В предыдущих статьях я уже давал ссылку на научный источник. Повторю ее еще раз https://arxiv.org/abs/2005.14165. В принципе, внимательное чтение этого препринта вносит полную ясность в рассматриваемом вопросе. Но я понимаю, что далеко не у всех есть время и силы читать 75 страниц на английском. Я постараюсь изложить принципы работы языковой нейросети по возможности коротко и просто.
Итак, что делает языковая нейросеть? Говоря по простому, она ищет следующее слово.
Следующее за чем? Да за чем угодно. В принципе, ее можно попросить выдать слово, которое ни за чем не следует. Т.е. первое слово. В каком-то смысле "главное" слово в интернете. Строго говоря, не в интернете, а в обучающей выборке. Но так как масштаб обучающей выборки для современных языковых моделей сравним с масштабом всего контента в интернете, то можно смело говорить "в интернете".
Обычно все же интересует ответ на конкретный вопрос. Поэтому модель ищет первое слово, следующее за этим самым вопросом. Этот вопрос уже когда-то обсуждали в интернете и давали на него ответы. Каждый ответ начинался с какого-либо слова. Из этих слов и выбирается первое. После первого слова выбирается второе, но уже с учетом вопроса и ранее выбранного первого слова. Этот процесс повторяется до тех пор, пока языковая модель не решит, что пора остановиться. Говоря другими словами, в качестве очередного слова выберет "стоп". Как видите, простая механика и никакой магии. Все дело в объемах обучающей выборки (и количестве ресурсов, потраченных на обучение, заметим).
Но есть один крайне важный нюанс. Поскольку обучающая выборка действительно огромна, мы каждый раз будем получать огромное множество кандидатов в очередное слово. Как сделать выбор?
Обратите внимание на то, что значения вероятностей в следующих ниже примерах я взял "из головы".
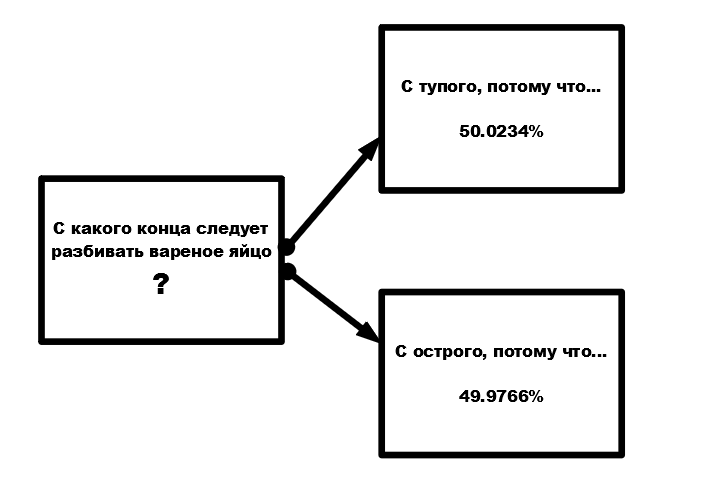
Какой вариант следует выбрать здесь? Первый, конечно, сумел обойти второй. Но ведь и второй ничем не хуже первого. Современные языковые модели решают вопрос выбора очень просто. Они используют генератор (псевдо)случайных чисел. И в данном случае с вероятностью 50.0234% будет выдан первый вариант, а с вероятностью 49.9766% второй.
Хорошо, с этим понятно. Но что делать в случае, когда распределение будет 80% на 20%? Что делать в случае с 90% на 10%? Наконец, что делать вот в этом случае?
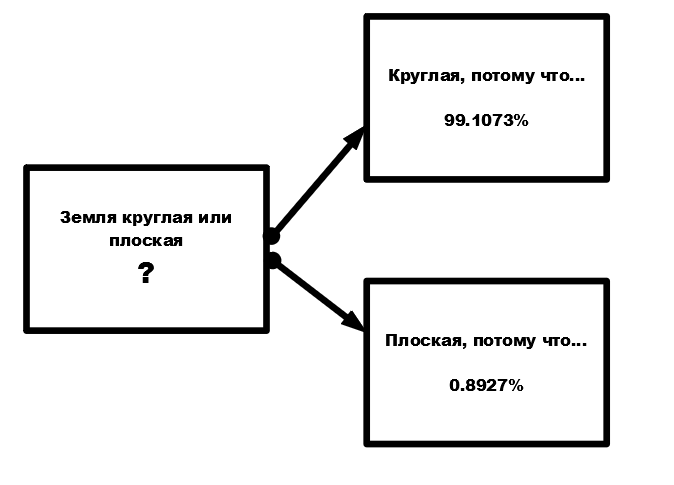
А ничего особенного не делать, говорят разработчики современных языковых моделей. Все так же, брать в руки генератор случайных чисел, и вперед. В результате с вероятностью 0.8927% вы получите второй вариант выбора первого слова. А так, как процесс повторяется много раз, за первым словом вы получите все остальные. И эти остальные слова с высокой вероятностью будут излагать вам наиболее убедительную версию изначально странного утверждения. Именно поэтому часть экспертов и называет современные языковые модели "генераторами бреда". Некоторые еще и добавляют: бреда, опасного своей убедительностью.
Почему же разработчики пошли по этому пути? По моему личному убеждению, именно недетерминированность больших языковых моделей, использование генератора случайных чисел и явилось причиной столь ошеломляющего успеха. Хотя объемы обучающей выборки тоже сыграли свою роль, но недетерминированность оказалась важнее. Она как бы придала описанному выше чисто механическому процессу человеческое лицо.
Каждый из нас в глубине души уверен, что в состоянии самостоятельно разобраться, что есть истина, а что есть ложь. Кроме того, современное информационное общество отодвигает устаревшую дихотомию истина-ложь на второй план. Сейчас все более и более важной становится другая дихотомия: ценная информация - ерунда. При этом ерунда вовсе не обязательно будет ложью. Чаще всего это будет привет от капитана очевидность. Информация вполне истинная и совершенно бесполезная.
С другой стороны, чем выше ценность информации, тем выше вероятность того, что она будет выглядеть, как фейк. Что он говорит? Что время может ускоряться и замедляться? Вот давайте не будем давать ход всякому околонаучному бреду. Что-то подобное раз за разом говорил нобелевский комитет, когда его призывали дать премию Эйнштейну. Что характерно, эту свою ошибку комитет так и не признал. Когда стало уже совсем неудобно, премию таки дали. Но не за теорию относительности, а за другую, менее значимую работу.
Как мы уже видим, неправильные ответы людей вовсе не отталкивают. Количество пользователей языковых моделей растет совершенно невиданными темпами. Напротив, детерминированность, жестко заданное поведение в одних тех же ситуациях, как я думаю, привели бы к гораздо более прохладному приему. Ну подумаешь, еще одна тупая машина!
Так что те, кто обращают внимание публики на "галлюцинации" и "бред" языковых моделей абсолютно правы. Языковые модели ведут себя именно так.
Тогда какие основания у тех (автор в их числе), кто говорит "вау!"? Очень простые. С большими языковыми моделями не стоит говорить о смысле жизни (это будет пустое времяпрепровождение, хотя если вас это развлекает, то почему нет). Им надо задавать сугубо практические задачи. И чем более конкретный результат ожидается на выходе, тем более полезна будет для вас языковая модель. Для тех, кто причисляет себя к лагерю скептиков, это может показаться парадоксальным, но если вдуматься, никакого парадокса здесь нет.
Я приведу пример, который будет близок и понятен тем, кто имеет дело с учетными системами. Но вообще, все, что здесь будет сказано, можно легко распространить на любые базы данных.
Допустим у нас есть несколько складов, на которых хранятся товары. И мы хотим получить ответ на вопрос:
Сколько чая на основном складе?
Да, вполне возможно, что кто-то уже обсуждал в интернете точно такой же вопрос насчет чая и основного склада. И даже получал в ответ какие-то значения. Но рассчитывать на то, что это будут значения соответствующие вашей ситуации, конечно же глупо.
Древняя мудрость гласит, что правильно заданный вопрос - это уже половина ответа. Но время не стоит на месте. И в нашем новом чудном мире правильно заданный вопрос это уже можно считать, что ответ целиком! В рассматриваемом случае, правильный вопрос будет звучать примерно так:
У меня в базе данных есть вот такие таблицы остатков, товаров, складов. Хочу получить ответ на вопрос "Сколько чая на основном складе". Каким должен быть текст запроса на SQL?
В ответ придет примерно следующее:
SELECT Остатки.количество, Товар.наименование, Склад.наименование
FROM Остатки
INNER JOIN Товар ON Остатки.товар_id = Товар.id
INNER JOIN Склад ON Остатки.склад_id = Склад.id
WHERE Товар.наименование = 'чай' AND Склад.наименование = 'основной'
Для того, чтобы этот запрос выполнился например в типовой конфигурации Управление торговлей редакция 11.5, его надо преобразовать к виду:
ВЫБРАТЬ РегистрТоварыНаСкладах.ВНаличииОстаток, СправочникНоменклатура.наименование, СправочникСклады.наименование
ИЗ РегистрНакопления.ТоварыНаСкладах.Остатки как РегистрТоварыНаСкладах
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Номенклатура как СправочникНоменклатура
ПО РегистрТоварыНаСкладах.Номенклатура = СправочникНоменклатура.ссылка
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Склады как СправочникСклады
ПО РегистрТоварыНаСкладах.Склад = СправочникСклады.ссылка
ГДЕ СправочникНоменклатура.наименование = "чай" И СправочникСклады.наименование = "основной"
Это задача по программированию для средней группы детского сада. Получить вопрос от пользователя, добавить к нему описание таблиц и волшебное слово SELECT, получить результат, преобразовать его к виду выполнимому в конкретной базе данных, выполнить запрос и показать результат пользователю. Ну никак не выше средней группы!
Если вы думаете, что это я просто нашел счастливое сочетание слов чай и основной, то это не так. Вместо этих двух слов можно подставить: холодильники и южный, утюги и северный, яблоки и резервный, груши и центральный и т.д. Языковая модель все эти и, наверное, все прочие варианты обработает правильно. Она ведь ищет слово за словом, но с учетом всего предыдущего. Поэтому если в вопросе был чай, то и в ответе будет чай.
Более того. Структура вопроса может быть любой, лишь бы сохранялся смысл.
Сколько осталось чая на основном складе?
Какое количество чая на основном складе?
Так! Сколько чая на основном складе?
Остатки чая на основном складе?
Cкажи-ка мне, пожалуйста, сколько чая на основном складе?
Еще один важный момент заключается в том, что когда я проводил эксперименты, у меня в описании таблиц была не одна лишь таблица остатков на складе. Были еще таблицы продаж и взаиморасчетов. И когда мой вопрос по смыслу подходил под остатки, языковая модель строила текст запроса по остаткам. А когда смысл вопроса подходил под продажи, строился запрос к таблице продаж, хотя и там и там встречаются одинаковые поля. Можно с полным правом сказать, что большая языковая модель вас понимает.
Может ли языковая модель "галлюцинировать", выдавая ответы на рассматриваемый нами вопрос? Исходя из того, что мы узнали, ответ должен быть "да". И действительно, в процессе проведения экспериментов с OpenAI GPT, мне случалось ловить определенного рода "глюки". Но что интересно, ни разу это не было заменой слова чай на какое-либо другое слово. Видимо все-таки вероятность того, что модель в процессе решения данной задачи после слова чай поставит снова чай слишком высока. "Глюки", которые я ловил были другого рода. Вместо ответа типа:
SELECT Остатки.количество, Товар.наименование, Склад.наименование
FROM Остатки
INNER JOIN Товар ON Остатки.товар_id = Товар.id
INNER JOIN Склад ON Остатки.склад_id = Склад.id
WHERE Товар.наименование = 'чай' AND Склад.наименование = 'основной'
Я получал ответ следующего вида:
SELECT Количество, Товар_id, Склад_id
FROM Остатки
WHERE Товар_id = 1 AND Склад_id = 1
Можно предположить, что наряду с правильной веткой ответа в интернете довольно часто встречалась побочная. Типа, вот тебе "скелет" запроса, сам подставь вместо единиц, что тебе надо. По ощущениям это встречалось менее, чем в 5% случаев. Как вы понимаете, такого рода "глюк" не представляет опасности. По крайней мере в среде 1С. Потому что этот запрос просто не выполнится. Т.е. мы не получим "фантазию" на тему остатка, не получим, например, значение 100 вместо 5. Мы просто не получим ничего. Если мы организуем для пользователя интерфейс на естественном языке, и будем изредка получать такие "промахи", не факт, что пользователи сочтут это значительным неудобством. Такие ситуации вполне укладываются в общую языковую практику. Если вас не расслышали, вы повторяете свой вопрос. Никто не делает из этого трагедию.
Все изложенное выше является результатом экспериментов автора. В конце февраля 2023 года автор открывает тестовую площадку. На этой тестовой площадке можно будет самостоятельно задавать вопросы и получать ответы в типовых конфигурациях УТ, КА и ERP. Также можно будет настроить свою схему, чтобы работать с любыми другими конфигурациями, в том числе нетиповыми. Вопросы по работе тестовой площадки задавайте здесь.
Вступайте в нашу телеграмм-группу Инфостарт