В предыдущей части статьи Концепция ORM как двигатель прогресса — выдержит ли ее ваша СУБД? было живое обсуждение и, как я понял из вопросов, не все осознают глубину проблемы низкой производительности ORM. Я верю, что можно написать ORM, где потери производительности минимальны, но на практике не смотрят, как это будет работать в СУБД. Результат – низкая производительность ORM. Да, проблема находится на границе программирования и тонкой настройки СУБД, и для понимания последствий нужно иметь хороший опыт на этих уровнях. Поэтому я решил сделать FAQ и добавил еще один тест с увеличенной длинной транзакции. Поскольку у нас здесь запись по непересекающимся ключевым полям, и уровень изоляции read committed, проблем с блокировками не будет. Статья была готова еще в прошлом году, но я предпочел опубликовать необычный прогноз на 2023 год, который отлично зашел на Smart Lab , но на хабре он не прошел в разделе научпоп – видимо, работы ученого Чижевского А. забыты.
Далее изложен FAQ, в данном случае для MS SQL и Oracle, но только для того, чтобы в будущем проверить Postgres тем же методом. Вот и увидим, является ли Postgres импортозамещением для 1С или нет.
Часто задаваемые вопросы
Вопрос: А о чём статья? О том, что ещё один слой абстракции ORM над данными замедляет работу? Так это как бы очевидно.
Ответ: ORM ускоряет разработку и делает ее удобной, но это не значит, что он должен замедлять работу. Если ORM изначально проектировать на запись наборами сущностей (операций, документов и т.д.), а внутри формировать ORM крупные DML, то никаких существенных замедлений не будет. Наоборот, за счет горизонтального маштабирования (смотрите ниже) можно ускорить обработку достаточно существенно.
Вопрос: Если не устраивает поток мелких DML создаваемых ORM, почему бы не использовать более низкий уровень работы с СУБД (ODBC, JDBC)?
Ответ: ORM позволяет делать более крупные DML, но если она изначально спроектирована для записи множества операций\записей одним крупным DML. Улучшения типа Batching, например, в JDBC эту проблему не решают. ORM позволяет ускорить разработку, проблема в том, что текущие известные мне библиотеки ORM на оптимальную работу с СУБД не рассчитаны. Это же не повод отказываться от концепции ORM для Highload приложений?
Вопрос: В статье утверждается, что SSD не является узким местом из за наличия запаса по IOPS. Используемая конфигурация с SSD это не доказывает, только лог на RAM диске покажет истинную картину.
Ответ: Тесты показывают, что сам RAM диск может быть узким местом, см. тут Тестирование скорости работы 1C в режиме файловой версии, MS SQL и POSTGRES на HDD, SSD и RAMDisk и проигрывает SSD. Скорее всего диспетчер RAM диска не поддерживает многопоточность и висит на одном ядре. Если найдете RAM диск с многопоточным диспетчером, проверю.
Вопрос: В статье утверждается, что Transaction log узкое место. Если Transaction log узкое место, а запись в transaction лог идет в определенной последовательности – какая разница, писать одним крупным DML или множеством мелких DML?
Ответ: Это не так, производители СУБД постоянно работают над ликвидацией узких мест. Например, в MS SQL запись в Transaction Log sql сервер сделали многопоточной, см. тут Troubleshoot slow SQL Server performance caused by I/O issues
Prior to SQL Server 2016, a single Log Writer thread performed all log writes. If there were issues with thread scheduling (for example, high CPU), both the Log Writer thread and log flushes could get delayed. In SQL Server 2016, up to four Log Writer threads were added to increase the log-writing throughput. See SQL 2016 - It Just Runs Faster: Multiple Log Writer Workers. In SQL Server 2019, up to eight Log Writer threads were added, which improves throughput even more. Also, in SQL Server 2019, each regular worker thread can do log writes directly instead of posting to the Log writer thread. With these improvements, WRITELOG waits would rarely be triggered by scheduling issues.
Вопрос: Если сделать транзакцию более крупной, поместив в нее больше мелких DML, данные в transaction log будут сбрасываться более крупными партиями? Разве это не решит проблему мелких DML?
Ответ: Если посмотрите на трейс, который порождает одна операция .Записать(), то там минимум 7 DML в одной транзакции. Т.е. у нас и так транзакция не на каждый DML, а на группу DML и результаты в предыдущей части показывают, что Transaction log это бутылочное горлышко. Но все таки есть осторожные рекомендации Tuning writelog
Too many small transactions: While large transactions can lead to blocking, too many small transactions can lead to another set of issues. If you don't explicitly begin a transaction, any insert, delete, or update will result in a transaction (we call this auto transaction). If you do 1,000 inserts in a loop, there will be 1,000 transactions generated. Each transaction in this example needs to commit, which results in a transaction log flush and 1,000 transaction flushes. When possible, group individual update, delete, or insert into a bigger transaction to reduce transaction log flushes and increase performance. This operation can lead to fewer WRITELOG waits.
У других производителей СУБД можно тоже найти рекомендации группировать мелкие DML в крупные транзакции. В нашем тесте мы можем себе это позволить поскольку он ориентирован на запись, чтение идет в самом начале, а полное разделение данных по регистраторам, и структура регистра исключает deadlocks. Это несколько идеальная ситуация, ведь при реальной задаче перепроведения документов мы делаем чтения наборов записей (возможно из других регистров\ структур данных), блокировки записываемых наборов. Все это в крупной транзации заставит вспомнить про уровни изоляции ( MS SQL Isolation levels ) про блокировки, дедлоки которые может повлечь укрупнение транзакции. Поэтому и рекомендации такие осторожные.
Тест с удлиненной транзакцией
Итак , модифицируем программный код обработки на возможность делать крупные транзации

Запускаем и смотрим результаты: Waits на write log ушли вниз, но, правда, среднее время ожидания на запись (AvgWait_s) для writelog все равно плохое (запомним это). В топе теперь ожидания на запись в файлы данных.
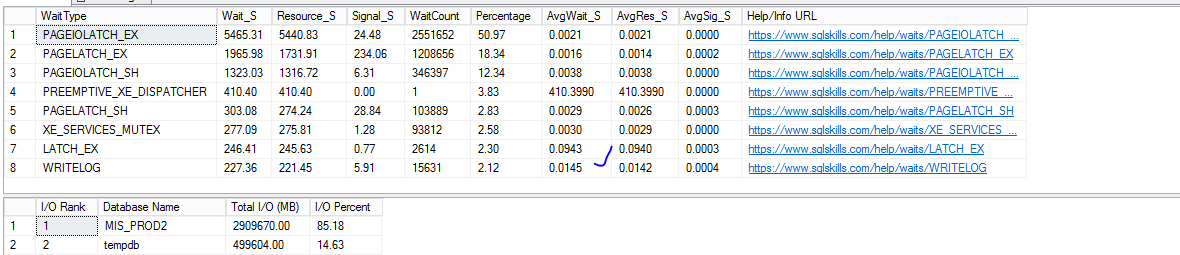
Далее смотрим – стал ли Writelog писать более интенсивно?
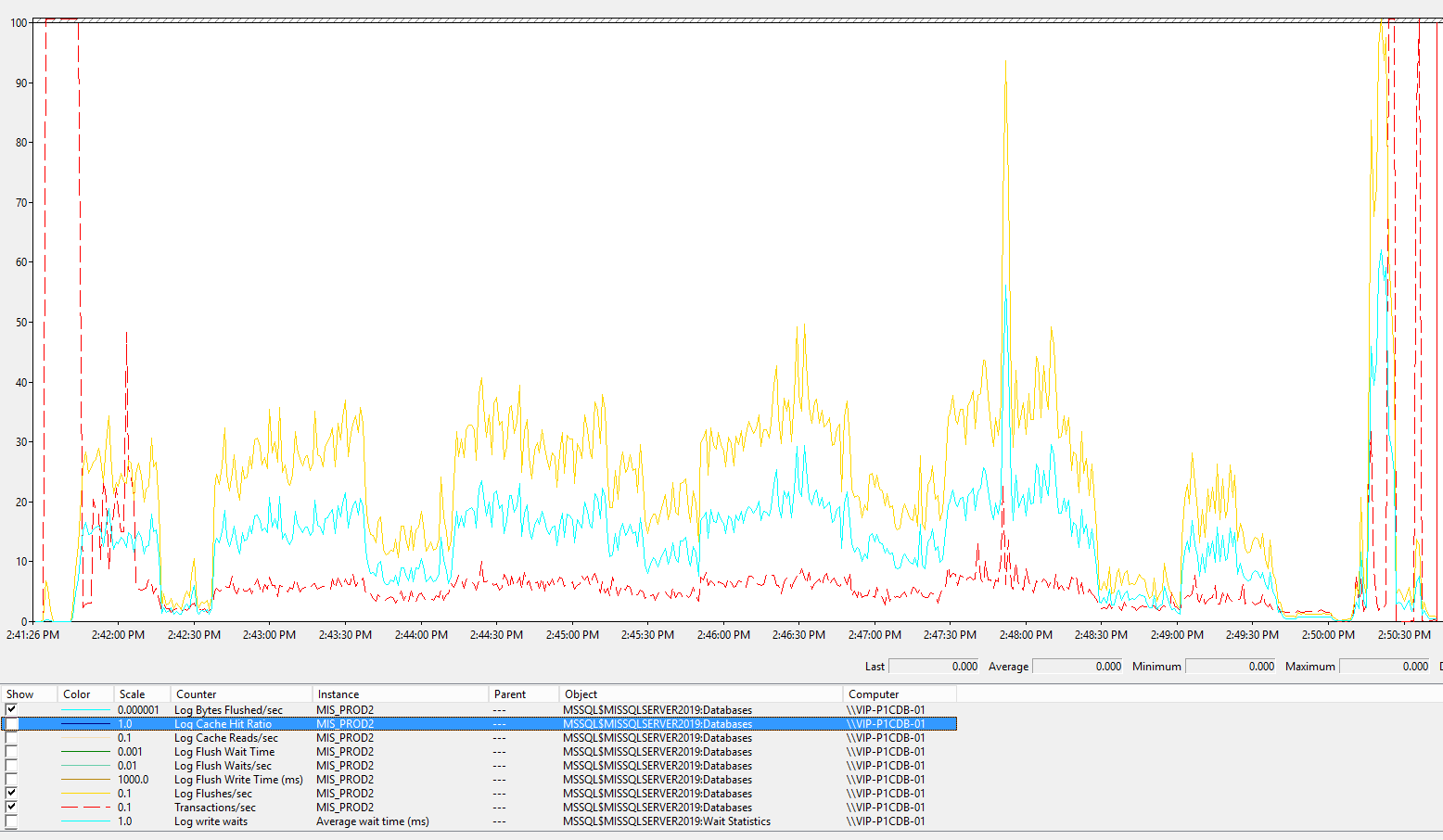
Log Bytes Flushed (голубой) – практически не поменялся по уровню, это и объяснимо: DML те же, но просто транзакция в 20 раз больше. Но вот Сброс Flushes\sec (песочный) резко упало с 60 до 30.
А почему не на большую величину? Потому что Commit, это не единственное событие, которое инициирует сброс данных в transaction log. Есть еще такое понятие, как Checkpoint, оно присутствует не только в MS SQL, Oracle. Его можно вызывать явно, либо оно срабатывает по условия – см. подробности тут Database checkpoints.
Ко всему прочему запись в Transaction log идет асинхронно. Я думаю, те, кто делал реструктуризации конфигурации в 1С, помнят, как может вырасти Transaction log при добавлении реквизита в объект, ведь все реструктуризацию 1С делает в одной! транзакции. Если думаете, что все зависит от commit, просто задайтесь вопросом – куда будут деваться измененные данные при транзакции на десятки миллионов, и Вы поймете, как функционирует запись в Transaction log. Примечание – в Oracle Redo log имеет структуру циклической записи, там еще все интересней.
Смотрим дальше – может, у нас изменилось количество обрабатываемых DML в секунду? Можем обратить внимание на BatchRequest\sec
Есть небольшое увеличение – раньше было ниже 10 тыс\сек, сейчас уже стабильно 10 тыс\сек.

Ну и, наконец, давайте проверим – повлияло ли это на скорость в самой обработке? Напомню, она написана с учетом горизонтального масштабирования (50 потоков), и даже небольшое увеличение в каждом потоке может дать мультипликативный эффект.
В целом, да, повлияла: 1803 против 1374 в предыдущем тесте, т.е. рост 31%. Т.е. меньше, чем 1% на поток. Это незаметно для одного потока, но при горизонтальном масштабировании очень заметно.
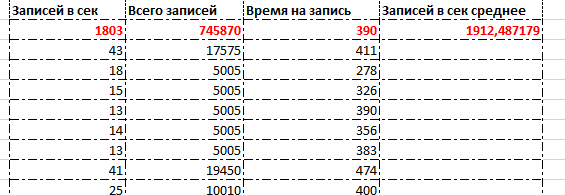
Но есть и хорошая новость, Waits стали гораздо меньше, значит, можно увеличить нагрузку, например, до 75 потоков.
Как протиснуться в бутылочное горлышко?
Собственно рекомендации были даны в исходной статье Концепция ORM как двигатель прогресса — выдержит ли ее ваша СУБД?, и я сторонник использовать более крупные операторы DML на пакет из Х записей, нежели псевдо оптимизации типа Batching или глубокий тюнинг Transaction log. Но, конечно, доказательство этого факта требует отдельной статьи. То, что проблема актуальна в разных языках – достаточно сделать поиск по словам «orm low performance», «jpa low performance» . Можно найти
Почему следует избегать использования JPA/Hibernate в продакшене / Хабр (habr.com)
Откуда тормоза в ORM? / Хабр (habr.com)
Node.js ORMs: Why you shouldn’t use them - LogRocket Blog
The two top performance problems caused by ORM tools : programming (reddit.com)
SivaLabs - Improve JPA application performance using HypersistenceOptimizer
Несмотря на поверья - увеличение длины транзакции существенного увеличения пропускной способности Transaction log не дает, но к проблемам в реальной системе с блокировками приведет с большой вероятностью. До новых встреч на нашем телеграмм канале. А пока эту методику можно использовать для оценки производительности Postgres в реальных системах, тем более что в 1С перевести базу из MS SQL в Postgres можно штатной выгрузкой\загрузкой базы.
Вступайте в нашу телеграмм-группу Инфостарт