






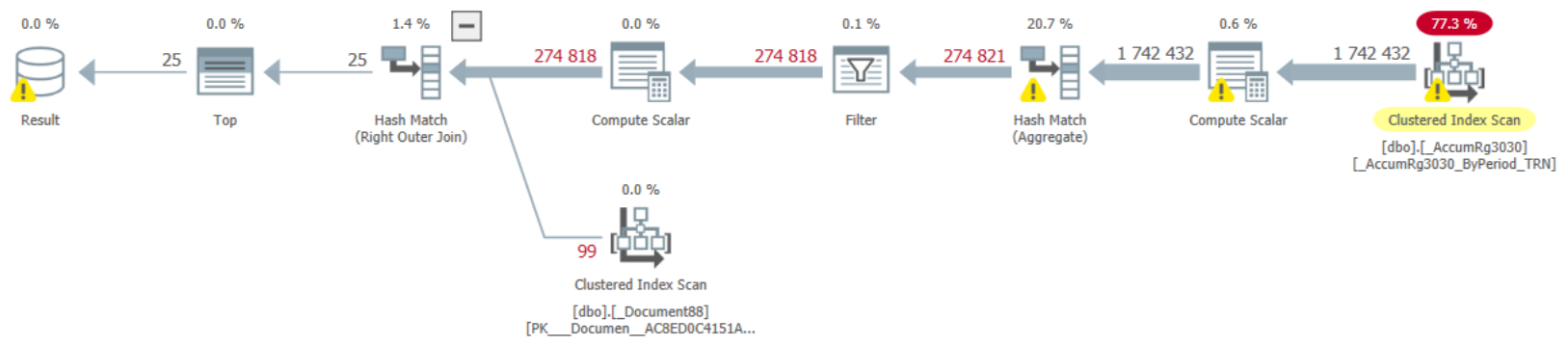


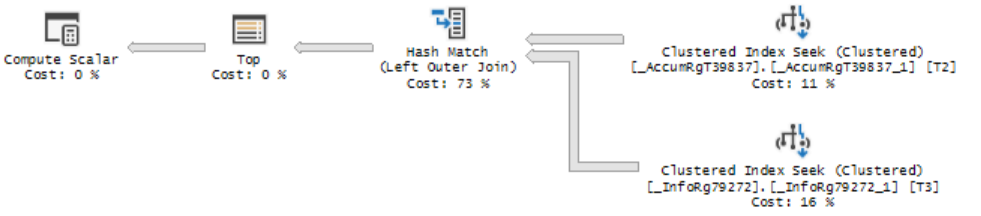


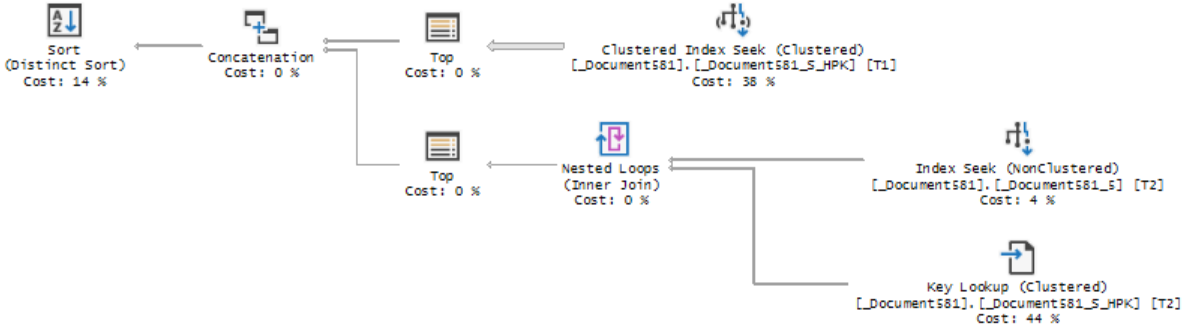









































Это продолжение статьи про распространенные ошибки разработчиков, в данном случае посмотрим, как выглядит обработка рассмотренных в этой статье "запросов" сервером MS SQL запросов из 1С. Также рассмотрим некоторые другие интересные ситуации.
Мы не ставим целью описать все возможные нюансы и особенности поведения сервера, сделать из вас профессионала (для этого требуется гораздо больше времени и больше различных источников информации).
Мы хотим показать, как выглядит оптимизация запросов из статьи о распространенных ошибках разработчиков с точки зрения SQL сервера.
Дополнительно мы надеемся, что по результатам прочтения статьи вы сможете:
- Настроить и подключить профайлер
- Получить/увидеть схему плана запроса, технологические данные - длительность (duration), нагрузку на CPU и др.
- Сделать некоторую "грубую" оценку - оценить: стало лучше, не изменилось или хуже (в большинстве случаев этого достаточно).
Мы ориентируемся на специалистов начального и среднего уровня. Возможно, даже господа сеньоры смогут почерпнуть для себя что-то новое, по опыту общения с коллегами до публикации такие ситуации имели место.
I) Инструменты и подготовка.
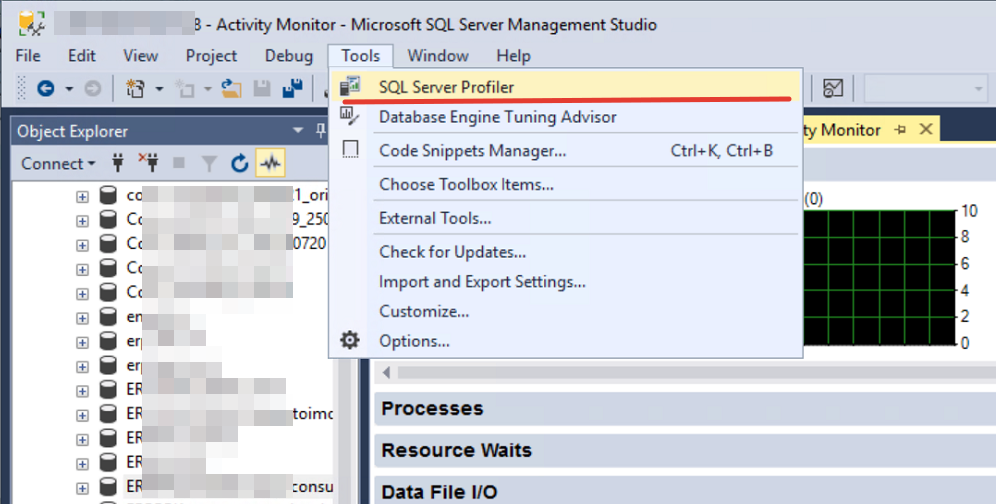
SQL Server Profiler вам потребуется, чтобы понять, почему может тормозить запрос, проверить результаты оптимизации, когда анализа кода на языке 1С недостаточно. В большинстве случаев результирующий запрос выглядит монстром (почти 95% из-за RLS), и понять там что-либо можно с трудом. В этом случае вам может помочь SQL Sentry Plan Explorer, который поможет выделить самые жирные цепочки. Статей в интернете и на текущем ресурсе по этой тематике много или если вы уже знаете, как с ним обращаться, листайте дальше. Но для тех, кто не знает, это будет хорошим кратким описанием.
1. Начинаем и запускаем SQL Server Profiler.
1.1 Открываем Microsoft SQL Server Management Studio
1.2 Запускаем SQL Server Profiler и подключаемся к базе данных (вводим адрес, логин и пароль).
2. Настраиваем трассировку (события).
В открывшемся приложении сразу будет открыта форма настройки подключения. Если это не так, то нажмите "New trace ..." (Новая трассировка) или "Ctrl+N".
2.1 На вкладке главное (General) смотрим настройки и сохраняем как шаблон, если нужно.
2.2 Переходим на вкладку события (Events Selection) и выполняем настройку захвата интересующих нас событий. Из выбранных по умолчанию оставляем RPC.Complated, остальные отключаем.
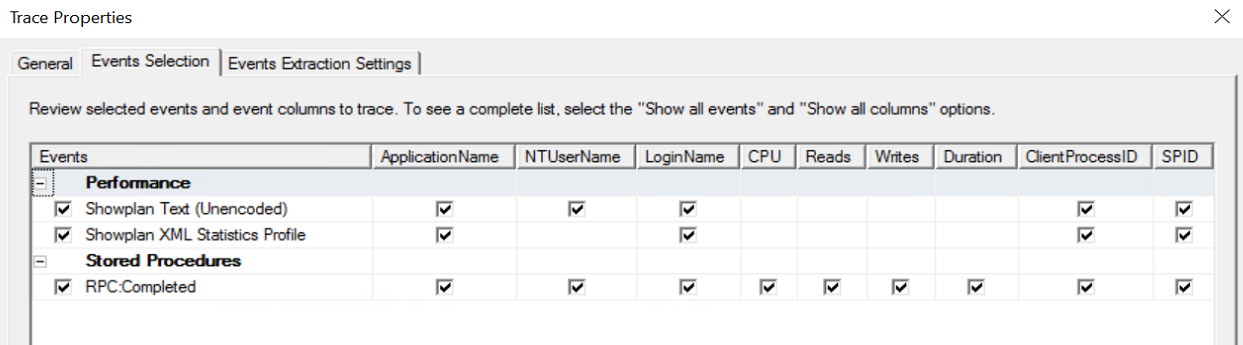
2.3 Добавляем еще следующие события из блока Performance:
- Show plan XML Statistic Profile- схема плана запросов с данными статистики
- ShowPlan Text (Unencoded) - текстовое представление запроса (не обязательно)
3 Ставим отборы в профайлере
3.1 Ставим отбор по базе данных. Устанавливаем фильтр на имя базы данных DatabaseName. Если не видно, то нажмите флаг "Show all columns" и выберите требуемую колонку.
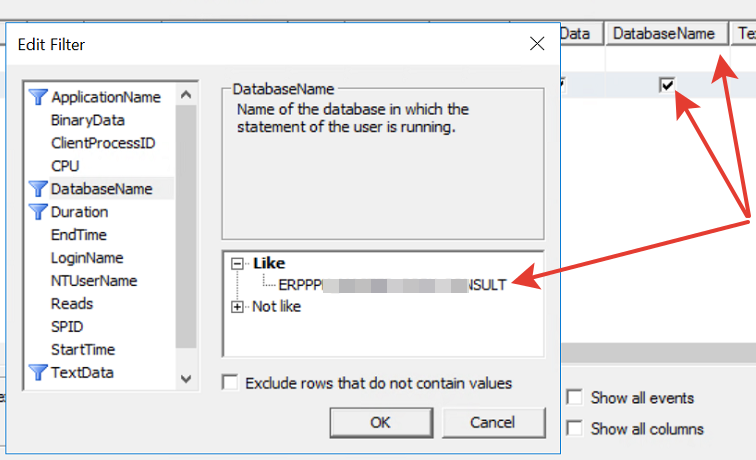
3.2. Ставим отбор по длительности Duration. Этот параметр вы можете поставить, чтобы искать длительные запросы или отсеять всякие мелкие служебные. При анализе нужно руководствоваться соображениями - чем меньше этот показатель, тем лучше. Фактически - это время выполнения запроса.

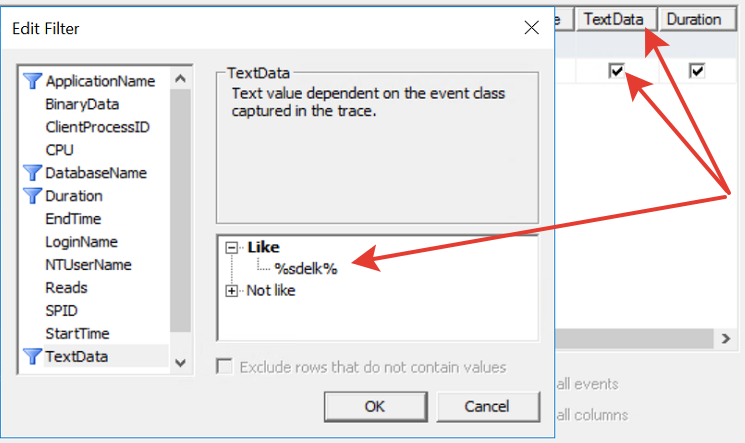
3.3 Ставим отбор по тексту. Устанавливаем по слову в тексте TextData. Будем искать по вхождению некоторого ключа. Обязательно поместите его в "%" (т.е. вхождение по подобно). Подставлять ключевое слово в запрос 1С и искать это ключевое слово в запросе в профайлере - это довольно популярный и удобный подход, и мы будем его использовать.
3.4. Дополнительные информационные поля. Добавляем еще поля
- RowCount – число записей, которые возвращает сервер.
- Reads - количество чтений, сколько данных было прочитано.
- Writes - количество записей, что было записано в нашем случае во временные таблицы.
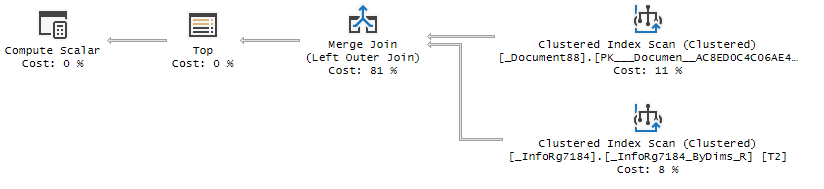
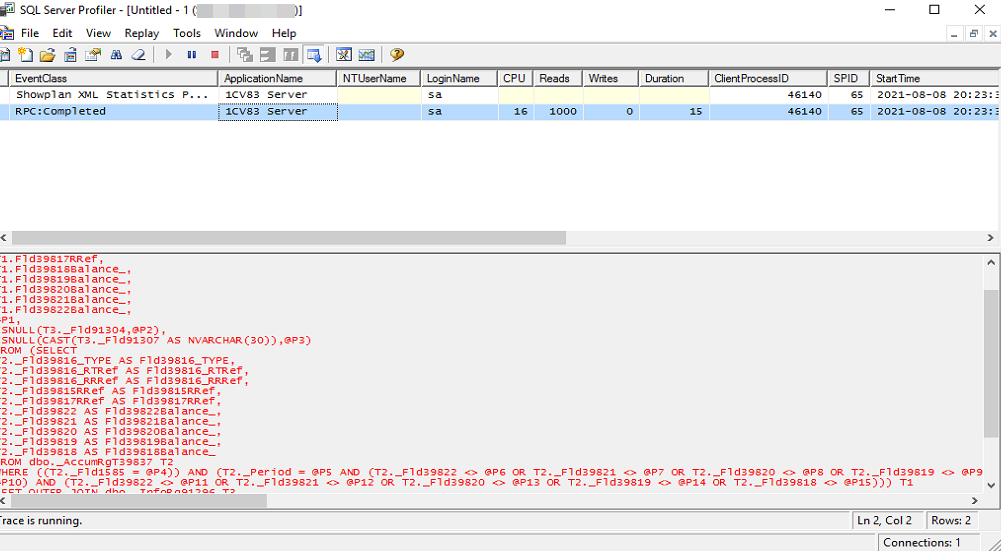
3.5. Жмем кнопку "Run" (Запуск). Приложение можно сказать разделено на две части. В первой части таблица с основной информацией по запросу: Событие, Нагрузка CPU, Время выполнения (Duration) и т.д. По ним мы будем понимать/получать оценку в значениях/цифрах. Во второй части - будет приводиться информация по тексту запроса или плану запроса в графическом виде. Все картинки запросов по тексту ниже взяты из нее.
4. Запускаем SQL Sentry Plan Explorer
Как было сказано выше, этот инструмент будем использовать, когда план запроса сложный, чтобы выделить в нем самые жирные цепочки. Для выделения этих цепочек пользуйтесь фильтром "Filter" и изменяйте значение %. С увеличением этого параметра будут пропадать цепочки с "малым" вкладом в стоимость плана. Т.е. останутся только те, которые вносят самое большое влияние.

Давайте рассмотрим, как в него загрузить данные чуть более подробно:
- кликнем левой кнопкой мышки на строке с событием "Show Plan XML" приложения MS SQL Profiler и в появившемся окне выберем опцию "Сохранить данные события... (Extract Event Data...)". Данные сохранятся в формате плана запроса "SQLPlan".
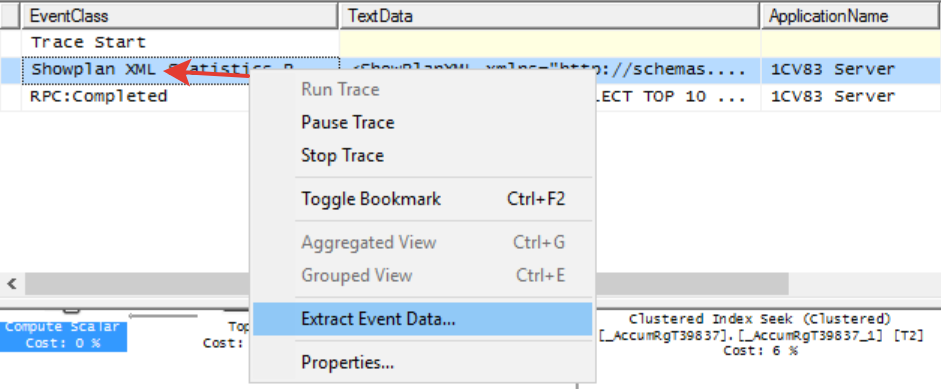
- Далее в приложении Plan Explorer открываем этот файл через "Открыть (Open)". В результате в данные сохраненного ранее плана загрузятся, и у вас появится возможность просмотра в более удобном варианте.
5. Запускаем тестируемого клиента
5.1. Открываем базу данных на платформе 1С. В нашем случае - это конфигурация ЕРП, некоторая версия с набором данных за хороший период. Запускаемся под администратором или под пользователем с ограничениями RLS (не забудьте для этого пользователя разрешить интерактивное открытие отчетов и обработок). Как вариант - можете добавить обработку в расширение и подключить ее.
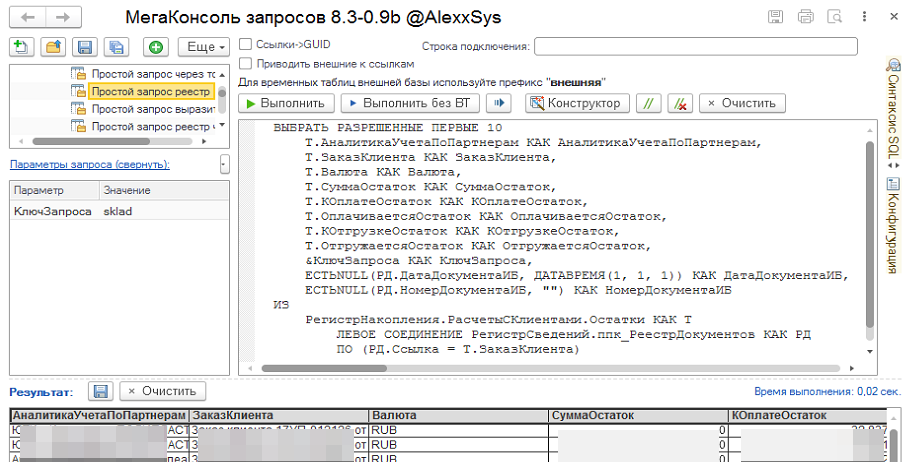
5.2. Открываем консоль запросов (любую консоль запросов). И переходим к примерам. Сами примеры это текстовое представление динамического списка на языке запросов 1С с включением некоторого ключа (параметр "КлючЗапроса"), по которому далее будет накладываться фильтр в профайлере TextData, т.ч. не забудьте его добавить. Еще раз - это значение будет ловиться фильтром TextData, поэтому убедитесь что значения фильтра и параметра "КлючЗапроса" совпадают.
II) Краткая информация про планы запросов
Прежде чем мы начнем смотреть, давайте введем несколько тезисов и рассмотрим краткую справку по операторам плана запросов. Мне понравилась статья на текущем ресурсе - "Зачем запросу план и кто его выполняет?"
Сначала давайте ответим на вопрос: Что же такое план запроса и зачем он нужен?
"План выполнения запроса — последовательность операций, необходимых для получения результата SQL-запроса в реляционной СУБД" - из Википедии
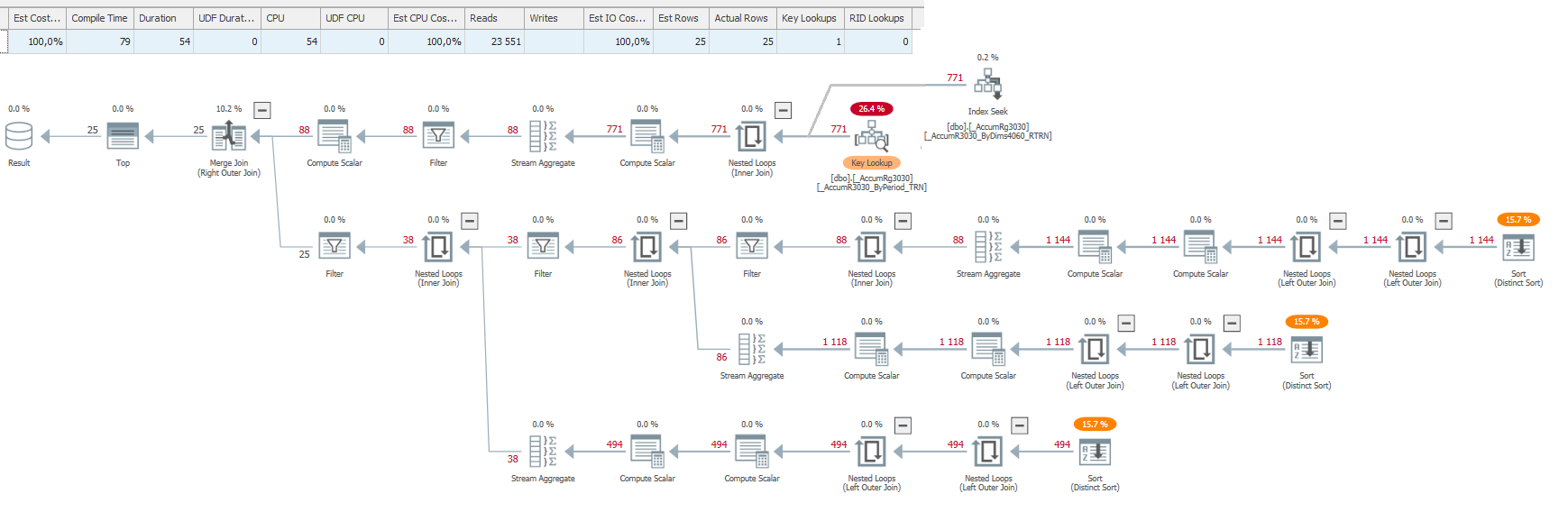
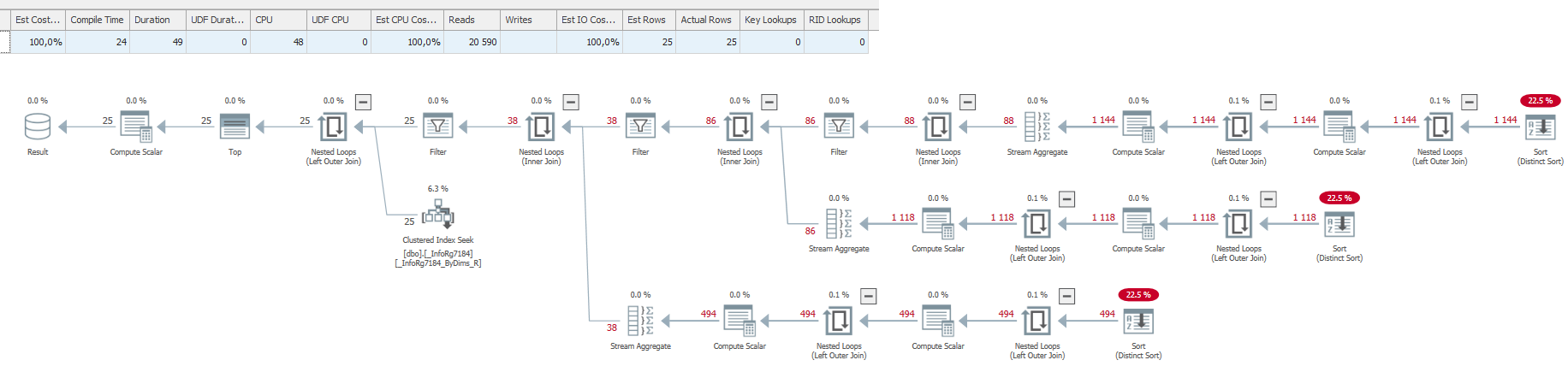
Т.е. на плане запроса мы видим, как SQL сервер получает и обрабатывает данные. И эта графическая (может, в формате структурированного текста) информация помогает нам выполнить оптимизацию. Однако, в рамках 1С нам доступен ограниченный набор операций по оптимизации, т.к. мы напрямую общаемся только с 1С.
Операторы:
- Sort (Сортировка) - сортирует данные
- Filter (Фильтр/Отбор) - фильтрует/отбирает данные согласно условию
- Compute Scalar (Вычислить) - вычисляет выражение
- Concatenation (Конкатенация) - объединяет все входные данные в один поток, в котором содержатся все данные (работает как оператор "ОБЪЕДИНИТЬ ВСЕ").
- Merge Interval (Объединение различные интервалов) - объединяет интервалы, выбирает только не пересекающиеся данные, различные.
- Select (Выбрать) - выбирает данные
- Insert (Вставить) - создает временную таблицу
- Key LookUp (Поиск ключа) - ищет ключ, если не хватает.
- Table Scan (Сканирует таблицу) - ходит по всей таблице, плохо для большого количества данных.
- Index Scan (Сканирует индекс) - считывает весь индекс.
- Index Seek (Поиск по индексу) - считывает только данные удовлетворяющие условию.
- Nested Loops (Соединение вложенным циклом) - пробегает по всем данным в цикле, работает всегда. Хорошо когда первая таблица маленькая, а вторая большая. При таком условии лучше Hash Match и Merge Join.
- Hash Match (Соединение хешированием) - для соединения использует хеш, при поиске по набору ключей, работает при операторе равно "=". Может потреблять много оперативной памяти и если ее не хватит, то полезет на диск в tempdb.
- Merge Join (Соединение слиянием) - самое быстрое слияние, требует сортировку в двух таблицах, а также наличие оператора равно "=". Хорошо на больших наборах данных.
- Stream Aggregate (Агрегирование) - вычисляет агрегирующую функцию MAX, MIN, SUM, AVG, COUNT. по агрегируемой колонке обычно в группировках. Требует обязательную сортировку данных.
Тезисы:
- Обычно чем проще и меньше структура плана запроса, тем лучше.
- Чем меньше данных обрабатывает SQL Server тем лучше, т.е. чем меньше чтений и записей тем система быстрее работает.
- Общая мудрость гласит, что поиск (seek) - это хорошо для производительности, поскольку он представляет собой прямой доступ SQL Server к требуемым строкам данных, в то время как сканирование (scan) - это плохо, поскольку он предполагает последовательное чтение индекса для извлечения большого числа строк, приводя к более медленной обработке.
- Соединения в плане запросов. Merge Join оптимально. Nested loops нормально для небольших данных. Hash match - присмотреться (возможно надо упорядочить сначала набор или индекс иметь на поля упорядочивания, по которым идет связь).
- Чем более высокая нагрузка, тем сложнее серверу выбрать наиболее оптимальный план запросов.
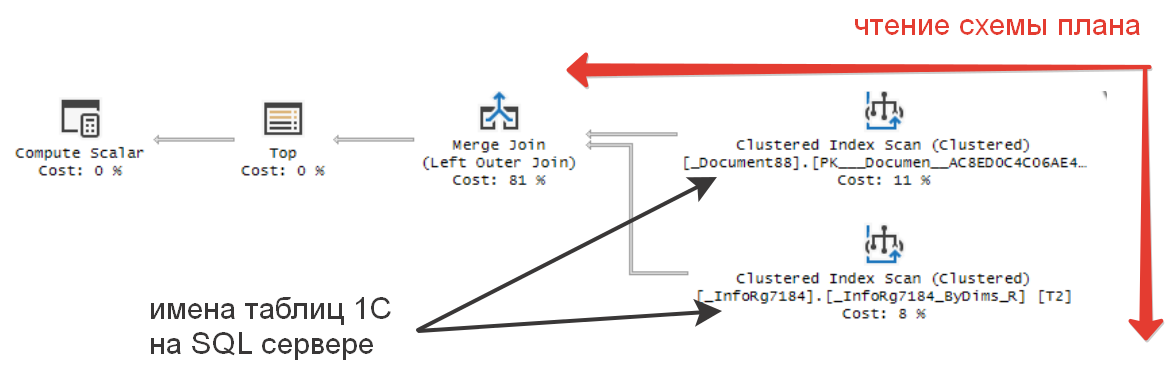
План запроса читается справа налево и сверху вниз. В плане для источников данных приводятся имена таблиц, которые находятся в таблицах SQL сервера. Чтобы получить обратное сопоставление (как они называются в 1С дереве конфигуратора), нужно воспользоваться специальной обработкой или функцией "ПолучитьСтруктуруХраненияБазыДанных" - возвращает таблицу значений с описаниями структуры таблиц, индексов и полей базы данных в терминах модели базы данных 1С:Предприятия или используемой СУБД.
III) Ситуации
1. Некоторые базовые простые ситуации
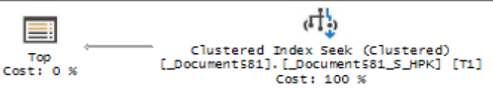
В данных примерах мы посмотрим только на структуру без цифровых показателей значений выполнения запроса (CPU, длительность, количество чтений и записей и др.), т.к. примеры супер простые. Проверку и просмотр проводим на ненагруженном мощном сервере. Платформа 1С 8.3.16 и MS SQL сервер 13.
В качестве начального запроса возьмем таблицу регистра накопления "Товары Организаций", в ней около 10 миллионов записей, что вполне достаточно для наших задач. Регистр накопления "Расчеты с клиентами", где 3 миллиона записей и документ "Заказ клиента", записей порядка 700 тысяч.
Для примеров ниже в профайлере необходимо отключить фильтр длительности (Duration), т.к. запросы выполняются быстро и вы их пропустите. Остальные два фильтра по имени базы и вхождению ключа в текст оставляем.

2. Ситуации из статьи "Типовые ошибки разработчиков приводящие к проблемам".
Теперь давайте с вами рассмотрим планы запросов для ситуаций рассмотренных в предыдущей статье и проверим, как происходит и происходит ли оптимизация. В заголовке спойлера может быть приведен номер пункта из предыдущей статьи. Проверить все варианты и "поиграться" с данными вы можете самостоятельно.
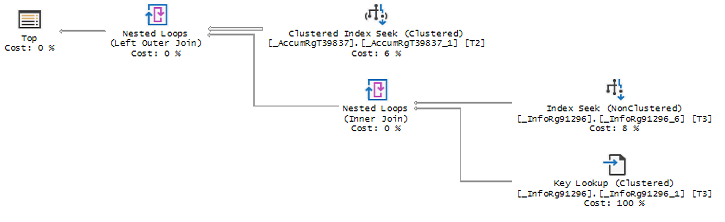
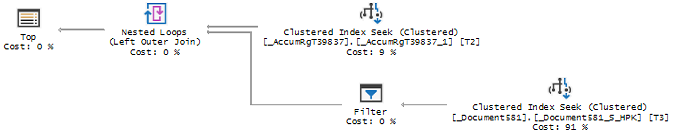
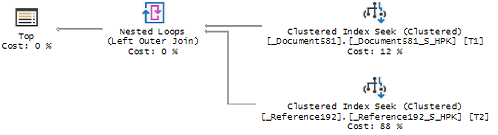
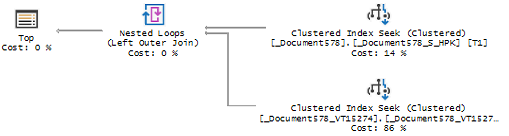
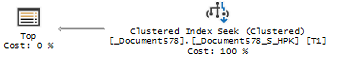
IV) Как найти, увидеть на боевой базе существующие проблемы для анализа
В предыдущих примерах мы анализировали известные ситуации. Теперь давайте перейдем к вопросу: Как найти или увидеть проблемные ситуации в существующей рабочей базе? Что для этого необходимо сделать?
Проанализировать всю конфигурацию - это довольно сложная задача. Давайте попробуем воспользоваться более простым решением, т.к. даже "оптимальные" варианты реализации тех или иных конструкций могут преподнести неожидаемое поведение в боевых условиях на рабочем сервере. Поэтому будем смотреть техническую информацию работы реальной базы или тестового стенда, будем искать и исправлять проблемы на "лету". В качестве инструмента помощника возьмем конфигурацию "Мониторинг производительности". Вы можете использовать блокнот, ЦКК, ЦУП, монитор активности студии SQL сервера или еще другие инструменты, но мы по результатам многолетней эксплуатации пришли к заключению что этот инструмент достаточно прост, удобен и гибок, а также бесплатен и является Open Source.
1) Настройка и загрузка технологического журнала
Процесс настройки и подключения конфигурации Мониторинг производительности отлично расписан в статье "5 простых шагов и 15 минут на разворачивание инструмента мониторинга проблем производительности базы 1С".
Нам потребуется настроить получение долгих запросов. Интервалы вы можете выставить последовательно: начать с ограничения в 60 секунд, а далее снизить показатель до 10 секунд (эти пороговые значения вам лучше определить из опыта на своем окружении и они могут отличаться от рекомендованных). Мы ставим задачу поиска больших и тяжелых запросов, которые следует оптимизировать в первую очередь. Ставить значения менее некоторого порогового числа нет смысла, т.к. будет очень много информации, которую в большинстве своем нельзя оптимизировать без изменения архитектуры (много однотипных запросов).
После некоторого времени наработки у нас с вами появится первая информация. И мы можем приступить к следующему шагу.
2) Настройка и описание инструмента
В предыдущем пункте вы должны были без особых проблем выполнить настройку технологического журнала и загрузку данных в базу. Теперь давайте рассмотрим как удобно настроить интерфейс и на что смотреть и что нажимать.
Первым делом давайте откроем замер и добавим необходимые информационные поля (колонки) в динамический список "События замера" как на рисунке ниже:

Это поля:
- Usr - пользователь, тот пользователь, под которым проявилась ситуация;
- SessionID - номер сеанса, вы можете отследить его действия в журнале регистрации в рамках интервала, чтобы к примеру, увидеть какой документ проводился и т.п.;
- p:processName - имя базы данных, в какой базе проявилась ситуации;
- Context - информация по стеку кода, где ситуация произошла. Позиция кода где смотреть возникшую проблему;
- Sql - текст запроса который выполнялся указанное время;
- Rows - количество строк полученных по запросу. Для динамических списков обычно не большое (25-50) и с ключевым словом в запросе TOP. Полезно чтобы оценить адекватность передаваемых пользователю данных, к примеру, если передается пользователю миллионы строк данных, то значит что-то не так;
- RowsAffected - количество строк добавленных во временную таблицу;
- SQL:Param - параметры запроса, могут входить в Sql. Удобно чтобы посмотреть, что передавалось.
Теперь давайте посмотрим, как выглядит у нас список:

В поле замер выбираем необходимый замер. Для нас "долгие запросы (не отчеты)".
В верхней части списка у нас должен появиться отбор по текущей дате - больше или равно началу сегодняшнего дня. Если у вас нет такого отбора установите его, т.к. это ограничит количество анализируемых данных и позволит списку довольно быстро работать.
В поле фильтра "длительность" устанавливаем ограничение в 60 секунд (или другое большее число - зависит от ситуации) и начинаем смотреть, что у нас набралось.
3) Смотрим ситуации и анализируем
А) Пример "поиск подобно по всем колонкам".
Открываем понравившуюся нам позицию и начинам анализировать. Ставим курсор на выбранную строку:
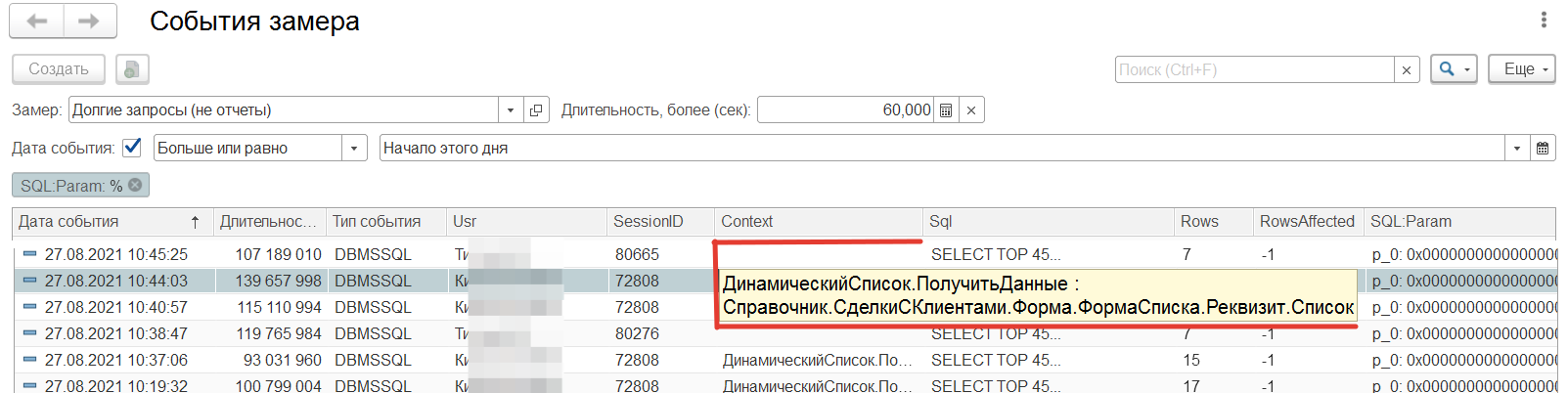
Из контекста видно, что проблемная ситуация находится в динамическом списке "Сделки с клиентами". Давайте посмотрим почему у нас появился этот запрос в топе, т.к. сам запрос на языке запросов 1С выглядит достаточно просто и в нем нет особых проблем.
Далее посмотрим свойства параметров и обратим внимание на наличие "%" и вхождения в запрос оператора языка запросов "ПОДОБНО (LIKE)". Двойной клик на полях соответствующих колонок "Sql" и "SQL:Param".

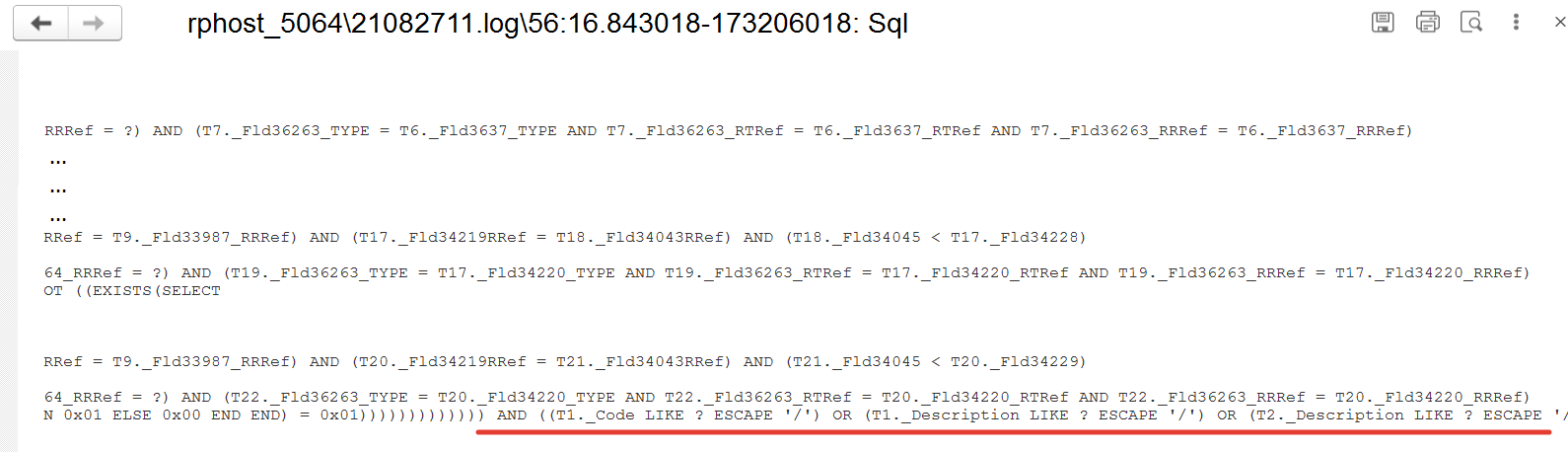
Количество вхождений параметров говорит нам о выполнении общего поиска по всем колонкам. Что мы можем увидеть на картинке ниже. Ситуацию усугубляет, то что пользователь дополнительно ограничивается RLS.
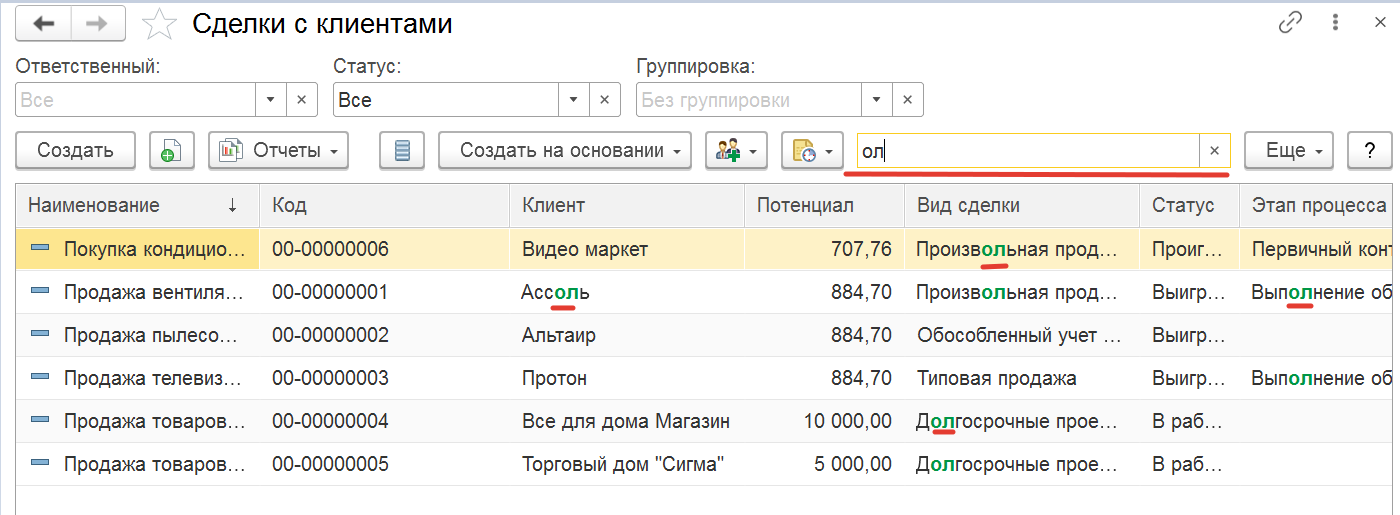
Резюме: В данном случае смотреть план запросов нет необходимости, т.к. проблема и решение на поверхности. Не используйте общий поиск по всем колонкам и просто отключите его. В результате время выполнения запроса сократиться на порядок.
Б) Выбор необоснованного количества данных.
Давайте посмотрим следующий пример, который на рисунке ниже.

Как мы видим, то происходит создание временной таблицы с количеством строк "RowsAffected" с более чем 620 тысяч строк. Это действительно большое количество для данных. Давайте посмотрим где это произошло по колонке "Context".

Это выполняется внешняя обработка, а позиция находится в модуле объекта и именно выполнение запроса.
Резюме: Тут ситуация не однозначная, требуется передать описание возникновения проблемы программистам в отдел разработки, для дальнейшего анализа и исправления ситуации. Возможно в запросе не хватает дополнительных фильтров или отборов судя по количеству помечаемых данных.
Б) Сортировки по неиндексированным полям в динамическом списке
Давайте посмотрим, что у нас с самым популярным списком в базе ЕРП. Как вы догадались, то это список называется "Заказы клиентов". Самое обидное что в этом примере пользователь получил пустой список и ждал более 2х минут.
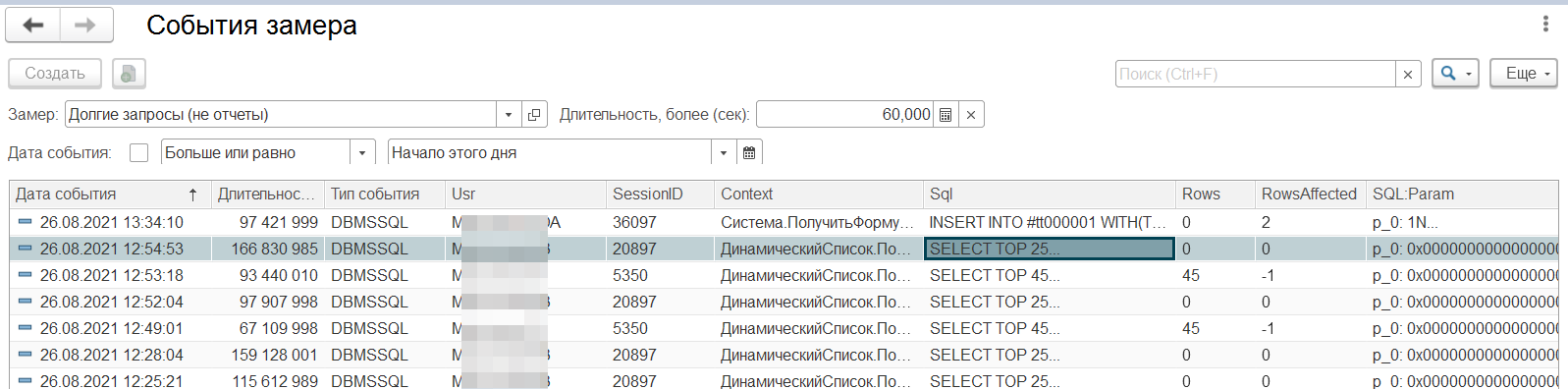
Контекст запроса: "ДинамическийСписок.ПолучитьДанные : Документ.ЗаказКлиента.Форма.ФормаСпискаДокументов.Реквизит.Список".
Первым делом поглядим на наличие подобно, его нет. Давайте посмотрим на еще один интересный оператор запросов "УПОРЯДОЧИТЬ ПО (ORDER BY)". Для этого возьмем запрос из колонки "Sql" посмотрим на него внимательней.

Как мы видим с вами, то сортировка присутствует и в него добавлено поле "Партнер". Дополнительно на быстродействие влияет наличие сложной RLS по этому пользователю. Также мы видим наличие некоторого количества отборов, в которые входит и партнер (не приведено на снимках экрана).
Пользователь при запросе от сотрудника сопровождения (поддержка) объяснил, что сортировку поставил случайно (кликнул по этому полю).
Резюме: Нам требуется убрать сортировку из динамического списка по неподходящему полю или выполнить его индексирование. Также можно взять консоль запросов и под этим пользователем посмотреть как меняется поведение (это можете сделать самостоятельно).
Г) Сложный запрос и дальнейший анализ по схеме выше
Давайте возьмем следующую позицию для запроса:
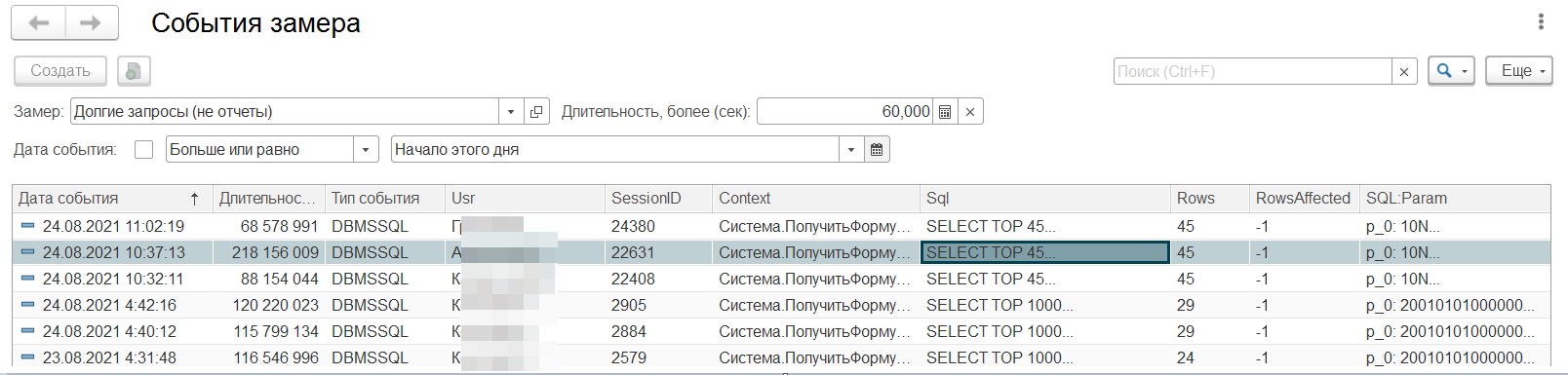
Открываем контекст и смотрим:

Тут у нас похоже открыта домашняя страница рабочего стола предприятия. Не понятно, какой из списков вносит проблемы. Давайте скопируем запрос и преобразуем SQL имена таблиц в 1С.
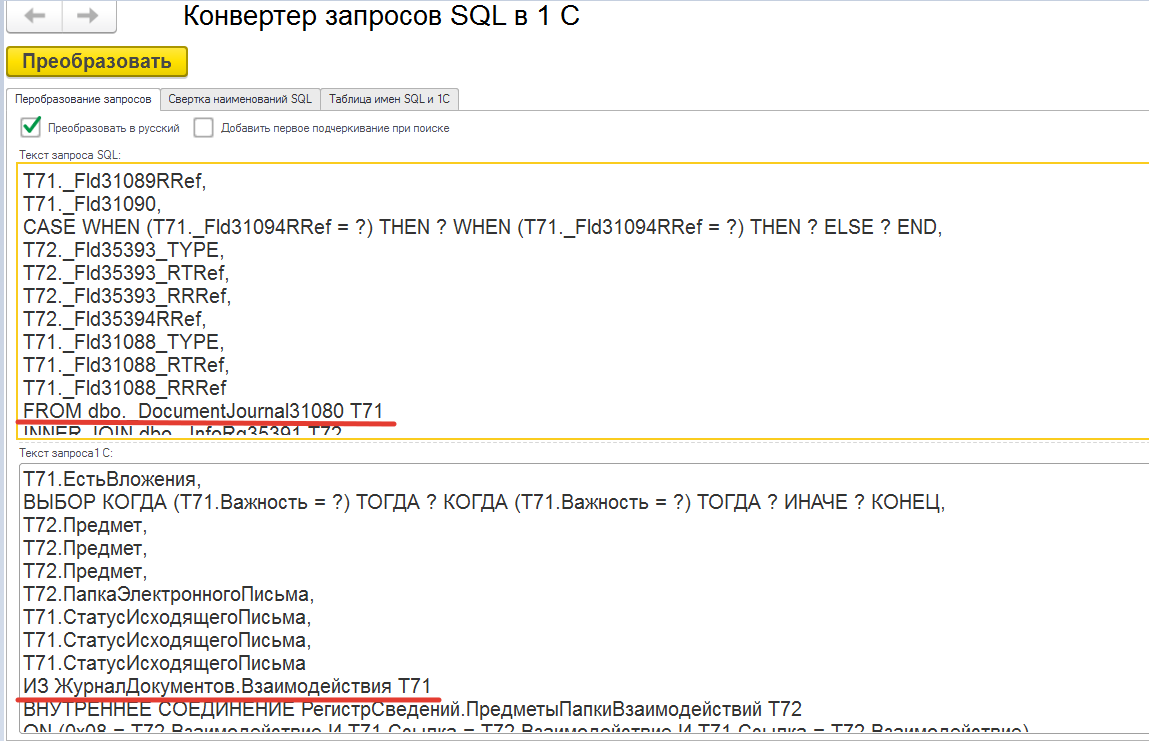
Мы видим, что это "ЖурналДокументов.Взаимодействия". В запросе нет поиска по подобно и сортировки по "плохим" полям. Давайте откроем эту форму списка и посмотрим на запрос:
Резюме: В списке нам не видно каких-то особых проблем, он достаточно простой. Дальнейшее расследование причин необходимо осуществлять с применением профайлера.
Дальнейшие рассмотрение практических примеров и ситуаций планирую рассмотреть на конференции или в следующей статье. Также хочу затронуть тему нагрузочного тестирования - моделирования нагрузки на рабочем стенде для выявления ситуаций и поведения под нагрузкой SQL сервера. Данную тему рассматривал на конференции QADays, думаю будет интересно.
V) РЕЗЮМЕ
- Оптимизатор плана запроса в MS SLQ сервер очень умный (если так можно сказать про программу) и он хорошо выполняет свою работу. Для того чтобы он правильно работал необходимо следить за актуальностью статистики, использовать другие процедуры обслуживания сервиса. Некоторые рекомендации от вендора смотрите тут: Регламентные операции на уровне СУБД для MS SQL Server
- Следите внимательно и не допускайте использования реквизитов в запросах через точку для составных типов.
- Всегда где это возможно используйте отборы - по дате, по периоду, по организации, контрагентам, и т.п.
- Избегайте где возможно использования в динамических списках общего поля поиска, отключайте, удаляйте, заклеивайте его.
- Обращайте внимание на наличие в схеме плана запроса оператора KeyLookUP - это говорит об отсутствии необходимых индексов. Однако, в типовых конфигурациях из-за наличия общих разделителей необходимо будет просматривать и анализировать каждый такой оператор, чтобы их отсеять. Добавление этих разделителей значительно ухудшило информативность схемы плана запросов и снизило возможности оптимизации, т.к. работа с этими реквизитами осуществляется платформой.
- Для очень сложных планов запросов используйте Plan Explorer и ищите "жирные" потоки данных, для того чтобы понять откуда идут проблемы. Если жирных потоков нет, то скорее всего требуется пересмотреть архитектуру решения.
- Проблема для динамических списков может иметь простое объяснение - прежде чем открывать профайлер посмотрите на наличие в тексте запроса "паразитных" вхождений: ПОДОБНО (LIKE), УПОРЯДОЧИТЬ ПО (ORDER BY), СГРУППИРОВАТЬ ПО (GROUP BY) - это могут быть признаки неоптимальной работы с элементом интерфейса.
- Обращайте внимание на "огромные" количества получаемых данных или помещаемых во временные таблицы - это может говорить о том что не хватает фильтров или про некорректные алгоритмы процедур.
Вступайте в нашу телеграмм-группу Инфостарт
