Мы уже убедились в том, что на 1С можно строить инструменты интеграции с крупными Enterprise-системами и различными экосистемами.
Первое, что нужно сделать для такой интеграции – это реализовать API, потому что именно API стоит между 1С и всеми прочими системами. Или между разными базами 1С.
Зачем нужен API?

Зачем нужен API? Есть же EnterpriseData, Конвертация данных, COM-соединение? К сожалению, сейчас в 1С:
-
EnterpriseData уже все наелись.
-
Конвертация данных – прекрасный инструмент, но со своими ограничениями.
-
Ну а о COM-соединении и говорить нечего.
Стандарты

Кроме реализации фронта или настройки событийной интеграции есть еще несколько кейсов, которые говорят в пользу того, что интегрироваться нужно посредством API.
Один из них – это стандарты.
Моя любимая фраза: «Лучший код – тот, который не написан. Лучшая интеграция – та, которая не разработана. Лучше всего – когда ничего делать не надо».
Видимо, я ленивый по природе, поэтому, если что-то уже сделали до нас, лучше использовать это.
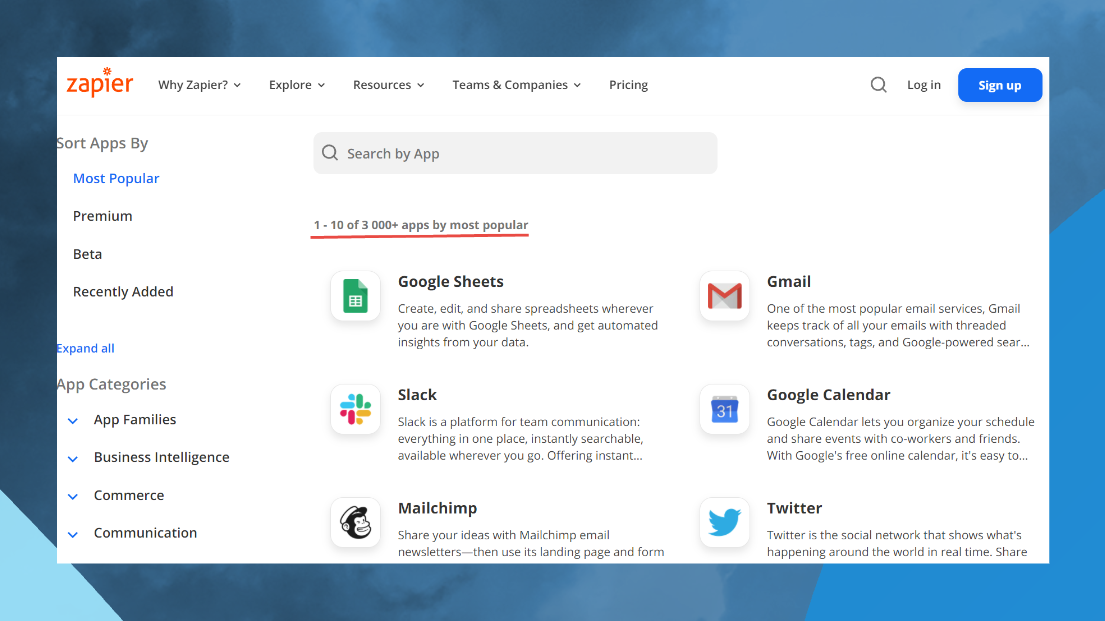
Слышали про Zapier? Если у вас есть какое-то решение, которое интегрируется с другим решением, и эти решения очень популярны – допустим, это Jira и Redmine, Jira и YouTrack – то прежде чем писать интеграцию из одного в другое, зайдите на Zapier и посмотрите, может, для них уже есть готовая интеграция (*рекомендация по состоянию на 2021-й год).
Zapier – это универсальная шина с открытыми интеграциями. Интегрирует все со всеми. Не всегда хорошо, но, чем более решение популярно, тем с большей вероятностью вы найдете для него что-то крутое на Zapier.
В базовом варианте это бесплатно, это open source, это круто. Это одна из причин, чтобы все-таки использовать REST API.
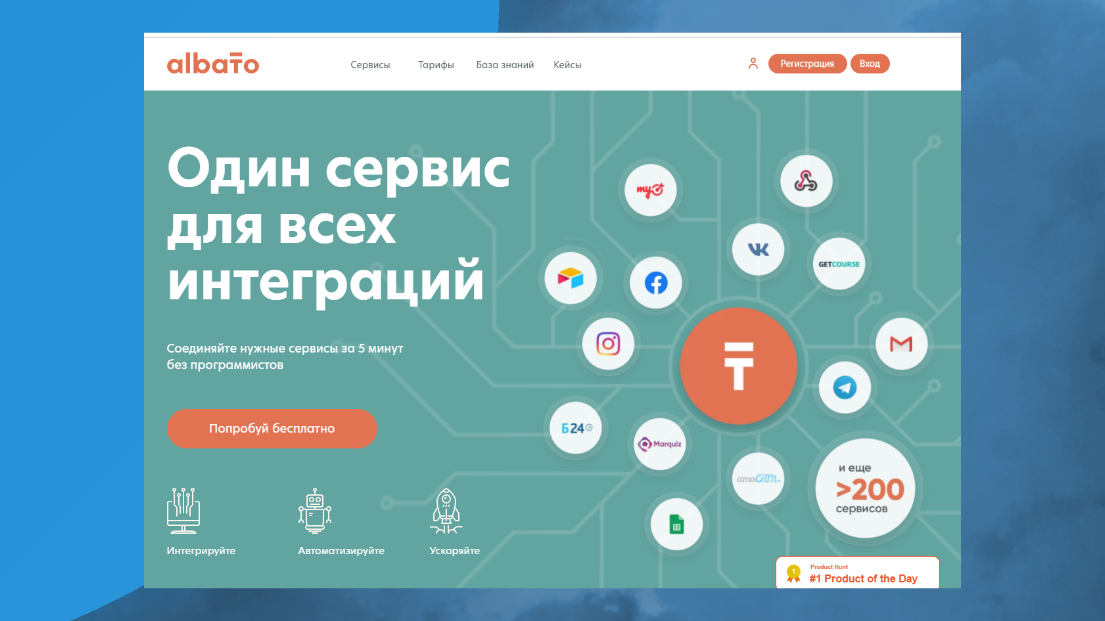
Таких сервисов как Zapier много. И если в заграничной буржуиндии популярен Zapier, то в нашей России – как пример, Albato. Я сам с ним не работал, но он, по крайней мере, выводится у нас на первых позициях в Google.
В Albato можно найти готовые варианты интеграций для наших отечественных систем, вроде Битрикс, MyTarget, AmoCRM.
1С там почему-то нет, и мне кажется, что это «самолетик» в сторону фирмы 1С – надо бы им туда со своим OData встать.
Инструменты
Интеграция через API приятна еще и тем, что есть инструментарий.

В очередной раз показываю в докладе картинку с Fiddler – им нужно уметь пользоваться.
Я регулярно на собеседование спрашиваю: «Чем отлавливать содержимое запроса, если непонятно, что пришло из сервиса в 1С?» Мало кто это знает.
С помощью Fiddler вы можете посмотреть все, что у вас гуляет по сети внутри одного компьютера, даже если данные защищены HTTPS.
Там все просто и удобно. Никакого blackbox внутри API интеграции нет, никогда не было и не будет.
Разработчиков во всем мире много, и они напилили очень много инструментов для той интеграции, которой пользуются. Например, для JS-ников прекрасный SOAP уже отошел на второй план, они больше любят REST или GraphQL.
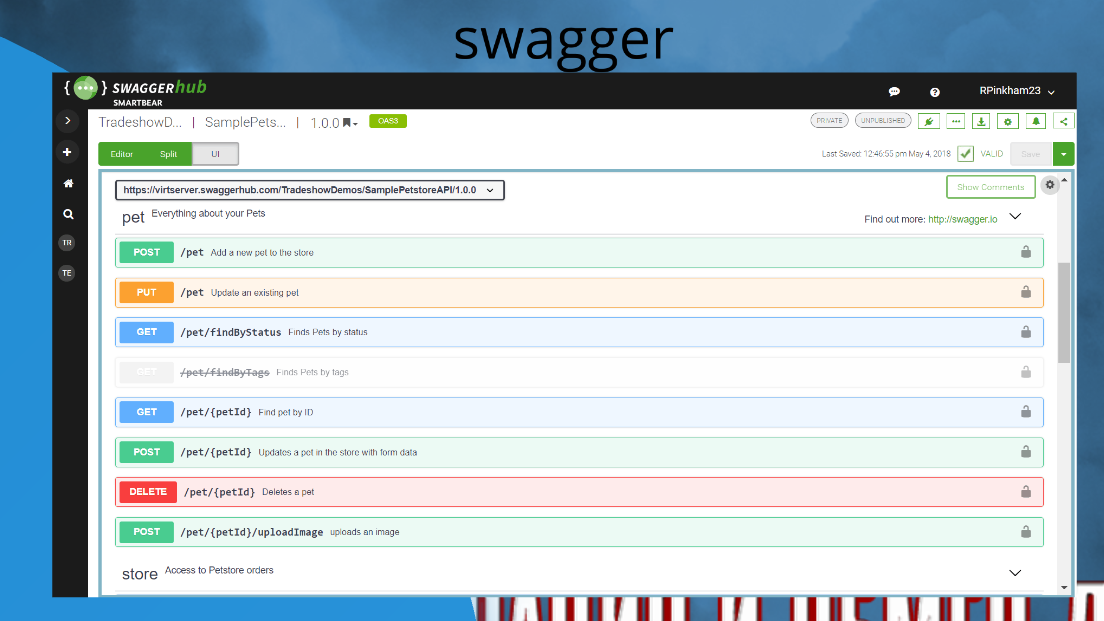
Swagger. Весь оставшийся доклад я буду говорить, что Swagger использовать не нужно, это относительно бесполезное решение. Тем не менее оно очень популярное – там удобно писать документацию, с него начинался OpenAPI. Swagger тоже надо знать.
Postman. Про него я чуть позже расскажу подробнее, мы посмотрим в сторону Postman flow.
И SoapUI – он уже не очень востребован и потихоньку уходит на второй план.
Скорость

Событийная интеграция – это очень важная история, чтобы обеспечить стабильность и скорость.
Что прикольного в событийной интеграции?
Допустим, у вас есть две базы. Из одной вы выгружаете большой XML, в другую загружаете – «Конвертация данных» с этим прекрасно справляется.
Но удобнее тот же самый XML, вернее, уже JSON, выгружать через событийку. Это когда вы кучу маленьких объектов в JSON куда-то закидываете – например, в Spark или в Kafka.
Spark удобно использовать для этих целей, потому что он легко параллелит.
Kafka – настраивается в три кнопочки.
Не нужно думать, что это что-то из мира Highload, это универсальный инструментарий, такой же, как, к примеру, файловая система.
Суть в том, что когда вы грузите один большой XML, у вас один поток его выгружает, а другой – загружает. Причем второй начнет работать только после того, как первый закончил. Это жуть, ужас, страх, потому что, во-первых, это полностью однопоточная история; а во-вторых, вы во второй системе ждете, пока первая закончит свою работу. В современном мире так делать не нужно.
Раньше говорили, что 1С не потянет событийную интеграцию, потому что там ничего не параллелится. 1С потянет все. Единственное «узкое горлышко» у 1С, которое может повлиять – это СУБД. Но СУБД PostgreSQL и MS SQL, которые поддерживает 1С, умеют записывать параллельно в несколько потоков, и делают это прекрасно. Поэтому не нужно в интеграции передавать данные последовательно – с одной системы быстро забираете, а в другую сразу пишете параллельно потоков в 50.
Все знают этот замечательный код «ОбменДанными.Загрузка = Истина». У вас там не будет блокировок. Если у вас там блокировки, значит, что-то с архитектурой не то.
Поэтому любую перегрузку можно параллелить, сколько вам влезет. Любую перегрузку можно сделать предельно быстрой, красивой, крутой.
Для этого нужно просто сделать API – читать не через XML-файлики, а просто отправлять REST-запрос в Kafka через Confluent и потом в другой системе-приемнике читать через тот же Confluent. Все. Это делается предельно просто.
Выбираем формат

Прежде чем разрабатывать API, надо выбрать формат. Я рассмотрю три.
REST

REST – это предельно простая штука, но почему-то очень много людей до сих пор не понимают, что это такое. Хотя вам, чтобы понять, что такое REST, нужно просто вглядеться в эту картинку и осознать пример, который здесь приведен с users.
Единственное, что нужно знать про REST – это HTTP-методы. Выучите их, пожалуйста, это важно.
-
POST данные пишет.
-
DELETE удаляет – если указать id-шник, удалит конкретного пользователя, без id-шника удалит всех.
-
GET без id-шника получит всех, с id-шником получит одного.
Конечно, для обмена через JSON есть еще RESTful (REST без состояния), где есть дополнительные правила для HTTP-кодов ответов. Но на поверку это никто не соблюдает, кроме тех, кто что-то мегасуперское пишет.
Но обычные правила REST для HTTP-методов нужно запомнить, и HTTP-сервисы делать нормальными, человеческими, адекватными.
GraphQL

Страшный GraphQL из какого-то другого мира. Ничего подобного, GraphQL прекрасный.

GraphQL подойдет 70% из вас. Вы можете легко развернуть у себя GraphQL и использовать. Вам это понравится.
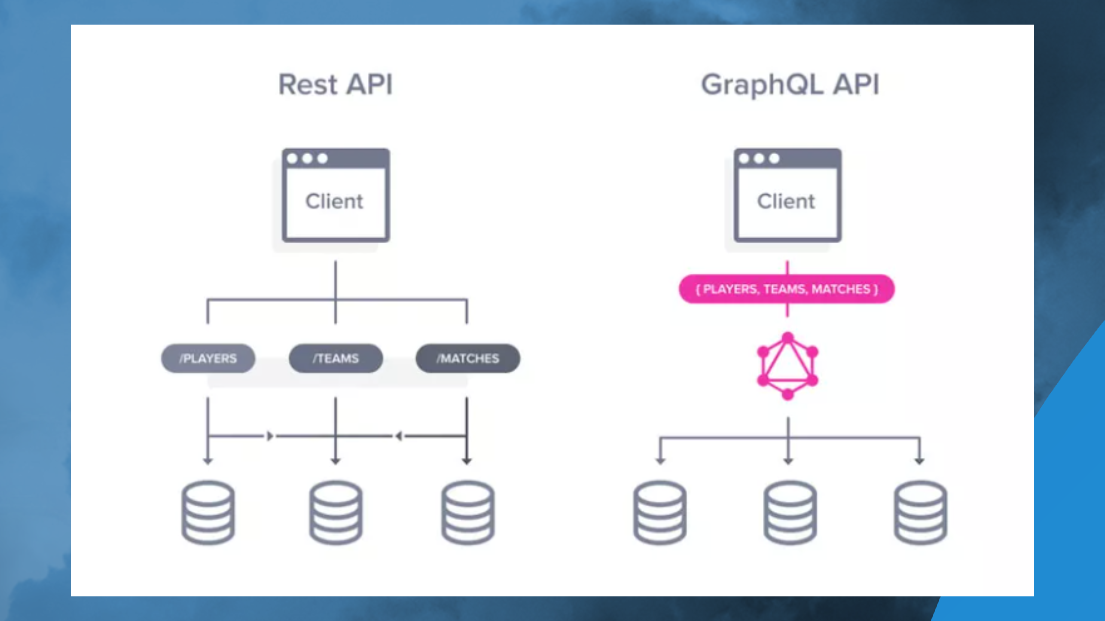
GraphQL отличается от REST одной простой штукой – он добавляет в процесс обмена некое подобие middleware, т.н. GraphQL-сервер.
У нас в WiseAdvice на практике работа с GraphQL не обкатана, потому что мы используем MuleESB, который эти вопросы решает, нам GraphQL не так принципиален. Но если у вас никакого middleware пока нет, GraphQL – прекрасная история.
Хотя GraphQL – это не совсем middleware в полном смысле. Для чего нужен?
Например, если вам нужно выбрать из базы данные таблиц Matches, Teams и Players, 80% фронтендеров не будут заморачиваться – они получат JSON-данные по каждой из этих табличек отдельно, потом сделают мэп и будут это дело джойнить на фронте. Это плохо, потому что нужно обработать три HTTP-запроса. А если у вас медленный интернет по HTTP 1.1, вам требуется установка соединения, обмен с сертификатами, хендшейки – вся эта байда вам в десятки раз удлинит ответ сервера, клиенты будут ждать.
А GraphQL: во-первых, заставляет фронтендеров работать по-человечески, а во-вторых, позволяет все это дело передать за один запрос.
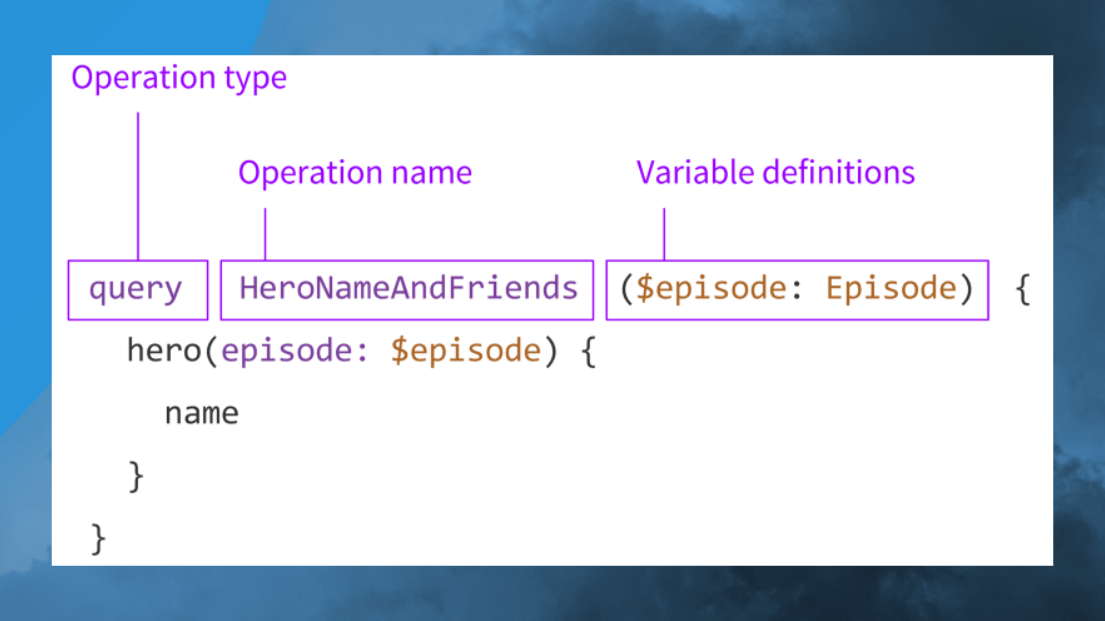
Вот так устроен GraphQL – запрос, операция, параметры. Детально на этом останавливаться не будем.

Теперь самое большое внимание – как быть с 1С. Страшный GraphQL. Что нам делать?
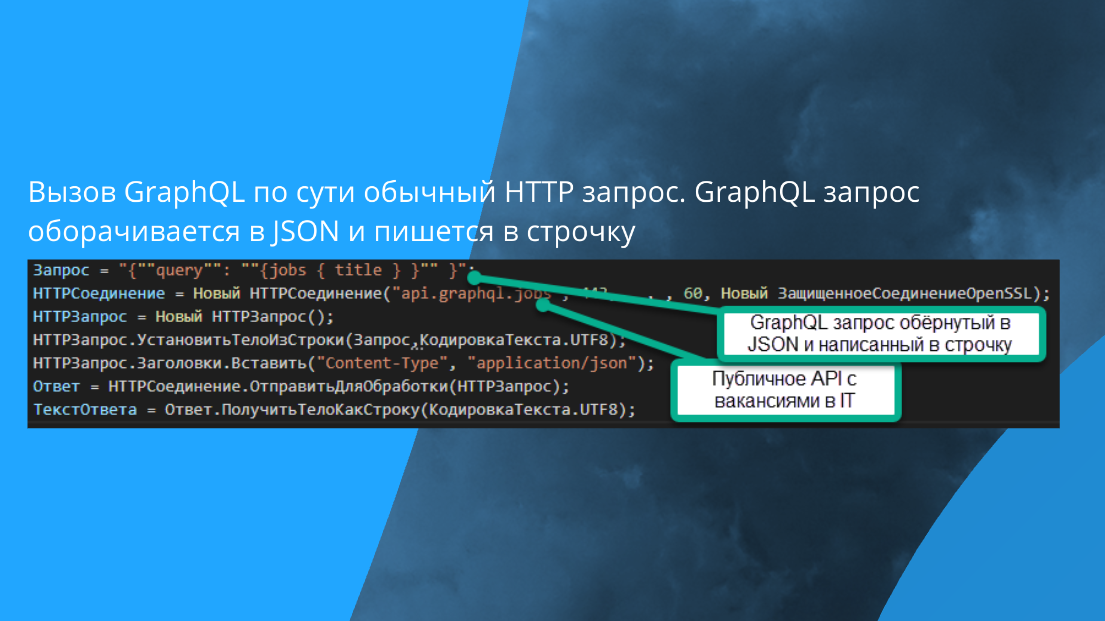
Вот так выглядит вызов GraphQL из 1С. Вам достаточно написать этот код, и вызов GraphQL прекрасно заработает. От обычного HTTP-запроса отличается только тем, что там query написан.
Формат запроса в GraphQL выучивается за 15 минут – и, пожалуйста, вы прекрасно можете использовать GraphQL.
Тут, кстати говоря, еще открытый сервер указан на получение вакансий для американских стартапов. Вызывается легко. 1С в качестве клиента GraphQL может работать легко.

В качестве сервера 1С тоже работает беспроблемно. Тут, где указан REST API, может быть 1С, поскольку 1С экспортирует REST API вообще без проблем – это либо OData, либо любой другой REST API, который вам нравится.
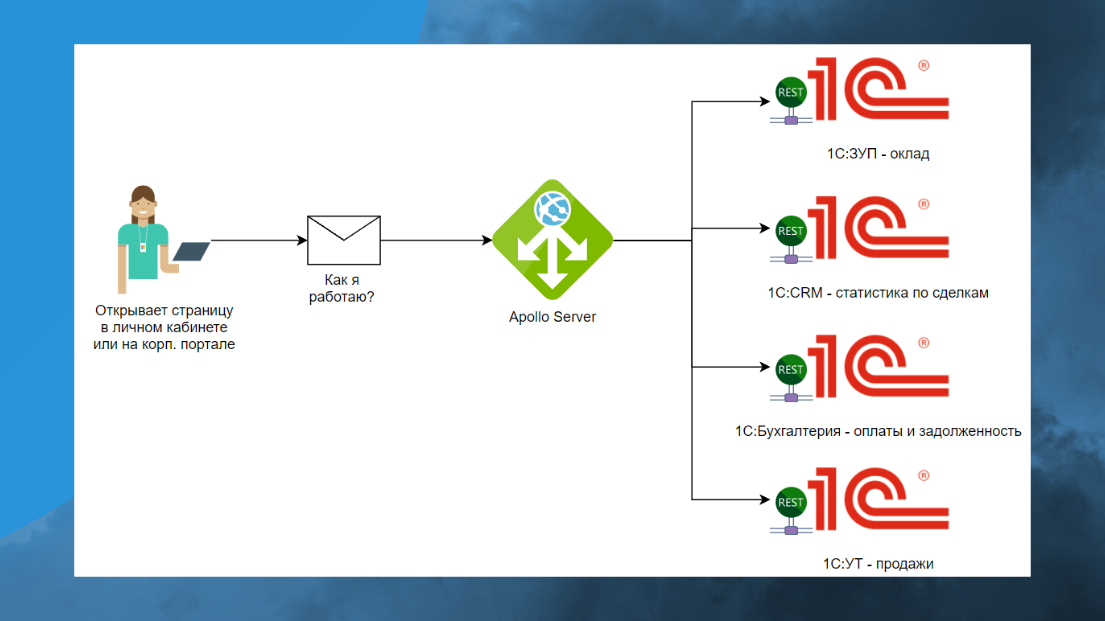
Покажу кейсы, где это используется.
Например, вы делаете какой-то портал, куда стекаются данные из других систем. Это простая классическая задача – вам нужно сотруднику дать информацию о том, какую премию он получит по итогам месяца.
Для этого вам нужно:
-
Залезть в 1С:ЗУП, взять оклад.
-
Потом залезть в CRM, получить статистику по сделкам.
-
Проверить оплаты в Бухгалтерии.
-
И потом еще в УТ получить его продажи.
Чаще всего, все те же самые решения могут быть не на 1С, но сам бизнес-процесс это не меняет.
Что сделает 1С-ник из 90-х? Он здесь сделает для базы портала еще одну отдельную 1С-базу и будет к ней писать запросы – дай бог, если еще REST-овые.
На самом деле ставится Apollo-сервер, публикуются отдельные HTTP-сервисы, и все.
Одним запросом вы получаете все необходимые данные, отдаете их фронтендеру, либо сами рисуете простенькую табличку на экране, которая все это дело отображает.

Мы все любим практику. Я подготовил специальный GitHub-репозиторий с примером обращения к 1С через GraphQL, куда выложил:
-
готовый GraphQL-сервер, в который нужно будет написать три строчки кода;
-
и простенькую маленькую 1С, которую нужно развернуть на веб-сервере, чтобы она отвечала на HTTP-вызовы.
Запуск этого примера занимает 10 минут. Если учесть, что EDT будет запускаться долго, то, наверное, минут 15 ?.

Здесь показано, как это будет выглядеть.
На веб-сервере публикуется база 1С с HTTP-сервисами, чтобы можно было получать данные по REST.
Ставите Node.js, разворачиваете GraphQL-сервер на localhost:4000, и можете делать запросы к 1С – он вам покажет описание всех полей, всех схем. Все, что экспортируется, там отображается.
Выполнили запрос – получили результат.
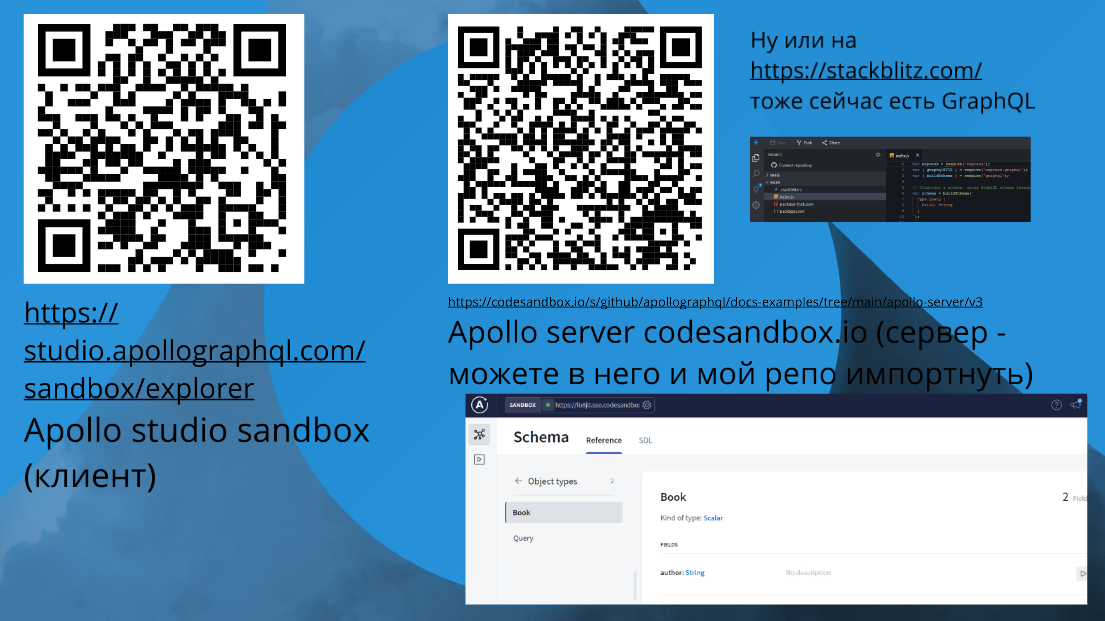
Если вам лень ставить Node.js, можете попробовать эти решения:
-
По ссылке https://studio.apollographql.com/sandbox/explorer вы можете скачать GraphQL-клиент,
-
А здесь – прекрасный codesandbox https://codesandbox.io/s/github/apollographql/docs-examples/tree/main/apollo-server/v3/getting-started – сервер, куда вы можете и мой репозиторий клонировать, тогда вам даже ставить ничего не надо.
Еще есть https://stackblitz.com/ – ничего не напоминает? Похоже на 1С:Элемент. По-моему, форк от VS Code в вебе не сделал только ленивый.
gRPC

Еще один протокол – gRPC. С ним будет немного сложнее. Это некая более модная штука.
Если GraphQL это примерно то же самое, что и Rest, то gRPC чуть посложнее. И тут, конечно, с 1С будут проблемы.
Но gRPC быстрее работает.
-
Там HTTP/2;
-
там Protobuf;
-
там Service Mesh;
-
и кодогенерация «из коробки».
Но с 1С будут проблемы, потому что gRPC нужен прежде всего, чтобы все выполнять быстро, а быстро это можно выполнять за счет HTTP/2 и Protobuf.
С 1С, как вы догадались, нам придется все оборачивать в HTTP интерфейс.

Если в 1С надо быть клиентом gRPC, это не проблема – ставится прокси https://github.com/grpc-ecosystem/grpc-gateway. Это за 15 минут разворачивается.
А с сервером 1С, как с сервером gRPC, так просто не получится. Хотел сделать какой-нибудь компонентик универсальный, но универсального не получается, потому что все-таки это RPC, у вас должна быть определена функция, функция должна быть observable.
Получается, что для каждого кейса нужна отдельная ВК для сервера gRPC, которую вы сами должны будете написать.
В общем, с 1С это не самая приятная история. Надеюсь, что когда-нибудь нам в платформу 1С завезут поддержку gRPC, тогда мы будем сами экспортировать через gRPC, потому что через него, конечно, работает быстрее.
Описываем
Окей. Закончили с хипстерскими штучками. Давайте пойдем в описание.
OpenAPI

Если у вас есть API, но он не описан – у вас нет API. Эту фразу надо уловить и усвоить.

Для описания API есть официальная спецификация OpenAPI, которая размещена по ссылке https://spec.openapis.org/oas/latest.html.
OpenAPI – это не Swagger. Swagger использует спецификацию OpenAPI и это – правильная история.
Для REST – это, пожалуй, единственное, что нужно сделать. Если вы все-таки в GraphQL не идете, потому что у вас одна база, то, пожалуйста, возьмите и опишите API по OpenAPI. Это делается быстро.

Для этого используются классический YAML. Кто пугается YAML – не пугайтесь.
YAML пишется быстро, Postman вам подсказывает, как его писать.
Документация к API нужна, чтобы им кто-то пользовался. API вообще пишут для того, чтобы кто-то пользовался. Если API не задокументирован, считайте, что вы его не написали.
Еще Ада Лавлейс говорила: «Если ваша работа не задокументирована, то вы не работали».

В WiseAdvice мы прекрасно используем документацию в стандарте OpenAPI – зашло прям очень хорошо почти во все команды.
Если бы не отдельные глюки Postman, зашло бы вообще прекрасно.
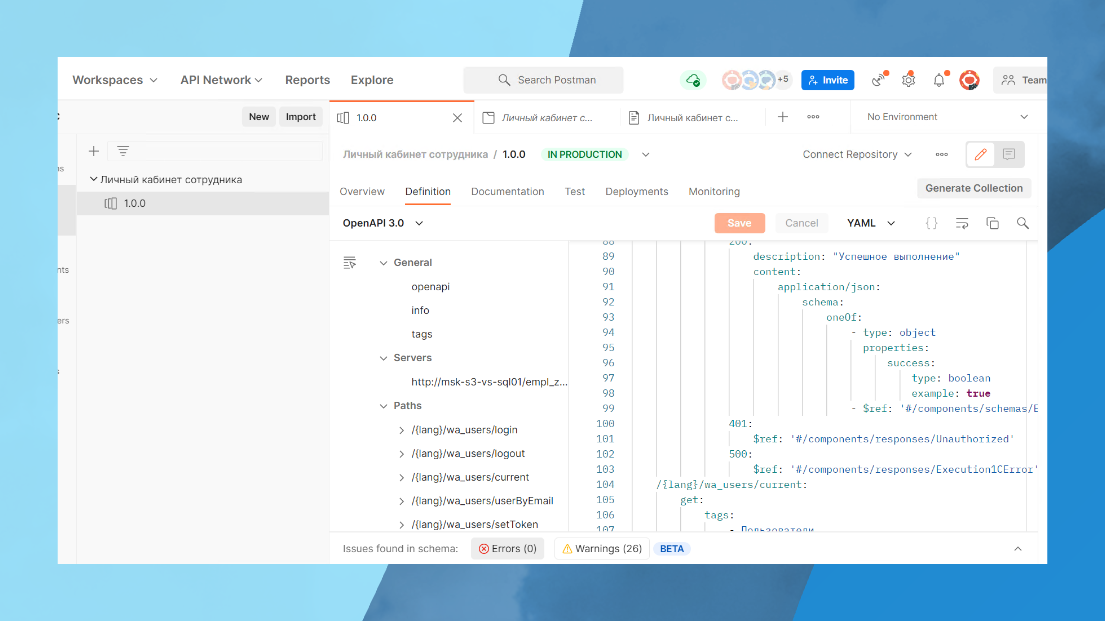
На слайде – живой пример, как это выглядит.
Видно описание по компонентам – мы можем какие-то коды возврата описывать.
Причем это делали ребята, которые практически не знали, что это такое. Они за полчаса сели и выучили. Потом по этому генерируется документация.

Внимание, документацию к API можно сразу сгенерировать автоматически и выложить даже вовне, если с вами интегрируются ваши клиенты, партнеры, поставщики.
Выглядит прекрасно. С примерами, с cURL, с описанием о том, какие JSON принимает, какие генерирует.
Причем, все это дело человек не писал руками. Человек просто писал схемку.
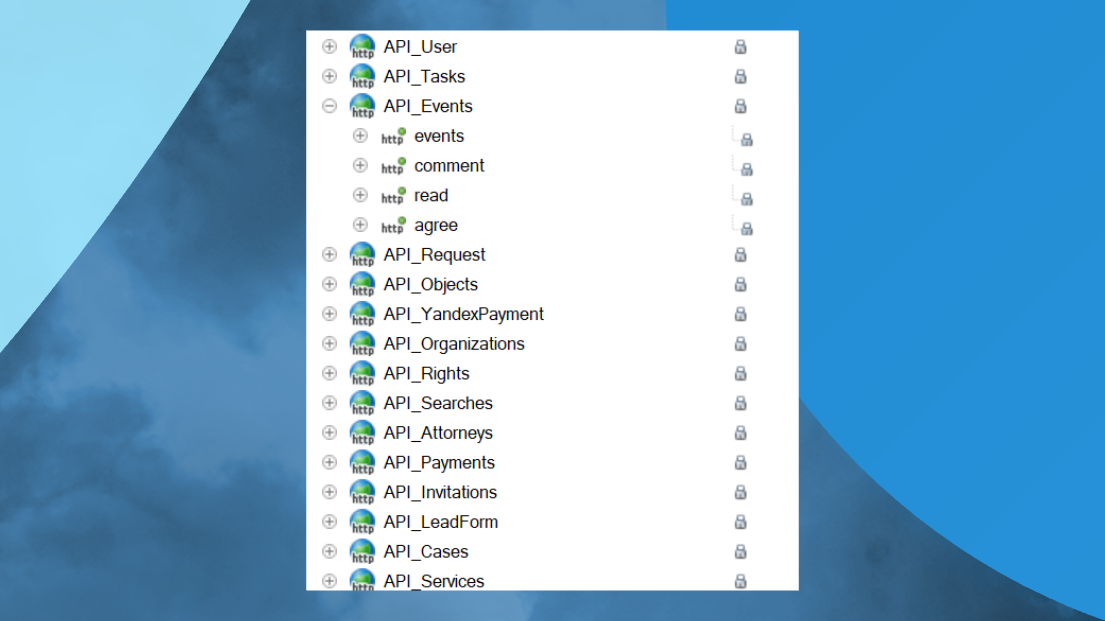
Вот так это потом выглядит в 1С.
Чтобы API выглядело по-человечески, оно должно выглядеть вот так. По крайней мере, один сервер.
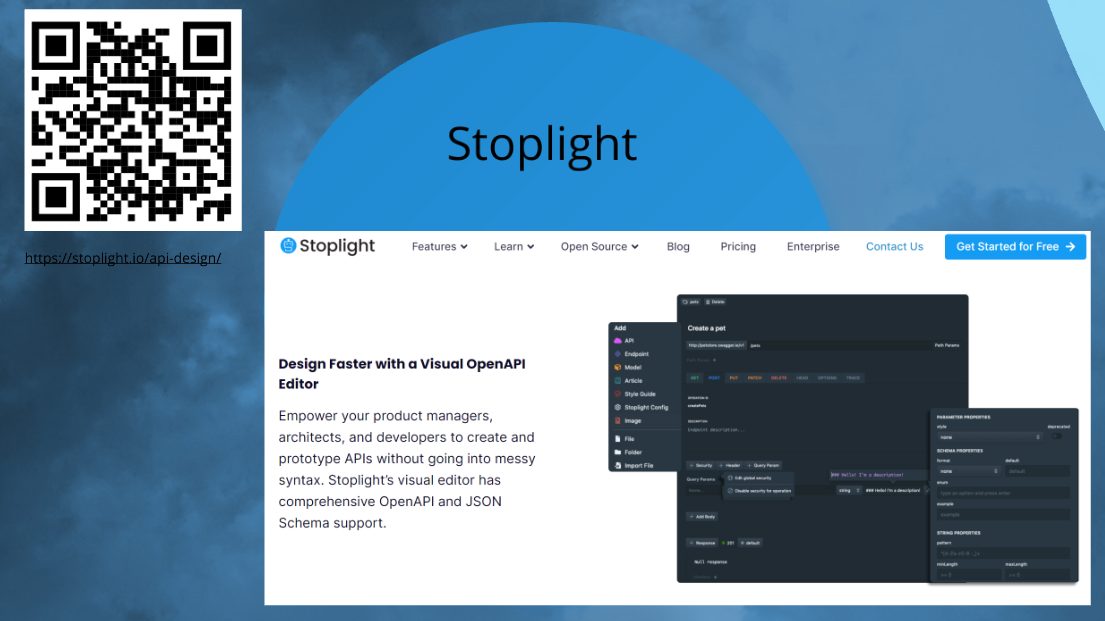
Мой любимый слайд для ленивых. Если прямо не хочется в YAML писать схемки, есть замечательная тулза Spotlight https://stoplight.io/api-design.
В базовом варианте она бесплатная, и вам этой бесплатной функциональности хватит. Визуально API можно сформулировать там.
Публикуем. API Gateway
Окей. С описанием разобрались. Теперь публикация. API Gateway.
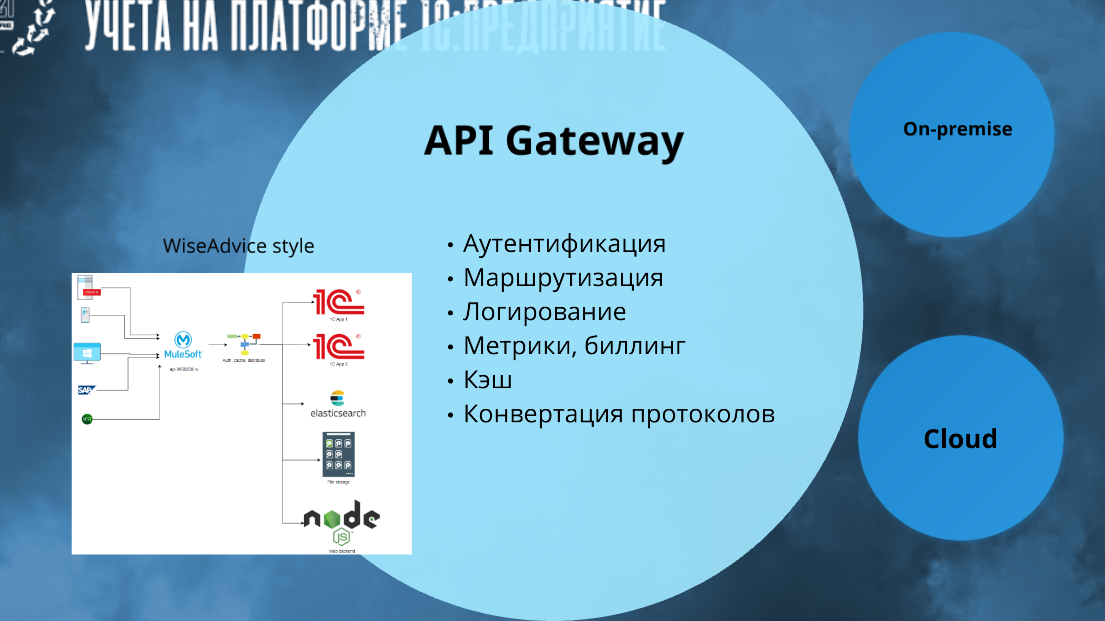
Когда вы делаете много разных API, у вас для них в любом случае есть общие функции, например:
-
Любой API у вас должен маршрутизироваться.
-
API должен логировать вызовы, которые были, если вдруг потом нужно будет расследование ошибок.
-
Если вы этот API еще и продаете, как какой-нибудь HeadHunter, вам его нужно билить.
-
Должна быть авторизация и логирование – чаще всего общие.
-
Защита от DDoS.
-
В случае, если у вас по API отдаются статические данные, вам API нужно кэшировать.
Все это делается через API Gateway.
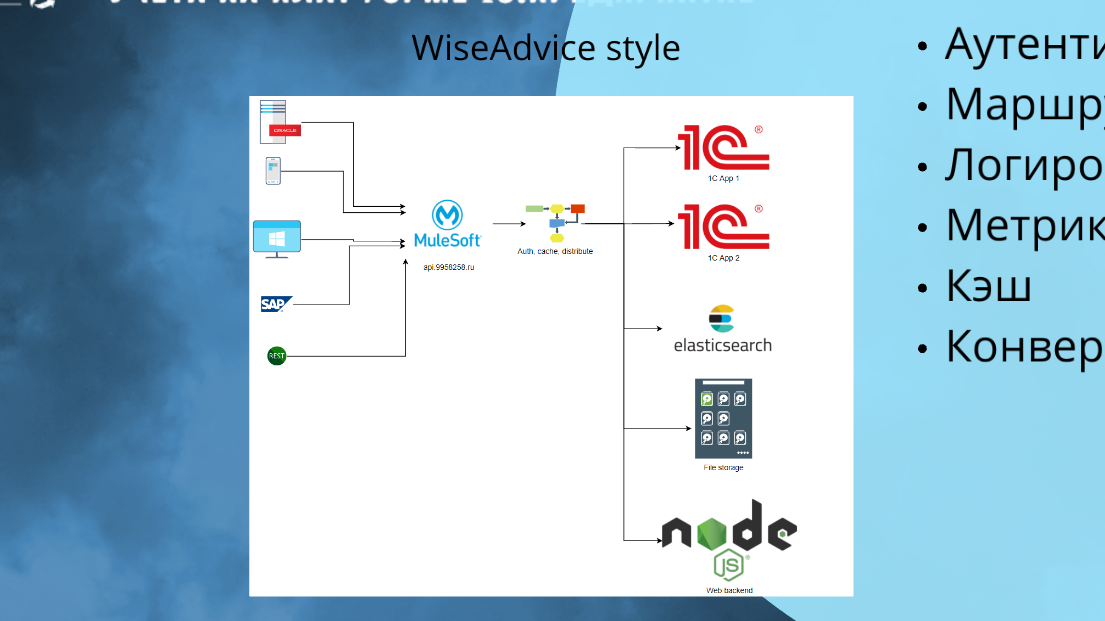
В WiseAdvice функцию API Gateway выполняет MuleESB. Он выполняет все те же самые функции – мы там и аутентифицируем, и защищаемся от DDoS, и кэш встраиваем. Много служебных функций, которые общие для всех API, происходят именно там.
А дальше он маршрутирует. Часть может пойти в Elastic, часть файлик с хранилища забрать. Есть какой-то бэкэнд на ноде, он может оттуда его отдать. И с 1С-ных приложений тоже что-то забрать.
On-premice API Gateway services

API Gateway есть и опенсорсные, их много.
-
Самый популярный, наверное, это Kong (тот, который с гориллой)
-
Мы у себя используем в качестве API Gateway MuleESB.
-
Тук тоже популярный.
-
Остальные тоже можете посмотреть:
Облачные API Gateway
Если вы решились использовать облачную инфраструктуру, там организовать API Gateway еще проще. В каждом клауде есть свой API Gateway.
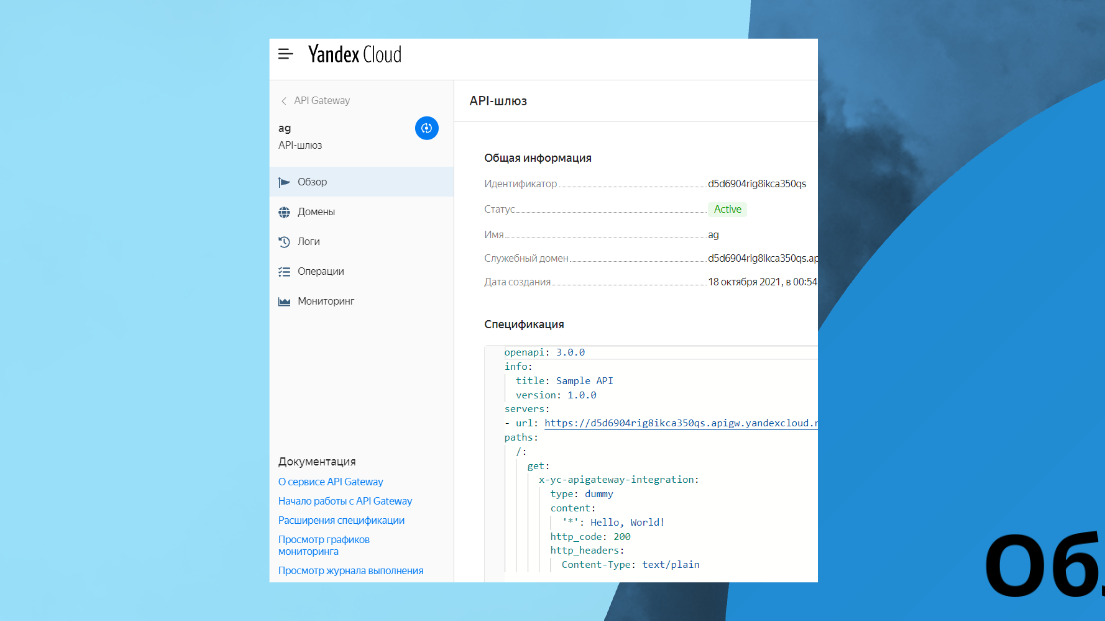
Вот так это работает в Serverless Яндекс облака.
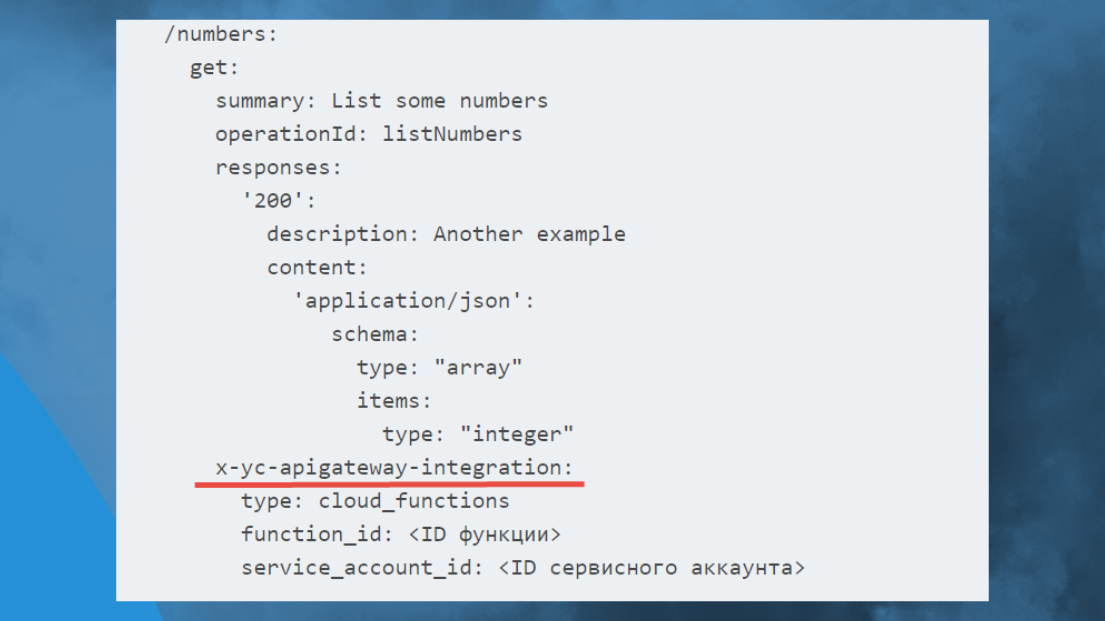
Это такой же Open API: просто схемка, только в одном прекрасном месте вы указываете расширение от Яндекс, к примеру, и говорите, что вот этот метод API вызывает ту функцию Serverless.
То есть вы просто написали код, и у вас все работает – больше ничего не нужно.
Описали API в OpenAPI, написали клауд-функцию и вот оно готовое приложение развернутое и масштабируемое.
Когда-нибудь, я надеюсь, в Яндекс OneScript все-таки доделают и будем вызывать на OneScript.
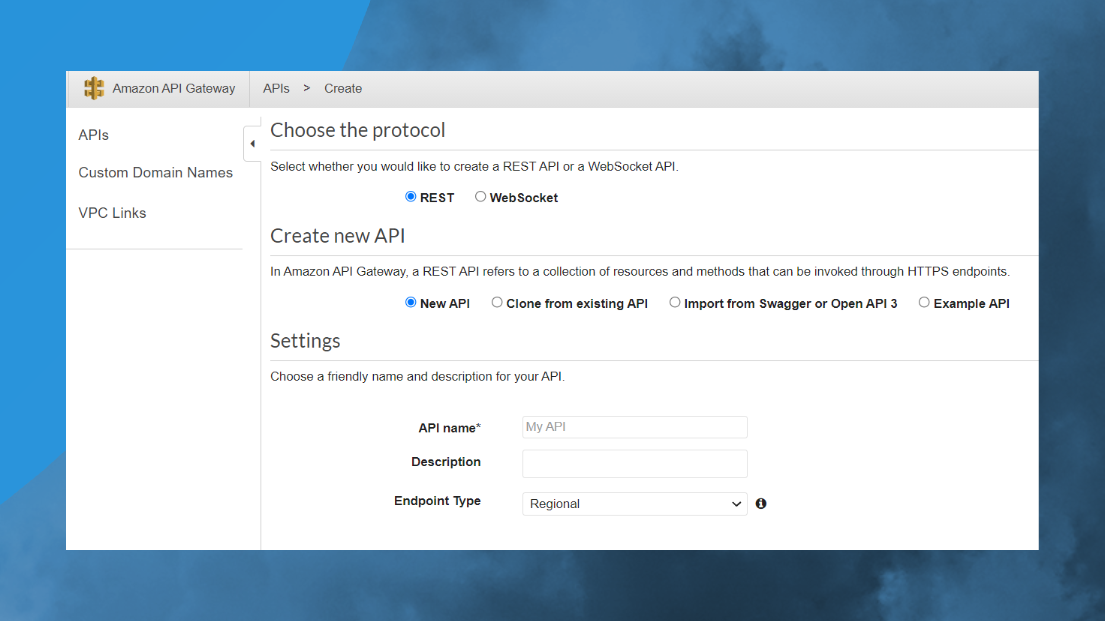
В Амазоне этого чуть побольше, конечно.
В Амазоне, в принципе, Serverless более продвинутый, там с этим поприятнее.
Тестируем
Перейдем к нашей главной теме – тестирование.
Именно ради тестирования мы изначально замутили у себя эту тему с описанием API. Не для того, чтобы его описать, хотя, конечно, описать API крайне важно. А во имя того, чтобы API сразу было покрыто тестами.

Тестирование – это важная история для устойчивости вашей системы.
Изначально я это называю Postman flow.
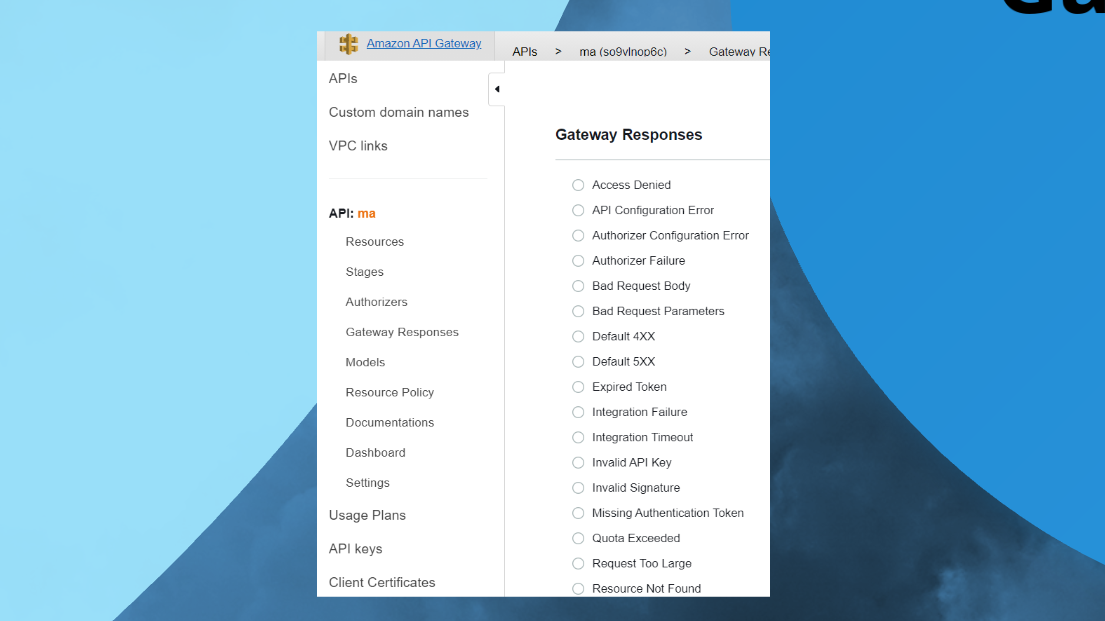
Когда вы ставите Postman, у вас в одном приложении содержится:
-
Общая информация API.
-
Здесь же вы можете его определить, YAML написать.
-
Здесь же вы можете потом сгенерировать документацию.
-
Сгенерировать тесты.
-
Настроить деплоймент этого всего API.
-
И еще мониторинг повесить.
Прекрасно. Все, что для API нужно, у вас есть в одном месте, в одном тулзе с коллективной работой.
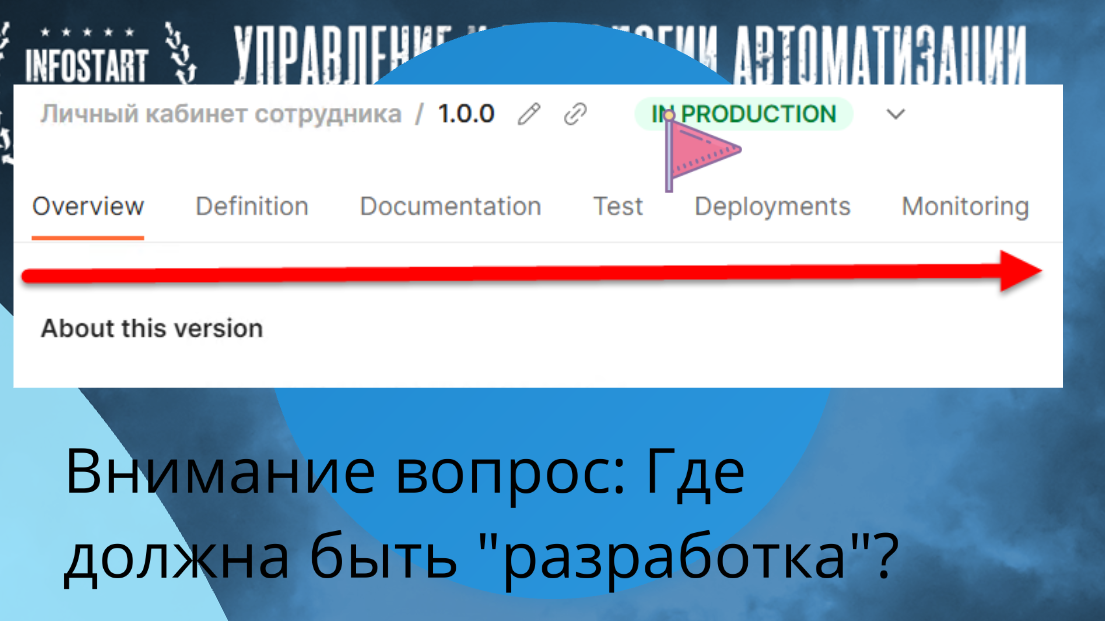
Здесь нет только разработки – разработка у нас в 1С.
Куда бы вы вставили разработку в этом flow? Перед тестами или после тестов? Правильно – после тестов.
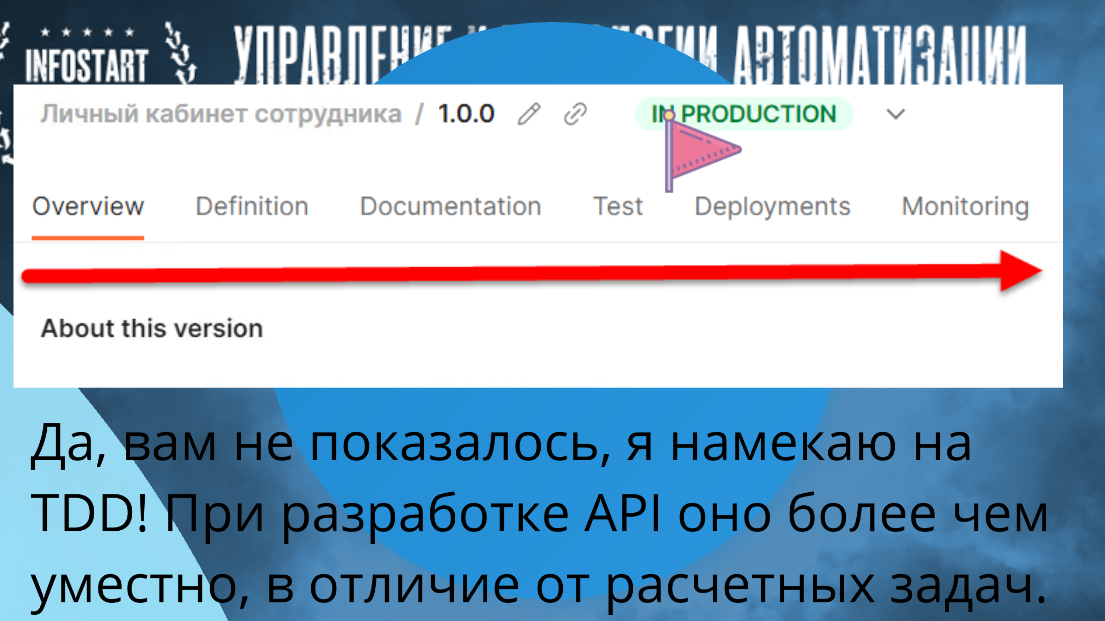
Кто меня знает, тот слышал, что я всегда был противником TDD.
Не надо через TDD разрабатывать отчет на СКД. Это low-code разработка.
Не надо через TDD разрабатывать какую-нибудь интерфейсную механику. TDD – это дикий overhead для таких задач.
Для API TDD – это must have. Это нужно. Без TDD API ну так себе. Вас Postman заставит TDD сделать.
Знаете почему? Ключевая история. Вот вы 1С-ник и вы сделали API для фронтендера либо для 1С-ника с соседней базы. Сделали API, описали его методы.
Дальше вы разворачиваете mock-сервер (тестовый сервер с заглушками для интеграционных методов) и говорите своему коллеге в него стучаться, чтобы получить тестовый пример.
Этот же mock-сервер содержит экземпляр возвращаемых данных – то есть, у вас уже есть готовый тест.
Дальше вы пишете просто реализацию этого теста, которая сверяет то, что приходит на вход с тем, что вы ожидаете.
Как только сверились, разработка закончена, меняете среду разработки на продакшен и отдаете вашему фронтендеру. У вас готовое приложение. Бинго.
Чтобы описать API для фронта либо для соседней базы, TDD – это крайне важный и полезный инструментарий, он сюда заходит просто на ура. Особенно с Postman.
Возможности Postman

Чтобы не загонять совсем что-то абстрактное, вот так Postman выглядит.
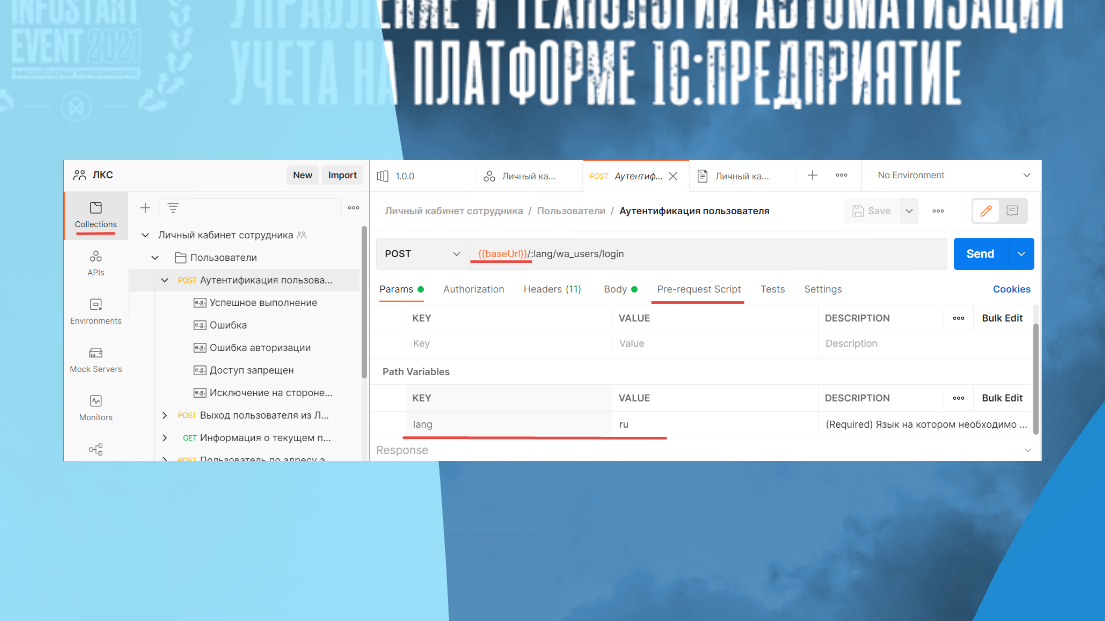
Можно писать pre-request скрипты, если хотя бы чуть-чуть JS владеете. Не надо прям быть богом JS, надо уметь if-then написать.
Можно подменять всякие юрлы, чтобы развернуть себе отдельный environment.
У вас есть все тесты, вы можете сразу протестить, как ваше API отработает с вашей базой.
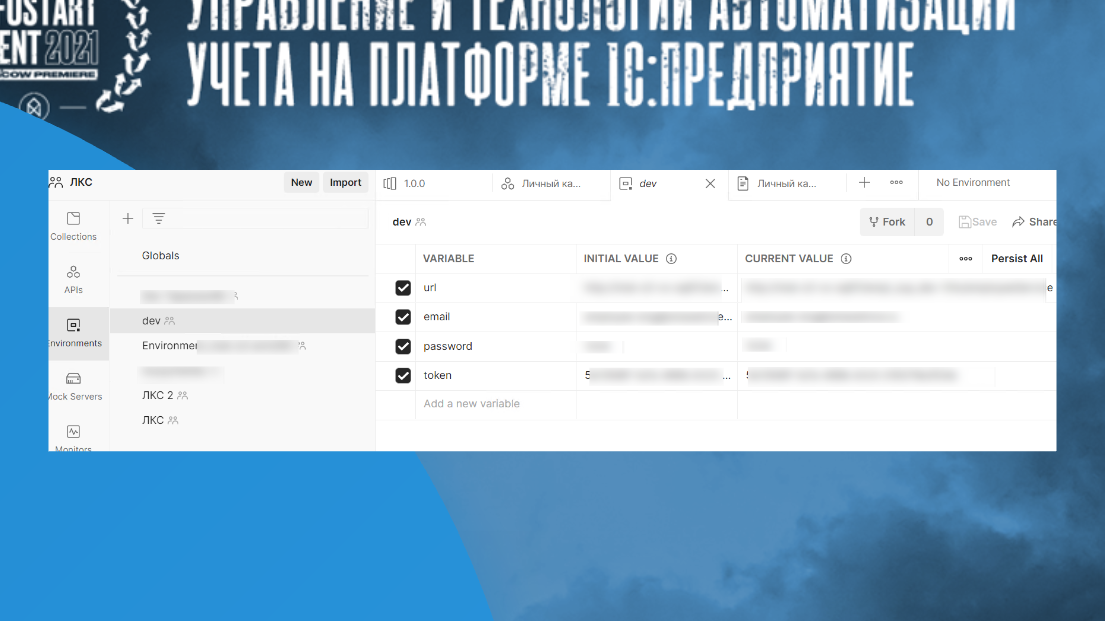
Каждый разработчик создает себе environment, говорит: «Стучись в мою базу с такими-то credentials». А потом просто переключается и все прогоняет у себя – тестит, отлаживает, делает все, что ему нравится.
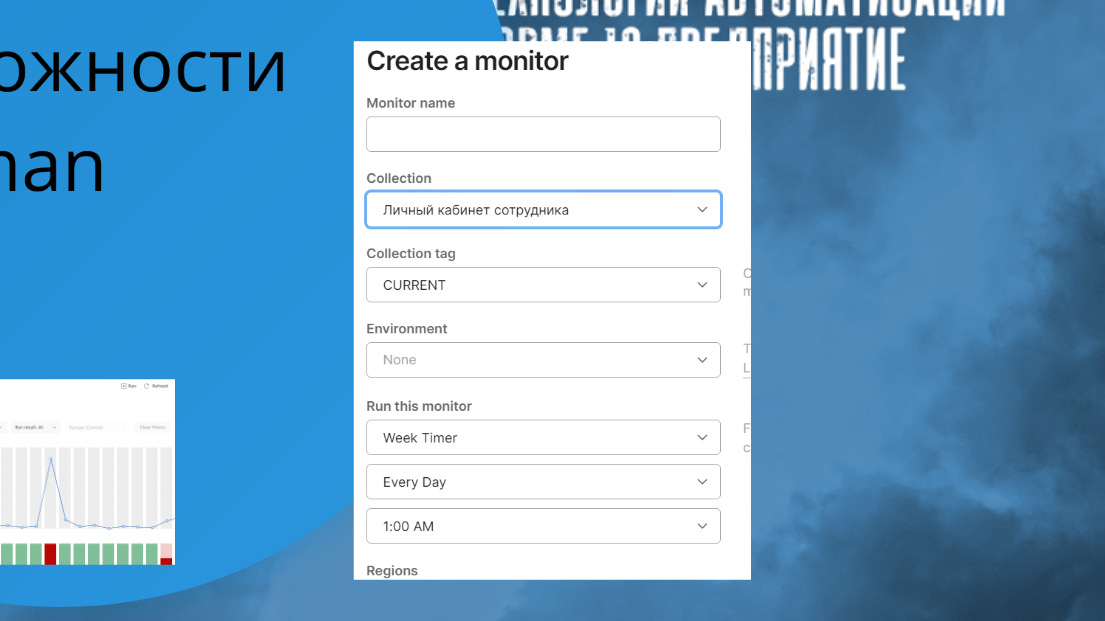
Можно настроить мониторинг API.
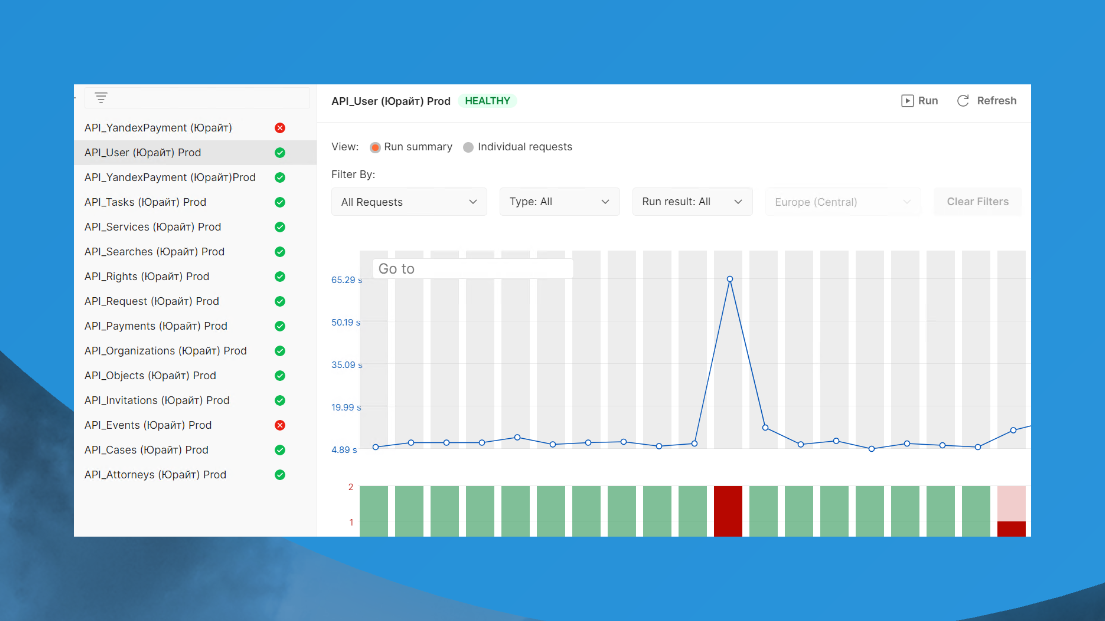
Мониторинг выглядит вот так.
Представьте, вы закончили разработку API, взяли тот же самый тест и настраиваете для его регламент выполнения – каждую минуту. И у вас каждую минуту Postman со всех сторон мира стучится в вашу 1С, спрашивает – ну что, как, работает? Работает хорошо?
Если вы в тайминг не уложились или ответ не тот вернули, вам сразу напишут телеграмм, что ваш API не работает или ваша 1С упала. Вы сразу все об этом узнаете. Причем для этого не надо ничего делать – Postman сам за вас все делает. Вам нужно просто написать API и сделать экземпляр тестов.

Mock-сервер. У вас фронтендер не ждет, пока 1С-ник закончит работать, а работает сразу.
Newman в Gitlab CI
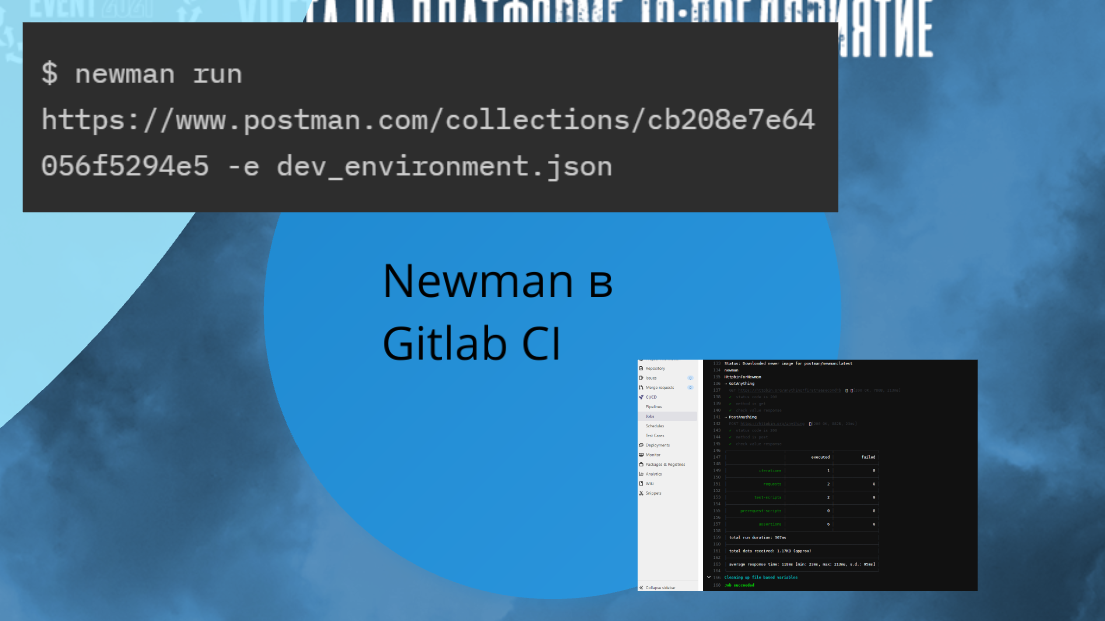
И последняя, наверное, история, которую еще хотел осветить, это Newman.
Если бы все это дело не встраивалось в CI-контур, его ценность была бы меньше. CI-контур нужен всем. Любой API в любой базе 1С должен разворачиваться и проходить тесты автоматически.
Пусть база будет разворачиваться не автоматически, но хотя бы тестирование в предпродакшн сделайте автоматически. Это настраивается за полчаса, опять же.
Newman — это консольный клиент Postman. У Postman есть коллекция, вы ее просто экспортируете и говорите, что по этой коллекции с таким-то environment нужно прогнать все тесты, которые там есть. И тестируете так каждый раз, когда выкатываете новую версию.

Встраиваете Newman в свой GitLab CI, он запустится и покажет вам результаты прохождения всех тестов.
Обязательно попробуйте этот инструментарий в работе, потому что все это действительно вещи крутые, прикольные, позволяют быстро сэкономить время на том же MVP.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Moscow Premiere.

Вступайте в нашу телеграмм-группу Инфостарт