Меня зовут Денис Рожков, я работаю в компании «Газинформсервис». Участвую в проекте по разработке СУБД Jatoba. Мы делаем свою реализацию СУБД на основе PostgreSQL – форк с необходимыми нам расширениями.
СУБД Jatoba появилась в результате нашего многолетнего опыта по внедрению проектов на другом программном обеспечении – у нас есть опыт работы не только с PostgreSQL и MS SQL, но и с Oracle, как с большой корпоративной СУБД, которая долгое время являлась стандартом.
PostgreSQL, как тренд последних лет, затронул нас настолько сильно, что мы начали разрабатывать на его основе свою СУБД. Мы не просто конфигурируем продукт на уровне пользователей, но и ковыряемся внутри, разрабатываем СУБД на уровне ядра и дописываем функциональность, которая нам нужна, на языке C.
Наша компания разрабатывает разные продукты, где СУБД используется как хранилище, и мы успешно реализовали ряд задач по миграции больших проектов с иностранных СУБД на PostgreSQL и отечественные СУБД. Поэтому опыт миграции у нас большой – это уже многолетняя история.
В ходе доклада:
-
Сначала будет теория – мы вспомним и обобщим знания по кластеризации, проговорим, что мы должны знать о кластерах при выборе реализации для того или иного решения.
-
Поговорим о том, какие технические решения уже есть для PostgreSQL, чтобы не изобретать велосипед и не делать то, что сделал уже кто-то другой.
-
Расскажу о паре граблей, с которыми можно столкнуться в процессе настройки.
Сосредоточимся на вопросе повышения доступности СУБД
Что касается отказоустойчивости, то этот вопрос очень широкий и глубокий, поэтому с самого начало надо разделить:
-
есть High Availability – высокая доступность;
-
и есть Disaster Recovery – как восстановить систему в случае сбоев. Сюда входят бэкапы, регламенты восстановления и т.д. – это более широкий термин, чем высокая доступность.
Мы сегодня не будем говорить про disaster recovery, мы обсудим только первый раздел – High Availability.
С точки зрения высокой доступности мы сосредоточимся на аспекте СУБД. Пробежимся по верхам и попробуем обобщить, вспомнить, что можно использовать для повышения доступности, и какие есть нюансы.
Виды кластеров
Начнем с того, что такое кластер и зачем он нужен?
Сейчас вопрос создания кластера для отказоустойчивости не так актуален, как 10 лет назад. Сейчас и железо уже стало мощнее и серьезнее, и внутренние реализации отказоустойчивости другие, и системы виртуализации присутствуют почти везде – механизмов обеспечения разного рода отказоустойчивости достаточное количество.
Так или иначе, кластер – это разновидность параллельной или распределенной системы, которая состоит из нескольких связанных между собой компьютеров. Эти компьютеры должны использоваться вместе, как единый ресурс – именно это может сделать группу компьютеров кластером.
Сами кластеры бывают разные:
-
отказоустойчивые кластеры – это и есть кластеры высокой доступности (High-availability clusters, HA, кластеры высокой доступности);
-
кластеры с балансировкой нагрузки, которые в зависимости от настроек умеют распределять входящую нагрузку (входящих клиентов) на определенные сервера (Load balancing clusters);
-
вычислительные кластеры (High performance computing clusters, HPC);
-
системы распределенных вычислений.
Два последних раздела нашей темы совсем не касаются, но в стандартной классификации они присутствуют.
Типы отказоустойчивых кластеров
Есть три варианта обеспечения отказоустойчивости, три типа отказоустойчивых кластеров:
-
с холодным резервом или активный/пассивный (master\slave). Активный узел выполняет запросы, а пассивный ждет его отказа и включается в работу, когда таковой произойдет. Пример – резервные сетевые соединения, в частности, алгоритм связующего дерева. Например, связка DRBD и HeartBeat /Corosync. Хотя многие говорят, что это не про отказоустойчивость, но это самый распространенный вариант. Если у вас все правильно настроено, именно master\slave-конфигурация позволяет с минимальным простоем продолжить обслуживание клиентов.
-
с горячим резервом или активный/активный (master\master) – когда все сервера работают в системе равнозначно, все узлы выполняют запросы, в случае отказа одного нагрузка перераспределяется между оставшимися. То есть кластер распределения нагрузки с поддержкой перераспределения запросов при отказе. Примеры – практически все кластерные технологии, например, Microsoft Cluster Server или OpenSource-проект OpenMosix. Эта конфигурация имеет свои плюсы и свои минусы, для некоторых инсталляций СУБД она вообще недоступна. Но такой вариант резервирования существует, и я потом расскажу, где конкретно в PostgreSQL его можно встретить и увидеть.
-
с модульной избыточностью, когда мы спускаемся на уровень RAID или реализуем избыточность на аппаратном уровне. Применяется в случае, когда простаивание системы недопустимо. Все узлы одновременно выполняют один и тот же запрос (либо части его, но так, что результат достижим и при отказе любого узла), из результатов берется любой. Необходимо гарантировать, что результаты разных узлов всегда будут одинаковы (либо различия гарантированно не повлияют на дальнейшую работу). Примеры – RAID и Triple modular redundancy. К самой СУБД это имеет опосредованное отношение, но такой вид классификации среди типов кластеров присутствует.
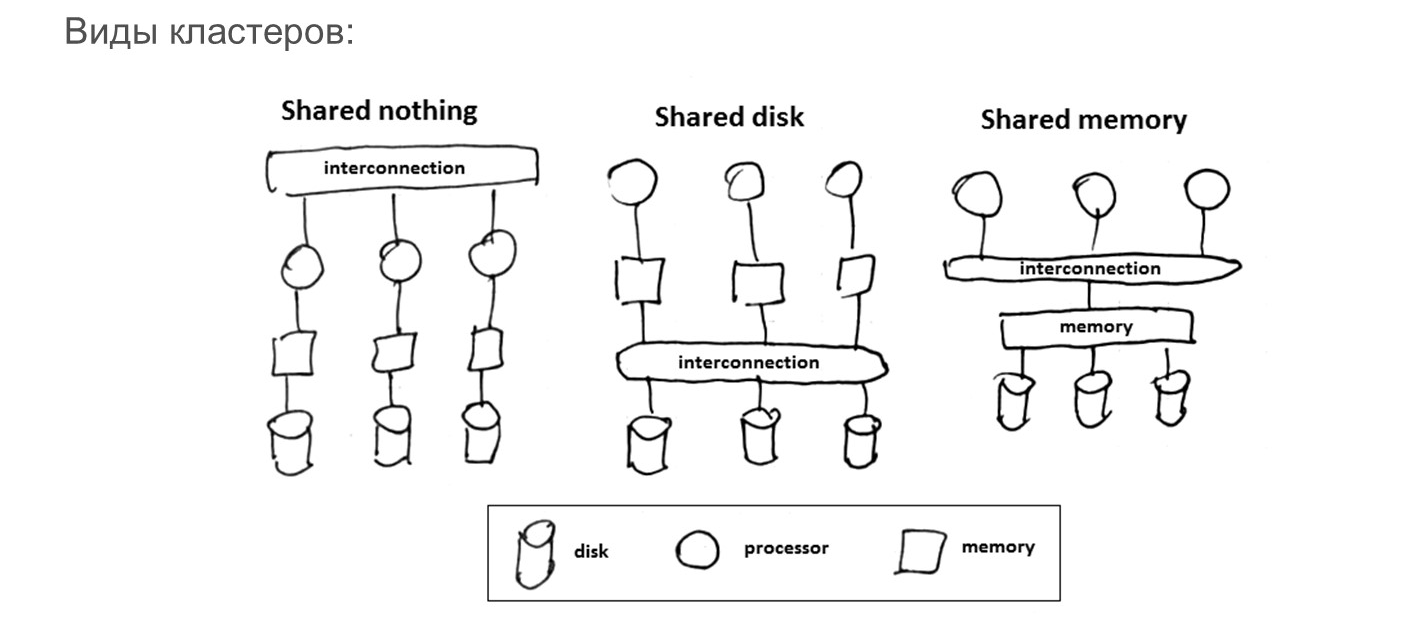
И последний теоретический момент, который нужно упомянуть – в разных семействах СУБД есть принципиальные различия в реализации определенных видов кластеров по распределению и использованию ресурсов.
-
Shared nothing – конфигурация, в которой когда каждый из серверов работает сам по себе, у каждого сервера есть собственный дисковый ресурс, где он автономно ведет все, что ему нужно. Серверы между собой ничего не делят, но они умеют между собой по определенной схеме взаимодействовать, передавая друг другу информацию и таким образом поддерживают консистентность.
-
Shared disk – конфигурация, когда несколько узлов могут работать с одним диском и умеют консистентно сопровождать данные на этом диске.
-
Shared memory – конфигурация, в которой можно шарить память и процессоры. Это не очень актуально в MS SQL и PostgreSQL, но в общей классификации этот вариант кластера тоже присутствует.
Таким образом, есть системы с разделением и неразделением ресурсов, когда ресурс (в частности, дисковая подсистема) используется на каждом сервере автономно или неавтономно.
Механизмы кластеризации в MS SQL Server
Я не буду проводить параллели, не буду устраивать битву MS SQL и PostgreSQL – я сначала напомню, какие механизмы кластеризации есть в Microsoft SQL Server и потом будем подробнее говорить про PostgreSQL.
Так или иначе, в ходе доклада мы рассмотрим обе эти системы с точки зрения основных аспектов. А параллели вы сами сможете провести. И в конце мы попробуем это обобщить.
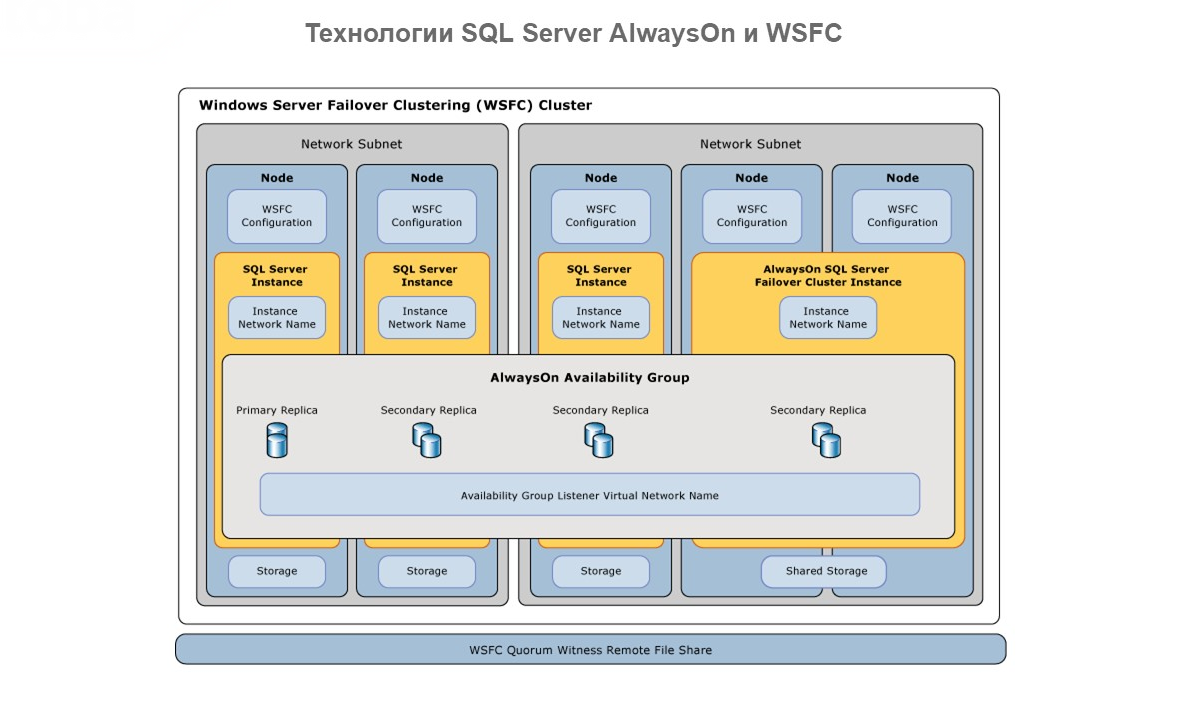
Напомню, что основные механизмы обеспечения отказоустойчивости в кластере СУБД MS SQL – это Microsoft Windows Server Failover Clustering (WSFC) и технология AlwaysOn.
Технология AlwaysOn представляет собой интегрированное непосредственно в операционную систему гибкое решение, которое обеспечивает высокий уровень доступности и аварийного восстановления.
AlwaysOn поддерживает три основных режима доступности:
-
асинхронная фиксация;
-
синхронная фиксация;
-
режим конфигурации.
Последний режим нам совсем не интересен, потому что в нем не фигурируют данные, но асинхронная и синхронная фиксация – это про нас.
Здесь нужно понять принципиальный нюанс в реализации кластеризации: чем эти два режима отличаются между собой – причем, они примерно одинаково отличаются как в семействе MS SQL, так и в PostgreSQL.
-
Asynchronous-commit mode (асинхронная фиксация) – это режим, когда первичная реплика фиксирует транзакции, не ожидая подтверждения того, что вторичная реплика записала журнал на диск. При этом каждая вторичная реплика работает в режиме асинхронной фиксации – ей передается информация, и уже неважно, что происходит дальше. Вместо ожидания запись журнала сразу помещается в локальный файл первичной реплики, и клиенту отправляется подтверждение транзакции. Главное, записать данные к себе и вторично проинформировать второй сервер о том, что транзакция была выполнена. За счет этого первичная реплика минимизирует задержку транзакций в базах данных-получателях, но позволяет им не успевать за базами данных-источниками, что создает риск возможной потери данных.
-
Synchronous-commit mode (синхронная фиксация) – это режим, в котором прежде чем фиксировать транзакции, первичная реплика ждет, чтобы вторичная реплика подтвердила, что запись журнала на диск завершена. В этом режиме возникает ожидание, и тайминги завершения транзакций будут другими. Но после синхронизации базы данных-получателя с базой данных-источником зафиксированные транзакции будут полностью защищены.
С одной стороны, при асинхронной фиксации транзакции вы можете увеличить скорость, но с другой стороны, если у вас на реплике транзакция не была получена, то восстановить эти данные на реплике можно только в том случае, если у вас останутся журналы с основного сервера. Это и есть нюанс использования механизма асинхронной транзакции – его можно использовать для повышения скорости транзакций, но есть риски.
Поскольку 1С – это система с высокой ценностью информации, мы, с одной стороны, рекомендуем асинхронный режим, но с другой стороны, это зависит от нагрузки и того, насколько тайминги и лаги в целом влияют на механизм работы.
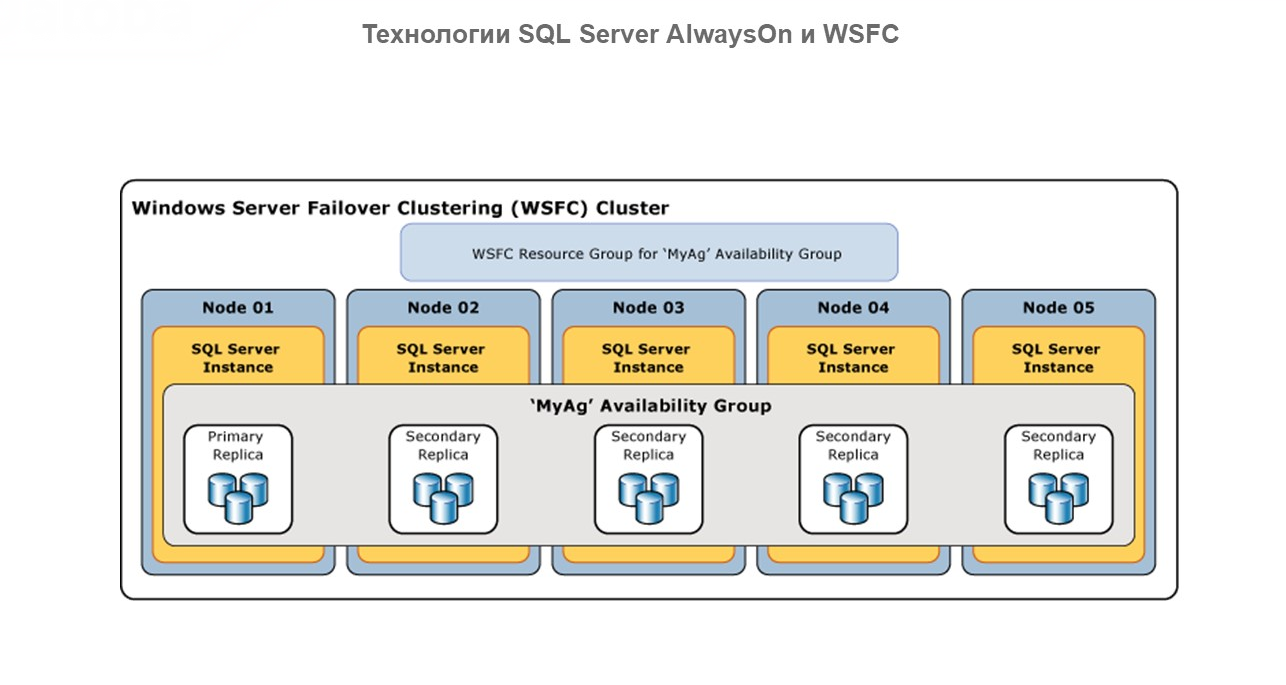
При масштабировании кластера на несколько узлов у нас есть понятие «Группа доступности» – это группа баз данных, для которых отработка отказа выполняется одновременно.
Группу доступности для чтения можно использовать для масштабирования нагрузки. В этом режиме наши реплики работают на read-only, снижая нагрузку с основной мастер-базы, позволяя распределять клиентов на вторичные базы. При этом основной первичный узел – единственный, кто работает read/write.
Здесь вопрос отказоустойчивости вторичен, потому что мы работаем для распределения нагрузки.
Нюансы при реализации кластера отказоустойчивости в MS SQL Server
Еще раз обобщим основные нюансы, которые нужно помнить при реализации кластера отказоустойчивости в SQL Server.
Режим доступности – свойство каждой реплики. Он определяет, ждет ли первичная реплика перед фиксацией транзакции, чтобы данные на вторичной реплике записались в журнал транзакции на диск.
Группы доступности AlwaysOn поддерживают два режима: режим синхронной и асинхронной фиксации.
В этих двух режимах доступности есть следующие ограничения:
-
При асинхронной фиксации транзакции переход на другой ресурс возможен только вручную. Причем здесь может возникнуть потеря данных – из-за того, что основной сервер не успел сообщить какую-то информацию резервному.
-
В синхронном commit mode переход на другой ресурс возможен как вручную, так и автоматически. При этом вы получите практически идентичный набор данных. Потеря данных здесь практически невозможна, хотя из-за некоторых технических нюансов могут быть некоторые потери транзакции на резервных серверах.
Важно, что экземпляры отказоустойчивого кластера MS SQL Server не поддерживают автоматический переход на другой ресурс с учетом групп доступности, поэтому любая реплика доступности, размещенная в них, должна быть настроена для перехода на другой ресурс вручную.
Механизмы кластеризации в PostgreSQL
В PostgreSQL зоопарк решений для кластеризации гораздо больше – сначала мы проговорим технические нюансы, а в конце обобщим, какие решения у нас есть.
Логическая репликация
В PostgreSQL есть логическая и физическая репликации.
Начнем с логической репликации.
Плюсы логической репликации:
-
Логическая репликация умеет копировать данные между разными версиями и архитектурами PostgreSQL. Ее можно использовать в случае, когда у вас в рамках одного комплекса используются разные версии Postgres, и вы хотите постепенно сделать апгрейд. В таких случаях логическая репликация позволяет постепенно обновлять версии и дойти до нужной.
-
Можно реплицировать не всю СУБД, а только отдельные объекты, которые вас интересуют. Например, иногда журналирование и какая-то отладочная информация являются для системы избыточными, их можно не реплицировать. В этих случаях вы можете ограничить логическую репликацию только теми объектами, которые вас интересуют.
-
Так как 1С генерирует в СУБД много динамических объектов, то логическая репликация с точки зрения 1С менее актуальна, чем физическая репликация, которая также присутствует для PostgreSQL.
Минусы логической репликации:
-
Практически невозможно реализовать синхронную репликацию, потому что двухфазный коммит на уровне логики триггеров затруднителен.
-
Также это решение дает дополнительную нагрузку на ЦПУ, поэтому если вы используете логическую репликацию, будьте готовы, что производительность ваших серверов еще больше просядет.
Из существующих решений по логической репликации можно отметить: Pglogical, Slony и менее известные – Londiste (Skytools) и Bucardo.
Физическая репликация
Физическая репликация в семействе Postgres используется более активно. Основные плюсы:
-
Минимальные накладные расходы на использование ресурсов.
-
Легко настраивать и сопровождать, но все относительно. Иногда для разработчиков СУБД легкая настройка – это час работы, а для разработчиков прикладных систем это конфигурирование – ад. Но относительно логической репликации здесь явно будет меньше времени потрачено.
Минусы этого решения:
-
все слейв-Standby-сервера будут работать в режиме только на чтение. Если у вас есть необходимость использовать конфигурацию с двумя read/write, то это уже другая технология.
-
Не могут работать с разными версиями и архитектурами по оборудованию, по умолчанию надо предполагать, что все сервера должны быть в одной версии. Они могут быть в разных минорных версиях, но мажорные версии точно должны совпадать, иначе не сможет работать.
-
Вы не сможете ограничиться отдельными объектами репликации: либо вся СУБД, либо ничего.
Схема физической репликации в PostgreSQL
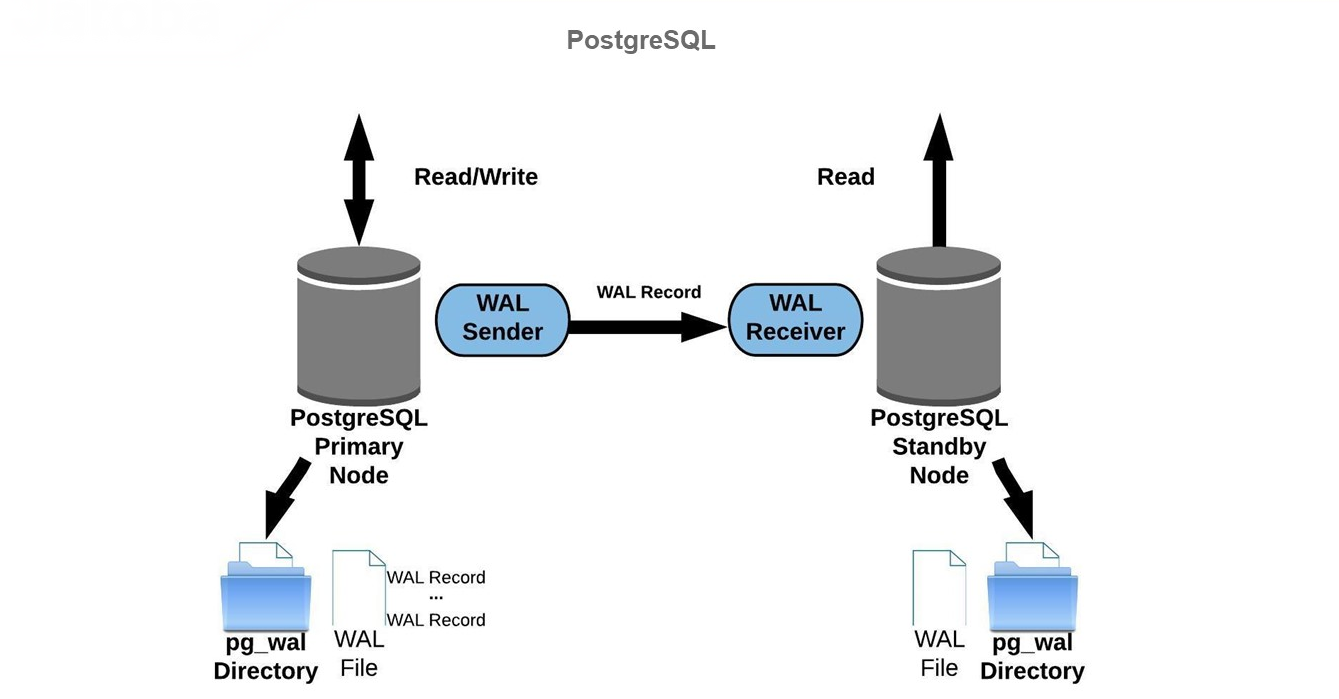
Почему присутствуют эти ограничения?
В PostgreSQL у нас есть основная Primary Node – мастер-база, которая работает на read/write. Она пишет журнал предзаписи – так называемые WAL-файлы, которые содержат информацию, позволяющую СУБД восстановиться, и несут в себе журнал транзакций. Благодаря этим WAL-файлам мы можем поддерживать в актуальном состоянии все остальные слейв-базы (Standby Node)/
Standby Node на PostgreSQL получают данные из WAL-файлов, обновляя свои данные на текущее состояние, тем самым проводя актуализацию.
Механизм похожий, он используется не только в PostgreSQL, но здесь он оперирует только журналами предзаписи (WAL-файлами).
В PostgreSQL надо помнить, что запись попадает в журнал предзаписи, а затем в файл данных. Это позволяет обеспечить консистентность и целостность.
Варианты репликации PostgreSQL
В PostgreSQL есть следующие варианты репликации:
-
синхронная и асинхронная репликация;
-
каскадная репликация;
-
One-directional и Bi-directional.
Bi-directional в PostgreSQL – это вариант кластеризации с горячим резервом master/master. Это немногим известно, технология не так широко распространена. Для этого есть свои причины, но так или иначе она существует.
Синхронная и асинхронная репликации знакомы почти всем.
Каскадная репликация – это когда вы с одной реплики можете сделать еще одну и так далее. Часто на мастер в высоконагруженных системах нельзя подключать несколько слейвов, которые могут вам позволить обслуживать нагрузку read-only, потому что от канал мастер-базы к многим слейвам будет перегружаться из-за дублирования передачи информации для каждого слейва.
Поэтому иногда в высоконагруженных системах целесообразно сделать первый слейв, а с него – что-то другое. Здесь есть определенные задержки при передаче и актуализации информации, надо это понимать и помнить, слейв со слейва не будет так же актуален, как первый слейв, но это позволяет разгружать каналы и основной мастер, потому что факт передачи нагружает не только каналы, но и другие ресурсы – выделение памяти и т.д., что негативно влияет на работу продуктива.
Создание кластера master/slave на PostgreSQL
Что делать в семействе баз данных PostgreSQL, чтобы получить конфигурацию master/slave – кластер, который может использоваться для отказоустойчивости.
-
В первую очередь нужно сконфигурировать мастер – мы всегда начинаем с мастера, нельзя просто развернуть слейв и сконфигурировать все на слейве.
-
Для получения слейва вам нужно создать полную бэкап-копию текущего мастера. Это отдельная процедура, она на продуктиве всегда не очень приятна. В любом случае, вторым шагом после настройки мастера вам придется делать слейв-копию.
-
Потом эту слейв-standby-копию нужно доконфигуровать.
-
В результате правильной настройки, если вы запускаете слейв-базу, то процедура донаката WAL-файлов должна идти стандартно.
-
Вы это можете проверить, посмотрев стандартные вьюшки и выполнив некоторые мероприятия, которые я покажу чуть позже.
Конфигурация MASTER server

Для конфигурирования мастер-сервера в обязательном порядке нужно:
-
Создать отдельного пользователя с определенными параметрами аутентификации, чтобы передавать через него файлы на резервную копию. Это можно сделать запросом:
CREATE ROLE replica WITH LOGIN REPLICATION PASSWORD '…';
Несмотря на то, что этот шаг я назвал обязательным, его можно не делать, можно использовать стандартного пользователя PostgreSQL. Но я считаю, что нужно вводить отдельную аутентификацию, делать отдельный пароль, потому что здесь идет речь о передаче между двумя СУБД. Чтобы контролировать этого пользователя, нужно настраивать параметры для его доступа отдельно, не используя внутреннего, предустановленного в PostgreSQL пользователя, который в СУБД всегда присутствует. Мои рекомендации – создавайте пользователя для конфигурирования резервных серверов. -
В postgresql.conf указать необходимый уровень wal_level и количество процессов отправки max_wal_senders:
wal_level=hot_standby
max_wal_senders > 0 -
В pg_hba.conf указать параметры аутентификации для пользователя, которого мы отдельно создали, в формате:
host replication username client_addr/mask authtype
В качестве метода аутентификации лучше указать md5:
host replication replica 192.168.1.0/32 md5
Нельзя использовать метод аутентификации trust, хоть это и упрощает работу. Поскольку слейв-сервер – это второй сервер, для него будет сетевое взаимодействие, поэтому даже если серверы у вас в отдельном сегменте сети, все-таки целесообразно указывать отдельную аутентификацию.
Создание копии БД

Для создания копии удобнее всего использовать утилиту pg_basebackup, потому что в нем есть возможность указывать скорость записи для передачи информации через параметр --max-rate, что позволяет не забивать канал при создании реплики.
Использование этой утилиты сводится к тому, что вы в определенный момент вводите нужные параметры и ждете, когда же у вас на резервном сервере создается полная копия на момент начала создания бэкапа.
Но в продуктиве выполнение этой операции трудоемко и занимает много часов – у нас были случаи, когда создание первого слейва занимало десятки часов. Поэтому сначала стоит подумать, как это можно оптимизировать.
Например, можно добавлять архивацию, можно использовать отдельное копирование самого файла и другие приемы – для этого могут быть полезны следующие утилиты из операционных систем Linux:
-
Lbzip2 – bzip2-сжатие, которое позволит архивировать в несколько потоков с использованием нескольких ядер, если нужно запаковать быстрее (аналоги: pbzip2, pigz);
-
Ionice – регулировка класса и приоритета для планировщика ввода-вывода (также можно использовать nice для регулировки приоритета процессов для CPU планировщика);
-
pv – контролируем объем передаваемых данных через pipe и т.о. используем для ограничения объема передаваемых данных в единицу времени (аналог — throttle);
-
tar – утилита архивирования, нужна для вспомогательных целей когда не используется сжатие bzip2/gzip;
-
tee – чтение с stdin c записью в stdout и другие файлы (является частью coreutils);
-
gpg – позволит обеспечить шифрование при передаче бэкапа на слейв-сервера.
Те, кто знаком с Linux, эти утилиты хорошо знают. В семействе Windows этот набор ограничивается, но можно найти и применить альтернативные решения – все зависит от того, в каком контексте вы хотите их использовать.

Грабли при использовании стандартной утилиты pg_basebackup.
-
Не забывайте включать в конфигурационном файле postgresql.conf параметры, о которых я рассказывал:
wal_level=hot_standby
max_wal_senders > 0 -
Операция создания бэкапа может быть очень продолжительной.
-
На больших базах помните, что клиенты работают на том же канале, что используется для создания резервной базы. Это может быть неочевидно, но помните об этом. Если есть возможность разносить на разные адаптеры – это замечательно, но тогда перед использованием настройте правильную маршрутизацию перед тем, как будете использовать. Или ограничьте скорость передачи через параметр --max-rate.
Ни в коем случае не ставьте в продуктиве на Linux для ускорения работы PostgreSQL в настройках fsync = off. Это известные грабли, которые не имеют отношения к pg_basebackup, но люди иногда меняют этот параметр, потом в продуктиве может возникнуть очень неприятная проблема, потому что консистентность базы в режиме бэкапа – отдельная история.

Все мы знаем, что pg_basebackup работает не особенно быстро. Ее плюс в том, что она входит в дистрибутив PostgreSQL и развивается одновременно с базой данных – все новшества, которые появляются в СУБД, также поддерживаются в pg_basebackup. По этой причине, она наиболее качественно протестирована для соответствия новым возможностям PostgreSQL. Но поскольку она уже не очень новая, отсюда ее минусы в производительности.
Для создания слейва и бэкапа можно использовать не только утилиту pg_basebackup, есть и совсем простой вариант:
-
запустить pg_start_backup();
-
затем перенести файлы на резервную копию на уровне ОС;
-
потом сделать pg_stop_backup();
-
и донакатить те WAL-файлы, которые были созданы в процессе.
Подчеркну, что вам просто нужно создать слейв-базу, каким образом вы это сделаете – это ваше решение.
Кроме утилиты pg_basebackup для создания бэкапов есть утилиты pg_probackup, wal-g (ext wal-e), barman, PGBACKREST.
-
Многие знают утилиту pg_probackup – ее поддерживают и выпускают наши отечественные коллеги из Postgres Professional.
-
Утилита wal-g сложнее, она умеет работать с облачными решениями – там другой технологический стек. Предшественником этой утилиты была утилита wal-e, ее развитие подхватили наши отечественные коллеги из Яндекса и сделали новое решение.
-
Есть еще PGBACKREST.
-
И есть barman – утилита со своим синтаксисом, плюсами и минусами.
Большинство из вновь созданных утилит поддерживают инкрементальный бэкап, иногда это тоже может понадобиться.
Как только вы начинаете работать с Postgre, вы понимаете, что pg_basebackup вас не устраивает, вам нужно что-то большее. Можете погуглить, поизучать альтернативные утилиты для бэкапов.
Донастройка STANDBY

Последний этап – донастройка STANDBY-базы. Вам необходимо убедиться, что параметры конфигурирования в мастере и на слейве совпадают.
В мастере должно быть включено то, что показывает, что у вас есть стендбай сервер:
hot_standby = on
На слейве должен быть включен standby_mode:
standby_mode = on
Параметр wal_receiver_timeout влияет на то, через какой период времени база данных будет понимать, что таймаут для приема WAL-файлов уже истек.
В документации Postgre эти параметры хорошо расписаны, обязательные и самые интересные я указал на слайде.
Проверки

Как проверить, что слейв работает?
К сожалению, в PostgreSQL нет инструментов с графическим интерфейсом по определению состояния кластера, но вы можете выполнить команды в командной и посмотреть:
-
в том ли у вас режиме восстановления находится база:
select pg_is_in_recovery(); -
посмотреть статистику со standby через вьюху pg_stat_replication:
select * from pg_stat_replication ; -
посмотреть наличие процессов wal sender и wal receiver в Linux – эти процессы должны присутствовать на мастере и слейве, чтобы обеспечить донакат WAL-файлов, о которых я говорил:
ps auxf
Это минимальный диагностический механизм, чтобы проверить, что слейв работает корректно.
В журнале событий можно увидеть ошибки, как при передаче, так и при получении – это тоже иногда полезно смотреть.
Как автоматизировать поднятие кластера
Все сложно, куча непонятных команд – зачем это знать и проверять руками? Неужели нет решений, которые обеспечат обычный FAILOVER, чтобы реализовывать стандартную отказоустойчивость – автоматически поднять резервную базу, чтобы она стала мастером. Не думать о том, что что-то случилось, чтобы клиенты в случае неполадок могли спокойно продолжать работу.
В коробочном решении PostgreSQL такого механизма переключения нет, но есть отдельные проекты, которые позволяет это реализовывать.
FAILOVER – это стандартная процедура, которая в PostgreSQL закрывается не одним и не двумя разными распространенными решениями, по которым мы сейчас пробежимся.
Большинство решений идут для Linux-like, поэтому проверяйте, работает ли это на Windows и сможете ли вы это использовать в своей инфраструктуре.
Ситуация со SPLITBRAIN также может быть неочевидной, может некорректно обрабатываться некоторыми утилитами, поэтому неплохо бы смотреть документацию, насколько там все хорошо проработано.
Подробная таблица сравнения решений для репликации есть в документе https://wiki.postgresql.org/wiki/Replication,_Clustering,_and_Connection_Pooling.
Давайте посмотрим, какие решения у нас присутствуют.
PGPOOL-II
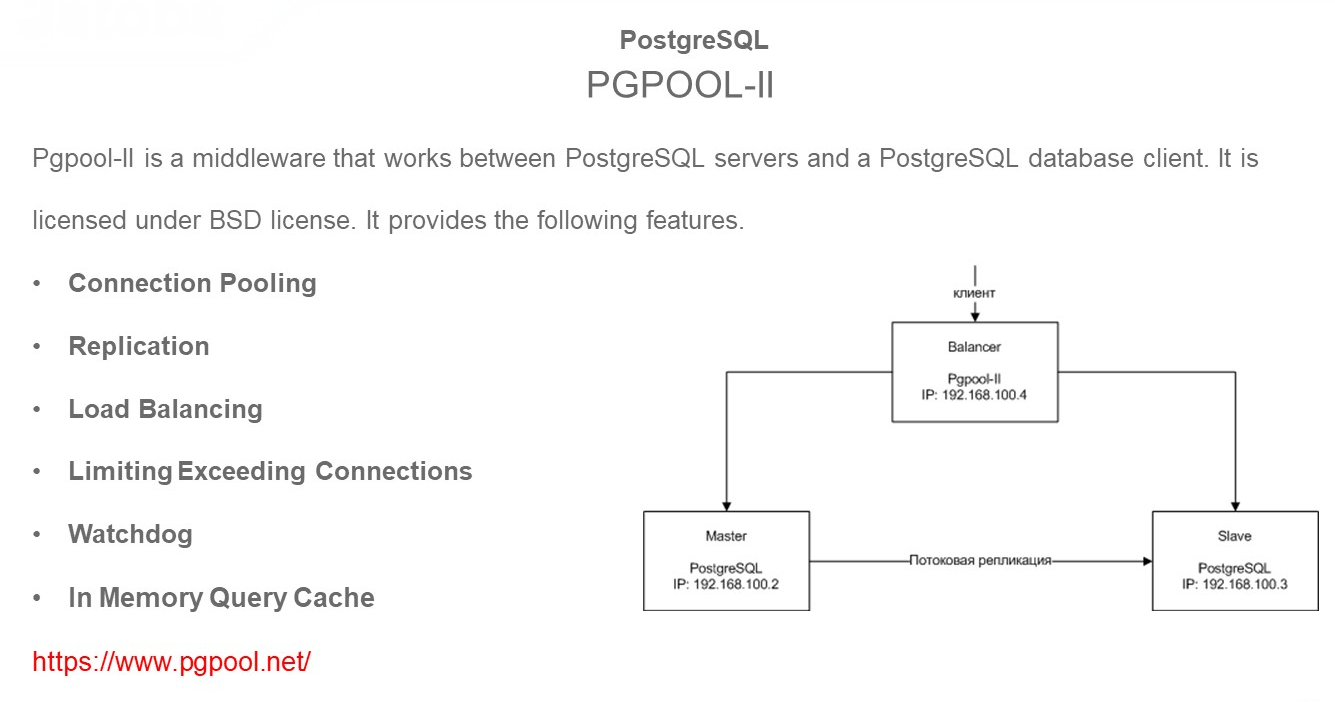
Начну не с самого очевидного и популярного – скажу про PGPOOL-II.
Это отдельная утилита, которая забирает на себя входящий трафик, и, контролируя сервера в кластере, определяет, куда этот трафик можно настраивать.
Этот инструмент может выполнять следующие роли:
-
Connection Pooling – забирать весь входящий трафик, при этом не контролируется количество соединений на СУБД.
-
Replication – он контролирует и помогает настраивать репликацию. То, что я вам рассказывал про команды создания вручную в PostgreSQL, он умеет настраивать сам и преднастроенные скрипты для выполнения у него есть.
-
Load Balancing – может выполнять балансировку нагрузки на read-only узлах. Если вы знаете, что для определенных отчетов определенные SQL-команды должны уходить на узлы read-only, можно в конфиг-файле настроить и использовать. Хотя для 1С это будет очень непросто, но такая функция у него есть.
-
Limiting Exceeding Connections – позволяет ограничивать использование памяти, предполагая использование кэша.
Это не простой FAILOVER. это утилита, которая позволяет работать с большим набором функций.
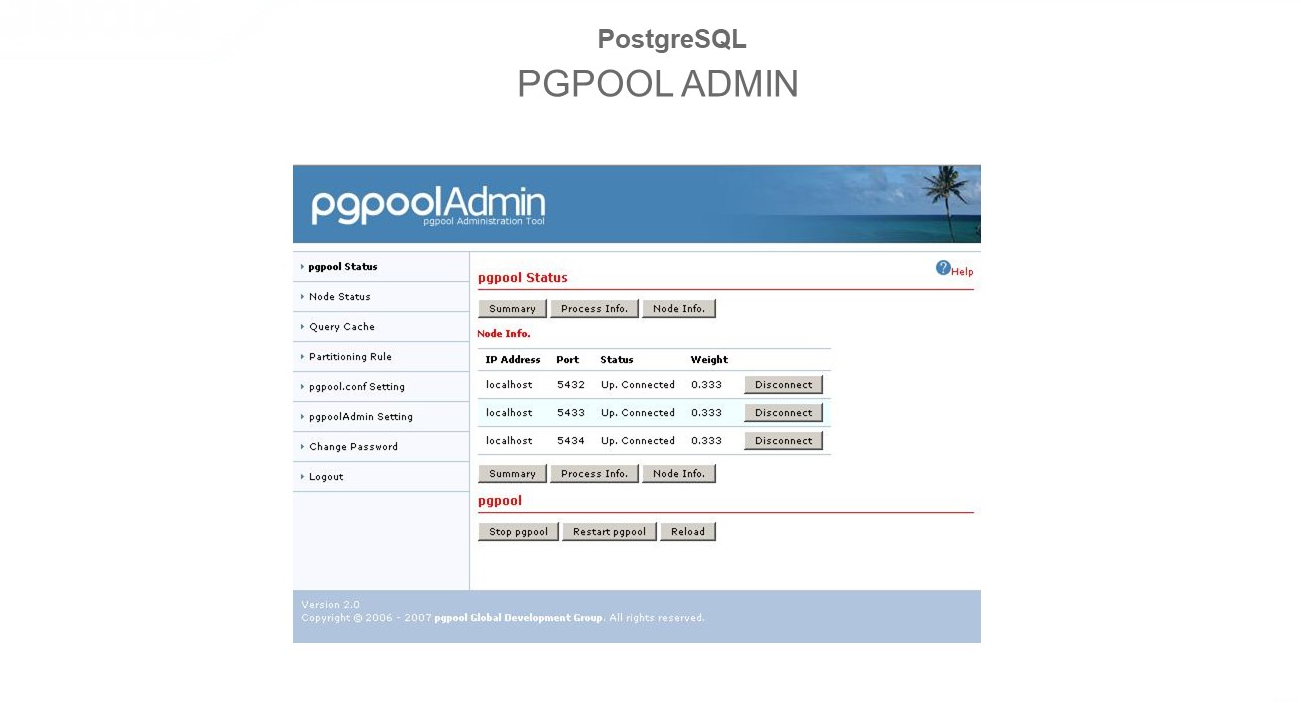
У утилиты PGPOOL-II есть отдельный, достаточно скромный интерфейс – это PGPOOL ADMIN.
Вы можете управлять этим решением кнопками и посмотреть, сколько серверов у вас есть. Подключиться, посмотреть статистику и т.д.
Даже если PGPOOL-II принимал автоматические решения, вы можете эти результаты тут увидеть.
Плюс администрировать ее здесь можете.
Patroni

Про Patroni сегодня в отдельном докладе рассказал Семен Трошкин.
Это отличное решение под Linux, которое строится на ZooKeeper, etcd и Consul. В Windows вам будет сложно его использовать.
Помните о том, что если вы делаете кластер, то Patroni вы можете использовать только тогда, когда у вас есть серверы на Linux.
CITUSDATA

Расширение для PostgreSQL Citus Data попало в мой доклад не потому, что это рекомендуемое решение для High Availability, а потому, что с его помощью можно построить на PostgreSQL хорошее горизонтальное масштабирование – распределить нагрузку между базами, используя шардирование.
Расширение Citusdata в поставку PostgreSQL для 1С не входит, но если вам нужно использовать шардирование и распределить нагрузку между разными базами, оставив их на read/write, то помните, что такое решение в семействе PostgreSQL есть.
Pgbouncer и HaProxy

Готовые решения под названием Pgbouncer и HaProxy нужны не для того, не для обеспечения отказоустойчивости и переключения FAILOVER. Эти решения нужны, чтобы распределять нагрузку и обеспечивать экономию ресурсов на серверах PostgreSQL в связи с тем, что каждый клиент PostgreSQL – это отдельный процесс с выделенными ресурсами на сервере PostgreSQL.
Если у вас много клиентов, на сервере это становится проблемой. Когда клиентов больше 1000, реально нужно экономить и взаимодействие между этими процессами становится проблемой для самой СУБД.
Поэтому, если в приложении нет стандартного пулинга, приходится думать, какой же пулинг использовать.
У нас есть опыт работы с Pgbouncer и HaProxy. HaProxy замечательно работает не только с СУБД – с его помощью можно также достаточно хорошо можно перенастраивать трафик на уровне TCP.
Но эти решения опять же можно использовать только в Linux, а вот в Windows они не работают. Мы даже пробовали их пересобрать, чтобы использовать на Windows, но это оказалось слишком сложно и остановились на другом решении.
Bi-Directional Replication
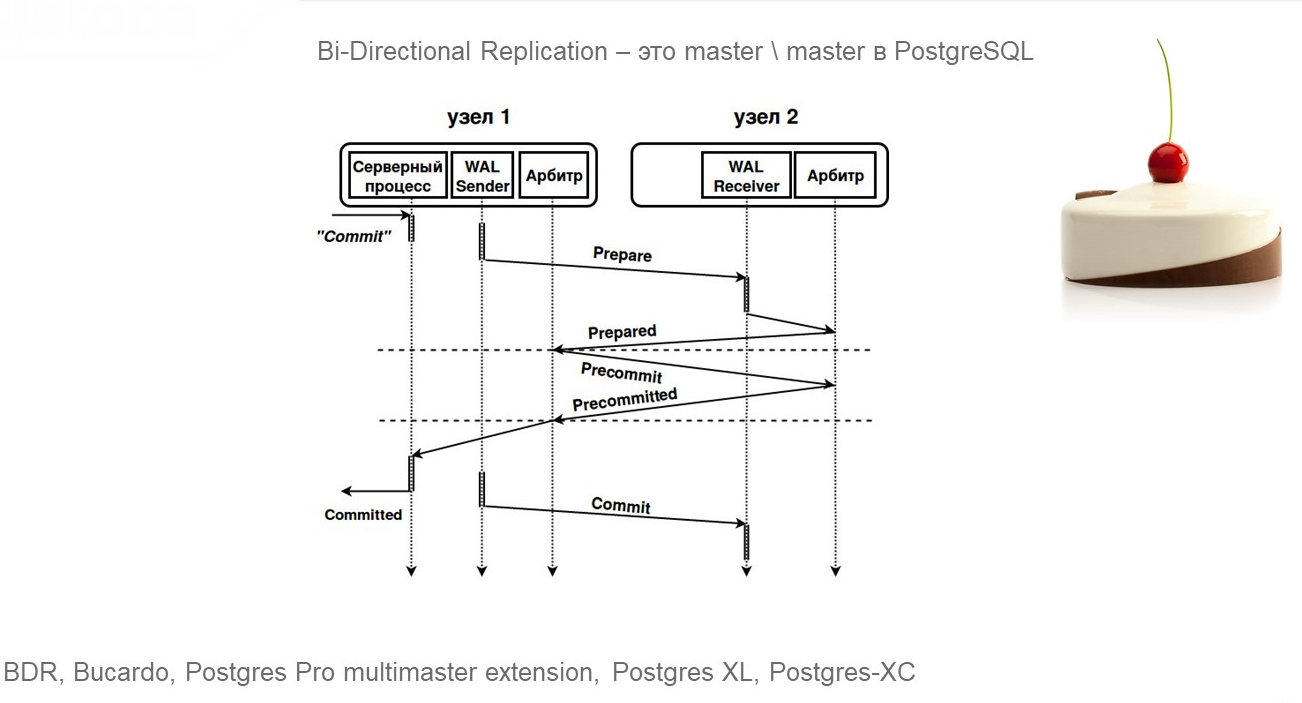
Bi-Directional Replication – интересная фича. Та самая функция, когда вы, выполняя одну транзакцию, можете убедиться, что она попала на резервный сервер.
Здесь идет использование двух-трех серверов в режиме read/write.
Выглядит это шикарно – когда у вас много серверов. они все работают на read/write, вы можете работать с любым из них.
Но здесь нужно помнить, что как и в MS SQL Server, здесь у вас будут задержки при синхронизации транзакции. Вам нужно подтвердить получение на резервном сервере, только после этого транзакция становится закоммиченной – это та многофазность транзакции, которая используется во всех решениях master/master.
В бесплатных версиях PostgreSQL поддержку Bi-Directional Replication вы можете найти только в очень древних версиях, которые вы не сможете использовать для 1С.
Но такая возможность есть в платных решениях отечественных производителей – Postgres Pro multimaster extension, Postgres XL, Postgres-XC.
В Bucardo такая возможность тоже есть. И иностранный вендор 2ndQuadrant в решении BDR тоже используют технологию Bi-Directional Replication для реализации кластерных серверов в режиме master/master.
Можно ли использовать эту технологию для серверов больше 3-5? Наш опыт показывает, что вряд ли. Мы использовали для двух серверов с хорошей нагрузкой. Лаг при подключении – минимальный, у вас будет работать практически два мастера. Но при этом будут действовать ограничения, которые есть на физической репликации.
По этой и некоторым другим причинам работоспособность этой технологии, на наш взгляд, под вопросом.
Jatoba
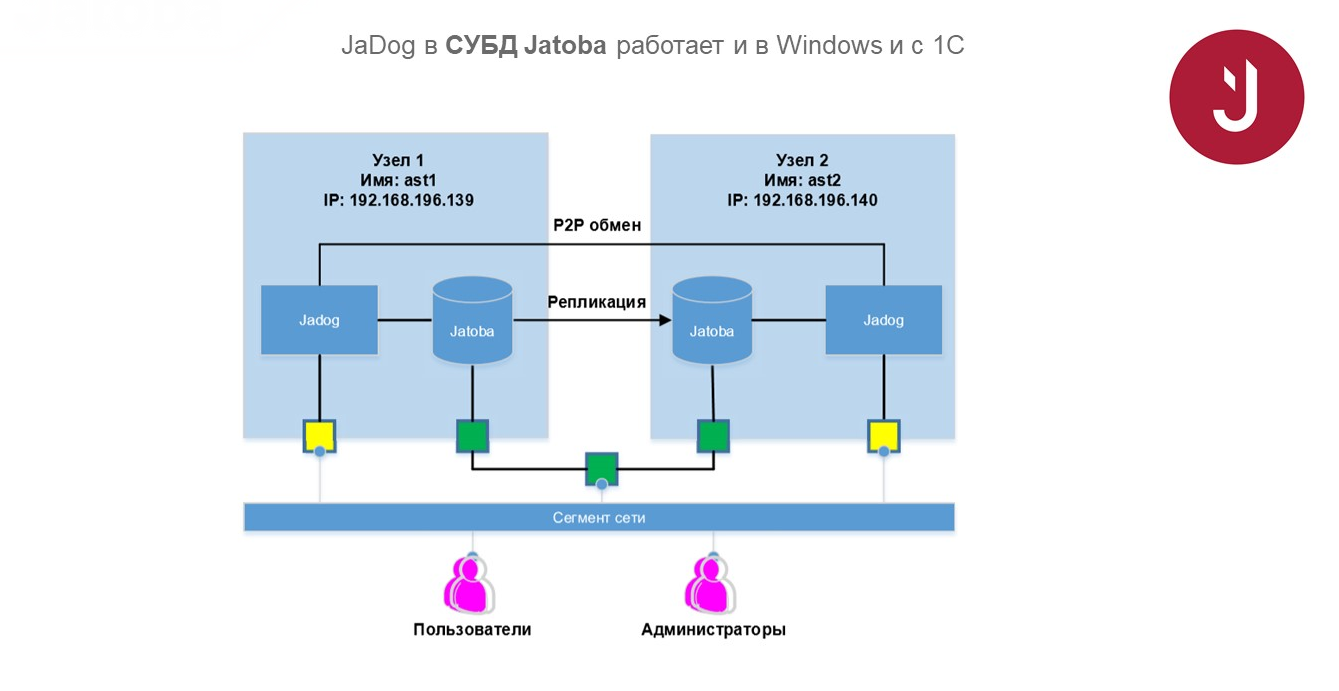
В СУБД Jatoba нами написан отдельный агент, обеспечивающий переключение нагрузки. Он контролирует, что с ним происходит, и автоматически принимает решение, куда переключиться.
Это позволяет избавить администратора от принятия решений вручную – наши утилиты делают это автоматически.
Возможность настроить PostgreSQL для работы с WSFC
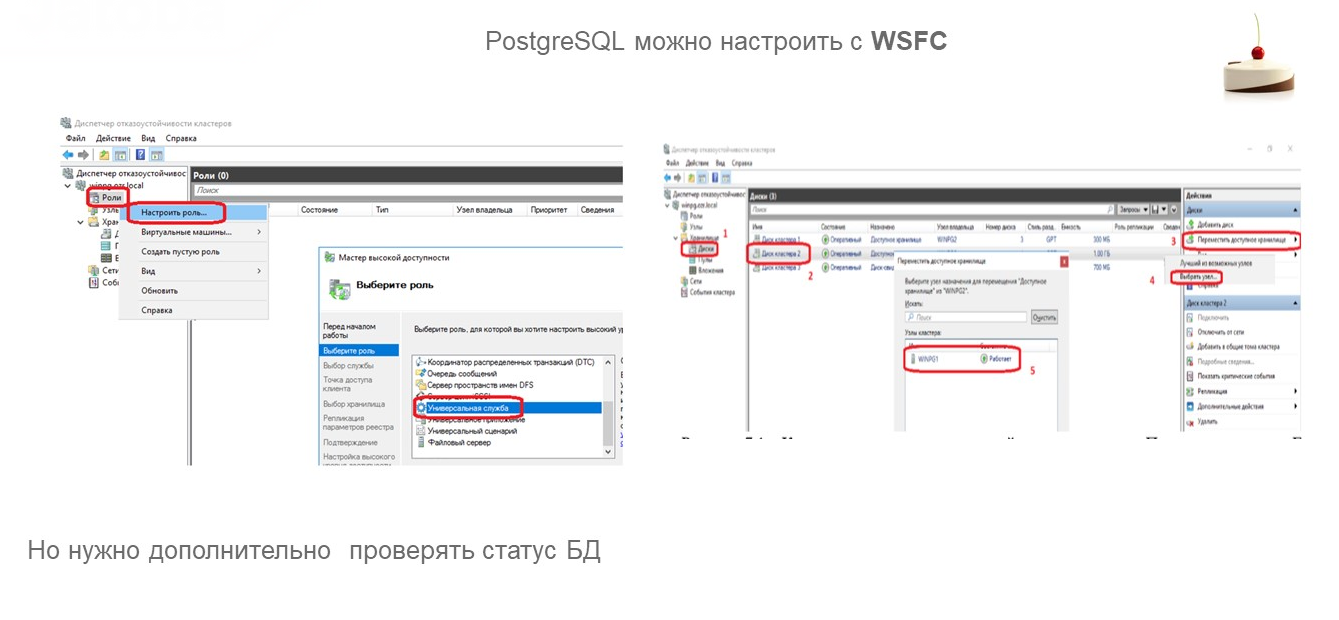
Можно ли на Windows PostgreSQL подключить к WSFC так же, как и MS SQL Server?
Да, вы можете в Windows добавить службу PostgreSQL Server так же, как обычную службу MS SQL Server.
Там есть нюанс, потому что автоматически статус подключения определяться не будет, плюс нужно будет запускать отдельные скрипты, которые будут пытаться подключиться к СУБД и активировать слейв, мастер – помогать кластеру WSFC принять решение о том, что пора мигрировать.
У нас такие скрипты есть. Если кого-то интересует, как это настроить – пишите в комментарии. Я скажу, каким образом настроить на Windows кластер WSFC с PostgreSQL любой конфигурации – даже с Postgres Pro Enterprise заработает.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "PostgreSQL VS Microsoft SQL".

Вступайте в нашу телеграмм-группу Инфостарт