Ранее я работал в компании, которая предоставляет ИТ-услуги и является одним из крупнейших поставщиков РФ по продаже ПО и оборудования. У нас стояла задача отдавать очень много данных из 1С для построения различных отчетов в системах Business Intelligence.
Расскажу, как все у нас было устроено – как мы пришли к такой архитектуре решения, какие вообще бывают способы передачи данных для их анализа в BI-платформах. И заодно на примере трех крупнейших BI-платформ – Power BI, Tableau и QlikView сравним, как эти способы интеграции с 1С работают «из коробки».
Начальные условия

Дано:
-
сильно переписанная УПП, почти полностью на управляемых формах, работающая на платформе 8.3.14 с режимом совместимости 8.3.13;
-
компания – «белая», ежегодно проходит аудит у «Большой четверки» и у Microsoft;
-
нам каждый день необходимо давать пересчитанные данные по отчету, в котором миллионы строк – данные по нему пересчитываются раз в день, и мы не можем сохранять их заранее;
-
у нас есть отдельная команда BI, которая занимается всей этой историей.

Давайте рассмотрим способы, которые позволяют быстро провести интеграцию 1С с BI с минимальным изменением конфигурации или вообще без него, это:
-
OData;
-
файл;
-
HTTP и веб-сервисы.
OData

OData – это самый простой способ интеграции со стороны 1С для разработчиков. Он представляет собой автоматический REST-интерфейс, который поднимается на стороне 1С и позволяет получать и изменять данные в 1С.
Для использования – все очень просто, нужно:
-
опубликовать базу;
-
опубликовать состав доступных объектов OData;
-
и дело в шляпе.
Формируем строку запроса на получение данных из какой-либо таблицы, и аналитики BI на своей стороне могут крутить, как хотят. Если вы сами поднимаете аналитику – можете сами все это настроить.
Проблемы могут возникнуть, если мы обратимся к справочнику или к регистру сведений с миллионами записей – мы рискуем долго прождать, пока 1С сформирует всю информацию о справочнике или регистре. Требуются очень большие мощности, и 1С не всегда может выдать все, что нам нужно.
Но такой обмен вполне подходит, если мы один раз загрузили в BI информацию, а потом обновляем ее редко или какими-то другими способами. Или, если у нас в базе не очень много информации – тогда мы можем спокойно подключить в состав интерфейса несколько разных объектов, и потихоньку подгружать их в BI.
-
На этапе запроса можно наложить различные фильтры: ограничить список выбираемых полей.
-
Ссылочные типы изначально отдаются как гуиды, поэтому если реквизиты нужны из нескольких таблиц, мы можем вытащить несколько таблиц и соединить их по гуидам.
-
Если нам достаточно одной таблицы и не нужны дополнительные соединения – можно передать в BI представления полей и сформировать там на их основе информацию.
-
Но если нам нужны данные, которые формируются на основе нескольких запросов к различным таблицам – здесь мы OData применить не сможем:
-
либо нужно будет эмулировать этот запрос самостоятельно обращением к нескольким таблицам на стороне платформы BI;
-
либо мы должны заранее рассчитать все нужные данные на стороне 1С и положить их в отдельную таблицу (регистр сведений), откуда OData их сможет забрать напрямую.
-
Так как OData позволяет и забирать, и записывать данные, возможно, для обмена платформой с BI, нам нужно забрать у пользователей, которые будут подключаться к базе, права на запись объектов – оставить только права на чтение, чтобы исключить несанкционированную запись объектов в базу.
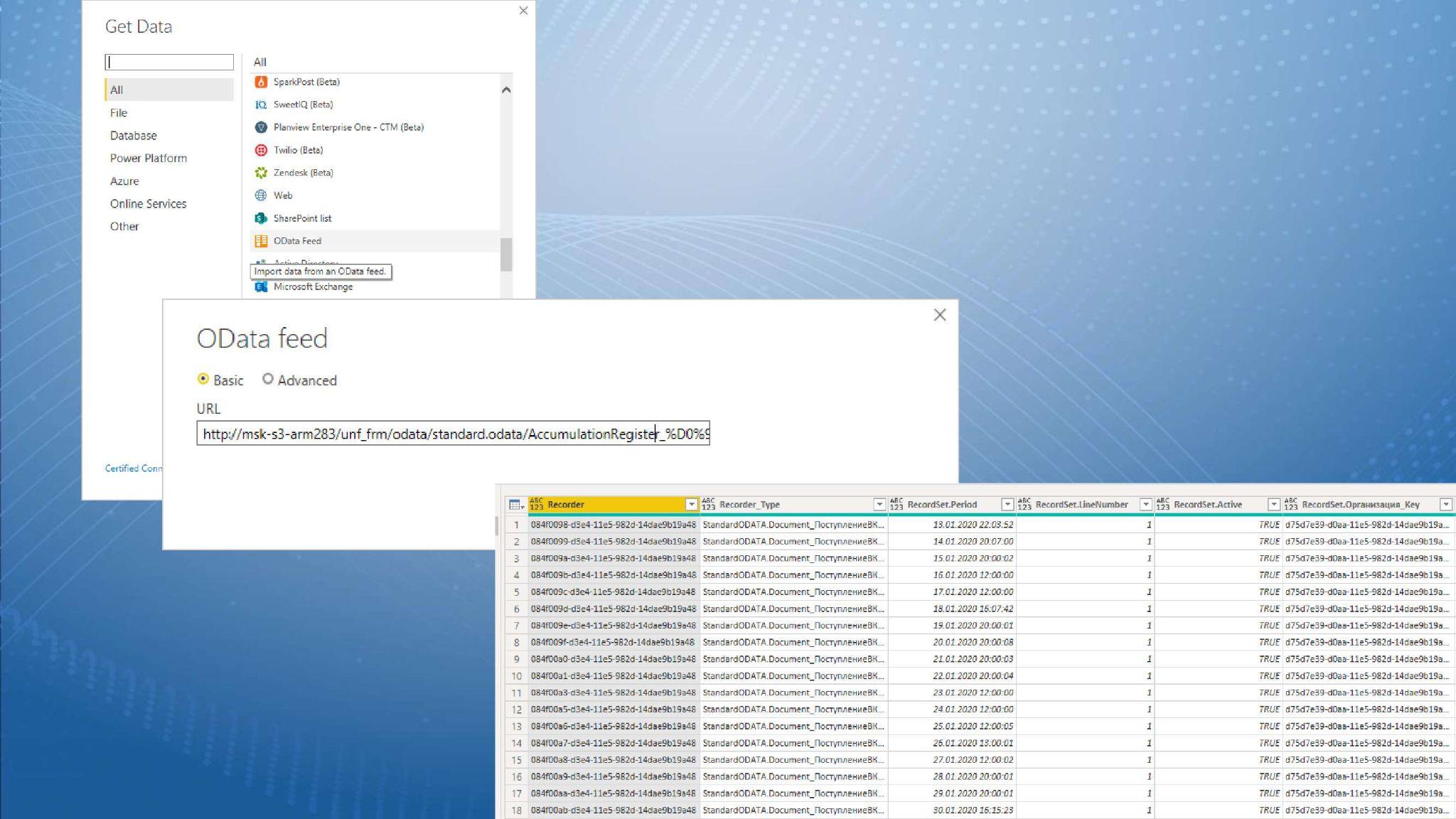
Расскажу на небольшом примере, как работает подключение коннекторов BI к 1С через OData.
Предположим, мы хотим получить информацию о доходах и расходах в разрезе проекта из базы «Управление небольшой фирмой», заранее опубликованной, с опубликованным составом OData.
На слайде показано создание коннектора OData в бесплатной версии Power BI Desktop (также для подключения через OData можно использовать стандартные возможности Qlik и Tableau).
Пишем строку запроса к регистру накопления «ДоходыИРасходы», получаем данные, которые в нем хранятся, и можем их использовать.
Как видите, здесь у нас хранятся гуиды – я решал задачу «в лоб», представления не вытаскивал.
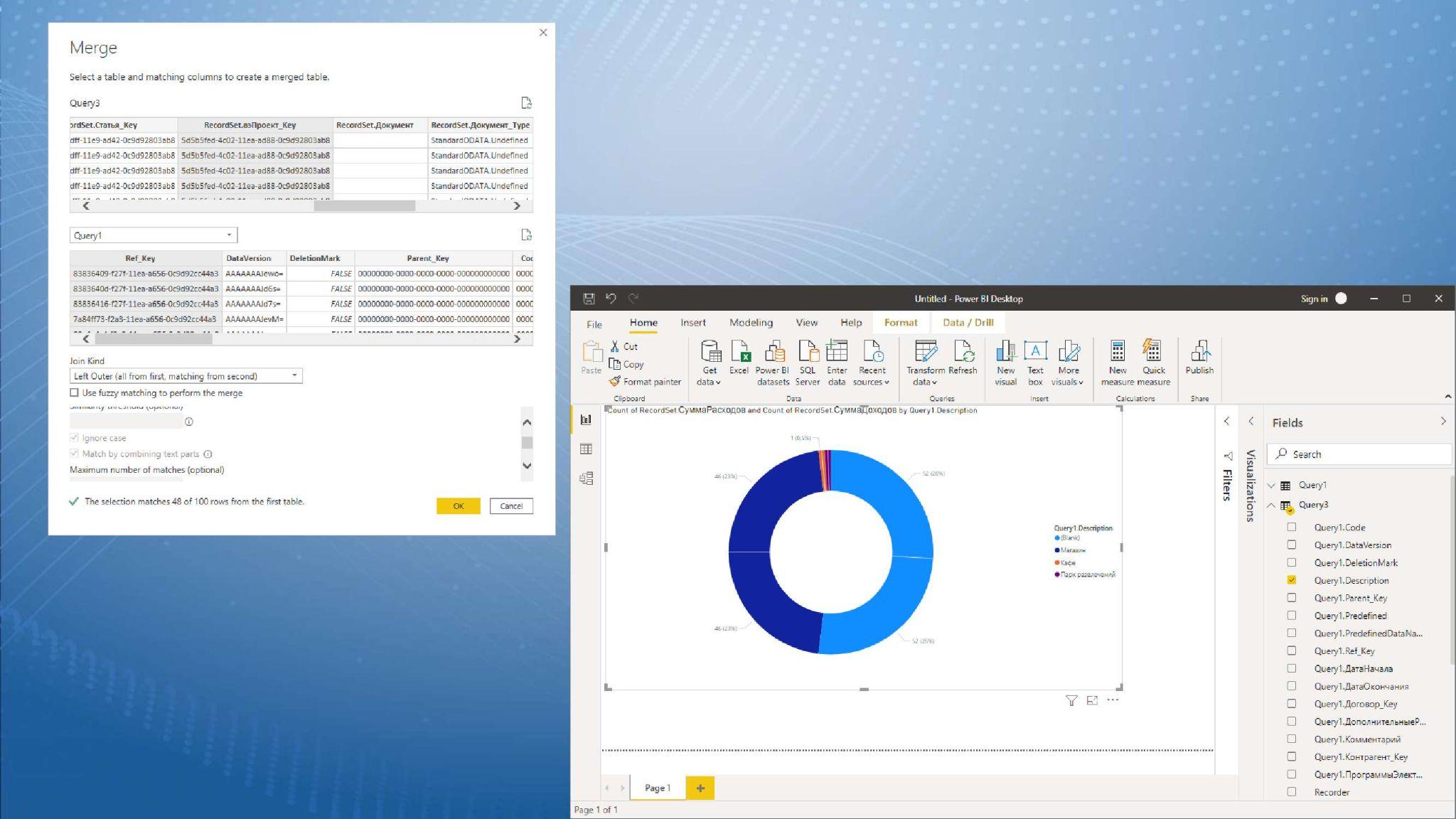
Следующим запросом я вытащил табличку проектов.
Потом соединил эти две таблички обычным левым соединением по гуиду проекта и сформировал диаграмму, которая показывает, какое количество записей по какому из проектов было.
Это просто и быстро, заняло 10 минут. Как начальный способ интеграции, чтобы что-то посмотреть, проверить какую-нибудь модель – отлично подходит.
Как обновлять данные на стороне Power BI – через OData и другие способы?
Есть несколько режимов.
-
Один способ – режим импорта, когда мы запрашиваем данные, Power BI и другие системы хранят их на своей стороне, они не обновляются автоматически. Для обновления нужно нажать рефреш или настроить расписание – в бесплатной версии Power BI Desktop количество подключений в расписании ограничено 8 раз в день.
-
Если подключаемся к сторонней SQL-базе напрямую, мы можем настроить онлайн-обмен. Это будут OLAP-кубы, запросы к которым будут строиться напрямую, и обновлять источник заранее не нужно будет.
Интеграция через файл
Для платформ BI мы можем выгрузить файлы в формате json, xml, Excel, прямо в текст с нужными нам разделителями – все, что поддерживает выбранная вами платформа аналитики.
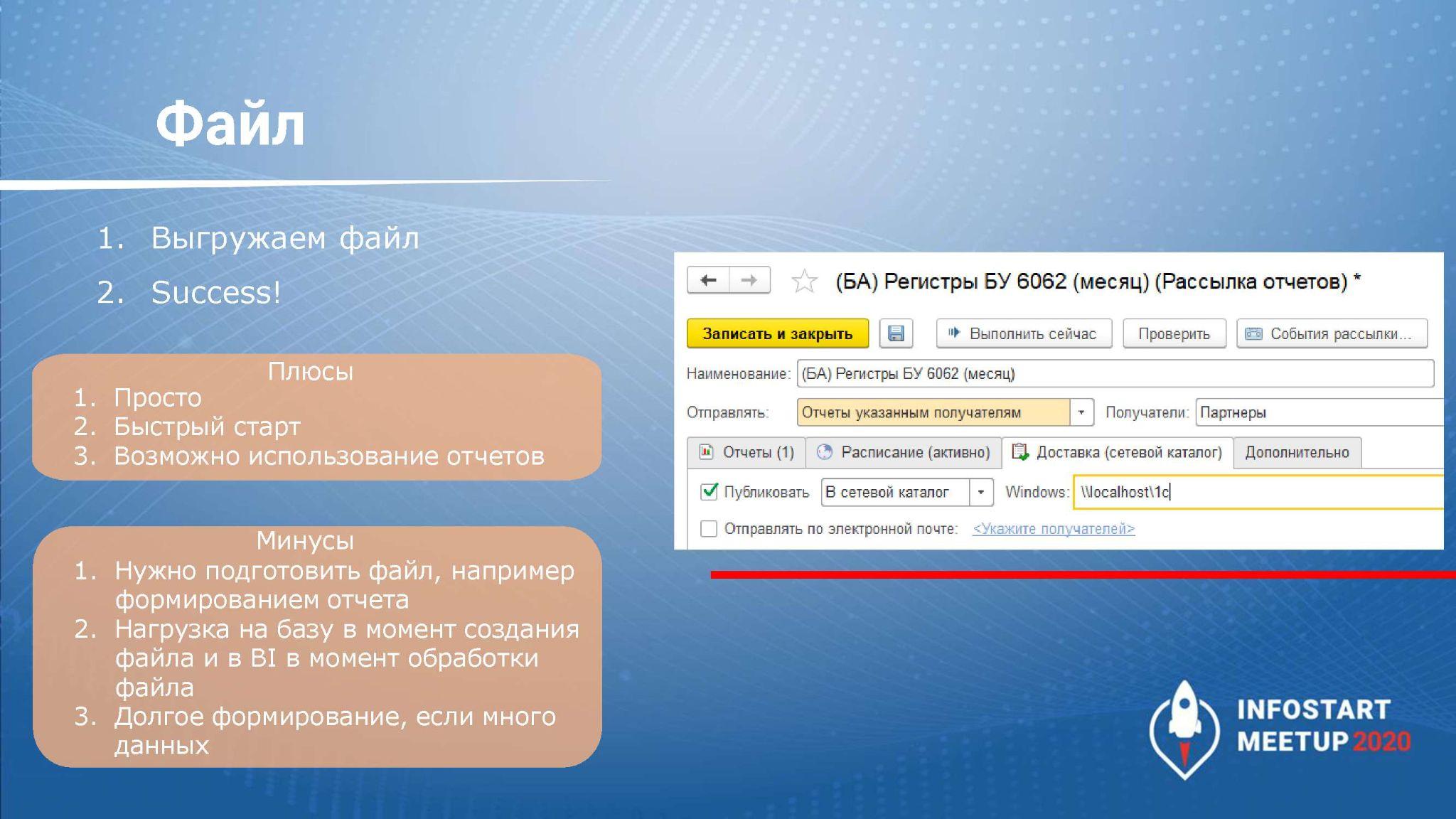
Например, в системе БСП есть рассылка отчетов, которая помогает формировать отчет СКД. Сохраняете его в сетевой каталог, и в дальнейшем платформа BI на своей стороне будет подтягивать данные из этого отчета, мы сможем их крутить, дополнять аналитикой и соединять с другими отчетами, строить дополнительный анализ.
Опять же, у нас есть те же проблемы, что и ранее:
-
если данных много – файл долго будет сохраняться физически;
-
плюс – его надо как-то сформировать, придумать, какие будут данные – если нам не нужны гуиды и соединения, то нужно сохранить представления;
-
если нужны данные из нескольких таблиц – нужно придумать, будем мы их передавать на разных листах Excel-файла или сохранять в отдельных файлах, а потом соединять их между собой на стороне OData.
Вопросов много, но способ интеграции через файлы достаточно простой – с этим все платформы BI с файлами работают прекрасно, проблем с коннекторами возникнуть не должно.
HTTP и web-сервисы

Для интеграции с BI можно использовать HTTP и web-сервисы.
-
У платформ BI есть такая функциональность как подключение к веб-странице. Мы можем написать запрос к какой-то веб-странице, и система автоматически вытащит оттуда данные на основе тегов table. Соответственно, данные на веб-странице можно обрабатывать. Например, нам служба безопасности запрещает формировать файл для интеграции с платформой BI – опасается, что к этому файлу кто-то получит несанкционированный доступ. В этом случае мы можем отдать данные в формате отчета СКД прямо в HTTP-сервисе, эмулируя HTML-страничку – запихнув эти данные в тегах table. И на своей стороне BI-платформа сможет эти данные прочесть и распознать.
-
Еще есть вариант: так как формат OData известен, его описание понятно, и мы можем по обращению к HTTP-сервису на стороне 1С отдать данные в формате OData. Конечно, через файл было бы проще, но если мы не можем использовать файл, такой вариант тоже возможен.
Если у нас 1С выступает для BI не мастер-системой, а является только одним из источников, мы можем стучаться в 1С по расписанию, чтобы забрать конкретные данные или сказать: пришло время, чтобы выгрузить эти файлы в табличку.
Это – оснастка, которая нам поможет данными обмениваться. Мы можем отдавать данные по конкретному гуиду или измерению регистра, можем отдавать данные в сериализованном JSON-виде – все зависит от требований и собранной архитектуры.
Как отдавать данные из 1С посложнее
Простые способы я рассмотрел – они хороши тем, что можно не модифицировать конфигурацию. Если у нас типовая конфигурация, и мы не хотим ее снимать с поддержки, то:
-
OData подходит отлично;
-
HTTP и веб-сервисы мы можем опубликовать в расширении;
-
а файл мы всегда можем сформировать подключением дополнительной обработки с выгрузкой по расписанию.
Перейдем к способам посложнее.

Если у нас данных очень много, и предыдущие способы не подходят либо данные нужны сразу после изменения – какие у нас есть способы?
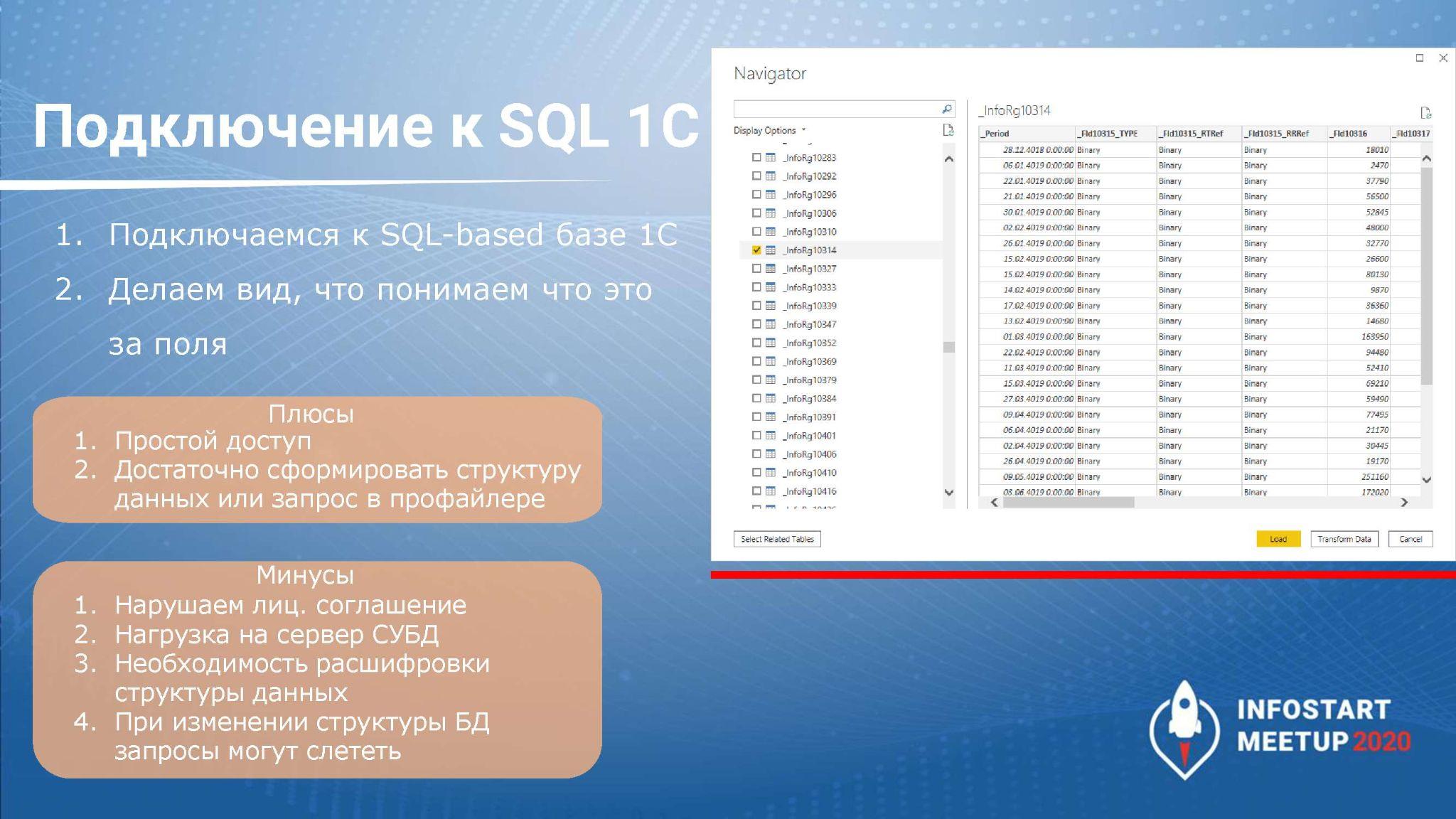
Первый способ – подключение напрямую к SQL-базе 1С.
Многие знают, что структура хранения в 1С не показывает синонимы объектов, как они хранятся в 1С-формате. Когда мы впервые подключимся к этой базе, увидим странные записи типа _InfoRg<n>, и все реквизиты будут ссылаться друг на друга – не сразу понятная структура.
Плюс подключение напрямую к базе 1С через SQL нарушает лицензионное соглашение 1С, хотя можно договориться с фирмой о таком прямом подключении. Об условиях не знаю, но такие случаи точно есть. Например, «ВкусВилл» и другие крупные клиенты, которые пользуются 1С, но им недостаточно мощностей.
На стороне BI это будет либо прямое подключение к SQL-базе, либо подключение через коннекторы OLE DB или ODBC. В результате на стороне BI можно будет эмулировать запросы, но в качестве табличек у нас будут выступать вот эти странные названия.
Чтобы сформировать понятные наименования таблиц и понять, какой запрос отправить, есть несколько вариантов:
-
сформировать изначальную структуру данных и отдать ее аналитику – он будет понимать, какой таблице какое имя соответствует, и сможет писать запросы;
-
либо мы можем ловить формат запроса на стороне профайлера SQL и отдавать этот запрос в платформу BI – таким образом формировать аналитику на стороне BI-платформы.

Логичное развитие предыдущей истории – коммерческий коннектор.
В коммерческих коннекторах уже есть структура расшифрованных данных, и в зависимости от того, какие запросы он умеет делать – есть ли у коннектора только View или есть еще промежуточная SQL-база – мы либо можем сформировать запрос для платформы BI, либо через запросы эти данные перегоняем в стороннюю SQL-базу, и уже BI обращается к ней напрямую.
Коммерческий коннектор – это упрощение прямого доступа в SQL-базу, он имеет все те же плюсы и минусы, но работать с ним немного проще.

А что делать, если мы не хотим подключаться напрямую к базе 1С – не хотим, нет доступа, боимся – какие у нас есть варианты?
Можно использовать промежуточную базу SQL: собственную или в формате хранилища данных, которое используется в компании.
Здесь есть несколько способов подключения:
-
либо через внешний источник данных;
-
либо через коннекторы – например, через COM-коннектор ADO.NET, если у нас Windows.
Если у нас Linux, остается только вариант со внешним источником данных.
О том, как передавать данные и какие таблицы писать – зависит от того, какие отчеты вы будете формировать, и от той структуры, которая у вас уже есть в хранилище данных вашей компании.

Но что делать, если нужно поддерживать транзакционные или событийные изменения – передавать данные в BI сразу, как только они изменятся?
В этом случае мы можем осуществить обмен через шину или брокер очередей. Либо у нас будет промежуточная база, в которую мы будем класть данные.
Это не назовешь отдельным способом интеграции с BI, но это помощник, который помогает положить данные туда, куда нужно.
Этот вариант может пригодиться, если мы хотим сделать первоначальный снимок всех нужных таблиц нашей базы 1С, а дальше поддерживать событийную интеграцию и сразу фиксировать все измененные данные в промежуточной базе, куда будет обращаться BI-система.
Для этого на стороне 1С мы должны просто фиксировать изменения объектов, и сразу, как только они изменятся, передавать их на сторону промежуточной базы. Это удобно делать через планы обмена или через какой-то регистр – в зависимости от того, как это у вас организовано.
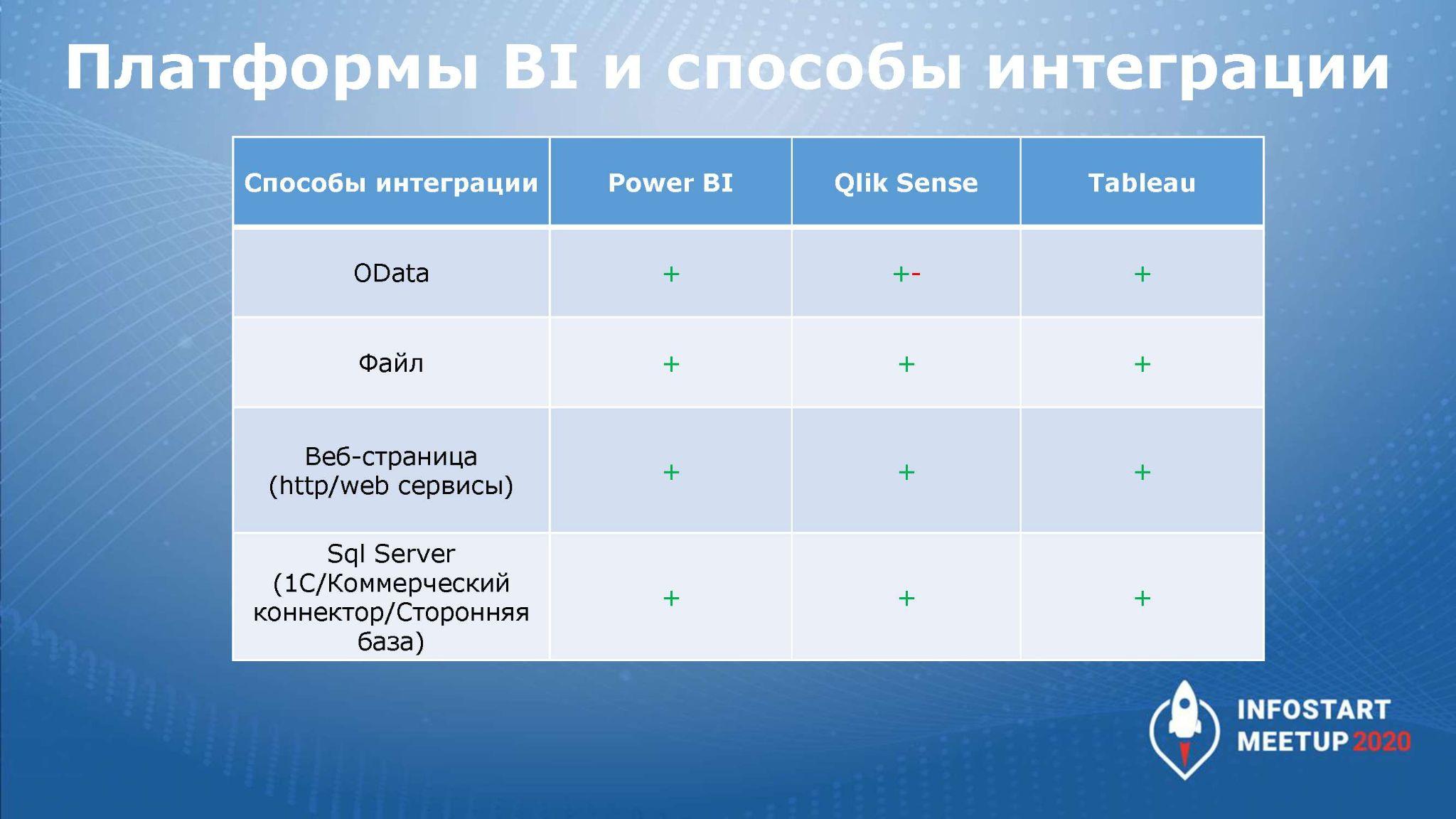
На слайде показана табличка с основными способами интеграции, которые поддерживаются в крупнейших BI-платформах.
Для нас с точки зрения интеграции с 1С выбор BI-платформы не имеет значения, здесь все будет зависеть уже от других факторов – от цены, от визуализации и т.д.
Как мы решали задачу

Перейдем к задаче, которую мы решаем. Расскажу, что, как и где мы делали.
У нас стоит задача – менеджеры хотят видеть продажи в разрезе подразделений и вендоров вплоть до конкретного заказа покупателя. Нужно видеть, сколько маржи принес заказ. Причем маржа считается в различных разрезах – по облакам, по ПО, по железу (в терминах 1С наш регистр продаж имеет около 15 измерений и 50 ресурсов).
На начало дня данные в BI-системе всегда должны быть актуальны.

Сначала мы попробовали решить задачу «в лоб».
У нас в компании уже был Power BI, и он всех устраивал, потому что на большое количество компьютеров можно было поставить бесплатную версию, ее хватало.
Данные, которые нам нужно отдать в BI, находились в нескольких регистрах. Если делать такой отчет на СКД, мы получим около миллиона записей за день, но так как данные мы отдаем помесячно, у нас формируется отчет на 15-20 млн записей.
Причем, на СКД у нас такой отчет уже был, он нормально работал, но мы в нем выводили совсем мало аналитик, и все записи были сгруппированы, поэтому строк получалось гораздо меньше. А в BI мы хотели видеть аналитику по всем измерениям, поэтому при передаче данных мы строили плоскую таблицу с миллионами записей.
-
Такой отчет с данными для BI у нас формируется 45 минут, но начать его формировать мы можем только после того, как предыдущий день закроется. Многие из вас знают, что в 1С есть «Закрытие месяца», у нас была такая же процедура, но в конце каждого рабочего дня. Поскольку «Закрытие дня» идет несколько часов, данные для BI мы можем начать отдавать уже ближе к утру, в 5-6 часов утра.
-
Результаты отчета мы сохраняли в Excel-файл, но при сохранении миллионов записей система подвисала – файл в итоге сохранялся, но это занимало до 10 часов.
-
Получалось, что общее время отдачи данных до поступления обновленных данных в BI занимало почти 20 часов – их можно было посмотреть в BI только к вечеру, т.е. по факту, на этом этапе мы отдавали данные в BI только за предыдущий день.
-
Кроме этого, в файле отчета мы передавали плоские данные, где в качестве элементов справочников были гуиды. А сами справочники мы передавали в BI через OData – она справлялась, но работала долго, потому что контрагентов у нас тоже было несколько миллионов. И пока наша 1С формировала данные, а Power BI их забирал, тратилось еще час-два времени.
Такая схема нам не подходила.
И, поскольку у нас уже использовалась интеграция BI с другими источниками данных, мы решили подключаться из 1С к промежуточной SQL-базе и использовать ее для дальнейшего анализа данных.
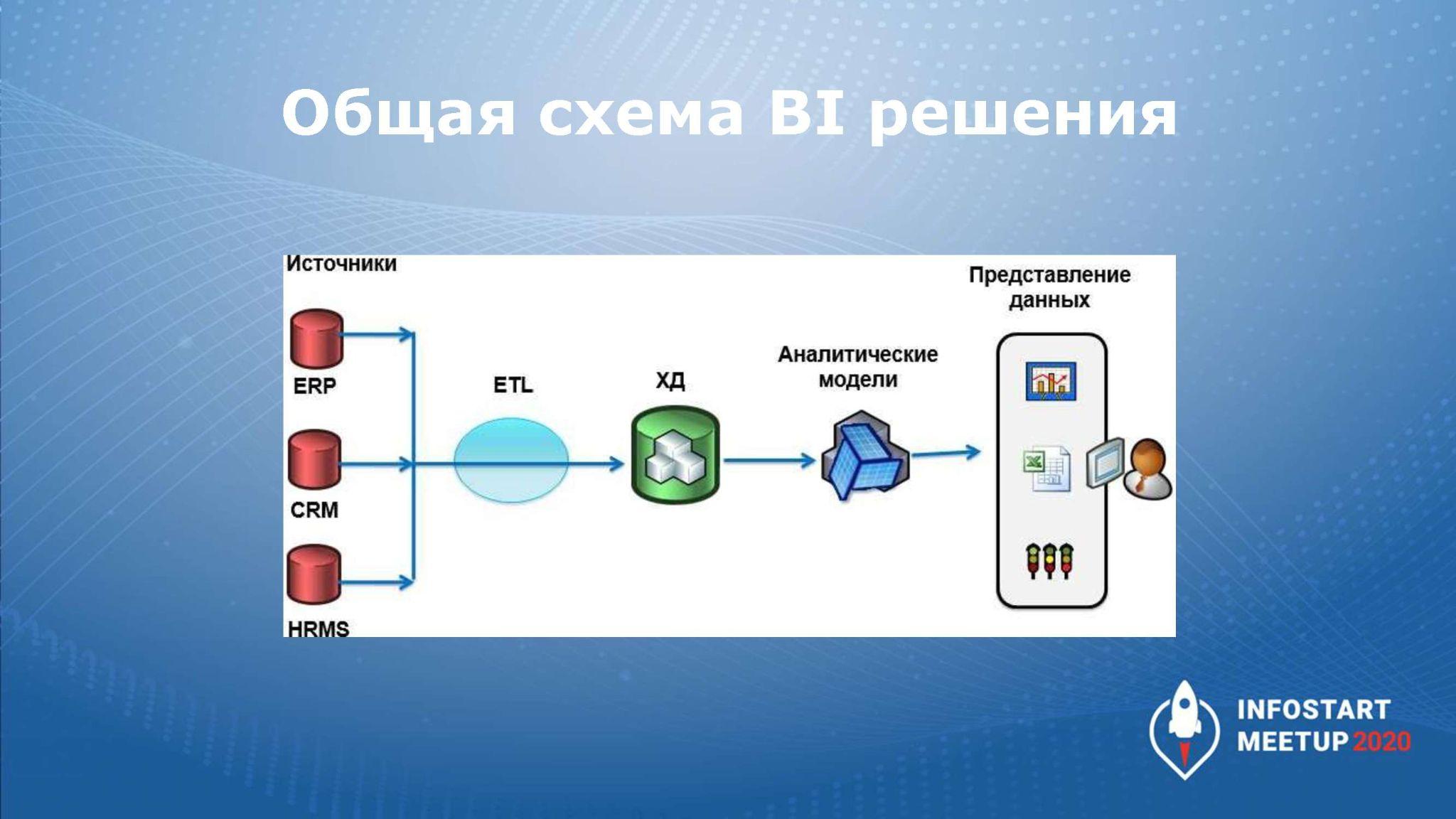
Что обычно из себя представляет схема, когда появляются промежуточные SQL-базы?
Данные поступают из нескольких источников, через процедуру ETL они трансформируются, кладутся в хранилище данных, и на его основе мы уже можем формировать какие-то данные в BI.
ETL – это аббревиатура Extract, Transform, Load, т.е. мы данные загружаем, трансформируем и передаем далее для анализа.

Здесь – небольшой обзорный слайд о возможностях настройки при интеграции с BI по этой схеме.
В данном случае, мы пытались решить задачу – как можно быстрее отдать данные со стороны 1С, поскольку для нас это было критично.

Переходим к следующему этапу: нам нужно отдать данные из 1С в стороннюю базу SQL.
Как я уже говорил, здесь у нас есть несколько вариантов – подключиться либо через внешний источник, либо через COM-коннектор ADO.NET, если у нас стоит Windows.
На первом этапе мы решили подключаться через ADO, потому что структура данных на стороне БД только формировалась – мы не знали, будет ли она меняться. Поэтому, чтобы не зависеть от этого и сильно не менять внешний источник, сделать через коннектор.
История пока такая же: происходит закрытие дня, после чего нам нужно отдать данные в BI. Здесь добавляем немного обвязки к обмену:
-
Администратор базы данных стучится в 1С по HTTP и спрашивает, можно ли забирать данные – если данные у нас рассчитались, мы их можем отдавать.
-
В этот момент мы формируем справочники в табличку SQL – они у нас были сериализованы через XDTO-пакеты – и отдаем на сторону BI.
-
После этого формируем нужный нам отчет по марже и его тоже передаем в табличке SQL – просто подключаемся, обходим все записи и обычным инсертом их вставляем, пока напрямую.
-
После того, как у нас завершилась загрузка, мы пишем строчку в табличку лога на стороне SQL-базы – на эту табличку стоит триггер, он понимает, что загрузка завершена успешно, и можно приступать к процедурам ETL.
В целом, у нас получилось сильно ускорить процесс плюс добавилась стабильность. Кроме этого, мы стали понимать, что и на каких этапах у нас происходит – мы добавили логирование всех событий, чтобы понимать, сколько времени это занимает.
Тем не менее, это было все еще долго – в зависимости от объема таблиц у нас запись в SQL-базу занимала до 5 часов. Плюс справочники отдавались около часа, и отчет формировался тоже долго.
На скрине виден кусочек обвязки – мы проверяем, есть ли уже таблица – если она есть, будем загружать ее, если нет – будем создавать таблицу для выгрузки данных из 1С.

Но надо было еще больше ускоряться, чтобы успеть отдать данные до 9 утра.
Думаем, что мы можем сделать.
Первое – мы решили, что нам незачем каждый раз отдавать справочники целиком, поэтому целиком мы отдаем их один раз, а дальше отслеживаем изменения и отдаем только измененные.
Для отслеживания изменений есть несколько способов – либо мы при каждой записи справочника кидаем его ссылку в какой-то регистр измененных объектов, либо отслеживаем изменения значимых реквизитов, и ставим объекты к обмену, только если эти значимые реквизиты поменялись.
Это тоже можно организовать несколькими способами.
-
С одной стороны, мы можем взять совокупность значимых атрибутов, сформировать его хэш и где-то сохранить – например, в обычном или дополнительном реквизите объекта. И потом при записи снова формировать хэш от наших значимых атрибутов и их сравнивать. Если они отличаются, мы понимаем, что наш объект изменился и его надо поставить в очередь к изменениям. Если не изменился – объект оставляем и не трогаем.
-
У нас для цели отслеживания изменений по значимым атрибутам объектов в базе была сторонняя подсистема – в ней можно было указать список отслеживаемых атрибутов каждого объекта. И мы в эту обвязку добавили запись в отдельный регистр «Очередь сообщений BI», куда закидывали все объекты, которые изменились с предыдущего сеанса обмена, чтобы отдать их в BI. То же самое можно сделать через план обмена, но у нас все обмены были построены через регистр.
В результате мы добились значимого уменьшения количества передаваемых объектов справочников – время передачи сильно сократилось, стало занимать минуту-две, максимум – до 15 минут, если в течение дня было изменено много объектов.
И, поскольку мы завязались на изменения объектов, мы их стали передавать регламентным заданием раз в несколько минут. Соответственно, на момент перед загрузкой отчета скорее всего, данных будет мало, и это все пройдет гораздо быстрее.
Дальше – смотрим запись в SQL.
-
Здесь у нас данные по каждой строке передавалась по одному инсерту, и это получалось долго. Экспериментальным путем мы выяснили, что в рамках одной транзакции мы можем передать 400 инсертов и сразу записать все данные.
-
Заодно мы проанализировали данные на нашей стороне, откинули строки с нулями и провели различные преобразования (проверку уникальности идентификаторов, пересчет таблиц) – то, что изначально было на стороне BI, перенесли на нашу сторону. Это ускорило обработку процедур ETL на стороне BI почти на час, а выгрузка пакетами с нашей стороны ускорила обмен почти в два раза – у нас миллион записей сейчас выгружается за несколько минут.
-
Кроме этого, мы отключили автоматическое обновление индексов для таблицы, в которую мы выгружаем – индексы построятся только после того, как все будет загружено, на этапе загрузки они не нужны.
-
И немного оптимизировали отчет, который у нас формируется – убрали пару временных таблиц и в два раза увеличили скорость.
Этого в целом нам было почти достаточно.

Единственным узким местом осталось закрытие дня, потому что мы передаем данные за 4 часа, и закрытие дня тоже идет 4 часа. Мы попытались этот механизм тоже оптимизировать, и закрытие дня у нас стало занимать полчаса.
-
Заодно на этапе анализа мы поняли, что некоторые данные для нашего отчета мы можем предрасчитать и записать в отдельную таблицу. Это позволило ускорить формирование нашего отчета на конец выгрузки – там было около 30 тысяч записей, и мы их записали в отдельный регистр, который далее использовали для заполнения нашего отчета. Это – важная часть: если мы хотим ускорить обмен, важно заранее продумывать архитектуру данных. Если мы сможем записать и сохранить максимальное количество данных, их вывод будет работать быстрее, чем при формировании динамически. Плюс если при динамическом формировании прервалась передача, возникает много проблем – нам придется формировать отчет заново или писать кучу обвязки, чтобы придумать, как это сделать.
-
Второе – мы реализовали отдачу справочников через шину, через брокер сообщений. Решили, что как только объект изменился, мы не будем его писать на нашу сторону, а сразу закинем в брокера. Это немного ускорило работу, у нас пропали коллизии, возникновение которых мы не предусмотрели изначально на стороне 1С – я думаю, все знают, какие могут быть проблемы с передачей данных.
-
У нас режим совместимости старый, и платформа не позволяет использовать стандартный 1С-ный механизм копий БД, поэтому мы использовали SQL-механизм AlwaysOn копии. Это копия, доступная только для чтения, в которой данные актуальны. Она нам нужна, чтобы переключить на нее работу, если у нас вдруг упадет первая база. Но здесь мы ее заодно использовали, чтобы обращаться к этой базе и забирать оттуда данные, чтобы ускорить формирование отчетов, потому что нагрузка на нее была поменьше. На стороне SQL мы сделали обвязки – если в какой-то промежуток времени нам данные реплика AlwaysОn не отдала, то мы будем обращаться к рабочей базе и данные оттуда забирать.
В результате получилось сильно ускорить отдачу – к 9-10 утра данные в BI у нас уже были. Но если количество данных будет увеличиваться, то мы снова не будем успевать, и нам нужно будет думать, как ускорить этот механизм дальше.
Еще несколько способов ускорить передачу данных

В проекте я далее участия не принимал, но расскажу о некоторых способах дальнейшего ускорения данных.
Если мы можем данные заранее предрасчитать или переделать архитектуру – это самый приемлемый вариант.
Если мы не можем данные изменять, то пробуем следующие способы.
-
Подключение внешнего источника данных. Запись через него быстрее, чем через ADO, хотя и незначительно. Обвязка играет роль.
-
Следующий способ – использование BULK INSERT. Это механизм, который позволяет в SQL-таблицу загрузить данные из файла, в момент загрузки отключаются все контроли, и у нас данные из файла складываются в нужную табличку. Это происходит очень быстро, но безопасники этот способ очень не любят, ведь файлы нужно куда-то выгрузить, сохранить. И, если заранее файл куда-то не сохранить, не сделать его копию (а копия это тоже чревато, потому что к ней может быть организован несанкционированный доступ) – мы не знаем, правильно ли у нас в файле сформировались данные, и все ли мы верно загрузили. Работает быстро, но нужно аккуратно продумывать обвязку и безопасность.
-
Следующий способ – параллельная запись через ADO в одну таблицу. Так как мы пишем через инсерты, у нас нет ключей, которые мы можем контролировать. Но в целом инсерты не блокируют таблицу, и мы можем писать туда многопоточно, многопараллельно.
-
Еще вариант – разбитие нужных нам таблиц на партиции. Механизм позволяет разбить одну табличку, используя стандартный реквизит (например, Период), на несколько таблиц. И данные, в зависимости от этого реквизита, будут храниться в отдельных таблицах. Например, у нас есть общая таблица с отчетом, где хранятся все данные за месяц – мы можем разбить ее на несколько таблиц в размере количества дней в месяце, и каждый день этого месяца будет автоматически записан в отдельную таблицу. Соответственно, потоков у нас будет по количеству дней, и такая передача данных будет работать быстрее. Это сложно организовать на стороне SQL-базы, и я не гарантирую, что этот вариант будет работать на 100%, но он возможен.
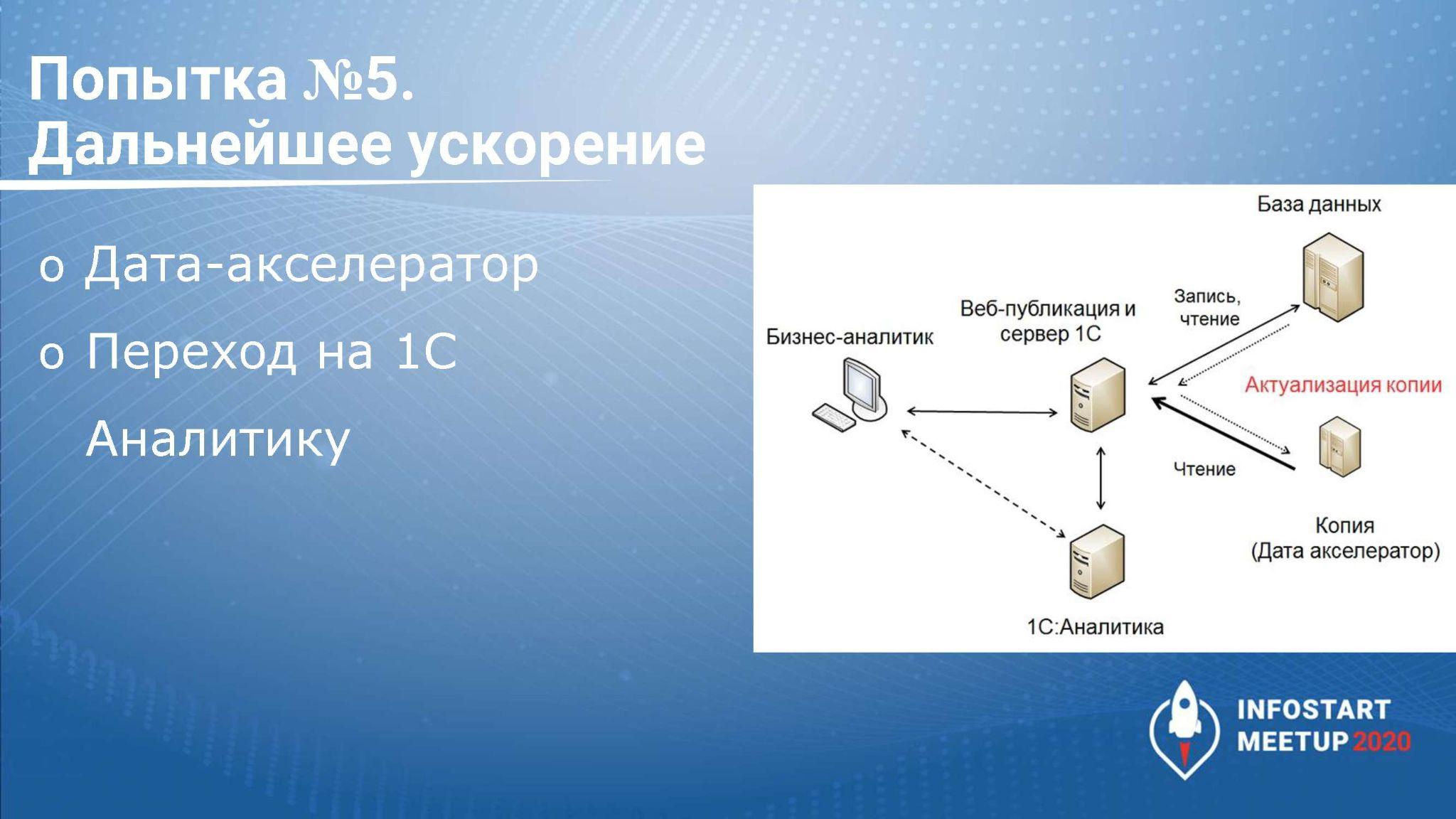
Есть еще два варианта ускорения – это механизм копий БД, Дата акселератор и использование 1С:Аналитики.
-
Механизм копий БД 1С позволяет сделать копию, актуализировать ее транзакционно либо через какое-то время. Если нам не нужен транзакционный анализ, мы эту копию можем обновлять раз в день и к ней строить BI-отчеты.
-
Дата-акселератор – это такая In-memory database, все данные хранятся в оперативной памяти. Данные будут получаться быстро, ее можно использовать в СКД и SQL-запросах, они будут работать быстро. Единственное, что нужно предусмотреть, что в него нужно положить все таблицы, которые будут участвовать в этом запросе или СКД, иначе запрос пойдет в основную базу, потому что в Дата акселераторе недостаточно данных. Используя механизм, мы можем значительно ускорить формирование данных на нашей стороне. Но если нам нужно данные записать куда-то, то скорее всего, нам нужно просто совместить несколько способов. И нужно понимать, сколько оперативки нужно, чтобы все данные сохранить.
-
Если 1С у вас – мастер-система, то стоит использовать 1С:Аналитику, а все сторонние данные выгружать в 1С.
Вопросы
Является ли прямое подключение к базе SQL нарушением лицензионной политики 1С? И является ли механизм копий способом обойти это ограничение? Я слышал, что коллеги просто делают копию базы средствами SQL и уже с ней работают – поскольку формально это не является уже проблемой для лицензионной политики.
Я согласен с этим мнением, потому что такой обход реально возможен. Но опять же, смотрите – в момент выгрузки вы уже нарушили соглашение. Если мы читаем и смотрим, как там все прописано, там все-таки прописано довольно хитро, потому что мы для SQL-базу по «букве закона» мы даже не можем формировать бэкап средствами СУБД. Естественно, на это никто не обращает внимание, и если вы сделаете бэкап средствами СУБД никто на вас «стучать не будет», но 100% утверждать не буду. Я просто озвучил сам факт – как это есть в самом соглашении. Дальше это все уже зависит от того, насколько вы хотите ему следовать, насколько вы правдивы и т.д. Но я считаю, что выгрузка в SQL и работа на копии – это вполне рабочий вариант.
Как быть, если у нас РИБ – несколько баз. Есть ли какой-то вариант работы с такой архитектурой?
В случае проекта, о котором я рассказывал в докладе, у нас была одна конфигурация, но 70 баз – базы стояли в разных странах, там разные условия. Я не касался этого в докладе, потому что не хотел усложнять.
Для такого способа интеграции, когда используется несколько баз, очень важно сначала сформировать базу НСИ. Мы в центральной базе сформировали ряд справочников, которые мы могли изменять только в центральной базе, а в остальные базы мы уже передавали только изменения. Это по факту – подразделения, вендоры, статьи расходов и т.д. У нас была не отдельная база с НСИ, а все было в нашей центральной базе. Соответственно, в момент выгрузки в BI, у нас данные грузились из 70 баз, там тоже через HTTP-оснастку сначала шел запрос в нашу центральную базу, потом запросы расходились по 70 остальным базам и грузились в отдельные таблички, которые уже на стороне BI ETL объединял. Но данные по гуидам НСИ были для всех баз одинаковые. Кроме контрагентов и номенклатуры – мы здесь не нормализовали, потому что у нас не было нужды формировать данные до такого разреза. Там было достаточно подразделений. Если у вас РИБ, то, скорее всего, у вас все данные в основную базу сливаются, и вам будет получать данные оттуда. А если у вас несколько баз, то очень важно нормализовать НСИ и тогда вы тоже сможете использовать различные способы интеграции как вам удобно.
Почему на слайде со сравнением систем у Qlik Sense стоит для OData +-?
Так получилось из-за различий в работе Qlik с 3-й и 4-й версией OData, потому что в Qlik для 4-й версии обрабатываются не все параметры и фильтры запросов. Но в 1С стоит 3-я версия OData, и Qlik с 3-й версией работает нормально. Поэтому минус оттуда можно убрать.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "Бизнес-анализ по данным базы 1С. Интеграция c платформами BI".

Загрузчик данных из 1С в BI-системы
Решение «Экстрактор данных 1С в BI» автоматически выгружает данные из 1С 8.3 в ClickHouse, PostgreSQL, Microsoft SQL для интеграции с BI. Работает с типовыми и кастомными конфигурациями 1С. Доступна бесплатная 5-дневная демо-версия.
Вступайте в нашу телеграмм-группу Инфостарт