Когда заходит речь про оптимизацию тяжелых запросов, разработчик рано или поздно приходит к мысли: «Хорошо, у меня есть план запроса. Это – красивая картинка с кучей каких-то непонятных символов, объектов. И что с этим делать дальше?».
Вроде мы много раз слышали, что именно в плане запроса скрыты все нюансы поведения системы, и изучив план, можно разобраться, в чем именно заключается проблема запроса. Но как к нему подступиться?
Как выполняется план
Прежде чем мы поговорим о том, куда смотреть в плане и как его анализировать, давайте разберемся, что такое план в принципе, и как он выполняется.
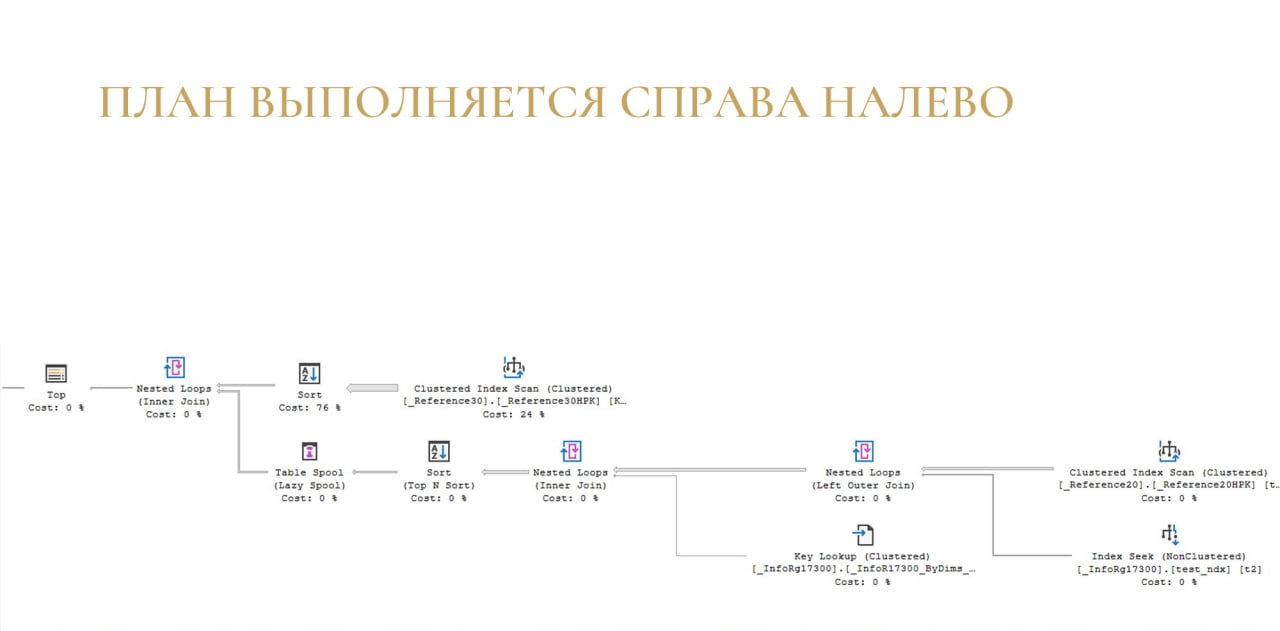
Обычный план на MS SQL выглядит примерно так, как на слайде. Это большое дерево, на котором много объектов. Это дерево - инструкция, что нужно сделать, чтобы получить результат запроса. Операторы в плане вызываются по порядку слева направо (с левого верхнего угла), а данные в плане перемещаются справа налево. Сейчас подробно разберём, как это работает.
Каждый блок на слайде – это оператор, который что-то умеет.
У каждого оператора есть несколько методов, но самый главный из них – Next(), который возвращает одну строку.
Следующий оператор его спрашивает: «Дай строку» и тот отдает. Если надо еще, то снова: «Дай строку» и т.д. И так по одной строке любой оператор выдает вот эти строки.
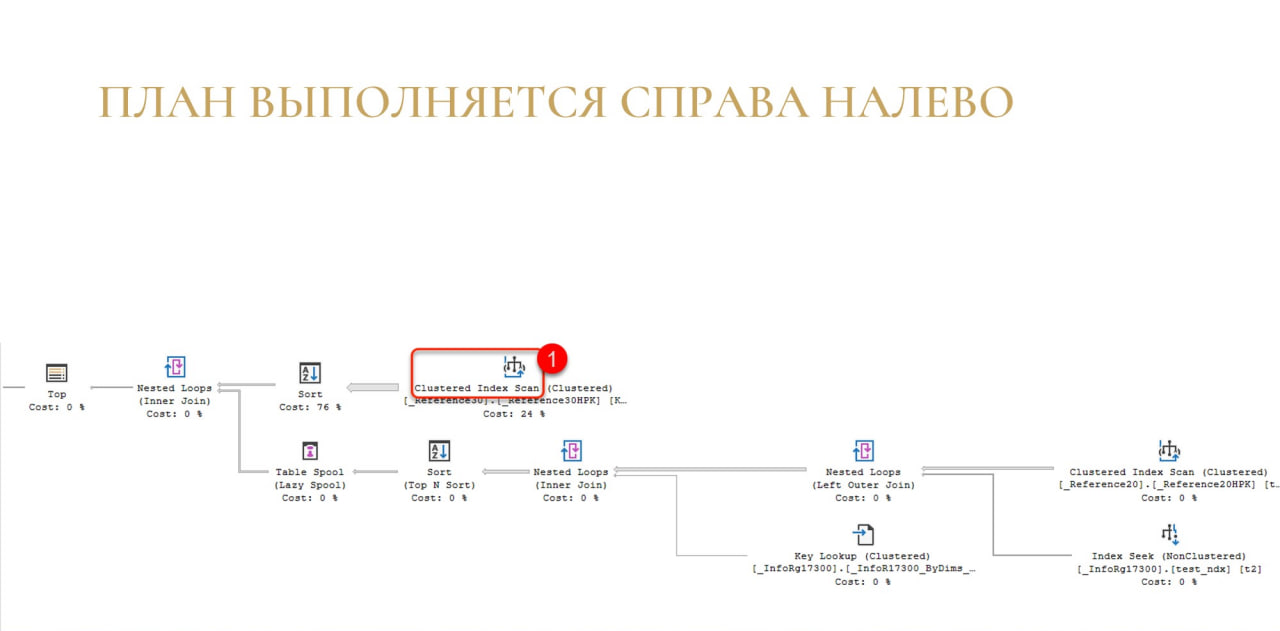
Например, Index Scan отдал строку оператору Sort.
Потом Nested Loops спрашивает у оператора Sort: «Дай строку» – тот ему строку отдал.
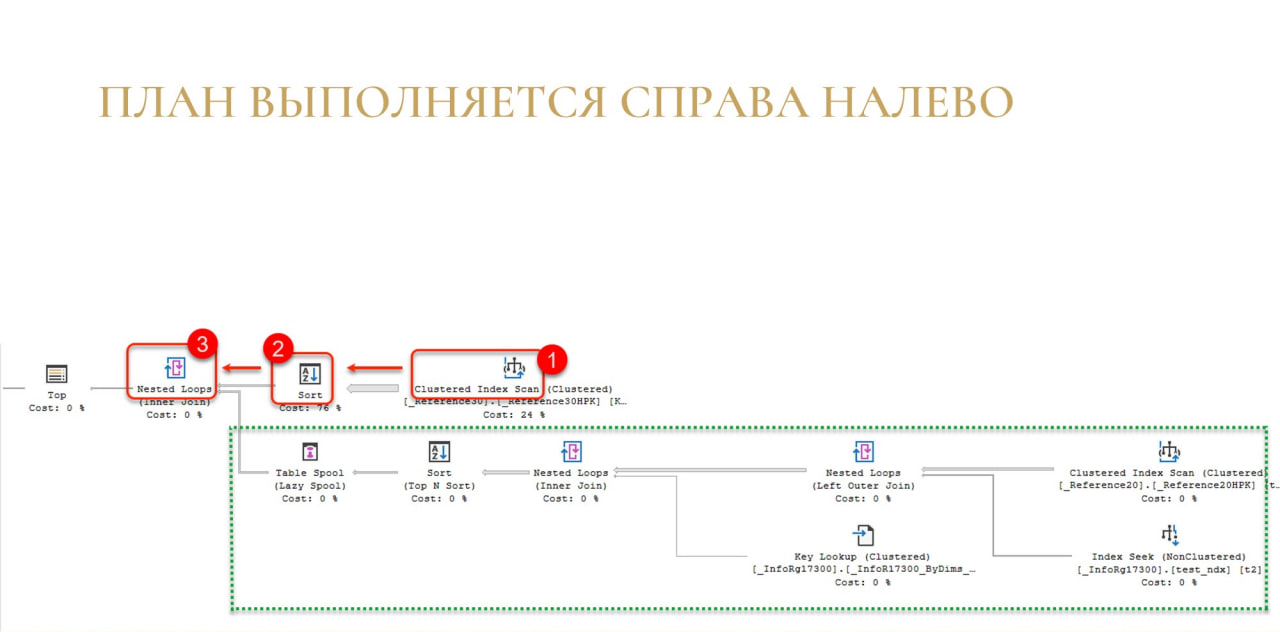
Потом уже у Nested Loops спрашивают: «Дай строку». Тот говорит, что не может, так как у него в этом плане есть еще одно поддерево, нужно его сначала выполнить, соединить результаты выполнения. Только после этого он сможет отдать строку.
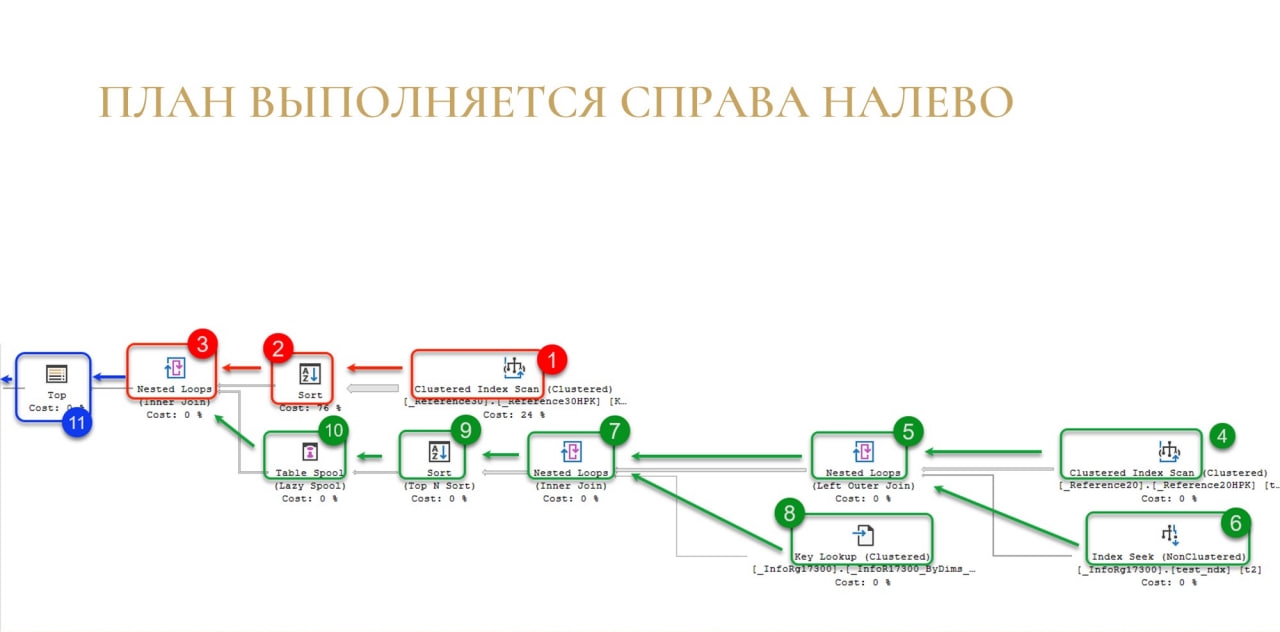
И в этом поддереве повторяется то же самое: по цепочке с правого угла эти строки выдаются.
И после того, как мы получили все строки в Nested Loops, передаем из дальше в Top и выполняем.
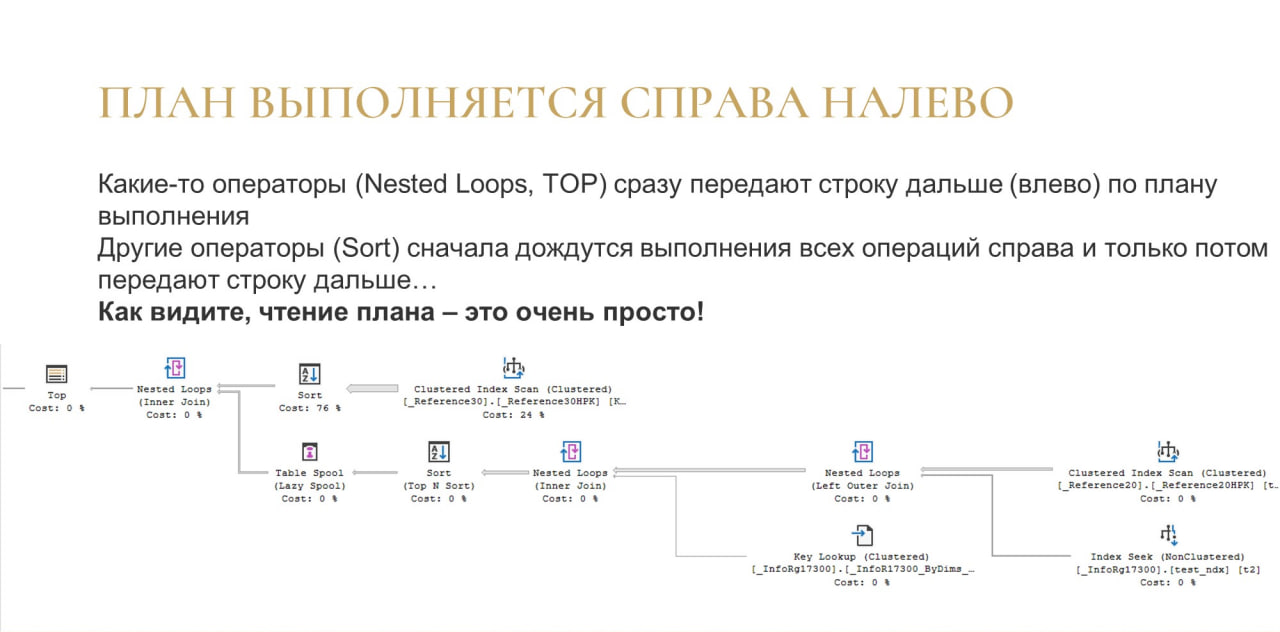
Важно понимать, что план выполняется справа налево, и именно так движутся данные в вашем плане. Зная это правило выполнения, вы понимаете, куда смотреть.
Конечно, нужно еще учитывать, что там есть какие-нибудь блокирующие операторы, есть какие-то операторы, которые что-то могут тормозить и т.д.
Если нет опыта изучения планов, это может быть иногда обескураживающе. Не очень понятно, как действительно выполнятся операции, и где находится какое-то узкое место.
Живой план выполнения
На этапе обучения важно понять, как выполняются планы и в каком порядке все работает.
К счастью, начиная с 16-й версии MS SQL (и нужна еще Management Studio 18) появилась такая штука, как живой план выполнения. Вы можете поместить план запроса в Management Studio, нажать «Получить живой план выполнения», запустить выполнение запроса, и план просто оживает.
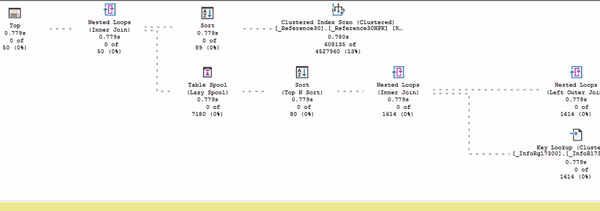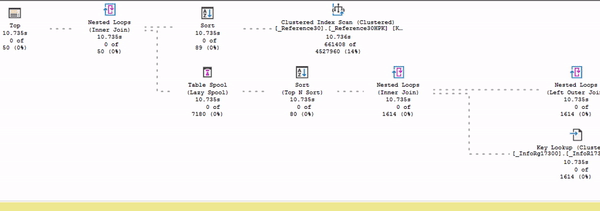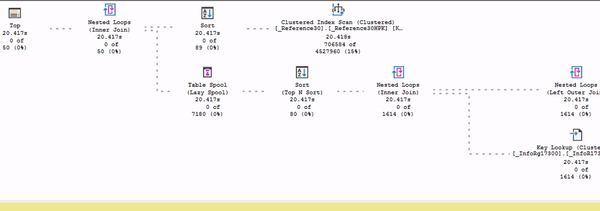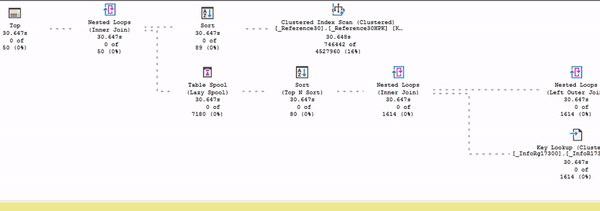
В этом представлении (в живом плане выполнения) видно, как считается статистика: собирается время выполнения, меняется количество строк, которое выбирается из плана по каждому оператору. Можно посмотреть, как идут данные и в каком порядке.
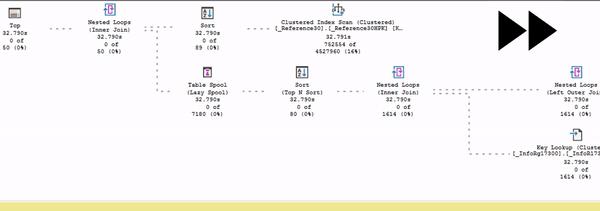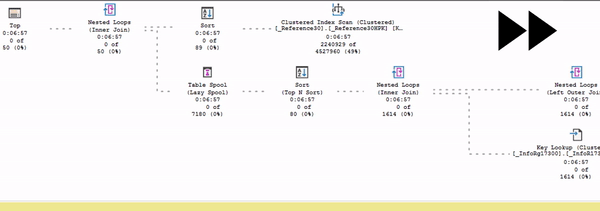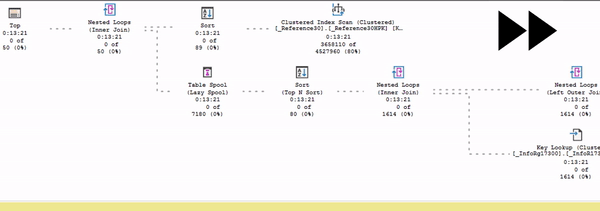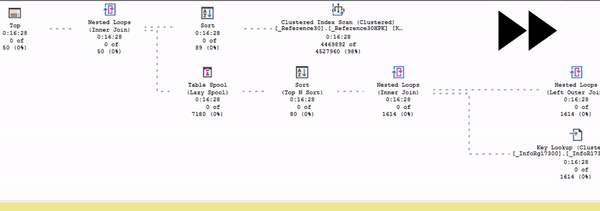
Здесь процесс выполнения запроса показан в режиме ускоренного воспроизведения – я специально подобрал тяжелый запрос, который будет выполняться очень долго.
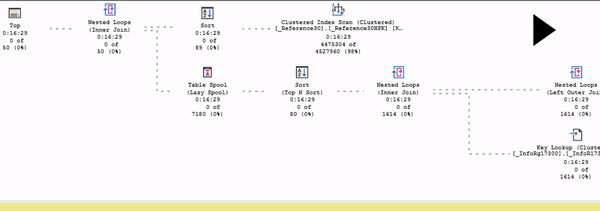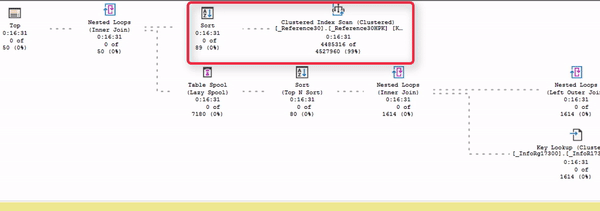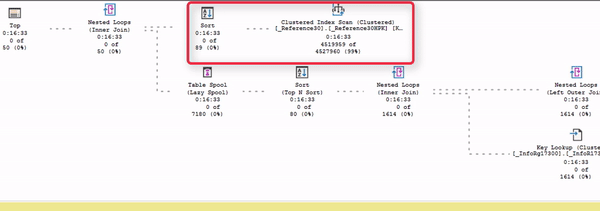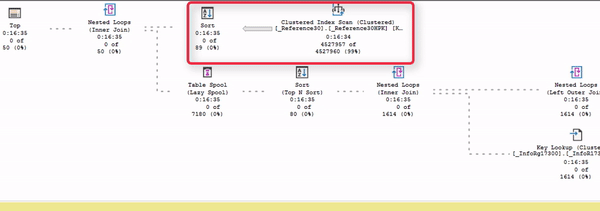
Обратите внимание: есть поток данных от Index Scan до сортировки. И дальше данные никуда пока не идут, потому что в данном случае сортировка – это блокирующий оператор. До сортировки движение есть, а дальше – никакого движения нет.
Это то, что вы можете наглядно в живом плане увидеть.
Почему так происходит? Потому что сортировке сначала нужно получить весь объем данных, который она собирается сортировать, и пока она его не прочитает и не отсортирует – она не может продолжать выдавать данные дальше.
Все ждут, когда сортировка получит эти данные.
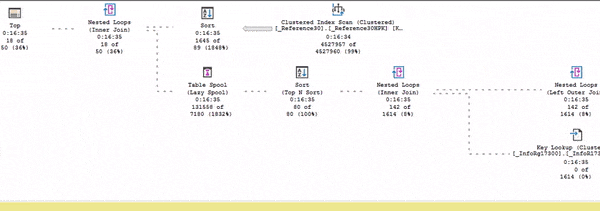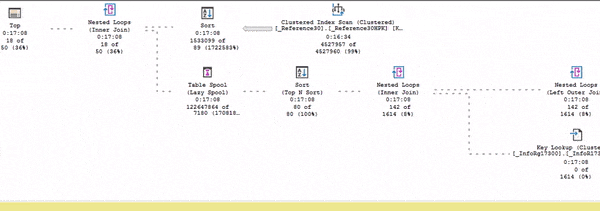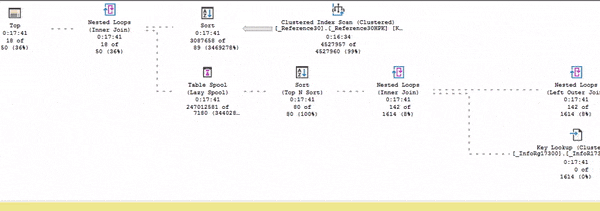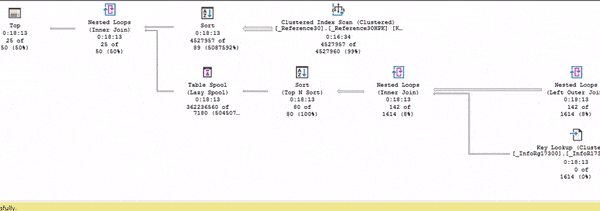
И только после этого весь остальной план оживает.
Еще раз повторюсь, живой план выполнения – это неоценимая вещь, чтобы понимать, что от чего зависит, как движутся данные и т.д.
Когда я разбираю планы и пытаюсь найти какие-то проблемы, для меня важно следить за потоком данных. Это как текущая река. В идеальном плане у вас от начала и до конца этот поток реки должен быть непрерывным и ровным.
Как только вы видите какое-то нарушение потока (как Sort на примере), скорее всего именно в этом месте у вас и находится проблема, которая мешает быстро выполняться вашему плану. Именно сюда стоит смотреть, именно это стоит изучить, и здесь вы, скорее всего, и найдете проблему.
Виды планов
Давайте разберемся, какие планы бывают в MS SQL, и чем они друг от друга отличаются.
Первый вид плана самый простой и самый доступный – Estimated Plan. Это то, что вы можете получить, не выполняя запроса. Даже более того: этот план создается перед выполнением запроса.
По-английски он звучит, как «предполагаемый», «предположительный» план. Но более правильный перевод тут будет - “предварительный”. На самом деле, это тот же самый план с тем же порядком операторов, который будет выполняться дальше. Единственное, чего в нем нет – это статистики о времени выполнения.
Estimated Plan знает, что мы сначала прочитаем из индекса, потом сделаем соединение. Он предполагает по статистике, сколько мы прочитаем из индекса, но точной информации в нем пока нет. Но это тот же самый план с тем же порядком операторов, который будет выполняться дальше.
Live Plan – это то, что вы видели на моих слайдах ранее. Это тот же Estimated Plan, который ожил. В нем мы видим живую статистику выполнения в реальный момент времени. Его удобнее всего наблюдать в Management Studio, хотя есть специальные вьюхи, из которых вы тоже можете вытащить эту информацию и изучать ее сторонними средствами.
Actual Plan – это самая полезная вещь, самая бесценная, но и самая дорогая. Мы не можем себе позволить получать Actual Plan для каждого запроса (это слишком медленно и очень сильно просаживает вашу производительность). Но именно в Actual plan у вас будет статистика по времени выполнения, вы будете знать реальные цифры: сколько времени прошло, сколько и чего было прочитано и т.д.
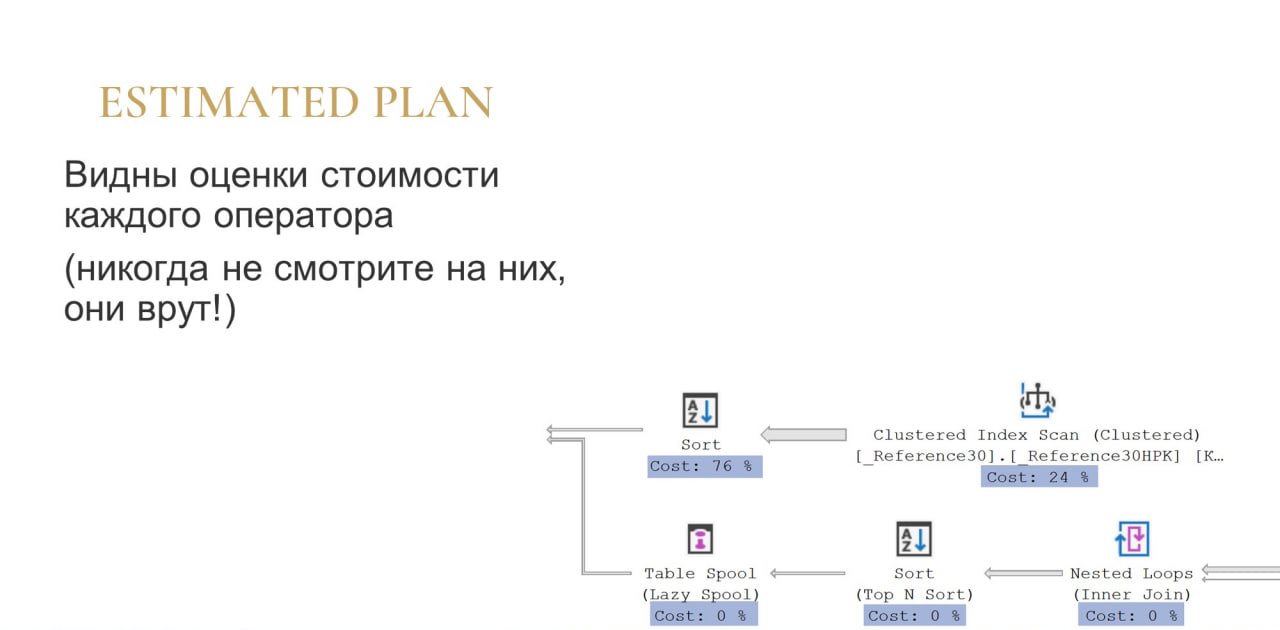
Если мы посмотрим на Estimated Plan, у нас будет просто порядок операций и внизу будут оценки, на которые обычно очень любят ориентироваться.
Не рассчитывайте на корректность этих оценок ни в коем случае! Если у вас более-менее сложный план (от десятка операторов), то скорее всего сумма этих процентов будет больше 100%. Во-первых, это само по себе смешно, а во-вторых, все эти оценки предварительные, они делаются на основе статистик. Если у вас статистики плохие, то и оценки тоже будут плохие, поэтому на них смотреть бессмысленно.
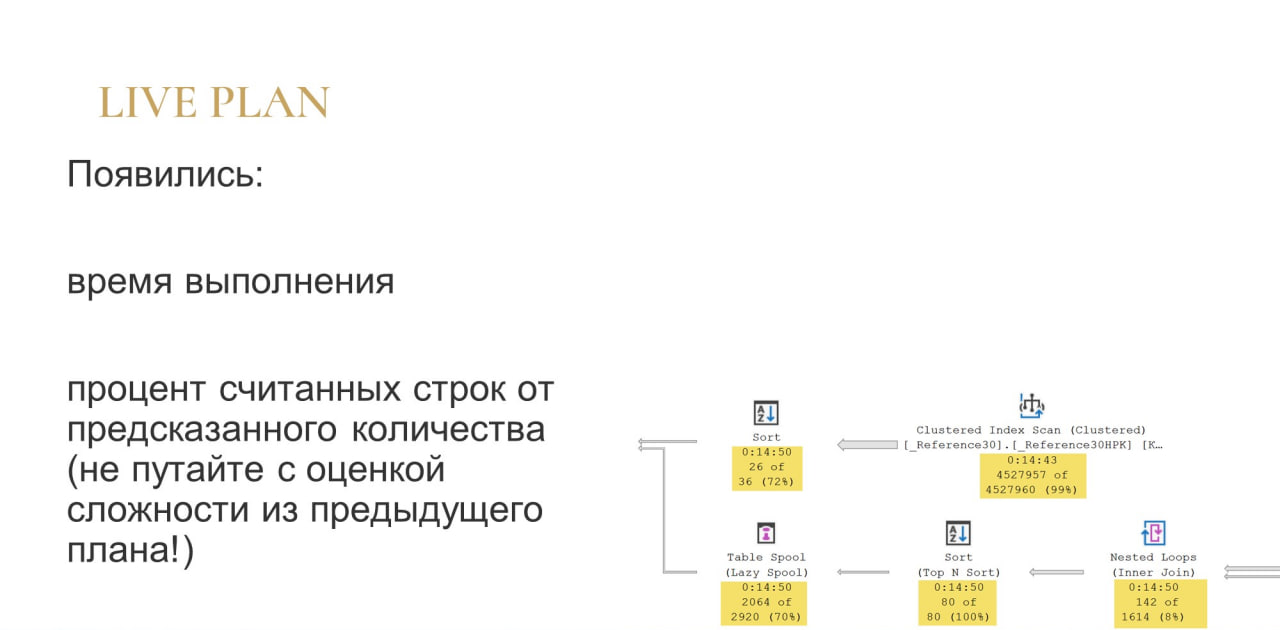
В Live Plan предыдущие оценки пропали, но появились другие (на слайде подсвечены желтым).
Первая строчка – это время выполнения на текущий момент. Что важно: обратите внимание, что под каждым оператором сейчас время выполнения одинаковое. В Live Plan у вас счетчик времени выполнения для каждого оператора считается синхронно.
Две следующие строки – это оценка ошибки. Показывается, сколько строк прочитано и сколько ожидалось прочитать.
-
Например, у оператора Sort сверху мы видим недооценку – 26 из 36. По статистике ожидали прочитать 36 строк, но пока прочитали 26. Либо это ошибка оптимизатора, либо мы просто пока не успели прочитать все, что хотели. Это же Live Plan, он продолжает выполняться. Возможно, сейчас время пройдет, и он дочитает все, что ему было нужно.
-
У оператора Nested Loops внизу та же самая недооценка: 142 из 1614, разрыв еще сильнее.
-
А у других операторов внизу мы видим 80 из 80 – сколько ожидалось, столько и прочитал.
На это можно ориентироваться, чтобы сразу на этапе выполнения понять, ошиблась у вас статистика или нет, правильный план построился, или он вообще не угадал, и цифры реального чтения расходятся.
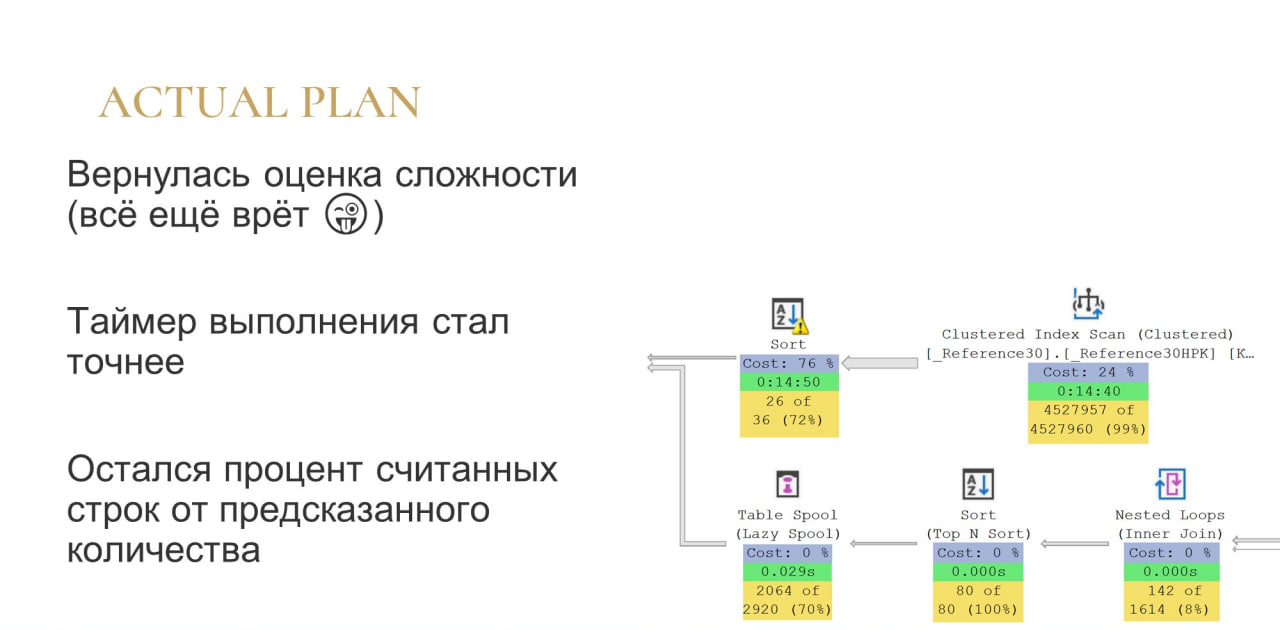
Ну и Actual Plan – это то, что мы можем увидеть на плане без какого-либо детального изучения.
-
Здесь также отображается статистика, которая была в Estimated Plan. Продолжаем ее игнорировать, потому что смысла в ней никакого нет.
-
Время выполнения: то время, которое в Live Plan тикало для каждого оператора одинаково и синхронно, здесь превратилось в накопительное время. Соответственно каждый оператор знает сколько времени у него потратилось.
-
И осталась статистика по эффективности, по тому, сколько мы ожидали и сколько мы прочитали. Это очень важно именно в контексте Actual Plan, потому что Actual Plan завершился. Мы больше ничего не ждем: все, что могло быть прочитано – прочитано. Поэтому смотрим и изучаем.
Что можно увидеть в плане
Расскажу, какую дополнительную информацию можно увидеть в планах.
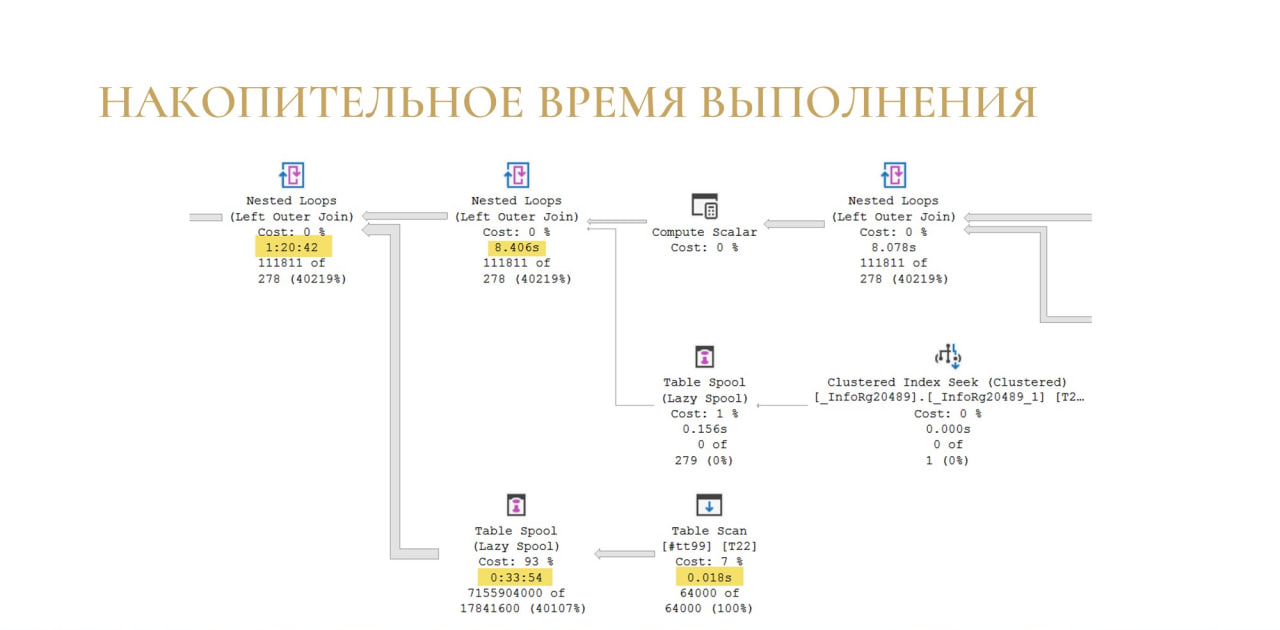
Во-первых, как я уже ранее говорил – в Actual Plan можно увидеть накопительное время выполнения.
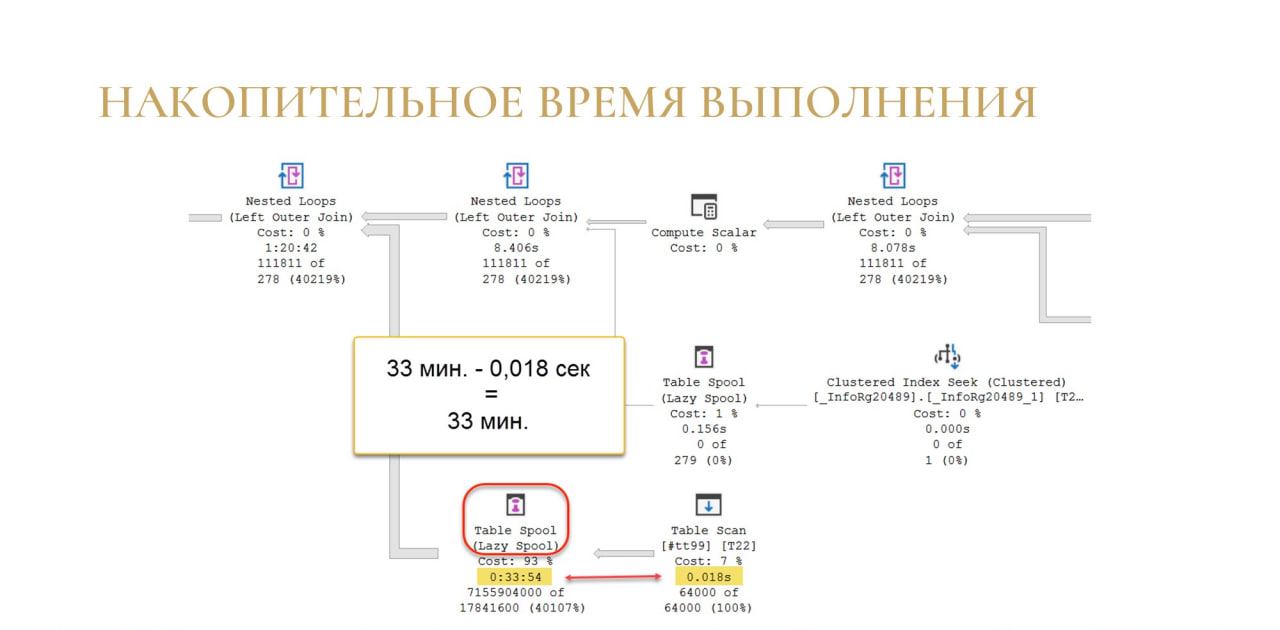
Чтобы понять время выполнения конкретной операции, мы просто вычитаем ее время из предыдущей.
Как на слайде: у нас есть Table Spool, на который ушло полчаса, предыдущая операция была выполнена за доли секунды, стало быть, все полчаса у нас ушли на формирование Table Spool.
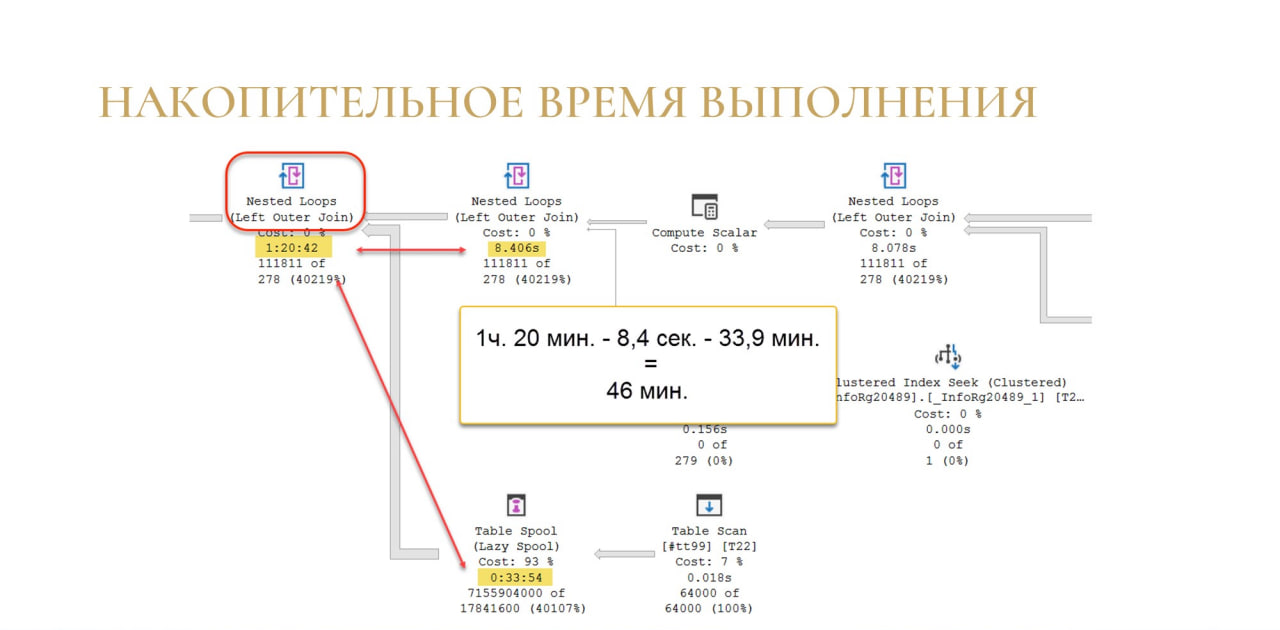
Для более сложного оператора соединения Nested Loops механизм тот же самый: мы просто вычитаем из времени ее выполнения время выполнения всех операторов в дереве, которые стоят перед этим оператором. По слайду мы понимаем, что 46 минут потом отдельно ушло на операцию соединения.
Если вы ищете в чем у вас проблема и если вы достали Actual Plan, это один из самых простых способов найти какую-то проблемную операцию. Просто сравниваете, ищете перепад по времени и понимаете, на какую именно операцию у вас ушло больше всего времени. Дальше уже разбираетесь, что с ней не так.

Еще из интересного у нас есть условия поиска в индексе.
По каждому оператору доступа данных (Seek, Scan – что бы это ни было) мы в секции Seek Predicates можем увидеть, по каким условиям выполнялся поиск.
Это тоже может быть интересно. Например, бывает так, что поиск разваливается на два оператора – сначала мы ищем по некластерному индексу, потом по кластерному и т.д.
Когда понятно, что именно мы достаем из этого индекса, мы можем понять, как это улучшить.

Если мы откроем план в виде .xml (по правой кнопке в Management Studio – Show xml), в полученном тексте мы тоже увидим много интересных вещей.
Во-первых, увидим информацию о статистиках, которые использовались при подготовке этого плана. Вы можете посмотреть, какие статистики были и, самое главное, в каком они были состоянии. Для этого не нужно ждать выполнения запроса и получать Actual Plan: эта информация доступна в Estimated Plan.
ModificationCount – это сколько изменений в статистике накопилось с момента пересчета. Если это значение зашкаливает, то пересчитываем статистики и, теоретически, план должен нормализироваться. И наоборот: если здесь все хорошо, то скорее всего что-то не так с запросом, и мы его как-то плохо написали.

Еще одна крутая штука, которая появилась в MS SQL Server 2016 – это статистика по ожиданиям. Она доступна в Actual Plan.
Здесь мы видим, какие у нас были ожидания во время выполнения запроса, и сколько времени мы на них потратили. Если что-то по непонятным причинам работает медленно, здесь вы можете посмотреть, на что вы потратили время, и сколько этого времени ушло.
Все эти типы ожиданий – стандартные системные, они очень легко гуглятся. На сайте Microsoft приведен полный список всех типов ожиданий, там все это подробно объяснено.
Если вы поймали Actual Plan по какому-то тяжелому запросу, статистика по ожиданиям тоже может многое вам объяснить.

И последний пример, который я привожу (но не последнее, что можно там найти) – это метаинформация о компиляции плана.
В ней можно посмотреть, сколько было памяти, какая степень параллелизма, почему было принято решение параллелить, не параллелить и пр.
Вверху очень интересное сообщение, почему закончилась оптимизация плана: из-за TimeOut.
Если вы такое видите, скорее всего, у вас слишком сложный план, очень большое дерево перебора вариантов и SQL-сервер просто не успевает перебрать все предоставленные варианты. В какой-то момент он останавливается, говорит: «Все! Хватит! Timeout! Берем то, что есть!» Это обычный знак того, что вы работаете не самым лучшим планом, могло бы быть и лучше, если бы вы упростили свой запрос.
Это не последнее, что здесь можно увидеть. Всех призываю посмотреть, что скрывается в этом .xml, наверняка что-то еще дополнительное и полезное для себя найдете.
Как искать проблемы в плане
Ну и самое интересное: как искать проблемы в плане?
Я сейчас дам несколько примеров. Важно, что это не какой-то исчерпывающий список, это просто несколько примеров, от которых можно оттолкнуться.
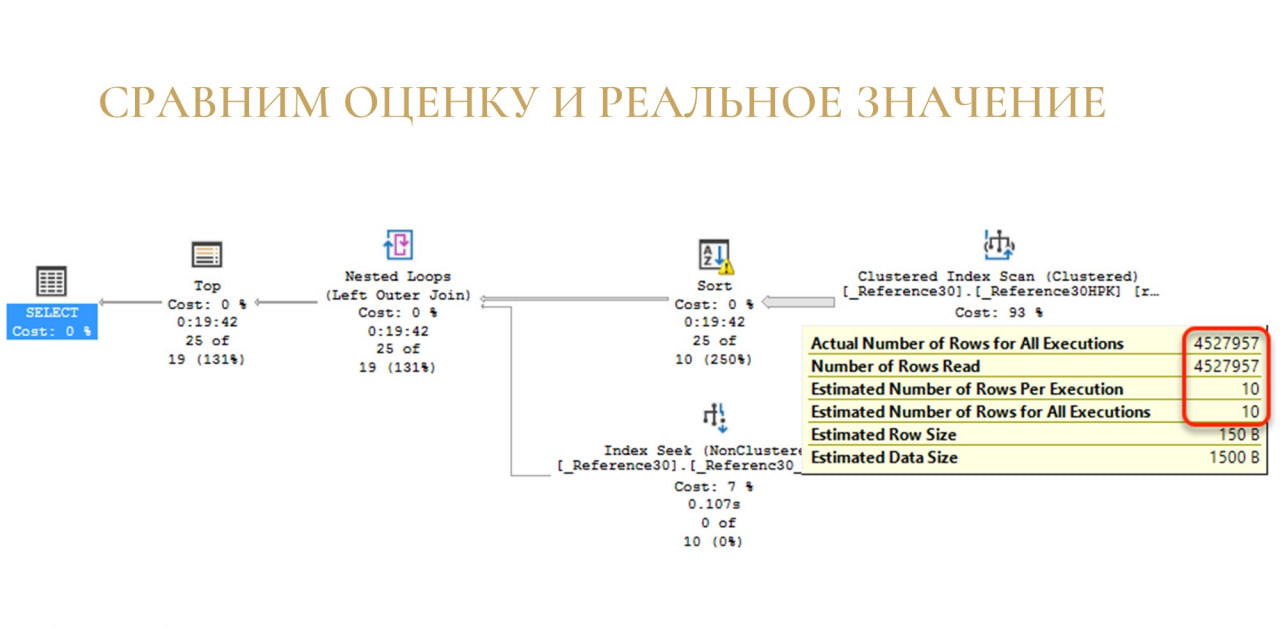
Ранее я уже говорил, что в Actual Plan у нас есть данные о примерном числе строк – сколько мы будем читать, и о том, сколько мы реально прочитали.
Это очень простая, но в то же время эффективная техника: берем и сравниваем, сколько мы ожидали и сколько мы прочитали.
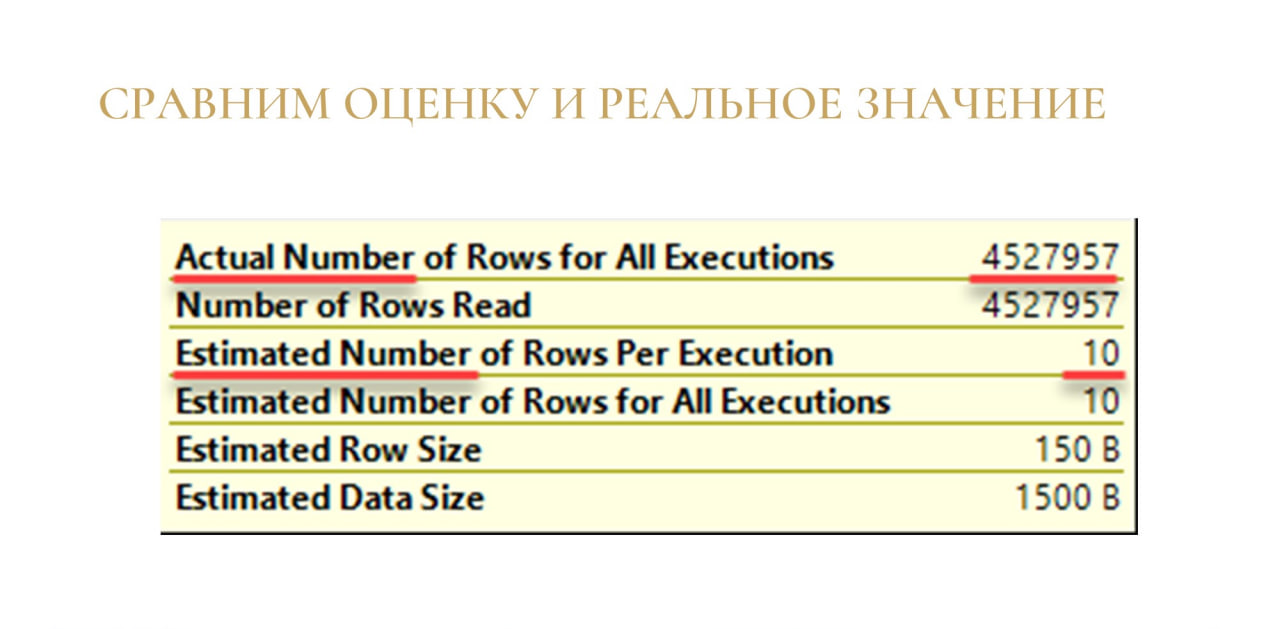
Если у вас такой же разрыв, что ожидали 10 строк, а прочитали 4,5 миллиона – первая и наиболее вероятная причина, что у вас просто протухла статистика. Из-за неправильной статистики MS SQL Server неправильно оценил число строк в вашей операции и построил неправильный план.
Обратите внимание, как изначально выглядит этот план – у нас Scan, потом какая-то сортировка, а потом – Nested Loops.

Мы пересчитываем статистику и план преображается, становится совершенно другим.
Самое важное – теперь вместо Nested Loops у нас Merge Join. Это совершенно другой оператор.
Nested Loops очень хорошо работает, когда у вас мало строк на входе (как ожидалось 10 строк), а когда MS SQL понял, что у вас будет много строк, он сразу отменил Nested Loops и поставил вместо него Merge Join.
Если сравнить:
-
в первом исходном варианте у оператора Top время выполнения 19 минут;
-
когда мы пересчитали нашу статистику, время выполнения стало 9 минут.
Просто за счет пересчета статистики мы ускорили выполнение запроса в два раза. И я скажу, что это не самый лучший результат: были результаты, когда запросы ускорялись в 10 раз и больше.
Сравниваем ожидаемое и реальное число строк. Если вы видим, что у нас очень большой разброс, пересчитываем статистику. План меняется и, скорее всего, всем от этого становится лучше.

Второй пример: ищем перепады в числе строк.
Для этого у меня есть запрос, который прикидывается запросом списка.
У нас есть справочник «Контрагенты», мы первые 25 строк выбираем, упорядочиваем по полю ОКВЭД (допустим, бухгалтеру так захотелось). Ожидаем, что у нас все будет достаточно быстро: всего-то надо забрать какие-то 25 строчек из таблицы.
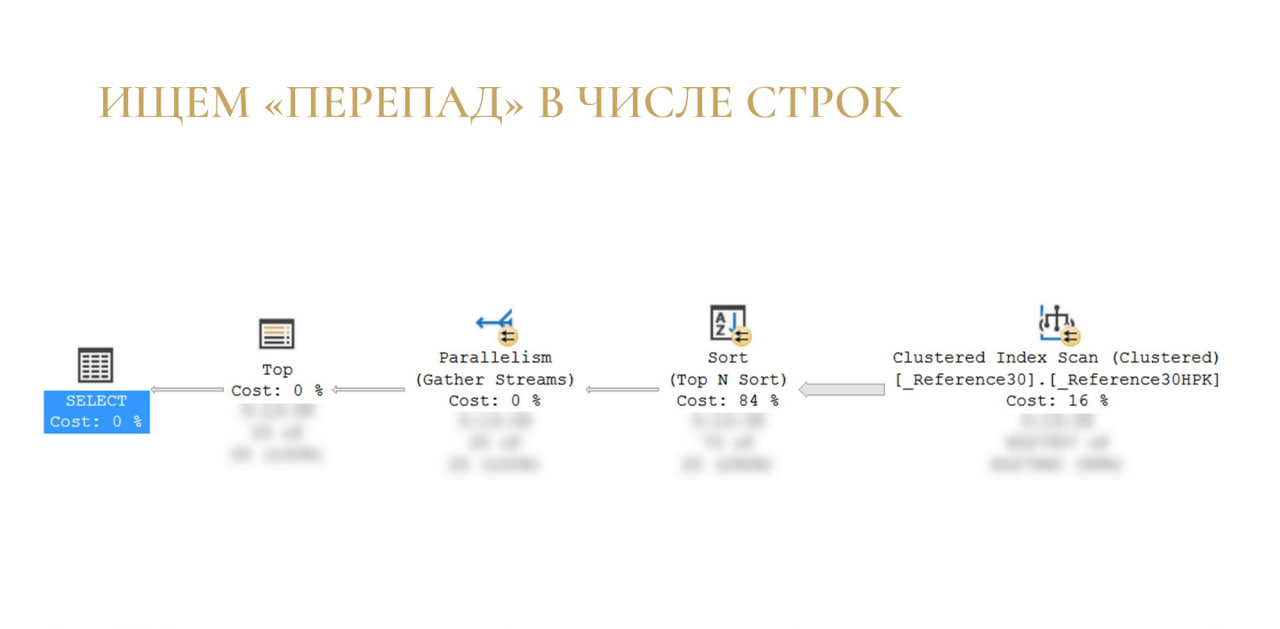
Но ничего подобного не происходит – запрос выполняется дольше, и я специально заблюрил статистику, чтобы она не отвлекала от главного.
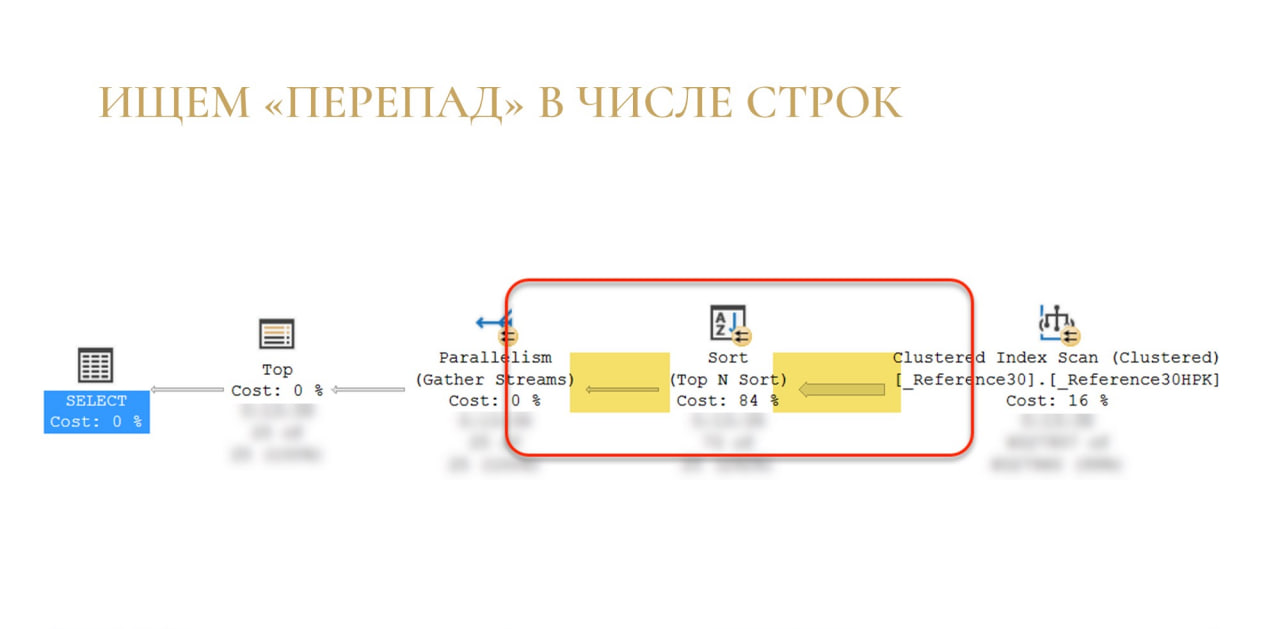
Помните, я говорил, что данные можно представить, как реку или какой-то поток и что важно следить за порогами и водоворотами?
Здесь та ситуация, когда у нас возник порог – на вход на сортировку приходит много данных (широкая стрелка), а после сортировки очень мало.
Если вспомнить запрос, становится понятно, в чем дело – у нас просто нет индекса для сортировки по полю ОКВЭД. Соответственно, чтобы достать первые 25 строк, приходится прочитать вообще всю таблицу и отсортировать ее. Если таблица большая, то, возможно, что-то даже в tempdb выгрузится. И только после того как сортировка будет готова, мы вытаскиваем вот эти первые 25 строк.
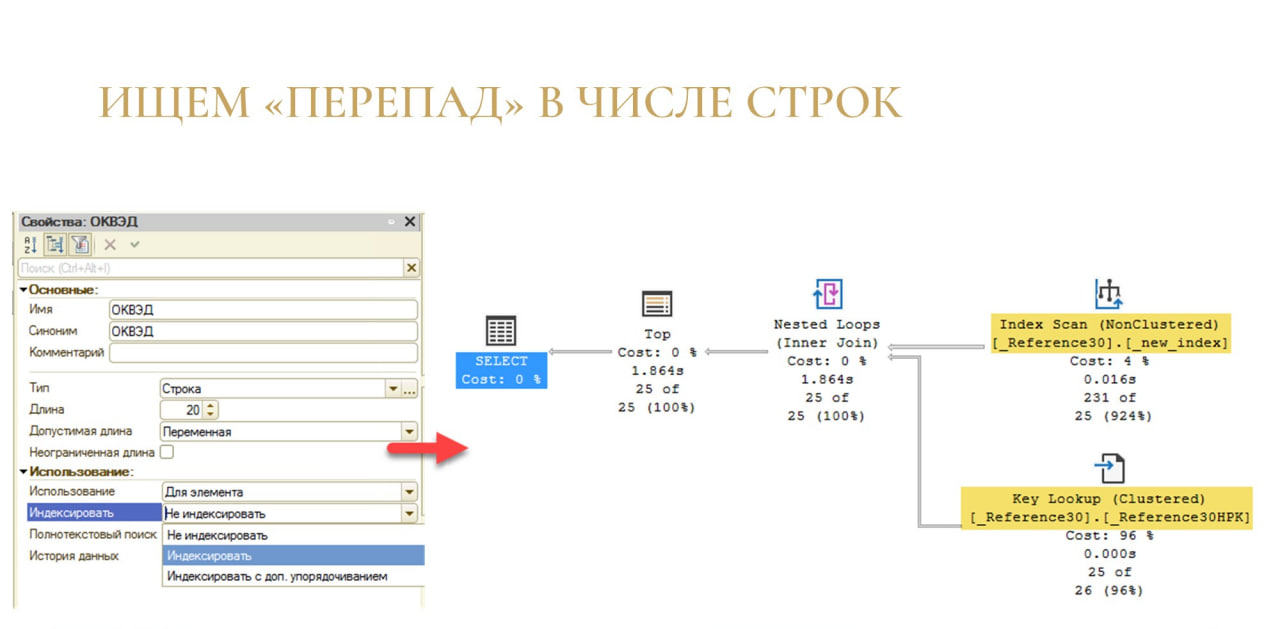
Лечение очень простое: если мы понимаем, что по нашему полю упорядочивания нет индекса, просто добавляем индекс в конфигураторе.
План преобразуется – обратите внимание, что стрелки теперь сбалансированы, больше нет перепада. План поменялся, мы читаем те 25 строк, которые были нужны, и перепада в объемах данных больше нет. План преобразился и стал эффективным.

И последний пример: проверяем «попадание» условий в наши индексы.
Здесь запрос немного интереснее: мы соединяем контрагентов самих с собой, отбираем их по КПП, по наименованию группы и соединяем по родителю.
В целом ничего криминального в этом нет – обычный запрос, может немного перекрученный.
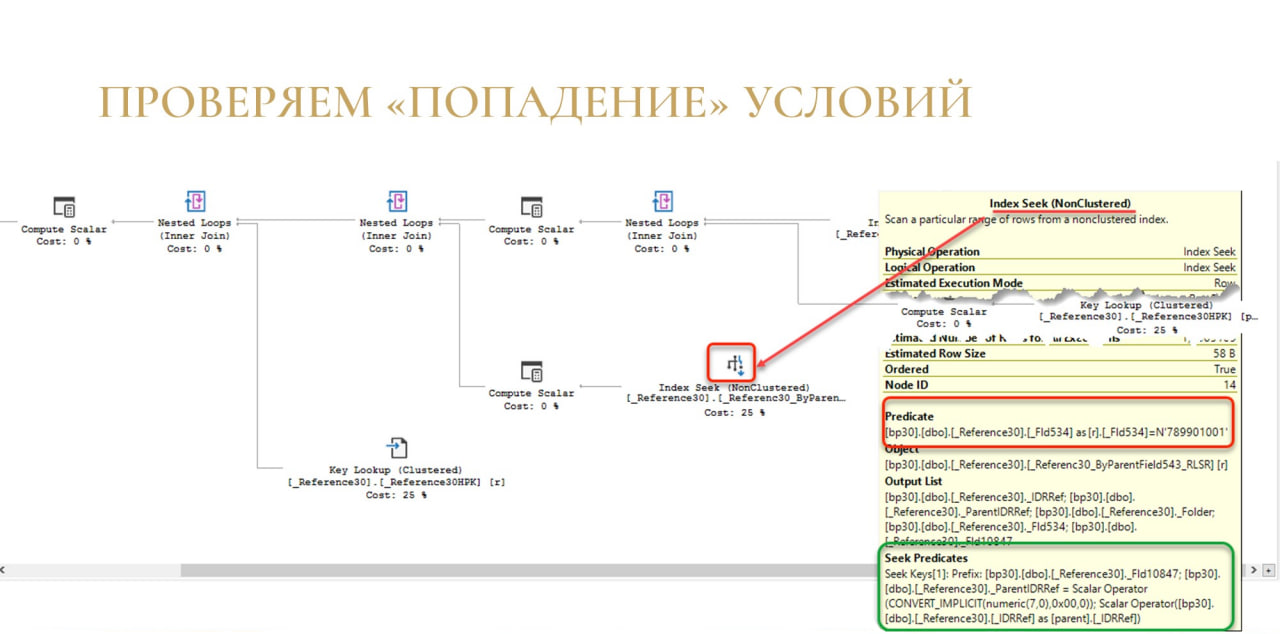
И план здесь тоже достаточно обычный – все сбалансировано, каких-то перепадов по стрелкам у нас нет. Все более-менее хорошо.
Но давайте посмотрим на секции условий. Я говорил, что у нас в каждом операторе доступа к данным можно посмотреть, какие условия мы применяли, чтобы эти данные прочитать.
Здесь у оператора Index Seek условия делятся на две группы: Seek Predicate и Predicate. И то и другое – это условия отбора, и то и другое – фильтруется, но в разных ситуациях.
-
Seek Predicate – это то, что мы фильтруем и проверяем прямо на этапе чтения индекса с жесткого диска или из памяти.
-
Predicate – это то, что мы потом дофильтровываем. Если кто-то помнит, когда интернет был маленьким, у «Яндекс» была кнопка «Искать в найденном». Естественно, это гораздо хуже и медленнее, чем искать сразу то, что тебе нужно. И вот Predicate – это то самое «Искать в найденном». Если вы видите Predicate, вы понимаете, что условие у вас работает по вашему индексу, но оно работает недостаточно эффективно. Лучше бы он сразу искал в Seek Predicate в тот момент, когда он читает эти данные.
Разбираемся дальше, почему так происходит.
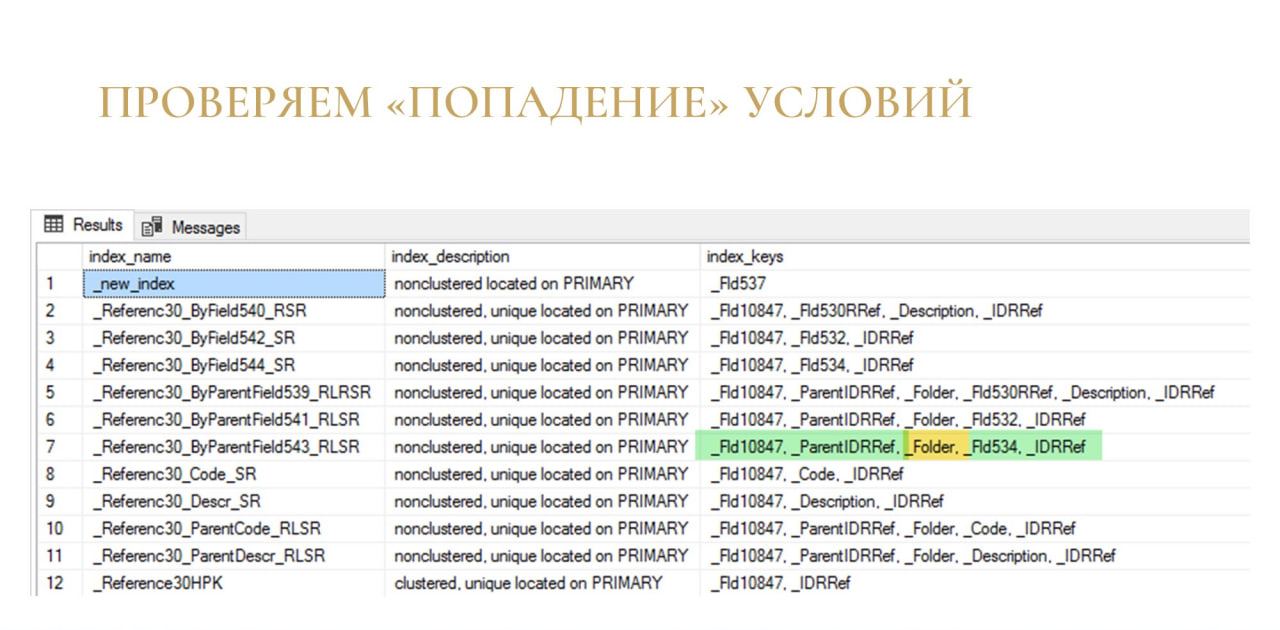
Смотрим состав индекса, из которого мы читаем. И видим вот такую картинку:
-
Зеленые – это те поля, которые мы вытаскиваем в рамках нашего запроса.
-
Желтое – это то поле, которого в запросе нет.
Все, что левее желтого поля Folder, попало в Seek Predicate. И СУБД шла по ключу индекса, искала по полям, по каким могла, а потом споткнулась о Folder, потому что Folder в условиях запроса не было, она не знает, какой Folder должен быть.
MS SQL споткнулся об этот Folder и все, что после него, ушло дальше в условия Predicate.
Он все прочитал, а дальше уже дофильтровывал в памяти среди этого разобранного набора.

Решение тоже достаточно простое – мы просто берем и добавляем дополнительное условие «ЭтоГруппа = ЛОЖЬ», чтобы полностью попадать в индекс.
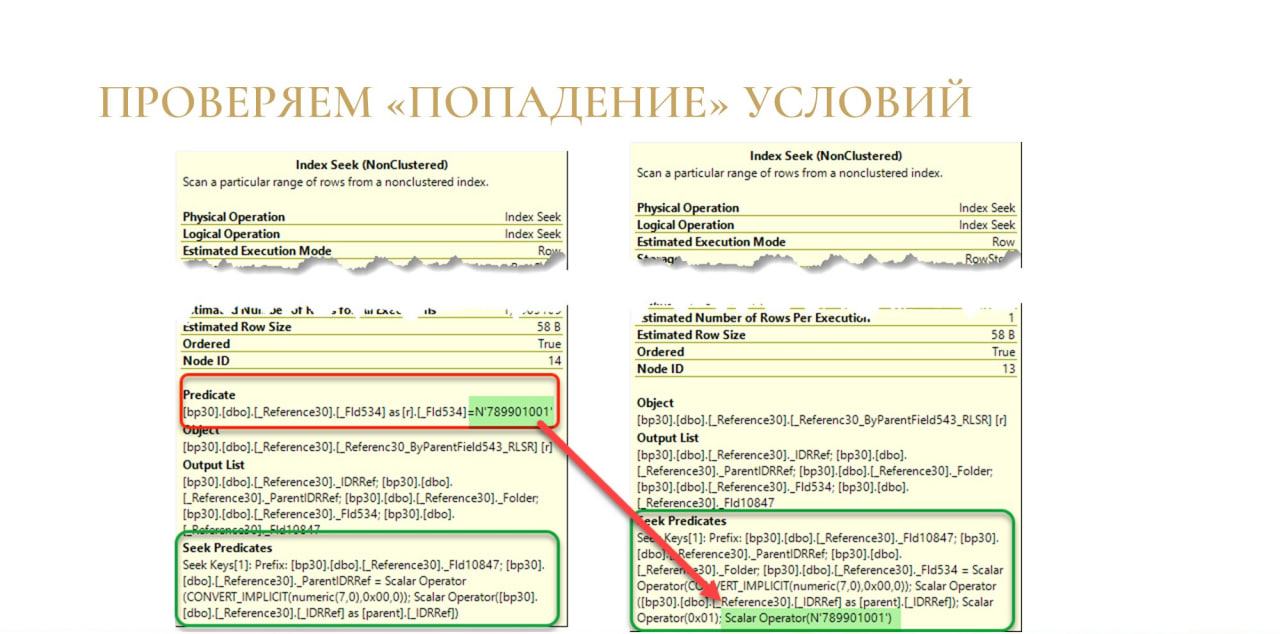
После этого условия оператора Index Seek преображаются – то, что было в Predicate, уходит в Seek Predicate. Мы максимально эффективно ищем наши данные, и все счастливы.
Это важно, потому что таким образом мы:
-
во-первых, экономим чтение и не засоряем память лишними страницами, которые мы бы отсекли на этапе Predicate;
-
во-вторых, мы экономим время, потому что происходит оптимизация, запрос работает быстрее.
Что почитать по теме
Еще порекомендую, что можно почитать по теме, потому что тема действительно очень большая и интересная. Я бы даже сказал бездонная.

На самом деле было очень тяжело найти русскоговорящие источники по этой теме. Очень много английских источников, по-русски практически ничего нет.
-
Во-первых, фундаментальная статья Remus Rusanu о том, как вообще работает SQL Server и как выполняются запросы. Статья очень большая, в ней есть всего понемногу, но качественно и по делу. Я настолько восхитился, что подготовил перевод этой статьи.
-
Во-вторых, это блог Дмитрия Пилюгина. Это человек, который, как мне кажется, больше всех в мире знает, как работает оптимизатор запросов в MS SQL. Это признанный специалист, у которого безумно интересный блог. Пишет он очень хорошо и разбирает какие-то мельчайшие детали и нюансы. Если хочется куда-то глубоко погрузиться, то это – как раз то самое место, которое стоит изучить.
-
И последняя ссылка – это инструмент Microsoft, который показывает типичные ошибки в плане запроса. Он встроен в Management Studio начиная с версии 17.4. Похож на SonarQube для планов запросов. Это – статический анализ, там какие-то очень простые примеры. Но, чтобы набить руку и примерно представлять, как это работает и на что обращать внимание, можно посмотреть и этот источник. Сложные вещи он не выловит, но хотя бы какую-то базу вам даст.
-
И еще одна вещь, которую я забыл указать на слайде: есть очень старая книжка Дена Тоу «Настройка SQL. Для профессионалов». В бумажном виде вы ее никогда и нигде уже не найдете, потому что она была издана в 2004 году, и ее уже раскупили. Но в электронном виде где-то можно найти. Книжка старая, но до сих пор актуальная. Она описывает фундаментальный низовой уровень оптимизации запросов. Там примеры для четырех СУБД. Есть ощущение, что в фирме «1С» читали эту книжку, потому что там примеры как раз на SQL Server, PostgreSQL, Oracle и DB2 – все, что в 1С поддерживается. Если вы эту книжку достанете, прочитайте обязательно – она очень хорошо поправляет голову в плане оптимизации.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Moscow Premiere.
Вступайте в нашу телеграмм-группу Инфостарт