяти не хватает. Можно тоже упереться в память. Либо она вообще упадет, не проанализируется. И последнее – не анализируйте регламентные отчеты. Они вам не нужны. Если вы, конечно, их не дорабатываете. Они очень много занимают файлов и очень много времени тратится, чтобы их проанализировать. И нужно правильно настроить конфиг анализа проекта. Исключить xml-файлы, анализировать только файлы с расширением bsl. И пользоваться последними релизами плагина, который с каждым разом становится все быстрее. Это даст вам экономию времени. Если мы где-то развернули SonarQube, обязательно нужно использовать реальную СУБД – MS SQL или PostgreSQL, не встроенную. Если вы используете встроенную базу, вы потом не обновитесь. Есть костыльные способы все это перевести в нормальную базу данных и разместить на сервер, но хапнуть горя, пока это делается. Мы используем PostgreSQL.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Новосибирск.Online.

Вступайте в нашу телеграмм-группу Инфостарт