До сих пор самым простым, проверенным, надежным средством для синхронизации данных между конфигурациями 1С остаются правила конвертации в формате КД 2. Это – старая технология, по которой существует огромное количество информации.
На эту тему на конференциях Инфостарте много раз читались доклады, в том числе, мои доклады – они доступны в видео и текстовом формате (например, этот и этот).
Существуют готовые решения – и так называемые «стандартные» переходы от фирмы «1С», и авторские решения, которые мы тоже можем использовать, чтобы сэкономить свое время и оптимизировать бюджет проекта. Но понятно, что на ряде проектов возможностей этой старой технологии будет уже недостаточно.
Мы столкнулись с подобной ситуацией и сейчас с расскажу, как мы с ней справлялись.
Сам доклад сегодня будет построен по принципу «от простого к сложному».
-
Сначала мы рассмотрим задачи интеграции данных просто и широко.
-
Потом перейдем к более узким ситуациям.
-
И в конце я расскажу о реальном кейсе сложного проекта, где нам пришлось создать симбиоз таких двух монстров, как правила конвертации КД 2 и модная технология использования брокера сообщений RabbitMQ.
Все материалы, о которых я говорю, и в том числе обработку «Универсальный обмен в формате XML со встроенным способом транспорта через RabbitMQ», можно будет скачать в приложении к данной статье.
О компании

Коротко про нашу компанию.
-
Мы – продуктовая команда, разрабатывающая продукты на 1С.
-
В сфере 1С наши специалисты с 2007 года.
-
С 2015 года мы активно растем и сотрудничаем с Инфостартом в плане распространения наших программных продуктов.
-
В основном, наши решения – это универсальные готовые переносы данных для различных ситуаций, которые имеют более широкую функциональность, и, я считаю, более высокое качество, чем стандартные обработки от фирмы 1С.
От простого к сложному

Задачи интеграции между различными решениями, между учетными системами могут быть различными.
-
Наверное, 99% стандартных задач, с которыми сталкиваются специалисты – это доработать что-то в стандартном обмене. Стандартный обмен между двумя конфигурациями 1С в текущих условиях – это план обмена в формате универсального обмена EnterpriseData. И, как правило, задачи будут заключаться в том, чтобы что-то в него добавить, что-то в нем поменять, что-то доработать.
-
Эти задачи – простые, их понятно, как делать. Рассказывать про них, в общем-то, неинтересно. И заниматься ими не так интересно. Для таких ситуаций нет смысла разрабатывать высокотехнологичное решение, поскольку уже есть стандартный обмен от фирмы «1С» через EnterpriseData. Он вполне устраивает и по формату данных (там есть все, что должно переноситься), и по производительности, и по оперативности, и по актуальности. Не нужно использовать космическую ракету, чтобы отвести продукты с фермы на городской рынок. Лучше использовать максимально подходящие инструменты для решения задач.
-
Если же перед вами стоит задача разработать что-то, для чего нет стандартного механизма, то в текущих реалиях, на мой взгляд, наиболее правильным будет использовать событийную интеграцию. В этом случае такие решения, как RabbitMQ и другие брокеры сообщений, подойдут наилучшим образом. В этом случае в момент события записи нового объекта сразу же происходит его отправка в некую шину обмена, откуда он попадает уже далее в те информационные системы, куда требуется.
Но, если стандартный обмен устраивает по всем параметрам, разрабатывать какие-то решения с нуля не всегда оправданно.
Технология КД 2 закрывает большинство методических вопросов перехода

Теперь попробуем сузить широкий спектр задач интеграции до задач перехода с некой старой конфигурации 1С, например, с УПП, на некую новую, которая стоит перед вами.
Наша компания, как правило, для подобных задач перехода использует стандартную обработку «Универсальный обмен в формате XML» и правила конвертации – либо стандартные от 1С, либо разработанные нами.
Почему мы предлагаем использовать именно эту технологию?
-
Во-первых, все стандартные обработки перехода от фирмы 1С до сих пор сделаны на КД 2.
-
Во-вторых, существует большое количество авторских решений на том же Инфостарте, которые можно приобрести и использовать на своем проекте.
Технология КД 2 старая, по ней существует большое количество специалистов, которые в ней разбираются. Вам будет несложно найти команду на такой проект – людей, которые смогут данные правила дорабатывать, поддерживать.
Но, на мой взгляд, самая главная ценность авторских правил и даже правил от фирмы «1С», в том, что они уже, по сути, содержат в себе методику перехода и внедрения новой конфигурации 1С. При разработке таких правил была проделана большая работа, чтобы учесть большое количество нюансов и вопросов именно методического соответствия конфигураций.
Если мы будем использовать готовые правила, все это «из коробки» уже у нас будет рассмотрено, реализовано и поддерживаться.

Рассмотрим более узкий случай – проект перехода с УПП на ERP.
Допустим, наш заказчик хочет прогрузить начальные остатки на январь 2021 года и успеть перенести первый квартал до того, как начнется процесс его закрытия, чтобы закрывать первый квартал уже из конфигурации ERP. Вот такая оптимистичная задача.
Чтобы решить эту задачу, нужно разобраться, как отражаются операции в этих конфигурациях и настроить соответствие между объектами разных систем.
Отмечу, что в стандартной обработке от 1С нет поддержки переноса документов. Хотя на ИТС есть замечательный и очень полный документ, который описывает способы корректного ввода начальных остатков ERP для всех разделов учета. Там для каждого счета учета прописана абсолютно корректная рекомендуемая фирмой «1С» методика.
Однако для документов у нас нет такого готового решения. И, как написано на слайде, интуиция, к сожалению, плохой помощник. Т.е. просто сесть и начать такое соответствие настраивать, нецелесообразно.
Объясню, почему.
-
Рассмотрим документ «Инвентаризация товаров» в УПП. Интуитивно мы считаем, что документ, который играет в ERP такую же роль– это «Пересчет товаров». Но, если посмотреть глубже, это другой документ.
-
В УПП документ «Инвентаризация товаров» не формирует никаких движений.
-
В ERP документ «Пересчет товаров» формирует движения по управленческим регистрам. А документы «Оприходование» и «Списание» в ERP формируют движения только по регламентированному учету. То есть вот так вот изменено методически.
-
-
Или покупка оборудования на счет 0804:
-
В УПП делается документом «Поступление товаров и услуг».
-
А в ERP делается документом «Приобретение услуг и прочих активов». Вы не сможете совершить данную хозяйственную операцию через «Приобретение товаров и услуг».
-
-
В ERP нет документа «Корректировка долга».
-
Если в УПП документ «Корректировка долга» содержал не вид операции «Взаимозачет» или «Списание задолженности», у вас возникнут с ним проблемы.
-
Мы у себя решили эту задачу так – если вид операции не «Взаимозачет» и не «Списание задолженности», мы переносим просто в «Корректировку записи регистров».
-
-
Кроме этого, в ERP нет отдельного документа «Корректировка заказа. Если вы переносите заказы, вам придется сразу пересчитывать их табличную часть с учетом всех корректировок, которые есть в УПП.
-
Ну и конечно, при переносе данных нужно сразу заполнять «Настройки отражения в регламентированном учете». Эта операция значительно изменилась при выходе ERP 2.5.
Стандартная обработка перехода или авторская

Мы с вами рассматриваем проект и постепенно идем к его усложнению.
Разберемся, как мы будем решать нашу задачу перехода на ERP технически.
В случае, если получилось согласовать с заказчиком план проекта, который включает в себя только перенос начальных проектов, переход выполняется в январские праздники, и вы можете использовать стандартную обработку от фирмы «1С». Я предлагаю не списывать ее со счетов – на ряде проектов она замечательно себя показывает. То, что не принеслось с помощью нее в автоматическом режиме, можно исправить уже либо вручную, либо групповыми обработками.
Но в ситуации, которая умозрительно сейчас перед нами стоит, стандартная обработка не подходит – она не переносит документы. Поэтому можно рассмотреть использование некоей авторской обработки. Например, такая обработка есть у нашей компании, за 6 лет на Инфостарте мы продали ее сотни раз, с ее помощью выполнялись уже сотни проектов. В ней реализовано уже много-много нюансов и учтено много сложностей переходного учета с переносом документов.
Особенности переноса «тяжелых» баз
Мы рассмотрели с вами инструмент, который будем использовать – это либо стандартная обработка, либо некая авторская обработка для выполнения такого проекта. Дальше встает следующая проблема – база УПП тяжелая. Она не всегда такая, но на нашем конкретном проекте было так. Что делать?
Я сейчас говорю о ситуациях, когда процесс выгрузки может выполняться неделями. Не говоря уже о загрузке, которая включает в себя операцию записи, и, понятно, что существенно тяжелее для базы данных.
Иногда технологическое окно, которое предоставляет вам заказчик, меньше, чем вам требуется.
Интуитивно понятно, что в этом случае рекомендуется разбивать процесс на этапы.
-
На первом этапе переносим настройки учетной политики, корректируем их вручную под потребности ERP.
-
После этого переносим нормативную справочную информацию. Возможно, не всю, если заказчик планирует произвести нормализацию информационной базы.
-
И только после этого, если нужно, мы переносим документы. Но поскольку они обычно представляют собой основной объем данных, их также можно разбивать – либо по правилам выгрузки данных (отдельно выгружать различные виды документов), либо разбивать выгружаемые данные по периоду.
Хочу сказать, что еще в 2016 году на Инфостарте мы за один стартмани выложили свою адаптацию стандартной обработки «Универсальный обмен формате XML», которая позволяет автоматически разбивать выгрузку данных или загрузку данных на отдельные файлы. С помощью этого методического решения можно:
-
во-первых, решить задачу, когда не хватает оперативной памяти на сервере, то есть бывает так, что даже просто выгрузка не доходит до конца и слетает из-за того, что не хватает оперативной памяти;
-
ну и просто автоматизировать процесс переноса данных – не нужно разбивать выгрузку на этапы, много-много раз нажимать «Выгрузить», а потом – много раз нажимать «Загрузить». Поставили галочку и создастся много файлов XML, и соответственно все файлы XML из определенной папки будут загружены.
Все материалы, о которых я говорю, и в том числе обработку «Универсальный обмен в формате XML со встроенным способом транспорта через RabbitMQ», можно будет скачать в приложении к данной статье.
А сейчас я расскажу, как мы к этой технологии пришли. Почему ее потребовалось использовать на реальном проекте, и почему мы не справились альтернативными способами.
Предпосылки доработки стандартной технологии

Итак, мы проговорили методику переноса в случае тяжелой базы, но в данном случае, это была очень тяжелая база.
-
Переход был запланирован в середине года, и уже после устных договоренностей, но до подписания договора оказалось, что заказчику нужно перенести один миллион документов за полгода.
-
Ситуация усугублялась еще и некоторыми организационными моментами. Я не знаю в точности, либо у ИТ-директора заказчика отсутствовал административный ресурс, либо просто в компании была анархия, либо местные ИТ-специалисты предчувствовали какую-то смену команды и устроили саботаж. Но факт был в том, что практически каждую ночь происходила перезагрузка сервера. База большая, и мы жили пару недель просто как «день сурка» – каждое утро приходишь и удаленно подключаешься и запускаешь выгрузку заново, заново, заново. И никак административный ресурс, который был в возможностях ИТ-директора заказчика, нам эту проблему решить не мог.
-
Исходя из этой проблемы, мы реализовали в своей обработке «Универсальный обмен в формате XML» возможность докачки (довыгрузки) данных и дозагрузки (продолжения загрузки) данных, которая прервалась в прошлый раз.
-
Кроме того, нам еще и не предоставляли достаточное количество места на диске – нам нужно было выгружать большое количество информации, и даже при условии разбиения выгрузки, места на диске не хватало. В этот момент мы уже пришли к необходимости использования отдельного брокера сообщений, который можно не разворачивать у заказчика.
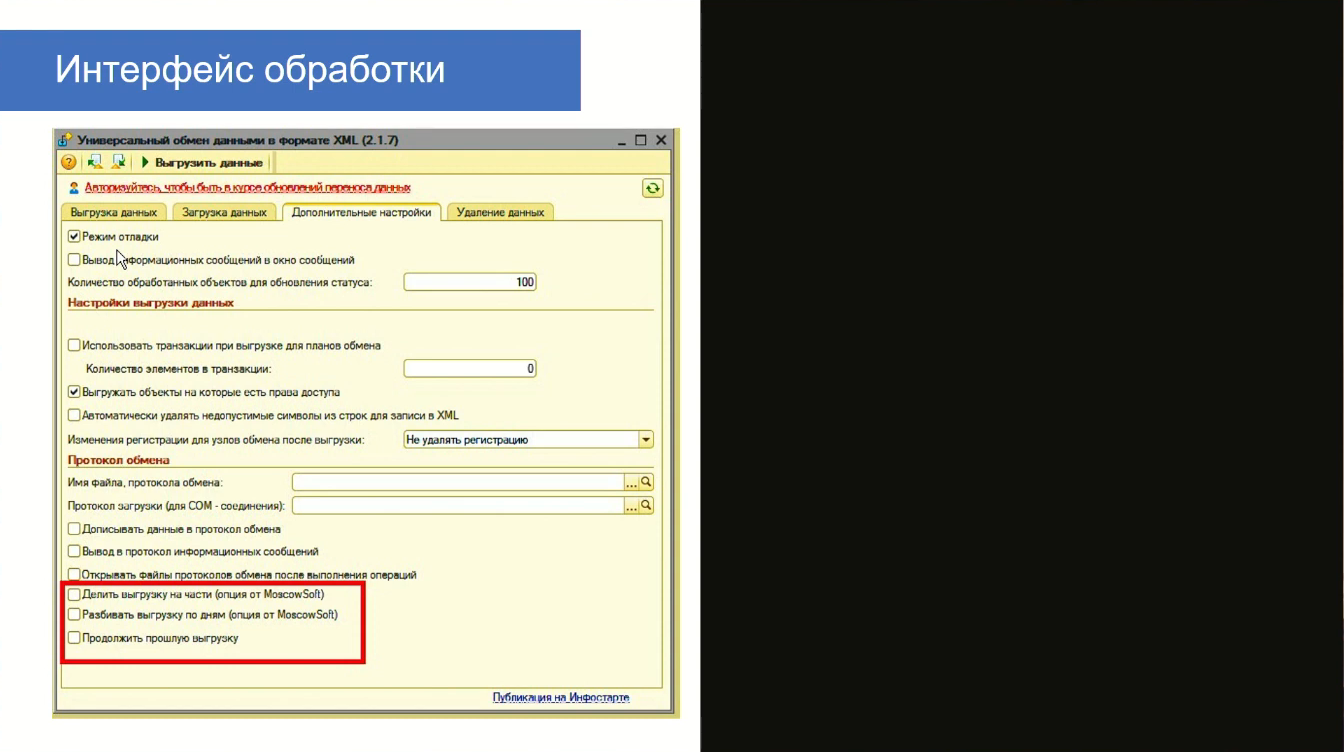
На слайде мы видим, как выглядит доработанная обработка выгрузки с возможностью докачки. В ней относительно стандартной обработки добавлен флажок «Продолжить прошлую выгрузку». А флажки «Делить выгрузку на части» и «Разбивать выгрузку по дням», как я уже говорил, были сделаны еще в 2016 году.
При сложных переходах использовать данную возможность очень полезно.
Как мы научили обработку «Универсальный обмен…» работать с RabbitMQ и зачем
Расскажу немного про сам процесс, как мы методически выполняли интеграцию «Универсального обмена на формате XML» и RabbitMQ. А потом расскажу, как мы выбирали библиотеку для встраивания.
Во-первых, из обсуждений на конференциях, в обсуждениях этой темы на Инфостарте, мы видели у коллег подход – выгружать 10 тысяч объектов в одно сообщение, которое отправляется в брокер сообщений.
Но это же методически некорректно, думали мы. Потому что эта технология создана для того, чтобы создавать много-много сообщений маленького, буквально атомарного размера. То есть корректнее выгружать по одному объекту в одно сообщение выгрузки.
Мы так и сделали. В обработке «Универсальный обмен в формате XML», в том месте, где объект уже сериализовался и сохраняется на диск, мы вместо записи на диск отправляли его в брокер сообщений.
Но помним о том, что нам перезагружают сервер, и выгрузка или загрузка данных могут прерваться. А если вспомнить, как технически устроена обработка «Универсальный обмен», то она содержит таблицу кэша для быстрого поиска выгруженных объектов при загрузке данных. И, если загрузка не дошла до конца, и мы запускаем ее заново, то в новом объекте есть ссылки на эту глобальную таблицу, а самой таблицы у нас уже нет, мы загрузку запустили заново.
Получается, у нас в брокере сообщений создались некие мусорные сообщения – объекты, которые мы сейчас загрузить не сможем. Их нужно выгружать заново, чтобы эта таблица была.
Получается, что мы снова приходим к необходимости отправлять в одной транзакции некоторое количество объектов. Потому что – какая у нас альтернатива?
-
Либо отправлять вообще все, но это неприемлемо – у нас нет такого времени, чтобы всю выгрузку выполнить, да если бы можно было, лучше бы сделали файловый ресурс.
-
То есть нам приходится разбивать все-таки на итерации и какое-то количество объектов выгружать. И мы в данный момент используем в обработке разбиение в точности такое же, как использовали при разбиении на файлы. То есть просто вместо записи файла мы отправляем сообщение в RabbitMQ и делим всю выгрузку документов либо по дням, либо по правилам выгрузки данных, то есть по видам документов – это было на прошлом скриншоте.
Таким образом мы это делаем.
Выбор библиотеки

Теперь про процесс выбора обработки для использования – расскажу, как мы к этому пришли.
-
Во-первых, при выборе мы использовали материалы, доступные на Инфостарте. Прислушивались к советам коллег на конференциях, находили доступную информацию в интернете. Это первый наш принцип.
-
Во-вторых, мы искали бесплатное решение, потому что заказчику, по сути, не нужна была регулярная обмена данными. Ему нужен был разовый технический перенос документов, чтобы опробовать возможности нового решения.
Теперь поясню, почему выбрана именно эта технология – то есть, почему, например, при выборе между Apache Kafka и RabbitMQ, мы выбрали последнего.
-
RabbitMQ оказался больше освещен на конференциях и больше представлен в статьях Инфостарта.
-
Во-вторых, по информации, которой у меня есть, Apache Kafka, при всех его преимуществах, все-таки существенно сложнее в интеграции.
Вот, исходя из всего перечисленного, у нас осталось два претендента.
-
Обработка, которая осуществляет обмен между 1С и RabbitMQ через COM.
-
И обработка PinkRabbitMQ – бесплатное низкоуровневое решение от компании ПервыйБит.
Мы смогли интегрировать в «Универсальный обмен» каждую – они обе нормально работали, по качеству, по стабильности все устраивало. Но в итоге мы остановились на последнем решении, потому что:
-
COM-компоненту приходится регистрировать каждый раз, когда вы запускаете выгрузку у нового клиента – про это забываешь, а это неудобно.
-
Native-обработка регистрируется автоматически с помощью пары строк кода. Кроме того, я хочу отметить большое преимущество обработки PinkRabbitMQ – она прекрасно документирована, устанавливается из макета буквально в две строки, и аналогично, очень проста в интеграции.
На скриншоте приведен код, как мы в цикле читаем сообщения. По сути, у нас наибольшее количество трудоресурсов ушло на то, чтобы доработать форму обработки – вывести на нее все необходимые поля (имя обмена, имя маршрута, имя очереди, выводить логин, пароль и т.д.) Это оказалось гораздо дольше по сравнению с трудозатратами на то, как встроить использование библиотеки в нашу обработку.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Post-Apocalypse.

Проверено на следующих конфигурациях и релизах:
- 1С:Конвертация данных 2.0, релизы 2.3.11.37
Вступайте в нашу телеграмм-группу Инфостарт