










- Потому что для 1С аналогов нет.
- Последняя установка на Windows, DATABASE не пригоден для использования.
- Методика анализа проблем для Postgres после первой неудачной попытки.
- Пиррова победа Postgres?
- Что делал Слон когда пришел наПолеОн ? Разбор «удачного» запуска.
- Помогите Postgres выиграть у MS SQL.
Потому что для 1С аналогов нет.
Когда долго работаешь с Oracle или MS SQL, причин рассматривать Postgres на нагруженный проект было совсем немного, ведь уже есть проверенные решения, знания и опыт, а «бесплатность СУБД» на фоне остальных затрат для HighLoad проекта не самое главное. Однако в прошлом году произошел «волшебный пинок судьбы» и стало ясно, что новых инсталляций MS SQL и Oracle (и даже IBM DB2) не будет, поэтому для 1С кроме Postgres уже альтернатив нет. По крайней мере не в этом солнечном цикле
Сегодня проверим, как поведет Postgresql на нагрузочном тесте с платформы 1С на запись (insert , update, delete) и сравним ее с MS SQL с той же базой и на том же сервере. Методика нагрузочного теста, и конфигурация оборудования изложена в первой части цикла статей.
Концепция ORM как двигатель прогресса — выдержит ли ее ваша СУБД?
Концепция ORM как двигатель прогресса – выявит слабое место Вашей СУБД
Если кратко, мы инициируем 50 потоков записи в оборотный регистр накопления с агрегатами 1С 8.3 в виде фоновых заданий. Сервер приложений 1С (1С8.3.22.1709 ) и сервер базы данных (Postgres 15.2, MS SQL 2019) на разных 2 х процессорных серверах HP, все сделано для ликвидации узких мест. Базы полностью находятся на серверных SSD (возможности по IOPS запись где-то 32 тысячи, а на чтение 85 тысяч в режиме Random). Заметим, что 1С порождает не только Insert, но и запись во временные таблицы, делает соединения для обновления итогов оборотов и т.д., поскольку это ORM объект со своей структурой, которая подробно изложена в первой части статьи. Эксперимент проводится на том же сервере Windows 2019, где MS SQL , базы лежат на одном и том же SSD – пришлось сделать маленькую версию базы на 80 гигабайт. Т.е. можно сравнить MS SQL vs Postgres на одинаковой задаче и оборудовании.
Тест в этой статье будет БЕЗ включения Delayed durability MS SQL\Асинхронный commit Postgresql, поскольку мы проверяем работу в обычном режиме Durability, для более объективного сравнения Postgres vs MS SQL. Режим Snapshot установлен платформой – у MS SQL «Is read committed snapshot on», у Postgres 15 - MVCC безальтернативно. Задача понять – будет ли у Postgres сравнимая с MS SQL производительность при средней нагрузке и как они загружают ресурсы сервера, хотя для кого-то и 50 фоновых заданий уже HighLoad.
Жесткий бескомпромиссный тюнинг, асинхронный commit, нагрузка с двух серверов приложений 1С это тема отдельной статьи – поверьте, даже при средней нагрузке уже видны проблемы, которые возникнут при HighLoad с двух серверов приложений 1С.
Почему я не делаю эмуляцию работы пользователей, а только запись из ORM 1С?
Все очень просто – с чтением любая из поддерживаемых 1С СУБД может справиться за счет внутренних механизмов СУБД и оптимизации запросов в 1С Лучшее соединение враг хорошего?, а при наличии проблем с нагруженностью оборудования это решается через репликацию. Тут много вариантов приспособиться.
А вот с записью, которая в 1С делается через неделимые методы .Записать() да еще создает мелкие DML операции (т.е. DML на одну сущность, а не на несколько сразу) вариантов оптимизации на уровне 1С нет. Все, что можно сделать - это оптимизация на уровне СУБД.
Именно операция записи в СУБД определяет границы возможного для 1С, поскольку распределить кластер 1С на несколько серверов приложений можно, как угодно, а настроить работу несколько Instance с разных серверов, на одну СУБД это другой уровень.
Полноценно распределить работу СУБД на несколько серверов (со всеми DML операциями), можно только решениями типа Oracle RAC или IBM DB2 Purescale. Для Postgres в Pro варианте нет, но судя по маркетингу есть сторонние платные, например Replication (enterprisedb.com), и как это работает в реальности, нужно проверять.
Если Вы планируете массовые перепроведения документов, или работу большого количества пользователей - производительность на запись будет критичной. Горизонтальное масштабирование как метод увеличения производительности тоже создает большую нагрузку на запись Язык мой – враг мой. Архитектору о будущем 1С . В итоге если нагрузочный тест на запись проходит нормально, то можно на 99% быть уверенным, что другие проблемы тем или иным способом решаемы в Вашем проекте. Стресс тест позволяет на цифрах оценить границы для объемов обрабатываемой информации.
Комплексные тесты это ящик пандоры. Они всегда подгоняются под какую-то архитектуру приложения. Например, типовые конфигурации 1С пишутся без учета горизонтального масштабирования – тем самым комплексный тест уже будет содержать неэффективность на уровне кода, и узкие места в архитектуре кода. С моей точки зрения только тесты на горизонтальном масштабировании показывают границы возможного.
Последняя установка на Windows, DATABASE не пригоден для использования
Кстати, тренд на отказ от Windows для работы Postgresql уже заявлен официально Самая знаменитая российская СУБД прекращает поддерживать Windows: Она больше не популярна : Компания Postgres Professional, так что торопитесь развернуть и протестировать\сравнить Ваши базы на Postgresql для Windows, пока есть такая возможность, и начинайте изучать Unix.
Я взял версию PostgreSQL 15.2 64bit с сайта https://1c.postgres.ru – адаптированную для 1С. С https://releases.1c.ru не скачивал, поскольку узнал о ней позднее. Для нагрузочного теста это достаточно, для рабочей эксплуатации и последующих обновлений лучше скачать с сайта 1С.
При инсталляции выбрал location не операционной системы, а “ru-Ru” что было ошибкой.
Сначала 1С при создании пустой базы написал «DATABASE не пригоден для использования», а потом
«Ошибка установки или изменения национальных настроек информационной базы
Порядок сортировки не поддерживается базой данных по причине: Порядок сортировки не поддерживается базой данных»
Поиск по подобным дал понимание, что параметры
LC_COLLATE, LC_CTYPE PostgreSQL: Documentation: 15: 24.1. Locale Support
не соответствуют сущностям, которые отдает\принимает 1С при создании базы данных. Включение технологического журнала 1С показало, что 1С запрашивает show lc_collate, но как обрабатывает - неизвестно.
Несмотря на то, что Locale в Windows на обоих серверах одинаковые Configure International Settings in Windows | Microsoft Learn что-то шло не так. Я решил установить кодовые страницы явно.
Для этого пришлось пересоздать кластер (не путать с переустановкой) командой без явного указания locale (я знал, что на уровне ОС он верен)
initdb -D D:\db_s\postgresql -E UTF8 -U sa -W -X D:\db_s\postgresql
поскольку через postgresql.conf эти два параметра установить нельзя. Файлы pg_hba.conf pg_ident.conf postgresql.conf скопировал из сохраненного каталога кластера.
Теперь collation стал выглядеть как Russian_Russia.1251, кодировка базы по-прежнему UTF8 , и создание базы прошло успешно.

Т.е. основной вывод – кодировки для lc_* параметров должны быть указаны явно и соответствовать locale серверов windows. У инсталлятора есть вариант «ru-Ru» и по параметрам ОС – нужно выбирать параметры locale “по параметрам ОС”, убедившись, что они правильно выставлены (в моем случае Россия). На эту тему можно написать отдельную статью, но здесь это следствие устройства windows, которая внутри работает с UTF-16 , выбор локали это по сути выбор других кодировок, подробнее тут Code Pages - Win32 apps | Microsoft Learn . Думаю, с отходом от Windows это все будет уже неактуально.
Методика анализа проблем для Postgres после первой неудачной попытки.
Первая попытка теста показала производительность в два раза ниже, чем на MS SQL. В таких случаях я использую следующий алгоритм анализа
- Какие ресурсы загружены\перегружены? Если процессор, диск или сеть показывают загрузку, близкую к 80%-100%, ищем сначала причину такого поведения. Недоступность ресурса сразу повлечет Waits на СУБД , странные планы запросов, т.е. это будет уже следствие
- Какие ресурсы\подсистемы провоцируют ожидания или находятся в ожидании? Классический пример, диск нагружен на 30%, а ожидания на запись для СУБД в наличии. В предыдущих HighLoad тестах показано, как запись в лог может провоцировать общие ожидания на запись, хотя формально аппаратные ресурсы не нагружены.
- И только потом смотрим, какие запросы \ DML создают большую нагрузку или \ и неоптимальны?
Т.е. спускаюсь на уровень запросов только тогда, когда понятны причины проблем в пп. 1) 2).
Методика позволяет выявлять истину даже на виртуальной среде, где виртуальные машины тайно душат производительность 1С + MS SQL против Матрицы виртуализации
Но с Postgres такая методика плохо применима – нет в нем хороших кумулятивных счетчиков типа. В MS SQL есть sys.dm_os_wait_stats в Oracle V$system_event . Для ожиданий в Postgres есть pg_stat_activity, но она в разрезе сессий и запросов, поэтому ее можно использовать только методом снимков, что не дает полной картины.
Надеюсь, вы мне подскажете хороший способ, а пока были только такие ответы https://qna.habr.com/q/1262384. На ИТС есть хорошая статья, но она только подтверждает, что удобных способов нет Методика расследования проблем производительности на уровне работы СУБД PostgreSQL (Новый раздел!) :: Проблемы и решения :: Методическая поддержка для разработчиков и администраторов 1С:Предприятия 8 (1c.ru)
Архитектура Postgres c нужными представлениями хорошо показана тут
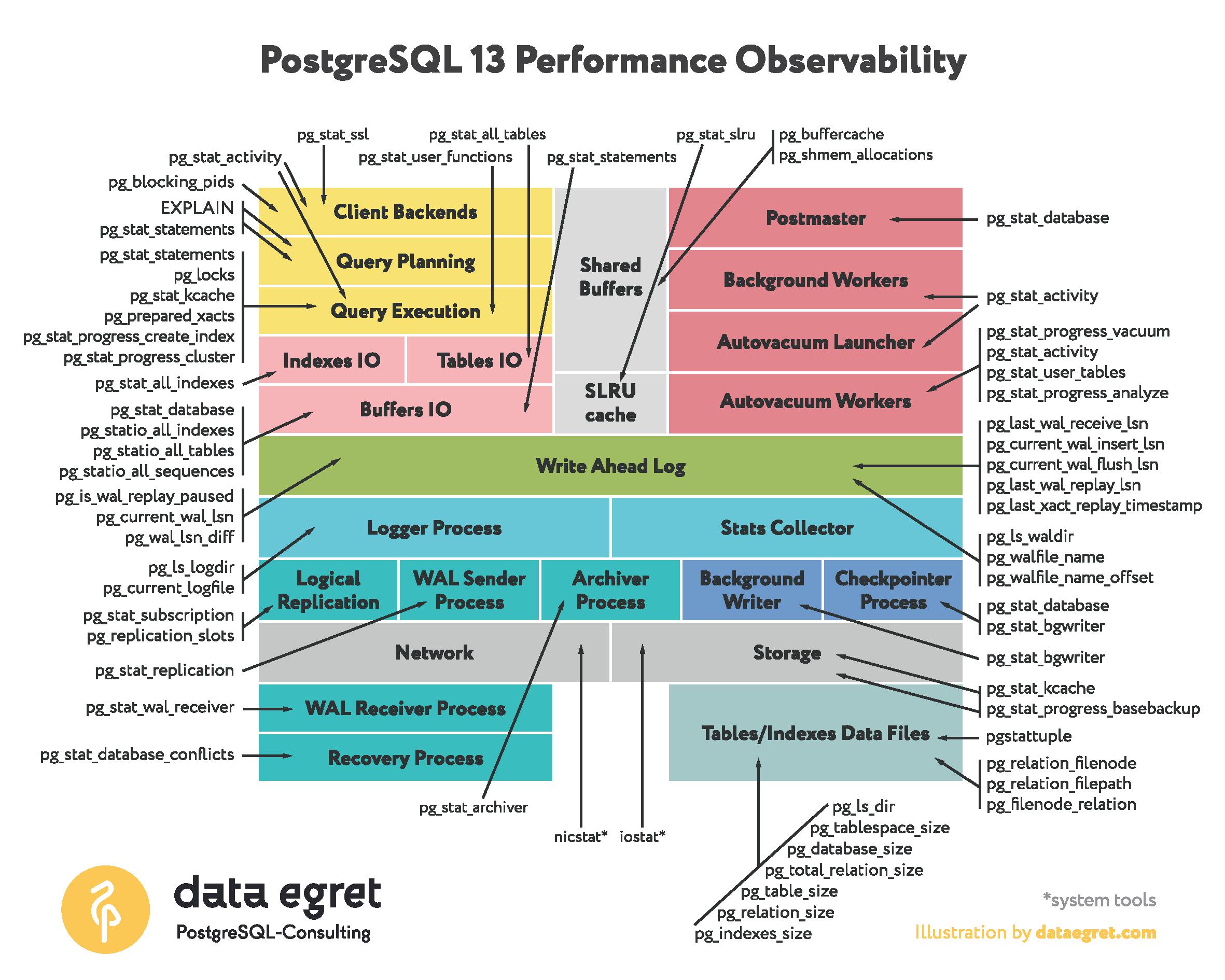
Параметры в PostgresSQL.conf я изначально скорректировал согласно рекомендациям 1С и основные уже были установлены инсталлятором (полный список по команде Show all) во вложении
Поставщик дистрибутива сразу устанавливает
# Add settings for extensions here
#Options for 1C:
escape_string_warning = off
standard_conforming_strings = off
shared_preload_libraries = 'online_analyze, plantuner, pg_stat_statements'
online_analyze.table_type = 'temporary'
online_analyze.verbose = 'off'
online_analyze.local_tracking = 'on'
plantuner.fix_empty_table = 'on'
online_analyze.enable = on
lc_messages = 'en_US.utf-8'
Я проверил и скорректировал согласно статье Настройки PostgreSQL для работы с 1С:Предприятием. Часть 2 :: PostgreSQL :: Методическая поддержка для разработчиков и администраторов 1С:Предприятия 8 (1c.ru) только Shared_buffers на 8 ГБ, и temp_bufffers на 32 мб, что достаточно для нагрузочного теста. Остальные оставил как в дистрибутиве, поскольку дальнейший тонкий тюнинг имеет смысл делать после теста на средних нагрузках.
Анализ ресурсов средствами Windows показал, что SSD диск загружен на четверть от возможного по IOPS, с сетью все ОК, а вот загрузка процессора с 32 логическими процессорами под 100%! В windows хорошо смотреть ее через Process explorer.

На картинке видно, как устроены процессы Postgres, их создается примерно равное количеству потоков тестирования и если каждый грузит под 2%, общая нагрузка будет 100%. На сервере субд 2 процессора с 16 ядрами, hyper threading создает 32 логических процессора, т.е. загрузка одного логического процессора может быть не более, чем 3.1%.
Анализ pg_stat_statements показал, что SELECT FASTTRUNCATE и ANALYZE pg_temp.tt* занимают 76% времени – неужели это они? Нет, это сервисные процедуры – не может быть так плохо.
Использовал запрос
--SELECT pg_stat_statements_reset(); --сброс счетчика
SELECT
pss.userid,
pss.dbid,
pd.datname as db_name,
round((pss.total_exec_time + pss.total_plan_time)::numeric, 2) as total_time,
pss.calls,
round((pss.mean_exec_time+pss.mean_plan_time)::numeric, 2) as mean,
round((100 * (pss.total_exec_time + pss.total_plan_time) / sum((pss.total_exec_time + pss.total_plan_time)::numeric) OVER ())::numeric, 2) as cpu_portion_pctg,
substr(pss.query, 1, 200) short_query
FROM pg_stat_statements pss, pg_database pd
WHERE pd.oid=pss.dbid
ORDER BY (pss.total_exec_time + pss.total_plan_time)
DESC LIMIT 30;
Решил перейти в отладку и включить уровень лога Postgres через log_min_messages = debug1 и тут заметил, что он стоит log_min_messages = error, но логи трассировки огромные, т.е. в них пишется все!!! Это не соответствует документации, пришлось переключить в panic.
Важно!!! Убедитесь, что логи трассировки не пишут ничего лишнего, даже если параметры выставлены верно, видимо, я наткнулся на какие-то ошибки релиза.
Пиррова победа Postgres?
Убедившись, что логгирование больше не пишет лишнего, тест был запущен еще раз. Результаты по цифрам порадовали ~ 1500 ORM записей в секунду
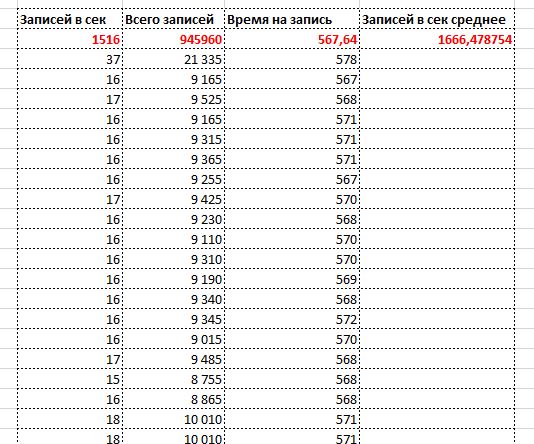
Для сравнения у MS SQL на той же базе с теми же данными 1400. Разница 7% в пользу Postgres.
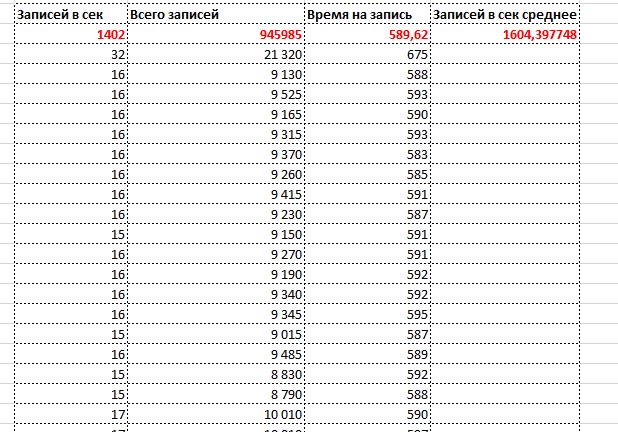
Однако у Postgres результаты замеров оборудования, и расхода времени на операторы не порадовали - 40% процессорного времени.
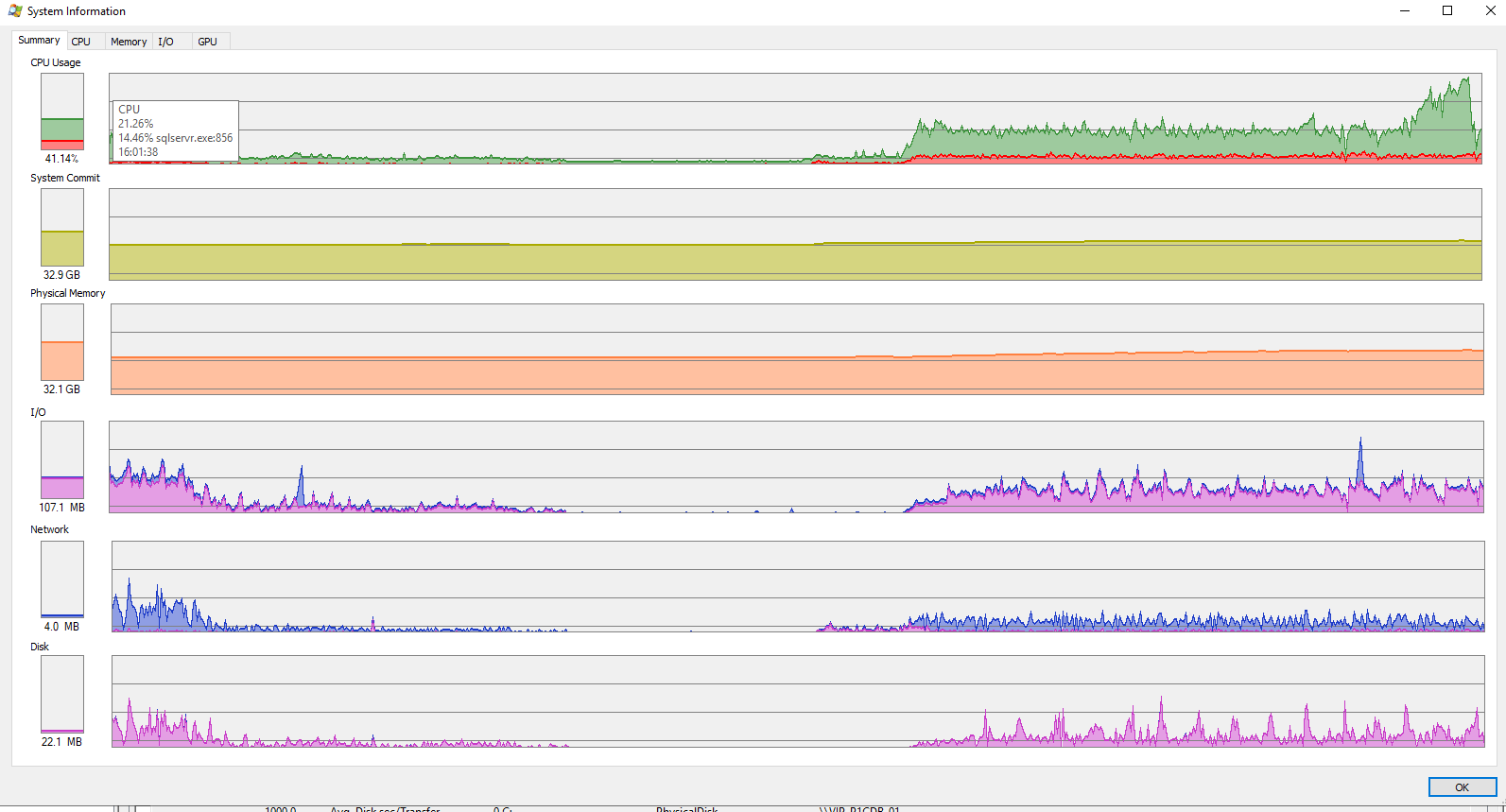
Которые порождает postgresbackend
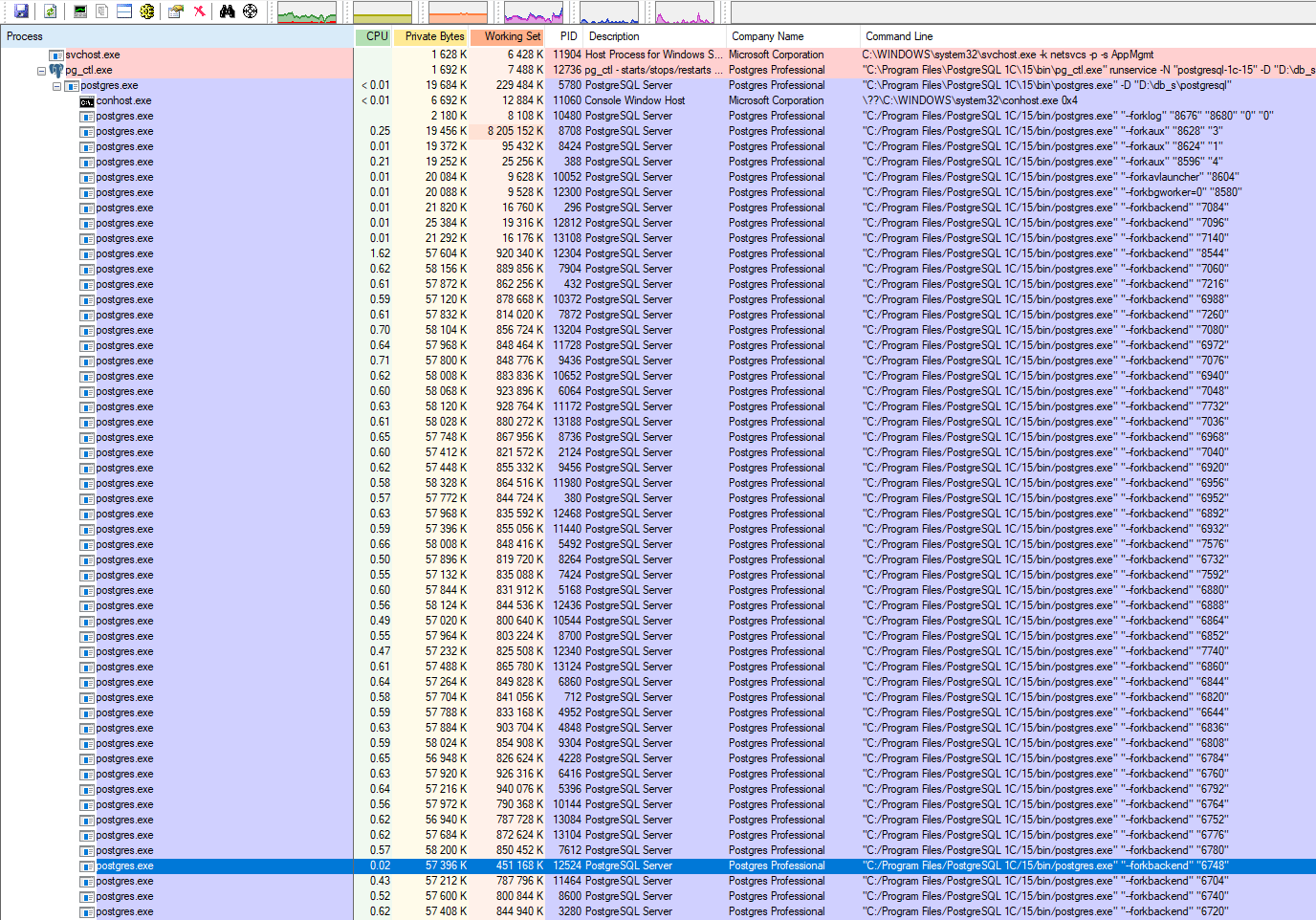
При этом Disk transfers (синий пунктир) не доходит до 10 тыс Iops. Очередей Current disk queue (коричневый) length можно сказать нет.
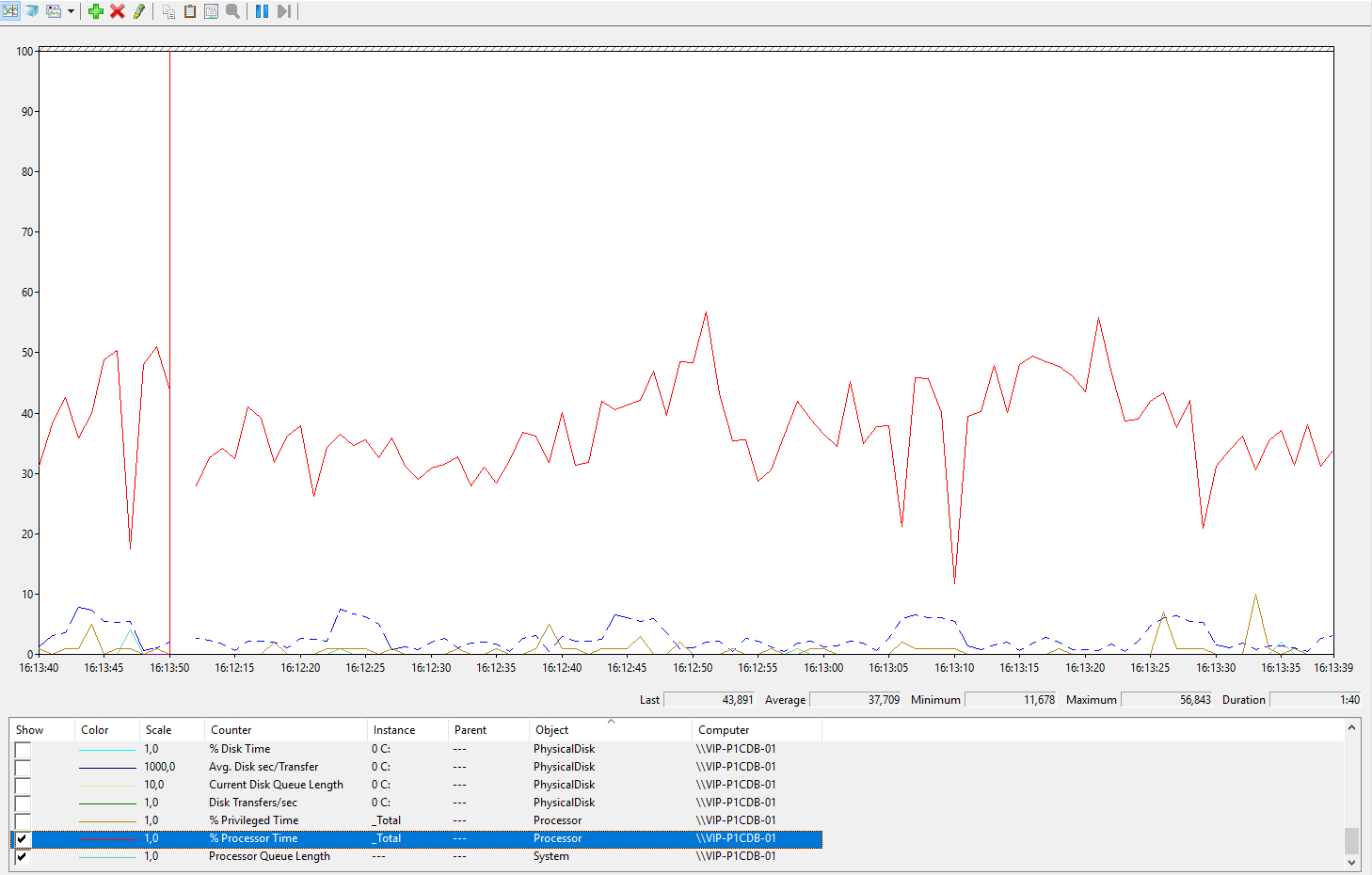
Та же самая база в тех же условиях, но на MS SQL в среднем не доходит до 30% загрузки процессора
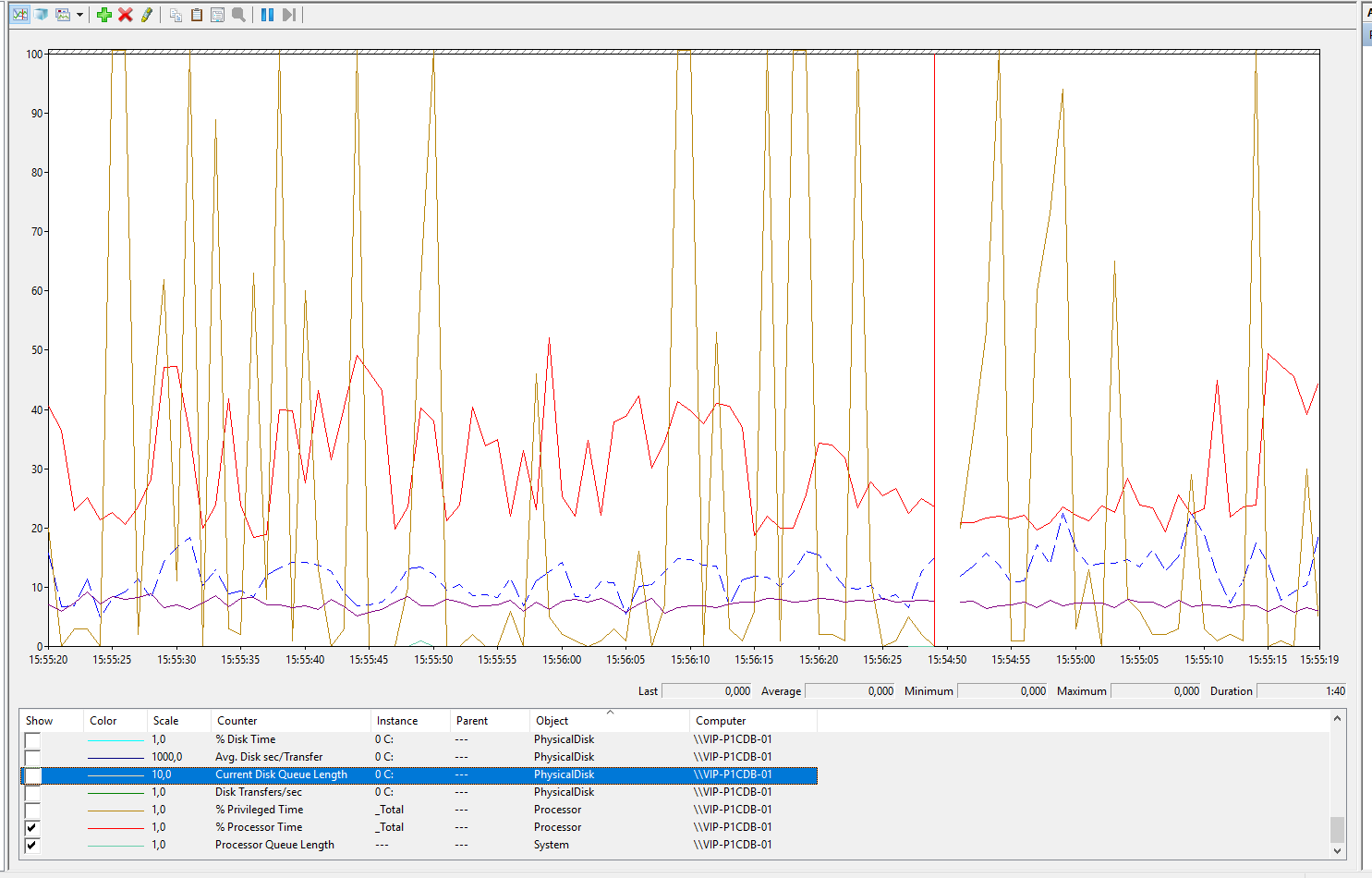
При этом со стороны MS SQL Disk transfers (синий пунктир) уже почти 10 тыс iops. Очереди Current disk queue (коричневый) length случаются. Это, конечно, не говорит о плюсах MS SQL, просто другая архитектура
Что это означает?
Если я увеличу нагрузку со стороны кластера 1С всего с двух серверов приложений, мы с большой вероятностью получим, что MS SQL имеет запас использования по производительности на CPU на треть больше, чем Postgres, который просто быстрее исчерпает ресурсы процессоров!!! Конечно, асинхронный коммит у обеих баз будет включен для избежаний wait на логе транзакций.
А может, текущие 7%-10% выигрыша Postgres сравняют шансы (об этом ниже)? Или MS SQL на большой нагрузке упрется в Waits на SSD? Интрига, да?
Что делал Слон, когда пришел наПолеОн ? Разбор «удачного» запуска.
Если посмотреть Trace средствами Postgres (нюансы включения см. выше)
|
Кратко что делает 1С |
Как я это интерпретирую |
|
BEGIN TRANSACTION |
Начинаем транзакцию |
|
SELECT … FROM _AccumRg16920 T1 …WHERE ((T1._Fld628 = CAST(0 AS NUMERIC))) AND (T1._RecorderTRef = |
Чтение основной таблицы регистра РегистрНакопления.СУУ_КубПрибылейИУбытков (dbo._AccumRg16920) , даже если мы исполняем просто метод .Записать() в режиме замещения |
|
SELECT …. FROM _AccumRgAggOptK21501 T1 … WHERE ((T1._Fld628 = CAST(0 AS NUMERIC))) AND (T1._RegID = … Вызывается несколько раз с разными параметрами |
Чтение таблицы опций сети агреггатов РегистрНакопления.СУУ_КубПрибылейИУбытков ( dbo._AccumRgAggOpt18422). Зачем это делать каждый раз при записи? |
|
DELETE FROM _AccumRg16920 WHERE (_AccumRg16920._RecorderTRef … AND ((_AccumRg16920._LineNo >= CAST(1 AS NUMERIC) AND _AccumRg16920._LineNo < CAST(3 AS NUMERIC)))) AND (_AccumRg16920._Fld628 = CAST(0 AS NUMERIC)) |
Удаление предыдущего набора записей из основной таблицы dbo._AccumRg16920 |
|
INSERT INTO _AccumRg16920 |
Вставка записи в основную таблицу регистра накопления РегистрНакопления.СУУ_КубПрибылейИУбытков. Один Insert на КАЖДУЮ запись регистра |
|
COPY pg_temp.tt2…FROM STDIN BINARY |
Вставка записи в таблицу pg_temp.tt2 |
|
INSERT INTO pg_temp.tt3 …SELECT date_trunc('month',T1._Period), T1._Fld17029RRef, T1._Fld16992RRef, T1._Fld16993RRef,…. FROM pg_temp.tt2 T1 GROUP BY date_trunc('month',T1._Period), T1._Fld17029RRef,
|
Подсчет новых оборотов для последующего обновления.
|
|
ANALYZE pg_temp.tt3 |
Собирает статистику |
|
UPDATE _AccumRgTn17037 SET…. FROM pg_temp.tt3 T2 WHERE (T2._Period = _AccumRgTn17037._Period AND T2._Fld1702…
|
Обновляет таблицу оборотов . Странно почему не используются _AccumRgDl _AccumRgBf? Если агрегаты включены? |
|
SELECT FASTTRUNCATE ('pg_temp.tt3') |
Чистим |
|
SELECT FASTTRUNCATE ('pg_temp.tt2') |
Чистим |
|
SELECT Creation,Modified,Attributes,DataSize,BinaryData FROM Params WHERE FileName = $1 |
Зачем то читаем параметры |
|
COMMIT |
|
Мы видим, что при каждом!!! вызове метода .Записать() для регистра накопления 1С вызывается
"ANALYZE pg_temp.tt2" пересчет статистики по временной таблице 37% времени
"SELECT FASTTRUNCATE ($1)" усечение временных таблиц 30% времени

Все остальное по сравнению с этим мелочи. В сочетании с исходным повышенным расходом ресурсов CPU это может сыграть отрицательно, при следующем этапе увеличения нагрузки.
У меня лично много вопросов как разработчикам Postgres, так и к 1С.
Неужели Postgres оптимизатор планов запросов не может нормально работать без статистики при правильно выставленных индексах?
Я точно знаю, что Oracle это может, а MS SQL с оговорками. Но в MS SQL это реализовано автоматически при включении флага трассировки 2731 для нужных объемов данных. То, что разработчики 1C в Postgres делают при каждом вызове .Записать() ANALYZE pg_temp.tt* так себе решение, хотя оно чем-то обосновано?
Почему FASTTRUNCATE не такой уж и fast?
Судя по описанию, его сделали специально для 1С https://postgrespro.ru/docs/postgrespro/15/fasttrun это супер – значит, 1С уважаемый клиент у разработчиков Postgres. Но 30% времени? Я понимаю, что 1С слишком активно использует временные таблицы, но мы все понимаем, для декларативного языка временная таблица это всего лишь аналог переменной (вспомните, что такое реляционная алгебра и реляционное исчисление) в пакете запросов, поэтому и MS SQL и Oracle развивают функционал временных таблиц.
Как определить в Postgres, на что тратится процессорное время, если не брать сами запросы?
Из теста видно, что Postgres загружает процессор на 35-40%, а MS SQL на 20-30%, это означает, что при большем Highload Postgres первым сойдет с дистанции. На что тратится эта разница? Я не нашел способа анализировать это, например, включение логгирования приводит к 100% загрузке процессора, но из представлений pg_* это не видно.
Помогите Postgres выиграть у MS SQL
Формально тест средней нагрузки по импортозамещению для средней загрузки пройден c небольшим преимуществом Postgres. Но детальный разбор показывает, что увеличение нагрузки будет не в пользу Postgres, с большой вероятностью. Если смотреть со стороны Oracle и MS SQL, конкурирующая СУБД должна быть сопоставимой по возможностям и обязательно в каких-то областях лучше, а разбор кода 1С уже показывает наличие уязвимого места. Я, конечно, не знаю всей магии в Postgres и интрига сохраняется, но надеюсь, мне подскажут, как эти проблемы решить или скомпенсировать. Выбора нет, только Postgres только вперед.
P. S. А пока подписывайтесь на продолжения, на нашем канале (в профиле) и регулярно делайте Image установок MS SQL, он еще может долго обеспечивать запас производительности без смены оборудования.
Вступайте в нашу телеграмм-группу Инфостарт