
Немного о себе:
-
Я программист уже 28 лет, начал программировать еще в школе.
-
В 1С – с 2000 года.
-
В последние 5 лет я, помимо разработки, занимаюсь проектированием и проверкой архитектуры систем на 1С.
-
Мой опыт в руководстве командами – 10 лет.
-
Последние 3 года я активно применяю автотестирование – это связано со стремлением повысить качество кода в разработке, где тестирование является одним из краеугольных камней.
В начале доклада я провел опрос, чтобы выяснить, работает ли уже кто-то из участников митапа с автотестированием:
-
тем, кто не использует тестирование (среди слушателей митапа таких 17%) – это доклад для вас, слушайте внимательно, вам будет очень полезно;
-
тем, кто уже внедряет тестирование или понимает, что это необходимо, будет интересна практическая реализация подходов;
-
тем, кто использует тестирование в полный рост – вы, скорее всего, ничего нового из доклада не узнаете, но мне было бы интересно получить от вас обратную связь – расскажите в комментариях, как начинали тестировать вы.

В ходе доклада мы обсудим следующие темы:
-
Я расскажу о том, почему ручное тестирование не работает, и почему утверждение, что ручным тестированием мы обеспечиваем качество – миф.
-
Поговорим про методику тестирования «Черный ящик»
-
Покажу практическую реализацию этого подхода.
Почему ручное тестирование не работает?
Разберемся на практике, как могут возникать ошибки при разработке, и почему надеяться на ручное тестирование – не вариант.
Задача №1: Сделать учет заказов покупателей
Типовая задача: у нас есть организация, которая использует у себя в качестве управленческой системы «Бухгалтерию предприятия». Там нет учета заказов покупателей, и программистам поручают эту функцию «прикрутить».
Задачу берет программист Миша, который очень качественно разрабатывает и следует стандартам разработки.
Он понимает, что «Заказ покупателя» в рамках терминологии «Бухгалтерии» – это «Счет на оплату», документ, который проводится, но не делает никаких движений.

Для Миши все просто – он создает регистр накопления «наш_ЗаказанныеТовары».
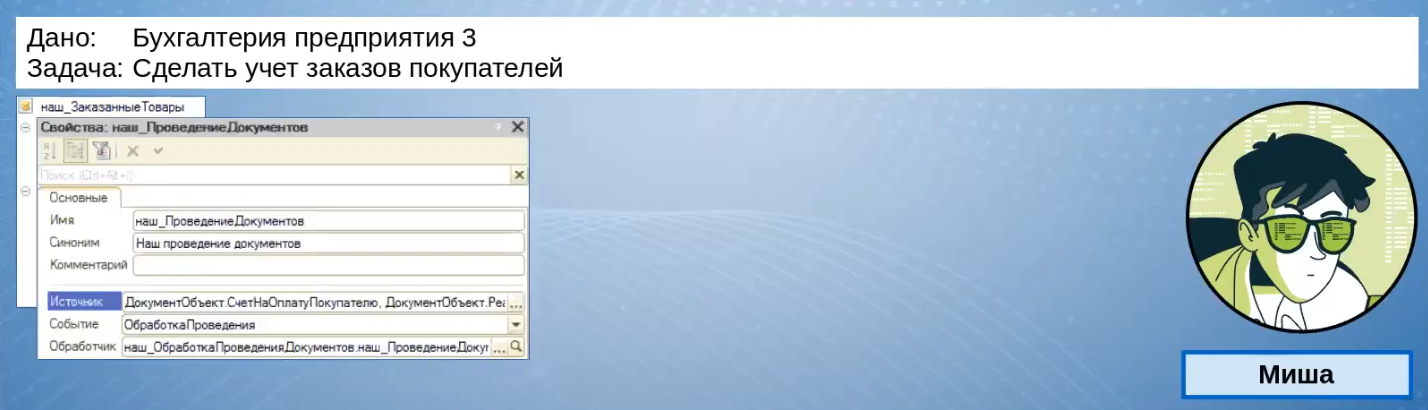
Чтобы не курочить основную конфигурацию, он создает подписку на событие «наш_ПроведениеДокументов», куда включает все необходимые документы.
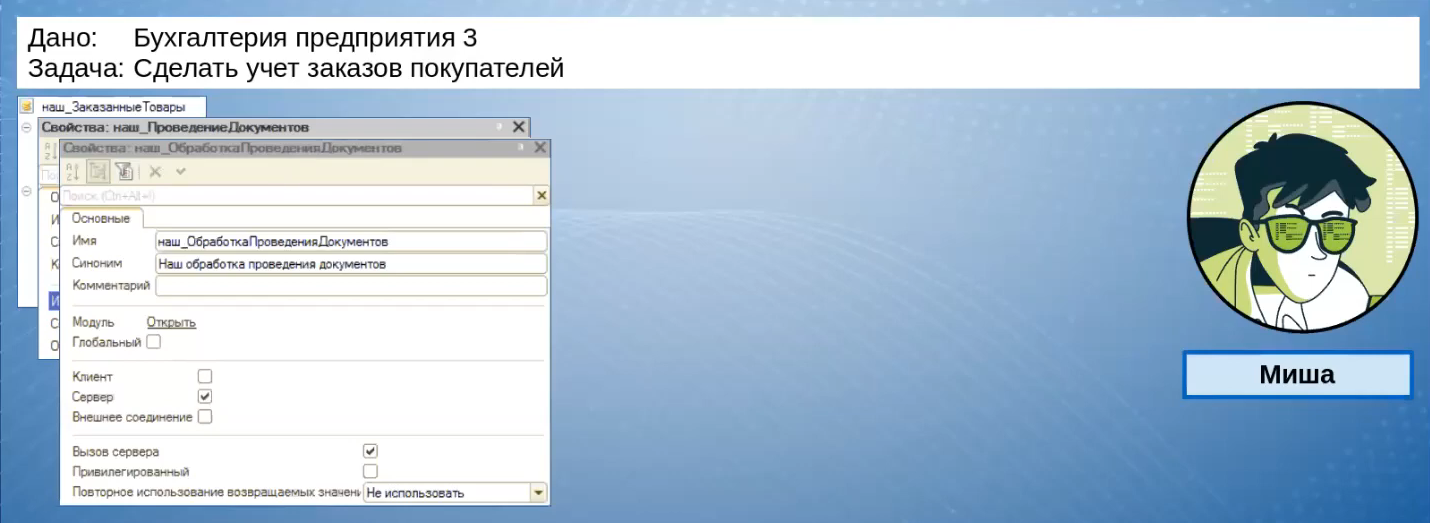
Для размещения обработчика подписки он создает общий модуль «наш_ОбработкаПроведенияДокументов».
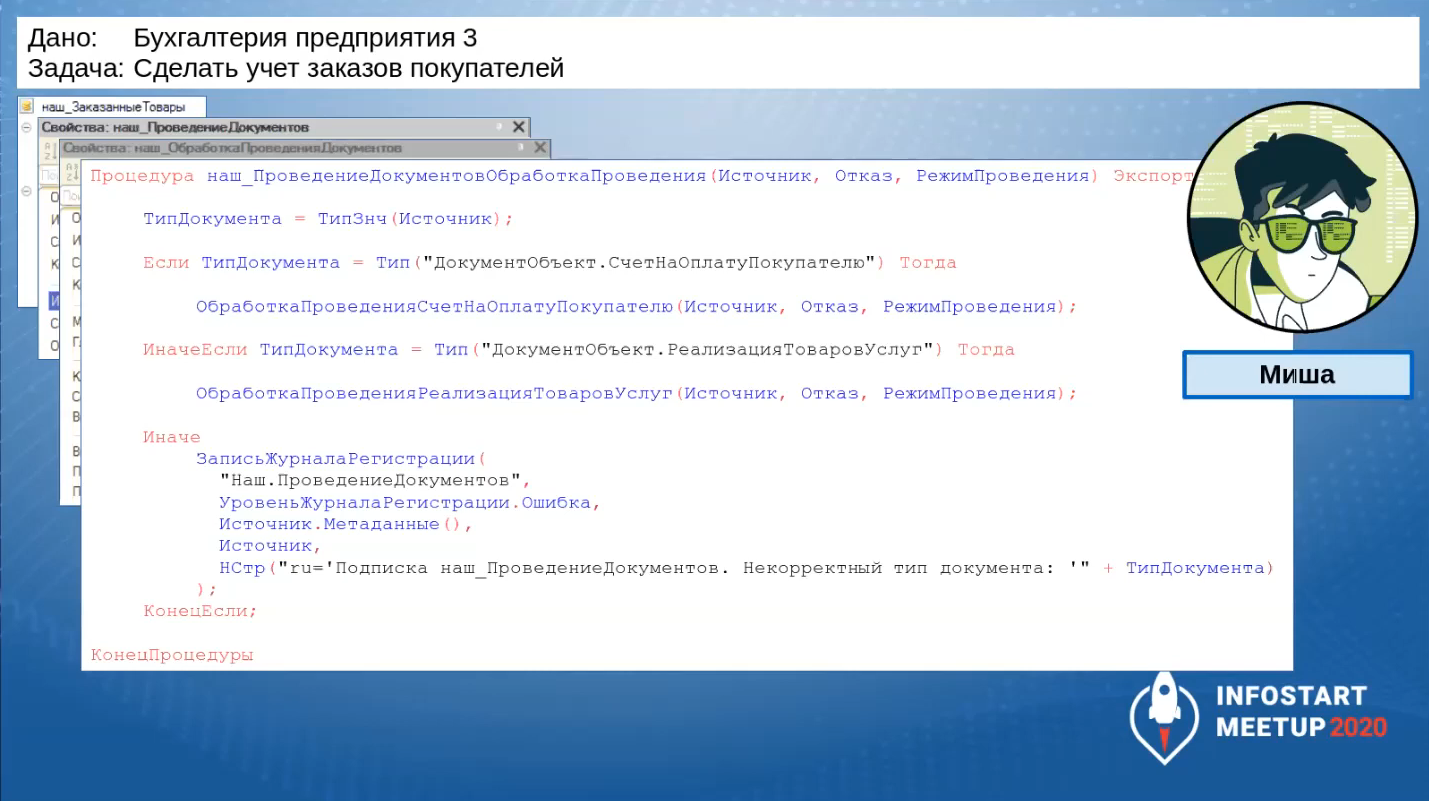
В этот общий модуль он добавляет процедуру «наш_ПроведениеДокументовОбработкаПроведения», реализующую вход в обработку проведения.
Процедура сделана качественно, вплоть до того, что он сделал защиту – если кто-то включит в подписку не тот документ, мы это увидим по журналу регистрации.
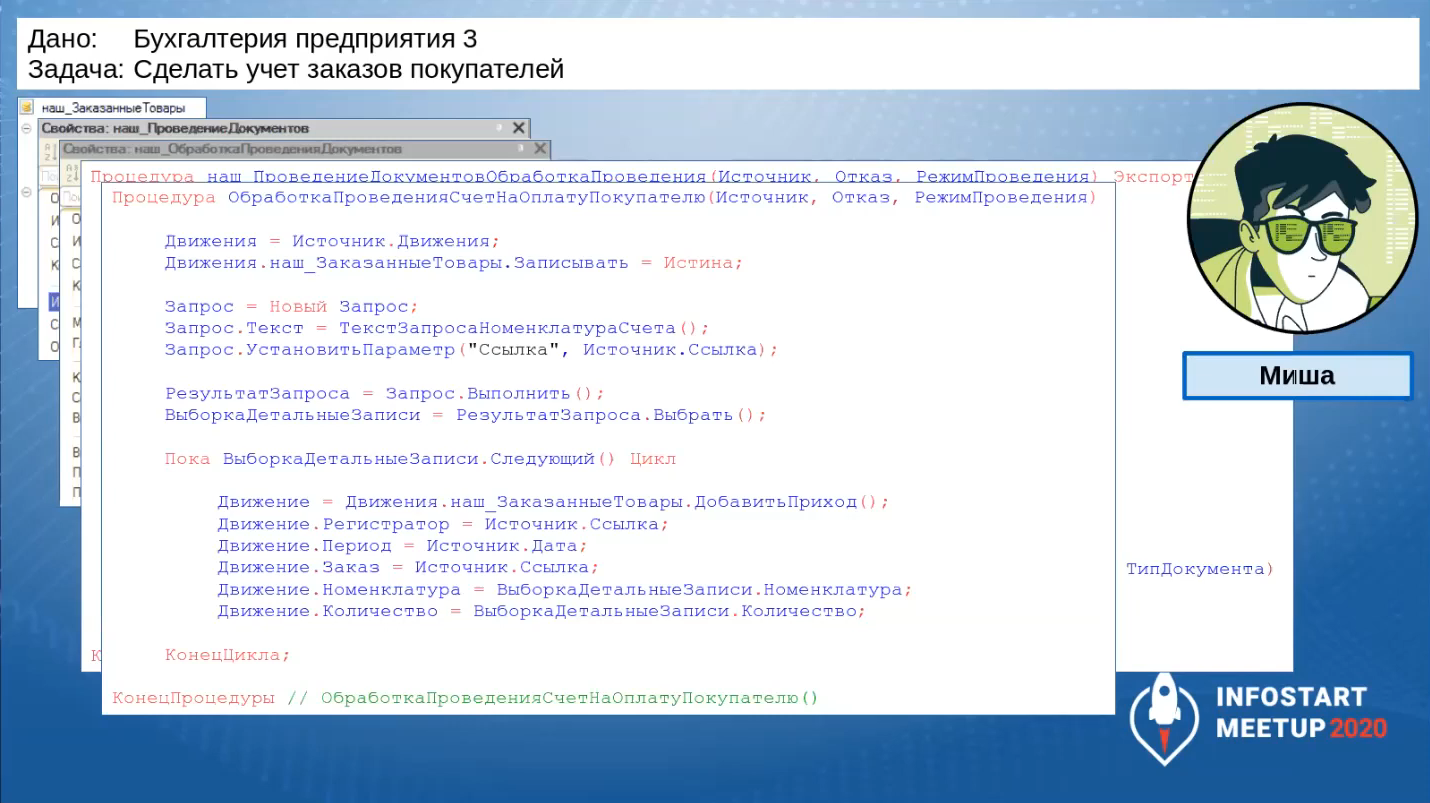
Вот так выглядит процедура «ОбработкаПроведения»: выборка данных, запись в соответствующий регистр.
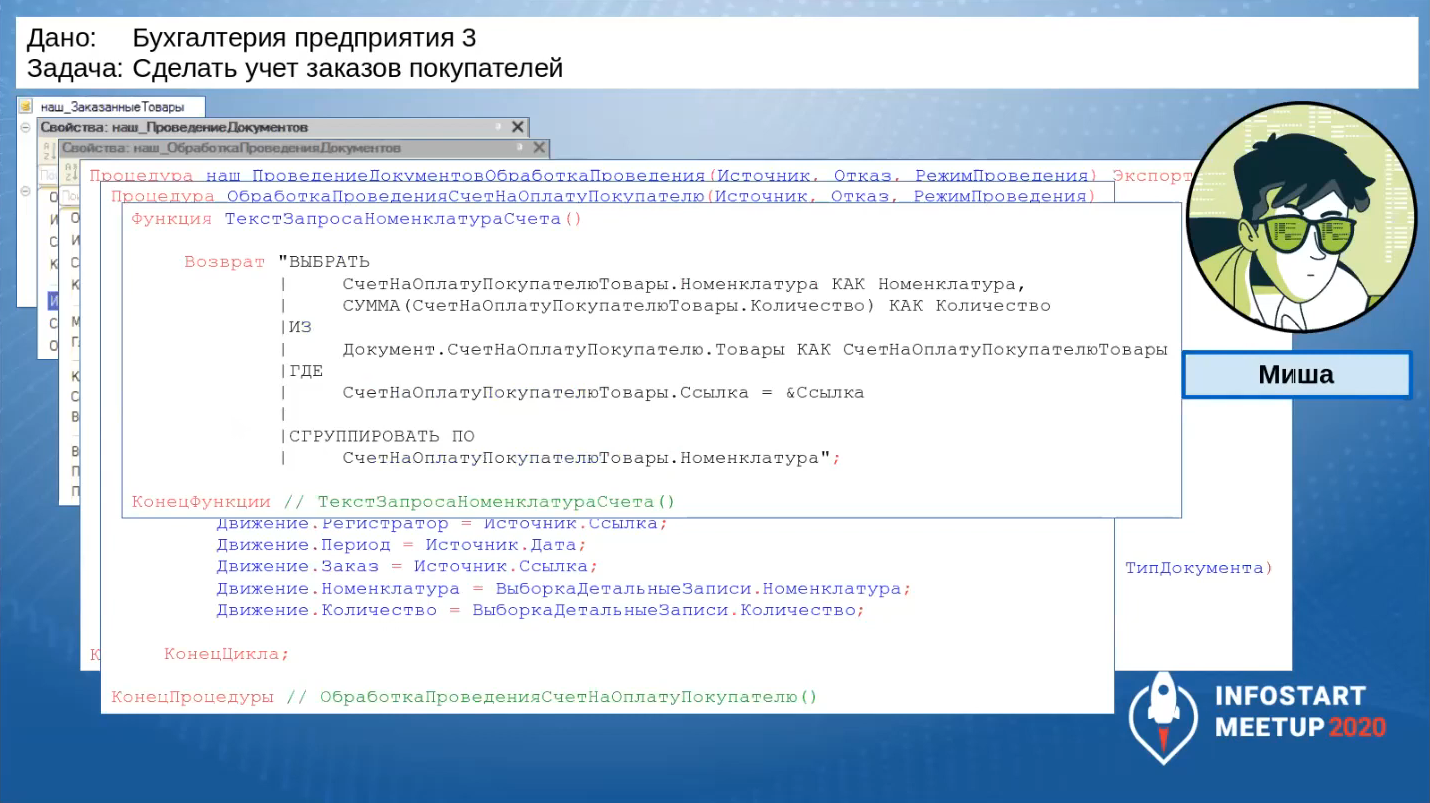
Чтобы уменьшить количество записей в регистре, Миша в запросе делает дополнительную группировку по номенклатуре.
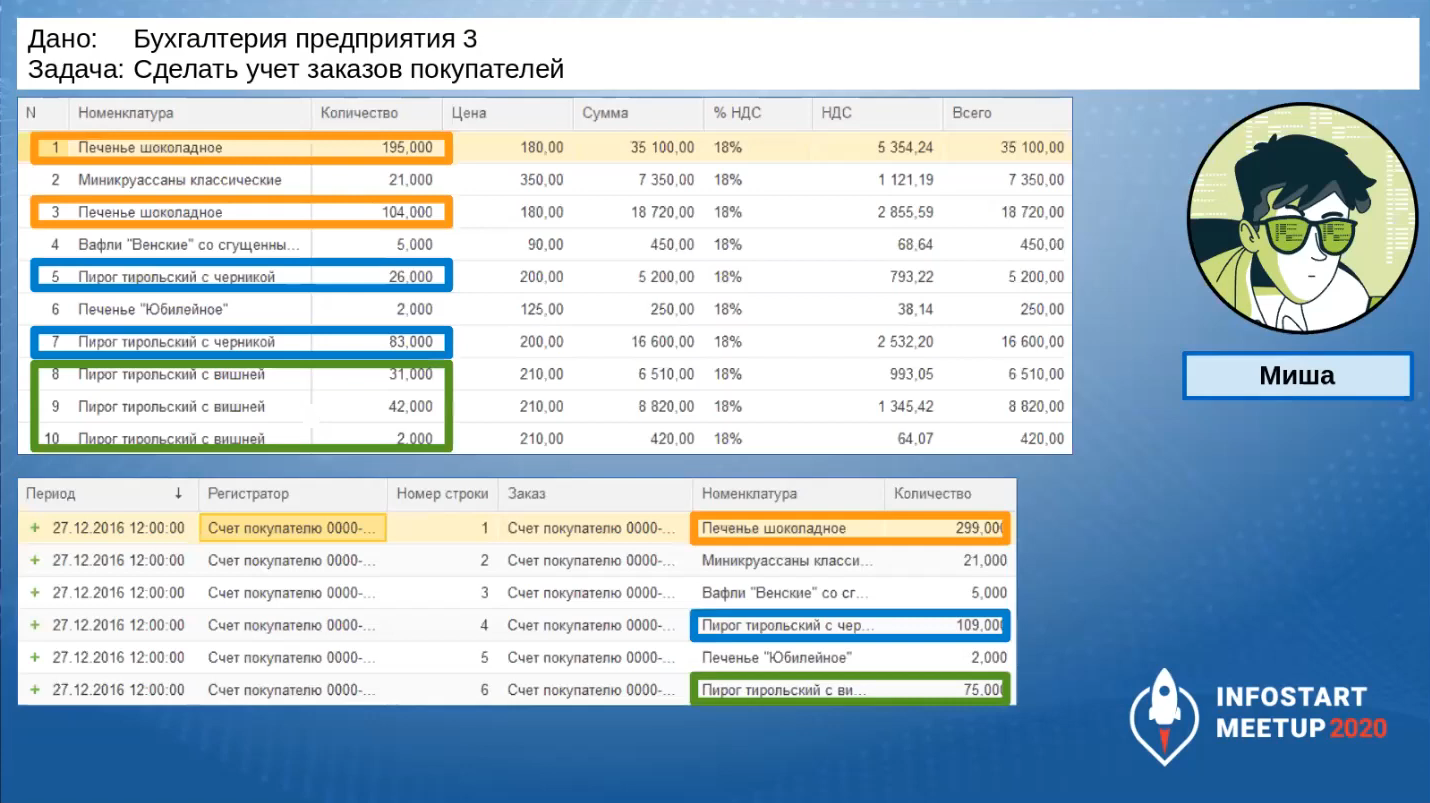
Он проверяет данные: сверху видно, как выглядит табличная часть, снизу – какие получаются движения. Группировка сработала.
Бинго, задача выполнена на отлично!
Задача №2. Статистика заказанных товаров
Через какое-то время появляется другая задача. Кто-то из менеджеров хочет видеть статистику по заказанным товарам без учета отгрузок – нужно знать, как часто на товар приходят заказы. Эта задача попадает Маше.
Маша у нас тоже очень качественный разработчик, она владеет терминологией, понимает, что такое OLTP-нагрузка, OLAP-нагрузка. Она понимает: раз это статистика, оперативные данные не нужны, здесь классическая OLAP-нагрузка.

Маша не хочет обращаться напрямую к регистрам, которые участвуют в транзакционной нагрузке. Поэтому она разрабатывает свой регистр накопления «наш_НоменклатураПоЗаказам»: периодический и независимый, в котором статистика по заказам собирается за каждый день.
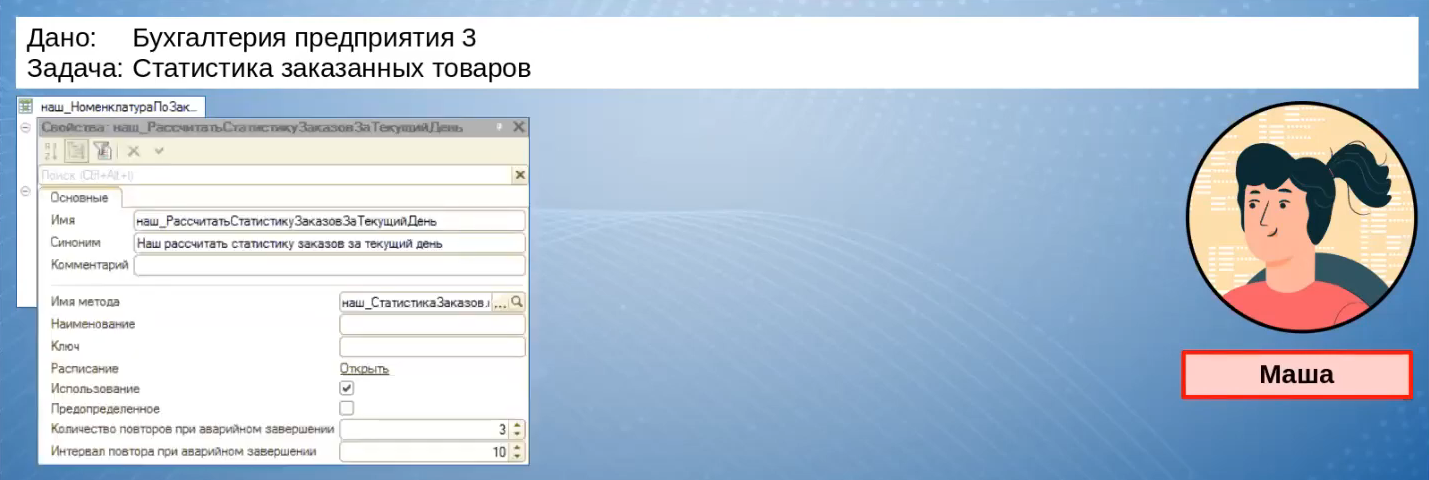
Заполняться этот регистр будет по регламентному заданию «наш_РассчитатьСтатистикуЗаказовЗаТекущийДень», которое должно отрабатывать раз в сутки.
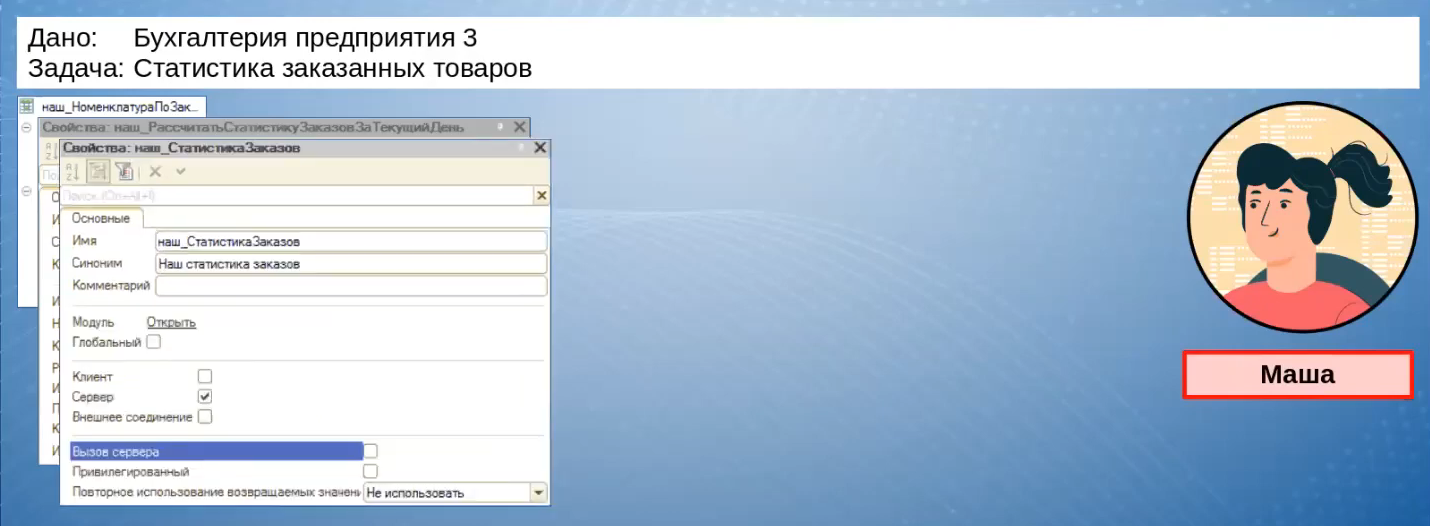
Обработчик регламентного задания находится в отдельном модуле «наш_СтатистикаЗаказов».
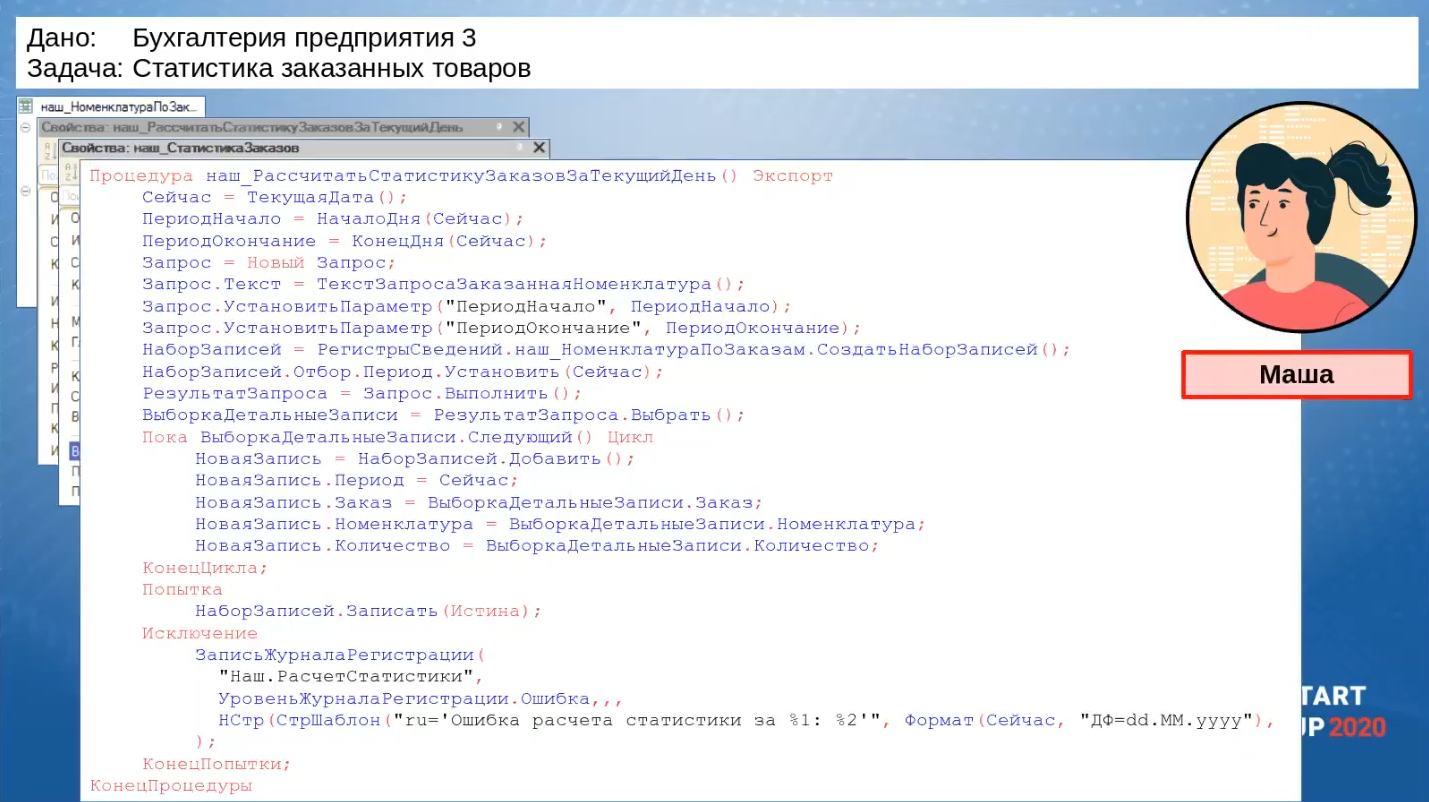
Вот так выглядит процедура загрузки данных. Ничего сложного нет, Маша качественный разработчик, и тоже ставит защиту: если записи не произойдет, в журнал регистрации упадет нужное ей событие.
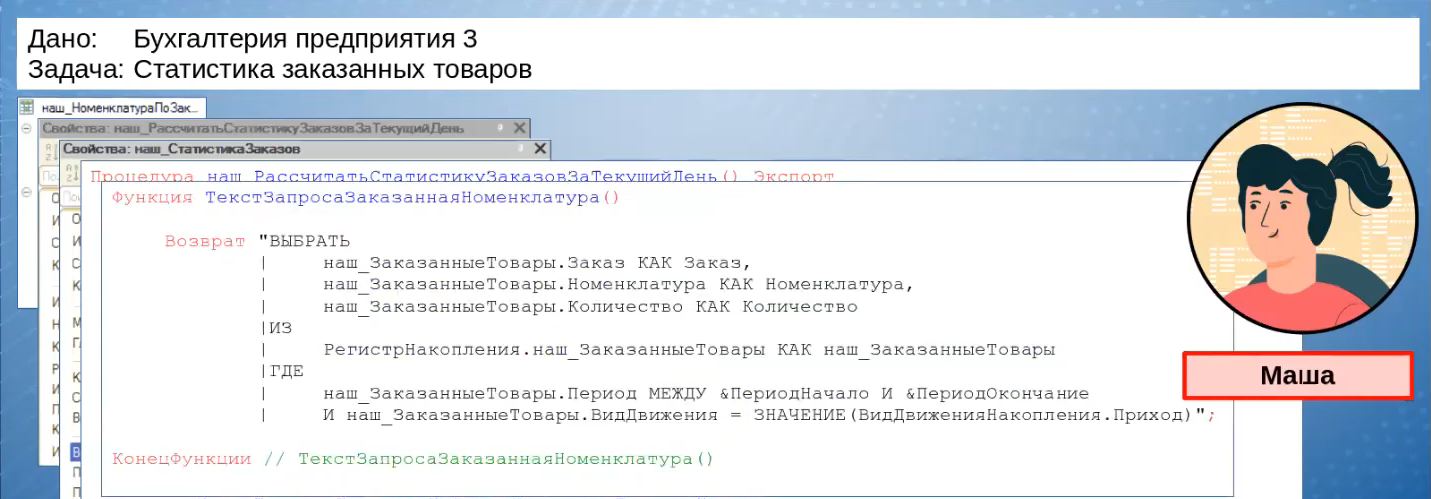
Так как Маша проанализировала, как заполняется нужный ей регистр, она видит, что там уже происходит предварительная группировка, и решает выбирать данные не через виртуальную таблицу оборотов, а напрямую из таблицы движений. Этим она хочет добиться оптимизации – не создавать вложенный запрос, а обращаться к реальной таблице.
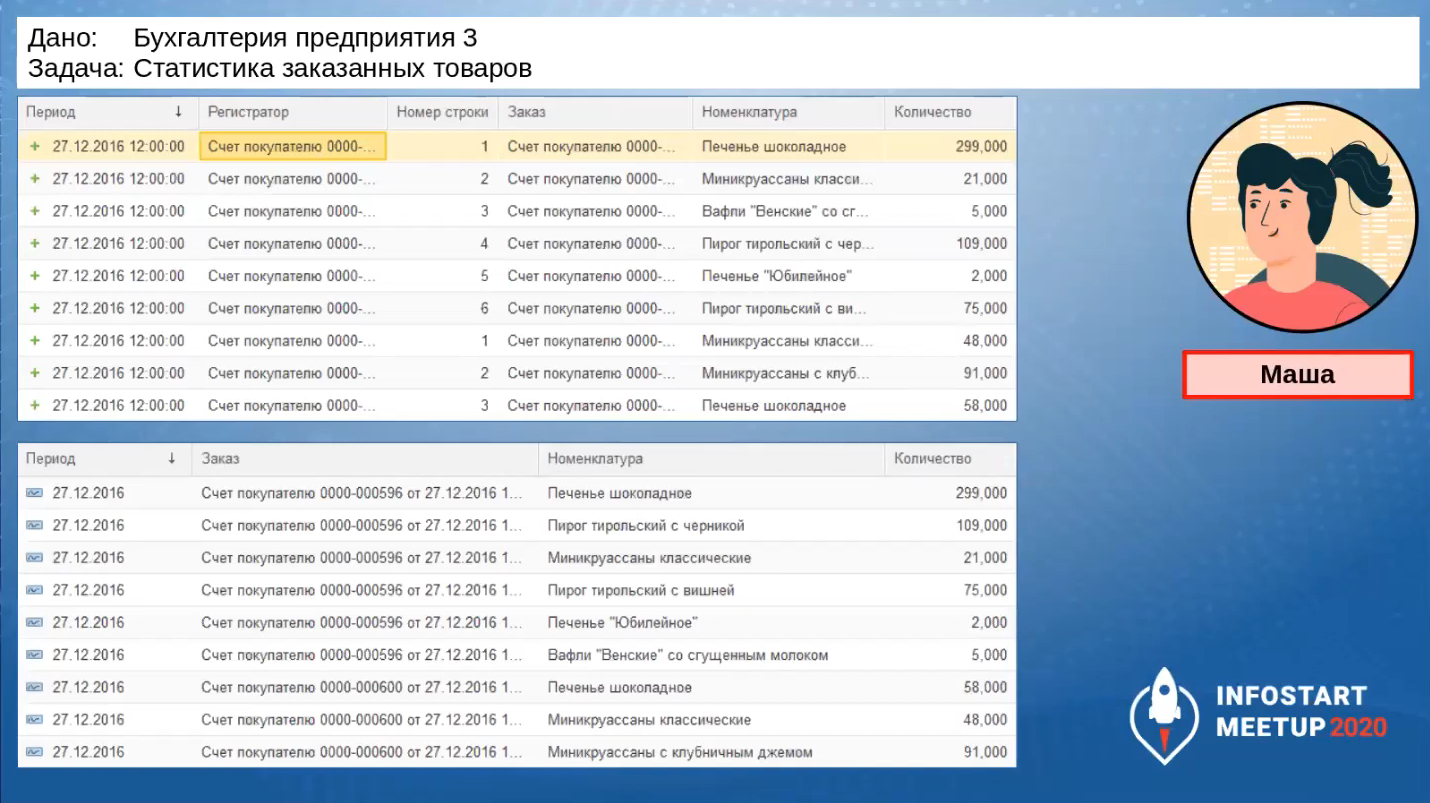
Она проверяет результаты: сверху показано, как выглядят исходные данные в регистре «наш_ЗаказанныеТовары», снизу – как данные заполняются в ее регистре «наш_НоменклатураПоЗаказам».
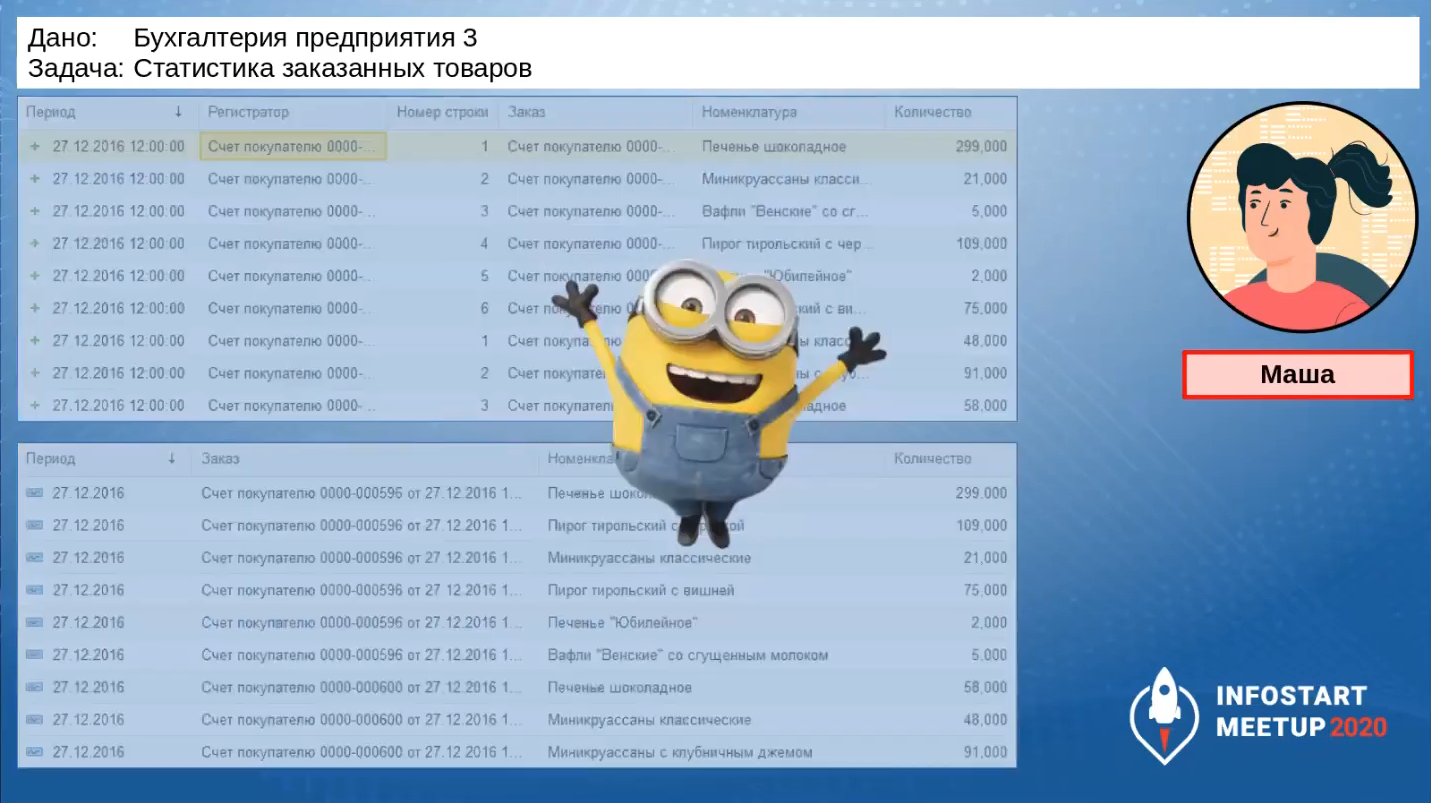
Дальше она приступает к отчетам, выполнению диаграмм. Все срабатывает, задача выполнена.
Задача №3: Доработать учет заказов покупателей в разрезе аналитик
Через какое-то время поступает новая задача: доработать учет заказов покупателей и добавить туда разрез аналитики. Эта задача попадает Мише.

Миша открывает регистр, добавляет туда новую аналитику.

Добавляет соответствующее поле в сам документ.
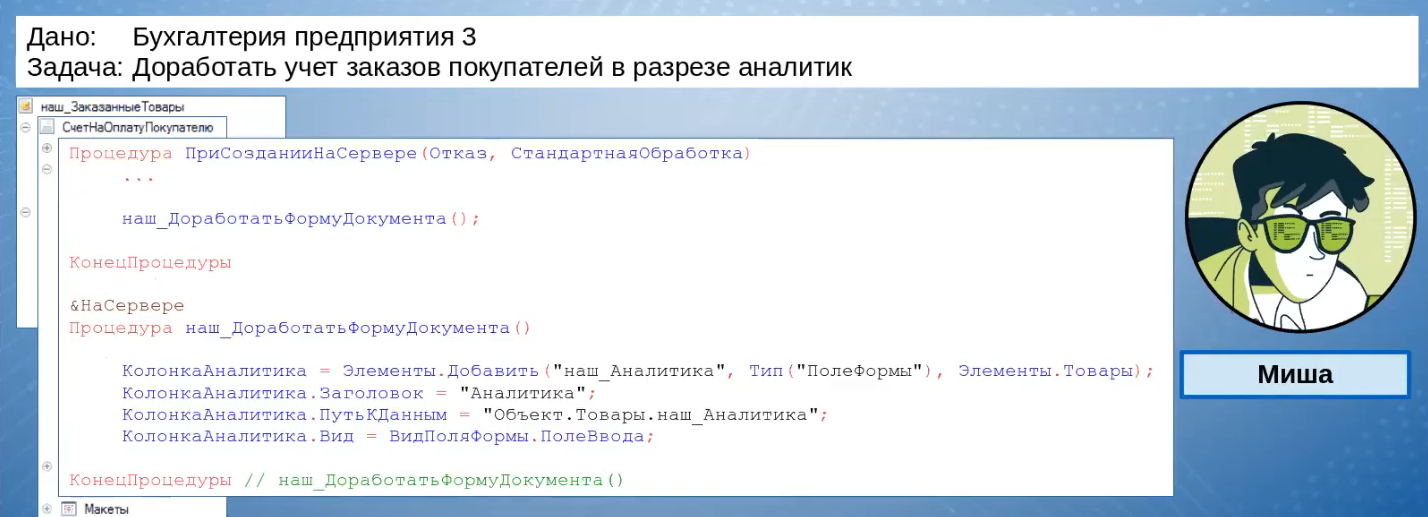
Чтобы не получить проблем при обновлениях, доработку формы он делает кодом.
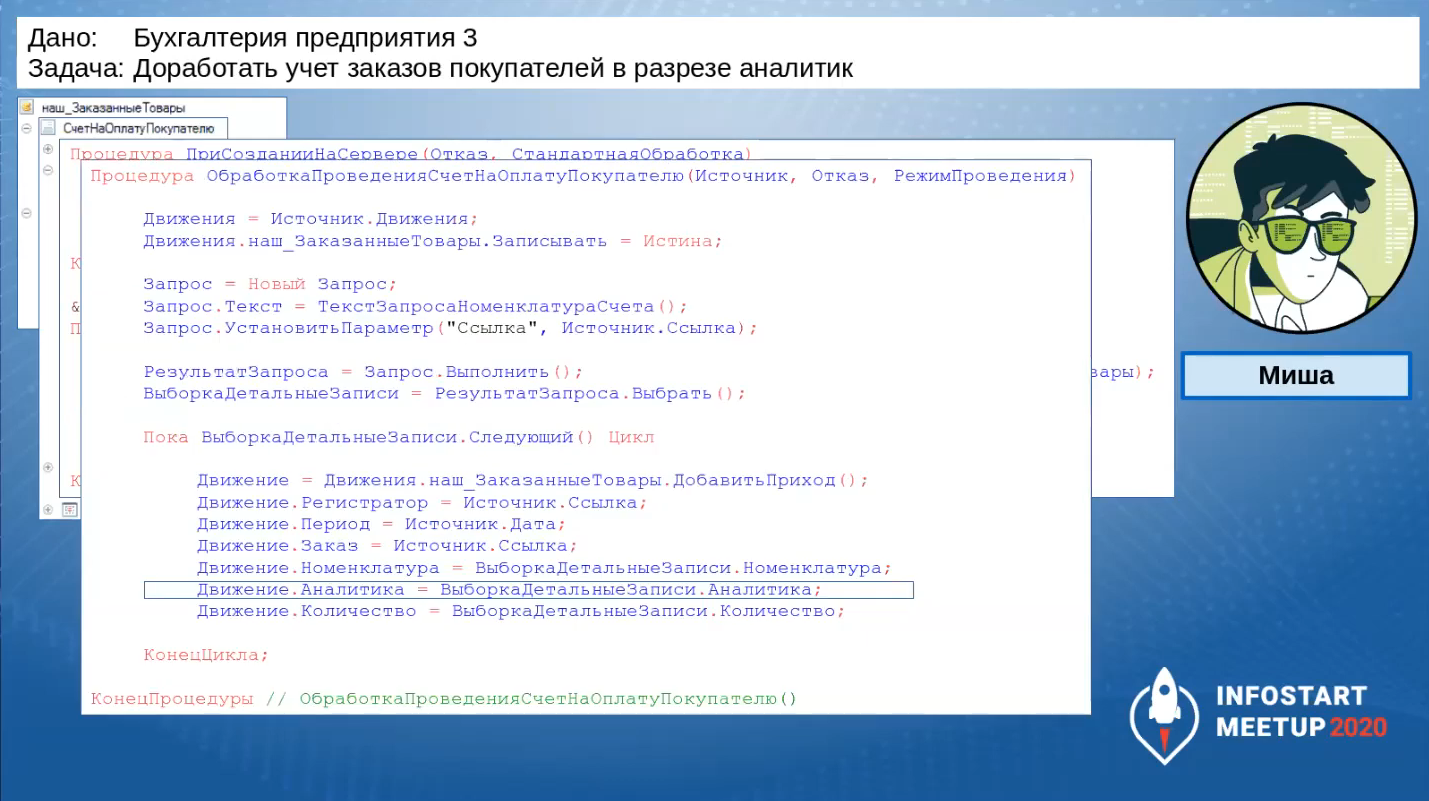
А в первоначальную процедуру, которая срабатывает в подписке на событие «Обработка проведения», он добавляет заполнение поля «Аналитика».
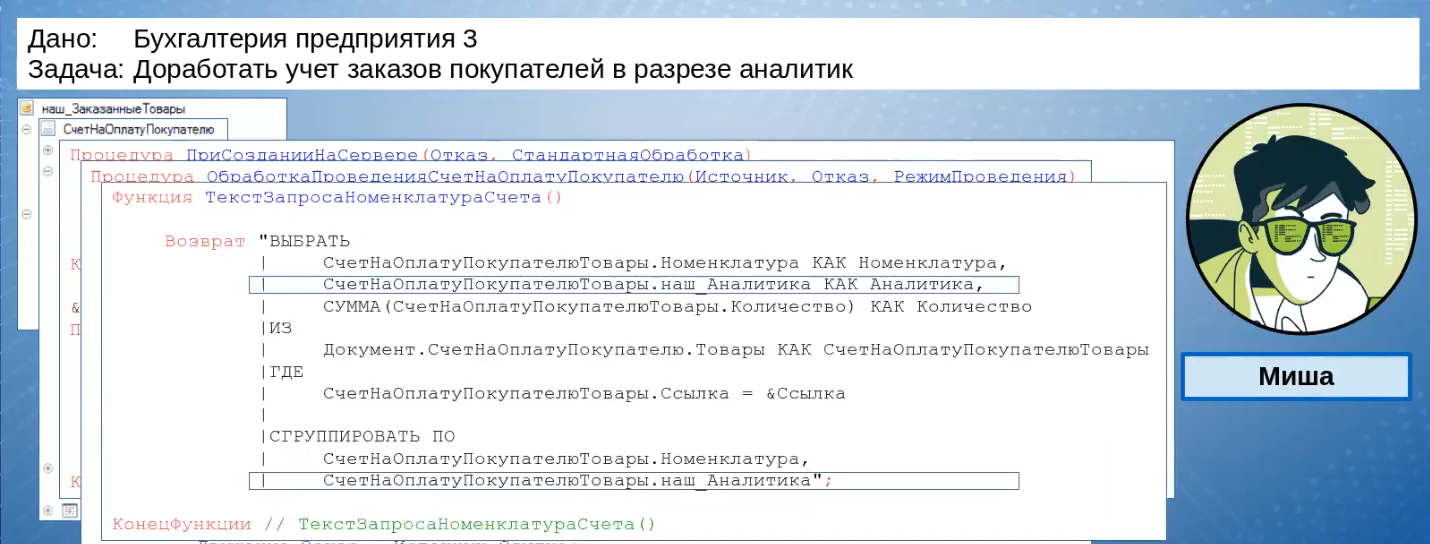
Аналитика выбирается из табличной части, и по ней делается дополнительная группировка.
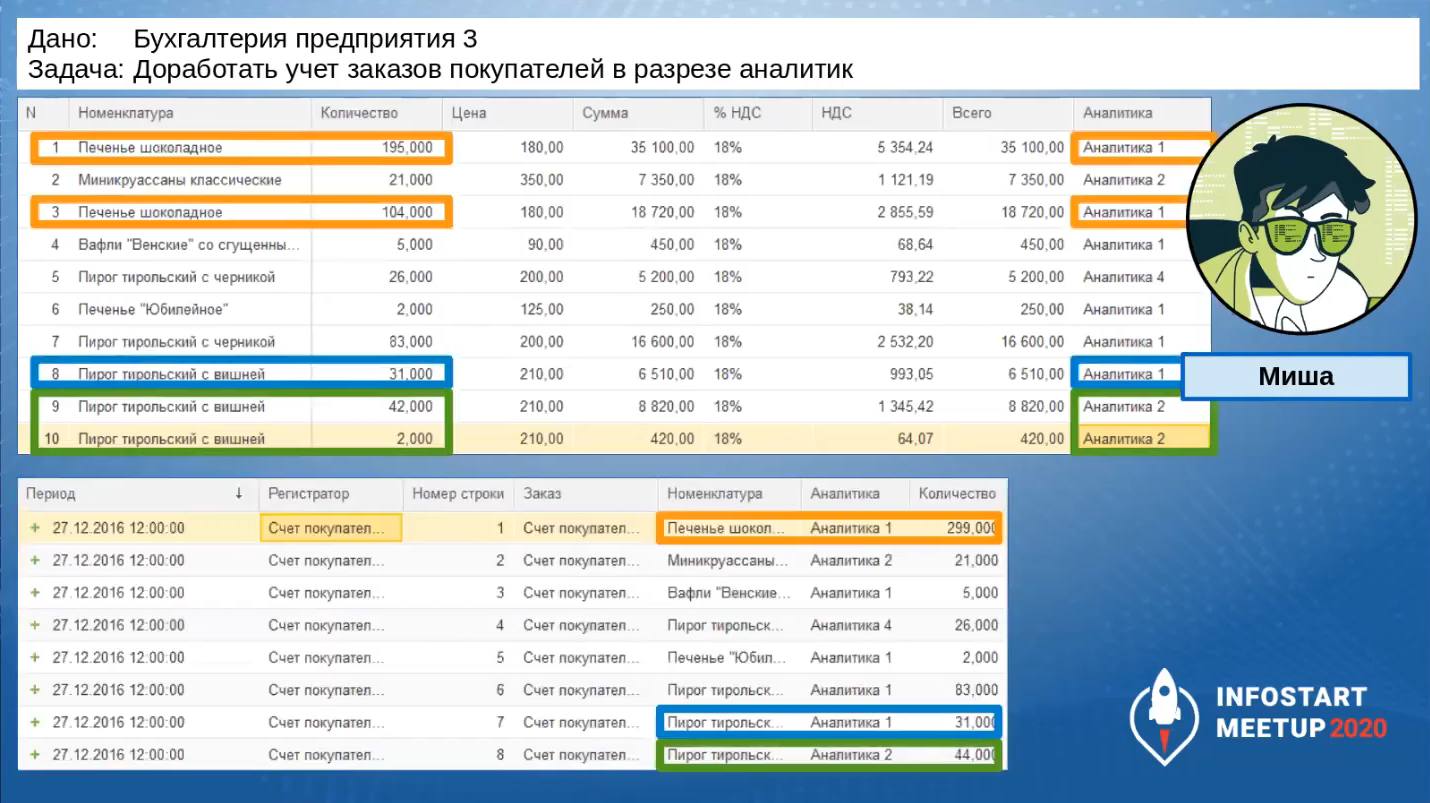
На слайде видно, как теперь выглядит табличная часть, как выглядят движения документа: все хорошо, ненужных группировок нет.
Все отлично, задача выполнена.
Задача №4: Ошибка со статистикой

Через какое-то время Маша получает сообщение о том, что со статистикой что-то не так.
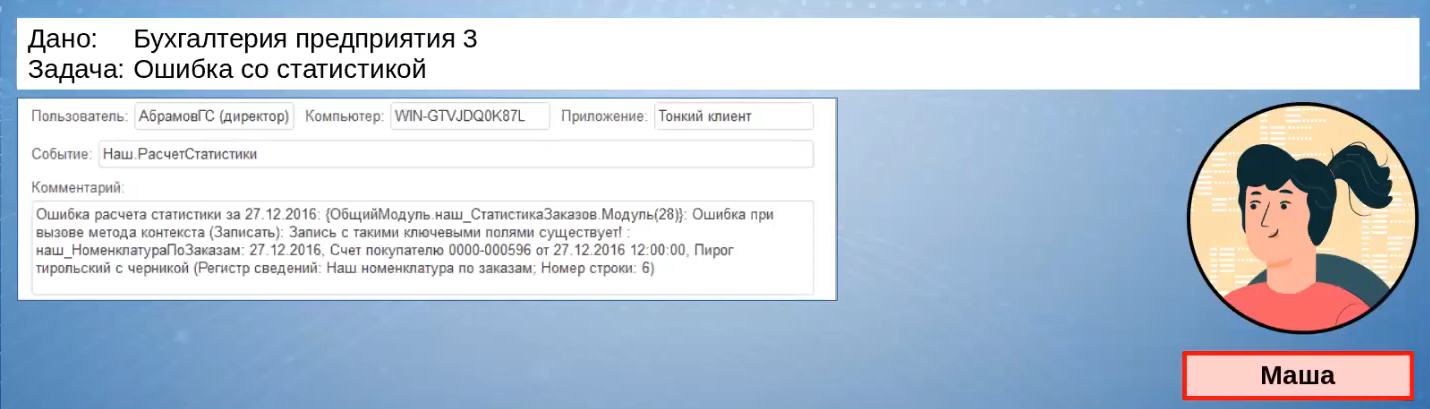
Маша обнаруживает, что, действительно, за какие-то дни статистика посчитана некорректно. Она проверяет журнал регистрации и находит в нем сообщения об ошибке записи в ее регистр.
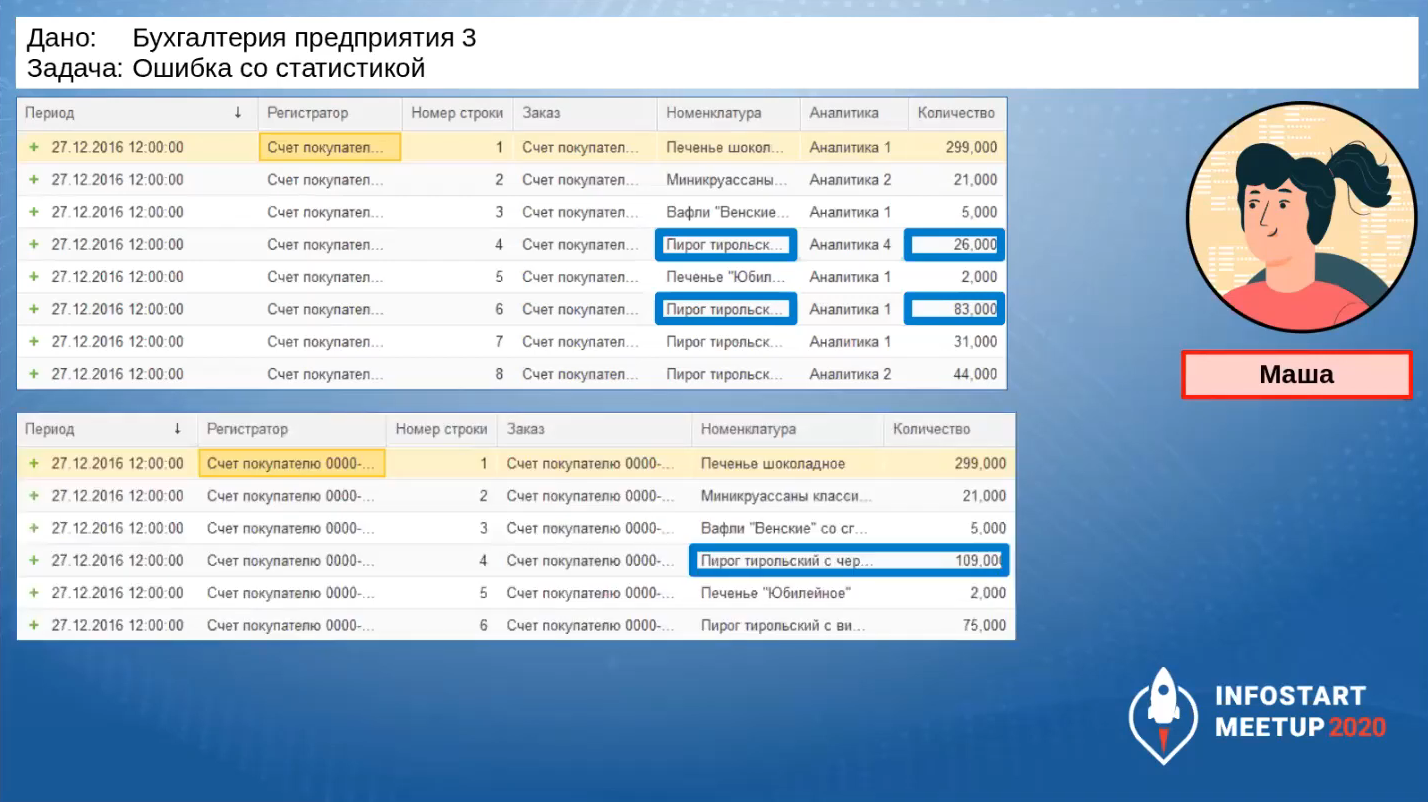
Она начинает разбираться дальше и получает исходные данные, на которых возникла ошибка: в регистре появились две записи с одинаковой номенклатурой, чего быть не должно. Ведь когда Маша разрабатывала, эта строчка была одна.
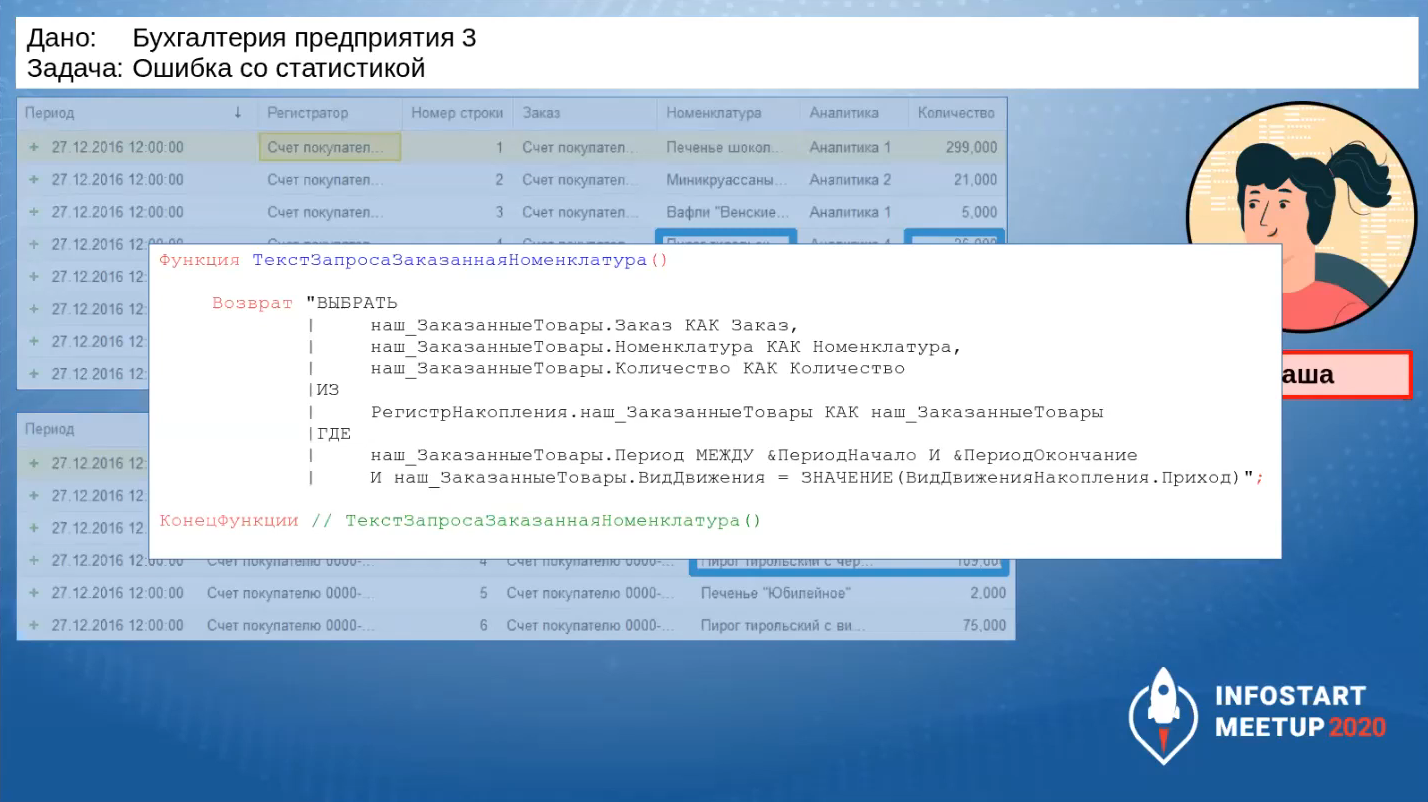
Она находит, что ошибка возникла из-за этого запроса, потому что в текущей ситуации, после того, как прошли изменения, этот запрос уже не работает.
Маша исправила запрос, пересчитала статистику, и проблема ушла.
Этим примером я хотел показать, что даже если мы разрабатываем по стандартам, занимаемся оптимизацией, ратуем за качество кода – мы не защищены от ситуации, когда в бизнес-логике возникает ошибка. С точки зрения качества кода все отлично, но не работает.
Возникает риторический вопрос.
Что важнее: «чистый код» или правильно работающая программа?
Все мы прекрасно знаем ответ на этот вопрос.

Выдам цитату Роберта Мартина из «Идеального программиста»:
Не забывайте – они [Заказчики] платят нам за создание программ, которые делают именно то, что им нужно
Для клиента качество кода неважно: пусть оно будет плохим, главное, чтобы выдавался нужный результат.
Что нам делать в ситуации, когда мы выдаем качественный код, но ошибки все равно возникают?
Ведь во всех вышеперечисленных случаях наши разработчики всегда тестировали разработку перед тем, как выкатить ее клиенту.
Самое интересное, что ответ на этот вопрос был дан еще в 1975 году.

Об этом говорил Фредерик Брукс.
Фундаментальная проблема при сопровождении программ состоит в том, что исправление одной ошибки с большой вероятностью (20-50%) влечет появление новой. Поэтому весь процесс идет по принципу «два шага вперед, шаг назад».
Почему не удается устранять ошибки более аккуратно? Во-первых, даже скрытый дефект проявляет себя как отказ в каком-то одном месте. В действительности же он часто имеет разветвления по всей системе, обычно неочевидные. Всякая попытка исправить его минимальными усилиями приведет к исправлению локального и очевидного, но, если только структура не является очень ясной, или документация очень хорошей, отдаленные последствия этого исправления останутся незамеченными. Во-вторых, ошибки обычно исправляет не автор программы, а зачастую младший программист или стажер.
Вследствие внесения новых ошибок сопровождение программы требует значительно больше системной отладки на каждый оператор, чем при любом другом виде программирования. Теоретически, после каждого исправления нужно прогнать весь набор контрольных примеров, по которым система проверялась раньше, чтобы убедиться, что она каким-нибудь непонятным образом не повредилась. На практике такое возвратное (регрессионное) тестирование действительно должно приближаться к этому теоретическому идеалу, и оно очень дорого стоит.
Заметьте, это 75 год. Здесь это сказано в контексте ошибок, но это можно трансформировать и для практики внесения изменений, потому что проблемы те же самые возникают.
Единственный выход, как говорит Брукс – проводить тестирование, причем тестировать не только ту функциональность, которую мы разработали, а всю функциональность.
Соответственно, с каждым новым изменением объем ручного тестирования будет расти. Это будет дорого.

Если ручное регрессионное тестирование – это дорого, нам нужно уменьшить его стоимость. Сделать это можно через автоматизацию.
Методика «тестирование черного ящика»
Эта методика существует в теории тестирования давно.

Идея заключается в том, что:
-
у нас есть доработанная конфигурация;
-
документации на нее нет;
-
конфигурацию нужно изменять;
-
себестоимость изменения должна быть минимальной;
-
времени на написание классических сценарных текстов у нас нет.
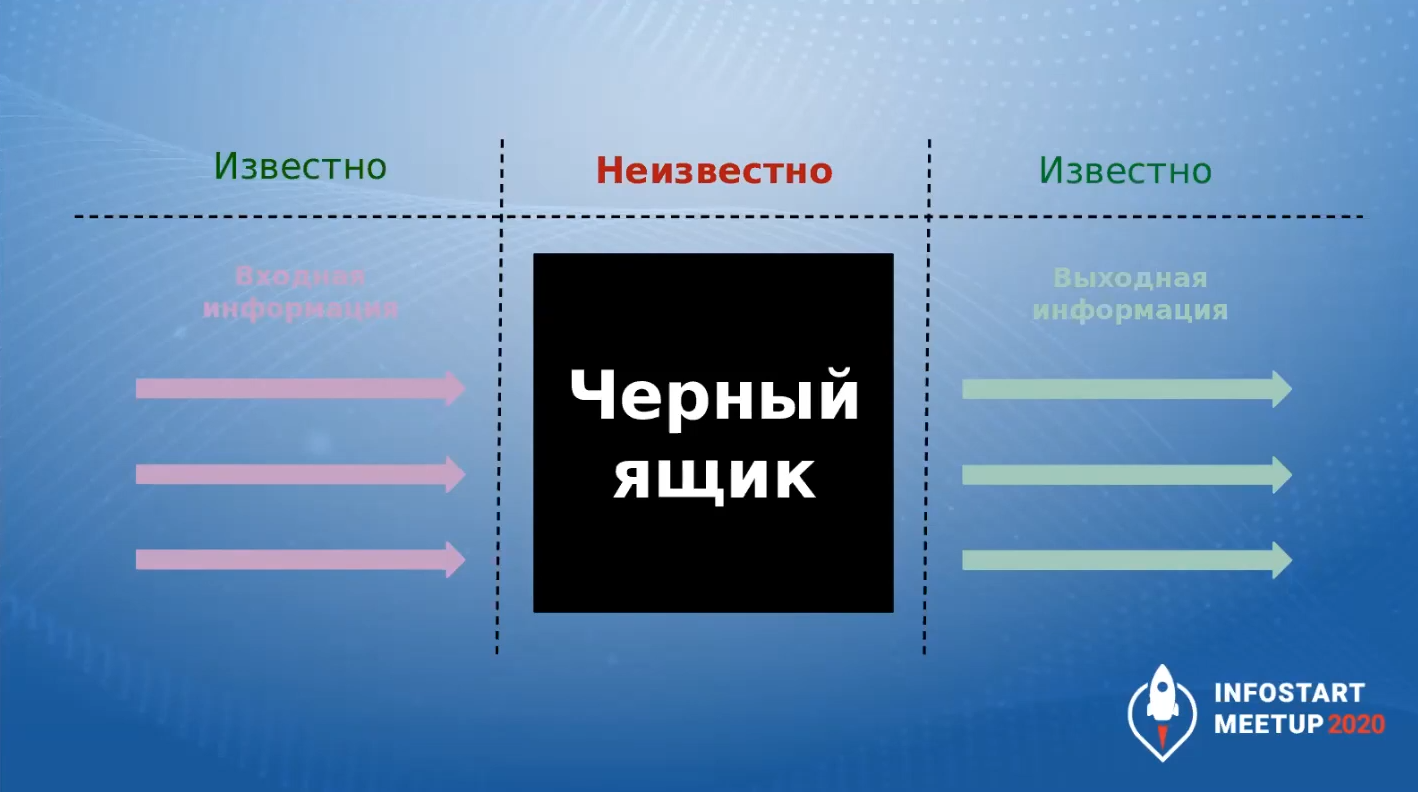
Методика говорит, что черный ящик – это и есть наша конфигурация.
Мы не знаем, как она работает, но мы знаем:
-
входную информацию;
-
и знаем, какой должна быть выходная информация.
На основе сравнения реальной выходной информации с тем, какой эта выходная информация должна быть, мы делаем вывод: система работает верно или неверно.
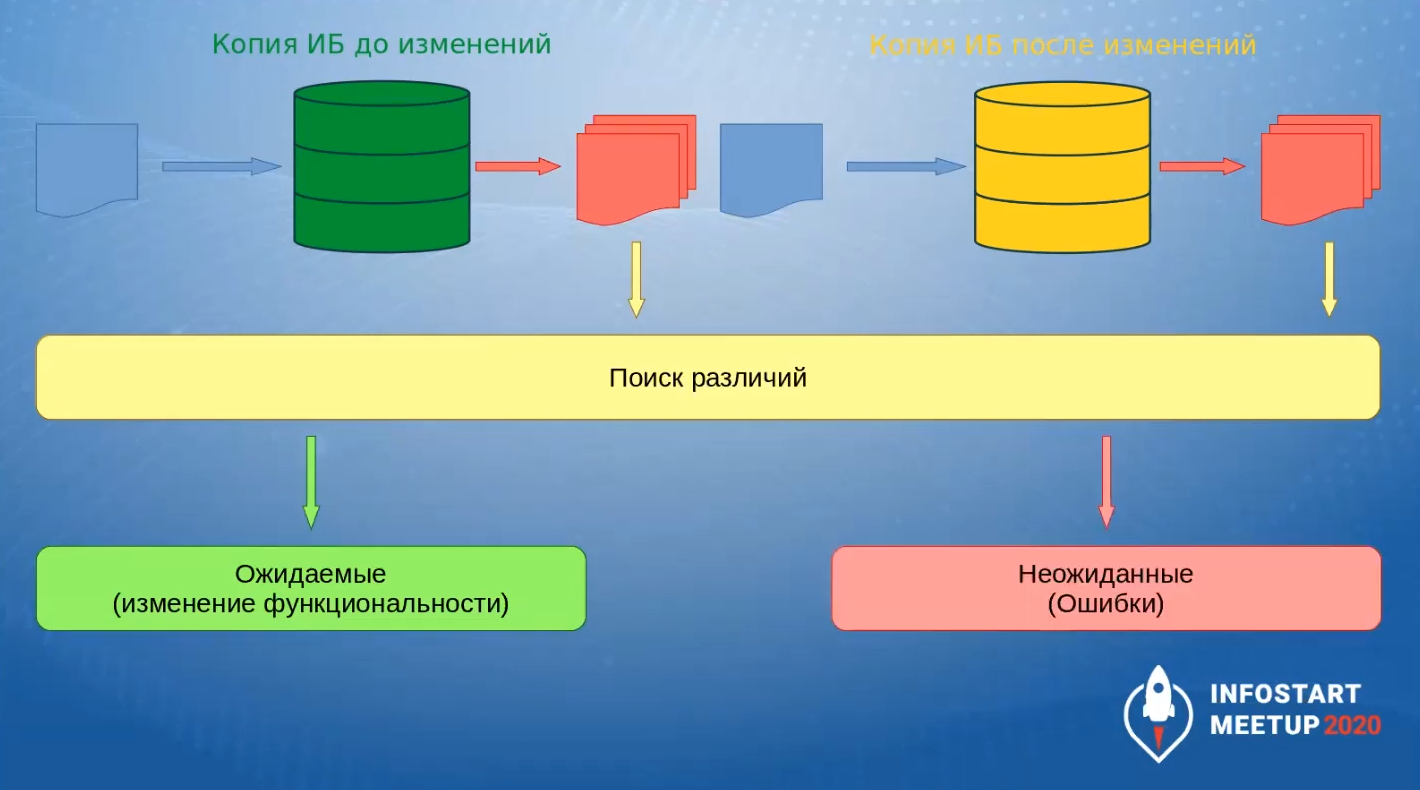
Как мы трансформируем эту методику, когда хотим проверить нашу конфигурацию?
У нас есть две копии информационной базы – до изменения и после изменения (после внесения новой функциональности).
Мы проводим одни и те же действия в обеих базах и получаем результаты
После этого мы в этих результатах ищем различия.
-
Ожидаемый результат – это когда различий нет или различия есть, но это произошло из-за изменения функциональности.
-
Неожиданные различия свидетельствуют о том, что есть ошибка.
Эта методика не приводит к точной идентификации ошибки. Она приводит к промежуточному результату: мы видим информацию, которую следует проанализировать и сделать выводы.
Практическая реализация
Тестировать по этой методике можно информацию, которая оставляет артефакты в системе.
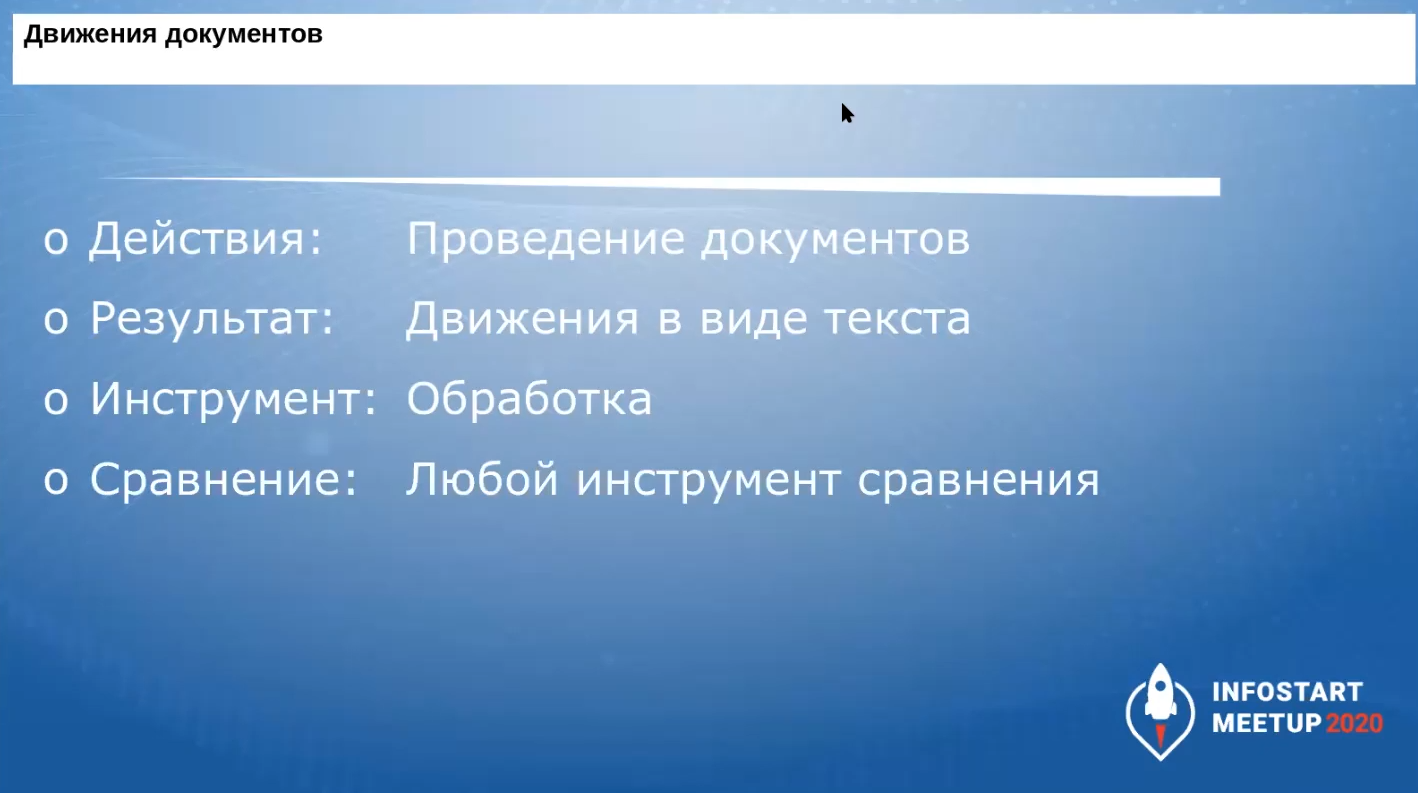
Допустим, мы проверяем движение документов.
-
Действием является перепроведение документов за период.
-
Результат – движения документа в виде текстового файла.
-
Инструмент – наша обработка.
-
Сравнение можно выполнять любыми инструментами сравнения, но на первом этапе я рекомендую использовать для этой цели программу WinMerge. Это open-source-инструмент, который очень быстро ищет различия в файлах.

Давайте посмотрим, как делать перепроведение.
-
Перепроведение мы выполняем по данным основной таблицы движений.
-
Обязательно указываем период, за который перепроводим документы. Можно встретить рекомендации перепровести 5-10-15 документов для выявления ошибок, но я рекомендую не останавливаться на количестве перепроводимых документов, а выбрать период, за который будем перепроводить. В ситуации, когда мы не знаем, как работает система, мы не можем определить минимальное количество данных, которое нам нужно для тестирования. Чтобы добавить определенности, мы выбираем период.
-
Период выбирается так, чтобы в него попали все операции, которые осуществляются в нашей базе.
-
для БП – это квартал;
-
для ЗУП – месяц, все зависит от количества людей, по которым производится расчет;
-
для финансовых систем это может быть год, а может быть и три – все зависит от того, какие у нас бюджеты, и на какой период они заключаются.
-
-
Для оптимизации все ссылочные типы в запросе показываем в виде представления.
-
Делаем сортировку по моменту времени.
-
Используем выборку запросов, а не выгрузку в таблицу значений.
-
Перепроведение делаем в транзакции.
-
Для записи лога используем объект ЗаписьТекста.
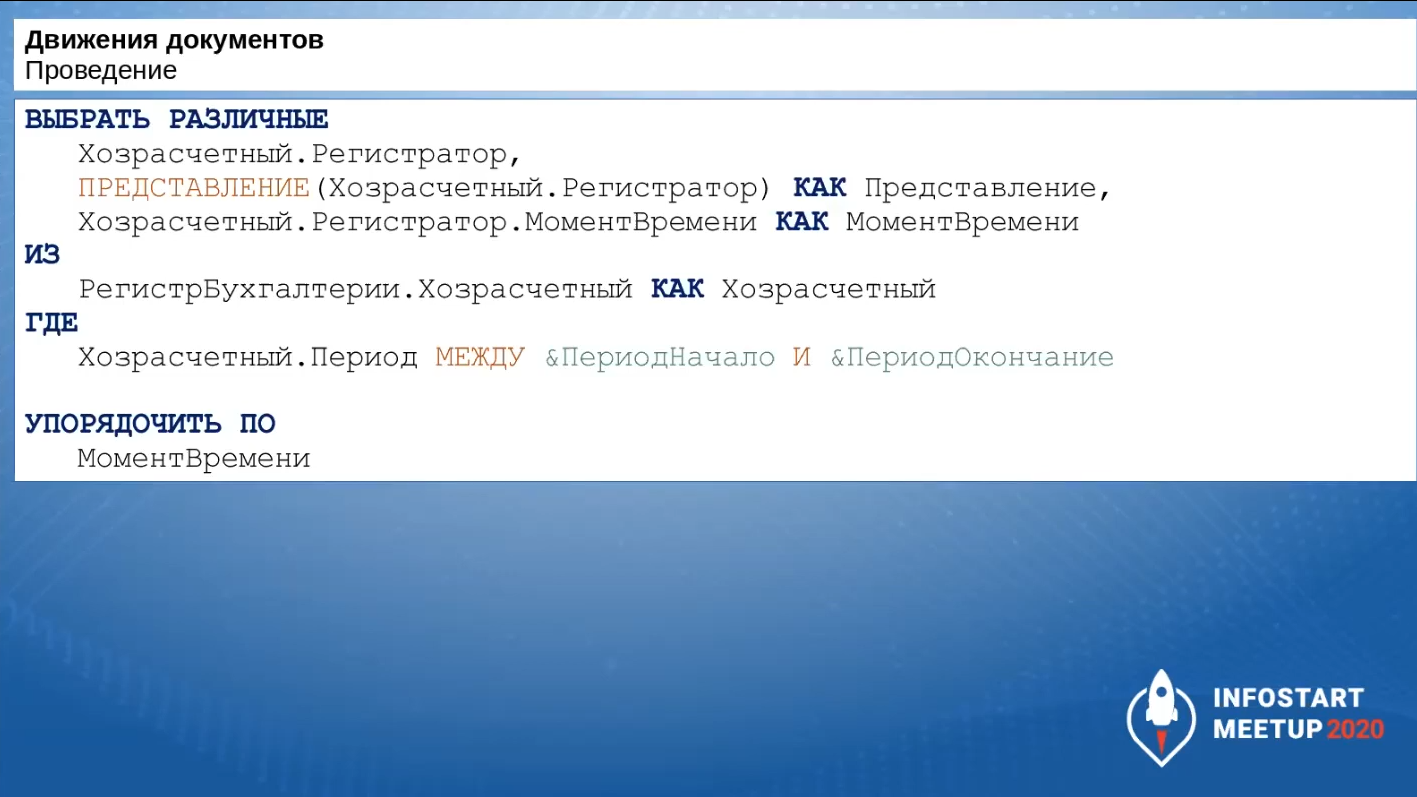
Вот так может выглядеть запрос по выборке тех документов, которые нам необходимо перепровести.
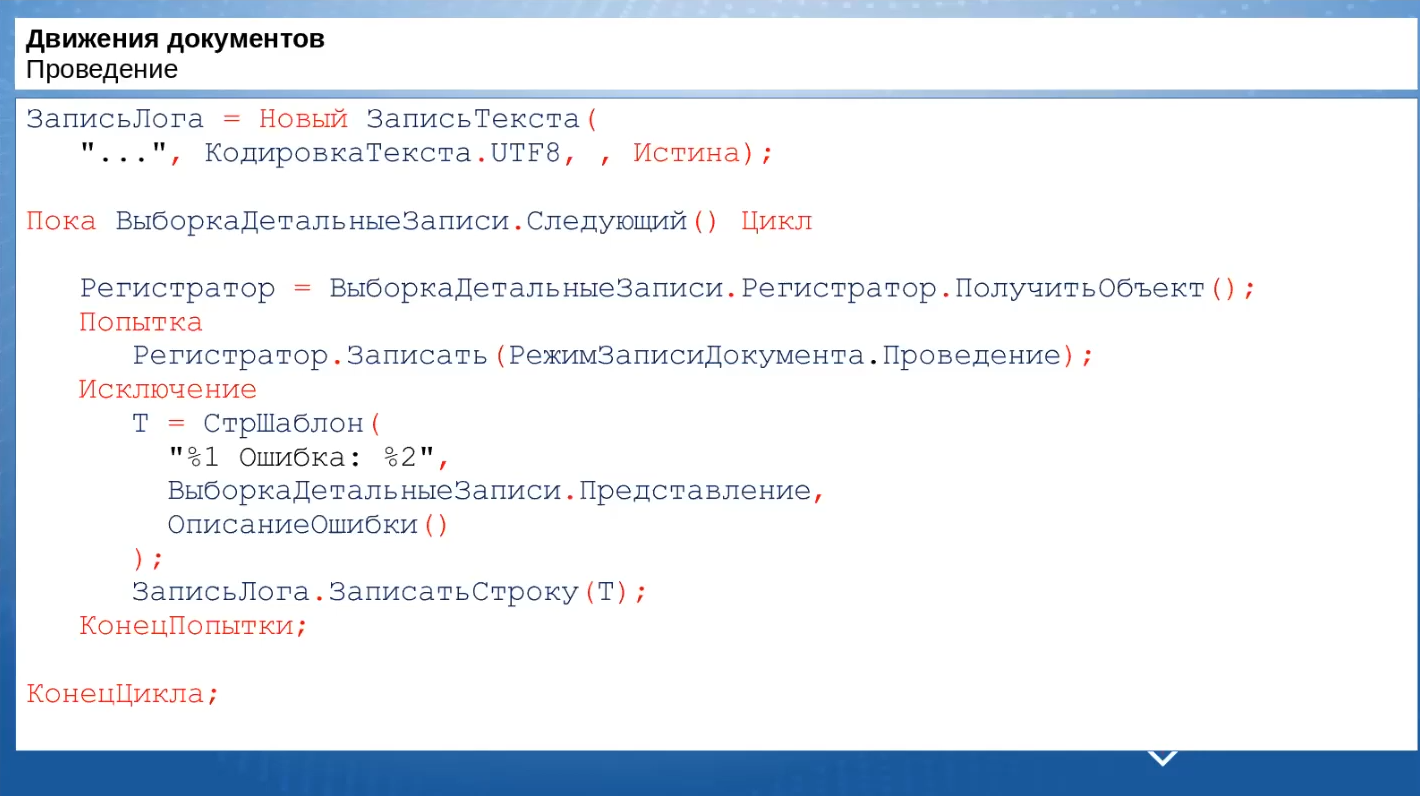
Вот так может выглядеть код для перепроведения документов. Главное здесь: если документ не перепровелся – нас это не должно смущать. Возможно, он и не проведется в базе после изменения, главное, чтобы в обеих базах – до и после изменений – лог-файл был одинаковым.

Как мы получаем результат – выгрузку движений?
-
Выгрузку движений получаем через запрос к основной таблице движений. Исключение составляет бухгалтерский регистр, потому что у него основная таблица движений не включает разрезы субконто. Для бухгалтерского регистра выгрузку движений получаем через запрос к таблице ДвиженияССубконто.
-
Определяем период, за который выгружаем.
-
Остальное – все то же самое, что и в запросе по документам для проведения: представление для ссылочных типов, сортировка по моменту времени, выборка запроса, а не выгрузка.
-
Для лога используется объект ЗаписьТекста.
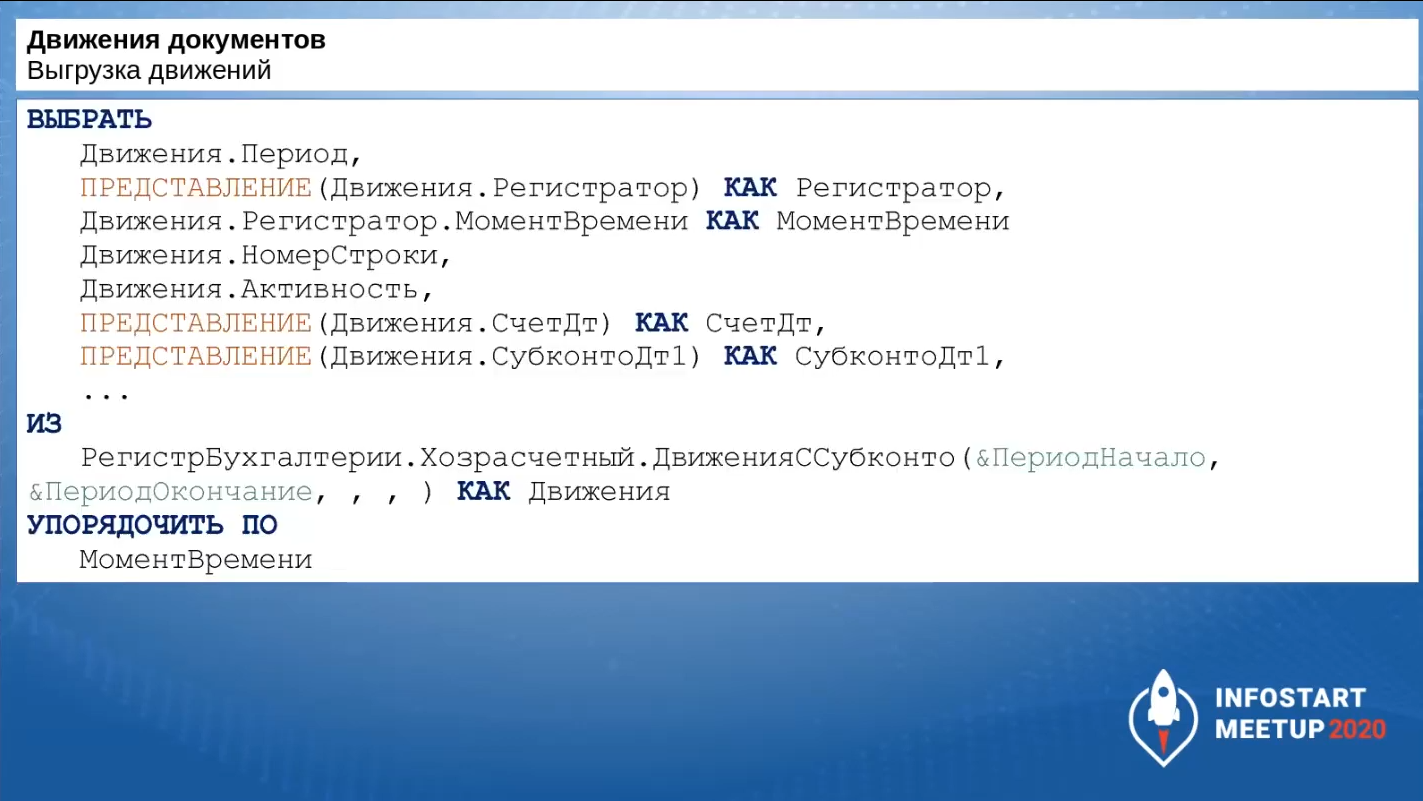
Вот так может выглядеть запрос. Вы можете делать выборку только тех полей, которые вам необходимы. Все зависит от ваших задач.
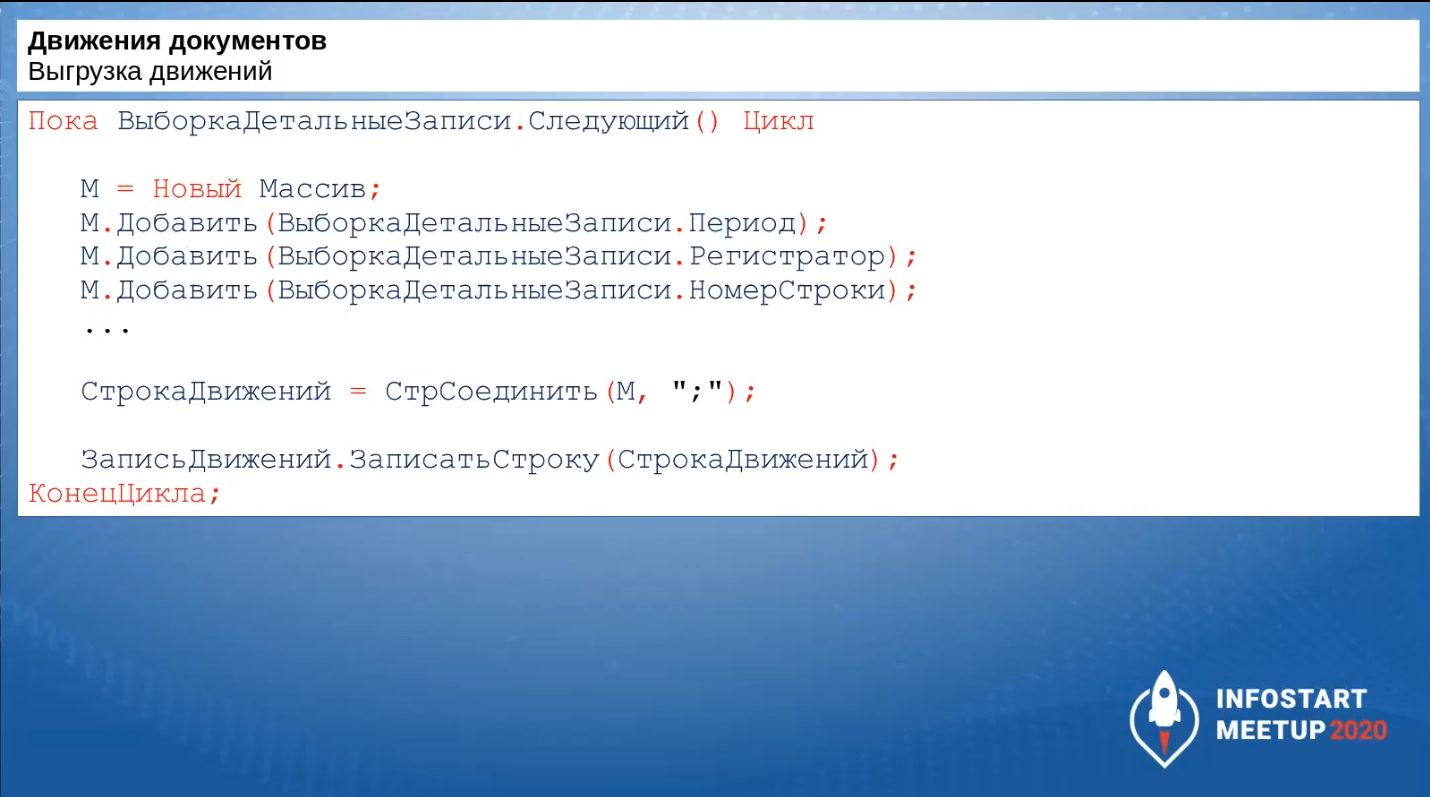
Вот так может выглядеть кусок кода для выгрузки движений.
Готовая обработка для выгрузки движений регистров по методике «Тестирование черного ящика»
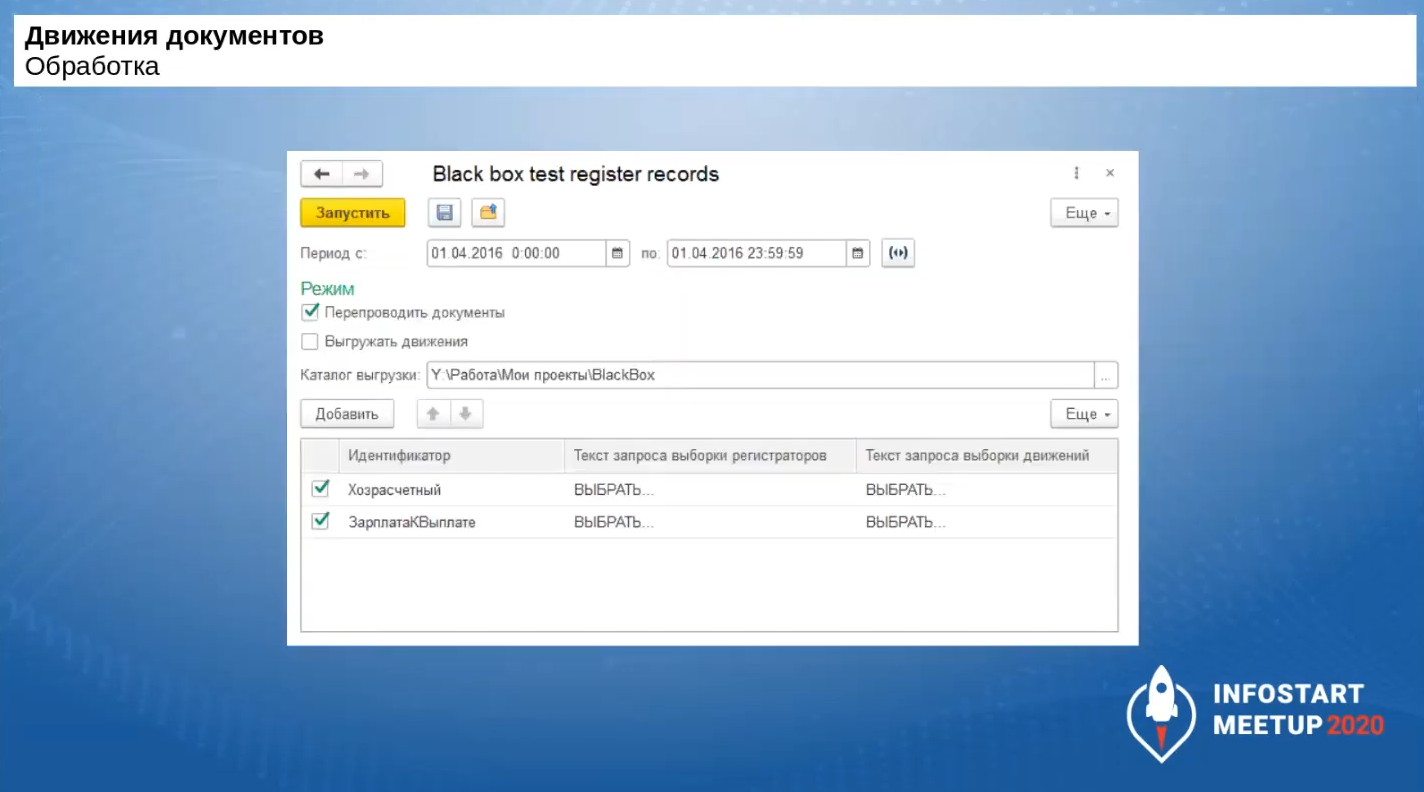
Такая обработка для выгрузки движений регистров в текстовые файлы уже существует – ее исходники в формате конфигуратора у меня опубликованы в репозитории на ГитХабе. В качестве первоначального варианта вам подойдет.
-
В ней есть вся обвязка по получению параметров запроса &ПериодНачало и &ПериодОкончание.
-
Реализовано так, что проведение документов производится на сервере, а потом результаты передаются на клиент и записываются в каталог выгрузки в клиентской процедуре.
-
Для гибкости сделано, что на каждый из регистров, которые проверяем, пользователь может создать два запроса – отдельно на выборку регистраторов и на выборку движений.
-
К тексту самих запросов есть определенные требования, они подробно описаны в документации, которая тоже выложена в репозитории.
Эту обработку можно забирать и использовать.
Применимость методики «черного ящика»
По методике «черного ящика» я тестировал не только проведение, но и заполнение документов. Правда, в этом случае вы должны уметь работать с Vanessa Automation, потому что в этом случае используются свои шаги по обработке заполнения и определенным образом построенные feature-файлы. Там смысл в том, что мы получаем табличную часть документа до заполнения, после чего заполняем ее, используя команду в интерфейсе, получаем два разных файла: до заполнения и после. И потом сравниваем эти файлы с эталонными данными.
По этой же методике мы тестировали даже процедуру согласования документов. Тоже использовали VA, но шаги не были универсальными, они были заточены под конкретную конфигурацию и проверку конкретной функциональности.
По этой методике мы можем получить «быстрые» тесты. Это не значит, что мы получим тесты, которые быстро выполняются – выполняться они могут как раз-таки очень долго, но для получения таких текстов никаких особых усилий не требуется.
А уже потом мы поймем, какие проверки нам нужно ускорять и переводить на сценарные тесты – будем потихоньку уходить в этих проверках от методики «черного ящика».
Вопросы
Есть вопросы к Машиному коду.
Сразу хочу сказать, что я выбрал тот пример, в котором мы сразу можем увидеть проблематику. Конечно, можно придраться, сказать, что Маша – нехороший программист. Я к тому, что бывают такие заковырки, что мы очень быстро не найдем эту проблему. Ведь мы не можем заранее знать, как система будет изменяться. И требования к коду могут поменяться. Если бы Маша эту задачу разрабатывала после того, как Миша второй раз внес изменения, то, конечно же, она пошла бы по другому пути. Но заранее мы это не можем спрогнозировать, потому что мы оцениваем задачу «здесь и сейчас». В этом – основной посыл, что на момент написания это был качественный код, но по прошествии какого-то времени он уже становится некачественным даже без внесения туда изменений.
Вы как-то снимаете покрытие кода?
Нет, покрытие кода – очень интересная задача, но нет, не снимаем.
Печатные формы как-то тестируете?
По этой методике – нет. А вообще Vanessa Automation прекрасно тестирует печатные формы – и документов, и отчетов.
Понятно, что тесты дают отличный профит. Как мотивировать команду и начать использовать тесты? Как сделать этот процесс естественным и однозначно необходимым в цикле разработки?
Мой опыт показывает, что декларативно с помощью какого-то кнута это не зайдет. Ни качество кода, ни автотесты. Это нужно уметь продать разработчикам. Продавать будете долго, но, если это у вас получится сделать, разработчики будут это использовать. Если вы сами поняли, что вам нужны автотесты, начните их писать, начните покрывать свой код, будьте лидером в этом направлении. Через какое-то время, когда вы этими тестами выловите какую-то ошибку в своем или в чужом коде, только после конкретных кейсов, когда это пригодилось, разработчики к этому тоже потянутся. Не факт, что им зайдет сценарное тестирование – это все-таки отдельная холиварная тема. Но юнит-тестирование может очень хорошо зайти, плюс вы убьете двух зайцев. У вас будет тест, и у вас улучшится качество кода, потому что юнит-тестирование накладывает определенные требования к структуре кода. И если юнит-тестирование разработчикам зайдет (а как правило, заходит), то и код у вас будет более структурированный даже без внедрения SonarQube, АПК и всего остального.
Какая в итоге база берется для тестирования – выгрузка рабочей на текущий момент? Или как-то отдельно подготавливается?
У нас берется выгрузка рабочей. Да, мы нарушаем best practice в тестировании, мы берем именно рабочую базу, потому что мы не знаем, как она работает, и не знаем, какой минимальный набор тестовых данных нам нужен для проведения тестирования. Поэтому берется рабочая. Почему я и говорю, что это – первые тесты, которые вы уже можете сейчас запустить. Но в дальнейшем вы будете избавляться от этих тестов, вам нужно будет часть функциональности уже переводить на юнит-тестирование или на сценарные тесты. Таким образом, редактируя запросы по выборке документов для перепроведения, в какой-то момент (через год или через два) вы поймете, что вам документы уже не нужно выбирать, вы их уже покрыли какими-то другими тестами. Поэтому через какое-то время уже не нужна будет полная копия рабочей базы.
Если Маша завернула свою статистику в отчете, разве такой случай можно покрыть тестами?
У этой методики есть свои ограничения, по этой методике мы тестируем именно артефакты. То, что у нас в базе появляется. Это не волшебная палочка, часть функциональности мы все равно проверить не сможем. Но могу привести практический пример – по этой методике внедрили тестирование в конфигурации «Проверка начислений ЖКХ», и вначале это тестирование шло 8-10 часов, но с разрастанием кодовой базы, с внесением изменений у нас эти тесты стали проходить несколько суток. Но разработчики к этому моменту уже поняли плюсы этого тестирования, что действительно очень много ошибок – неявных, они этой методикой вылавливаются. Поэтому через какое-то время разработчики бизнес-задач пошли навстречу и внедрили параллельное проведение документов с точки зрения основной функциональности программы. И время выполнения тестов опять спустилось с неприемлемых трех суток до приемлемых нескольких часов. Это тоже большой плюс.
Представленный подход – это попытка сделать регрессионное тестирование самым быстрым доступным способом?
Да, мы сразу же выбираем ту функциональность, которая не должна упасть на все 146%, потому что всю конфигурацию проверять очень долго. Здесь мы берем именно то, что вообще никогда не должно упасть и проверяем только это. Но да, это действительно регресс.
Тут в любом случае есть побочный эффект, и сложно будет не зависеть от данных. Если есть ошибки в данных, и из-за этого тесты падают, то тут беда.
Да, но у нас же есть две копии базы. У нас эти ошибки появятся как в первой, так и во второй базе. И мы их увидим. Главное, чтобы эти ошибки совпали. Допустим, два документа не провелись из-за того, что ошибки в данных. Но если ошибка одинаковая – да и ладно. Мы же проверяем не только движение документов, но и логику перепроведения. Главное, чтобы все это совпадало. А если в одной базе документ провелся, а в другой – нет, то наверняка это ошибка, потому что набор из начальных данных – одинаковый.
Мне такой подход знаком по обработке «Сценарное тестирование» от фирмы «1С». У них даже есть шаг «Сверить с эталоном».
Методика-то сама хорошая, если вам нужно что-то сделать быстро. Потому что сколько времени вы будете разрабатывать все юнит-тесты, чтобы это покрыть Сколько времени вам нужно, чтобы разработать все сценарные тесты для покрытия этой функциональности. При условии, что документации нет. Даже если она существует, насколько вы уверены, что она соответствует действительности.
Кто-то проводил реверс-инжиниринг кода, сколько тестов нам нужно, чтобы покрыть этот код, просчитать все сценарии, которые заложены в коде? У меня был такой опыт, я неделю проводил такой анализ. Я плюнул, когда количество тестовых сценариев у меня получилось около 50. Причем я еще не до конца дошел.
Это большой больной вопрос, особенно с учетом всех функциональных опций. И вообще вопрос глобальный – нужно ли тестировать типовой код и в каком объеме.
Согласен, но это более философский вопрос – нужно ли нам все тестировать, когда у нас и так все хорошо работает. В реальности для наших клиентов, они же не разделяют – это типовой код или это наш код. Это, в принципе, программа. И даже если ошибка в типовом коде – это не значит, что мы не должны ее исправлять. Тут все зависит от рисков, которые несет бизнес при возникновении этой ошибки. Если это допустимый риск, то, наверное, тестировать не нужно. Если не допустимый – даже если типовой код, надо писать тесты.
Есть мнение, что тесты на типовой код должны поставляться фирмой «1С». Отчасти так и есть, сейчас с УНФ поставляются сценарии тестирования. Раньше команда «Бухгалтерии предприятия» поставляла тесты для «Сценарного тестирования». Факт в том, что нужно уметь эти тесты запустить – для этого нужна инфраструктура. Сам процесс тестирования длительный. И набор поставляемых тестов не покрывает все сценарии на 100% с учетом всех функциональных опций. У нас пока еще типовые конфигурации не адаптированы под тестирование глобально. Движение в эту сторону только еще начинается.
Хорошо, что оно началось. Есть термин «В мире большого программирования» – я всегда смеюсь, когда его слышу. Если смотреть open-source-решения на GitHub – как правило, там в требованиях к контрибьютеру написано, что вы должны писать тесты на свой код. И это нормально. У других программистов даже не возникает мысли о том, что можно написать код и не покрыть его юнит-тестами своими собственными. Но почему-то в мире 1С к теме автотестирования такой скептический настрой.
В оправдание мира 1С могу сказать, что в отличие от остального мира программирования у нас очень сложно написать быстрые модульные тесты, которые за секунды выполняются. Даже если параллелить потоки, у нас 10 секунд на один тест, а в других фреймворках – 10 секунд на все тестирование. Многих отталкивает то, что результат тестирования нельзя увидеть сразу. Особенно, если нужно прогнать большое количество тестов.
Да, это большая холиварная тема. Из-за того, что система получается очень сложно-связная, невозможно понять, какое количество тестов нужно запустить, чтобы проверить ту функциональность, которую я поменял. Мы этого заранее не знаем.
В тему запуска тестов – на хабре недавно опубликовали перевод письма бывшего разработчика Oracle, в котором он рассказывал, как у них идет разработка. Это очень интересно – там количество тестов исчисляется миллионами. И если разработчик исправит какую-то ошибку, его задача будет тестироваться двое-трое суток. Он за это время приступает к другой задаче, потратит на нее день и так же ее отправляет в тестирование. Для его тестов поднимается своя собственная ферма серверов и опять же, на двое-трое суток уходит в тестирование. А к моменту, когда он отправил на тестирование вторую задачу, придет результат по первой. И там таким образом работают. Основной посыл статьи – почему решение Oracle стабильное, несмотря на то, что там очень много кода двадцатилетней давности. Количество тестов очень большое, процент покрытия очень большой. И тогда вероятность ошибки снижается на несколько порядков.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "Путь к идеальному коду".


Вступайте в нашу телеграмм-группу Инфостарт