
В этой статье поговорим о миграции высоконагруженных решений на технологической платформе 1С:Предприятие 8 (далее «платформа 1С») в операционную систему Linux с СУБД PostgreSQL.
Материалов на эту тему в последнее время появилось довольно много, но как показывает практика – до сих пор закрыты далеко еще не все вопросы в этой области.
Почему мы рассматриваем именно высоконагруженные системы?
Есть разница в технологии миграции информационных систем на платформе 1С в зависимости от их «объема». Сравнительно небольшая система переносится с использованием типовых средств платформы 1С, и в процессе эксплуатации в новом месте, как правило, не возникает никаких дополнительных вопросов.

Крупная, высоконагруженная система требует бóльшего внимания. Понятно, что разделение на «крупную» и «не крупную» систему четких границ не имеет. В этом докладе мы под «крупной» предлагаем ориентироваться на более 1000 рабочих мест в одной информационной базе, где размер самой базы данных – не менее 1Тб. И для успешной миграции такой крупной системы лучше сразу придерживаться определенной технологии, чтобы все прошло гладко.
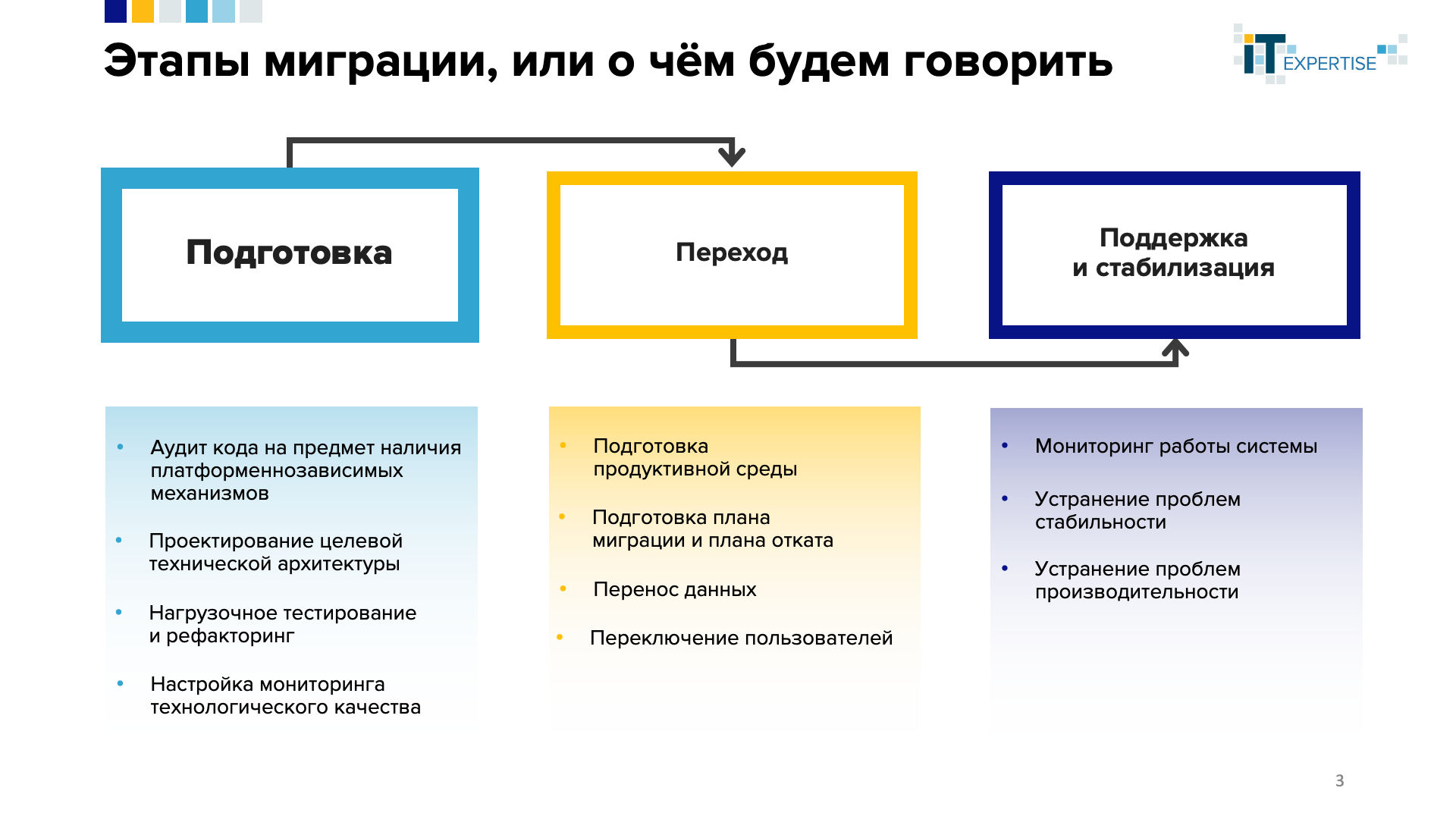
Технологию миграции крупной информационной системы на платформе 1С можно разделить на три этапа:
- Подготовка к миграции
- Собственно, переход
- Поддержка и стабилизация мигрировавшего решения
При этом, если первые два этапа выполнены корректно, третий – больше будет про поддержку в нормальном рабочем режиме, нежели про стабилизацию.
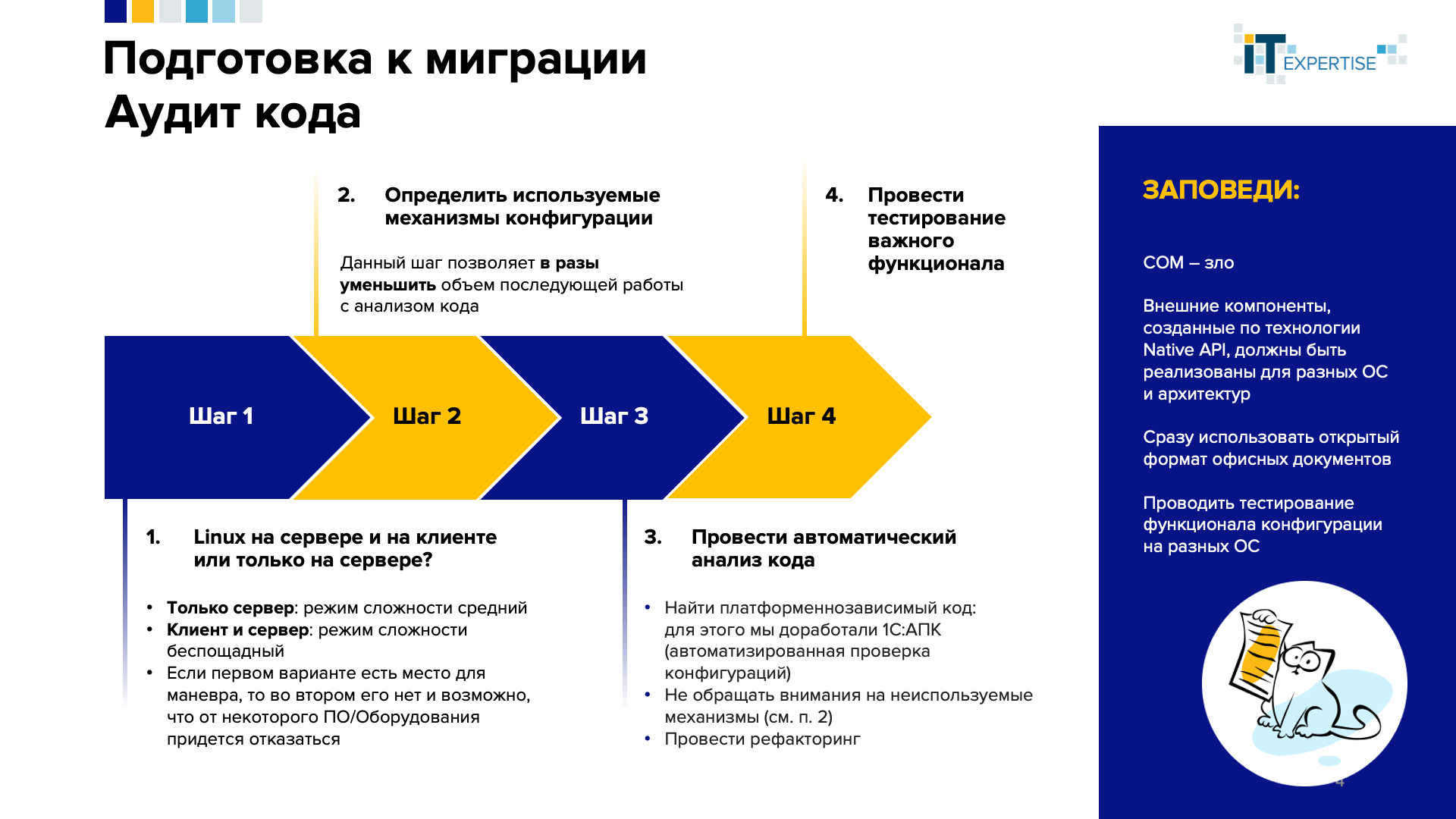
Этап подготовки начинается с аудита кода. Этот момент особенно важен, если решения на платформе 1С довольно преклонного возраста. Например, в решении могут быть использованы популярные ранее технологии COM/COM+, поддерживаемые только семейством ОС Windows.
И все это legacy придется выявить и устранить до начала процесса переноса системы в Linux.
Учитывая объем кода современных корпоративных систем, никто в здравом уме «вручную» весь этот объем не просматривает. Поиск опасного (с точки зрения перехода) кода можно автоматизировать. Мы сами используем на подобных проектах и всем крайне настоятельно рекомендуем использовать автоматический анализ кода.
Нам известно несколько решений, существенно облегчающих анализ кода по различным критериям. Например, «1С:АПК» и «BSL LS». Сейчас мы чаще используем «1С:АПК», т.к. хорошо адаптировали его под свои нужды и он встроен в уже отлаженный процесс успешного проведения такого рода проектов.
Мы доработали «1С:АПК» таким образом, чтобы в анализируемом решении можно было быстро найти все платформеннозависимые классы, методы и функции. В простых случаях генерируется даже программный код для замены и выдаются полезные рекомендации. Это очень облегчает анализ и подготовку к рефакторингу и экономит время.
В сложных ситуациях без ручного вмешательства не обойтись. Поэтому перед запуском анализа кода рекомендуем провести инвентаризацию тех подсистем, которые реально используются в работе. Цель – сузить воронку анализируемого кода.
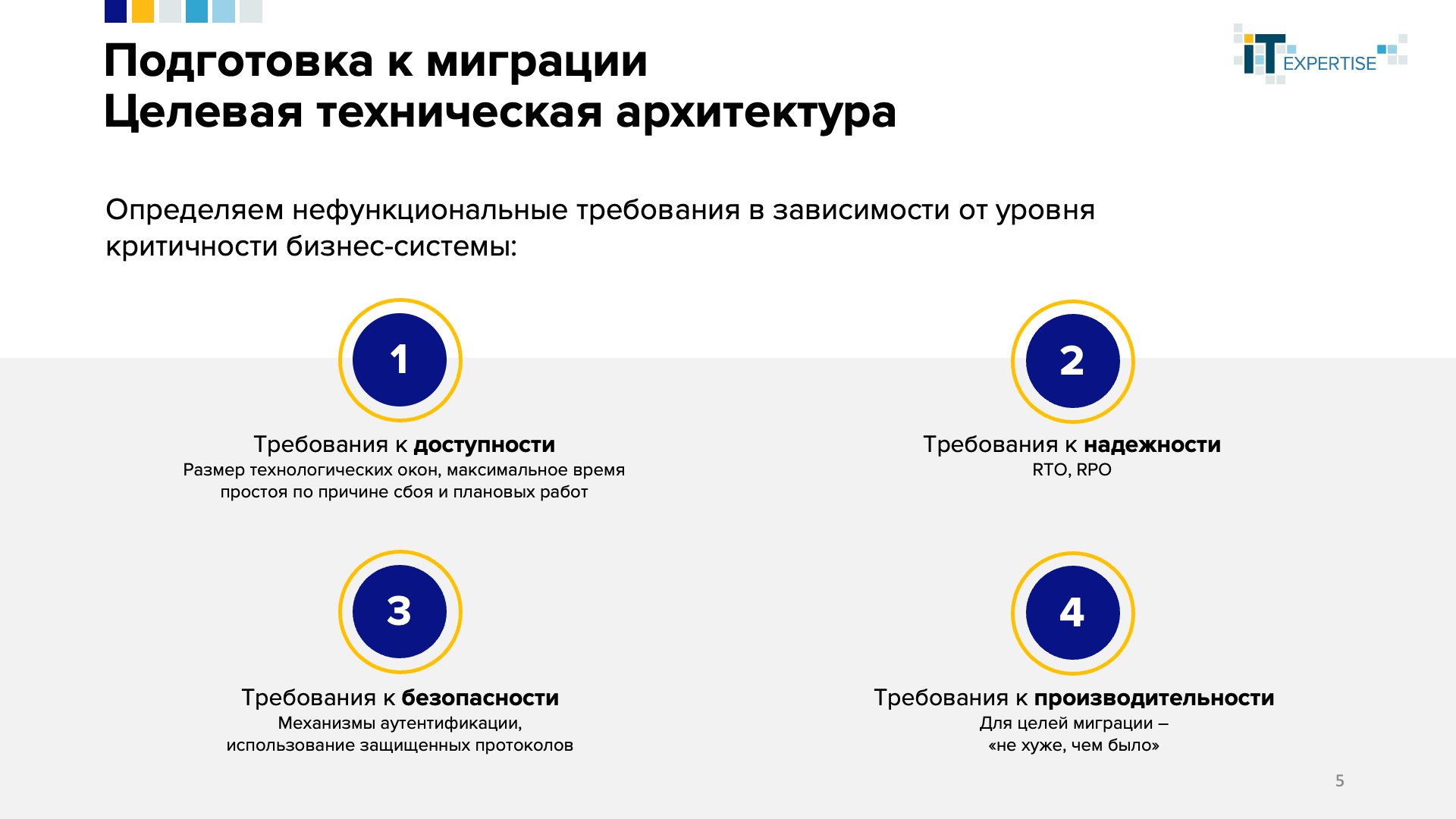
Параллельно с анализом и рефакторингом кода начинаем готовить проект «целевой технической архитектуры».
Условно раздела для заполнения такого документа можно выделить два:
- Нефункциональные требования к системе
- Решения по их удовлетворению
Нефункциональные требования обычно надо собирать. Но если у вас есть прод, к которому претензий нет, то все эти требования вам уже хорошо известны – например, доступность 24/7, минимальные технологические окна и тому подобное.

Собрав нефункциональные требования, переходим к описанию решений по их удовлетворению. Здесь главное – сосредоточиться на корректном наборе целевого ПО, его настройке и тестированию.
Как правило, мы начинаем с описания ландшафта (сайзинг). Здесь тоже вполне нормально обратиться к проду и взять параметры оттуда. С версиями платформы 1С:Предприятие и прикладных решений на ней тоже более-менее все понятно.
Важный момент – версия Postgres. Вот тут нужно проявить внимание! Версий этой СУБД много. Но если система действительно эксплуатируется в режиме highload, мы рекомендуем иметь поддержку вендора и сразу рассматривать версию Postgres Pro Enterprise. И дальше станет понятно, почему это может оказаться полезным.
Далее. Что касается конфигурации кластера Postgres. Здесь нужно обратить внимание на построение отказоустойчивого кластера сразу. И если говорить о MS SQL Server, то автоматический failover был в комплекте. С точки зрения Postgres, способ, который его обеспечит, придется выбрать самостоятельно из набора доступных open-source решений – «в коробке» его нет. Наибольшую популярность имеют связки: [Patroni + ETCD + HA-Proxy], [Corosync/Pacemaker]. Наверняка вы сможете вспомнить что-то еще – решений много.
Тут главное не просто «выбрать» из понравившихся названий. ИТ-служба должна развернуть ПО и выполнить тестирование (как минимум - тестирование с отказом, тестирование автоматического переключения), собрать все показатели и принять окончательное решение, какое ПО подходит именно вашей системе и требованиям к ней.

Следующий шаг – стратегия и средства резервного копирования.
Традиционно для Postgres многие начинают с [pg_dump + pg_restore]. Но в highload решениях это не поможет. Это логический бэкап. Он консистентен на момент начала, а восстановления на какое-то конкретное время – нет. На крупных базах выполнение резервного копирования может занимать дни. В такой ситуации бэкап вряд ли когда-нибудь пригодится, разве что можно развернуть его потом в среде разработки.
[pg_basebackup] – еще одна «родная» утилита. Она выполняет файловый бэкап всего кластера сразу, как единого организма – с единым WAL, не разделенным по базам, единым счетчиком транзакций и многим другим . Даже если выбрать подходящий для этого вариант «одна база в одном кластере», вряд ли вы будете выполнять полный бэкап кластера чаще раза в сутки. Соответственно, восстановиться, например, на час дня при созданном бэкапе в полночь – займет непрогнозируемое время, но вы точно не уложитесь в технологическое окно.
В итоге приходим к [pg_probackup] – получаем дифференциальные, инкрементные бэкапы. Все, к чему привыкли в MS SQL Server.
Нельзя забывать про обслуживание системы. План обслуживания нужно настроить, замерить и описать в техническом проекте. В первую очередь – убедиться, что показатели попадают в необходимые требования.
В отличие от MS SQL Server, Postgres версионник, поэтому кроме привычных задач обслуживания, нужно еще помнить про удаление устаревших версий. Строго говоря, в MS SQL версии строк тоже присутствуют при использовании определенных режимов изоляции, но там их будет удалять фоновый процесс, которого обычно хватает, и вряд ли вам придется о них думать (но есть нюансы, как всегда).
Здесь же возможностей «autovacuum» вам точно не хватит (и это нормально). Наверняка на просторах интернета можно прочитать про прекрасный «vacuum full» каждую ночь. Но увы, на enterprise решениях с многотерабайтными базами этот замечательный инструмент будет выполняться несколько дней. Что вряд ли понравится пользователям, работа которых с обрабатываемыми autovacuum таблицами будет заблокирована.
В итоге можно прийти к рекомендуемому нами подходу по формированию плана обслуживания:
1. REINDEX INDEX (CONCURRENTLY)
2. vacuumdb --all --analyze (--freeze)
3. pg_repack: REINDEX + CLUSTER + VACUUM FULL онлайн
Чем хороша утилита [pg_repack]:
- Она умеет выполнять «vacuum full» онлайн
- Она умеет делать «CLUSTER»: команду, которая упорядочивает физические данные таблицы по индексу, который в MS SQL Server называется кластерным. В Postgres такого индекса нет, а таблица упорядочена только в момент ее создания. Поэтому со временем порядок записей в таблице нарушается, что может привести к деградации производительности запросов к ней.
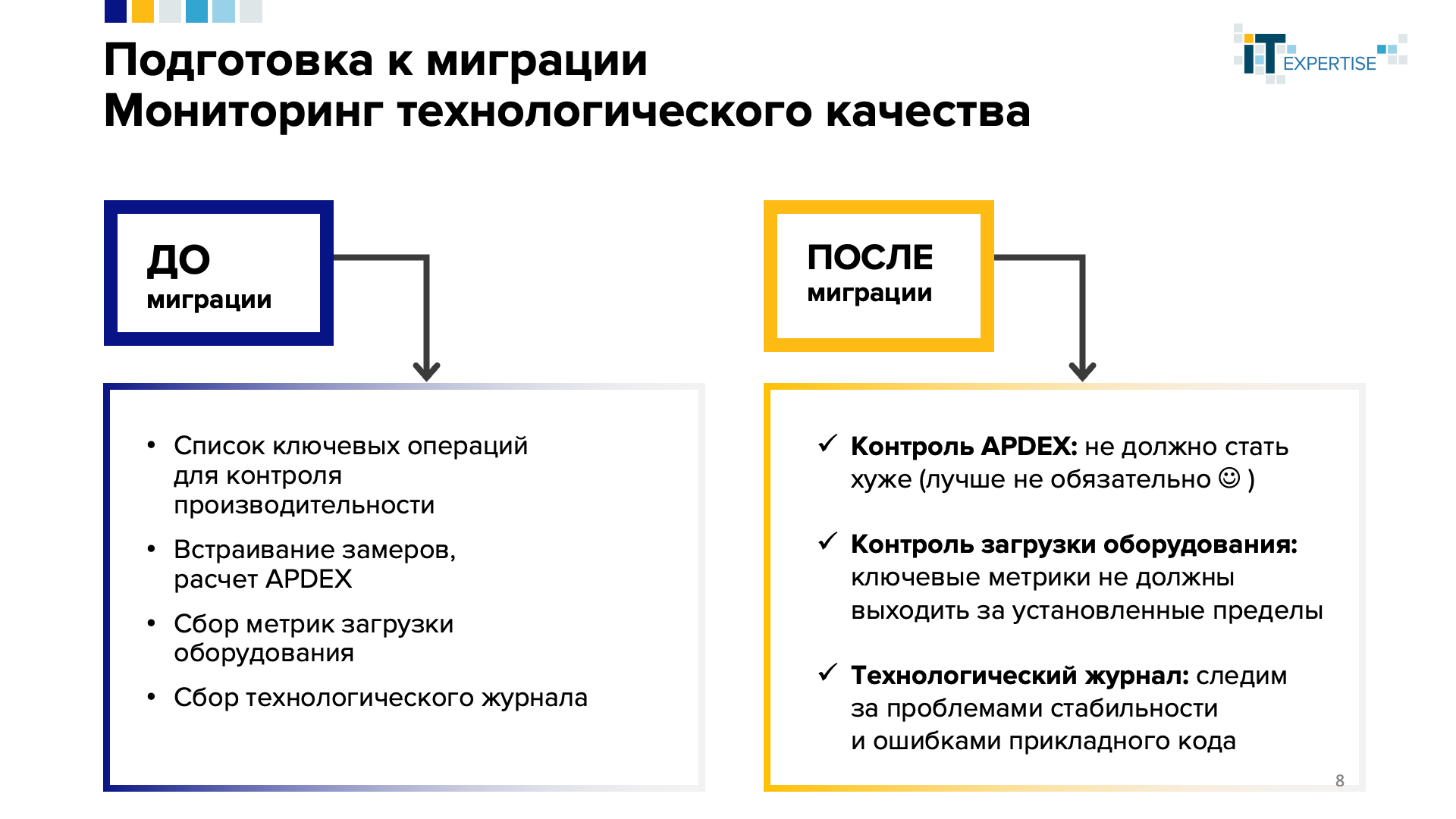
В подготовке к миграции важно уделить внимание мониторингу технологического качества.
Это не тот мониторинг с красивыми дашбордами, к которому все привыкли. Здесь главная задача – понять после миграции, стало хуже, лучше или осталось так же.
В мире 1С для контроля производительности используется методика APDEX. Если кратко: выделяется набор ключевых операций, которые начинаются на клиенте и на клиенте же завершаются. Например, момент начала ключевой операции – пользователь нажимает кнопку, инициирующую некий процесс в информационной системе. Финал такой ключевой операции – пользователю возвращается возможность работать в системе дальше.
Обычно по набору ключевых операций от пользователей собирается информация – сколько по времени, по их мнению, эти ключевые операции должны выполняться. Но с точки зрения процесса миграции такой опрос пользователей проводить не нужно. В качестве эталона берутся текущие показания продуктивной среды, с которой планируется осуществлять миграцию.
Иными словами, до начала процесса миграции нужно определиться со списком ключевых операций и в продуктивном контуре посчитать APDEX по всем этим операциям.
Кроме этого, необходимо следить за нагрузкой на оборудование. А для платформы 1С включить сбор технологического журнала – чтобы разбираться с проблемами стабильности и ошибками (если есть).
После миграции нужно будет повторить все эти процессы – это поможет в получении объективной картины. Подробнее – чуть ниже в статье.

Важным моментом подготовки к миграции является этап нагрузочного тестирования. Разработка сценария тестирования должна начинаться практически в самом начале проекта миграции – сразу после проведения технологического аудита и рефакторинга.
Для решений на платформе 1С с целью выполнения нагрузочного тестирования нами используется «Тест-центр». «Тест-центр» удобен по следующим причинам:
- умеет автоматически запускать нужное количество рабочих мест в системе 1С
- умеет выполнять заранее заготовленные бизнес-сценарии на этих рабочих местах – фактически эмулируя работу реальных пользователей
Здесь главное правильно описать состав ролей и сценариев. Это позволит сэмулировать практически полностью продуктивную нагрузку, не привлекая к этому живых пользователей.
Результаты нагрузочного тестирования позволят понять, с какими проблемами производительности и активной параллельной работы пользователей можно столкнуться в целевом контуре (куда, собственно, и планируется миграция). Причем, узкие места такое тестирование выявляет заранее – до того, как в новой системе начнут работать живые люди.
Чем еще полезно такое упражнение?
- Проверка корректности сайзинга.
- Можно спокойно и без аврала подобрать корректные настройки для систем 1С и PostgreSQL.
- Выявить узкие места информационной системы 1С и определиться с рефакторингом.
- Уже в этом процессе можно обучиться расследовать проблемы производительности и стабильности в новой среде. DBA смогут повысить свой уровень для качественной поддержки целевой системы.

Важность проведения нагрузочного тестирования в проектах миграции поясним двумя примерами.
Пример 1

Нагрузочное тестирование «1С:ERP» крупного холдинга позволило выявить узкое место – ключевой запрос, который в исходной системе выполнялся 3 минуты, а в целевой системе – 17 часов.
Синопсис: Две временные таблицы соединяются друг с другом. Отсутствует необходимый индекс. Во внешней таблице ~8000 строк. Во внутренней – ~2 500 000 строк. В результате такого соединения возвращается пустота. При этом само соединение выполняется трижды – те же таблицы, но с чуть разными условиями.
Решение: Добавили отсутствующий индекс. Запрос стал выполняться за 1 минуту.
Пример 2

База решения «1С:Розница» с 2000+ пользователями, выполняющими однообразные схожие операции — оформляют продажи.
Синопсис: В таком режиме работы регулярно получали 2000 бэкендов – то есть 2000 процессов Postgres, так как операции выполнялись с большой интенсивностью. Активно использовался механизм временных таблиц платформы 1С. Тест завершался негативно. Согласно отчету по APDEX, практически никто не уложился в целевое время. При этом сервер СУБД простаивал, а сервер приложений 1С был перегружен. Радости добавлял сбор дампов и перезапуск рабочих процессов мониторингом кластера 1С:Предприятие, считавшим их зависшими.
Решение: Расследование собранных дампов показало, что все потоки рабочих процессов висели в ожидании ответа СУБД, которая, повторимся, была не загружена, но и не отвечала по какой-то причине.

Анализируем дальше: смотрим, чего же ждала СУБД, пока ее так ждали рабочие процессы:
LWLock | LockManager | 36341376
Про механизм легких блокировок мы в курсе и понимаем, как они работают. В этой ситуации не поняли, почему они такие длинные и что с ними вообще происходит. Обратились за помощью к вендору – к команде Postgres Pro (именно поэтому рекомендовали ранее сразу рассматривать Postgres Pro Enterprise).
Ребята из Postgres Pro помогли (спасибо им!) – провели анализ ситуации, выявили причину, после чего провели внутреннюю оптимизацию в продукте. Краткое описание причины такого поведения – на врезке. Описание оптимизации можно изучить по ссылке: https://postgrespro.ru/docs/enterprise/14/release-proee-14-7-1
Описание: Каждый серверный процесс отправляет в общую циклическую очередь сообщения об аннулировании кэша в результате изменения данных или их схемы. При высокой нагрузке, где большое количество серверных процессов интенсивно меняет данные, это может
приводить к чрезмерно частому сбросу кэша и последующему поднятию в него данных.
После установки исправленной версии PostgreSQL APDEX поднялся до практически идеальных 0.979.
Надеемся, эти 2 примера убедили сомневающихся в необходимости этапа нагрузочного тестирования в серьезных проектах миграции.
Идем дальше.

Теперь нужно сказать несколько слов о самой миграции.
Составляем план миграции – документ, где пошагово, с указанием сроков и ответственных, в технологической последовательности описывается процесс выполнения миграции. Попадание в плановое время рекомендуем отрепетировать (проверить) заранее. Все более-менее просто, но есть нюанс. Скрывается он на шаге «выгрузка базы в формат .dt».
Понятно, что ранее DBA все операции с СУБД выполняли средствами этой СУБД. Но перенос между разными СУБД для систем 1С требует выполнения выгрузки-загрузки через файл-контейнер, формируемый платформой 1С.
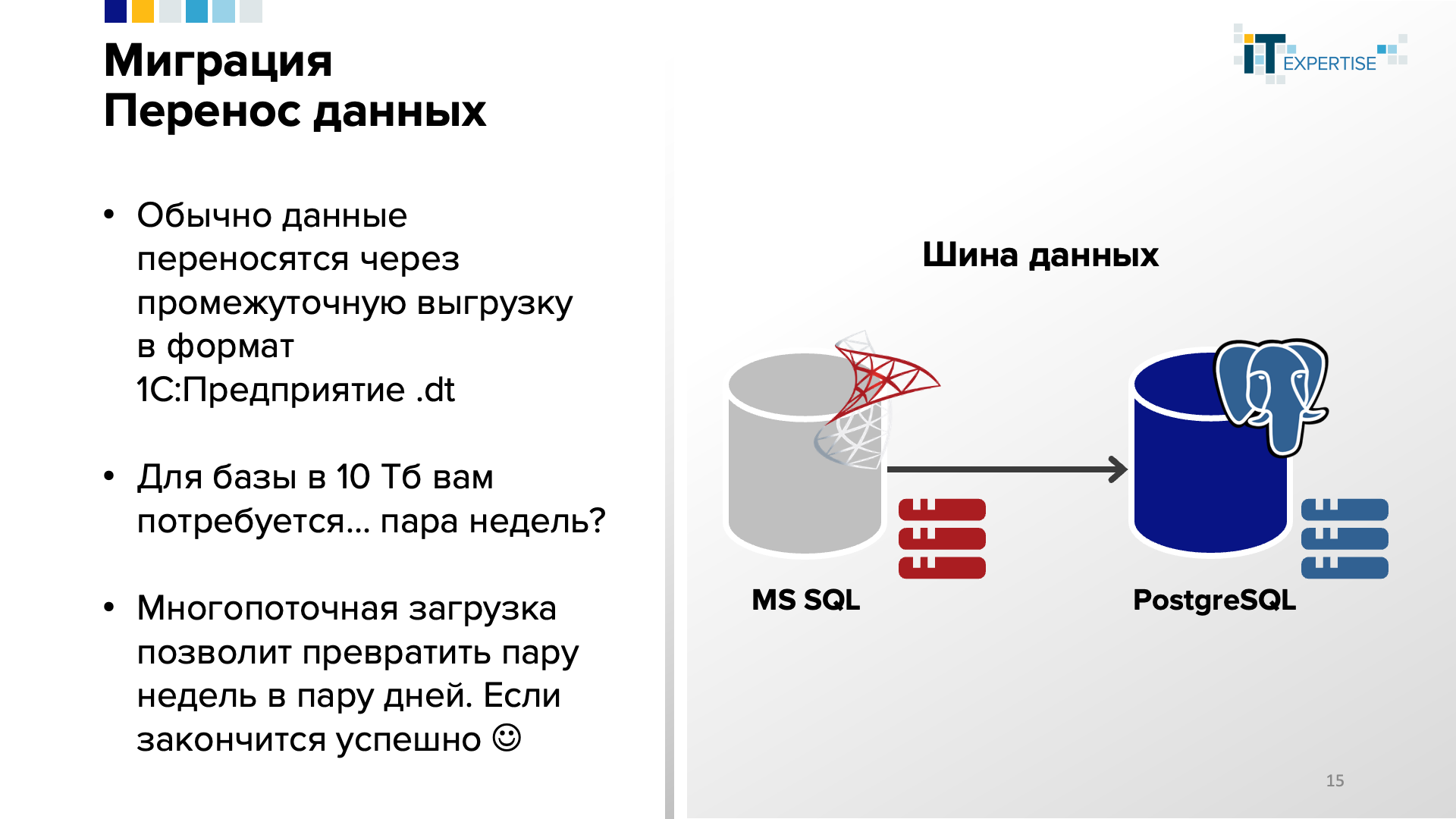
Для базы 10Тб выгрузка в dt-файл может занимать, например, неделю.
Многопоточная загрузка из этого файла может занять на порядок меньше времени, но в технологическое окно вписаться вряд ли получится. К тому же, такая загрузка может завершиться конфликтом блокировок, и такое бывало.
Многопоточная загрузка (параметр –JobsCount в команде пакетного режима /RestoreIB) в технологической платформе 1С:Предприятие появилась сравнительно недавно – лишь в версии 8.3.19.
Надежду в упрощении процесса миграции из СУБД в СУБД дает анонс в версии технологической платформы 1С:Предпрятияе 8.3.23, где заявлена новая функциональность переноса данных без необходимости использования промежуточного файла.
А пока ждем новые возможности – у нас уже есть проверенное решение. Это, как ни странно - корпоративная шина данных (КШД, ESB)!
Разворачивается отказоустойчивая, масштабируемая, высокопроизводительная КШД (мы используем «1С:Интеграция КОРП»). К ней подключаются система-источник и система-приемник. После чего запускается «полный обмен» из системы-источника в систему-приемник.
Какие плюсы:
- Пользователи продолжают работать – их не нужно выгонять на неделю, пока идет выгрузка в dt-файл.
- Обмен по такой шине не мешает работе, работает быстро. Через какое-то время в системе-приемнике вы получаете полную копию информационной базы системы-источника.
- После проверки данных, можно оперативно переключить пользователей с исходной системы на целевую.
- Мало того, в случае необходимости можно сохранить на какое-то время шину, поменяв «полярность» обмена. Данные из целевой системы какое-то время могут синхронизироваться в источник. Это даст возможность без проблем вернуться в начальное состояние в случае какого-то форс-мажора.
Что в итоге или Ключи к успешной миграции

В качестве заключения можно отметить следующие моменты:
- Нужно смириться, что процесс миграции занимает время
- Ощутимую часть этого процесса – занимает подготовка и проведение нагрузочного тестирования, и оптимизации системы после
- Это время можно потратить по-разному. Мы рекомендуем воспользоваться им, чтобы подтянуть знания у DBA и системных администраторов. Причем, этап нагрузочного тестирования позволит прокачать навыки на практически реальных данных и ситуациях
- Как видно из примеров в этой статье и тех, что мы писали ранее в рамках серии «Экспертный кейс» – иногда достаточно точечно исправить несколько запросов и все взлетает и летит как надо
Благодарим за внимание! Надеемся, наш опыт может пригодиться в многочисленных ныне проектах импортозамещения и перехода в стек Linux/Postgres.
Вступайте в нашу телеграмм-группу Инфостарт