Партицированная дисциплина программиста в 1С
Как известно, возможности партицирования при использовании 1С ограничены по ряду причин:
- Этому мешают общие реквизиты \ разделители, которые добавляются как первое поле в каждый индекс (справедливо для типовых конфигураций.)
- Ряд метаданных не поддается партицированию (Например, Регистры бухгалтерии, Документы с табличными частями) поскольку они состоят из нескольких таблиц, в которых нельзя выделить одинаковое по смыслу поле для партицирования (partitioned column)
Подробнее все описано тут Методика похудения для 1С - 100%
Но можно жить и без партицирования, если правильно ставить условия в запросах и «попадать в индекс». Однако просто «попадания в индекс» недостаточно. Причем такие эффекты проявляются именно при росте базы 1С.
При работе с большими объемами в 1С храните версии.
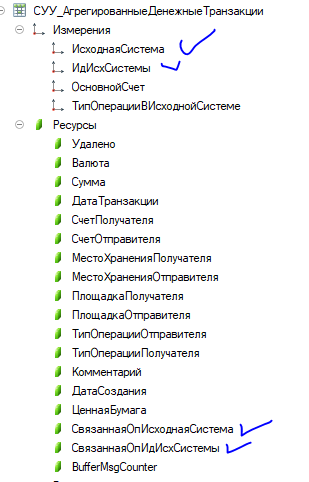
Для примера возьмем сделки и трансферы, которые хранятся в двух регистрах сведений
Трансферы со ссылкой на сделку
И сделки
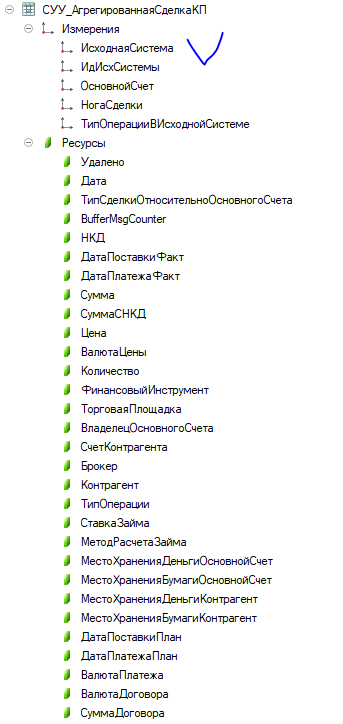
Почему в регистрах сведений, а не документах? Для того чтобы повысить скорость импорта операций, используя запись версий операций, пакетами по 1000 штук. Версия хранится в поле Период как дата\время загрузки. Подробнее можно прочитать тут Язык мой враг мой. В этом случае можно использовать максимальную возможную для платформы 1С скорость импорта, поскольку нет обновлений с фильтром на равенство для измерений , а идет только запись новых наборов записей. В качестве минуса – в запросах на каком-то этапе приходится вычислять последние версии операций.
Наша задача:
- Отобрать трансферы по нужным критериям, сохранить СвязаннаяОпИдИсхСистемы во временную таблицу
- Проиндексировать Врем_ИдОперацийИзТранзакций.
- Соединить Врем_ИдОперацийИзТранзакций с СУУ_Агрегированная_СделкаКП по Ид сделки
Типичная задача соединения трансферов со сделками.
Вопрос: Почему приходится соединять через временную таблицу?
Просто при версионной структуре хранения, напрямую трансферы и сделки соединить не получится – ведь у них разные значения версий. Соединять срезы последних неэффективно (это тема отдельной статьи). Но даже простое соединение по Ид не так просто,когда записей сотни миллионов.
Таблицы большие
- СУУ_АгрегированнаяСделкаКП - 210 миллионов записей
- СУУ_АгрегированныеДенежныеТранзакции – 474 миллиона записей
- В качестве MS SQL используется версия 2019 (15.0.2000.5)
Итак, базовый запрос, ничего сложного
Отбираем ограниченный набор Ид, а потом соединяем с большой таблицей сделок
ВЫБРАТЬ РАЗЛИЧНЫЕ
СУУ_АгрегированныеДенежныеТранзакции.СвязаннаяОпИдИсхСистемы КАК СвязаннаяОпИдИсхСистемы
ПОМЕСТИТЬ Врем_ИдОперацийИзТранзакций
ИЗ
РегистрСведений.СУУ_АгрегированныеДенежныеТранзакции КАК СУУ_АгрегированныеДенежныеТранзакции
ГДЕ
СУУ_АгрегированныеДенежныеТранзакции.Период >= &ДатаНачала
ИНДЕКСИРОВАТЬ ПО
СвязаннаяОпИдИсхСистемы
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
СУУ_АгрегированнаяСделкаКП.Период,
СУУ_АгрегированнаяСделкаКП.ИсходнаяСистема,
СУУ_АгрегированнаяСделкаКП.ИдИсхСистемы КАК ИдИсхСистемы,
СУУ_АгрегированнаяСделкаКП.ОсновнойСчет,
СУУ_АгрегированнаяСделкаКП.НогаСделки
ПОМЕСТИТЬ РезультатВыбранныеВерсииСделок
ИЗ
РегистрСведений.СУУ_АгрегированнаяСделкаКП КАК СУУ_АгрегированнаяСделкаКП
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Врем_ИдОперацийИзТранзакций КАК Врем_ИдОперацийИзТранзакций
ПО СУУ_АгрегированнаяСделкаКП.ИдИсхСистемы = Врем_ИдОперацийИзТранзакций.СвязаннаяОпИдИсхСистемы
;
И каждый раз сбрасываем в SQL Server все что можно
DBCC SQLPERF("sys.dm_os_wait_stats",CLEAR);
DBCC SQLPERF("sys.dm_os_wait_stats",CLEAR);
DBCC FREEPROCCACHE ;
DBCC DROPCLEANBUFFERS;
Все индексировано, а счастья нет
Последний SQL запрос выглядит так
INSERT INTO #tt2 WITH(TABLOCK) (_Q_001_F_000, _Q_001_F_001RRef, _Q_001_F_002, _Q_001_F_003RRef, _Q_001_F_004RRef) SELECT
T1._Period,
T1._Fld18861RRef,
T1._Fld18865,
T1._Fld18863RRef,
T1._Fld19363RRef
FROM dbo._InfoRg18860 T1 WITH(NOLOCK) –Таблица сделок
INNER JOIN #tt1 T2 WITH(NOLOCK) –Временная таблица с Ид сделками
ON (T1._Fld18865 = T2._Q_000_F_000) –Условие соединения по номеру
WHERE (T1._Fld628 = @P1) –Общий реквизит разделитель ОбластьДанныхОсновныеДанные
Если его исполнить на небольшом количестве записей 100-200 тыс, то SQL картина будет несколько искаженная: SQL Server использует Nested loop, и не пытается использовать более правильный Merge Join – видимо, все соединение можно сделать в памяти
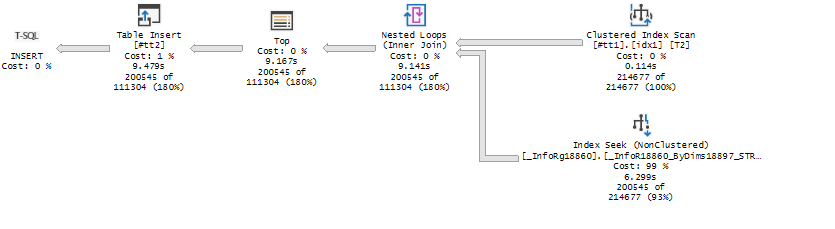
А нужный индекс для Merge join существует _InfoR18860_ByDims18897_STRRRR (_Fld18865 -ИдИсхСистемы)
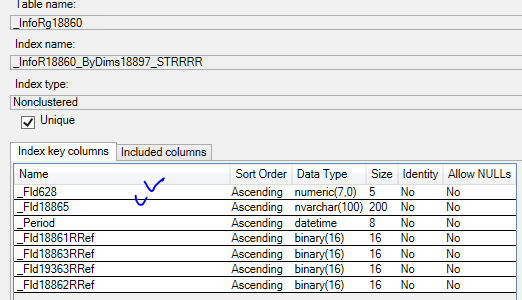
и как покажет следующая итерация ниже – используется
Увеличим период выборки по трансферам, получим больше Ид во временную таблицу (20 миллионов – типичный наш объем за месяц )
Врем_ИдОперацийИзТранзакций посмотрим, как поменялось соединение
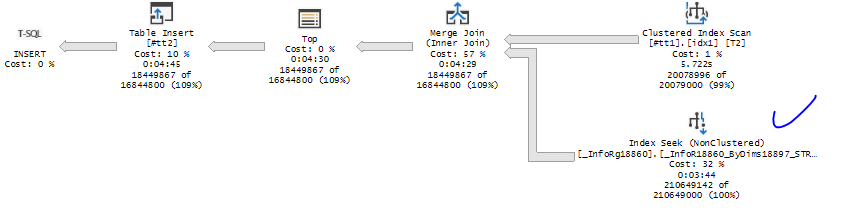
Index seek стал выполнятся с выдачей в поток почти всех данных (ранее был цикл обхода), а Nested loop в Merge join который принимает на вход потоки отсортированных данных по таблицам #tt1 и _InfoR18860. Вроде все корректно?
Подробнее можно увидеть тут

Данные отсортированы строго по индексам но проблема в том, что оптимизатор SQL Server выбирает Index Seek по _InfoR18860_ByDims18897_STRRRR и дает на вход Merge Join 210 649 142 строк т.е. весь индекс , хотя он соединяется с таблицей #tt1, в которой всего 20 миллионов отсортированных значений и по которой он делает
|--Merge Join(Inner Join, MANY-TO-MANY MERGE:([T2].[_Q_000_F_000])=([T1].[_Fld18865]), RESIDUAL:(#tt1.[_Q_000_F_000] as [T2].[_Q_000_F_000]=[MIS_PROD2].[dbo].[_InfoRg18860].[_Fld18865] as [T1].[_Fld18865]))
|--Clustered Index Scan(OBJECT:([tempdb].[dbo].[#tt1] AS [T2]), ORDERED FORWARD)
|--Index Seek(OBJECT:([MIS_PROD2].[dbo].[_InfoRg18860].[_InfoR18860_ByDims18897_STRRRR] AS [T1]), SEEK:([T1].[_Fld628]=[@P1]) ORDERED FORWARD)
Здесь, конечно, есть Seek [T1].[_Fld628]=[@P1] по общему реквизиту разделителю (ОбластьДанныхОсновныеДанные), но это неизбежность при использовании типовой конфигурации или БСП
Анонс: Влияние общих разделителей на запросы
Обратите внимание как поведет себя MS SQL, если еще увеличить количество Ид в #tt1
Вместо Index Seek по _InfoR18860_ByDims18897_STRRRR может превратится в Index Scan в зависимости от количества записей в #tt1
Проблема
1) получается печальная картина, чем больше таблица, тем медленней будет простой запрос на соединение с фиксированным количеством записей (в нашем случае 20 миллионов)
2) идеологически правильный план MS SQL берет на больших данных, а на объемах поменьше может выбрать Nested loop, который по факту может быть не таким эффективным.
Правильно сформулированный запрос, это половина ответа
В теории MS SQL , который принимает отсортированные потоки для Merge join мог бы посмотреть на значение первого и последнего элемента в #tt1 и сделать более умный Index seek который возвратил бы меньшее количество записей. Но если он это он это делать не умеет – придется помочь. В нашем примере два варианта
- Наложить условие на поле ИдИсхСистемы, ограничив его минимальным из #tt1 значением. Оно _Fld18865 тут строковое, поэтому могут быть нюансы производительности в зависимости от типа данных
- Наложить условие на поле Period (Период) – поскольку там содержатся даты\время загрузки версий (примечание в поле Дата – дата операции ). Можно наложить условие на заведомо закрытый период
Попробуем условие на Period тем более, что оно следующее за _Fld18865 в индексе _InfoR18860_ByDims18897_STRRRR
В последний запрос будет добавлено условие
ГДЕ
СУУ_АгрегированнаяСделкаКП.Период >= ДОБАВИТЬКДАТЕ(&ДатаНачала, МЕСЯЦ, -3)
Смотрим новый план
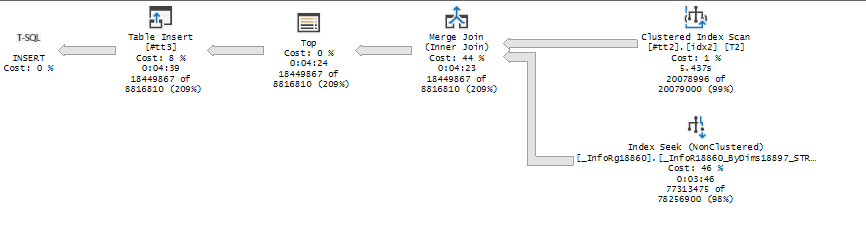
Картина становится гораздо приятнее теперь Index Seek дает всего 77 миллионов записей записей
Условие Index Seek тоже поменялось, раньше оно выдавало все а теперь только то, что мы ограничили снизу
|--Index Seek(OBJECT:([MIS_PROD2].[dbo].[_InfoRg18860].[_InfoR18860_ByDims18897_STRRRR] AS [T1]), SEEK:([T1].[_Fld628]=[@P1]), WHERE:([MIS_PROD2].[dbo].[_InfoRg18860].[_Period] as [T1].[_Period]>=[@P2]) ORDERED FORWARD)
Если сравним фактическую стоимость запроса, увидим что Estimate IO и CPU уменьшились именно на merge join. На минуты\секунды можно не смотреть, поскольку тест был на виртуальной среде с совместным использованием ресурсов сервера

Общая стоимость в «попугаях» снизилась с 11424 до 7801
Вывод -
нам всегда в MS SQL нужно указывать явно границу для Index Seek.
Партицируем непартицируемое
На что это похоже? Кто работал с партицированием, увидит partitioning column
Для эффективных запросов по партицированным таблицам она должна быть всегда в условиях, иначе будет обход всех партиций, даже если требуемые индексированные данные только в одной
подробно этот эффект описан тут Работа с партициями в MS SQL
Как замечено выше, для типовых конфигураций партицирование применять затруднительно,но для того, чтобы работать с большими объемами, для каждого запроса придется выбирать свой аналог «partitioning column», чтобы ограничить стремление MS SQL сделать неэффективный Index seek. Получается, на больших базах нельзя жить без партиций, даже если их нет. 1С по сути всего лишь очень удобный генератор запросов к СУБД и если нужно делать это эффективно, без знания работы СУБД не обойтись. Все что изложено – применимо и к другим метаданным, поскольку соединения MS SQL делает по одинаковому принципу.
Лучший план запроса враг хорошего?
Можно ли еще улучшить план? Это не так просто, поскольку тут уже нужно смотреть глубже на работу оптимизатора SQL и подбирать нестандартные индексы,а это уже отдельная статья. Один простой вариант – отказаться от Join и применить условие IN.
Последний запрос этом случае будет выглядеть так
ВЫБРАТЬ
СУУ_АгрегированнаяСделкаКП.Период,
СУУ_АгрегированнаяСделкаКП.ИсходнаяСистема,
СУУ_АгрегированнаяСделкаКП.ИдИсхСистемы КАК ИдИсхСистемы,
СУУ_АгрегированнаяСделкаКП.ОсновнойСчет,
СУУ_АгрегированнаяСделкаКП.НогаСделки
ПОМЕСТИТЬ РезультатВыбранныеВерсииСделок
ИЗ
РегистрСведений.СУУ_АгрегированнаяСделкаКП КАК СУУ_АгрегированнаяСделкаКП
ГДЕ
СУУ_АгрегированнаяСделкаКП.Период >= ДОБАВИТЬКДАТЕ(&ДатаНачала, МЕСЯЦ, -3) И СУУ_АгрегированнаяСделкаКП.ИдИсхСистемы В (ВЫБРАТЬ СвязаннаяОпИдИсхСистемы ИЗ Врем_ИдОперацийИзТранзакций)
Как ни странно, в MS SQL оно работает лучше , хотя план почти похож (исчез cost на IO на уровне Merge). Кстати, стоимость стала 4666
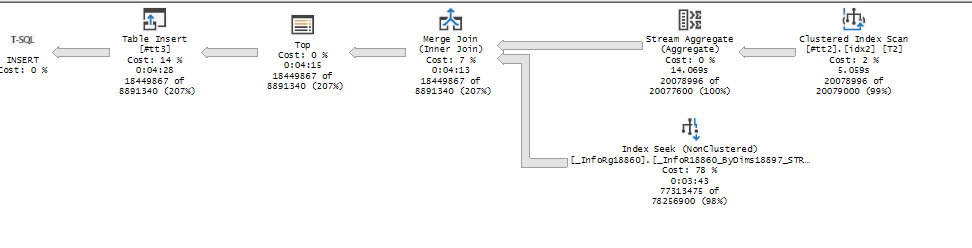
Но цена ниже

Т.е. с ростом объемов, программировать на 1С без углубления знаний в СУБД невозможно – ведь 1С это всего лишь генератор запросов (ORM Object-Relational Mapping подобный) со всеми его минусами. Буду рад видеть Вас на нашем канале 😊
Вступайте в нашу телеграмм-группу Инфостарт