Метод исследования и инструменты
1С это не только удобный инструмент для быстрой прикладной разработки и кастомизации готовых конфигураций, это еще и идеальный нагрузочный тест в стиле ORM (Object relationship mapping) для СУБД (на текущий момент поддерживается MS SQL, Oracle, PostgreSQL\Pro, IBM DB2). Количество DML, порождаемых только одной операцией .Записать() для регистра накопления, позволяет быстро найти узкое место вашего сервера СУБД, а кому-то снять розовые очки 0^0 в идеологии ORM решений. Еще с версии 1С 7.7 ORM подход, реализованный 1С, мне казался очень удобным и правильным, поскольку позволял не думать при разработке о многих вещах, таких как
- Реальная структура таблиц СУБД, индексов, первичных ключей
- Вид СУБД (файловая, Сервер баз данных)
- Сколько таблиц и индексов в одном объекте.
- И, наконец, быстрый результат при меньшем количестве кода
Можно сосредоточиться на бизнес-логике, где визуальное! создание одного объекта на уровне платформы создает все необходимые структуры СУБД, а управление идет через простые методы. Недостатки в производительности были видны и тогда, но ведь компания 1С это решит со временем, думал я? Однако активная работа с горизонтальным маштабированием в 1С 8.2\8.3 см. Язык мой враг мой привела к мысли, что это не отдельные недостатки отдельной компании. Это системная проблема текущей реализации различных ORM.
По концепции ORM ускоряет разработку и делает ее удобной, но это не значит, что он должен замедлять работу. Если ORM изначально проектировать на запись наборами сущностей (операций, документов и т.д.), а внутри формировать ORM крупные DML , то никаких существенных замедлений не будет.
Сам тест проведем на реальной базе 1С платформы 8.3 с оборотным регистром накопления с включенными агрегатами (подробнее тут Регистры накопления в 1С). Смоделируем перепроведение документов с переформированием движений\проводок, это частая операция при закрытии месяца либо меньшего периода. Если кому-то не интересно, как организован накопительный регистр, сразу посмотрите ниже таблицу DML операторов, которые порождает одна операция .Записать()
Такой тип регистра наиболее быстрый для записи, поскольку регистры накопления с остатками или регистр бухгалтерского учета имеют более сложную структуру. Кроме того, при записи в регистры остатков, обращение к итогам происходит при записи в текущую дату, и это происходит даже если отключены итоги на текущую дату, а период рассчитанных итогов сдвинут на месяц назад. В регистрах накопления с остатками при записи в период с рассчитанными итогами они обновляются при записи каждого блока проводок, что может провоцировать блокировки при интенсивной записи, несмотря на использование механизма разделителей.
В регистре накопления с агрегатами обновление агрегатов производит перенос данных из таблиц движений выбранного регистра в соответствующие таблицы агрегатов. Переносятся те движения, которые были созданы в таблице движений после предыдущего обновления агрегатов. Обновление агрегатов можно делать регламентным заданием, в этом его основное преимущество. Подробнее можно почитать тут Агрегаты оборотных регистров накопления .
Возьмем регистр полупроводок, который расширяет функциональность регистра Бухгалтерии
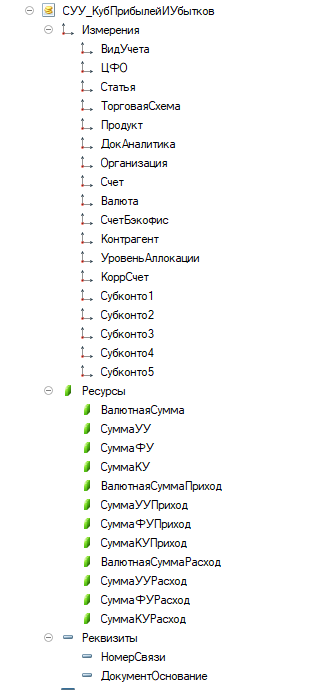
Все измерения проиндексированы, поэтому индексов, замедляющих запись и ускоряющих выборки, достаточно. Регистр достаточно типичный – результаты теста на нем можно использовать для предсказания поведения на подобных решениях
На уровне SQL Profiler мы можем увидеть, что происходит при записи в регистр
Полный трейс можно посмотреть тут <>
Поскольку часть логики скрыта в коде платформы, некоторые вещи можно только предполагать, но нам достаточно и этой информации. Допустим, мы вставляем набор из нескольких записей, подчиненных одному регистратору
|
Кратко: что делает 1С |
Как я это интерпретирую |
|
SET TRANSACTION ISOLATION LEVEL READ COMMITTED BEGIN TRANSACTION |
Устанавливаем уровень изоляции и начинаем транзакцию |
|
SELECT … FROM dbo._AccumRg16920 T1 … WHERE ((T1._Fld628 = @P1)) AND (T1._RecorderTRef = 0x00003FFA AND T1._RecorderRRef = @P2) |
Чтение основной таблицы регистра РегистрНакопления.СУУ_КубПрибылейИУбытков (dbo._AccumRg16920) , даже если мы исполняем просто метод .Записать() в режиме замещения |
|
SELECT …. FROM dbo._AccumRgAggOpt18422 T1 WHERE ((T1._Fld628 = @P1)) AND (T1._RegID = @P2 AND T1._Fld628 = @P3) |
Чтение настроек НастройкиРежимаАгрегатовРегистровНакопления РегистрНакопления.СУУ_КубПрибылейИУбытков ( dbo._AccumRgAggOpt18422). Зачем это делать каждый раз при записи? |
|
DELETE FROM T1 FROM dbo._AccumRg16920 T1 WHERE (T1._RecorderTRef = 0x00003FFA AND T1._RecorderRRef = @P1 AND ((T1._LineNo = @P2) |
Удаление предыдущего набора записей из основной таблицы dbo._AccumRg16920. Один DML для КАЖДОЙ записи с LineNo |
|
INSERT INTO dbo._AccumRg16920 |
Вставка записи в основную таблицу регистра накопления РегистрНакопления.СУУ_КубПрибылейИУбытков. Один Insert на КАЖДУЮ запись регистра |
|
INSERT INTO #tt1 |
Вставка записи в таблицу #tt1 , на КАЖДУЮ запись из основной таблицы регистра накопления |
|
INSERT INTO #tt2 WITH(TABLOCK) …. FROM #tt1 T1 WITH(NOLOCK) GROUP BY DATETIME2FROMPARTS(DATEPART(YEAR,T1._Period),DATEPART(MONTH,T1._Period),1,0,0,0,0,0) ….. |
Подсчет новых оборотов для последующей вставки в таблицу НовыеОбороты _AccumRgDl18433 |
|
INSERT INTO dbo._AccumRgDl18433 …. FROM #tt2 T1 WITH(NOLOCK) .. |
Вставляем НовыеОбороты _AccumRgDl18433 которые предварительно аккумулировали в #tt2 |
|
TRUNCATE TABLE #tt1 TRUNCATE TABLE #tt2 COMMIT TRANSACTION |
Чистим за собой и делаем COMMIT |
|
|
|
В общем, Вы поняли, что SQL Server скучать не будет, когда 50 потоков начнут в цикле обходить свои 1000 регистраторов, которым подчинены наборы записей.
Код выглядит так
//Производим запись наборов в несколько циклов
Для Счетчик=1 По ЦикловПерезаписи Цикл
СУУ_Лог.ЗаписатьСообщение(ИДВызова, "СтартоватьНагрузочныйПоток", Перечисления.СУУ_ВидСообщения.Информация, " Цикл перезаписи № "+Счетчик);
Для Каждого Элем Из МассивНаборов Цикл
Элем.ДополнительныеСвойства.Вставить("Проверять",Ложь);
Если Элем.Количество()>0 Тогда
Для Каждого Запись Из Элем Цикл
//Запись=Элем.Получить(0);
//Одной записи заменить недостаточно, она и запишет только одну а неизмененную записывать не будет
Запись.Период=Запись.Период+1;
КонецЦикла;
КонецЕсли;
Если Элем.Модифицированность() Тогда
КоличествоЗаписей=КоличествоЗаписей+Элем.Количество();
Элем.ОбменДанными.Загрузка=Истина; //Если так сделать – в методе .Записать не будет лишних проверок
Элем.Записать(); //Всего лишь один вызов порождает вышеперечисленное
КонецЕсли;
КонецЦикла;
КонецЦикла;
Тут нужно заметить, что на уровне платформы отслеживается – была ли изменена запись или нет? Только измененные записи записываются, поэтому в нагрузочном тесте я меняю поле Период на одну секунду.
Оптимальность реализации ORM внутри метода .Записать() со стороны 1С это не тема данной статьи, хотя фирме 1С есть там над чем поработать.
Может быть, это только в 1С «неправильный» ORM?
Если Вы думаете, что в «нормальных» языках программирования, например, Java все хорошо - прочитайте вот эту свежую статью Implementing bulk updates with spring data jpa про то, как обстоит дело в популярном Java Framework – Spring . Где они эти стандарты Java как бы улучшают, делая свои обертки. Там та же самая ситуация – даже если Вы подготовили наборы в памяти Java и сделали saveAll() - на каждую запись будет отдельный DML оператор.
Автор статьи предлагает методы решения
А) JDBC batching – по сути агрегирование однотипных DML операций. Он лечит не причину, а следствие, и как видно не очень хорошо.
Б) Написать свой метод с одной DML операцией на несколько записей. Это радикально, но по сути мы уже строим свой ORM, а не используем стандартные методы.
Проблема в том, что базовые методы JPA ориентированы на работу с отдельными записями по первичному ключу, а не наборами по списку первичных ключей. Ну а разработчики используют, то что им предлагают. Ведь если сервер СУБД достаточно мощный – он справится? Посмотрим
Почему много маленьких DML это плохо
Запускаем тест с параметрами
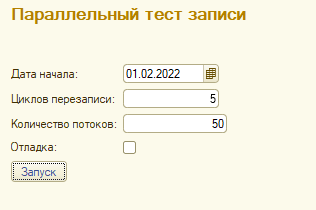
50 параллельных потоков делают запись в регистр накопления, изменяя у каждой записи время на секунду.
Железо для СУБД у нас ориентировано на высокую нагрузку и работает с 2014 года
Дисковая подсистема реализована на SSD на оборудовании HP MSA2040 , с высокоскоростными контроллерами. Жесткие диски SSD HP 400GB 2.5''(SFF) SAS ME 6G Hot plug SSD for MSA2040. Если посмотреть IOPS тут MSA2040.PDF, то на запись где-то 32 тысячи, а на чтение 85 тысяч в режиме Random. Много это или мало - видно по результатам ниже. MS SQL Server 2019 , памяти 64 гигабайта. 1С на отдельном сервере приложений такой же конфигурации, но только с одним Raid1 для ОС и приложения.
Сначала смотрим SQL Server waits, именно они покажут нам, где больше всего ждет SQL Server
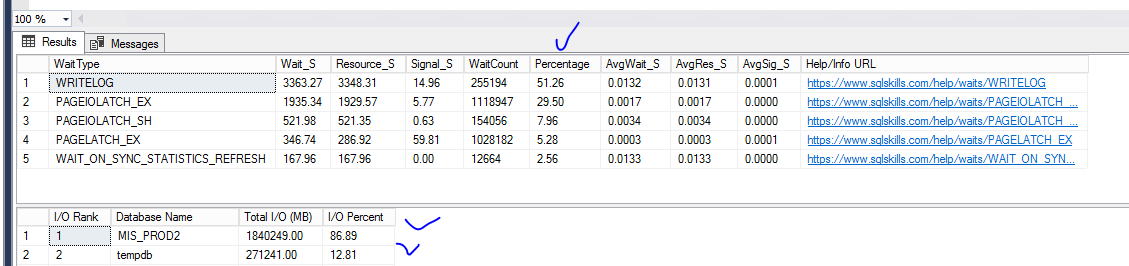
Чемпион по Wait Transaction log, за ним идут Wait на запись в СУБД из буфера. Результат не является неожиданным – похожее видели, когда исследовали проблемы производительности в виртуальной среде см статью 1С + MS SQL против Матрицы виртуализации. Много мелких DML операций (не путать с транзакцией) должны пройти через Transaction log в определенной последовательности, определяемой транзакциями.
Картинка ниже показывает, как работает лог. Видно, что данные пишутся в асинхронном режиме. В последних версиях появились даже Delayed transaction, причем на хабре докладывают, что производительность растет Delayed Durability или история о том как получилось ускорить выполнение автотестов с 11 до 2,5 минут
Если посмотрим на IOPS по SSD Диску D: где находится и лог и нужные нам таблицы СУБД – мы далеко от максимума его возможностей
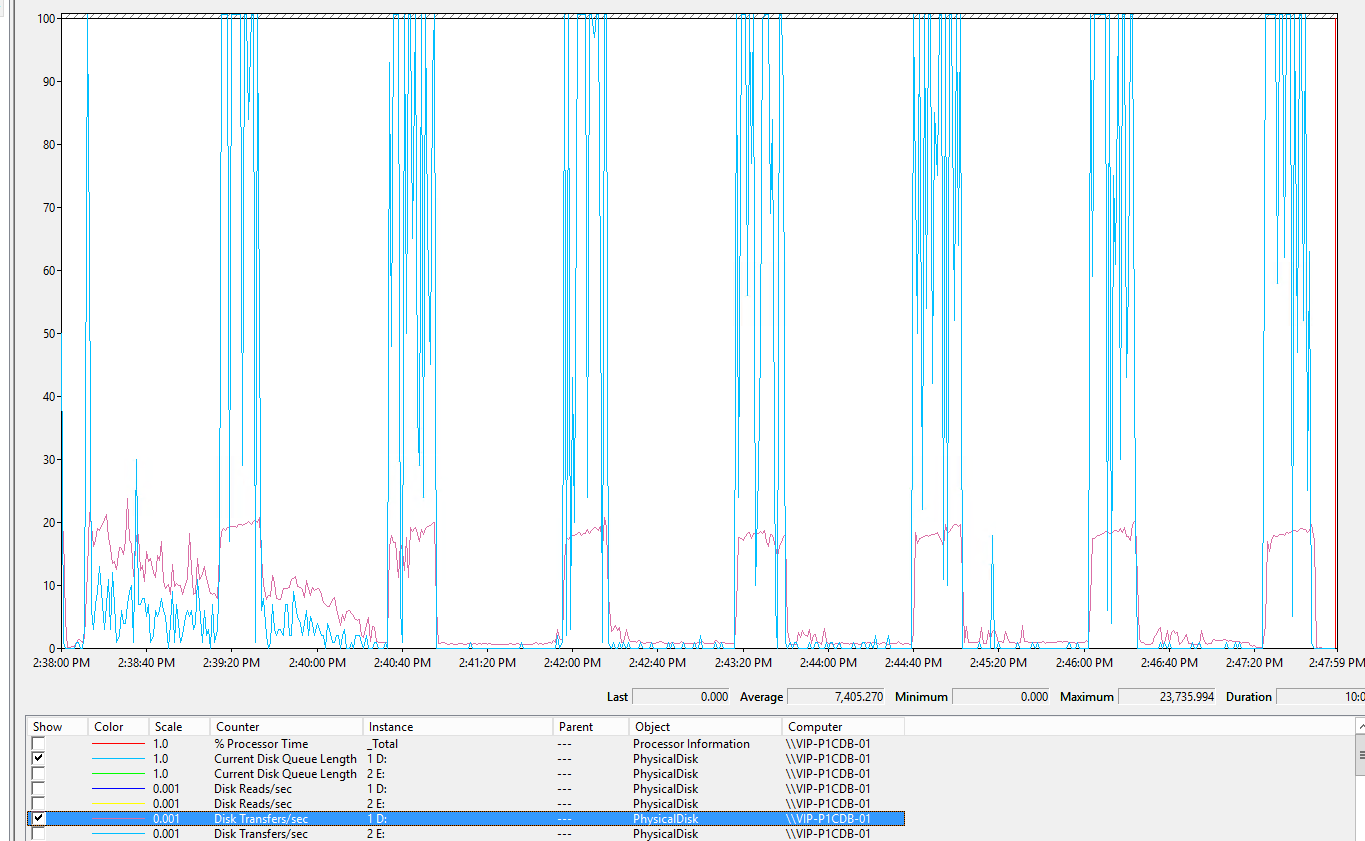
Количество трансферов на диск SSD (фиолетовый) не превышает 20 тыс - это далеко от максимума, на который он способен даже если не учитывать реальные размеры блоков. Очереди при большом количестве IOPS фиксируются (голубой).
На таблице ниже видно, что IOPS не зависят от количества Batch Request( фиолетовый пунктир ), процессорного времени (красный). В момент возникновения очереди закономерно растет Avg.Disk sec/transfer (желтый).
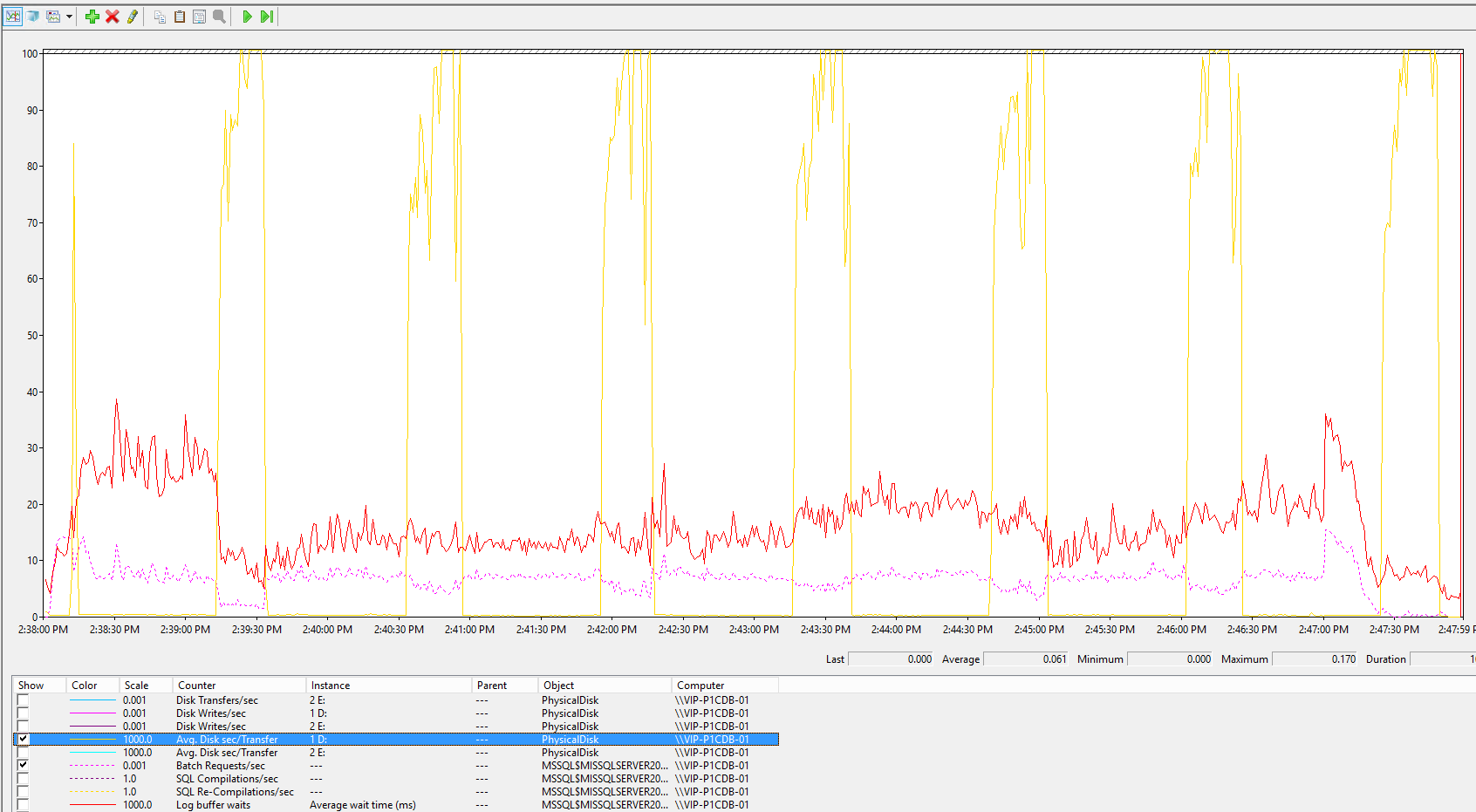
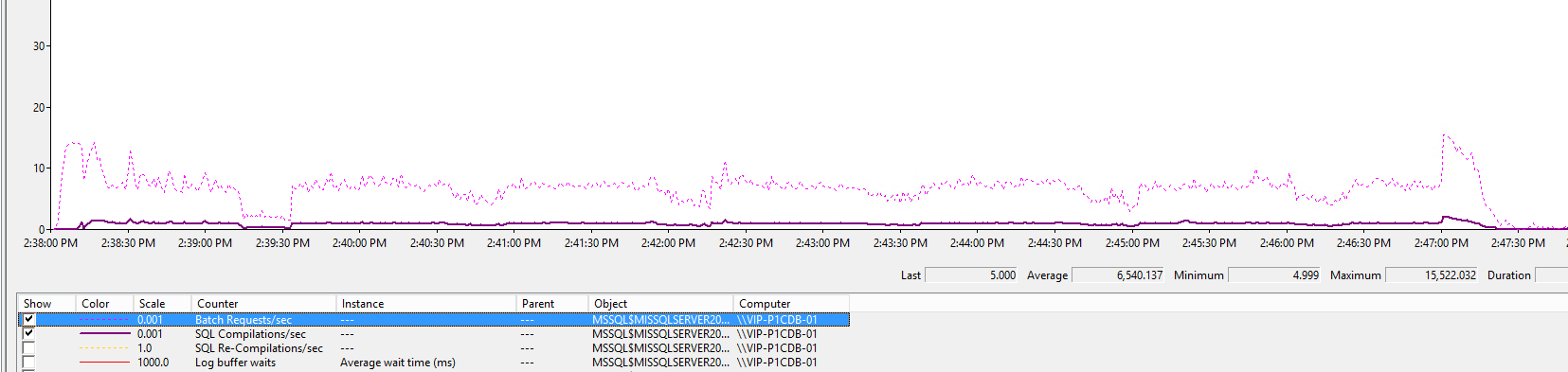
Таблица ниже показывает, что количество Compilations (фиолетовый жирный) гораздо меньше Batch request (фиолет пунктир) – значит, все-таки повторное использование планов мелких DML работает
И, наконец, отдельно статистика по логу. Сброс Flushes (песочный) идет равномерно как Log Bytes Flushed (голубой) . Ожидания тоже распределены равномерно Log Flush Waits (зеленый).

На этой картинке видно, что Disk queue length (голубая) находится в противофазе к Log flushes (желтая) – это означает, что SSD для лога НЕ является узким местом
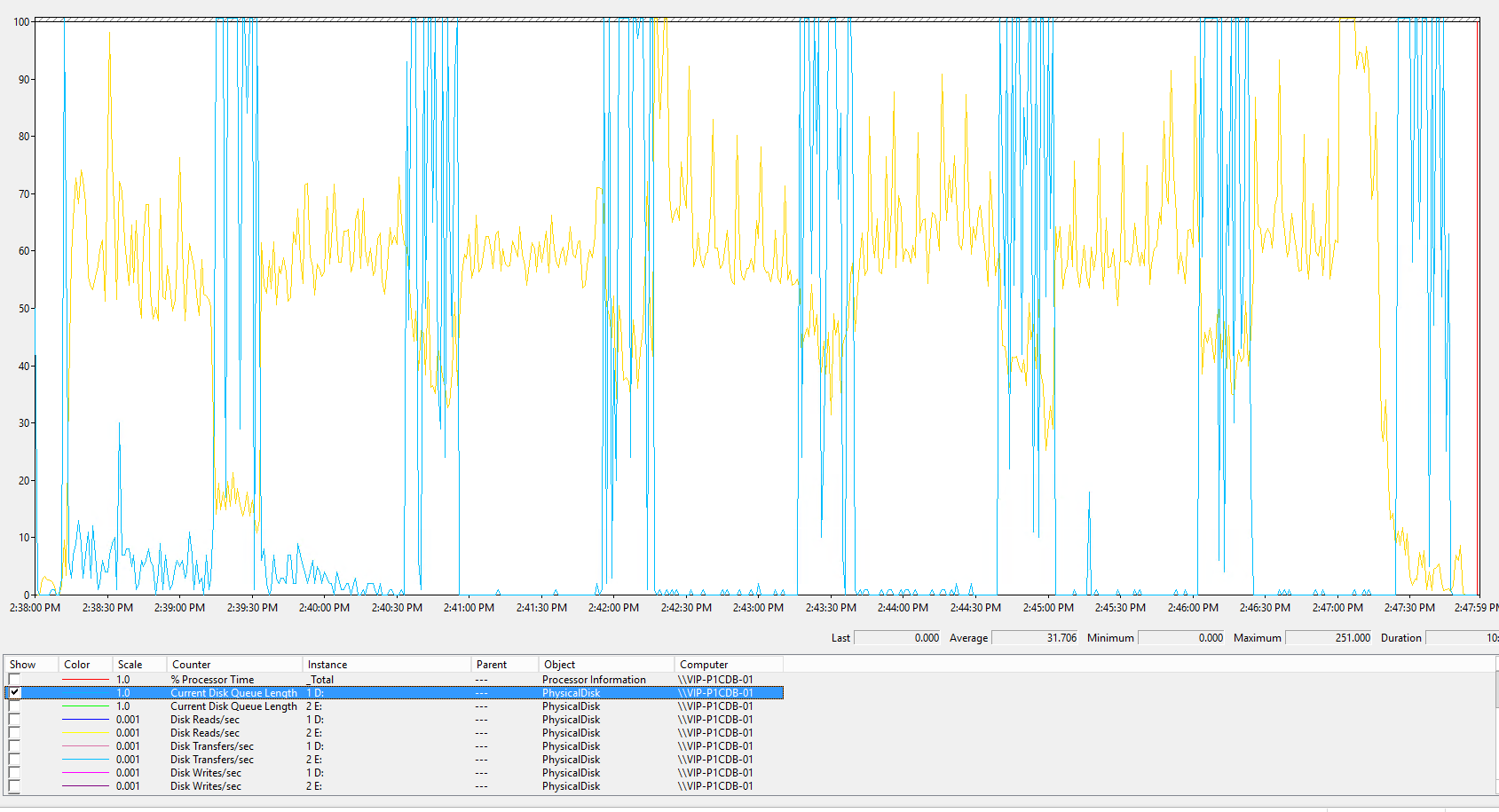
Пределов для 1С нет, но есть узкое место в СУБД.
Выводы очевидны:
Создать много потоков для записи в 1С труда не составит , учитывая возможность подключить нужное количество серверов к кластеру (сервер приложений) 1С. Однако много мелких DML от 1С упрутся в Transaction log, даже если он на SSD диске и остается запас по IOPS, просто по архитектурному построению СУБД. Из статистики выше Вы видели, что waits по Writelog не только заняли 50%, но еще среднее время ожидания достаточно большое 0.0132 против 0.001 в нормальной ситуации. Исправить это можно только укрупнением DML операторов (не путать с транзакцией), но это можно реализовать только под капотом платформы, поскольку сейчас на каждую запись делается один INSERT\DELETE . СУБД бессильна против такого подхода к реализации ORM (Object Relationship Mapping) .
Можно, конечно, заняться более глубоким тюнингом Transaction log (тема отдельной статьи), но это кардинально не решит проблемы из-за его архитектуры последовательной записи. Пусть эта запись и асинхронна, и многопоточна с MS SQL 2016, и на нее влияет не только COMMIT, но и Checkpoint. В разных СУБД есть свои улучшения и особенности. Например, в Oracle по умолчанию есть разделение на циклический Redo log и Rollback segment с более совершенной архитектурой (сравните с режимом Snaphot MS SQL) , но он тоже имеет пределы по количеству мелких DML в секунду.
Архитектор 1С может использовать данную ниже статистику при планировании возможной нагрузки на решение. Запись\удаление самая тяжелая операция , которая кроме изменения данных таблиц меняет связанные индексы. Природа Transaction log как узкого места реляционной СУБД – предполагает зависимость от последовательности транзакций, поэтому количеством ядер ее не решить, а рост тактовых частот уже не тот.
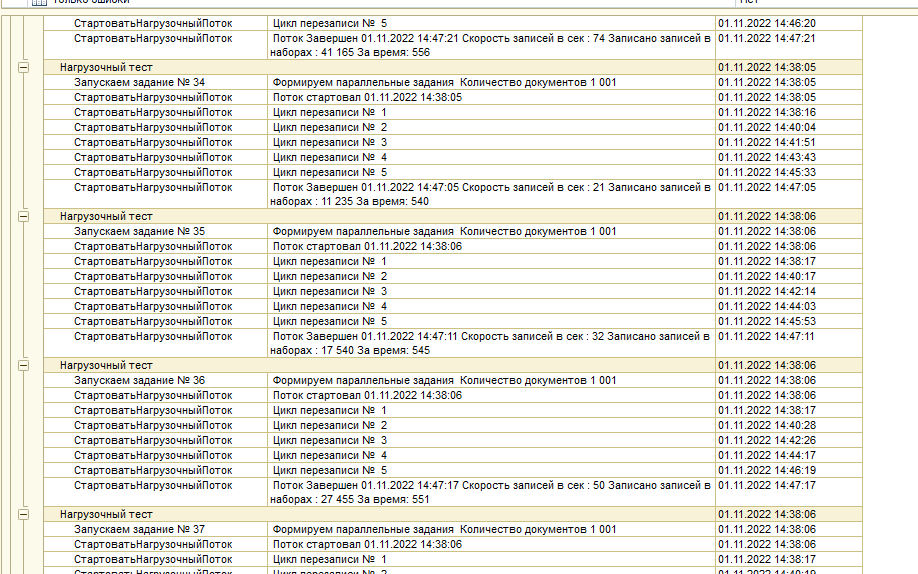
Как видно из таблицы, скорость записи в параллельных заданиях неравномерна. Причины разные
- Под документом-регистратором может быть разное количество записей в регистре накопления, а метод .Записать() идеологически может быть выполнен только по одному регистратору
- Общее количество документов в заданиях примерно одинаково, но общее количество записей под документами-регистраторами разное
- Количество заданий 50, а 1С 8.3 пытается дать всем заданиям равномерно отработать, но мы сейчас не ставим задачу максимальной производительности 1С, просто делаем нагрузочный тест СУБД. На сервере приложений общая загрузка процессора не более 30 процентов. На нас даже задержки 10 гигабитной сети не влияют, поскольку распараллеливание использует широту пропускания
Посчитаем общее количество записей в секунду, которое мы можем записать с распараллеливанием. Если суммировать средние по заданиям, то будет 1374, если от общего проведенного, то 1397 записей в секунду.
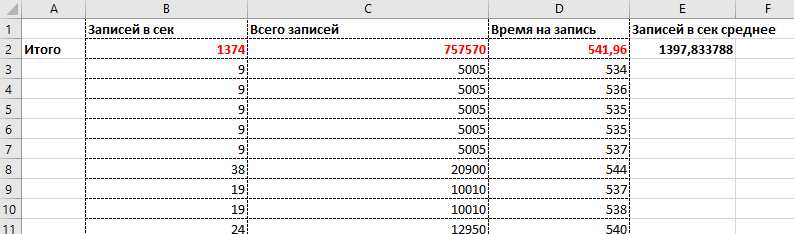
Т.е. данный регистр позволяет записывать без дополнительных операций чтения подготовки и т.д. 1400 записей (ORM записей 😉) в секунду на указанном оборудовании. Если вы ходите провести 1 миллион регистраторов, где у каждого в среднем 5 движений \проводок, у Вас это займет минимум 3571 секунду, т.е почти час. Исходя из этой цифры Вы можете оценить, хватит ли Вам технологического окна для закрытия месяца или других действий. Например, у российского брокера – 1 миллион операций в день может быть обычным объемом.
Что важно – оборудование позволяет пропустить больше IOPS, но много мелких DML не позволяют эффективно использовать Transaction log.
Конечно, можно оптимизировать регистр, убрать «лишние индексы» и еще перечень мероприятий достойных отдельной статьи, но Вы не уберете красную линию – вы просто ее отодвинете.
Может быть, бывает правильный ORM?
Детальный разбор записи в регистр накопления через SQL Profiler (см. выше), сразу показывает, что компания 1С может оптимизировать алгоритм записи в регистр накопления, даже в существующей идеологии (запись наборов по одному регистратору), но это лишь отодвинет момент Bottleneck в Transaction log. Как это возможно поменять кардинально – описано в первой статье цикла Язык мой враг мой, путь один - трансформировать методы с записи одиночных объектов (регистратор набора записей) на запись наборов объектов (массив регистраторов набора записей).
Фактически в организации методов ORM должна быть заложена не только возможность пакетной записи по нескольким значениям первичного ключа, но ее эффективная внутренняя в базе реализация крупными DML. Я вижу, многие ищут убийцу 1С, но без эффективного с точки зрения СУБД ORM он таковым не будет. Надеюсь, в комментариях кто-нибудь покажет такой ORM – ориентированный на пакетную запись объектов, будет печально, если его не существует. Если 1С сделает это первой (а они об этой проблеме знают), то это будет самый качественный ORM на рынке со всех точек зрения. А оптимизировать 1С есть что – на оптимизации только механизма общих реквизитов\разделителей можно в 2 раза план запросов улучшить см Лучшее соединение враг хорошего?
Вторая сторона медали – горизонтальное масштабирование. Понятно, что всю запись на один Instance СУБД бесконечно возлагать невозможно, даже если решить проблему с мелкими DML. Распределение таблицы по отдельным узлам в духе Map Reduce резко усложнит разработку, если только платформа 1С не возьмет это на себя.
Хорошим и дорогим вариантом может стать Oracle Real application cluster Oracle RAC, который позволяет работать с одной СУБД из нескольких Instance. В принципе он может быть достаточным для большинства приложений с интенсивным OLTP. Но бомбить его мелкими DML не стоит, сначала нужен навести порядок внутри ORM и сделать возможность записи нескольких объектов более крупными DML. Если нагрузка за запись сильно велика, что не спасает Oracle Real application cluster, то тут единственный вариант делить ее на несколько баз данных с разными transaction log, но это не тема для 1С. С нагрузкой по чтению вообще проблем нет, поскольку она хорошо кэшируется и есть много вариантов с ней работать.
Не следует путать Oracle RAC c разного рода репликациями, которые могут снизить нагрузку только по чтению и повысить отказоустойчивость. Его, кстати, тестировали еще 10 лет назад.
1С на Oracle RAC и, как я понял, Microsoft нечего было на это ответить 😊 Microsoft не согласен с результатами тестов 1С на Oracle RAC
Из конкурентов сейчас я нашел только решение от Amazon Альтернатива Oracle RAC от Amazon
Мы ответственны за тех, кого научили.
Вообще программный код библиотек уже перерос задачу повторного использования кода (использование готовых решений) . Любая библиотека несет в себе Best Practice, реальное использование Patterns или говоря просто – т.е. “мы изучили, как лучше эти задачи решать, и закодили это в библиотеку\framework”. Для примера можно взять библиотеки на Java для RabbitMQ.
Где в «нормальных» языках приучаться к правильной архитектуре, как не в библиотеках к языку?
По Patterns? Ну почитайте эти книги по паттернам, там пишется, как рекомендуется сделать, но не Best practice, проверенный опытом. На работе некогда наступать на одни и те же грабли.
Но разве строить библиотеку ORM так, чтобы бомбить мелкими DML Вашу СУБД, это лучшая практика?
В целом попытка отделить программиста от СУБД кончается игнорированием вопросов внутреннего устройства. Да, это необходимо для построения сложных систем, но тогда нужно заботиться о том, чтобы библиотека давала Вам хороший стиль программирования.
Позиция 1С понятна по поведению - им на данном этапе важен только функционал, а вопросы производительности вторичны. Но почему тогда при проектировании стандарта JPA в Java, где community людей с разным опытом, заложен тот же изьян? Понятно, что архитектор, свободно плавающий и в устройстве СУБД, и в устройстве программ, должен иметь редкую трудовую биографию, чтобы знать все, но community предполагает синергию от взаимодействия разных специалистов. Тут хорошо почитать эту статью про историю логгирования в Java Java logging история кошмара - из нее сразу становится понятно, почему в Java можно легко найти решение на любой случай, но так трудно найти качественное решение. При всех равных я сторонник платных решений, по крайней мере 1С достаточно демократична в обратной связи с клиентами, и общими усилиями продукт улучшается. Какой ORM будет использовать убийца 1С, покажет будущее и, надеюсь, подскажут читатели данной статьи – невозможно изучить их все. До новых встреч на нашем телеграмм канале.
Вступайте в нашу телеграмм-группу Инфостарт